寫 Claude Skill 最大的盲區,Anthropic 終於幫你補上了
整理版優先睇
寫Claude Skill最大盲區係無法驗證效果,Anthropic更新skill-creator引入測試框架幫你補返呢個窿。
作者寫咗幾十個Claude Skill,最大困惑係唔知個Skill到底有冇用。每次寫完放落.claude/skills/目錄,就靠感覺判斷效果,唔確定係Skill起作用定係模型隨機行為。Claude更新之後,原來好用嘅Skill會唔會悄悄失效,完全冇頭緒。呢個困惑應該唔止佢一個人有,寫Skill嘅人大多唔係工程師,清楚流程但缺少工具驗證。
Anthropic最新更新skill-creator,核心係將軟件工程嘅測試、基準評估、迭代改進搬過嚟,但唔需要寫Code。新功能包括用自然語言寫eval、多Agent並行測試、benchmark模式、觸發時機優化。作者認為設計eval嘅過程,本質上係逼你將「期望咩行為」講清楚,好多模糊預期會浮面。結論係:下次寫Skill,少靠感覺,加個eval驗一驗。
- Skill寫作最大盲區係無法驗證效果,Anthropic更新skill-creator引入eval測試,將軟件工程方法引入。
- 用自然語言寫eval,描述期望結果,唔使寫code,直接判斷Skill有冇經得住檢驗。
- 兩種Skill類型:能力補充型(加新能力)同流程編排型(串流程),測試策略同預期生命週期都唔同。
- 設計eval倒逼你諗清「期望咩行為」,好多模糊預期會浮面,係提升Skill質量嘅關鍵。
- 即刻安裝skill-creator,畀你嘅Skill加個eval,一條prompt加一段預期描述就得,跑一次可能發現未意識到嘅問題。
skill-creator 插件
Claude Code用戶可以直接用claude plugin install skill-creator安裝,用於測試、衡量同迭代Skill。
Anthropic 官方 Skills 倉庫
Anthropic提供嘅公開Skills範例,可以參考同學習。
原文連結
Anthropic關於skill-creator更新嘅官方公告。
寫Skill嘅困惑終於有解
