【保姆教程】我用 Obsidian +hermes搭了一個會自己整理的知識庫
整理版優先睇
用 Obsidian 搭一個會自己整理的知識庫,AI 幫你分類歸檔,你只需負責扔入新內容。
嬌姐係一個 40+ IT 從業者,前榮耀員工,而家專注 AI 效率工具研究。佢發現好多人筆記記咗一大堆,但係要用嗰陣揾唔到,因為冇一個系統。呢篇文章係佢由 0 到 1 搭建個人知識庫嘅實戰經驗,唔係得個講字嘅水文。
佢揀咗 Obsidian,原因係所有筆記都係本地純文字 Markdown,AI 可以直接讀寫,唔使搞 API。佢設計咗一套目錄結構,係改良版嘅 PARA 方法,分咗收件箱、領域、項目、資源、內容生產、系統控制六個區域,新嘢先掉入 Inbox 消除分類摩擦。每篇筆記用 Frontmatter 變成數據庫記錄,配合模板標準化。仲寫咗一個 _INDEX.md 作為 AI 說明書,畀 AI Agent 讀完就知道點分類。
日常用好簡單:有新嘢就掉入 Inbox,每星期清理一次,要寫內容就用模板。舊內容唔使一次過遷移,慢慢搞就得。接入 AI Agent 分三個階段:最基本係手動將內容貼畀 AI 叫佢整理;進階係用 Claude Code 或 Hermes Agent 直接讀寫知識庫,一句指令就搞掂;最高級係 LLM Wiki 模式,AI 會主動整理筆記、生成概念頁面同自動連結,令知識庫越用越乾淨。成個系統嘅核心係降低存入門檻,提高取用效率,中間嘅整理交畀 AI。
- 結論:揀 Obsidian 係因為本地純文字,AI 可以直接讀寫,數據永遠屬於你。
- 方法:採用改良版 PARA 目錄結構,設 Inbox 降低分類摩擦,用 Frontmatter 同模板標準化筆記。
- 差異:寫 _INDEX.md 作為 AI 說明書,令 AI 可以自動分類,而唔係靠人手整理。
- 啟發:AI 整理分三個階段,由手動到半自動到全自動,逐步減少人工幹預。
- 可行動點:立即下載 Obsidian,跟住文章建立目錄結構同模板,開始掉入第一條筆記。
工具選型:點解揀 Obsidian
市面上筆記工具多到眼花,嬌姐幾乎用過曬,最後留低 Obsidian。原因好簡單:所有筆記都係本地純文字 Markdown 文件,AI 可以直接讀寫,唔使搞 API,數據永遠屬於你。相比 Notion、飛書呢類雲端工具,Obsidian 冇鎖倉風險,而且文件夾就係目錄結構,所見即所得。
Obsidian 係目前 AI Agent 最容易操作嘅筆記工具,冇之一。
嬌姐仲整理咗一個主流工具對比表,話你知邊個適合咩情況:Notion 適合團隊協作、飛書適合企業辦公、Logseq 適合大綱式筆記,而 Obsidian 就係個人知識庫長期積累嘅首選。
從零搭建:目錄、模板、插件同 AI 說明書
第一步係設計目錄結構,呢步係地基,做錯咗之後會亂到七彩。嬌姐用改良版 PARA,分咗六個區:00_Inbox(收件箱)、01_Areas(持續關注領域)、02_Projects(有截止日期項目)、03_Resources(資料庫)、04_Content(內容生產)、05_Archive(歸檔)同 00_System(系統控制)。新嘢一律先掉入 Inbox,消除分類摩擦。
D:\zhishiku\
├── 00_Inbox\
├── 01_Areas\
│ ├── AI學習\
│ ├── 自媒體運營\
│ └── 個人成長\
├── 02_Projects\
├── 03_Resources\
│ ├── AI工具\
│ ├── 工作流\
│ ├── 行業資訊\
│ └── 書籍課程\
├── 04_Content\
│ ├── 選題庫\
│ ├── 草稿\
│ ├── 已發佈\
│ └── 素材庫\
├── 05_Archive\
└── 00_System\
├── _INDEX.md
└── _TEMPLATES\每篇筆記頂部要加 Frontmatter,變成一條數據庫記錄,方便 AI 過濾。仲要建立三個模板(筆記模板、項目模板、內容模板),配合 Templater 插件自動套用。三個必裝插件:Templater(模板引擎)、Dataview(數據查詢)、Smart Connections(AI 語義搜索)。
文件夾前面加數字係為咗控制排序,令目錄順序固定唔會亂。
---
title: YouTube 長視頻工作流
date: 2026-04-23
tags: [YouTube, 工作流, 自媒體]
area: 自媒體運營
status: done
source: 本地文件遷移
---最關鍵嘅係寫一個 _INDEX.md,呢個係 AI Agent 進入知識庫嘅說明書,入面有分類判斷樹,AI 讀完就知點放內容。
1. 有截止日期、有明確目標的事?
→ 是 → 02_Projects
2. 要發佈的自媒體內容?
→ 是 → 04_Content/對應子目錄
3. AI 工具的教程、測評、使用心得?
→ 是 → 03_Resources/AI工具
4. 可複用的工作流程或方法論?
→ 是 → 03_Resources/工作流
5. 行業資訊、趨勢、新聞?
→ 是 → 03_Resources/行業資訊
6-8. 讀書筆記 / 運營策略 / AI學習...
→ 對應 Resources 或 Areas 子目錄
9. 以上都不確定?
