你的AI助手正在靜默遺忘你:Claude Code和Codex的記憶工程拆解
整理版優先睇
Claude Code 同 Codex CLI 記憶系統拆解:記憶有上限,遺忘係設計
呢篇文章係基於 Claude Code 嘅源碼洩漏同 Codex CLI 嘅開源,拆解兩大 AI 編程助手嘅記憶系統設計。作者從工程角度分析咗 Claude Code 嘅7層防禦同 Codex CLI 嘅極簡 markdown 方案,指出佢哋有個共同嘅硬限制:記憶有上限,超過嗰條線嘅資訊會靜默遺失,而 AI 自己都唔知。
整體結論係:記憶唔係儲存問題,而係取捨問題。喺有限嘅記憶預算裏面,揀咩嘢嚟記住比點樣儲存更重要。兩套系統各自用唔同嘅工程哲學去應對,但最終都逃唔過同一條天花板。
作者提醒開發者,無論你用邊個工具,都要清楚知道個記憶系統點運作,主動管理重要資訊,避免依賴自動記憶而失去關鍵上下文。
- Claude Code 同 Codex CLI 嘅記憶系統都有硬性上限(200行/25KB 同 5000 token),超過就靜默丟失,AI 完全唔知道自己唔記得咗。
- Claude Code 採用7層縱深防禦,由工具結果儲存到夢境系統,層層遞進延緩壓縮,設計目標係用最平嘅層擋住問題。
- Codex CLI 行極簡路線:純 markdown 檔案、grep 檢索、5000 token 硬切,可預測但召回能力有限,空閒6小時先觸發記憶提取。
- 共同教訓:記憶預算有限,設計者必須取捨「記住咩」而唔係「點樣記」;自動記憶唔可靠,開發者要主動管理。
- 可行動點:定期編輯 CLAUDE.md 或者自定義記憶提取規則,將最關鍵嘅架構決策、偏好、環境資訊寫入,降低被截斷嘅風險。
結構示例
# Session Title_A short and distinctive 5-10 word descriptive title_# Current State_What is actively being worked on right now?_# Task specification# Files and Functions# Workflow# Errors & Corrections# Codebase and System Documentation# Learnings# Key results# Worklog當 AI 助手靜默遺忘你
你用 Claude Code 寫咗三個月項目,佢知道你偏好集成測試、記得接口不穩定、明白 team 嘅 hotfix 流程。但有一日,佢開始重複問你已經答過嘅問題,寫嘅測試撞返嗰個不穩定接口,架構決策被推翻。佢唔係幻覺,佢只係唔記得咗。
唔係幻覺,係忘記
呢個唔係 bug,係設計。Claude Code 源碼洩漏後,開發者發現一個從未公開嘅硬限制:記憶索引檔案最多 200 行。超過第 201 行,最老嘅記憶被靜默截斷,冇警告、冇報錯、冇日誌。AI 見到嘅係一個乾乾淨淨嘅系統提示,佢完全唔知有任何嘢丟失咗。
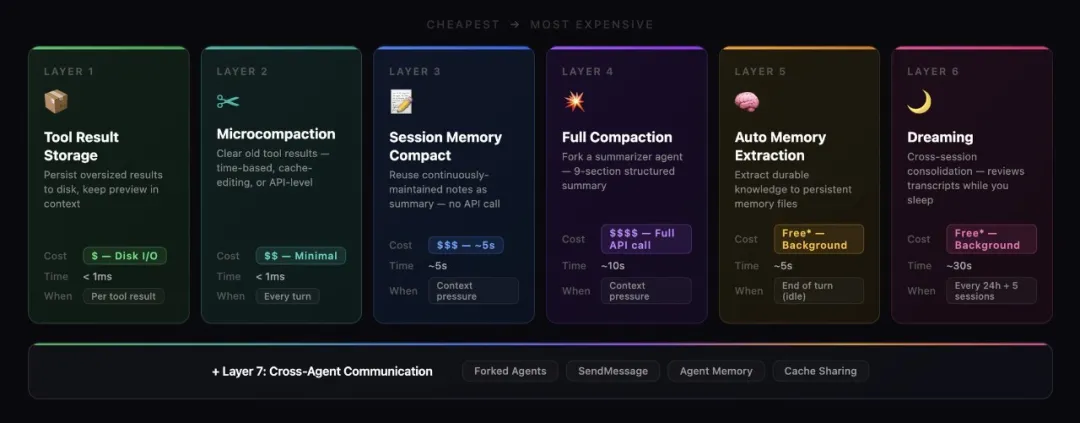
Claude Code 嘅7層縱深防禦
Claude Code 嘅記憶系統好似一座精心設計嘅城堡,有7層防線,每層都比上一層更貴,但目標係用最平嘅層擋住問題,避免觸發昂貴嘅壓縮。
7層防禦
- 1 工具結果儲存:大結果寫磁碟,上下文只留 2KB 預覽,模型需要時再讀完整內容。
- 2 微壓縮:每輪對話前檢查時間衰減(60分鐘 cache TTL)、Cache-Editing API、Context Management API,用最低成本清理舊結果。
- 3 會話記憶:fork 子 agent 持續維護一個 markdown 筆記檔案,包含 Session Title、Current State、Task specification 等,壓縮時直接用,零 API 成本。
- 4 全量壓縮:fork summarizer agent 兩階段輸出 9 段式摘要,分析塊喺壓縮後被剝離,提升質量,仲有熔斷器防止連續失敗。
- 5 自動記憶提取:每輪對話結束後後台 agent 審查內容,提取四類記憶(用戶、反饋、項目、引用),明確唔存可以從 codebase 推斷嘅資訊。
- 6 夢境系統:跨會話記憶整合後台進程,按 Orient、Gather、Consolidate、Prune 四個階段鞏固長期記憶,有 PID 鎖同超時自動回收。
- 7 跨 Agent 通信:forked agent 模式隔離可變狀態但共享 prompt cache,防止成本爆炸。
