你裝了幾十個 Skill,Claude Code反而變笨了
整理版優先睇
裝太多 Skill 會令 Claude Code 變笨,關鍵在於按需安裝同定期精簡。
呢篇文章係關於Claude Code嘅Skill管理問題。作者觀察到社區好多人見一個Skill就裝一個,結果裝到幾十個之後,AI開始出現揀錯工具、漏執行步驟等現象。問題唔係出喺個別Skill,而係數量太多,令AI嘅判斷力下降。
作者解釋咗Skill嘅本質係一個叫SKILL.md嘅文件,入面係畀AI睇嘅指示。加載機制分三層,但無論點,每次對話都要掃描所有Skill嘅描述,呢個係「描述税」。加上模型注意力有限,同埋用過嘅Skill唔會自動退場,三者疊加令AI變笨。呢啲原因令到裝得越多,AI越唔穩定。
作者話三十個係個常見嘅關口,再上就開始出現誤觸發、步驟做一半、互搶等問題。佢提供咗三條原則:按實際工作裝、窄而專、定期清理。總結嚟講,真正幫到手嘅得幾個,與其囤積Skill,不如精簡,令AI更聽話。
- 裝太多 Skill 會引發「描述税」及注意力攤薄,導致 AI 揀錯工具或漏步驟,問題根源係數量,唔係個別 Skill。
- Skill 本質係提示詞文件(SKILL.md),唔係插件,每次對話都會消耗上下文判斷是否觸發。
- 三十個係常見臨界點,超過後問題按順序出現:誤觸發、步驟中斷、Skill 互搶、參考文檔不穩。
- 常見濫用包括:將固定規則做成 Skill、跟風囤積、描述寫得太長太含糊,佔用描述位。
- 解決方法:按實際工作裝、窄而專、定期清理,真正幫到手嘅得幾個,刪掉多餘 Skill 反而更聽話。
見一個裝一個,然後AI就亂了
好多人見到商店嘅Skill覺得有用就裝,裝到幾十個之後,AI開始出現嘅問題包括揀錯工具同漏執行步驟。
揀錯工具、漏執行步驟
Skill本質:唔係插件,係提示詞
好多人將Skill理解成插件,其實佢係一個叫SKILL.md嘅文件,入面係畀AI睇嘅指示,唔係代碼。
三層加載機制
- 1 第一層:名字加簡短描述(百幾字),永遠掛喺上下文,AI靠佢判斷用唔用。
- 2 第二層:正文,AI判斷要用先讀入。
- 3 第三層:附帶腳本同參考文檔,用到先加載。
裝住備用唔係免費
點解裝多咗會變笨:三層原因
三個機制疊加,令AI變笨。
- 1 第一,每發一條消息,所有描述都要重讀一遍,判斷邊個適用。裝20個要判斷20次,裝100個就100次。
- 2 第二,注意力被攤薄,描述越多,分到每一條嘅越少,容易睇漏關鍵。
- 3 第三,用過嘅Skill唔會自動退場,內容留喺上下文繼續佔位,影響後續判斷。
有研究記錄嘅注意力攤薄
用過嘅Skill唔會自動退場
幾多先算多?三十個係個提醒
三十個係社區經驗嘅關口,唔係官方數字,但提醒你質量會慢慢下滑。
- 偶爾誤觸發:十幾個穩定觸發,到三四十個開始抽風。
- 步驟只做一半:八步流程只穩定執行前五步,後面被擠掉。