→ 先放 00_Inbox,備註原因日常使用同 AI 接入:三個動作搞掂
日常用好簡單:有新嘢掉入 Inbox -> 每星期清理一次 -> 要寫內容就用模板。舊內容唔使一次過遷移,慢慢搞就得。呢個系統嘅價值係將「整理」呢個最費時間嘅環節從你身上拎走。
重點:系統的價值在於把「整理」呢個最費時間的環節,從你身上拿走了。
AI 接入分三個階段。階段一係手動指令模式:將內容貼畀任何 AI 工具,叫佢跟住提示詞整理。階段二係半自動:用 Claude Code 或 Hermes Agent 直接讀寫知識庫,一句指令就自動分類。階段三係 LLM Wiki 模式:AI 主動整理筆記,生成概念頁面同自動交叉連結,令知識庫越用越乾淨。
LLM Wiki 模式:AI 主動整理,生成概念頁面,自動連結,知識庫越用越乾淨。
嬌姐仲推薦咗兩個進階方案:方案 A 用 Claude Code 命令行工具,方案 C 用 Hermes Agent 開源框架,支援定時任務同跨平台觸發。如果你係進階用戶,可以試 LLM Wiki 模式,呢個係 Andrej Karpathy 提出嘅概念,係 RAG 嘅進化版。
LLM Wiki 同 RAG 嘅本質分別:一個係主動整理,一個係被動檢索。

文末嬌姐整理咗 openclaw 或者 hermes 嘅所有文章連結
想了解嬌姐就撳文末連結
你手機備忘錄入面有幾多條筆記?飛書文檔存咗幾多篇?瀏覽器書籤欄收藏咗幾多「以後先睇」嘅文章?
我估你嘅答案係:唔少。
但如果我問你:上個月學到最有價值嘅一個方法論係咩,你能唔能夠喺 30 秒內揾到佢?
通常都唔得。
呢個就係大多數人嘅現狀:筆記記咗一大堆,但知識冇沉澱到。 記咗等於冇記,因為你根本揾唔到、用唔到。
問題出喺邊?唔係你唔夠勤力,而係你欠一個系統。

今日呢篇文章,我會將自己由 0 到 1 建立個人知識庫嘅完整過程寫出嚟。唔係嗰種「推薦你用 XX 工具」嘅水貨文,而係一篇你跟住做就搞得掂嘅實戰教學。
重點:呢個知識庫有一個特別能力——佢會自己整理。你淨係負責掟嘢入去,AI 幫你分類、整理、歸檔。
一、工具揀選:點解我揀咗 Obsidian
市面上嘅筆記工具太多喇。我幾乎全部用過一次,最後留低咗 Obsidian。先講結論,再講原因。
主流工具對比
Obsidian ★ 推薦
數據儲存本地 MD 檔案
AI 對接極低(AI 直接讀寫檔案)
費用完全免費
適合個人知識庫、長期積累
Notion
數據儲存雲端數據庫
AI 對接高(需要 API)
適合團隊協作、項目管理
飛書文檔 / 語雀
數據儲存雲端
AI 對接高(需開放平台 / API 受限)
適合企業辦公、團隊知識庫
Logseq
數據儲存本地 MD 檔案
AI 對接低,但大綱格式 AI 解析較麻煩
適合大綱式筆記、日記
我揀 Obsidian 只得一個核心原因:所有筆記都係本地嘅純文字 Markdown 檔案。
即係話有三件事:
第一,數據永遠係你嘅。 唔靠任何雲服務,唔怕產品摺埋、唔怕加價、唔怕被封號。你啲筆記就係電腦上面一堆 .md 檔案,用記事本都開到。
第二,AI 可以直接讀寫。 呢個係最關鍵嘅。Notion 嘅數據鎖咗喺數據庫裏面,AI 要操作佢要行 API,設定好複雜。但 Obsidian 嘅筆記就係檔案,AI Agent 直接讀檔案、寫檔案就搞掂,零門檻。
第三,資料夾就係目錄結構。 唔需要學乜嘢「數據庫視圖」「關聯屬性」,資料夾點樣建立,知識庫就點樣組織,所見即所得。
提示:Obsidian 係目前 AI Agent 最容易操作嘅筆記工具,冇之一。
二、由 0 開始搭建:手把手教你
第 1 步:下載安裝
去 Obsidian 官網(obsidian.md)下載,Windows / Mac / Linux 都支援。安裝完之後佢會叫你建立一個「倉庫」(Vault)。
倉庫其實就係一個資料夾。 Obsidian 會將呢個資料夾入面所有 .md 檔案當作筆記嚟管理。建議放喺非系統磁碟,方便備份。
第 2 步:設計目錄結構
呢個係成個知識庫最重要嘅一步。 好多人裝咗 Obsidian 就即刻開始記筆記,三個月之後又亂到七彩。目錄結構係地基,地基唔啱,後面全部都係白做。
我用嘅係 PARA 方法嘅變體,喺四個基本分類之上加咗收件箱、內容生產區同系統控制層:
目錄結構
D:\zhishiku\
├── 00_Inbox\
← 收件箱,新內容先掟嚟呢度
├── 01_Areas\
← 持續維護嘅領域(冇截止日期)
├── AI學習\
├── 自媒體運營\