用最平嘅層擋住問題
整個系統嘅設計哲學就係一句話:用最平嘅層擋住問題,只有擋唔住先觸發更貴嘅層。prompt cache 優化到變態,fork 子 agent 嘅 API 請求前綴字節級一致,係為咗慳 cache miss 嘅成本。
Codex CLI 嘅極簡 markdown 哲學
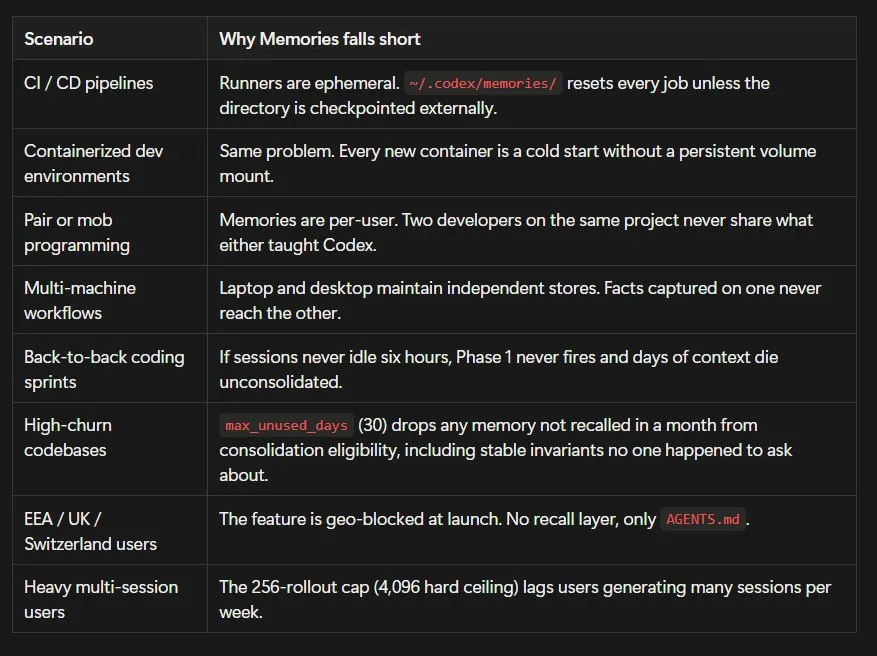
Codex CLI 嘅方案係一個精心整理嘅檔案櫃。所有記憶住喺 ~/.codex/memories/,核心檔案得幾個:memory_summary.md、MEMORY.md、raw_memories.md、rollout_summaries/。冇 SQLite、冇 embedding 索引、冇不透明嘅二進制 blob,就係 markdown。
純 markdown,冇黑盒
- 1 寫入分兩階段後台整合:Phase 1 per-session 提取(空閒6小時觸發),Phase 2 全局整合(獲取鎖、同步磁盤、spawn 獨立子 agent)。
- 2 讀取用 5000 token 硬切:session 啟動時將 memory_summary.md 全量讀入後截斷,超出的靜默丟棄。
- 3 回退用 grep 搜 MEMORY.md:冇向量檢索,純文字子串匹配,可預測但隨檔案增長代價線性上升。
5000 token 硬切
Codex 用 predictable time 同 zero retrieval cost 換走咗 semantic recall。grep miss 嘅代價隨記憶檔案增長,但佢哋認為可接受。另外,6小時空閒門控意味住連續高強度開發者嘅記憶提取可能永遠唔會觸發。
嗰條睇唔見嘅線
兩個方案都有一道硬線,超過就丟失。Claude Code 嘅 MEMORY.md 索引檔案有 200 行上限(另加 25KB 字節上限),超過後系統靜默截斷最老嘅記憶,AI 下次啟動見到嘅係乾淨嘅被截斷過嘅索引。Codex CLI 嘅 memory_summary.md 每次 session 啟動截斷到 5000 token,超出部分靜默丟棄,冇警告。
200行懸崖
5000 token 硬切
共同點只有一個:記憶有上限,超過上限嘅丟失係靜默嘅,AI 唔知道自己唔知道啲咩。有人翻遍 Claude Code 記憶系統後話:「It's not hallucinating. It's not broken. It just forgot.」
Claude Code 選擇建一座越來越高嘅城堡,7層唔夠就加第8層,加 circuit breaker 防止雪崩。Codex 選擇接受上限存在,將一切做到可預測、可審計、可控。兩種哲學,同一條底線。
唔係儲存問題,係取捨問題
呢篇拆解最值得記住嘅啟發係:記憶系統嘅設計核心唔係技術,而係取捨。你冇辦法記住所有嘢,AI 都係。開發者要理解工具嘅記憶操作,主動將最重要嘅資訊——例如架構決策、個人偏好、環境設定——寫入明確嘅位置(如 CLAUDE.md),而唔係依賴自動記憶。
主動管理記憶
- 定期檢查記憶檔案內容,確保關鍵資訊冇被截斷。
- 善用系統提示或 CLAUDE.md 將必要上下文固化。
- 考慮將長期記住嘅資訊寫入獨立檔案,並喺 prompt 中引用。
記住:記憶嘅上限,就係智能嘅上限。理解呢條線,先至可以真正用好 AI 助手。
你用 Claude Code 寫咗三個月嘅項目。佢知道你鍾意集成測試,知道嗰個接口唔穩定,知道你哋團隊 hotfix 會 skip 咗 PR 審核。
然後有一日,佢開始重複問你之前已經答過嘅問題。寫嘅測試撞咗落嗰個唔穩定嘅接口度。架構決策畀人推翻咗。
佢唔係喺度『幻覺』。佢只係唔記得咗。而且佢完全唔知自己唔記得咗。
呢個唔係 bug,呢個係設計。
2026年3月底,Claude Code 嘅源碼被洩漏到網上,開發者們蜂擁入去揾,有人睇 prompt,有人睇計費邏輯,有人直接衝向記憶系統。佢哋發現咗一個 Anthropic 從未公開文檔化嘅硬限制:你嘅記憶索引檔案,最多200行。
超過第201行嘅一刻,最老嘅記憶被靜默截斷。冇警告,冇報錯,冇日誌。AI 睇到一個乾乾淨淨嘅系統提示,佢唔知道有任何嘢唔見咗。
同一時間,OpenAI 嘅 Codex CLI 都開源咗自己嘅記憶系統。方案完全唔同,純 markdown 檔案、grep 檢索、5000 token 硬切。簡單到幾乎原始,但天花板同樣真實。
兩大 AI 編程助手,兩種截然相反嘅工程哲學,回答同一個問題:喺一個上下文窗口有限嘅模型裏面,點樣令 AI 『記住』你?
