借鑑劉小排的 BuilderPulse :我用 Hermes 發現值得看的github項目
整理版優先睇
借鑑 BuilderPulse 的「信號思維」,將 GitHub 項目發現從「隨機刷資訊」升級為一套可持續運行的趨勢雷達系統。
- 核心轉變:從被動接收演算法推薦,轉向主動構建基於公開信號(如 GitHub Search API)的發現機制。
- 信號壓縮:不追求項目數量,而是透過「Why now」維度判斷項目是否處於活躍更新或賽道爆發的窗口期。
- 結構化情報:將 repo 原始資訊加工成包含主賽道分類、適用場景及目標用戶的高密度情報,降低消費門檻。
- 動態追蹤:透過保留歷史快照對比新增項目與增長勢頭,從單次搜索進化為觀察賽道演進的趨勢分析。
- 機會識別:從生態層(如 WebUI、治理工具、桌面端)的湧現,判斷底座技術是否正向產品化與商業化邁進。
GitHub Trend Scout 工作流
一套基於 Hermes 實現的自動化掃描、篩選、分類及追蹤 GitHub AI 項目的標準化流程。
AI 開源項目追蹤文檔
作者將 GitHub Trend Scout 發現的項目整理至飛書文檔,供社羣參考。
點解你 star 咗咁多項目,最後都係一場空?
好多人刷 GitHub 嘅方式同刷 IG 差唔多:睇到 Trending 或者 X 有人轉發就點入去,覺得唔錯就先 star 為快。結果收藏夾越嚟越長,但對 AI 賽道嘅認知依然好碎片化。
借鑑 BuilderPulse:建立你嘅「信號雷達」
BuilderPulse 嘅啟發唔係佢推薦咗啲乜,而係佢點樣做「信號壓縮」。我將呢套邏輯遷移到 GitHub,整咗套 GitHub Trend Scout 工作流。
唔好追住資訊跑,要建立自己嘅發現機制。
我將判斷標準收斂成三個維度:近期活躍度(最近有無 push)、關鍵詞相關性(精準鎖定 Agent/RAG 等)、以及爆發勢頭(新創建但增長快)。
Hermes 實操:將 Repo 轉化為結構化情報
喺 Hermes 入面,我將呢件事拆解成四個自動化模塊,確保輸出嘅內容係「可消費」嘅情報而唔係一堆連結。
1. Scan: 掃描 7 天內活躍項目,對「近期變化」保持敏感。
2. Classify: 強制單一賽道分類(如 Coding Agent, Infra),增加可讀性。
3. Brief: 補全使用場景(適合邊個用、解決乜問題)。
4. Track: 寫入狀態文件,對比歷史快照,睇邊啲係新增,邊啲係持續增長。深度洞察:從項目入面睇到「二級機會」
跑咗一段時間之後,我發現最值錢嘅唔係發現咗邊個大項目,而係睇到生態層嘅長出。例如 Hermes 相關項目,最火嘅唔係主體,而係 WebUI 同治理控制層。

先關注後閲讀,嬌姐怕失去上進的你
文末嬌姐整理openclaw或者hermes所有文章連結
想了解嬌姐點擊文末連結
如果你也經常刷 GitHub 看 AI 項目,大概率會有一種熟悉的感覺:
每天都有新東西,天天都像在漲潮。
今天是 agent,明天是 RAG,後天又是 workflow、MCP、multi-agent。你以為自己看了很多,其實最後留下來的,常常只是一個越來越長的 star 列表。
我自己很長一段時間也是這樣。
看到新項目,先點進去; 覺得還不錯,先 star; 過幾天再看,又是一批新 repo;
最後的問題不是“我沒看過”,而是——我並沒有真正形成一套穩定的項目發現機制。
後來,我看到劉小排做的 BuilderPulse,整件事一下子有了新的抓手。
github :https://github.com/BuilderPulse/BuilderPulse
BuilderPulse 在 README 裏把自己定義得很直接:
它是一份 daily opportunity brief for indie hackers,每天給出一個值得做的 build idea,並說明它為什麼是現在。更關鍵的是,這個結論不是隨手拍出來的,而是來自 300+ live public signals 的交叉驗證,覆蓋 Hacker News、GitHub Trending、Product Hunt、HuggingFace、Google Trends、Reddit 等公開來源。
我真正被它擊中的地方,不是“它今天推薦了什麼”,而是它背後的工作方式:
