使用 Claude Code:會話管理與 100 萬 上下文
整理版優先睇
掌握 Claude Code 嘅會話管理技巧,先至發揮到 100 萬上下文嘅威力
呢篇文章係由 Anthropic 員工 Thariq 寫嘅,佢係 Claude Code 嘅核心對外佈道者。原文係講 Claude Code 最近推出嘅 /usage 更新,同埋點樣管理超長上下文窗口(而家最多 100 萬 Token)。作者發現好多人唔識得點樣有效管理會話,成日浪費上下文空間或者搞到模型表現變差。
成篇文章嘅核心結論係:喺 Claude Code 入面,每一次 AI 回覆完之後,你都係一個決策路口——你可以選擇繼續、回溯、清空、壓縮或者用子智能體。識得喺啱嘅時候用啱嘅方法,先至可以引導 Claude 產出高質素結果。作者特別強調,回溯(Rewind)係一個好高質素嘅習慣,比直接糾正錯誤更有效。另外,壓縮(Compact)係「有損」嘅,要主動控制先唔會翻車;而子智能體就可以幫你隔離大量中間結果。
- 上下文管理係 Claude Code 體驗嘅核心,直接影響模型表現同成本。
- 五種選擇(繼續、回溯、清空、壓縮、子智能體)各有適用場景,新任務應該開新會話。
- 回溯(Rewind)比直接糾正更高明,可以跳返之前嘅節點再落指令,避免累積錯誤。
- 壓縮(Compact)係有損總結,最好主動帶住「下一步想做乜」去執行,否則可能丟失重要資訊。
- 子智能體適合處理大量「閲後即焚」嘅中間結果,畀佢獨立工作,最後只拎結論返嚟。
上下文窗口、衰減同壓縮係乜嘢?