LLM 有一個繞唔過去嘅基本限制:上下文窗口係固定嘅。
Claude Code 預設 200K token,加咗 [1m] 後綴可以擴展到 1M。Codex CLI 嘅情況差唔多,模型嘅上下文長度有物理上限。
聽落好大。但一個寫程式嘅 session 好容易就爆咗呢個窗口:讀幾個檔案、跑幾轉 grep、做幾轉編輯迭代,token 就滿咗。
所以核心矛盾係:世界係無限嘅,上下文係有限嘅。
兩個團隊俾出咗完全唔同嘅答案。
Claude Code:7層縱深防禦
Claude Code 嘅方案好似一座精心設計嘅城堡,7層防線,每一層都比上一層更貴,但設計目標係令平嗰層擋住問題,避免觸發貴嗰層。
第1層:工具結果儲存
呢個係最輕嘅一層,成本幾乎係零,得磁盤 I/O。
問題在於,一次 grep 掃全庫可能返回 100KB+ 嘅文本。一次 cat 大檔案都有 50KB。呢啲結果塞入上下文之後,幾輪對話就過時咗。
Claude Code 嘅做法係:大結果寫磁盤,上下文裏便只留 2KB 預覽。
每次工具結果都會經過一個預算系統。超過門檻嘅,完整結果存到 tool-results/<sessionId>/<toolUseId>.txt,上下文裏便放一個 <persisted-output> 標籤包裹嘅預覽片段。模型需要睇全文時,可以主動去讀。
呢度有一個精妙嘅細節:一旦某個工具結果被替換為預覽,呢個決定就被凍結在 ContentReplacementState 記錄咗。後續每次 API 調用,同一個結果拎到嘅係同一個預覽,保證 prompt 前綴字節級一致,唔會破壞服務端 prompt cache。
第2層:微壓縮(Microcompaction)
每輪對話開始之前,Claude Code 會檢查是否需要清理舊嘅工具結果。三種機制並行工作:
時間衰減:如果距離上次對話已經超過60分鐘(啱啱好卡喺 Anthropic 服務端 prompt cache 嘅 TTL 上),清咗舊嘅工具結果。反正 cache 已經過期,prefix 要重寫,不如趁機將唔需要嘅嘢刪咗佢。
Cache-Editing API:呢個係最技術流嘅一招。唔修改本地消息(會破壞 cache),而係通過 API 嘅 cache_edits 機制,令服務端從緩存中刪除指定內容,但唔破壞 prefix。本地消息紋絲不動,服務端 cache 裏便啲佔空間嘅舊工具結果已經冇咗。
Context Management API:更新嘅方案,直接喺 API 參數裏便話俾服務端『幫我管理上下文』,客戶端連追蹤都唔使做。
三種機制嘅目標得一個:用最低嘅成本,推遲更貴嘅壓縮。
第3層:會話記憶(Session Memory)
呢一層開始有意思啦。
與其等到上下文滿咗再手忙腳亂咁總結,不如每輪對話持續維護筆記。咁樣真係到咗需要壓縮嘅時候,摘要已經準備好咗,唔使額外花 API 調用。
Claude Code 會 fork 一個子 agent,專門維護一個 markdown 檔案:
# Session Title
_A short and distinctive 5-10 word descriptive title_
# Current State
_What is actively being worked on right now?_