- 相近Skill互搶:兩個管類似範疇嘅Skill,AI揀錯。
- 參考文檔唔穩定:連帶附帶文檔都開始唔可靠。
三十個係個關口
漸進式加載救唔到裝太多
點樣裝先啱:三條原則
- 1 按你實際做嘅嘢裝,唔按「睇落有用」裝。一週八成正職寫前端,就裝前端相關,唔好放一堆部署、運維Skill陪開場。
- 2 窄而專勝過大而全。一個觸發條件清楚嘅Skill,好過五個含糊其辭嘅。
- 3 定期清比謹慎裝更重要。一個月冇用過就刪,裝咗唔用係交緊描述税。
按實際工作裝
窄而專勝過大而全
一個月冇用過就刪
全網嘅 Skill 加埋幾萬個,好多人見一個裝一個。但係裝到三十個左右,AI 就開始揀錯工具、漏咗執行步驟——唔係 Skill 唔好,係裝得多咗。
先講個常見嘅場景
Skill 呢樣嘢,第一次用就會上癮。
寫代碼自動審查、提交自動生成 commit、文檔一鍵生成、PDF 解析、前端規範、測試補全……商店裏一排排掛住,每個望落都有用。於是見一個裝一個,清單越拉越長,裝到幾十個,心入面仲幾踏實:工具齊全,準備充分。
然後 AI 開始唔對路。
叫佢審查啱啱寫嘅代碼,佢走去改文檔。一個本來應該行七步嘅流程,佢做到第四步就話「完成」。同樣一句話,今日觸發咗啱嘅 Skill,聽日換咗個唔關事嘅。你第一反應就係「呢個 Skill 唔掂,換一個」,再裝一個新嘅入去——結果仲亂。
問題唔係喺某一個 Skill 身上,係喺數量。裝到一定程度,Skill 唔再係幫手,而係負擔。呢篇就講清楚:點解會咁,幾多算多,同埋應該點樣裝。
Skill 到底係咩,先糾正一個誤解
好多人將 Skill 理解成插件——裝到工具欄入面,需要嗰陣㩒一下就用。呢個理解係錯嘅,亦都係後面所有麻煩嘅根源。
Skill 嘅本質,係一個叫 SKILL.md 嘅文件,入面寫住一段畀 AI 睇嘅說明:幾時應該做呢件事、具體點樣做。Anthropic 喺 2025 年 10 月推出 Agent Skills 嘅時候,定嘅就係呢套機制。佢唔係代碼,係提示詞。
佢點樣入到 AI 個腦入面,分三層(官方叫漸進式加載):
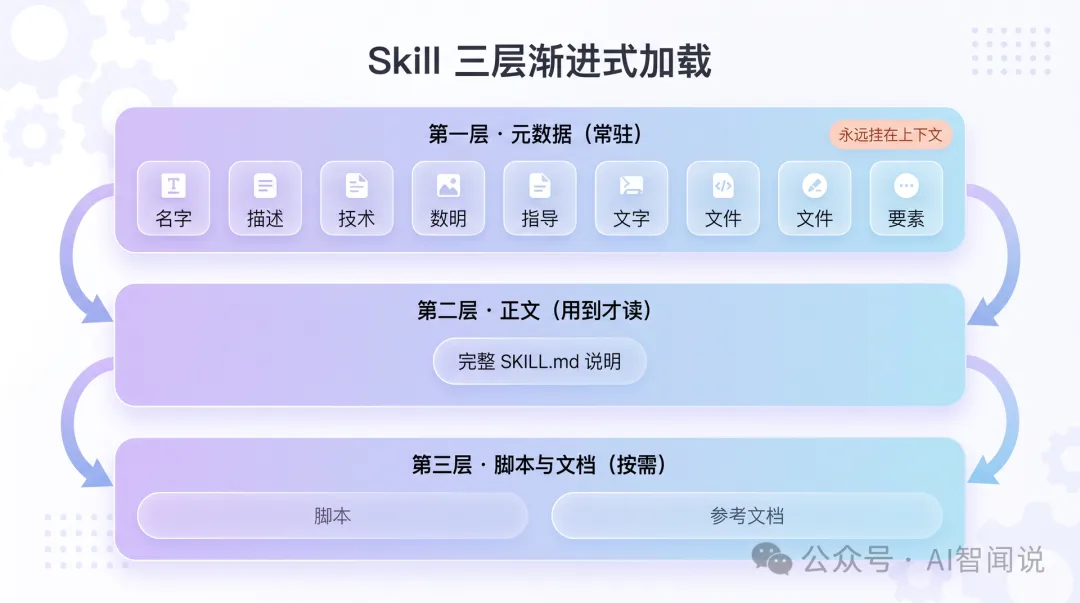
第一層,名加一段簡短描述(官方建議百幾字)。呢部分永遠掛喺上下文入面。AI 靠佢判斷:「今次嘅任務,用唔用得著呢個 Skill?」
第二層,正文。AI 判斷今次要用了,先至將成篇說明讀入嚟。
第三層,附帶嘅腳本同參考文檔。真係做到嗰一步、需要查嘞,先至加載。
重點係第一層嗰個「永遠」。你裝一個 Skill,就算佢成個禮拜一次都冇被用過,嗰句描述都日日霸住個位,每次對話都要被 AI 掃一次。裝得越多,開場要先讀嘅描述就越長。呢個就係點解「裝住備用」唔係免費嘅。
點解裝多咗,AI 反而變蠢
呢一段最關鍵,後面所有毛病都可以追溯返呢三件事:
第一,每次發一條消息,所有描述都要重新讀一次。