不要靠刷信息流找方向,而要靠公開信號,持續構建自己的發現機制。
這個思路對我特別有啓發。
因為我長期關注 GitHub 上的 AI 開源項目,我真正缺的從來不是“項目不夠多”,而是下面這些能力:
更早發現正在升温的 AI repo 更快判斷一個項目屬於哪個賽道 更清楚知道它適合什麼場景、什麼人 更重要的是,能從項目裏看出機會,而不是隻看到一個連結和 star 數
於是我開始做一件事:
把 BuilderPulse 的方法,遷移到 GitHub AI 項目發現這件事上。
最後,我在 Hermes 裏做出了一套專門用來掃描、分類、追蹤、判斷 AI 開源項目的工作流。
我給它起名叫:
GitHub Trend Scout
這篇文章,我就把這個過程完整寫出來。
不是講概念,也不是講“我做了一個腳本”,而是把我怎麼從 BuilderPulse 得到啓發、怎麼落到 GitHub 項目發現、最後實際發現了哪些 AI 項目,完整講透。

一、我後來發現,問題從來不是“信息太少”,而是“沒有發現系統”
很多人看 GitHub,方式其實很像刷內容流:
看 Trending 搜幾個關鍵詞 在 X 上看到有人轉發就點進去 覺得不錯先 star 了再說
這種方式當然不是沒用,但它有一個很明顯的問題:
你永遠是被動的。
你今天看到什麼,取決於平台給你什麼、別人轉發什麼、算法推什麼。
這就意味着,你看到的未必是最值得看的,你記住的也未必是最重要的。
尤其在 AI 開源項目這個領域,噪音特別大:
老項目因為歷史 star 多,長期霸佔注意力 新項目即使很有潛力,剛冒頭時也很容易被忽略
很多 repo 的 description 非常短,看完還是不知道它到底值不值得繼續看
同一個方向會不斷出現變種項目,不做歸類很快就會看亂
所以我後來慢慢意識到,自己真正要解決的問題不是“再多刷幾個項目”,而是:
怎麼搭一套能持續發現值得看項目的機制。
這就是我後來最認同 BuilderPulse 的地方。
它給我的啓發不是“怎麼做日報”,而是:
與其追着信息跑,不如建立自己的信號雷達。
二、BuilderPulse 最值得借鑑的,不是某一條推薦,而是它的“信號思維”
我認真看了 BuilderPulse 的公開說明,它最打動我的,不是它每天那條 build idea 本身,而是它背後那種很剋制的結構:
從大量公開信號中找線索 做交叉驗證,而不是隻看單一熱度 最後收斂成一個清楚結論
並且明確回答一句很關鍵的話:為什麼是現在
這四件事,我覺得非常重要。
1. 它不是做信息堆疊,而是在做信號壓縮
很多內容產品的問題,是信息越來越多,判斷越來越少。
BuilderPulse 正好反過來:它不是給你一堆“最近很熱的東西”,而是替你從很多信號裏壓出一個更值得行動的方向。
這個思路直接影響了我後來做 GitHub Trend Scout 的方式。
我不再追求一次掃出 100 個項目,而是更關心:
哪幾個項目更值得優先看 它們為什麼會冒出來 這些變化反映了什麼方向
也就是說,我想要的不是“更多 repo”,而是“更有效的信號壓縮”。
2. 它強調“Why now”,而不只是“這是什麼”
BuilderPulse 的一個核心表達是:
Why now
這一點我特別認同。
因為“值不值得看”和“現在值不值得看”是兩件不同的事。
GitHub 上一直都有很多好項目,但不是每個好項目都處在值得重點關注的窗口期。
所以後來我把這個思路遷移到了 GitHub 項目發現裏。
我不只看一個項目做什麼,還會多看幾層:
它是不是最近還在活躍更新 它是不是最近一段時間才開始冒頭 它是不是踩在一個更大的方向變化上 它是不是開始帶出配套項目、周邊項目、生態項目
你會發現,這其實就是把 BuilderPulse 的 “Why now”,翻譯成了:
這個 GitHub repo 為什麼值得我現在關注。
3. 它依賴公開信號,而不是憑感覺選題
BuilderPulse 很強調自己的信號來源是公開的,而且是可以交叉驗證的。
這一點對我也很重要。
因為如果你想把“發現值得看的項目”做成方法,而不是一時的直覺,那麼最好建立在一些可重複、可驗證的東西上。
所以我後來在 GitHub Trend Scout 裏,也儘量把邊界收得很清楚:
主要看 GitHub 內部信號
主要用 GitHub Search API
不接外部榜單 不把判斷建立在傳聞和碎片化討論上 儘量讓每一次掃描都能重複執行
