免費、本地、語音克隆、CPU 可跑、三語支持——這個開源 TTS 項目值得收藏
整理版優先睇
MOSS-TTS-Nano係一個免費、本地可跑、支援語音克隆嘅輕量TTS系統,中英日語三語通吃。
呢篇文章由OpenMOSS Team嘅開發者撰寫,介紹佢哋開源嘅MOSS-TTS-Nano項目。作者注意到市面上嘅語音合成方案有兩極分化:一邊係雲端TTS API(好似Azure、訊飛),音質好但越用越貴,短視頻博主每個月配音開銷幾百上千;另一邊係開源小模型,但多數依賴複雜、只支援單語言、文檔唔齊全。作者想填補中間地帶——一個免費、輕量、本地可跑、支援中英日語、仲開箱即用嘅TTS系統。
MOSS-TTS-Nano就係呢個答案。佢得100M參數,普通CPU就推到;內置16種音色,中英日語男女聲都有;仲有零樣本語音克隆功能,畀3秒參考音頻就可以復刻把聲。整體結論係:呢個項目雖然細,但喺「輕量、免費、本地、可控」呢條線上,係目前做得最均衡嘅一個,適合短視頻配音、AI播客、教育微課、語音助手等場景。
- MOSS-TTS-Nano係免費開源、本地可跑、支援語音克隆嘅輕量TTS,中英日語三語通吃。
- 核心架構係GPT式雙通道生成:文本層同音頻層共享語言模型上下文,自迴歸生成自然語音。
- 提供兩大模式:voice_clone(語音克隆)同continuation(文本續說),支援精細採樣參數調控。
- 內置16種預設音色,另可零樣本克隆任何把聲;雙推理後端(PyTorch同ONNX),CPU就推到。
- 可整合AI Agent(Claude Code、OpenClaw等)做到全自動配音流程,將TTS變成開發工具鏈一部分。
GitHub 倉庫
MOSS-TTS-Nano 原始碼、安裝指南同使用文檔
文檔網站
詳細嘅 API 參考同部署指引
安裝命令
pip install moss-tts-nano
內容結構
PART 01|AI 語音合成:大而全 vs 小而美PART 02|一探究竟:MOSS-TTS-Nano 是什麼PART 03|核心架構:GPT 式雙通道生成PART 04|兩大模式:語音克隆與文本續說PART 05|16 種內置音色,中英日語全覆蓋PART 06|兩套推理後端:PyTorch 與 ONNX 雙引擎PART 07|快速上手:5 分鐘跑通 TTSPART 08|實戰管線 + AI Agent 集成:從配音到微課視頻PART 09|哪些場景可以用它?點解需要一個中間地帶嘅 TTS?
如果你有留意AI語音合成領域,會發現一個有趣嘅分化:一邊係「大而全」——雲端TTS API(如Azure Speech、訊飛),音質頂尖、音色豐富,但月月俾錢,越用越貴;另一邊係「小而美」——開源社區嘅小模型TTS,免費、本地可跑,但你會發現大部分項目依賴複雜、只支援單語言、文檔唔齊全。
兩個方向之間,一直缺一個中間地帶:免費嘅、輕量嘅、本地可跑嘅、同時支援中英日語、仲要開箱即用——呢個要求不過分。
MOSS-TTS-Nano就係填補呢個空白嘅項目,由OpenMOSS Team開源。
MOSS-TTS-Nano 核心定位
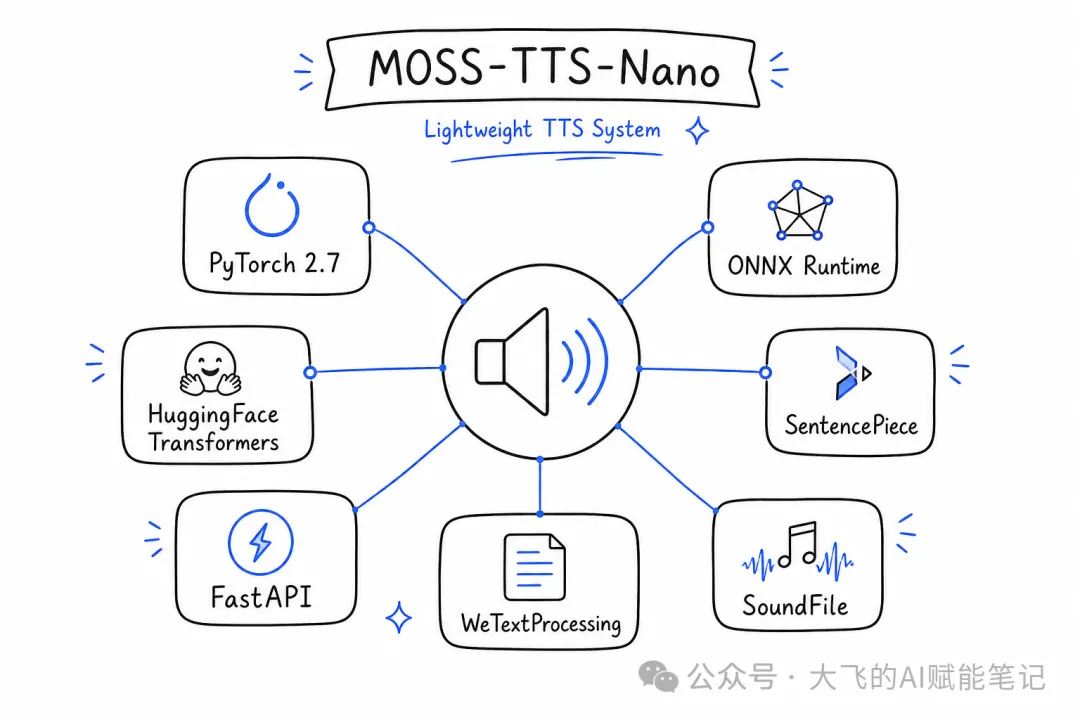
MOSS-TTS-Nano係一個實時多語言輕量TTS系統,核心數字好清晰:100M參數、中英日語三語、16種預設音色、零樣本語音克隆、雙推理後端。
技術棧好乾淨:PyTorch / ONNX Runtime做推理引擎,HuggingFace Transformers加載模型,SentencePiece分詞,FastAPI提供Web服務。
- 100M參數——同類模型中極小體量,普通CPU即可推理
- 中英日語三語——一個模型全部覆蓋
- 16種預設音色——中/英/日語男女聲,即開即用
- 零樣本語音克隆——3秒參考音頻即可復刻聲音,無需微調
- 雙推理後端——PyTorch用於研究,ONNX用於生產部署
核心架構:GPT式雙通道生成
MOSS-TTS-Nano將語音生成拆成兩個階段,複用GPT式因果語言模型嘅範式。第一階段:文本編碼——輸入文本通過SentencePiece分詞器編碼為token序列,送入Causal LM自迴歸生成「文本層logits」;第二階段:音頻解碼——文本層輸出送入音頻token預測層,自迴歸生成音頻token,再經MOSS-Audio-Tokenizer-Nano解碼為最終波形。