所謂 上下文窗口(Context Window),就係模型每次生成回答時可以睇到嘅全部資訊,包括系統提示詞、對話歷史、工具調用同輸出,仲有讀過嘅文件。而家 Claude Code 有 100 萬個 Token 嘅超大容量,但可惜係用得多就會出現 上下文衰減(Context Rot)——模型注意力被太多 Token 分散,早期無關內容會干擾當前任務。
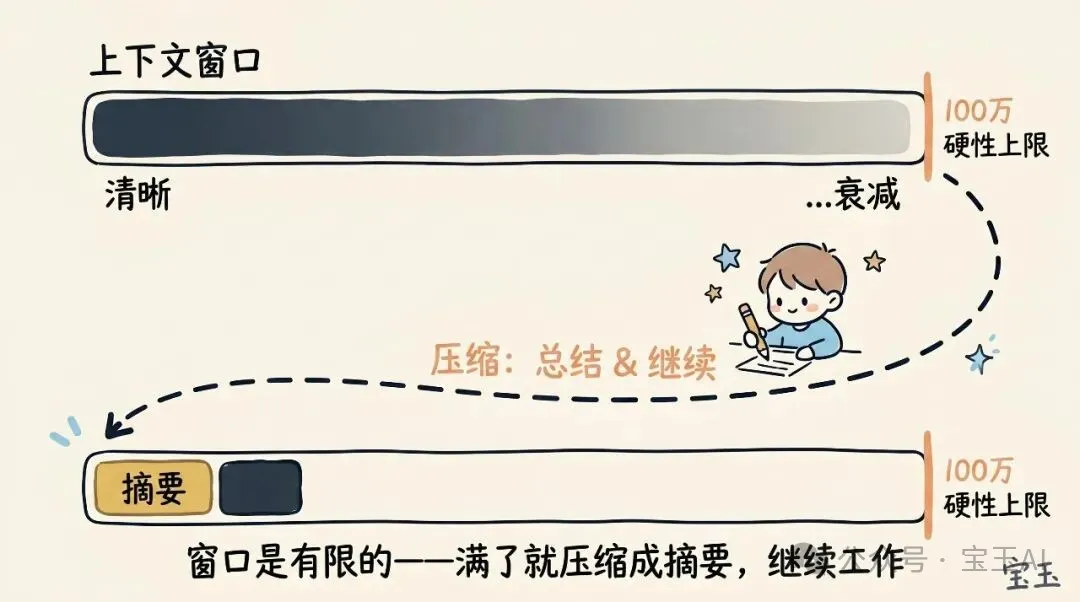
當上下文窗口就快爆嘅時候,你需要做 上下文壓縮(Compaction):將成個任務總結成一段簡短描述,然後帶住呢段描述喺新窗口繼續。呢個過程可以手動觸發,亦可以自動做。
每一次回覆之後,你都有五個選擇
當 Claude 完成咗一個任務,你唔係得「繼續」一個選項。以下係你可以做嘅嘢:
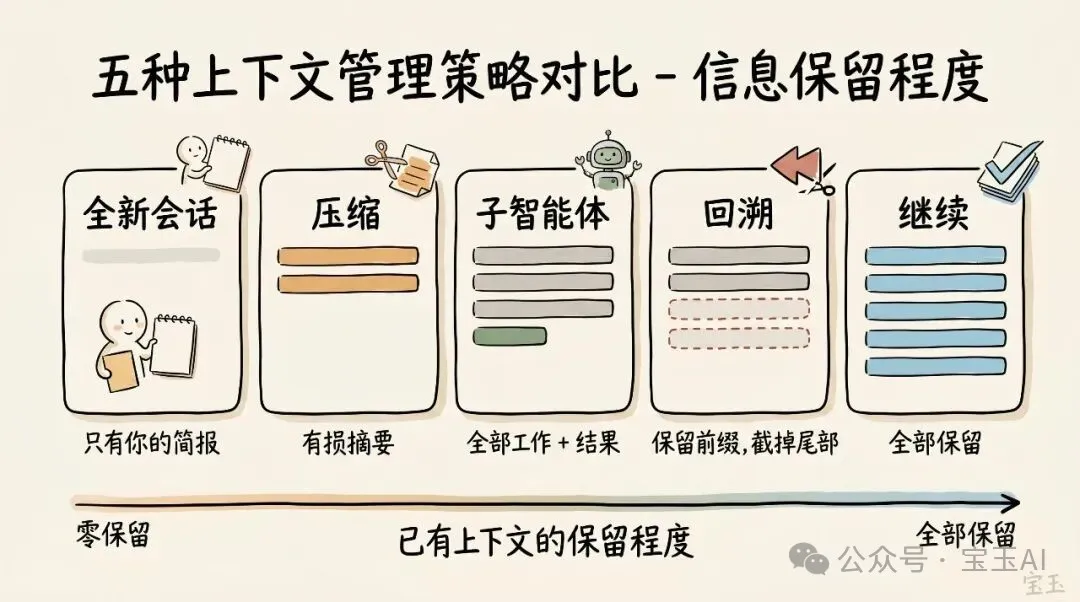
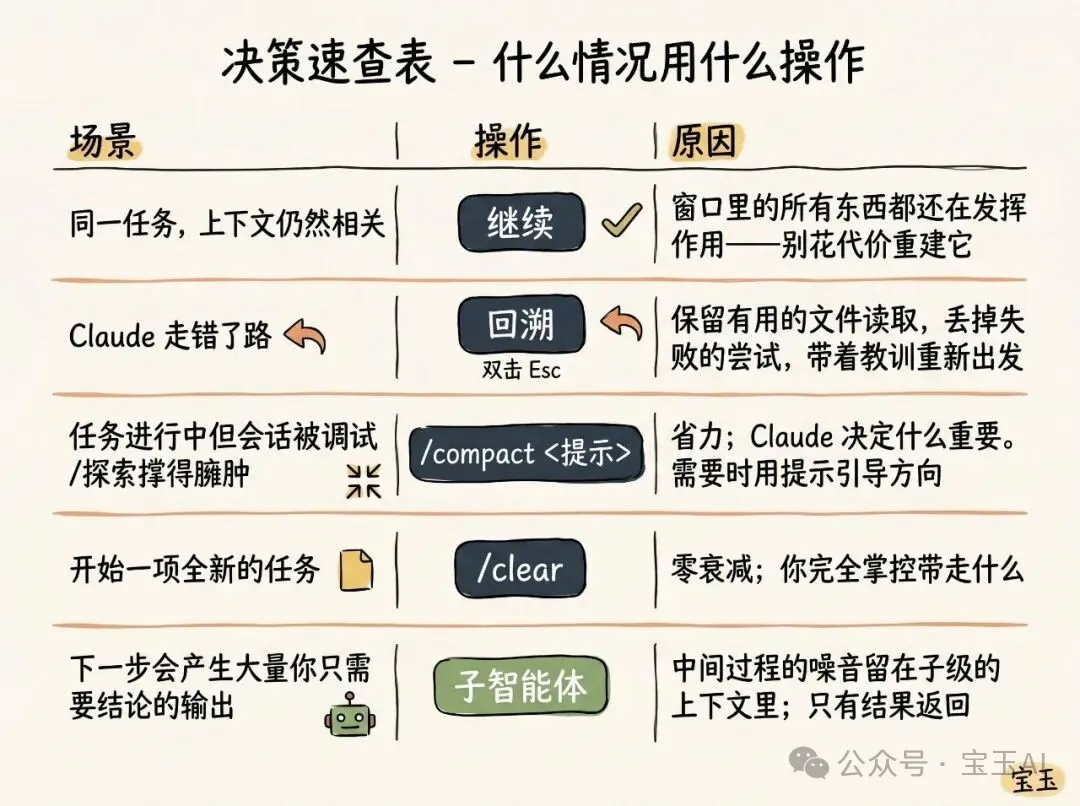
- 1 繼續(Continue):同一個會話直接發下一條訊息,最自然但最易令上下文失控。
- 2 回溯(Rewind / 雙擊 Esc):返到之前某個節點,由嗰度重新落指令,之後嘅對話全部丟棄。係糾正錯誤嘅最佳方法。
- 3 清空(/clear):開全新會話,但要自己寫低核心要點,例如做緊乜任務、限制條件係乜、相關文件係邊啲。
- 4 壓縮(/compact):叫模型總結當前對話,用摘要替換冗長歷史。你可以畀指令指定重點,例如「專注喺身份驗證模塊重構,唔使理測試除錯」。
- 5 子智能體(Subagents):委派下一階段工作畀一個有全新獨立上下文嘅 AI Agent,最後只攞佢嘅最終報告返嚟。
雖然直接「繼續」好順手,但其他四個選項係設計嚟幫你管理上下文嘅。熟練運用呢啲決策,就係高效使用 Claude Code 嘅關鍵。
幾時應該開新會話?幾時應該繼續?