這會讓整套方法更穩,也更適合沉澱成 Hermes 的中文實操文檔。
4. 它真正厲害的地方,不是“今天給出一個答案”,而是“每天都能持續給出答案”
這是我覺得 BuilderPulse 最值得學的地方。
很多人看到它,會被每天那條 build idea 吸引。
但我覺得更重要的是:它把“發現機會”這件事,做成了一套持續運行的機制。
這給我的啓發非常直接。
因為我想要的也不是某一天運氣好發現一個好項目,
而是長期來看,我都能穩定地發現:
新冒頭的 AI repo 正在升温的細分方向 看起來不起眼但很可能會繼續長的配套層 從項目裏延伸出來的實際機會
這才是我後來做 GitHub Trend Scout 的真正起點。
三、我怎麼把 BuilderPulse 的思路,遷移成 GitHub Trend Scout
如果用一句話概括,我做的事情其實就是:
把“機會發現”拆成一套可執行的 GitHub 項目發現流程。
具體來說,我把它拆成了下面幾步:
掃描:先找近期活躍且相關的 repo
篩選:降低噪音,保留更值得看的項目
分類:給每個項目一個主賽道
補全:推斷適合場景和用戶
追蹤:保留歷史快照,觀察變化
判斷:從項目本身延伸出機會層
這幾個動作聽起來簡單,但背後的認知變化其實很重要。
1. 從“搜項目”變成“掃信號”
最早很多人找 GitHub 項目,會直接問:
最近有什麼熱門 AI 項目?
最近有什麼值得 star 的 repo?
最近有沒有新的 agent 項目?
後來我越來越少這麼問了。
我會改成:
最近哪些 AI repo 正在升温?
哪些雖然星數還不高,但已經有明顯信號?
哪些方向不是隻出一個項目,而是開始出現一組項目?
這個變化的意義在於:
你看的不再只是“列表”,而是“變化”。
一旦你開始看變化,GitHub 就不再是收藏夾,而會慢慢變成一個趨勢雷達。
2. 從“看 star 總量”變成“看近期活躍 + 關鍵詞相關 + 爆發勢頭”
這是我後來最穩定的一套判斷方式。
因為我很早就發現,只看 star 總量,其實很容易被“歷史慣性”帶偏。
一個去年就很火的項目,今天 stars 還是很多,但不代表它今天依然是最值得重點看的對象。
所以我後來把判斷標準,儘量收斂成三個維度:
第一,近期活躍
如果一個 repo 最近還在持續 push,說明它還在發展,不只是歷史成績。
第二,關鍵詞相關
我不會泛泛地搜“AI”,而是用更收斂的關鍵詞池,比如:
AI agent coding agent RAG AI workflow open-source LLM
因為關鍵詞本身,會決定你能看到哪個世界。
第三,爆發勢頭
有些項目 stars 不高,但因為創建時間新、最近活躍、描述貼近當下需求,反而值得優先關注。
這套判斷標準,本質上就是把 BuilderPulse 的“Why now”落到了 GitHub repo 上。
3. 從“項目列表”變成“結構化情報”
我後來越來越確定一件事:
只給項目連結,其實用處不大。
因為多數人看完 repo 後,還是會接着問:
它到底屬於什麼賽道?
它更適合誰?
它到底能解決什麼問題?
它為什麼值得我現在看?
所以我在 GitHub Trend Scout 裏,不滿足於只掃出 repo,而是繼續要求自己補兩層信息:
一層是主賽道分類
我現在固定只用 8 個主賽道:
coding agent AI agent RAG AI workflow open-source LLM multimodal AI infra AI tools
而且一個項目只給一個主賽道。
這樣雖然不追求“標籤越多越好”,但可讀性會高很多。
一層是場景和用戶補全
GitHub 上很多項目 description 很短,不補這一層,輸出就很難直接拿來用。
所以我會結合:
description topics 語言棧 項目命名方式
繼續推斷:
它適合什麼使用場景 它更適合哪類人關注 它更像能力底座、工具層、控制層,還是產品化外殼
這樣處理之後,項目才會從一個 repo 變成一條可以消費的信息。
4. 從“一次搜索”變成“持續追蹤”
這一步是整套方法真正成型的關鍵。
如果每次只是搜一遍、看一眼、關掉網頁,那你得到的永遠只是“此刻的列表”。
但如果你把每次掃描結果保存下來,事情就完全不一樣了。
你開始能回答這些問題:
哪些項目是這次第一次出現的?