文本層同音頻層共享同一個語言模型嘅上下文,模型既理解語義又生成聲學特徵。
用一句話理解:佢似GPT寫文章咁,逐token咁「寫」出音頻。
兩大模式 + 精細控制
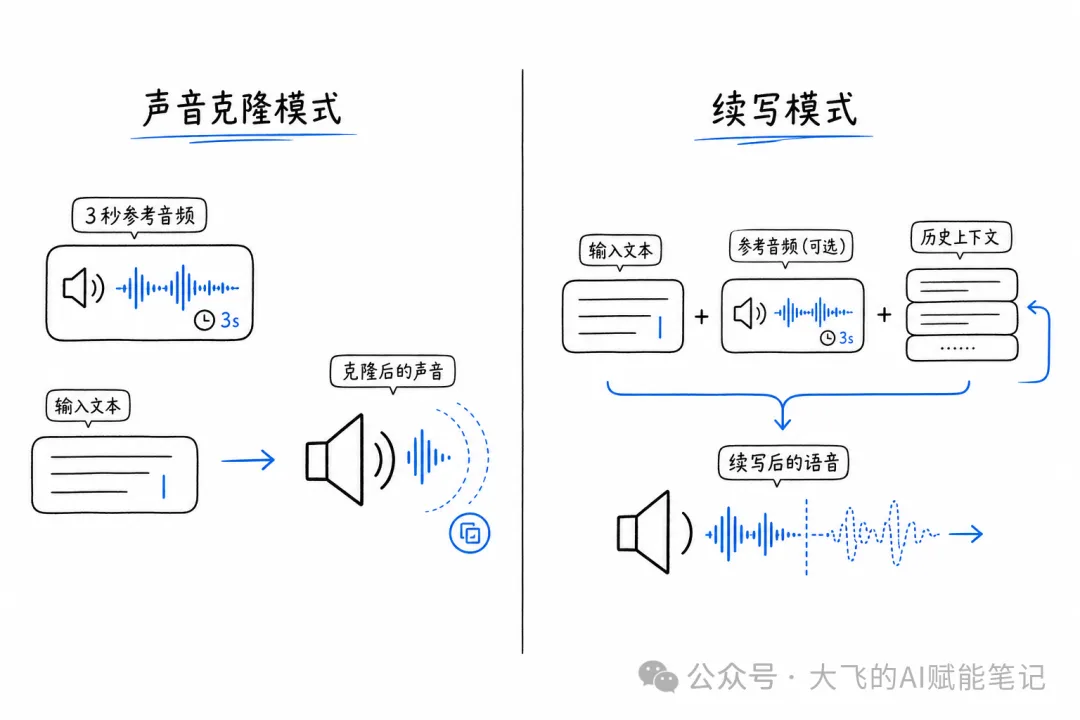
模式一:voice_clone(語音克隆)——最核心功能,3秒參考音頻即可零樣本克隆把聲。
模式二:continuation(文本續說)——畀定文本同參考音頻,可以以上文語氣繼續講落去。
- voice_clone模式下有自動分塊機制:--voice-clone-max-text-tokens 75,長文本自動切句分批生成再合併
- 採樣參數全開放:text-temperature、audio-temperature、audio-top-p、audio-top-k、audio-repetition-penalty,畀你精細調控
- 想穩定就壓低temperature同top-p,想多樣性就調高
實戰管線:從配音到AI Agent集成
作者用一個真實案例展示咗點樣將MOSS-TTS-Nano融入自動化管線:將一篇18個場景嘅文案,逐段用ONNX後端批量生成WAV配音,再用Playwright截圖HTML動畫、FFmpeg合成視頻。
一條命令:文案 → 配音 → 視頻,全自動。
仲可以將MOSS-TTS-Nano註冊為AI Agent嘅Tool,例如Claude Code入面設定一個tool叫moss-tts,之後講句「幫我生成配音」Agent就會自動調用。
- 1 Claude Code:直接執行Shell命令,或將CLI註冊為Tool
- 2 OpenClaw / Hermes:封裝為Function Tool,Agent自主調用
- 3 QClaw / WorkBuddy:嵌入DAG流水線,實現每日自動文章→配音→視頻→發佈
呢種就係「TTS-as-a-Function」——唔再係手動㩒掣,而係讓AI Agent替你行。
點解揀佢唔揀其他?
市面上唔缺TTS項目,但MOSS-TTS-Nano嘅組合拳係獨特嘅。同雲端TTS API比,佢免費、本地可跑;同其他開源TTS比,佢原生支援多語言、零樣本語音克隆、AI Agent集成。
佢嘅目標唔係取代Azure或訊飛——喺大規模生產級場景下,雲端方案依然係王者。
但喺「輕量、免費、本地、可控」呢條線上,MOSS-TTS-Nano係目前做得最均衡嘅一個。
MOSS-TTS-Nano 係一個輕量、免費、本地行到、支援語音複製嘅中英日語TTS,專為解決「好用但唔貴、強大但唔重」嘅語音合成需求而設。呢篇文章會由項目定位、核心架構、功能特性講起,然後帶你5分鐘上手實戰,最後深入實戰管線同AI Agent整合——由淺入深,一次過講曬。
📖 本文目錄
PART 01|AI 語音合成:大而全 vs 小而美
PART 02|一探究竟:MOSS-TTS-Nano 是什麼
PART 03|核心架構:GPT 式雙通道生成
PART 04|兩大模式:語音克隆與文本續說
PART 05|16 種內置音色,中英日語全覆蓋
PART 06|兩套推理後端:PyTorch 與 ONNX 雙引擎
PART 07|快速上手:5 分鐘跑通 TTS
PART 08|實戰管線 + AI Agent 集成:從配音到微課視頻
PART 09|哪些場景可以用它?如果你留意過AI語音合成領域,會發現一個有趣嘅分化:
一邊係「大而全」——雲端TTS API(例如Azure Speech、訊飛、火山引擎),音質頂尖、音色豐富,但係按月俾錢,越用越貴。做短片嘅博主,每個月光係配音開支就幾百上千;做自動化管線嘅團隊,每千字幾毫子嘅成本,量一多就變成真金白銀嘅負擔。
另一邊係「細而靚」——開源社羣嘅細模型TTS,免費、本地行到,但你翻勻GitHub就會發現幾個尷尬嘅現實:
• 大部份項目依賴複雜,環境要搞半日,一跑顯卡就勁叫 • 一係淨係支援英文,一係淨係支援中文,想雙語就要裝兩套模型 • 所謂「coming soon」嘅功能一拖就係一年 • 文件能慳就慳,API設計隨心所欲
呢兩個方向之間,一直都缺一個中間地帶:
免費、輕量、本地行到、同時支援中英日語、仲要開箱即用——呢個要求過分咩?