└── 個人成長\
├── 02_Projects\
← 有截止日期嘅項目
├── 03_Resources\
← 參考資料庫(AI 檢索主要區域)
├── AI工具\
├── 工作流\
├── 行業資訊\
└── 書籍課程\
├── 04_Content\
← 內容生產流水線
├── 選題庫\
├── 草稿\
├── 已發佈\
└── 素材庫\
├── 05_Archive\
← 已完結歸檔
└── 00_System\
← 系統檔案(AI Agent 專用)
├── _INDEX.md
└── _TEMPLATES\
每個區域嘅核心邏輯:
① 00_Inbox 收件箱
成個系統嘅入口。任何新嘢全部先掟嚟呢度,唔使諗分類、唔使整理格式。「分類」呢個動作會產生摩擦,收件箱就消除咗呢個摩擦。
② 01_Areas 領域
你持續關注嘅方向,冇截止日期,要長期維護。例如「AI 學習」係一個你會一直關注嘅領域,唔係做完就完咗嘅。
③ 03_Resources 資料庫
知識庫嘅核心區域,亦係後續 AI Agent 主要檢索嘅地方。工具教學、工作流方法論、行業資訊、讀書筆記全部喺呢度。
④ 04_Content 內容生產
如果你做自媒體,呢個區域就係你嘅內容流水線。選題 → 草稿 → 已發佈,三段式管理。唔做自媒體嘅話可以唔建立。
⑤ 00_System 系統層
專為 AI Agent 設計。裏面有 _INDEX.md——AI 進入知識庫嘅「說明書」,後面會詳細講。
提示:資料夾名前面加數字(00、01、02...)係為咗控制排序。Obsidian 預設按字母排序,加數字之後目錄順序固定,唔會走位。
第 3 步:每篇筆記定一個標準格式(Frontmatter)
喺 Obsidian 入面,每篇筆記頂部可以寫一段叫 frontmatter 嘅資訊,佢令每篇筆記變成一條「數據庫記錄」,AI Agent 可以按條件過濾筆記。
YAML Frontmatter 示例
---
title: YouTube 長視頻工作流
date: 2026-04-23
tags: [YouTube, 工作流, 自媒體]
area: 自媒體運營
status: done
source: 本地檔案遷移
---
status 嘅流轉邏輯:draft(啱啱寫嘅草稿)→ done(整理完畢)→ archived(唔再活躍)。
你唔需要記住呢啲,後面會用範本自動生成。
第 4 步:建立筆記範本
在 00_System/_TEMPLATES 喺資料夾入面建立三個範本檔案:
筆記範本.md(用於 01_Areas、03_Resources)
---
title:
date: {{date}}
tags: []
area:
status: draft
---
## 呢篇解決啲乜問題
## 核心內容
## 行動/參考
正文結構用嘅係「問題 → 核心內容 → 行動」三段式,呢個結構會自然導向「呢條資訊解決啲乜問題、對我下一步有咩用」,而唔係得摘錄。
喺 Obsidian 設定範本:
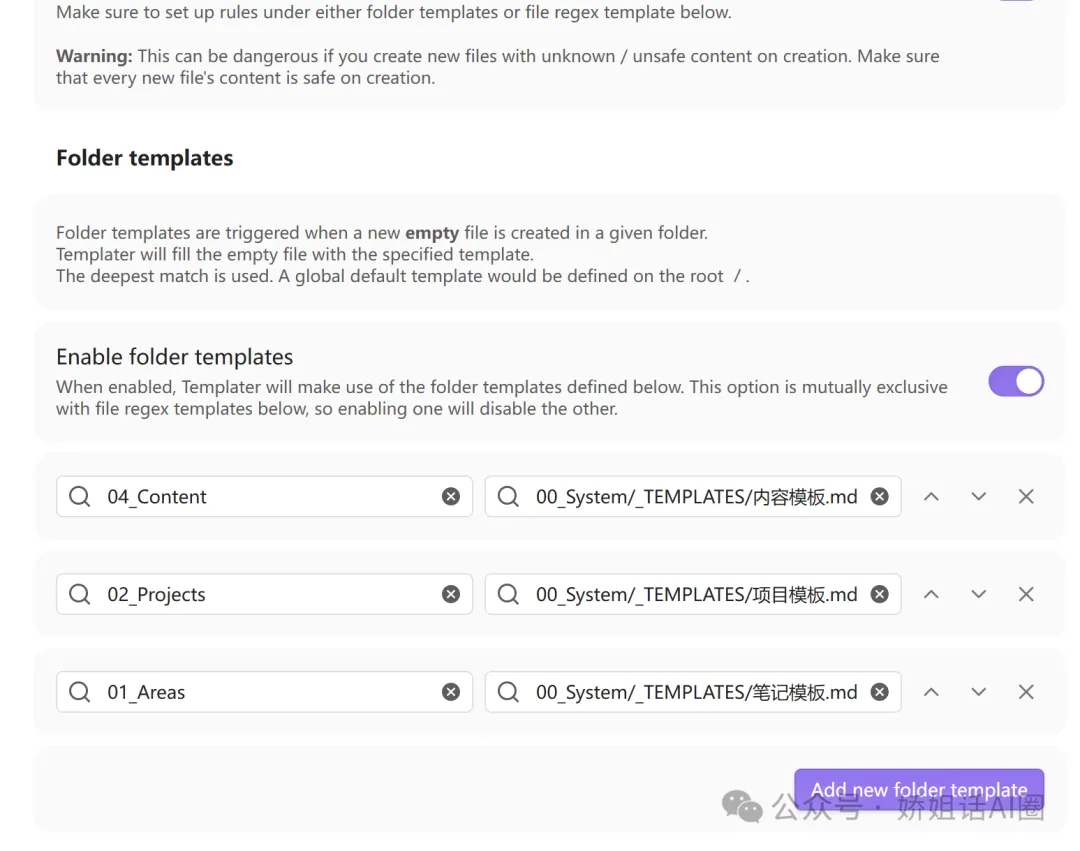
第 5 步:安裝三個必備插件
安裝路徑:設定 → 第三方插件 → 關閉安全模式 → 瀏覽 → 搜尋 → 安裝 → 啓用。
插件① Templater(範本引擎)
作用:新建筆記時自動套用範本,frontmatter 日期會自動填寫當日。
配置:喺 Folder Templates 入面為每個資料夾設定對應範本,之後新建檔案就會自動套用。
插件② Dataview(數據查詢)
作用:好似數據庫咁查詢你嘅筆記。裝好即用,唔使額外設定。
示例:喺筆記入面寫查詢語句,可以列出所有 status=done 嘅完成筆記,或者按日期排序曬所有資料。
插件③ Smart Connections(AI 語義搜尋)
作用:用自然語言對住知識庫發問,AI 會揾到最相關嘅筆記並回答,唔係簡單嘅關鍵詞配對。
配置:安裝之後揀選 embedding 模型(推薦 Claude API 或本地 Ollama),首次執行會掃描倉庫建立向量索引。
第 6 步:寫一個 AI 讀得明嘅索引檔案(_INDEX.md)
呢個係成套系統最關鍵嘅設計。 呢個檔案係 AI Agent 進入你知識庫嘅「說明書」,寫清楚每個目錄係做咩、命名規範、分類判斷邏輯。
最核心嘅部分係一棵分類判斷樹,AI Agent 攞到一篇內容之後,按順序行:
_INDEX.md 分類判斷樹
1. 有截止日期、有明確目標嘅事?