哪些項目連續幾次都出現了?
哪些項目雖然 star 不高,但一直在增長?
哪些方向開始從“一個項目”變成“一組項目”?
這一步做完之後,GitHub 才真正從“查項目的地方”,變成“看趨勢的地方”。
這也是 BuilderPulse 對我影響最大的一點:
它讓我意識到,真正有價值的不是一次命中,而是持續積累後的方向感。
5. 從“發現項目”升級成“發現機會”
這是整個遷移裏最重要的一層。
如果只是發現項目,那你做得再勤奮,也可能只是一個高效收藏者。
但如果你能從項目裏繼續看到:
它反映了什麼需求 為什麼這個需求開始變強 這個方向是不是已經開始長出配套層 哪一層最可能形成產品機會
那你就不再只是“看開源”,而是在“看機會”。
這正是我最認同 BuilderPulse 的地方,也是我後來最想保留的部分。
四、我在 Hermes 裏,把這件事變成了一個真正能跑的工作流
我最後沒有把這件事做成一堆鬆散動作,而是在 Hermes 裏,把它收斂成了幾個固定模塊。
這樣做的目的很簡單:
讓“發現 AI 開源項目”從一個隨緣動作,變成一個可以重複跑、可以累積判斷的工作流。

1. scan:掃描近期值得看的項目
這是整個流程的入口。
我會用一個關鍵詞、一個時間窗、一個結果上限,去掃描 GitHub Search API。
目前這套流程裏,我用得比較多的默認值是:
默認關鍵詞:AI agent
默認時間窗:7 天
默認返回量:8 個
默認輸出語言:中文
為什麼是 7 天?
因為它對“近期變化”足夠敏感,但又不會短到只剩日常波動。
如果當前環境沒有配置 GITHUB_TOKEN,我也會讓流程自動降級,比如:
limit 上限降到 5 fetch 數量做限制
這樣至少可以保證流程繼續跑,不至於因為限流直接失效。
2. classify:給每個項目一個主賽道
很多 AI 項目其實橫跨多個方向。
比如一個項目可能既是 agent,又帶 workflow,還沾點 RAG。
但我後來發現,如果你把標籤打得太寬,反而會讓輸出變得發散。
所以我乾脆強制每個項目只給一個主賽道。
這樣做最大的好處是:
泛讀者看起來更清楚,
而我自己在後續做聚類判斷時,也更容易看到賽道變化。
說白了,這一步不是為了做“學術上最嚴謹的分類”,而是為了讓結果更能消費。
3. brief:補上“適合什麼場景”和“適合誰”
這是我覺得 AI 最能發揮價值的一步。
GitHub 上很多項目寫得很工程化,
description 短,topics 也不全。
如果你只把這些原樣轉給別人,大概率別人還是不會知道它到底值不值得花時間。
所以我後來在輸出項目簡報時,至少會補兩類信息:
使用場景
比如:
適合做團隊的 AI 工作台 適合整合多個消息入口 適合做本地私有化 agent 管理 適合文檔問答、文檔抽取、知識增強 適合用戶
比如:
Python 後端開發者 做 AI 產品的團隊 需要多 agent 協作的工程師 想把 agent 從終端工具變成產品的人
這一步做完,項目才真正從“代碼倉庫”變成“可以被理解、被比較、被判斷的對象”。
4. track:追蹤變化,而不是重複搜索
我後來越來越覺得,單次掃描的價值,其實有限。
真正更有價值的,是連續幾次跑下來之後,你能看出什麼變化。
所以我在 Hermes 裏會把掃描結果寫進狀態文件,保留歷史快照。
下一次再跑時,我不只是重掃一遍,而是去比較:
哪些是新增項目 哪些項目在漲 哪些方向開始密集出現 哪些可能只是瞬時噪音
這一步一旦做起來,整套系統就會從“搜項目工具”變成“趨勢工作流”。
5. correct:允許人工修正,讓系統越用越準
再好的自動分類,也一定會有偏差。
尤其是新項目很多 description 很短,topics 也不完整,光靠自動規則很容易誤判。
所以我專門保留了人工修正機制。
如果某個 repo 分類不準,我就把修正結果寫進 categoryOverrides,讓後續判斷持續生效。
這個設計很小,但我自己很喜歡。
因為它體現的是一種很實際的思路:
不是要求系統第一次就永遠正確,而是讓系統可以在使用中不斷變準。
五、這套方法真正帶給我的,不是發現更多,而是判斷更快了
跑了一段時間之後,我最大的感受其實不是“我發現了更多 repo”,而是:
我對項目的判斷速度明顯變快了。
這種變化體現在幾個地方。
1. 我不再那麼容易被 star 總量帶偏
以前很容易看到一個大項目就覺得“這肯定值得看”。
現在我會先問:
它為什麼這周值得看?