唔過分。MOSS-TTS-Nano就喺呢個位置。
PART 02|一探究竟:MOSS-TTS-Nano係咩嘢
MOSS-TTS-Nano係 OpenMOSS Team 開源嘅一個實時多語言輕量TTS系統,核心就幾個數字:
• 100M參數——同類模型中超細體積,普通CPU已經可以推理 • 中英日語三語——一個模型全部覆蓋 • 16種預設音色——中/英/日三語男女聲,即開即用 • 零樣本語音複製——3秒參考音頻就可以複製聲音,唔使微調 • 雙推理後端——PyTorch用嚟研究同實驗,ONNX用嚟生產部署
技術棧都好乾淨:
所有依賴加埋,一個 requirements.txt 就列曬。冇大而全嘅框架捆綁,冇收收埋埋嘅私有依賴。
呢個正正係佢同好多TTS項目嘅本質分別:唔係為咗出論文,而係為咗開發者真係用到。
PART 03|核心架構:GPT式雙通道生成
MOSS-TTS-Nano嘅架構思路好得意:佢將語音生成拆成兩個階段,重用咗GPT式因果語言模型嘅範式。
第一階段:文本編碼
輸入文本經SentencePiece分詞器編碼做token序列。呢啲token被送入一個因果語言模型(Causal LM),自迴歸噉生成「文本層logits」,從中採樣得到下一層需要嘅條件信號。
第二階段:音頻解碼
文本層嘅輸出被送入音頻token預測層,同樣自迴歸噉生成音頻token。呢啲token再經 MOSS-Audio-Tokenizer-Nano——一個專門嘅神經音頻編解碼器——解碼做最終波形。
輸入文本 → 文本分詞 → [Causal LM 文本層] → 文本 token
↓
[Causal LM 音頻層] → 音頻 token
↓
MOSS-Audio-Tokenizer-Nano
↓
波形輸出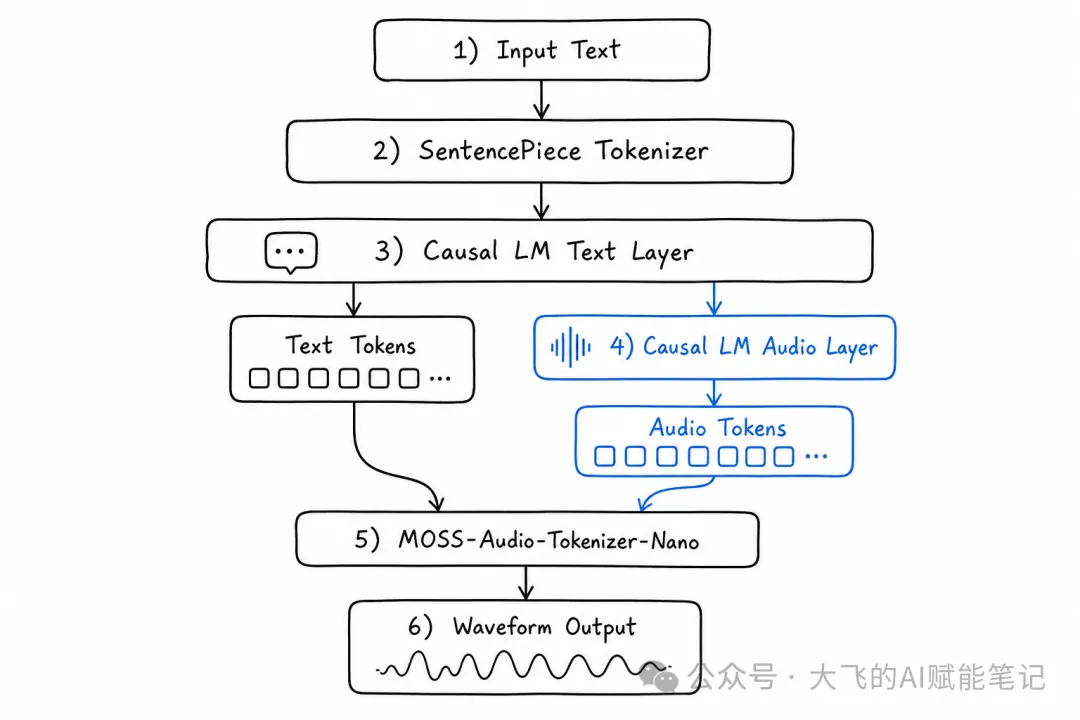
呢個設計嘅巧妙之處在於:
• 文本層同音頻層共享同一個語言模型嘅上下文,模型既理解語義又生成聲學特徵 • 自迴歸採樣保證咗生成嘅自然度同連貫性 • Audio Tokenizer可替換,意味住後面嘅音質仲有優化空間
訓練階段,模型喺大量(文本,音頻)配對嘅語料上學習;推理時,俾定文本同一段參考音頻(語音複製模式),模型就可以生成同參考音色一致、語義準確嘅語音。
用一句話理解:佢好似GPT寫文章噉,逐個token噉「寫」出音頻。
PART 04|兩大模式:語音複製同文本續說
MOSS-TTS-Nano提供兩種推理模式,覆蓋曬大部份實際使用場景。
模式一:voice_clone(語音複製)
呢個係最核心嘅功能。你只要一段參考音頻(3-5秒就得),加上目標文本,模型就可以零樣本複製呢個聲音。
moss-tts-nano generate \
--mode voice_clone \
--prompt-audio-path assets/audio/zh_1.wav \
--text "歡迎使用 MOSS-TTS-Nano 語音合成系統" \
--output output.wav實際測試落嚟,3秒參考音頻已經有唔錯嘅複製效果。聲音嘅語調、節奏、音色特徵都重現到。
對於長文本,佢內置咗自動分塊機制:
--voice-clone-max-text-tokens 75當文本token長度超過門檻時,模型會按語義自動切句分批生成,再無縫合併。你俾佢3000字嘅長文案,佢自己會搞掂分段同拼接。
背後係pocket-tts風格嘅分句策略:先計最優分割點,逐塊生成,最後拼接成完整音頻。
模式二:continuation(文本續說)
呢個模式似傳統嘅TTS——俾定文本,模型直接生成語音。但如果同時提供 --prompt-text 和 --prompt-audio-path,佢都可以做到「以上文語氣繼續講落去」嘅效果。
moss-tts-nano generate \
--mode continuation \
--prompt-text "大家好,歡迎收看今天的節目" \
--prompt-audio-path reference.wav \
--text "今天我們聊一個有趣的話題" \
--output output.wav採樣參數全開放
兩個模式之下,你可以仔細調控生成效果:
--text-temperature | ||
--audio-temperature | ||
--audio-top-p | ||
--audio-top-k | ||
--audio-repetition-penalty |
想穩定就降低temperature同top-p,想多啲變化就調高佢哋。每個參數都開放俾用戶,俾你最大嘅控制權。
PART 05|16種內置音色,中英日語全部覆蓋
一個模型,三語通用。MOSS-TTS-Nano內置咗 16種預設音色:
默認音色係 Junhao(中文男聲),呢個都係本地項目入面實際用緊嗰個。
所有預設音頻檔案喺 assets/audio/ 目錄下,格式係WAV(部份係MP3)。你可以將自己嘅錄音放落去自訂。
呢個對開發者嚟講意義係乜?