# Task specification
# Files and Functions
# Workflow
# Errors & Corrections
# Codebase and System Documentation
# Learnings
# Key results
# Worklog呢個檔案持續更新。當 autocompact 觸發時,系統先檢查會話記憶有冇內容,如果有,直接將會話記憶當壓縮摘要用。零 API 成本,因為摘要已經存在咗。
第4層:全量壓縮(Full Compaction)
當上下文真係頂唔順,前面幾層都擋唔住,就輪到全量壓縮。
系統會 fork 一個 summarizer agent,用兩階段輸出生成一個9段式摘要:先在 <analysis> 塊裏便組織思路,再喺 <summary> 塊裏便輸出正式摘要。<analysis> 塊喺進入上下文之前會被剝離,提升咗摘要質量,但唔會佔用壓縮後嘅 token。
壓縮完之後,Claude Code 會做一系列恢復操作:重新注入最近讀過嘅5個檔案(每個5K token,總共50K預算)、重新加載技能內容、重新執行 SessionStart hooks 恢復 CLAUDE.md……
仲有一個硬核嘅熔斷器:連續3次失敗之後,autocompact 喺呢個 session 裏便徹底停止。呢個係因為佢哋發現,有 1279 個 session 連續失敗咗50次以上(最誇張嘅一個失敗咗 3272 次),每日浪費約 25 萬次 API 調用。
第5層:自動記憶提取(Auto Memory Extraction)
會話記憶只管當前 session。但 Claude Code 仲有一套跨 session 嘅記憶系統。
每輪對話結束之後,一個後台 agent 會審查對話內容,提取值得長期保存嘅資訊。記憶被嚴格分類為四種類型:
• 用戶記憶:你嘅角色、專業背景、溝通偏好 • 反饋記憶:你俾過嘅修正、驗證過嘅方法、要求停止做嘅事 • 項目記憶:截止日期、架構決策、代碼庫本身無法推斷嘅上下文 • 引用記憶:bug 追蹤喺邊、應該睇邊個 Slack 頻道
代碼裏便明確寫着:如果資訊可以透過 grep 或 git 從代碼庫推斷出來,就不要唔好存做記憶。
第6層:夢境系統(Dreaming)
呢一層係最詩意嘅,亦都係最超前嘅。
Dreaming 係一個跨會話記憶整合嘅後台進程,類似生物學裏便嘅記憶鞏固:白天經歷嘅事,喺睡眠中被回顧、整理、整合入長期儲存。
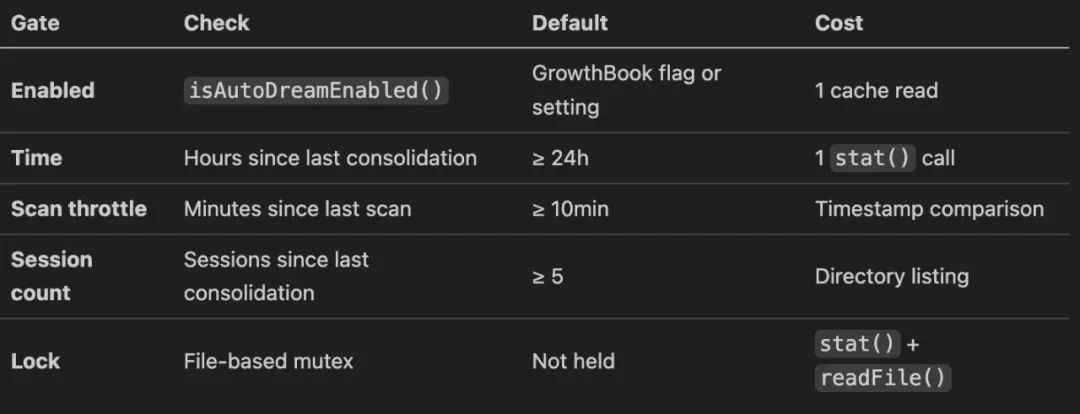
佢按四個階段工作:
1. Orient:瀏覽記憶目錄,讀 MEMORY.md 索引,瞭解當前記憶全貌 2. Gather:回顧最近嘅會話日誌,檢查有冇同代碼庫矛盾嘅記憶 3. Consolidate:合併新信號到現有記憶檔案中,刪除有矛盾嘅事實 4. Prune:更新索引,保持200行/25KB上限,清理過時條目
整個進程有 PID 鎖保護,60分鐘超時自動回收,crash 之後下個 session 可以接管。
第7層:跨 Agent 通信
最外層係 Agent 之間嘅協作基礎設施。Claude Code 裏便幾乎所有後台操作(session memory、auto memory、dreaming、compaction)都用 forked agent 模式。