→ 係 → 02_Projects
2. 要發佈嘅自媒體內容?
→ 係 → 04_Content/對應子目錄
3. AI 工具嘅教學、評測、使用心得?
→ 係 → 03_Resources/AI工具
4. 可重用嘅工作流程或方法論?
→ 係 → 03_Resources/工作流
5. 行業資訊、趨勢、新聞?
→ 係 → 03_Resources/行業資訊
6-8. 讀書筆記 / 營運策略 / AI學習...
→ 對應 Resources 或 Areas 子目錄
9. 以上都唔肯定?
→ 先放 00_Inbox,備註原因
AI Agent 讀完呢個檔案,就知道要將內容放喺邊度、用咩格式、點樣命名。
三、日常使用:淨係得三個動作
搭完之後,日常用起嚟好簡單:
① 有任何新嘢 → 掟入 00_Inbox
見到好文章、學到新方法、突然諗到嘅諗法,全部先掟入 Inbox。唔使諗分類,唔使整理格式,甚至淨係寫一句話都得。先存低,呢個係最重要嘅。
② 每星期清理一次 Inbox
呢個動作之後會交畀 AI 自動完成。就算手動做都好簡單:打開 Inbox 裏面嘅檔案,按分類判斷樹決定放邊度,移過去就得。
③ 要寫內容 → 去 04_Content/草稿 新建
範本會自動套用,frontmatter 會自動填好,直接開始寫。
重點:系統嘅價值在於將「整理」呢個最花時間嘅步驟,由你身上拎走咗。
四、舊內容點樣遷移
原則:唔好追求一次過遷移曬。先將新內容嘅流程行順,舊內容慢慢搬。
- 飛書筆記:
文檔 → 右上角「...」→ 匯出 → Word → 下載,用 Pandoc 轉成 .md 檔案,全部掟入 Inbox,後續畀 AI 批量整理。 - 本地檔案:
.md 檔案直接複製入對應資料夾;Word、PDF 等先掟入 Inbox,後續手動或 AI 整理。 - 手機備忘錄:
複製內容 → 喺 Obsidian 手機端新建筆記 → 貼上入 Inbox(iOS/Android 客戶端都有,可以用 iCloud 或 Syncthing 同步)。 - 瀏覽器書籤:
大部分你以後都唔會再睇。建議淨係搬你真係覺得有價值嘅,唔好全部導入。
五、接入 AI Agent:等知識庫自己整理
前面四個部分,你已經有咗一個結構清晰嘅知識庫。但「整理」呢個動作仍然要你自己手做。接下來係呢套系統嘅核心升級:等 AI 幫你整理。
我將 AI 對接分成三個階段,由最簡單到最高級,你可以根據自己嘅情況揀由邊度開始。
階段一:手動指令模式(零設定,即刻用得)
唔需要任何技術基礎。喺任何 AI 工具(ChatGPT、Claude、豆包、Kimi 都得),將內容貼畀佢,傳送呢段提示詞:
整理筆記提示詞
請幫我將以下內容整理成結構化筆記。
要求:
1. 頂部加上 frontmatter(title/date/tags/area/status/source)
2. 正文結構:
- 呢篇解決啲乜問題(一兩句)
- 核心內容(保留所有細節)
- 行動/參考(下一步可以做啲乜)
3. 保留所有步驟、例子、數據,唔好刪減
以下是原始內容:[貼上你嘅內容]
AI 傳返整理好嘅筆記之後,複製到 Obsidian 對應目錄嘅新檔案入面。優點係零門檻,缺點係要手動複製貼上。
階段二:AI 直接讀寫知識庫(半自動)
等 AI Agent 直接存取你電腦上面嘅檔案,自己讀 _INDEX.md 瞭解規則,自己判斷分類,自己建立檔案寫入。
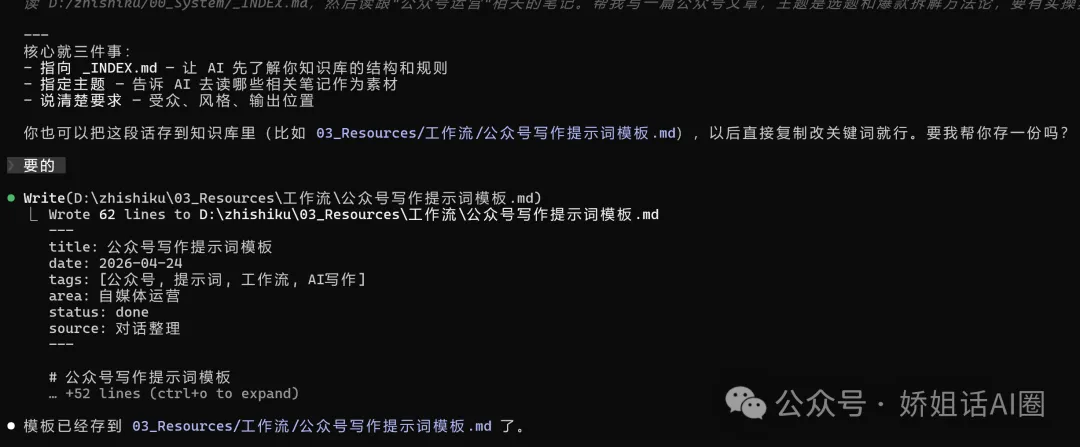
推薦 方案 A:用 Claude Code
Anthropic 出嘅命令行工具,可以直接操作本地檔案。安裝好之後喺終端輸入一句話:「讀 _INDEX.md,幫我清理 00_Inbox,將裏面嘅檔案分類整理到對應目錄」。