唔使再為每種語言去搞唔同嘅TTS引擎。一個pip包,一個模型,中英日語嘅語音需求全部搞掂。如果客戶要某個特定音色,攞一段參考音頻零樣本複製就得。
PART 06|兩套推理後端:PyTorch同ONNX雙引擎
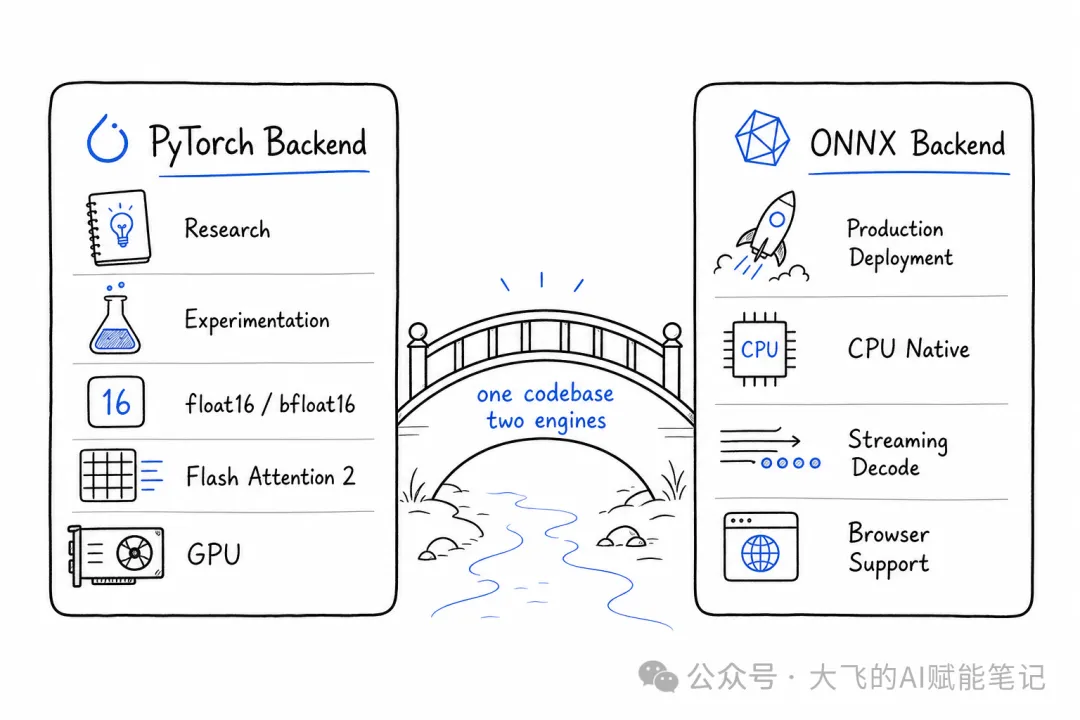
呢個係MOSS-TTS-Nano一個好務實嘅架構設計——一套代碼,兩套推理引擎,按場景切換。
PyTorch後端(研究探索用)
適合開發除錯、實驗調參嘅場景:
• 基於 transformers的AutoModelForCausalLM加載Hugging Face格式checkpoint• 支援 float16/bfloat16精度• 支援Flash Attention 2(CUDA下可用) • 默認模型ID: OpenMOSS-Team/MOSS-TTS-Nano
moss-tts-nano generate --backend pytorch --text "你好" --prompt-audio-path ...ONNX後端(生產部署用)
適合上線部署、資源受限嘅場景:
• 基於 onnxruntime推理,唔依靠PyTorch運行時• CPU原生支援——唔需要用GPU都做到實時推理 • 支援CUDA執行提供程序(需要 onnxruntime-gpu)• 支援流式解碼( --realtime-streaming-decode),邊生成邊輸出,延遲更低• 可配置多種採樣策略: greedy/fixed/full
moss-tts-nano generate --backend onnx --text "你好" --prompt-audio-path ...項目仲提供咗完整嘅ONNX導出腳本(onnx/ 目錄):
• export_hf_to_tts_onnx.py——將HuggingFace checkpoint導出做標準ONNX• export_moss_tts_browser_onnx.py——導出做 瀏覽器兼容ONNX,甚至可以在瀏覽器端運行
本地已經導好嘅模型位於 models/MOSS-TTS-Nano-100M-ONNX/,配合 models/MOSS-Audio-Tokenizer-Nano-ONNX/ 組成完整推理鏈路。
點解ONNX後端咁重要?因為喺生產環境中,你唔可能每部機都裝PyTorch + CUDA。ONNX Runtime嘅部署成本低好多,用CPU就跑到,呢個係MOSS-TTS-Nano從「實驗項目」走向「生產工具」嘅關鍵一步。
PART 07|快速上手:5分鐘跑通TTS
廢話少講,直接上手。
第一步:安裝
pip install moss-tts-nano係㗎,就係一行。佢已經發布咗上PyPI,pip install 就裝好。
如果從原始碼安裝:
git clone https://github.com/OpenMOSS/MOSS-TTS-Nano.git
cd MOSS-TTS-Nano
pip install -e .第二步:CLI一句話生成語音
moss-tts-nano generate \
--mode voice_clone \
--prompt-audio-path assets/audio/zh_1.wav \
--text "你好,歡迎瞭解 MOSS-TTS-Nano" \
--output my_audio.wav第一次運行會自動下載模型(約100M),之後就離線運行。輸出嘅WAV檔案用播放器聽就得。
第三步:Python API整合
如果你將TTS嵌入自己嘅代碼:
from infer import main as tts_infer
result = tts_infer([
"--text", "嵌入你自己的 Python 項目就這麼簡單",
"--prompt-audio-path", "assets/audio/zh_1.wav",
"--mode", "voice_clone",
])
# result["audio_path"] → 生成的 WAV 文件返回嘅dict包含 audio_path、sample_rate、audio_token_ids,攞到路徑直接去下游播放或者編輯。
第四步:啟動Web服務
moss-tts-nano serve --backend onnx --host 0.0.0.0 --port 18083啟動後訪問 http://localhost:18083,會見到FastAPI自動生成嘅互動式API文檔頁面。你亦可以用任何HTTP客戶端呼叫 POST /tts 接口上傳文本同參考音頻,獲取生成嘅語音檔案。
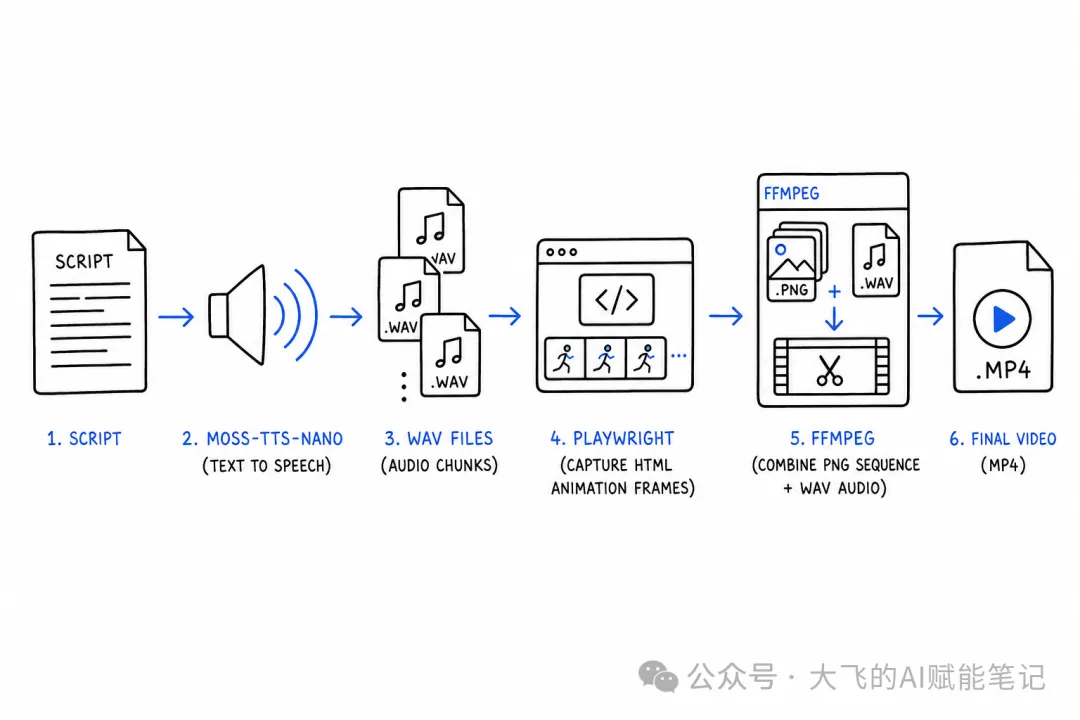
PART 08|實戰管線 + AI Agent整合:從配音到微課視頻