子 agent 克隆父級嘅可變狀態(防止交叉污染),但共享 prompt cache 前綴(防止成本爆炸)。隔離太多浪費 cache,共享太多容易出 bug,兩邊都喺度行鋼線。
整個系統嘅設計哲學可以總結為一句話:用最平嘅層擋住問題,只有擋唔住時先觸發更貴嘅層。
Codex CLI:極簡 markdown 哲學
Codex CLI 嘅方案係一個精心整理嘅檔案櫃。
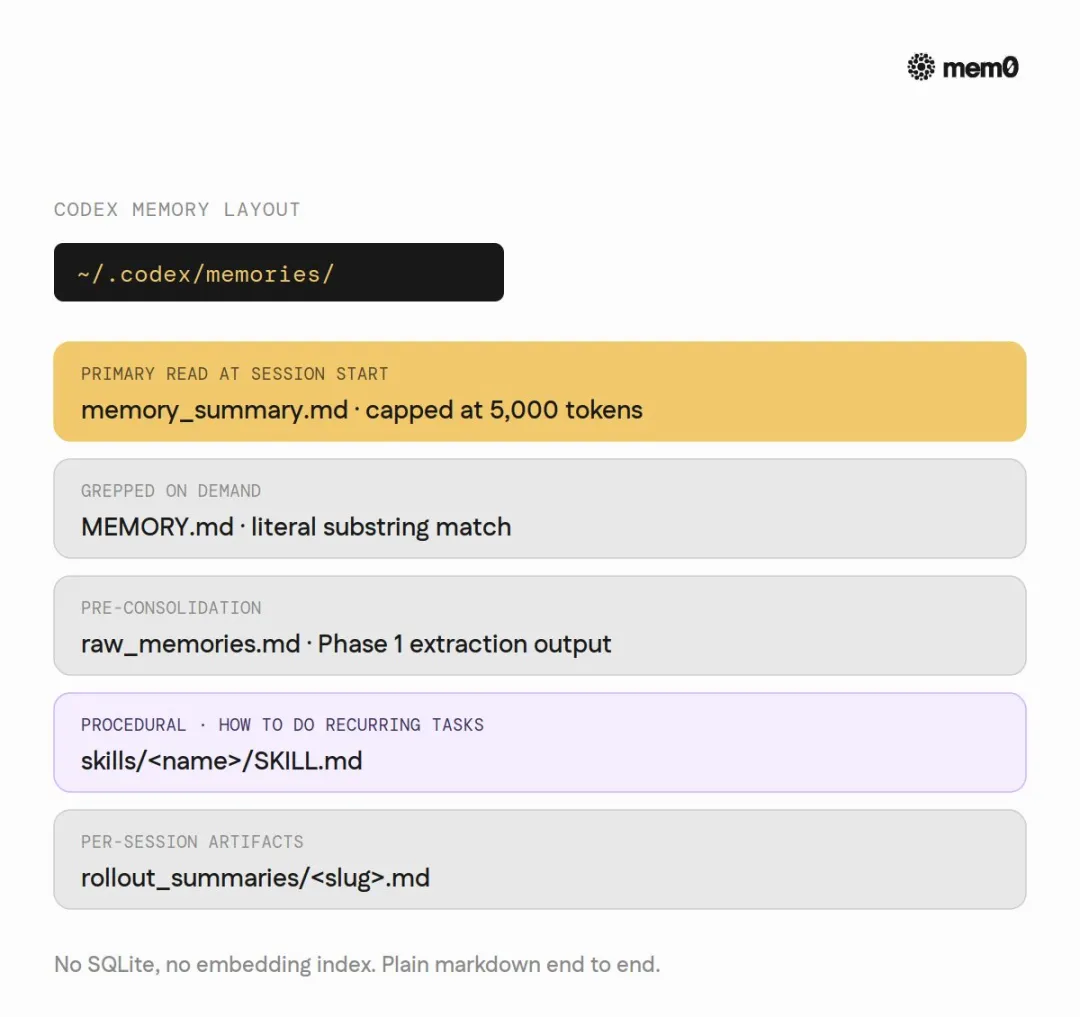
所有記憶住喺一個目錄裏便:~/.codex/memories/。冇 SQLite,冇 embedding 索引,冇唔透明嘅二進制 blob。就係 markdown 檔案。
核心檔案得幾個:memory_summary.md(合併視圖)、MEMORY.md(長表單記憶)、raw_memories.md(提取中間態)、rollout_summaries/(每 session 摘要)。
寫入:兩階段後台整合

Phase 1 係 per-session 嘅。當一個 session 空閒超過6小時(預設值),Codex 啟動一個提取任務,用嚴格嘅 schema prompt 審查對話內容,將輸出經過憑證脱敏之後存入本地狀態數據庫。此時記憶仲未到檔案目錄。
Phase 2 係全局嘅。佢先獲取全局鎖(防止兩個整合進程並行跑),加載最近嘅 Phase 1 輸出,同步到磁盤,檢查 workspace 有冇變化,然後 spawn 一個獨立嘅整合子 agent。子 agent 決定邊啲合併、邊啲修補、邊啲丟棄,將結果寫返 ~/.codex/memories/。
兩個階段都可以配置唔同嘅模型(extract_model 和 consolidation_model),整合 pass 作為獨立子 agent 運行,唔佔用用戶對話嘅資源。
讀取:5000 token 硬切
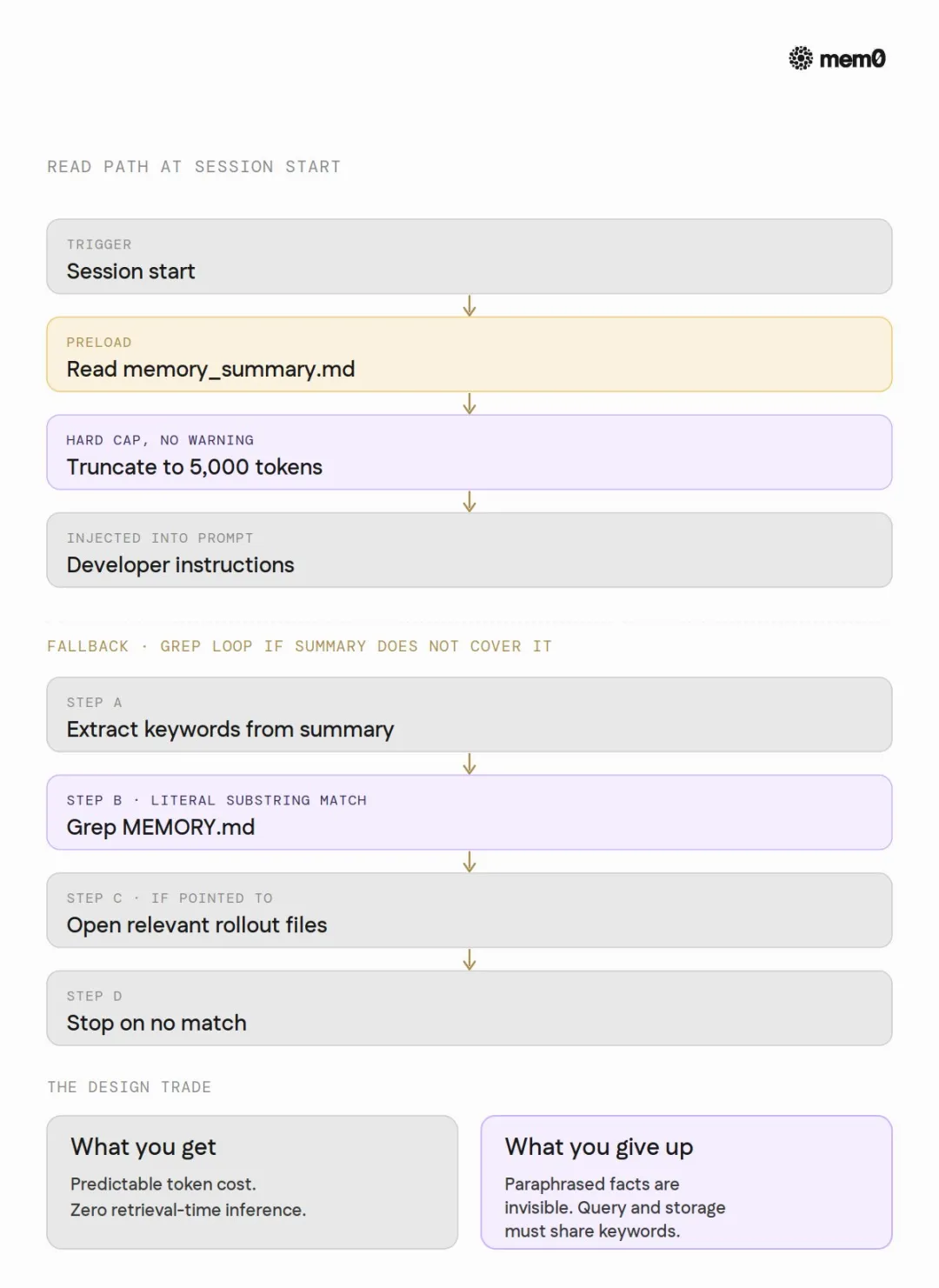
Session 啟動時,Codex 將 memory_summary.md 全量讀入,然後截斷到 5000 token。呢個係一個硬編碼嘅常量,寫喺讀取路徑嘅 Rust 源碼裏便,唔喺公開文檔中。
呢 5000 token 就係 agent 啟動時拎到嘅全部『記憶』。
如果答案唔喺 summary 裏便點算?Agent 被指示用 grep 搜 MEMORY.md。冇 embedding,冇向量檢索,冇 rerank。就係純文本子串匹配。
設計取捨好清晰:用可預測性同零檢索時間成本,換走咗語義召回能力。grep miss 嘅代價隨記憶檔案增長線性上升,但 Codex 認為呢個代價可接受。
嗰條睇唔見嘅線
兩個方案都有一道硬線,超過就冇咗。
Claude Code:200行懸崖
MEMORY.md 索引檔案有200行上限(另有25KB字節上限)。一旦超過,系統靜默截斷。

最老嘅記憶從索引底部跌出去。Claude 下次啟動時,系統提示裏便係一個乾淨嘅、被截斷過嘅索引。佢唔知道有任何嘢唔見咗。
仲有一個限制:每輪對話最多加載5個記憶檔案。靠一個 Sonnet 側調用來做『語義檢索』,但 Sonnet 睇到嘅只係檔案名同一行描述,唔係 embedding 向量。