作者嘅經驗法則係:當你開始一項新任務,就應該開一個新會話。100 萬上下文夠你完成好長嘅任務,例如由零搭建全棧應用。但係如果前後關聯嘅任務,例如寫完功能後要寫文檔,你未必想完全由頭開始——因為 Claude 要重新讀曬啲檔案,又慢又貴。
呢個時候可以考慮繼續舊會話,或者用回溯跳返之前嘅節點,而唔係硬食成個歷史。另外,如果你預測到下一步會產生大量中間結果,就應該用子智能體隔離佢哋。
回溯:高手必備嘅習慣
作者認為,回溯(Rewind)係最能代表「優秀上下文管理能力」嘅好習慣。喺 Claude Code 入面,雙擊 Esc 或者用 /rewind 命令可以返到之前任何一條訊息,由嗰度重新落提示詞,之後嘅對話全部消失。
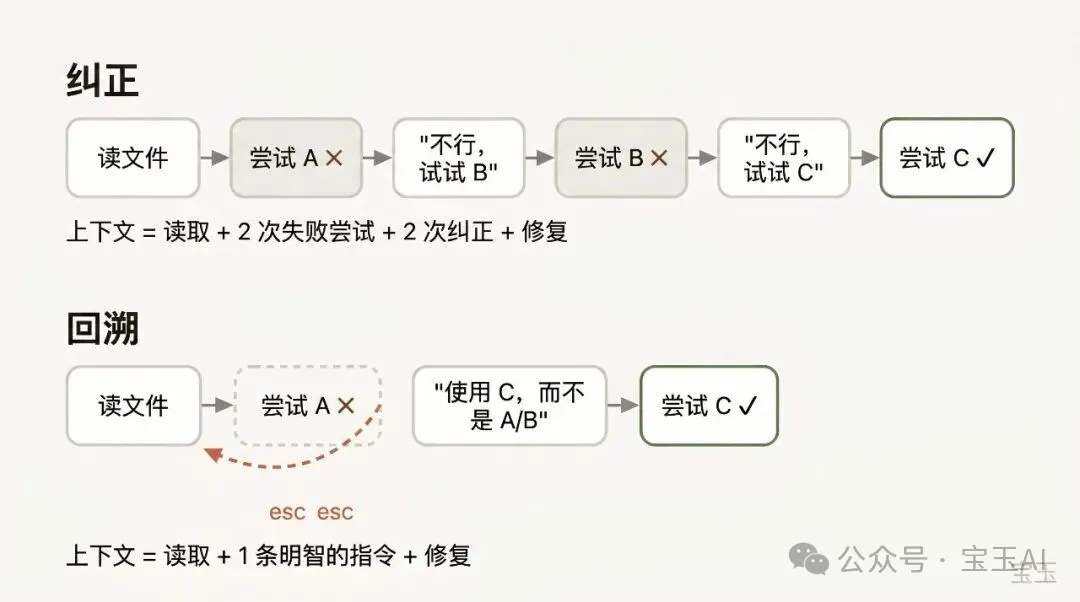
舉個例:Claude 讀咗五個文件,試咗 A 方法失敗咗。你唔應該直接打「呢招唔掂,試 X 方法」,而係回溯到佢啱啱讀完文件嗰刻,然後話:「唔好用 A 方法,foo 模塊唔支援嗰個——直接試 B 方法。」你仲可以用 summarize from here 功能,叫 Claude 自動總結教訓,好似未來版 Claude 留低張字條俾過去版本。
壓縮同子智能體:進階上下文管理
壓縮(/compact)同清空(/clear)都係減輕上下文負擔,但效果唔同。壓縮係有損,Claude 會自己揀重點,好處係你唔使寫太多嘢;清空就要你自己寫核心要點,但換嚟一個完全乾淨嘅上下文。翻車通常發生喺 LLM 估唔到你下一步想做乜嗰陣——例如除錯完之後自動壓縮,你之後想修另一個警告,但嗰個警告已經被當成無關資訊丟咗。
好在而家有 100 萬容量,你可以主動帶住「我接下來想做乜」嘅描述去執行 /compact。至於子智能體,佢哋嘅精髓係「以後仲需唔需要睇啲中間結果?」如果答案係唔需要,就應該用子智能體。你可以好明確咁指揮,例如:「派個子智能體去根據規範文件驗證我哋嘅工作」或者「派個子智能體去讀另一個 codebase,總結佢點樣做身份驗證」。
- 壓縮時畀明確指示:/compact 將重點放喺 XX 模塊,丟掉測試除錯內容。
- 子智能體適合:大量中間結果唔需要保留,只要最終結論。
- 例子:「派個子智能體去根據 Git 修改記錄寫說明文檔」
作者:Thariq
原文:Using Claude Code: Session Management & 1M Context[1]
【注:Thariq 係 Anthropic 員工,Claude Code 嘅核心對外佈道者。呢篇本質上係產品使用指南,有官方推廣成分,但操作建議的確實用。】
今日,我哋為 /usage 命令推出咗一個全新更新,想幫你更加清楚噉瞭解自己喺 Claude Code 裏面嘅使用情況。呢個決定嘅背後,係我哋近期同用戶進行嘅多次深入交流。
喺呢啲交流入面,我哋不斷聽到一個現象:大家管理會話嘅習慣可謂係五花八門。尤其係最近 Claude Code 將上下文窗口(Context Window)升級到 100 萬大關,呢種差異就更加明顯。
你係習慣喺終端機裏面只保持一兩個開緊嘅會話?定係每次輸入提示詞都重新開個新會話?你通常喺咩時候會用到壓縮(Compact)、回溯(Rewind)或者子智能體(Subagents)?又係咩原因導致咗一次糟糕嘅壓縮呢?