它只是歷史很強,還是現在還在釋放新信號?
這個區別很重要。
2. 我更容易看到“二級機會”
比如在 Hermes 相關項目裏,真正更有產品空間的,未必是“再做一個 agent”,而往往是:
WebUI Dashboard Governance Control plane Team ops 審批和審計層
如果只盯着主項目本體,很容易錯過這些更接近產品機會的層。
3. 我開始更自然地從項目裏看賽道變化
以前看項目,是一個個看。
現在更像是在看“羣”。
如果同一類項目開始同時出現,那往往比單個項目本身更重要。
因為那說明一個方向可能正在形成真正的需求層。
4. GitHub 對我來說不再只是收藏夾,而更像一個趨勢雷達
這是最本質的變化。
以前是“先 star 再說”;
現在是“先判斷它在 signal 裏代表什麼”。
這種心態一變,整個工作方式都會變。
六、用真實掃描結果舉幾個例子:這套方法到底能發現什麼
案例一:Hermes 相關項目,最明顯的信號不是“主項目還在火”,而是“生態層正在長出來”
我前面掃 Hermes 相關關鍵詞時,比較值得看的幾個項目包括:
1)NousResearch/hermes-agent
項目地址:GitHub - NousResearch/hermes-agent: The agent that grows with you
賽道:AI agent
Stars:108.1k
語言:Python
這個項目已經不只是一個“值得 star 的 agent 項目”,而更像 Hermes 生態的底座。
它本身當然值得看,但更重要的是,它會帶出什麼新的外圍層。
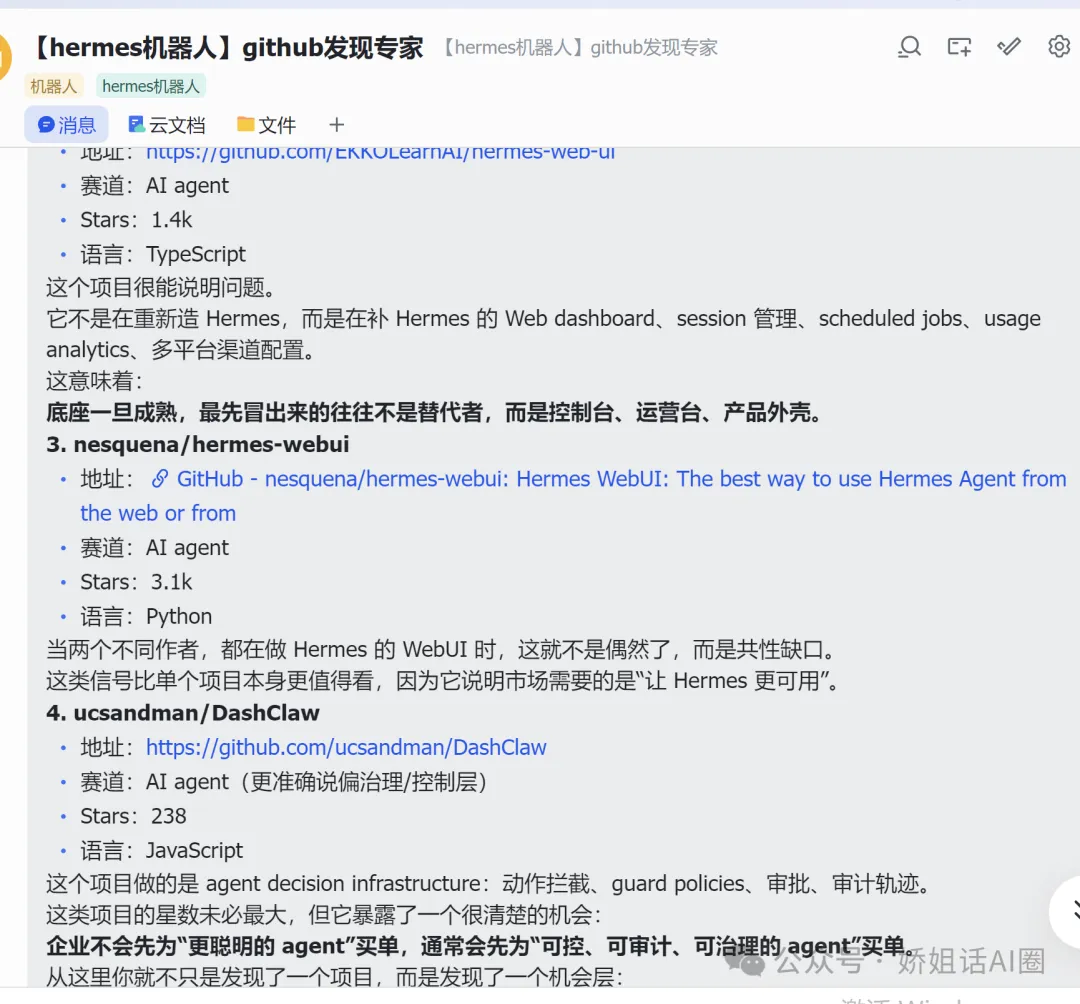
2)EKKOLearnAI/hermes-web-ui
項目地址:https://github.com/EKKOLearnAI/hermes-web-ui
賽道:AI agent
Stars:1.4k
語言:TypeScript
這個項目不是在重造 Hermes 本體,而是在補它的 Web dashboard、session 管理、scheduled jobs、usage analytics、多平台渠道配置。
這個信號很關鍵。
因為它說明,一旦底座成熟,最先冒出來的往往不是替代者,而是:
控制枱 可視化入口 管理台 運營層
3)nesquena/hermes-webui
項目地址:GitHub - nesquena/hermes-webui: Hermes WebUI: The best way to use Hermes Agent from the web or from
賽道:AI agent
Stars:3.1k
語言:Python
當兩個不同作者都在做 Hermes 的 WebUI,這就不是偶然了,而是一個很清楚的共性缺口:
大家不是不想用 Hermes,而是需要一個更好用的入口。
4)ucsandman/DashClaw
項目地址:https://github.com/ucsandman/DashClaw
賽道:AI agent(更準確說偏治理/控制層)
Stars:238
語言:JavaScript
這個項目做的是 agent 的決策基礎設施,包括:
動作攔截 審批要求 guard policies 審計軌跡
它的 stars 不算最多,但它代表的機會非常清楚:
企業不會先為“更聰明的 agent”付費,往往會先為“可控、可審計、可治理的 agent”付費。
這就是為什麼我說,這套方法最後想發現的,不只是項目,而是機會層。
5)awizemann/scarf
項目地址:GitHub - awizemann/scarf: Native macOS GUI for the Hermes AI agent — multi-window, multi-server (loc
賽道:AI agent
Stars:199
語言:Swift
這是一個 Hermes 的 macOS GUI。
它指向的不是“底座創新”,而是“高頻工作台入口”。
這也很有代表性:
當一個生態開始往桌面端、GUI 端走的時候,說明它正在從“開發者工具”往“日常工作系統”靠近。
案例二:掃 AI agent 關鍵詞時,我最在意的不是“火不火”,而是“這是不是一個正在長的新需求”
我最近實際掃 AI agent 時,前幾個結果包括:
1)microsoft/aitour26-WRK542-prototype-agents-with-Foundry-toolkit-and-model-context-protocol
項目地址:https://github.com/microsoft/aitour26-WRK542-prototype-agents-with-Foundry-toolkit-and-model-context-protocol
Stars:48
語言:Python
這個項目不是那種一眼就特別“爆”的項目,但因為:
最近仍在活躍 和 agent / MCP 高度相關 背後是大廠技術棧組合
所以它值得進入觀察清單。
這類項目的重要性,很多時候不在“馬上會不會火”,而在於它透露了誰在用什麼組合。
2)Broomy-AI/broomy
項目地址:GitHub - Broomy-AI/broomy: Tool for making it easy to work with lots of AI agents
Stars:44
語言:TypeScript
描述:Tool for making it easy to work with lots of AI agents
這個項目非常典型。
它不是在做“一個更強的 agent”,而是在處理“agent 變多之後,怎麼管理多個 agent”這個問題。
也就是說,它反映的是一個二級需求:
主體需求出現以後 配套管理需求開始變強
這類信號我會特別重視,因為它往往意味着新一層產品空間開始出現了。
3)dvhma1994/openclaw-swarm
項目地址:GitHub - dvhma1994/openclaw-swarm: 🦀 Multi-Agent AI System - 100% Local with Ollama
Stars:1
語言:Python
描述:Multi-Agent AI System - 100% Local with Ollama
它 stars 很低,但也不是完全沒有意義。
這類項目的價值在於,它說明“本地化 + 多 agent + Ollama”這個組合,依然有人在繼續探索。