Codex CLI:5000 token 硬切
memory_summary.md 喺每次 session 啟動時被截斷到 5000 token。超出部分靜默丟棄,冇警告。
而 grep 回退方案有一個隱性成本:MEMORY.md 係線性搜索嘅。對於一個用咗幾個月嘅開發者,記憶檔案會越來越長,每次 grep miss 嘅代價越來越大。
此外,Codex 嘅6小時空閒門控意味住:如果你係一個連續高強度寫程式嘅開發者,記憶提取可能永遠唔會觸發。空閒6小時對好多開發者嚟講係個奢望。
唔係儲存問題,係取捨問題
Claude Code 揀咗縱深防禦,7層架構,每層有唔同嘅成本同觸發條件,prompt cache 優化到變態嘅程度(fork 子 agent 嘅 API 請求前綴字節級一致,只係為咗慳嗰幾毫子 cache miss)。複雜、精密、工程量巨大。
Codex CLI 揀咗極簡哲學,純 markdown,grep 檢索,5000 token 預算。可預測、零黑盒、開源可審計。但天花板同樣真實。
共同點得一個:記憶有上限,超過上限嘅丟失係靜默嘅,AI 唔知自己唔知啲乜。 無論你用 Claude Code 寫咗三個月項目,定係用 Codex CLI 跑咗幾十個 session,嗰條睇唔見嘅線都喺嗰度。
Claude Code 嘅做法係起一座越來越高嘅城堡,7層唔夠就加第8層,加 circuit breaker 防止雪崩,加 feature flag 隨時可以回滾。Codex 嘅做法係接受上限嘅存在,將一切做到可預測、可審計、可控。
真正值得問嘅問題係喺有限嘅記憶預算裏便,乜嘢應該記住,乜嘢應該遺忘?
Claude Code 源碼洩漏之後,有人翻曬成個記憶系統,講咗一句:
"It's not hallucinating. It's not broken. It just forgot."
佢只係唔記得咗。而且佢唔知自己唔記得咗。
Macaron 🧁 | 記憶嘅上限,就係智能嘅上限
你用 Claude Code 寫了三個月的項目。它知道你偏好集成測試、知道那個接口不穩定、知道你們團隊 hotfix 跳過 PR 審核。
然後某一天,它開始重複問你之前已經回答過的問題。寫的測試撞上了那個不穩定接口。架構決策被推翻。
它不是在"幻覺"。它只是忘了。而且它完全不知道自己忘了。
這不是 bug,這是設計。
2026年3月底,Claude Code 的源碼被泄露到了網上,開發者們蜂擁進去翻找,有人看 prompt,有人看計費邏輯,有人直接衝向了記憶系統。他們發現了一個 Anthropic 從未公開文檔化的硬限制:你的記憶索引文件,最多200行。
超過第201行的那一刻,最老的記憶被靜默截斷。沒有警告,沒有報錯,沒有日誌。AI 看到一個乾乾淨淨的系統提示,它不知道有任何東西丟失過。
與此同時,OpenAI 的 Codex CLI 也開源了自己的記憶系統。方案完全不同,純 markdown 文件、grep 檢索、5000 token 硬切。簡單到近乎原始,但天花板同樣真實。
兩大 AI 編程助手,兩種截然相反的工程哲學,回答同一個問題:在一個上下文窗口有限的模型裏,怎麼讓 AI "記住"你?