呢度其實大有學問。呢啲睇落唔起眼嘅細節,極大咁影響住你使用 Claude Code 嘅體驗。而呢一切嘅核心,都歸結到一件事:點樣管理你嘅上下文窗口。
快速科普:上下文、上下文壓縮與上下文衰減
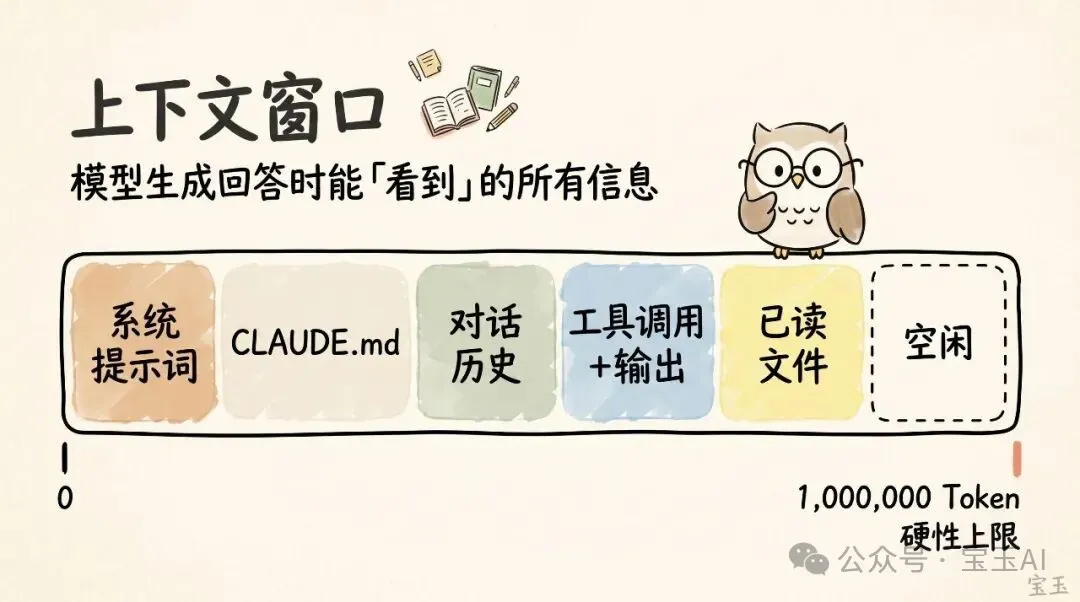
所謂「上下文窗口(Context Window)」,就好似模型喺生成下一次回答時,眼前能夠同時「見到」嘅所有信息。佢包括咗你嘅系統提示詞(System Prompt)、到目前為止嘅聊天記錄、每一次嘅工具調用(Tool Call)同佢嘅輸出結果,甚至仲有佢讀過嘅每一個文件。而家,Claude Code 擁有高達 100 萬個詞元(Token)(註釋:Token 係大模型處理文本嘅基本單位,通常一個英文單詞約為 1 個 Token,一個漢字可能佔 1-2 個 Token) 嘅超大上下文窗口。
但可惜嘅係,使用上下文係需要付出一啲代價嘅,我哋通常稱之為上下文衰減(Context Rot)(註釋:指隨住對話歷史越來越長,模型需要處理嘅信息量過大,導致佢嘅注意力分散,遺忘早期重要信息或被無關內容幹擾嘅現象)。隨住上下文越來越長,模型嘅表現往往會變差,係因為佢嘅注意力被分散到更多嘅 Token 上。早期遺留落嚟、已經無關重要嘅內容,會開始幹擾模型當前執行緊嘅任務。
上下文窗口有硬性容量上限。所以,當你快要用爆個窗口嗰陣,你一定要將你做緊嘅任務總結成一段簡短嘅描述,然後帶住呢段描述喺一個新嘅上下文窗口入面繼續工作。我哋將呢個過程稱為上下文壓縮(Compaction)(註釋:為咗騰出內存空間,將超長歷史記錄提煉成精簡摘要嘅過程)。當然,你可以隨時手動觸發呢個壓縮過程。
每一次回合,都係一個分叉路口
幻想嚇,你啱啱叫 Claude 幫你做咗一件事,而佢已經完成咗。而家,你嘅上下文裏面已經塞咗一啲信息(例如工具調用、工具嘅輸出結果、你畀嘅指令)。接下來應該點做?你可能會驚訝咁發現,自己竟然有咁多種選擇:
• 繼續(Continue) — 喺同一個會話入面,直接 send 下一條消息 • 回溯(/rewind 或連撳兩下 Esc 掣) — 時光倒流,退返到之前嘅一條消息,由嗰度重新開始嘗試 • 清空(/clear) — 開一個全新嘅會話,通常帶住你由啱啱嘅對話入面提煉出嚟嘅簡短總結 • 壓縮(Compact) — 將目前嘅對話做個總結,然後喺呢個總結嘅基礎上繼續做嘢 • 子智能體(Subagents) — 將下一階段嘅工作委派畀另一個擁有自己乾淨上下文嘅 AI 智能體(AI Agent),而且只係將佢最終嘅工作結果拉返過嚟
雖然直接「繼續」係最順理成章嘅反應,但係其他四個選項嘅設定,正正係為咗幫你更好咁管理你嘅上下文。
幾時應該開個新會話?