全程淨係講一句話就得。 Claude Code 會自動讀規則、掃描檔案、判斷分類、寫入目錄、更新索引。
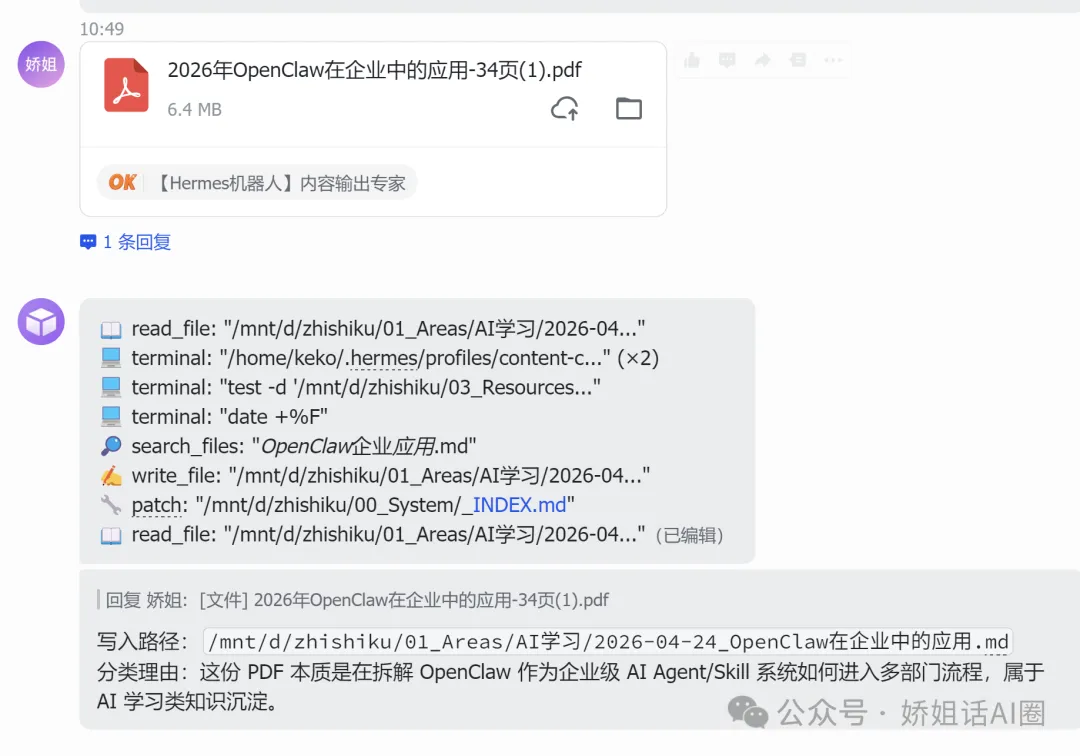
進階 方案 C:用 Hermes Agent
Nous Research 推出嘅開源 AI Agent 框架,透過 MCP filesystem 掛載知識庫路徑。你可以喺飛書、釘釘、Telegram 度講「整理到知識庫」,佢會自動執行完整流程。
特別優勢:支援定時任務(每日自動清理 Inbox),跨平台觸發,唔使開電腦。
階段三:LLM Wiki 模式(最高級)
Andrej Karpathy(OpenAI 聯合創始人)提出咗一個更激進嘅諗法:唔係等 AI 喺你查詢時檢索筆記,而係等 AI 主動整理筆記,生成結構化嘅 wiki 頁面,頁面之間自動交叉連結。
舉個例:你掟咗 10 篇關於「公眾號營運」嘅筆記入知識庫。
- 普通模式:
10 篇筆記靜靜雞放喺度,你要用嘅時候自己走去揾。 - LLM Wiki 模式:
AI 自動提取關鍵概念(選題方法、標題公式、數據指標),為每個概念生成獨立 wiki 頁面,頁面之間自動雙向連結。再掟新筆記入去,AI 會自動合併入已有頁面。
重點:知識庫越用越乾淨,而唔係越堆越亂。呢個就係 LLM Wiki 同普通筆記嘅本質分別。
LLM Wiki vs RAG 對比
RAG(檢索增強)
AI 做咩你問先揾,由筆記度檢索相關片段
筆記狀態原始筆記堆積,靠檢索揾內容
適合快速揾已有內容
LLM Wiki(主動整理)
AI 做咩主動整理,生成概念頁面,自動連結
筆記狀態知識持續精煉,自動交叉連結
適合長期知識積累,產生複利效應
理想嘅最終形態:
① 原始輸入 → 00_Inbox
所有新內容統一入口,唔理咩格式
② Agent 自動分類整理(階段二)
讀 _INDEX.md → 行判斷樹 → 寫入對應目錄
③ LLM Wiki 提煉概念、生成雙鏈(階段三)
概念自動提煉,知識網絡自動生長
④ 圖譜視圖 + 語義檢索
知識網絡可視化 + 自然語言發問,知識庫由「儲存工具」變成「思考夥伴」
六、呢套系統到底解決咗啲乜
之前筆記散落喺飛書、本地、手機,揾唔到
現在統一喺 Obsidian,結構清晰
之前記完就忘,用唔到
現在結構化儲存 + 語義檢索,隨時查到
之前整理筆記太嘥時間
現在AI 自動分類整理,我只負責掟
之前知識係孤島,無法關聯
現在LLM Wiki 自動生成雙鏈,知識網絡可視化
之前擔心數據安全、產品摺埋
現在全部本地儲存,唔靠任何雲服務
總結
呢套系統嘅核心邏輯得一句話:
重點:降低存入門檻,提高攞用效率,等 AI 負責中間嘅整理。
你唔需要係技術高手。Obsidian 免費,插件免費,AI 工具越來越平。成套系統嘅啟動成本接近零。
唯一需要你做嘅,係養成一個習慣:有嘢就掟入 Inbox。
剩低嘅,交畀 AI。
hermes 系列文章
持續更新,建議每篇認真睇
【唔推薦用官方命令】Windows 環境下安裝 Hermes 及遷移 Openclaw 嘅實戰分享
參考劉小排嘅 BuilderPulse :我用 Hermes 發現值得睇嘅 github 項目
【Hermes 整理】OpenClaw 變現項目地圖:6 大賽道
我將 OpenClaw 嘅 Agent 無縫遷移咗去 Hermes——就靠呢一份 Skill
參考 Hermes 優化 OpenClaw:等你嘅 AI 學識記、識覆盤、識巡檢
openclaw 系列文章
openclaw 系列文章
持續更新,建議每篇認真睇
設定與理解
唔好畀人呃,OpenClaw 可以 24 小時開工——但你要先做啱呢 6 件事
紅咗三個月嘅「龍蝦」,普通人裝咗真係有用咩?