LLM 有一個繞不過去的基本約束:上下文窗口是固定的。
Claude Code 默認 200K token,加了 [1m] 後綴可以擴展到 1M。Codex CLI 的情況類似,模型的上下文長度有物理上限。
聽起來很大。但一個編程session很容易就炸掉這個窗口:讀幾個文件、跑幾輪 grep、做幾輪編輯迭代,token 就滿了。
所以核心矛盾是:世界是無限的,上下文是有限的。
兩個團隊給出了完全不同的回答。
Claude Code:7層縱深防禦
Claude Code 的方案像是一座精心設計的城堡,7層防線,每一層都比上一層更貴,但設計目標是讓便宜的那層擋住問題,避免觸發昂貴的那層。
第1層:工具結果存儲
這是最輕的一層,成本幾乎為零,只有磁盤 I/O。
問題在於,一次 grep 掃全庫可能返回 100KB+ 的文本。一次 cat 大文件也有 50KB。這些結果塞進上下文後,幾輪對話就過時了。
Claude Code 的做法是:大結果寫磁盤,上下文裏只留 2KB 預覽。
每次工具結果都會經過一個預算系統。超過閾值的,完整結果存到 tool-results/<sessionId>/<toolUseId>.txt,上下文裏放一個 <persisted-output> 標籤包裹的預覽片段。模型需要看全文時,可以主動去讀。
這裏有一個精妙的細節:一旦某個工具結果被替換為預覽,這個決定就被凍結在 ContentReplacementState 裏。後續每次 API 調用,同一個結果拿到的是同一個預覽,保證 prompt 前綴字節級一致,不破壞服務端 prompt cache。
第2層:微壓縮(Microcompaction)
每輪對話開始前,Claude Code 會檢查是否需要清理舊的工具結果。三種機制並行工作:
時間衰減:如果距離上次對話已經超過60分鐘(正好卡在 Anthropic 服務端 prompt cache 的 TTL 上),清掉舊的工具結果。反正 cache 已經過期了,prefix 要重寫,不如趁機把不需要的東西刪掉。
Cache-Editing API:這是最技術流的一招。不修改本地消息(會破壞 cache),而是通過 API 的 cache_edits 機制,讓服務端從緩存中刪除指定內容,但不破壞 prefix。本地消息紋絲不動,服務端 cache 裏那些佔空間的舊工具結果已經沒了。
Context Management API:更新的方案,直接在 API 參數裏告訴服務端"幫我管理上下文",客戶端連追蹤都不用做。
三種機制的目標只有一個:用最低的成本,推遲更昂貴的壓縮。
第3層:會話記憶(Session Memory)
這一層開始有意思了。
與其等到上下文滿了再手忙腳亂地總結,不如每輪對話持續維護筆記。這樣真到了需要壓縮的時候,摘要已經準備好了,不用額外花 API 調用。
Claude Code 會 fork 一個子 agent,專門維護一個 markdown 文件:
# Session Title
_A short and distinctive 5-10 word descriptive title_
# Current State
_What is actively being worked on right now?_
# Task specification
# Files and Functions
# Workflow
# Errors & Corrections
# Codebase and System Documentation
# Learnings
# Key results
# Worklog這個文件持續更新。當 autocompact 觸發時,系統先檢查會話記憶有沒有內容,如果有,直接把會話記憶當壓縮摘要用。零 API 成本,因為摘要已經存在了。
第4層:全量壓縮(Full Compaction)
當上下文真的撐不住了,前面幾層都擋不住,就輪到全量壓縮。
系統會 fork 一個 summarizer agent,用兩階段輸出生成一個9段式摘要:先在 <analysis> 塊裏組織思路,再在 <summary> 塊裏輸出正式摘要。<analysis> 塊在進入上下文前會被剝離,提升了摘要質量,但不佔用壓縮後的 token。
壓縮完之後,Claude Code 會做一系列恢復操作:重新注入最近讀過的5個文件(每個5K token,總共50K預算)、重新加載技能內容、重新執行 SessionStart hooks 恢復 CLAUDE.md……
還有一個硬核的熔斷器:連續3次失敗後,autocompact 在這個 session 裏徹底停止。這是因為他們發現,有 1279 個 session 連續失敗了50次以上(最誇張的一個失敗了 3272 次),每天浪費約 25 萬次 API 調用。
第5層:自動記憶提取(Auto Memory Extraction)
會話記憶只管當前 session。但 Claude Code 還有一套跨 session 的記憶系統。
每輪對話結束後,一個後台 agent 會審查對話內容,提取值得長期保存的信息。記憶被嚴格分類為四種類型:
• 用戶記憶:你的角色、專業背景、溝通偏好 • 反饋記憶:你給過的修正、驗證過的方法、要求停止做的事 • 項目記憶:截止日期、架構決策、代碼庫本身無法推斷的上下文 • 引用記憶:bug 追蹤在哪、該看哪個 Slack 頻道
代碼裏明確寫着:如果信息可以通過 grep 或 git 從代碼庫推斷出來,就不要存為記憶。
第6層:夢境系統(Dreaming)
這一層是最詩意的,也是最超前的。
Dreaming 是一個跨會話記憶整合的後台進程,類比生物學裏的記憶鞏固:白天經歷的事情,在睡眠中被回顧、整理、整合進長期存儲。
它按四個階段工作:
1. Orient:瀏覽記憶目錄,讀 MEMORY.md 索引,瞭解當前記憶全貌 2. Gather:回顧最近的會話日誌,檢查有沒有與代碼庫矛盾的記憶 3. Consolidate:合併新信號到現有記憶文件中,刪除被矛盾的事實 4. Prune:更新索引,保持200行/25KB上限,清理過時條目
整個進程有 PID 鎖保護,60分鐘超時自動回收,crash 後下個 session 可以接管。
第7層:跨 Agent 通信
最外層是 Agent 之間的協作基礎設施。Claude Code 裏幾乎所有後台操作(session memory、auto memory、dreaming、compaction)都用 forked agent 模式。
子 agent 克隆父級的可變狀態(防止交叉污染),但共享 prompt cache 前綴(防止成本爆炸)。隔離太多浪費 cache,共享太多容易出 bug,兩邊都在走鋼絲。
整個系統的設計哲學可以總結為一句話:用最便宜的層擋住問題,只有擋不住時才觸發更貴的層。
Codex CLI:極簡 markdown 哲學
Codex CLI 的方案是一個精心整理的文件櫃。
所有記憶住在一個目錄裏:~/.codex/memories/。沒有 SQLite,沒有 embedding 索引,沒有不透明的二進制 blob。就是 markdown 文件。
核心文件只有幾個:memory_summary.md(合併視圖)、MEMORY.md(長表單記憶)、raw_memories.md(提取中間態)、rollout_summaries/(每 session 摘要)。
寫入:兩階段後台整合
Phase 1 是 per-session 的。當一個 session 空閒超過6小時(默認值),Codex 啓動一個提取任務,用嚴格的 schema prompt 審查對話內容,把輸出經過憑證脱敏後存入本地狀態數據庫。此時記憶還沒到文件目錄。
Phase 2 是全局的。它先獲取全局鎖(防止兩個整合進程並行跑),加載最近的 Phase 1 輸出,同步到磁盤,檢查 workspace 是否有變化,然後 spawn 一個獨立的整合子 agent。子 agent 決定哪些合併、哪些修補、哪些丟棄,把結果寫回 ~/.codex/memories/。
兩個階段都可以配置不同的模型(extract_model 和 consolidation_model),整合 pass 作為獨立子 agent 運行,不佔用用戶對話的資源。
讀取:5000 token 硬切
Session 啓動時,Codex 把 memory_summary.md 全量讀入,然後截斷到 5000 token。這是一個硬編碼的常量,寫在讀取路徑的 Rust 源碼裏,不在公開文檔中。
這 5000 token 就是 agent 啓動時拿到的全部"記憶"。
如果答案不在 summary 裏怎麼辦?Agent 被指示用 grep 搜 MEMORY.md。沒有 embedding,沒有向量檢索,沒有 rerank。就是純文本子串匹配。
設計取捨很清晰:用可預測性和零檢索時間成本,換掉了語義召回能力。grep miss 的代價隨記憶文件增長線性上升,但 Codex 認為這個代價可接受。
那條看不見的線
兩個方案都有一道硬線,超過就丟失。
Claude Code:200行懸崖
MEMORY.md 索引文件有200行上限(另有25KB字節上限)。一旦超過,系統靜默截斷。
最老的記憶從索引底部掉出去。Claude 下次啓動時,系統提示裏是一個乾淨的、被截斷過的索引。它不知道有任何東西丟失。
還有一個限制:每輪對話最多加載5個記憶文件。靠一個 Sonnet 側調用來做"語義檢索",但 Sonnet 看到的只是文件名和一行描述,不是 embedding 向量。
Codex CLI:5000 token 硬切
memory_summary.md 在每次 session 啓動時被截斷到 5000 token。超出部分靜默丟棄,沒有警告。
而 grep 回退方案有一個隱性成本:MEMORY.md 是線性搜索的。對於一個用了幾個月的開發者,記憶文件會越來越長,每次 grep miss 的代價越來越大。
此外,Codex 的6小時空閒門控意味着:如果你是一個連續高強度編碼的開發者,記憶提取可能永遠不會觸發。空閒6小時對很多開發者來說是個奢望。
不是存儲問題,是取捨問題
Claude Code 選了縱深防禦,7層架構,每層有不同的成本和觸發條件,prompt cache 優化到了變態的程度(fork 子 agent 的 API 請求前綴字節級一致,只為省那幾毛錢 cache miss)。複雜、精密、工程量巨大。
Codex CLI 選了極簡哲學,純 markdown,grep 檢索,5000 token 預算。可預測、零黑盒、開源可審計。但天花板同樣真實。
共同點只有一個:記憶有上限,超過上限的丟失是靜默的,AI 不知道自己不知道什麼。 無論你用 Claude Code 寫了三個月項目,還是用 Codex CLI 跑了幾十個 session,那條看不見的線都在那裏。
Claude Code 的做法是建一座越來越高的城堡,7層不夠就加第8層,加 circuit breaker 防止雪崩,加 feature flag 隨時可以回滾。Codex 的做法是接受上限的存在,把一切做到可預測、可審計、可控。
真正值得問的問題是在有限的記憶預算裏,什麼該記住,什麼該遺忘?
Claude Code 源碼泄露後,有人翻遍了整個記憶系統,說了一句:
"It's not hallucinating. It's not broken. It just forgot."
它只是忘了。而且它不知道自己忘了。
Macaron 🧁 | 記憶的上限,就是智能的上限