這並不一定意味着它馬上會火,但它至少說明:
本地私有化、多 agent、自主運行,還是持續存在的需求。
當然,這一組結果裏也有不少噪音。
這也是為什麼我越來越確信:
掃描不是為了自動相信結果,而是為了更快做第一輪判斷。
案例三:掃 RAG 時,我更看重它貼不貼近真實應用場景
我最近掃 RAG 時,結果裏既有已有規模的項目,也有很新的小項目。
1)cactus-compute/cactus
項目地址:GitHub - cactus-compute/cactus: Low-latency AI engine for mobile devices & wearables
Stars:4.7k
語言:C
描述:Low-latency AI engine for mobile devices & wearables
它被命中到 RAG 關鍵詞結果裏,但更準確地看,其實它偏 edge AI / on-device inference。
這個例子剛好說明:
關鍵詞命中,並不等於語義完全準確。
所以哪怕有了自動化流程,人的二次判斷依然非常重要。
否則你會把很多“相關但不夠對”的項目,誤當成重點。
2)MSam-data/PDF_Oracle_Agent
項目地址:https://github.com/MSam-data/PDF_Oracle_Agent
Stars:0
語言:HTML
描述裏明確提到了 Python、Gemini 2.0、PDF、RAG、文檔自動化
這個項目雖然 stars 為 0,但它依然有觀察價值。
因為它對應的不是一個抽象概念,而是非常真實的應用場景:
PDF 問答 非結構化文檔處理 文檔抽取 知識增強
這類項目未必最終會成長成大項目,但它們很能反映真實需求從哪裏開始出現。
所以我現在看這類項目,不會只問“它火不火”,我還會問:
它是不是貼近真實問題?
它是不是一類長期存在的需求入口?
值不值得繼續盯着同類項目一起看?
關於openclaw/hermes資料包和系列文章
配套資料包
私信 kekohu 獲取,內容不定期持續更新。
注意:付費社羣包含資料包全部內容,無需重複購買。
hermes系列文章
持續更新,建議每篇認真閲讀
【不推薦用官方命令】Windows 環境下安裝Hermes及遷移Openclaw的實操分享
【Hermes整理】OpenClaw 變現項目地圖:6 大賽道
我把 OpenClaw 的 Agent 無縫遷移到了 Hermes——就靠這一份 Skill
借鑑 Hermes 優化 OpenClaw:讓你的 AI 學會記、會覆盤、會巡檢
openclaw系列文章
openclaw系列文章
持續更新,建議每篇認真閲讀
配置與理解
別被騙,OpenClaw 可以 24 小時幹活——但你得先做對這 6 件事
火了三個月的"龍蝦",普通人裝了真的有用嗎?
用 OpenClaw 把 AI 失憶治好:開關、精簡、外掛三步走
多 Agent 與協作
技能與工具
實戰與案例
排錯與安全
關於嬌姐
40+ IT 從業者,前榮耀員工,現專注 AI 效率工具研究與實踐。持續輸出 OpenClaw 及 AI 工具的乾貨教程與落地案例,偶爾分享職場思考與生活感悟。
提示:覺得有用,點贊、關注、轉發,是我持續創作的動力。