用 OpenClaw 醫好 AI 失憶:開關、精簡、外掛三步走
多 Agent 與協作
技能與工具
實戰與案例
排錯與安全
關於嬌姐
40+ IT 從業者,前榮耀員工,而家專注 AI 效率工具研究同實踐。持續輸出 OpenClaw 同 AI 工具嘅乾貨教學同落地案例,間中分享職場思考同生活感悟。
提示:覺得有用,讚好、關注、轉發,係我持續創作嘅動力。
文末嬌姐整理openclaw或者hermes所有文章連結
想了解嬌姐點擊文末連結
你手機備忘錄裏有多少條筆記?飛書文檔裏存了多少篇?瀏覽器書籤欄收藏了多少"以後再看"的文章?
我猜你的回答是:不少。
但如果我問你:上個月學到的最有價值的一個方法論是什麼,你能在 30 秒內找到它嗎?
大概率不能。
這就是大多數人的現狀:筆記記了一大堆,但知識沒有沉澱。 記了等於沒記,因為你根本找不到、用不上。
問題出在哪?不是你不夠勤快,而是你缺一個系統。
今天這篇文章,我把自己從 0 到 1 搭建個人知識庫的完整過程寫出來。不是那種"推薦你用 XX 工具"的水文,而是一篇你照着做就能跑起來的實操教程。
重點:這個知識庫有一個特別的能力——它會自己整理。你只管往裏扔東西,AI 幫你分類、整理、歸檔。
一、工具選型:為什麼我選了 Obsidian
市面上筆記工具太多了。我幾乎都用過一遍,最後留下了 Obsidian。先說結論,再說原因。
主流工具對比
Obsidian ★ 推薦
數據存儲本地 MD 文件
AI對接極低(AI 直接讀寫文件)
費用完全免費
適合個人知識庫、長期積累
Notion
數據存儲雲端數據庫
AI對接高(需要 API)
適合團隊協作、項目管理
飛書文檔 / 語雀
數據存儲雲端
AI對接高(需開放平台 / API 受限)
適合企業辦公、團隊知識庫
Logseq
數據存儲本地 MD 文件
AI對接低,但大綱格式 AI 解析較麻煩
適合大綱式筆記、日記
我選 Obsidian 只有一個核心原因:所有筆記都是本地的純文本 Markdown 文件。
這意味着三件事:
第一,數據永遠是你的。 不依賴任何雲服務,不怕產品倒閉、不怕漲價、不怕被封號。你的筆記就是電腦上的一堆 .md 文件,用記事本都能打開。
第二,AI 可以直接讀寫。 這是最關鍵的。Notion 的數據鎖在數據庫裏,AI 要操作它得走 API,配置複雜。但 Obsidian 的筆記就是文件,AI Agent 直接讀文件、寫文件就行,零門檻。
第三,文件夾就是目錄結構。 不需要學什麼"數據庫視圖""關聯屬性",文件夾怎麼建,知識庫就怎麼組織,所見即所得。
提示:Obsidian 是目前 AI Agent 最容易操作的筆記工具,沒有之一。
二、從 0 搭建:手把手教你
第 1 步:下載安裝
去 Obsidian 官網(obsidian.md)下載,Windows / Mac / Linux 都支持。安裝後它會讓你創建一個"倉庫"(Vault)。
倉庫本質上就是一個文件夾。 Obsidian 會把這個文件夾裏所有的 .md 文件當作筆記來管理。建議放在非系統盤,方便備份。
第 2 步:設計目錄結構
這是整個知識庫最重要的一步。 很多人裝了 Obsidian 就直接開始記筆記,三個月後又亂成一團。目錄結構是地基,地基不對,後面全白搭。
我用的是 PARA 方法的變體,在四個基礎分類上加了收件箱、內容生產區和系統控制層:
目錄結構
D:\zhishiku\
├── 00_Inbox\
← 收件箱,新內容先扔這裏
├── 01_Areas\
← 持續維護的領域(無截止日期)
├── AI學習\
├── 自媒體運營\
└── 個人成長\
├── 02_Projects\
← 有截止日期的項目
├── 03_Resources\
← 參考資料庫(AI 檢索主區域)
├── AI工具\
├── 工作流\
├── 行業資訊\
└── 書籍課程\
├── 04_Content\
← 內容生產流水線
├── 選題庫\
├── 草稿\
├── 已發佈\
└── 素材庫\
├── 05_Archive\
← 已完結歸檔
└── 00_System\
← 系統文件(AI Agent 專用)
├── _INDEX.md
└── _TEMPLATES\
每個區域的核心邏輯:
① 00_Inbox 收件箱
整個系統的入口。任何新東西全部先扔這裏,不用想分類、不用整理格式。"分類"這個動作會產生摩擦,收件箱消除了這個摩擦。
② 01_Areas 領域
你持續關注的方向,沒有截止日期,長期維護。比如"AI 學習"是一個你會一直關注的領域,不是做完就結束的。
③ 03_Resources 資料庫
知識庫的核心區域,也是後續 AI Agent 主要檢索的地方。工具教程、工作流方法論、行業資訊、讀書筆記都在這裏。
④ 04_Content 內容生產
如果你做自媒體,這個區域就是你的內容流水線。選題 → 草稿 → 已發佈,三段式管理。不做自媒體可以不建。
⑤ 00_System 系統層
專門為 AI Agent 設計。裏面有 _INDEX.md——AI 進入知識庫的"說明書",後面詳細講。
提示:文件夾名前面加數字(00、01、02...)是為了控制排序。Obsidian 默認按字母排序,加數字後目錄順序固定,不會亂跑。