你每講一句話,AI 都要將已裝嘅所有 Skill 描述掃一次,決定今次用邊個。裝咗 20 個,就係 20 次判斷;裝咗 100 個,就係 100 次。而且唔係睇一眼,係逐條逐條諗「呢條同眼前嘅工作有冇關聯」。Skill 越多,呢筆開銷越大——多佔注意力、答得更慢,仲更容易揀錯。有人叫佢做「描述税」,裝住唔用都要照樣交。
第二,注意力被攤薄咗。
AI 嘅注意力係有限嘅,描述越多,分到每一條上面嘅就越少。模型喺長內容入面「顧此失彼」係有研究記錄嘅現象——關鍵信息從兩頭移到中間,模型跟甩嘅概率明顯上升。嗰個研究講嘅係長文檔檢索,但同一類位置效應,好大機會都落喺夾喺中間嗰幾條 Skill 描述上面:明明應該觸發,AI 卻睇漏咗。
第三,用過嘅 Skill 唔會自動退場。
一個 Skill 被調起身用過之後,佢嘅內容會留喺上下文入面跨好幾輪對話,唔會因為話題變咗就自己退出。你三句說話之前叫佢處理圖片,而家已經喺講第二啲嘢,嗰段圖片處理嘅說明仲賴喺上下文入面,繼續霸位、繼續搞亂佢對當前問題嘅判斷,將回答帶咗去錯嘅方向。
三件事疊埋就係一個結論:Skill 越多越強係錯覺。每多裝一個,AI 就要喺更多互相打架嘅描述入面揀一個,揀錯、睇漏、走偏嘅概率都在升。
咁到底幾多算多
先講清楚,呢個唔係一道硬牆——Claude 唔會裝到第 31 個就罷工。佢係質量慢慢下滑,好似天慢慢變陰,唔係啪一聲斷電。
有社區將大量用戶嘅反饋梳理咗一次,發現三十個左右係一個坎:再加落去,問題開始走出來。(呢個係社區經驗,唔係 Anthropic 畀嘅官方數字,唔好當成精確指標,當成一個提醒就得。)
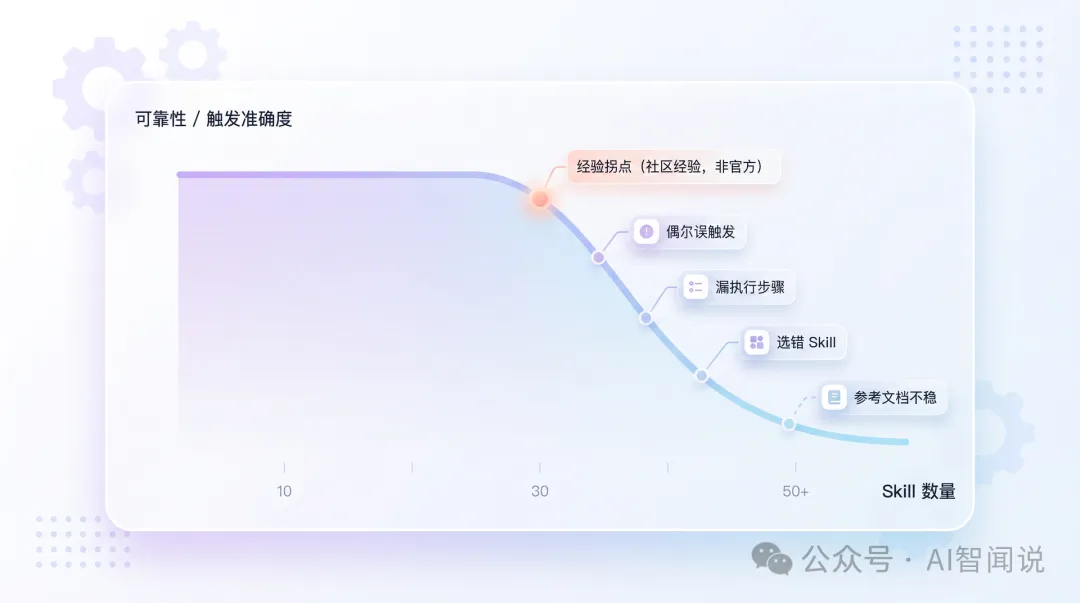
開頭嗰啲問題,其實係有出場順序嘅——裝得越多,越後期嘅越容易出現:
最先係偶爾誤觸發——十幾個嗰陣穩定觸發嘅 Skill,到三四十個開始失常。
接住係步驟只做一半——一個八步嘅流程,穩定執行嘅得頭五步,後面被擠走咗。
再後啲係相近嘅 Skill 互相搶——一個管代碼審查、一個管文檔,你話「幫我睇下呢個」,AI 喺兩個入面犯迷糊,揀錯嘅次數變多。
最後連帶附帶嘅參考文檔都開始唔穩定。
仲有一個反直覺嘅點值得講:漸進式加載成日俾人當成「裝幾多都冇事」嘅擋箭牌——反正正文用到先加載。但佢只係將成本向後移,冇消滅到。裝 50 個,每次開場仲要將 50 句描述全部讀入嚟,呢筆開銷走唔甩。佢令每個 Skill 更慳,但救唔到「裝太多」。
「濫用」係點樣,對住自查
將最常見嘅幾種擺出嚟,你對住睇下自己中咗幾個。呢度淨係講點樣,點解唔好前面嗰章已經講透咗。
一、將一句話嘅「事實」硬做成 Skill。 例如「本項目接口統一返回呢種錯誤格式」——呢個係一條固定規矩,寫入 CLAUDE.md(項目根目錄嗰個畀 AI 睇嘅說明文件)就夠。官方講得好直白:反覆要做嘅流程,先值得做成 Skill;只係一條死規矩,寫入 CLAUDE.md 就得。做反咗,等於用日日霸位嘅成本,去裝一句話。