理論講完,嚟睇一個真實管線——呢個就係MOSS-TTS-Nano喺本地項目入面嘅實際用法。
場景:將一篇文案做成有配音嘅微課視頻
需求好簡單:一篇18個場景嘅文案,每個場景一段話,需要配上語音,再合成做視頻。用MOSS-TTS-Nano嚟解決。
批量配音生成
# generate_all_audio.py(核心邏輯)
for scene_text in script_lines:
subprocess.run([
"python", "infer_onnx.py",
"--prompt-audio-path", "assets/audio/zh_1.wav",
"--text", scene_text,
"--output-audio-path", f"scene-{i:02d}.wav",
])18段文案,逐個呼叫ONNX後端生成WAV音頻,自動跳過已有檔案(方便斷點續跑)。生成完成後,每個場景配一個WAV檔案。
視頻合成
# render_video.py(核心邏輯)
# Playwright 截圖 HTML 動畫頁面 → 每秒 10 幀 PNG
# FFmpeg 合成:PNG 序列 → MP4 + 疊加 WAV 音頻
# 最終合併所有場景片段為一個完整視頻具體流程:
1. Playwright打開每個場景嘅GSAP動畫HTML頁面 2. 按時間線逐幀截圖(利用GSAP timeline精確控制動畫進度) 3. FFmpeg將截圖序列合成冇聲音嘅MP4 4. 再疊加MOSS-TTS-Nano生成嘅配音WAV檔案 5. 最後 ffmpeg concat將所有場景片段合併成最終視頻
一條命令:文案 → 配音 → 視頻,全部自動。
AI Agent整合:令語音生成真正「隨叫隨到」
以上仲只係「腳本自動化」。再進一步,你可以將MOSS-TTS-Nano交俾 AI Agent 嚟呼叫,等佢成為Agent工具鏈入面嘅一個節點。
喺Claude Code入面用
Claude Code可以直接執行Shell指令。你只要話俾佢聽:
「幫我將呢段文案生成配音,用MOSS-TTS-Nano,音色用Junhao。」
Claude Code就會自動拼湊出完整嘅CLI指令並執行,唔使你手動打參數。
更優雅嘅方式,係將MOSS-TTS-Nano嘅CLI指令註冊做一個 Tool。喺Claude Code嘅配置入面:
{
"tools": {
"moss-tts": {
"command": "moss-tts-nano generate --mode voice_clone --prompt-audio-path assets/audio/zh_1.wav --text \"${input}\" --output \"${output_path}\""
}
}
}之後你只要講「生成配音」,Claude Code就會自動呼叫呢個工具完成。
喺OpenClaw / Hermes入面整合
如果你用緊OpenClaw或Hermes呢類Agent框架,可以將MOSS-TTS-Nano封裝做一個函數工具(Function Tool):
@tool
def tts_generate(text: str, output_path: str = "output.wav") -> str:
"""調用 MOSS-TTS-Nano 生成語音"""
result = subprocess.run([
"moss-tts-nano", "generate",
"--mode", "voice_clone",
"--prompt-audio-path", "assets/audio/zh_1.wav",
"--text", text,
"--output", output_path,
], capture_output=True, text=True)
return output_path咁樣,Agent就可以喺你嘅工作流程入面自主呼叫TTS,唔再需要人手介入。
喺QClaw / WorkBuddy入面編排流水線
對於更複雜嘅場景——例如「每日自動抓取最新文章 → 生成配音 → 合成視頻 → 發佈」——QClaw或WorkBuddy呢類任務編排工具可以將MOSS-TTS-Nano作為一個節點嵌入DAG流水線:
[文案輸入] → [文本處理] → [MOSS-TTS-Nano] → [視頻合成] → [發佈]
↑
[參考音頻(固定)]成個過程無需人工幹預。Agent負責調度,MOSS-TTS-Nano負責語音生成,FFmpeg負責視頻合成。
呢個就係「TTS即服務(TTS-as-a-Function)」——唔再係手動㩒掣,而係讓AI Agent幫你打點。
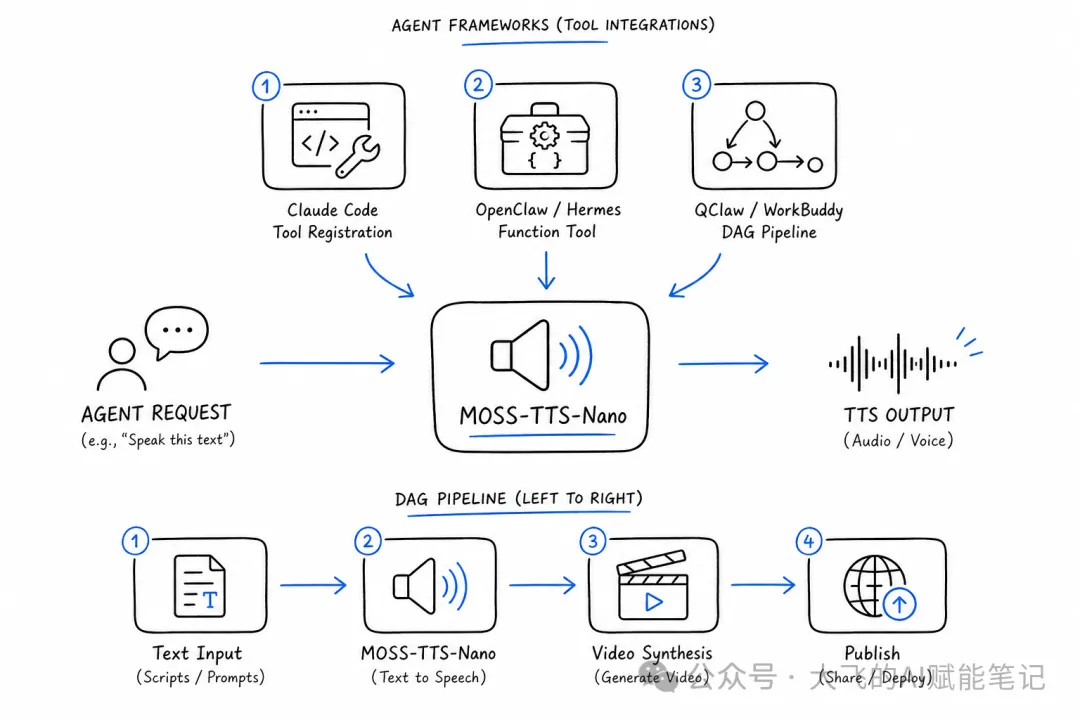
PART 09|邊啲場景可以用佢?