到底幾時應該維持一個漫長嘅老會話,幾時又應該另起爐灶呢?我哋嘅經驗法則係:當你開始一項新任務嘅時候,你都應該開一個新會話。
100 萬嘅上下文窗口,意味住你而家可以非常可靠咁完成更長、更複雜嘅任務。例如,叫 Claude 由零開始為你搭建一個全棧應用。
但有時候,你可能做緊一啲前後關聯嘅任務。呢個時候,你需要保留一部分之前嘅上下文,但唔係全部。舉個例,你啱啱寫完一個新功能,而家要為佢寫一份使用文檔。你當然可以開個新會話,但係咁樣 Claude 就要將你啱啱寫過嘅所有代碼文件重新讀一次——咁樣唔單止慢,仲會貴啲。
用「回溯」代替「糾正」
如果一定要我揀一個代表「優秀上下文管理能力」嘅好習慣,一定係用好「回溯(Rewind)」
喺 Claude Code 入面,雙撳 Esc 掣(或者行 /rewind 命令)可以令你穿越返去之前嘅任何一條消息,然後由嗰度重新落提示詞。至於嗰個節點之後發生嘅所有對話,都會被從上下文中徹底拋棄。
喺糾正 AI 嘅錯誤時,「回溯」通常係更高明嘅做法。舉個例:Claude 讀咗五個文件,嘗試咗一種方法,結果失敗咗。你嘅本能反應可能係喺對話框度打:「呢招唔得,試 X 方法啦。」但更聰明嘅做法係,回溯到佢啱啱讀完五個文件嘅時刻,然後帶住你啱啱學到嘅教訓重新同佢講:「唔好用 A 方法啦,foo 模塊根本唔支援嗰個——直接去試 B 方法。」
你甚至可以用「由呢度開始總結(summarize from here)」嘅功能,叫 Claude 將佢自己學到嘅教訓總結成一段「交接信息」。感覺就好似係嗰個啱啱踩咗坑嘅「未來版 Claude」,寫咗張字條畀過去仲未開始行動嘅自己。

上下文壓縮 vs 全新會話
當一個會話變得越來越長嗰陣,你有兩個方法可以幫佢「減負」:用 /compact (壓縮)或者 /clear (清空並由頭開始)。呢兩個操作聽落好似,但實際表現好唔同。
壓縮(Compact) 係叫模型將到目前為止嘅對話總結一下,然後用呢份摘要取代冗長嘅歷史記錄。呢個過程係「有損」嘅,意味住你將決定「咩內容重要」嘅權力交咗畀 Claude。好處係你唔使寫嘢,而且 Claude 喺保留重要嘅經驗教訓或者文件記錄時,可能比你想得仲周到。你都可以透過畀佢指令嚟掌控壓縮嘅方向(例如:/compact 將重點放在身份驗證模塊的重構上,丟掉那些關於測試調試的內容)。
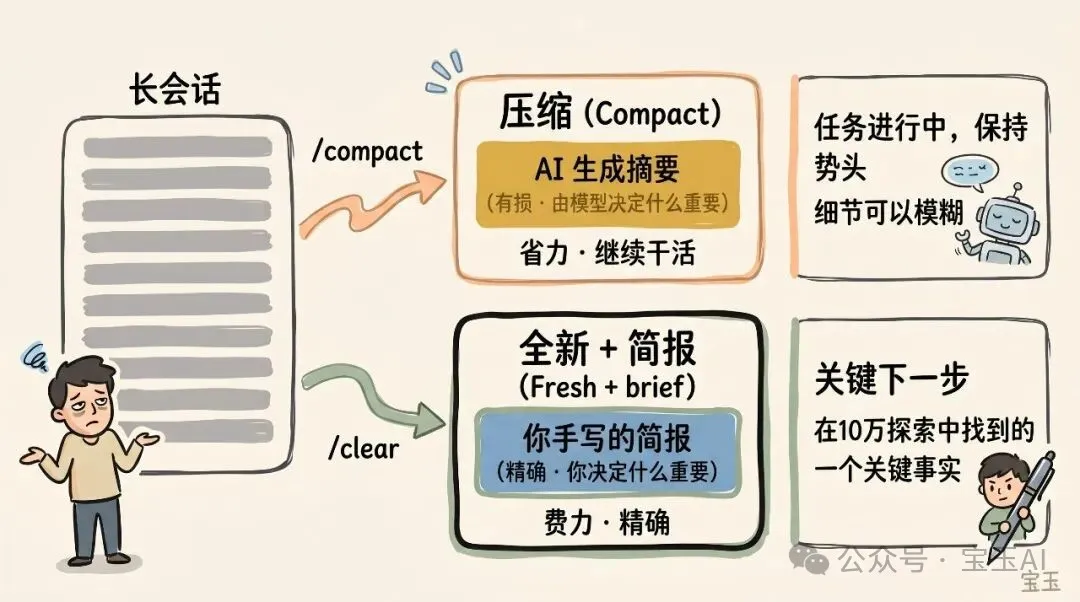
而使用 /clear,就要你自己寫低核心要點(例如:「我哋重整緊身份驗證嘅中間件,目前嘅限制條件係 X,相關嘅重要文件係 A 同 B,而且我哋已經排除咗方法 Y」),然後以一個無比乾淨嘅狀態重新開始。雖然要花啲功夫,但係咁樣產生嘅新上下文,百分百都係你認為真正相關嘅精華。
乜嘢樣嘅「壓縮」會出事?