二、跟風囤積。 見到清單推薦就裝,裝完一次冇真正用過,但佢日日霸住描述位,每輪開場都要被 AI 掃一次。
三、一個 Skill 乜都想管。 觸發條件糊成一團,AI 根本判斷唔出幾時應該用佢,結果一係亂觸發,一係應該用嗰陣唔用。
四、描述寫成產品文檔。 又長又空,仲同其他 Skill 撞車。AI 冇辦法靠佢準確判斷,只能估。
一句說話自查:打開 /skills 將裝嘅全部列曬出嚟,逐個問自己「上個月真係用過嗎」。答唔出嗰啲,留喺度就係喺度拖後腿。
應該點樣裝:三條原則
唔展開成一長串待辦,就三條,記住呢三條比記十條有用。
按你實際做嘅嘢裝,唔按「望落有用」裝。 一星期八成時間喺寫前端,咁就裝前端相關嘅,唔好俾一堆部署、運維、數據分析嘅 Skill 日日陪住你開場。你嘅 agent 應該服務你嘅工作,唔係服務成個商店。
窄而專,好過大而全。 一個觸發條件清清楚楚嘅 Skill,比五個含糊其辭嘅強得多。可以寫入 CLAUDE.md 嘅,就唔好做成 Skill。
定期清理,比謹慎裝更重要。 與其糾結「呢個應唔應該裝」,不如定期回頭清理:一個月冇用過嘅,刪咗或者歸檔。裝住唔用,佢唔會閒住,每一輪都喺靜靜雞收你税。
講到底,全網幾萬個 Skill,單個商店都掛住幾千個,但真正幫到你嘅就得咁幾個。官方嗰幾個、頭部嗰幾個確係好用——問題從來唔喺 Skill 本身,係喺「見一個裝一個」嘅囤積心態。
寫喺最後
將 Skill 當裝備囤積嘅人,囤嘅唔係能力,係一種「我準備充分」嘅錯覺,代價係日日被佔用嘅上下文同注意力。
agent 強唔強,從來唔係睇佢裝咗幾多個 Skill,係睇應該用嗰一個可唔可以每次都準確觸發、完整執行。清單再長,真正做嘢嘅就得嗰幾個。剩下嘅刪走,佢反而更聽話。
全網的 Skill 加起來幾萬個,很多人見一個裝一個。可裝到三十個上下,AI 就開始挑錯工具、漏執行步驟——不是 Skill 不好,是裝多了。
先說個常見的場景
Skill 這東西,第一次用上癮。
寫代碼自動審查、提交自動生成 commit、文檔一鍵生成、PDF 解析、前端規範、測試補全……商店裏一排排掛着,每個看着都有用。於是見一個裝一個,清單越拉越長,裝到幾十個,心裏還挺踏實:工具齊全,準備充分。
然後 AI 開始不對勁。
讓它審查剛寫的代碼,它跑去改文檔了。一個本該走七步的流程,它做到第四步就說"完成"。同樣一句話,今天觸發了對的 Skill,明天換了個不相干的。你第一反應是"這個 Skill 不行,換一個",再裝一個新的進去——結果更亂。
問題不在某一個 Skill 身上,在數量。裝到一定程度,Skill 不再是幫手,而是負擔。這篇就講清楚:為什麼會這樣,多少算多,以及該怎麼裝。
Skill 到底是什麼,先糾正一個誤解