第 3 步:給每篇筆記定一個標準格式(Frontmatter)
在 Obsidian 裏,每篇筆記頂部可以寫一段叫 frontmatter 的信息,它讓每篇筆記變成一條"數據庫記錄",AI Agent 可以按條件過濾筆記。
YAML Frontmatter 示例
---
title: YouTube 長視頻工作流
date: 2026-04-23
tags: [YouTube, 工作流, 自媒體]
area: 自媒體運營
status: done
source: 本地文件遷移
---
status 的流轉邏輯:draft(剛寫的草稿)→ done(整理完畢)→ archived(不再活躍)。
你不需要記住這些,後面用模板自動生成。
第 4 步:創建筆記模板
在 00_System/_TEMPLATES 文件夾裏創建三個模板文件:
筆記模板.md(用於 01_Areas、03_Resources)
---
title:
date: {{date}}
tags: []
area:
status: draft
---
## 這篇解決什麼問題
## 核心內容
## 行動/參考
正文結構用的是"問題 → 核心內容 → 行動"三段式,這個結構會自然導向"這條信息解決什麼問題、對我下一步有什麼用",而不只是摘錄。
在obsidian配置模版:
第 5 步:安裝三個必備插件
安裝路徑:設置 → 第三方插件 → 關閉安全模式 → 瀏覽 → 搜索 → 安裝 → 啓用。
插件① Templater(模板引擎)
作用:新建筆記時自動套用模板,frontmatter 日期自動填寫當天。
配置:在 Folder Templates 裏為每個文件夾配置對應模板,之後新建文件自動套用。
插件② Dataview(數據查詢)
作用:像數據庫一樣查詢你的筆記。裝好即用,無需額外配置。
示例:在筆記裏寫查詢語句,可列出所有 status=done 的完成筆記,或按日期排序全部資料。
插件③ Smart Connections(AI 語義搜索)
作用:用自然語言對着知識庫提問,AI 找到最相關的筆記並回答,不是簡單的關鍵詞匹配。
配置:安裝後選擇 embedding 模型(推薦 Claude API 或本地 Ollama),首次運行掃描倉庫建立向量索引。
第 6 步:寫一個 AI 能讀懂的索引文件(_INDEX.md)
這是整套系統最關鍵的設計。 這個文件是 AI Agent 進入你知識庫的"說明書",寫清楚每個目錄是幹什麼的、命名規範、分類判斷邏輯。
最核心的部分是一棵分類判斷樹,AI Agent 拿到一篇內容後,按順序走:
_INDEX.md 分類判斷樹
1. 有截止日期、有明確目標的事?
→ 是 → 02_Projects
2. 要發佈的自媒體內容?
→ 是 → 04_Content/對應子目錄
3. AI 工具的教程、測評、使用心得?
→ 是 → 03_Resources/AI工具
4. 可複用的工作流程或方法論?
→ 是 → 03_Resources/工作流
5. 行業資訊、趨勢、新聞?
→ 是 → 03_Resources/行業資訊
6-8. 讀書筆記 / 運營策略 / AI學習...
→ 對應 Resources 或 Areas 子目錄
9. 以上都不確定?
→ 先放 00_Inbox,備註原因
AI Agent 讀完這個文件,就知道把內容放到哪裏、用什麼格式、怎麼命名。
三、日常使用:只有三個動作
搭完之後,日常用起來非常簡單:
① 有任何新東西 → 扔 00_Inbox
看到好文章、學到新方法、突然冒出的想法,全部先扔進 Inbox。不用想分類,不用整理格式,甚至可以只寫一句話。先存進來,這是最重要的。
② 每週清理一次 Inbox
這個動作後面會交給 AI 自動完成。即使手動做,也很簡單:打開 Inbox 裏的文件,按分類判斷樹決定放哪裏,移過去就行。
③ 要寫內容 → 去 04_Content/草稿 新建
模板自動套上,frontmatter 自動填好,直接開始寫。
重點:系統的價值在於把"整理"這個最費時間的環節,從你身上拿走了。
四、舊內容怎麼遷移
原則:不要追求一次遷移完。先把新內容的流程跑通,舊內容慢慢遷。
- 飛書筆記:
文檔 → 右上角"..." → 導出 → Word → 下載,用 Pandoc 轉成 .md 文件,全部扔進 Inbox,後續讓 AI 批量整理。 - 本地文件:
.md 文件直接複製進對應文件夾;Word、PDF 等先扔 Inbox,後續手動或 AI 整理。 - 手機備忘錄:
複製內容 → 在 Obsidian 手機端新建筆記 → 粘貼進 Inbox(iOS/Android 客戶端均有,可用 iCloud 或 Syncthing 同步)。 - 瀏覽器收藏夾:
大部分你再也不會看了。建議只遷移你確定有價值的,不要全量導入。
五、接入 AI Agent:讓知識庫自己整理
前面四個部分,你已經有了一個結構清晰的知識庫。但"整理"這個動作還是需要你手動做。接下來是這套系統的核心升級:讓 AI 幫你整理。
我把 AI 對接分成三個階段,從最簡單到最高級,你可以根據自己的情況選擇從哪裏開始。
階段一:手動指令模式(零配置,現在就能用)