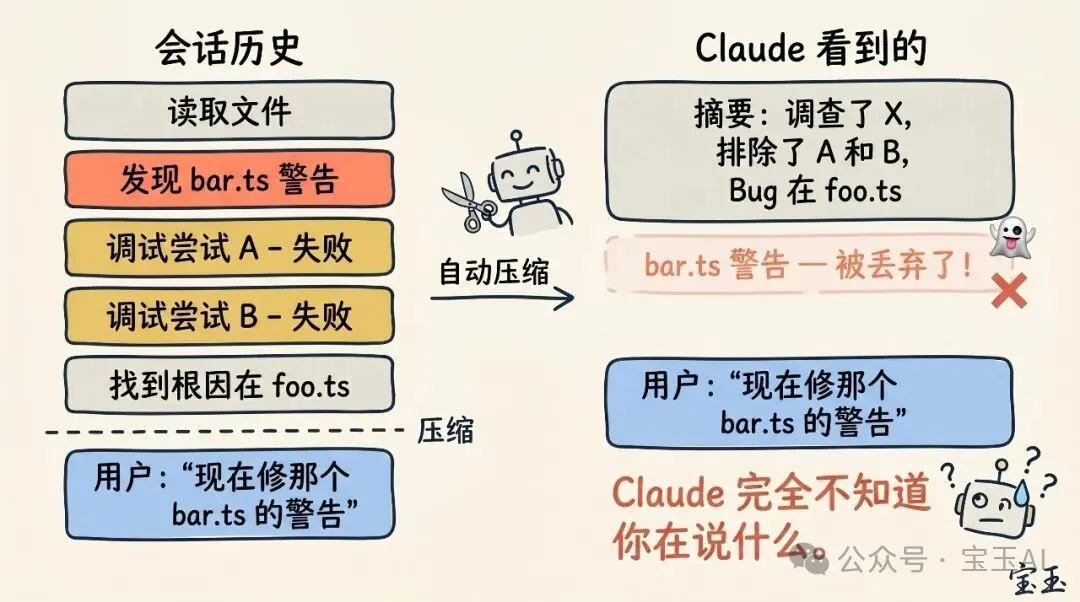
如果你成日掛住超長嘅會話,你大概遇到過「壓縮」效果極之差嘅情況。我哋發現,呢啲「出事」通常發生喺一個特定時刻:就係大語言模型(LLM)無辦法預測你下一步工作方向嘅時候。
舉個例,喺一段漫長嘅代碼除錯之後,系統觸發咗自動壓縮,將之前嘅排查過程總結咗一輪。結果你跟手講咗句:「而家,將我哋之前喺 bar.ts 度見到嘅另一個警告都修咗佢。」
但係,由於啱啱嘅會話重點全喺除錯前一個 Bug 度,嗰個未得閒修嘅警告好可能已經被當成無關重要嘅信息,喺總結時直接丟棄咗。
呢個係一個相當棘手嘅問題。因為受限於上下文衰減,模型喺進行壓縮那一刻,往往係佢「智商」最唔在線嘅時候。好彩有咗 100 萬嘅上下文容量,你而家有咗更充裕嘅空間,可以主動帶住「我接下來想做啲乜」嘅描述,去提前執行 /compact。
子智能體與全新的上下文窗口
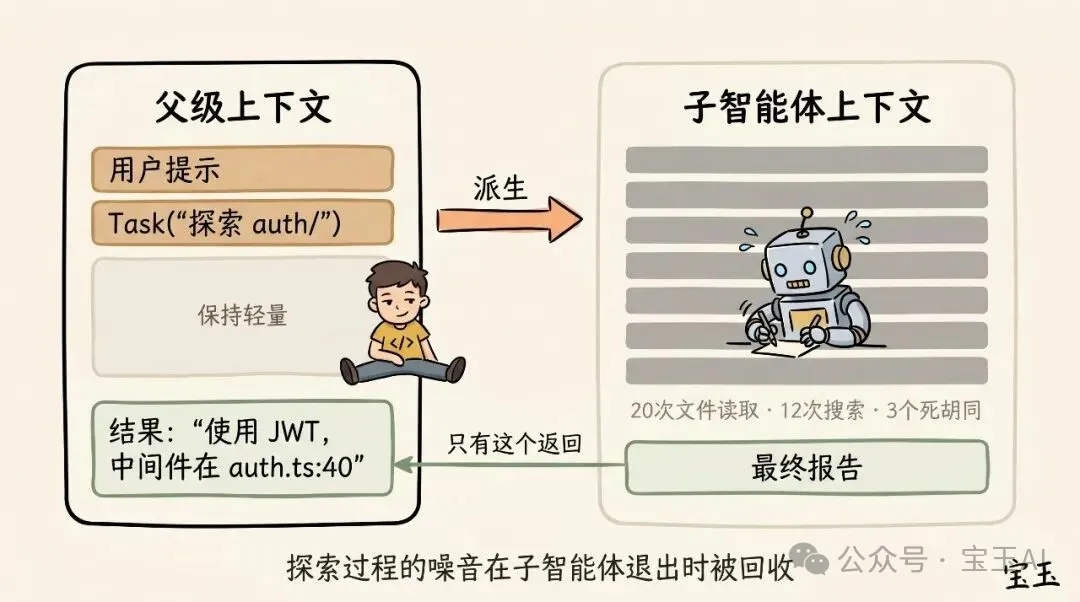
子智能體都係一種管理上下文嘅絕佳手段。當你預先知到某一項工作會產生大量「睇完就掉」(以後再唔會用)嘅中間結果嗰陣,呢招特別有用。
當 Claude 透過智能體工具(Agent tool)衍生出一個子智能體時,呢個細路會得到一個完全嶄新嘅上下文窗口。佢可以喺裏面任意搞,做幾多工夫都得。等到搞掂,佢會將結果提煉出嚟,淨係將最終嘅報告交返畀「父級」Claude。
我哋判斷係咪要用子智能體嘅「靈魂拷問」係:之後我仲要睇呢啲工具運行嘅詳細輸出嗎,定係我只係想要一個最終結論?