講咗咁多技術細節,最後返到一個實際問題:呢個嘢到底可以用喺邊?
短片 / 自媒體配音
如果你做短片,每個月要出幾十條配音。MOSS-TTS-Nano可以:
• 零成本代替付費TTS(慳返每月嘅API帳單) • 批量生成一期節目嘅全部配音 • 結合AI Agent實現「文案寫完 → 自動配音 → 自動合成」嘅全自動流程
AI Podcast / 音頻內容
將你嘅博客文章轉成Podcast,或者生成有聲書:
博客文章 → MOSS-TTS-Nano → MP3 播客唔需要租伺服器、唔需要買API額度,本地跑完直接上傳。
教育微課 / 培訓視頻
呢個係本地項目已經驗證過嘅場景。一篇課程文案 → 分場景配音 → 合成視頻。對於在線教育平台或企業內部培訓,呢個係一個零成本嘅配音方案。
語音助手 / 嵌入式設備
100M參數意味住佢可以喺樹莓派呢類低功耗設備上運行。嵌入式語音助手、智能家居語音回饋、無障礙輔助工具——呢啲場景對模型大細敏感,MOSS-TTS-Nano啱啱好。
語音複製研究 / 音色定製
如果你做緊語音合成方向嘅研發,MOSS-TTS-Nano提供咗一個好嘅基線:
• 零樣本複製能力令你快速驗證想法 • ONNX導出能力令你將實驗成果部署到實際系統 • 開源令你可以深入原始碼理解實現細節
點解揀佢而唔揀其他?
市面上唔缺TTS項目,但MOSS-TTS-Nano嘅組合拳係獨特嘅:
| 免費 | |||
| 100M | |||
| 原生支援 | |||
| 中英日語 | |||
| 零樣本 | |||
| CLI + API雙通道 |
佢唔係要取代Azure或訊飛——喺大規模生產級TTS場景下,雲端方案依然係王者。但喺「輕量、免費、本地、可控」呢條線上,佢係目前做得最平衡嘅一個。
寫在最後
MOSS-TTS-Nano唔係一個「大」項目——100M參數擺喺今日嘅大模型語境下,連個零頭都唔到。但正正係呢種「細」,令佢有咗獨特嘅價值:
你可以在任何機器上運行佢,唔需要用GPU,唔需要聯網,唔需要付費。想改咩直接改原始碼,想部署到邊就部署到邊。佢將TTS嘅能力從「要向雲端廠商購買嘅服務」變成了「本地開發工具鏈嘅一部分」。
如果你對佢有興趣:
• GitHub倉庫:github.com/OpenMOSS/MOSS-TTS-Nano • 文檔:studio.mosi.cn/docs/moss-tts-nano • 安裝: pip install moss-tts-nano
下一步可以試試:用MOSS-TTS-Nano幫你下星期要出嘅視頻配個音,睇下成品效果。如果有咩有趣嘅用法,歡迎喺評論區分享。
既然睇到呢度,如果覺得唔錯,順手俾個like、睇、轉發三連啦,如果想第一時間收到推送,亦可以俾我個星標⭐~
多謝你睇我嘅文章,我哋,下次再見
MOSS-TTS-Nano 是一個輕量、免費、本地可跑、支持語音克隆的中英日語 TTS,專為解決"好用但不貴、強大但不重"的語音合成需求而生。本文從項目定位、核心架構、功能特性講起,接着帶你 5 分鐘上手實操,最後深入實戰管線與 AI Agent 集成——由淺入深,一次性講透。
📖 本文目錄
PART 01|AI 語音合成:大而全 vs 小而美
PART 02|一探究竟:MOSS-TTS-Nano 是什麼
PART 03|核心架構:GPT 式雙通道生成
PART 04|兩大模式:語音克隆與文本續說
PART 05|16 種內置音色,中英日語全覆蓋
PART 06|兩套推理後端:PyTorch 與 ONNX 雙引擎
PART 07|快速上手:5 分鐘跑通 TTS
PART 08|實戰管線 + AI Agent 集成:從配音到微課視頻
PART 09|哪些場景可以用它?如果你關注過 AI 語音合成領域,會發現一個有趣的分化:
一端是"大而全"——雲端 TTS API(如 Azure Speech、訊飛、火山引擎),音質頂尖、音色豐富,但按月付費,越用越貴。做短視頻的博主,每個月光配音開銷就幾百上千;做自動化管線的團隊,每千字幾毛錢的成本在量起來之後成了真金白銀的負擔。
另一端是"小而美"——開源社區的小模型 TTS,免費、本地可跑,但你翻遍 GitHub 就會發現幾個尷尬的現實:
• 大部分項目依賴複雜,環境要配半天,跑起來顯卡呼呼叫 • 要麼只支持英文,要麼只支持中文,想雙語得裝兩套模型 • 所謂"coming soon"的功能一鴿就是一年 • 文檔能省則省,API 設計隨心所欲
兩個方向之間,一直缺一個中間地帶:
免費的、輕量的、本地可跑的、同時支持中英日語、還要開箱即用——這要求過分嗎?