不需要任何技術基礎。在任意 AI 工具(ChatGPT、Claude、豆包、Kimi 都行),把內容粘貼給它,發送這段提示詞:
整理筆記提示詞
請幫我把以下內容整理成結構化筆記。
要求:
1. 頂部加上 frontmatter(title/date/tags/area/status/source)
2. 正文結構:
- 這篇解決什麼問題(一兩句話)
- 核心內容(保留所有細節)
- 行動/參考(下一步可以做什麼)
3. 保留所有步驟、示例、數據,不要刪減
以下是原始內容:[粘貼你的內容]
AI 返回整理好的筆記後,複製到 Obsidian 對應目錄的新文件裏。優點是零門檻,缺點是需要手動複製粘貼。
階段二:AI 直接讀寫知識庫(半自動)
讓 AI Agent 直接訪問你電腦上的文件,自己讀取 _INDEX.md 瞭解規則,自己判斷分類,自己創建文件寫入。
推薦 方案 A:用 Claude Code
Anthropic 出的命令行工具,可直接操作本地文件。安裝好後在終端輸入一句話:"讀 _INDEX.md,幫我清理 00_Inbox,把裏面的文件分類整理到對應目錄"。
全程只需說一句話。 Claude Code 會自動讀規則、掃描文件、判斷分類、寫入目錄、更新索引。
進階 方案 C:用 Hermes Agent
Nous Research 出品的開源 AI Agent 框架,通過 MCP filesystem 掛載知識庫路徑。你可以在飛書、釘釘、Telegram 裏說"整理到知識庫",它自動執行完整流程。
特別優勢:支持定時任務(每天自動清理 Inbox),跨平台觸發,不需要打開電腦。
階段三:LLM Wiki 模式(最高級)
Andrej Karpathy(OpenAI 聯合創始人)提出了一個更激進的想法:不是讓 AI 在你查詢時檢索筆記,而是讓 AI 主動整理筆記,生成結構化的 wiki 頁面,頁面之間自動交叉連結。
舉個例子:你往知識庫裏扔了 10 篇關於"公眾號運營"的筆記。
- 普通模式:
10 篇筆記靜靜地躺在那裏,你需要的時候自己去翻。 - LLM Wiki 模式:
AI 自動提取關鍵概念(選題方法、標題公式、數據指標),為每個概念生成獨立 wiki 頁面,頁面之間自動雙向連結。再扔進來新筆記,AI 自動合併進已有頁面。
重點:知識庫越用越乾淨,而不是越堆越亂。這就是 LLM Wiki 和普通筆記的本質區別。
LLM Wiki vs RAG 對比
RAG(檢索增強)
AI做什麼你問才找,從筆記裏檢索相關片段
筆記狀態原始筆記堆積,靠檢索找內容
適合快速查找已有內容
LLM Wiki(主動整理)
AI做什麼主動整理,生成概念頁面,自動連結
筆記狀態知識持續精煉,自動交叉連結
適合長期知識積累,產生複利效應
理想的最終形態:
① 原始輸入 → 00_Inbox
所有新內容統一入口,不管格式
② Agent 自動分類整理(階段二)
讀 _INDEX.md → 走判斷樹 → 寫入對應目錄
③ LLM Wiki 提煉概念、生成雙鏈(階段三)
概念自動提煉,知識網絡自動生長
④ 圖譜視圖 + 語義檢索
知識網絡可視化 + 自然語言提問,知識庫從"存儲工具"變成"思考夥伴"
六、這套系統到底解決了什麼
之前筆記散落在飛書、本地、手機,找不到
現在統一在 Obsidian,結構清晰
之前記了就忘,用不上
現在結構化存儲 + 語義檢索,隨時可查
之前整理筆記太費時間
現在AI 自動分類整理,我只負責扔
之前知識是孤島,無法關聯
現在LLM Wiki 自動生成雙鏈,知識網絡可視化
之前擔心數據安全、產品倒閉
現在全部本地存儲,不依賴任何雲服務
總結
這套系統的核心邏輯只有一句話:
重點:降低存入門檻,提高取用效率,讓 AI 負責中間的整理。
你不需要是技術大佬。Obsidian 免費,插件免費,AI 工具越來越便宜。整套系統的啓動成本幾乎為零。
唯一需要你做的,是養成一個習慣:有東西就扔 Inbox。
剩下的,交給 AI。
hermes系列文章
持續更新,建議每篇認真閲讀
【不推薦用官方命令】Windows 環境下安裝Hermes及遷移Openclaw的實操分享
借鑑劉小排的 BuilderPulse :我用 Hermes 發現值得看的github項目
【Hermes整理】OpenClaw 變現項目地圖:6 大賽道
我把 OpenClaw 的 Agent 無縫遷移到了 Hermes——就靠這一份 Skill
借鑑 Hermes 優化 OpenClaw:讓你的 AI 學會記、會覆盤、會巡檢
openclaw系列文章
openclaw系列文章
持續更新,建議每篇認真閲讀
配置與理解
別被騙,OpenClaw 可以 24 小時幹活——但你得先做對這 6 件事
火了三個月的"龍蝦",普通人裝了真的有用嗎?
用 OpenClaw 把 AI 失憶治好:開關、精簡、外掛三步走
多 Agent 與協作
技能與工具
實戰與案例
排錯與安全
關於嬌姐
40+ IT 從業者,前榮耀員工,現專注 AI 效率工具研究與實踐。持續輸出 OpenClaw 及 AI 工具的乾貨教程與落地案例,偶爾分享職場思考與生活感悟。
提示:覺得有用,點贊、關注、轉發,是我持續創作的動力。