雖然 Claude Code 會喺背後自動調用子智能體,但有時候你可以好明確咁指揮佢。例如,你可以同佢講:
• 「派個子智能體去,根據下面呢份規範文件,驗證一下我哋啱啱做嘅工作啱唔啱」 • 「派個子智能體去通讀一下另一個代碼庫,總結出佢係點樣實現身份驗證流程嘅,然後你自己照辦煮碗,喺呢邊都實現一次」 • 「派個子智能體去,根據我嘅 Git 修改記錄,畀呢個新功能寫份說明文檔」
總結
總括嚟講,當 Claude 完成咗一輪回答,而你準備 send 一條新消息嗰陣,你就企喺一個決策嘅路口。
我哋期望喺未來,Claude 能夠夠聰明,自己幫你打理好呢一切。但係以目前嚟講,熟練掌握呢啲決策,正正係你引導 Claude 產出高質量結果嘅必經之路。
引用連結
[1] Using Claude Code: Session Management & 1M Context: https://x.com/trq212/status/2044548257058328723
作者:Thariq
原文:Using Claude Code: Session Management & 1M Context[1]
【注:Thariq 是 Anthropic 員工,Claude Code 的核心對外佈道者。這篇本質是產品使用指南,有官方推廣成分,但操作建議確實實用。】
今天,我們為 /usage 命令推出了一項全新更新,旨在幫助你更清晰地瞭解自己在 Claude Code 中的使用情況。這個決定的背後,是我們近期與用戶進行的多次深入交流。
在這些交流中,我們反覆聽到了一個現象:大家在管理會話時的習慣可謂是五花八門。尤其是最近 Claude Code 將上下文窗口(Context Window)升級到了 100 萬大關,這種差異就更明顯了。
你是習慣在終端裏只保持一兩個開着的會話?還是每次輸入提示詞都重新開個新會話?你通常在什麼時候會用到壓縮(Compact)、回溯(Rewind)或者子智能體(Subagents)?又是什麼原因導致了一次糟糕的壓縮呢?
這裏頭其實大有學問。這些看似不起眼的細節,極大地影響着你使用 Claude Code 的體驗。而這一切的核心,都歸結於一件事:如何管理你的上下文窗口。
快速科普:上下文、上下文壓縮與上下文衰減
所謂“上下文窗口(Context Window)”,就好比模型在生成下一次回答時,眼前能同時“看到”的所有信息。它包括了你的系統提示詞(System Prompt)、到目前為止的聊天記錄、每一次的工具調用(Tool Call)及其輸出結果,甚至還有它讀過的每一個文件。現在,Claude Code 擁有高達 100 萬個詞元(Token)(註釋:Token 是大模型處理文本的基本單位,通常一個英文單詞約為 1 個 Token,一個漢字可能佔 1-2 個 Token) 的超大上下文窗口。
但遺憾的是,使用上下文是需要付出一點代價的,我們通常稱之為上下文衰減(Context Rot)(註釋:指隨着對話歷史越來越長,模型需要處理的信息量過大,導致其注意力分散,遺忘早期重要信息或被無關內容干擾的現象)。隨着上下文越來越長,模型的表現往往會變差,這是因為它的注意力被分散到了更多的 Token 上。那些早期遺留的、已經無關緊要的內容,會開始干擾模型當前正在執行的任務。
上下文窗口是有硬性容量上限的。所以,當你快要把窗口撐滿時,你必須把你正在做的任務總結成一段簡短的描述,然後帶着這段描述在一個新的上下文窗口裏繼續工作。我們把這個過程稱為上下文壓縮(Compaction)(註釋:為了騰出內存空間,將超長曆史記錄提煉成精簡摘要的過程)。當然,你也可以隨時手動觸發這個壓縮過程。
每一次回合,都是一個分叉路口
想象一下,你剛剛讓 Claude 幫你做了一件事,並且它已經完成了。現在,你的上下文裏已經塞進了一些信息(比如工具調用、工具的輸出結果、你給的指令)。接下來該怎麼做?你可能會驚訝地發現,自己竟然有這麼多種選擇:
• 繼續(Continue) — 在同一個會話裏,直接發送下一條消息 • 回溯(/rewind 或連按兩次 Esc 鍵) — 時光倒流,退回到之前的一條消息,從那裏重新開始嘗試 • 清空(/clear) — 開啓一個全新的會話,通常帶上你從剛才對話中提煉出的簡短總結 • 壓縮(Compact) — 把目前的對話做個總結,然後在這個總結的基礎上繼續幹活 • 子智能體(Subagents) — 把下一階段的工作委派給另一個擁有自己乾淨上下文的 AI 智能體(AI Agent),並且只把它最終的工作結果拉取回來
雖然直接“繼續”是最順理成章的反應,但其他四個選項的設定,正是為了幫你更好地管理你的上下文。
什麼時候該開個新會話?