不過分。MOSS-TTS-Nano 就在這個位置。
PART 02|一探究竟:MOSS-TTS-Nano 是什麼
MOSS-TTS-Nano 是 OpenMOSS Team 開源的一個實時多語言輕量 TTS 系統,核心就幾個數字:
• 100M 參數——同類模型中極小體量,普通 CPU 即可推理 • 中英日語三語——一個模型全部覆蓋 • 16 種預設音色——中/英/日三語男女聲,即開即用 • 零樣本語音克隆——3 秒參考音頻即可復刻聲音,無需微調 • 雙推理後端——PyTorch 用於研究和實驗,ONNX 用於生產部署
技術棧也很乾淨:
所有依賴加在一起,一個 requirements.txt 就能列完。沒有大而全的框架捆綁,沒有藏着掖着的私有依賴。
這正是它和很多 TTS 項目的本質區別:不是為了發論文,而是為了讓開發者真的能用。
PART 03|核心架構:GPT 式雙通道生成
MOSS-TTS-Nano 的架構思路很有意思:它把語音生成拆成了兩個階段,複用了 GPT 式因果語言模型的範式。
第一階段:文本編碼
輸入文本通過 SentencePiece 分詞器編碼為 token 序列。這些 token 被送入一個因果語言模型(Causal LM),自迴歸地生成"文本層 logits",從中採樣得到下一層需要的條件信號。
第二階段:音頻解碼
文本層的輸出被送入音頻 token 預測層,同樣自迴歸地生成音頻 token。這些 token 再通過 MOSS-Audio-Tokenizer-Nano——一個專門的神經音頻編解碼器——解碼為最終波形。
輸入文本 → 文本分詞 → [Causal LM 文本層] → 文本 token
↓
[Causal LM 音頻層] → 音頻 token
↓
MOSS-Audio-Tokenizer-Nano
↓
波形輸出這個設計的巧妙之處在於:
• 文本層和音頻層共享同一個語言模型的上下文,模型既理解語義又生成聲學特徵 • 自迴歸採樣保證了生成的自然度和連貫性 • Audio Tokenizer 可替換,意味着後面的音質還有優化的空間
訓練階段,模型在大量(文本,音頻)配對的語料上學習;推理時,給定文本和一段參考音頻(語音克隆模式),模型就能生成與參考音色一致、語義準確的語音。
用一句話理解:它像 GPT 寫文章一樣,逐 token 地"寫"出音頻。
PART 04|兩大模式:語音克隆與文本續說
MOSS-TTS-Nano 提供兩種推理模式,覆蓋了大部分實際使用場景。
模式一:voice_clone(語音克隆)
這是最核心的功能。你只需要一段參考音頻(3-5 秒即可),加上目標文本,模型就能零樣本克隆這個聲音。
moss-tts-nano generate \
--mode voice_clone \
--prompt-audio-path assets/audio/zh_1.wav \
--text "歡迎使用 MOSS-TTS-Nano 語音合成系統" \
--output output.wav實際測試下來,3 秒參考音頻已經能得到不錯的克隆效果。聲音的語調、節奏、音色特徵都能復現。
對於長文本,它內置了自動分塊機制:
--voice-clone-max-text-tokens 75當文本 token 長度超過閾值時,模型會按語義自動切句分批生成,再無縫合並。你給它 3000 字的長文案,它自己會搞定分段和拼接。
背後是 pocket-tts 風格的分句策略:先計算最優分割點,逐塊生成,最後拼接成完整音頻。
模式二:continuation(文本續說)
這個模式更像傳統的 TTS——給定文本,模型直接生成語音。但如果同時提供 --prompt-text 和 --prompt-audio-path,它也能實現"以上文語氣繼續往下說"的效果。
moss-tts-nano generate \
--mode continuation \
--prompt-text "大家好,歡迎收看今天的節目" \
--prompt-audio-path reference.wav \
--text "今天我們聊一個有趣的話題" \
--output output.wav採樣參數全開放
兩個模式下,你可以精細調控生成效果:
--text-temperature | ||
--audio-temperature | ||
--audio-top-p | ||
--audio-top-k | ||
--audio-repetition-penalty |
想穩定就壓低 temperature 和 top-p,想多樣性就調高它們。每個參數都暴露給用戶,給你最大的控制權。
PART 05|16 種內置音色,中英日語全覆蓋
一個模型,三語通吃。MOSS-TTS-Nano 內置了 16 種預設音色:
默認音色是 Junhao(中文男聲),這也是本地項目中實際使用的那一個。
所有預設音頻文件在 assets/audio/ 目錄下,格式為 WAV(部分為 MP3)。你也可以將自己的錄音放進去自定義。
這對開發者的意義是什麼?
不用再為每個語言去折騰不同的 TTS 引擎了。一個 pip 包,一個模型,中英日語的語音需求全部解決。如果客戶需要某個特定音色,拿一段參考音頻零樣本克隆就行。
PART 06|兩套推理後端:PyTorch 與 ONNX 雙引擎
這是 MOSS-TTS-Nano 一個很務實的架構設計——一套代碼,兩套推理引擎,按場景切換。
PyTorch 後端(研究探索用)
適合開發調試、實驗調參的場景:
• 基於 transformers的AutoModelForCausalLM加載 Hugging Face 格式 checkpoint• 支持 float16/bfloat16精度• 支持 Flash Attention 2(CUDA 下可用) • 默認模型 ID: OpenMOSS-Team/MOSS-TTS-Nano
moss-tts-nano generate --backend pytorch --text "你好" --prompt-audio-path ...ONNX 後端(生產部署用)
適合上線部署、資源受限的場景:
• 基於 onnxruntime推理,不依賴 PyTorch 運行時• CPU 原生支持——不需要 GPU 也能實時推理 • 支持 CUDA 執行提供程序(需要 onnxruntime-gpu)• 支持流式解碼( --realtime-streaming-decode),邊生成邊輸出,延遲更低• 可配置多種採樣策略: greedy/fixed/full
moss-tts-nano generate --backend onnx --text "你好" --prompt-audio-path ...項目還提供了完整的 ONNX 導出腳本(onnx/ 目錄):
• export_hf_to_tts_onnx.py——將 HuggingFace checkpoint 導出為標準 ONNX• export_moss_tts_browser_onnx.py——導出為 瀏覽器兼容 ONNX,甚至可以在瀏覽器端運行
本地已經導好的模型位於 models/MOSS-TTS-Nano-100M-ONNX/,配合 models/MOSS-Audio-Tokenizer-Nano-ONNX/ 組成完整推理鏈路。
為什麼 ONNX 後端很重要?因為在生產環境中,你不可能每台機器都裝 PyTorch + CUDA。ONNX Runtime 的部署成本低得多,用 CPU 就能跑,這是 MOSS-TTS-Nano 從"實驗項目"走向"生產工具"的關鍵一步。
PART 07|快速上手:5 分鐘跑通 TTS
廢話少說,直接上手。
第一步:安裝
pip install moss-tts-nano是的,就是一行。它已經發布到了 PyPI,pip install 就能裝好。
如果從源碼安裝:
git clone https://github.com/OpenMOSS/MOSS-TTS-Nano.git
cd MOSS-TTS-Nano
pip install -e .第二步:CLI 一句話生成語音
moss-tts-nano generate \
--mode voice_clone \
--prompt-audio-path assets/audio/zh_1.wav \
--text "你好,歡迎瞭解 MOSS-TTS-Nano" \
--output my_audio.wav第一次運行會自動下載模型(約 100M),之後就是離線運行。輸出的 WAV 文件拿播放器聽就行。
第三步:Python API 集成
如果你想把 TTS 嵌入自己的代碼:
from infer import main as tts_infer