很多人把 Skill 理解成插件——裝到工具欄裏,需要時點一下就用。這個理解是錯的,也是後面所有麻煩的根源。
Skill 的本質,是一個叫 SKILL.md 的文件,裏面寫着一段給 AI 看的說明:什麼時候該做這件事、具體怎麼做。Anthropic 在 2025 年 10 月推出 Agent Skills 的時候,定的就是這套機制。它不是代碼,是提示詞。
它怎麼進到 AI 腦子裏,分三層(官方叫漸進式加載):
第一層,名字加一段簡短描述(官方建議百來字)。這部分永遠掛在上下文裏。AI 靠它判斷:"這次的任務,用不用得上這個 Skill?"
第二層,正文。AI 判斷這次要用了,才把整篇說明讀進來。
第三層,附帶的腳本和參考文檔。真做到那一步、需要查了,才加載。
重點在第一層那個"永遠"。你裝一個 Skill,哪怕它一整週一次沒被用上,那句描述也天天佔着位置,每次對話都要被 AI 掃一遍。裝得越多,開場要先讀的描述就越長。這就是為什麼"裝着備用"不是免費的。
為什麼裝多了,AI 反而變笨
這一段最關鍵,後面所有毛病都能往回追到這三件事:
第一,每發一條消息,所有描述都要重讀一遍。
你每說一句話,AI 都要把已裝的所有 Skill 描述掃一遍,決定這次用哪個。裝了 20 個,就是 20 次判斷;裝了 100 個,就是 100 次。而且不是掃一眼,是一條條琢磨"這條跟眼下的活兒沾不沾邊"。Skill 越多,這筆開銷越大——多佔注意力、回得更慢,還更容易挑錯。有人把它叫"描述税",裝着不用也照樣交。
第二,注意力被攤薄了。
AI 的注意力是有限的,描述越多,分到每一條上的就越少。模型在長內容裏"顧此失彼"是有研究記錄的現象——關鍵信息從兩頭挪到中間,模型跟丟的概率明顯上升。那個研究講的是長文檔檢索,但同一類位置效應,大概率也落在夾在中間的那幾條 Skill 描述上:明明該觸發,AI 卻看漏了。
第三,用過的 Skill 不會自動退場。
一個 Skill 被調起來用過之後,它的內容會留在上下文裏跨好幾輪對話,不會因為話題變了就自己退出去。你三句話前讓它處理圖片,現在已經在聊別的了,那段圖片處理的說明還賴在上下文裏,繼續佔地方、繼續攪它對當前問題的判斷,把回答往溝裏帶。
三件事疊起來就是一個結論:Skill 越多越強是錯覺。每多裝一個,AI 就得在更多互相打架的描述裏挑一個,挑錯、漏看、跑偏的概率都在漲。
那到底多少算多
先說清楚,這不是一道硬牆——Claude 不會裝到第 31 個就罷工。它是質量慢慢往下滑,像天慢慢變陰,不是啪一下斷電。
有社區把大量用戶的反饋梳理了一遍,發現三十個上下是個坎:再往上加,毛病開始冒出來。(這是社區經驗,不是 Anthropic 給的官方數字,別當成精確指標,當成一個提醒就行。)
開頭那些毛病,其實是有出場順序的——裝得越多,越靠後的越容易冒出來:
最先是偶爾誤觸發——十幾個的時候穩定觸發的 Skill,到三四十個開始抽風。
接着是步驟只做一半——一個八步的流程,穩定執行的只有前五步,後面被擠掉了。
再往後是相近的 Skill 互相搶——一個管代碼審查、一個管文檔,你說"幫我看看這個",AI 在兩個裏面犯迷糊,選錯的次數變多。
最後連帶附帶的參考文檔也開始不穩。
還有一個反直覺的點值得說:漸進式加載經常被當成"裝多少都沒事"的擋箭牌——反正正文用到才加載。但它只是把成本往後挪,沒消掉。裝 50 個,每次開場還是要把 50 句描述全讀進來,這筆開銷跑不掉。它讓每個 Skill 更省,但救不了"裝太多"。
"濫用"長什麼樣,對着自查
把最常見的幾種擺出來,你對着看看自己中了幾個。這裏只說長什麼樣,為什麼不好前面那章已經講透了。
一、把一句話的"事實"硬做成 Skill。 比如"本項目接口統一返回這種錯誤格式"——這是一條固定規矩,寫進 CLAUDE.md(項目根目錄那個給 AI 看的說明文件)就夠了。官方說得很直白:反覆要走的流程,才值得做成 Skill;只是一條死規矩,寫進 CLAUDE.md 就行。做反了,等於拿天天佔地方的成本,去裝一句話。
二、跟風囤。 看到清單推薦就裝,裝完一次沒真用過,但它天天佔着描述位,每輪開場都得被 AI 掃一遍。
三、一個 Skill 什麼都想管。 觸發條件糊成一團,AI 根本判斷不出來啥時候該用它,結果要麼亂觸發,要麼該用時不用。
四、描述寫成產品文檔。 又長又虛,還和別的 Skill 撞車。AI 沒法靠它準確判斷,只能猜。
一句話自查:打開 /skills 把裝的全列出來,挨個問自己"上個月真用過嗎"。答不上來的那些,留着就是在拖後腿。
該怎麼裝:三條原則
不展開成一長串待辦,就三條,記住這三條比記十條管用。
按你實際乾的活裝,不按"看着有用"裝。 一週八成時間在寫前端,那就裝前端相關的,別讓一堆部署、運維、數據分析的 Skill 天天陪着你開場。你的 agent 該服務你的活,不是服務整個商店。
窄而專,勝過大而全。 一個觸發條件清清楚楚的 Skill,比五個含糊其辭的強得多。能寫進 CLAUDE.md 的,就別做成 Skill。
定期清,比謹慎裝更重要。 與其糾結"這個該不該裝",不如定期回頭清:一個月沒用過的,刪掉或歸檔。裝着不用,它不會閒着,每一輪都在悄悄收你的税。
說到底,全網幾萬個 Skill,單個商店也掛着幾千個,但真正幫到你的就那麼幾個。官方那幾個、頭部那幾個確實好用——問題從來不在 Skill 本身,在"見一個裝一個"的囤積心態。
寫在最後
把 Skill 當裝備囤的人,囤的不是能力,是一種"我準備充分"的錯覺,代價是天天被佔用的上下文和注意力。
agent 強不強,從來不看它裝了多少 Skill,看的是該用的那一個能不能每次都準確觸發、完整執行。清單再長,真正幹活的就那幾個。剩下的刪掉,它反而更聽話。