到底什麼時候該維持一個漫長的老會話,什麼時候又該另起爐灶呢?我們的經驗法則是:當你開始一項新任務時,你也應該開啓一個新會話。
100 萬的上下文窗口,意味着你現在可以非常靠譜地完成更長、更復雜的任務。比如,讓 Claude 從零開始為你搭建一個全棧應用。
但有時候,你可能在做一些前後關聯的任務。這時候,你需要保留一部分之前的上下文,但不是全部。舉個例子,你剛寫完一個新功能,現在要為它寫一份使用文檔。你當然可以開個新會話,但這意味着 Claude 必須把你剛才寫過的所有代碼文件重新讀一遍——這不僅速度更慢,而且花費也更高。
用“回溯”代替“糾正”
如果非要我挑出一個能代表“優秀上下文管理能力”的好習慣,那一定是用好“回溯(Rewind)”。
在 Claude Code 裏,雙擊 Esc 鍵(或者運行 /rewind 命令)能讓你穿越回之前的任意一條消息,然後從那裏重新下發提示詞。至於那個節點之後發生的所有對話,都會被從上下文中徹底拋棄。
在糾正 AI 的錯誤時,“回溯”往往是更高明的做法。舉個例子:Claude 讀了五個文件,嘗試了一種方法,結果失敗了。你的本能反應可能是在對話框裏敲下:“這招不管用,換 X 方法試試。”但更聰明的做法是,回溯到它剛讀完那五個文件的時刻,然後帶着你剛學到的教訓重新對它說:“別用 A 方法了,foo 模塊根本不支持那個——直接去試 B 方法。”
你甚至可以使用“從這裏開始總結(summarize from here)”的功能,讓 Claude 自己把它學到的教訓總結成一段“交接信息”。這感覺就像是那個剛剛踩了坑的“未來版 Claude”,給過去那個還沒開始行動的自己留下了一張字條。
上下文壓縮 vs 全新會話
當一個會話變得越來越長時,你有兩種方法可以給它“減負”:使用 /compact (壓縮)或者 /clear (清空並從頭開始)。這兩個操作聽起來挺像,但實際表現大相徑庭。
壓縮(Compact) 是讓模型把到目前為止的對話總結一下,然後用這份摘要替換掉冗長的歷史記錄。這個過程是“有損”的,意味着你把決定“什麼內容重要”的權力交給了 Claude。好處是你什麼都不用寫,而且 Claude 在保留重要的經驗教訓或文件記錄時,可能比你想得更周到。你也可以通過給它下達指令來掌控壓縮的方向(比如:/compact 將重點放在身份驗證模塊的重構上,丟掉那些關於測試調試的內容)。
而使用 /clear,則需要你自己寫下核心要點(例如:“我們正在重構身份驗證的中間件,目前的限制條件是 X,相關的重要文件是 A 和 B,而且我們已經排除了方法 Y”),然後以一個無比干淨的狀態重新開始。雖然這要費點勁,但由此產生的新上下文,百分百都是你認為真正相關的精華。
什麼樣的“壓縮”會翻車?
如果你經常掛着超長的會話,你大概率遇到過“壓縮”效果極其糟糕的情況。我們發現,這種“翻車”通常發生在一個特定的時刻:那就是大語言模型(LLM)無法預測你下一步工作方向的時候。
舉個例子,在一段漫長的代碼調試之後,系統觸發了自動壓縮,把之前的排查過程總結了一番。結果你緊接着發了一句:“現在,把我們之前在 bar.ts 裏看到的另一個警告也修了吧。”
可是,由於剛才的會話重點全在調試前一個 Bug 上,那個沒來得及修的警告很可能早就被當成無關緊要的信息,在總結時被直接丟棄了。
這是一個相當棘手的問題。因為受限於上下文衰減,模型在進行壓縮的那一刻,往往是它“智商”最不在線的時候。好在有了 100 萬的上下文容量,你現在有了更充裕的空間,可以主動帶上“我接下來想做什麼”的描述,去提前執行 /compact。
子智能體與全新的上下文窗口
子智能體也是一種管理上下文的絕佳手段。當你提前預知某一項工作會產生大量“閲後即焚”(以後再也用不上)的中間結果時,這招特別管用。
當 Claude 通過智能體工具(Agent tool)衍生出一個子智能體時,這個小傢伙會獲得一個完全嶄新的上下文窗口。它可以在裏面肆意折騰,做多少工作都行。等到大功告成,它會把結果提煉出來,只把最終的報告交還給“父級”Claude。
我們判斷是否該用子智能體的“靈魂拷問”是:以後我還需要看這些工具運行的詳細輸出嗎,還是我只想要一個最終結論?
雖然 Claude Code 會在背後自動調用子智能體,但有時候你也可以非常明確地指揮它。比如,你可以對它說:
• “派個子智能體去,根據下面這份規範文件,驗證一下我們剛才做的工作對不對” • “派個子智能體去通讀一下另一個代碼庫,總結出它是怎麼實現身份驗證流程的,然後你自己照貓畫虎,在這邊也實現一遍” • “派個子智能體去,根據我的 Git 修改記錄,給這個新功能寫份說明文檔”
總結
總而言之,當 Claude 完成了一輪迴答,而你正準備發送一條新消息時,你就站在了一個決策的路口。
我們期望在未來,Claude 能足夠聰明,自己幫你打理好這一切。但就目前而言,熟練掌握這些決策,正是你引導 Claude 產出高質量結果的必經之路。
引用連結
[1] Using Claude Code: Session Management & 1M Context: https://x.com/trq212/status/2044548257058328723