result = tts_infer([
"--text", "嵌入你自己的 Python 項目就這麼簡單",
"--prompt-audio-path", "assets/audio/zh_1.wav",
"--mode", "voice_clone",
])
# result["audio_path"] → 生成的 WAV 文件返回的 dict 包含 audio_path、sample_rate、audio_token_ids,拿到路徑直接去下游播放或編輯。
第四步:啓動 Web 服務
moss-tts-nano serve --backend onnx --host 0.0.0.0 --port 18083啓動後訪問 http://localhost:18083,可以看到 FastAPI 自動生成的交互式 API 文檔頁面。你也可以用任何 HTTP 客戶端調用 POST /tts 接口上傳文本和參考音頻,獲取生成的語音文件。
PART 08|實戰管線 + AI Agent 集成:從配音到微課視頻
理論講完,來看一個真實管線——這就是 MOSS-TTS-Nano 在本地項目中的實際用法。
場景:把一篇文案做成帶配音的微課視頻
需求很簡單:一篇 18 個場景的文案,每個場景一段話,需要配上語音,再合成為視頻。用 MOSS-TTS-Nano 來解決。
批量配音生成
# generate_all_audio.py(核心邏輯)
for scene_text in script_lines:
subprocess.run([
"python", "infer_onnx.py",
"--prompt-audio-path", "assets/audio/zh_1.wav",
"--text", scene_text,
"--output-audio-path", f"scene-{i:02d}.wav",
])18 段文案,逐一調用 ONNX 後端生成 WAV 音頻,自動跳過已有文件(方便斷點續跑)。生成完成後,每個場景配一個 WAV 文件。
視頻合成
# render_video.py(核心邏輯)
# Playwright 截圖 HTML 動畫頁面 → 每秒 10 幀 PNG
# FFmpeg 合成:PNG 序列 → MP4 + 疊加 WAV 音頻
# 最終合併所有場景片段為一個完整視頻具體流程:
1. Playwright 打開每個場景的 GSAP 動畫 HTML 頁面 2. 按時間線逐幀截圖(利用 GSAP timeline 精確控制動畫進度) 3. FFmpeg 將截圖序列合成無聲音頻的 MP4 4. 再疊加 MOSS-TTS-Nano 生成的配音 WAV 文件 5. 最後 ffmpeg concat把所有場景片段合併為最終視頻
一條命令:文案 → 配音 → 視頻,全自動。
AI Agent 集成:讓語音生成真正"隨叫隨到"
以上還只是"腳本自動化"。更進一步,你可以把 MOSS-TTS-Nano 交給 AI Agent 來調用,讓它成為 Agent 工具鏈中的一個節點。
在 Claude Code 中使用
Claude Code 可以直接執行 Shell 命令。你只需要告訴它:
"幫我把這段文案生成配音,用 MOSS-TTS-Nano,音色用 Junhao。"
Claude Code 就會自動拼接出完整的 CLI 命令並執行,無需你手動敲參數。
更優雅的方式,是將 MOSS-TTS-Nano 的 CLI 命令註冊為一個 Tool。在 Claude Code 的配置中:
{
"tools": {
"moss-tts": {
"command": "moss-tts-nano generate --mode voice_clone --prompt-audio-path assets/audio/zh_1.wav --text \"${input}\" --output \"${output_path}\""
}
}
}之後你只需要說"生成配音",Claude Code 就會自動調用這個工具完成。
在 OpenClaw / Hermes 中集成
如果你在使用 OpenClaw 或 Hermes 這類 Agent 框架,可以把 MOSS-TTS-Nano 封裝為一個函數工具(Function Tool):
@tool
def tts_generate(text: str, output_path: str = "output.wav") -> str:
"""調用 MOSS-TTS-Nano 生成語音"""
result = subprocess.run([
"moss-tts-nano", "generate",
"--mode", "voice_clone",
"--prompt-audio-path", "assets/audio/zh_1.wav",
"--text", text,
"--output", output_path,
], capture_output=True, text=True)
return output_path這樣,Agent 就能在你的工作流中自主調用 TTS,不再需要人工介入。
在 QClaw / WorkBuddy 中編排流水線
對於更復雜的場景——比如"每天自動抓取最新文章 → 生成配音 → 合成視頻 → 發佈"——QClaw 或 WorkBuddy 這類任務編排工具可以把 MOSS-TTS-Nano 作為一個節點嵌入 DAG 流水線:
[文案輸入] → [文本處理] → [MOSS-TTS-Nano] → [視頻合成] → [發佈]
↑
[參考音頻(固定)]整個過程無需人工干預。Agent 負責調度,MOSS-TTS-Nano 負責語音生成,FFmpeg 負責視頻合成。
這就是"TTS 即服務(TTS-as-a-Function)"——不再是手動點按鈕,而是讓 AI Agent 替你跑腿。
PART 09|哪些場景可以用它?
聊了這麼多技術細節,最後回到一個實際問題:這個東西到底能用在哪?
短視頻 / 自媒體配音
如果你做短視頻,每個月要出幾十條配音。MOSS-TTS-Nano 可以:
• 零成本代替付費 TTS(省下每月的 API 賬單) • 批量生成一整期節目的全部配音 • 結合 AI Agent 實現"文案寫完 → 自動配音 → 自動合成"的全自動流程
AI 播客 / 音頻內容
把你的博客文章轉成播客,或者生成有聲讀物:
博客文章 → MOSS-TTS-Nano → MP3 播客不需要租服務器、不需要買 API 額度,本地跑完直接上傳。
教育微課 / 培訓視頻
這是本地項目已經驗證過的場景。一篇課程文案 → 分場景配音 → 合成視頻。對於在線教育平台或企業內部培訓,這是一個零成本的配音方案。
語音助手 / 嵌入式設備
100M 參數意味着它可以在樹莓派這類低功耗設備上跑。嵌入式語音助手、智能家居語音反饋、無障礙輔助工具——這些場景對模型大小敏感,MOSS-TTS-Nano 正好合適。
語音克隆研究 / 音色定製
如果你在做語音合成方向的研發,MOSS-TTS-Nano 提供了一個很好的基線:
• 零樣本克隆能力讓你快速驗證想法 • ONNX 導出能力讓你把實驗成果部署到實際系統 • 開源讓你可以深入源碼理解實現細節
為什麼選它而不是別的?
市面上不缺 TTS 項目,但 MOSS-TTS-Nano 的組合拳是獨特的:
| 免費 | |||
| 100M | |||
| 原生支持 | |||
| 中英日語 | |||
| 零樣本 | |||
| CLI + API 雙通道 |
它不是要取代 Azure 或訊飛——在大規模生產級 TTS 場景下,雲端方案依然是王者。但在"輕量、免費、本地、可控"這條線上,它是目前做得最均衡的一個。
寫在最後
MOSS-TTS-Nano 不是一個"大"項目——100M 參數放在今天的大模型語境下,連個零頭都不到。但正是這種"小",讓它有了獨特的價值:
你可以在任何機器上跑它,不需要 GPU,不需要聯網,不需要付費。想改什麼直接改源碼,想部署到哪就部署到哪。它把 TTS 的能力從"需要向雲廠商購買的服務"變成了"本地開發工具鏈的一部分"。
如果你對它感興趣:
• GitHub 倉庫:github.com/OpenMOSS/MOSS-TTS-Nano • 文檔:studio.mosi.cn/docs/moss-tts-nano • 安裝: pip install moss-tts-nano
下一步可以試試:用 MOSS-TTS-Nano 給你下週要發的視頻配個音,看看成品效果。如果有什麼有意思的用法,也歡迎在評論區分享。
既然看到這裏了,如果覺得不錯,隨手點個贊、在看、轉發三連吧,如果想第一時間收到推送,也可以給我個星標⭐~
謝謝你看我的文章,我們,下次再見