作者寫咗幾十個Claude Skill,最大困惑係唔知個Skill到底有冇用。每次寫完放落.claude/skills/目錄,就靠感覺判斷效果,唔確定係Skill起作用定係模型隨機行為。Claude更新之後,原來好用嘅Skill會唔會悄悄失效,完全冇頭緒。
呢個困惑應該唔止佢一個人有,寫Skill嘅人大多唔係工程師,清楚流程但缺少工具驗證。
Anthropic最新更新skill-creator,核心係將軟件工程嘅測試、基準評估、迭代改進搬過嚟,但唔需要寫Code。
先搞清楚你寫緊邊種Skill
Anthropic將Skill分成兩種:能力補充型同流程編排型。呢個區分對設計Skill好有參考價值。
- 能力補充型:畀模型添加佢本來做唔好嘅能力,例如官方文檔生成類Skill。風險係隨模型變強,可能變得多餘甚至限制Claude。
- 流程編排型:模型本身識做每個環節,但Skill將環節按規範串聯,例如NDA審查、每週報告。更耐用,但測試重點係驗證有冇按順序行完。
如果有測試,你能及時發現「呢個Skill已經完成歷史使命了」,而唔係一直帶住個冇用嘅包袱。
流程編排型嘅價值完全依賴於流程嘅嚴格執行,測試重點係驗證有冇按預定順序走完每一步。
用eval取代感覺,仲有觸發優化
skill-creator而家可以幫你寫eval,形式好簡單:畀出測試提示詞,描述期望行為,然後判斷Skill有冇經得住檢驗。做過軟件測試嘅人會覺得呢個模式好熟悉,分別係唔使寫code。
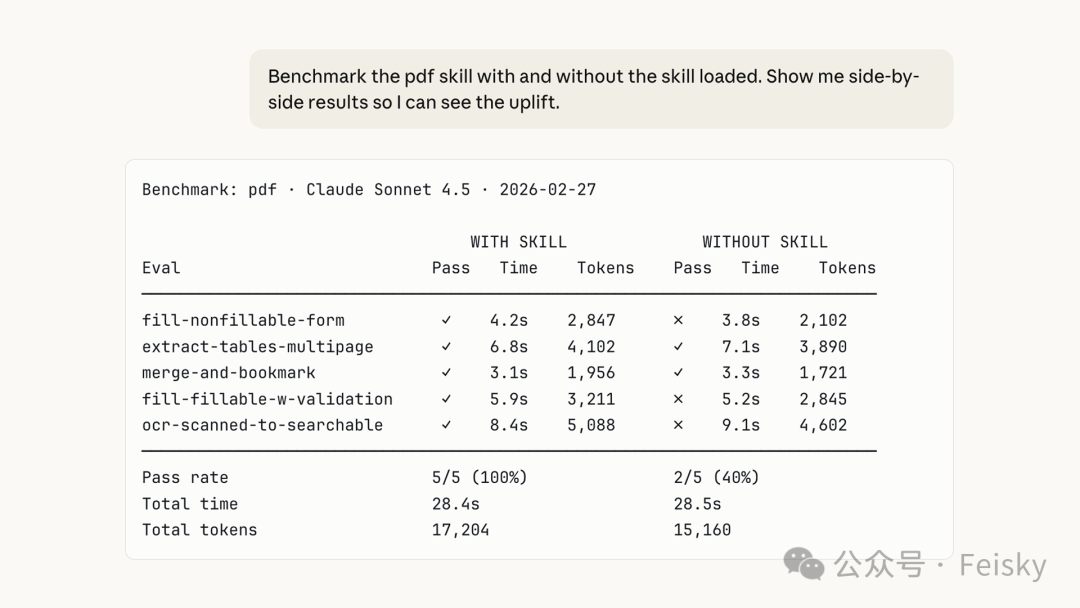
- 1 eval最直接價值係捕捉質量回歸:模型升級或基礎設施變動後,Skill可能行為變化,eval能提前預警。
- 2 仲有個微妙用途:對於能力補充型Skill,如果基礎模型唔加載Skill就能通過eval,說明技巧已被內化,Skill可以退役。
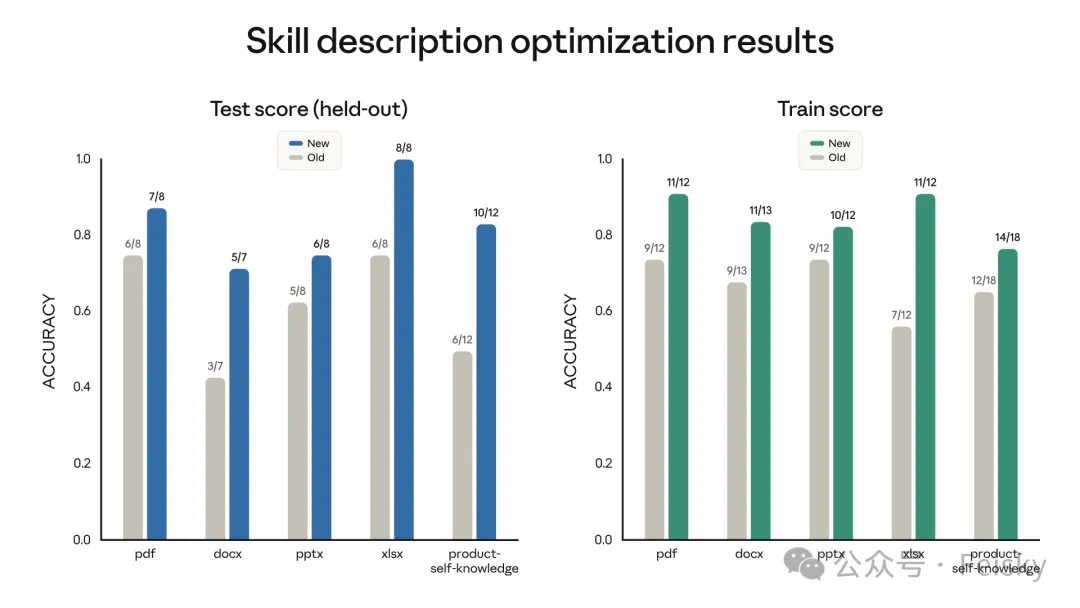
- 3 觸發時機優化功能:分析當前Skill描述,對照測試提示詞,推薦修改減少誤觸發同漏觸發。作者認為呢個功能最實用。
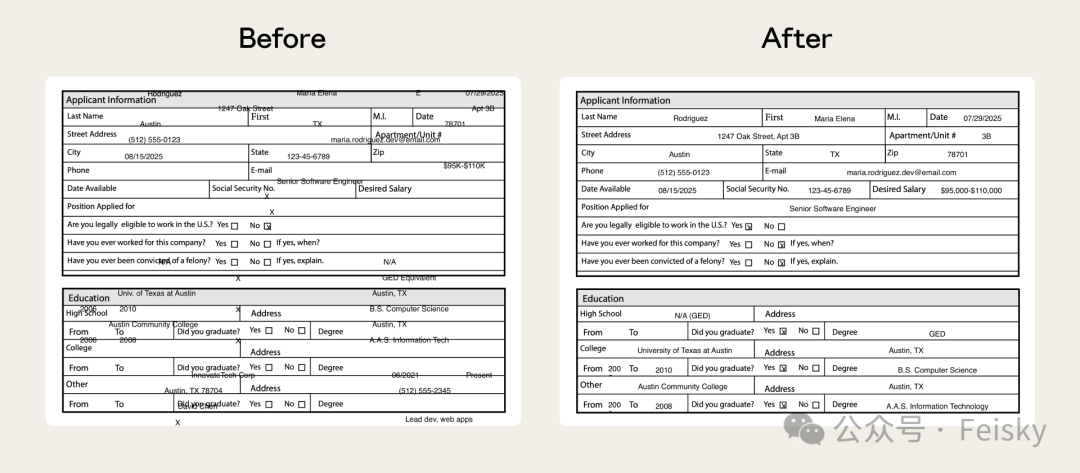
如果冇eval,呢個bug可能就一直隱藏,每次遇到不可填寫嘅表單就悄悄出問題。
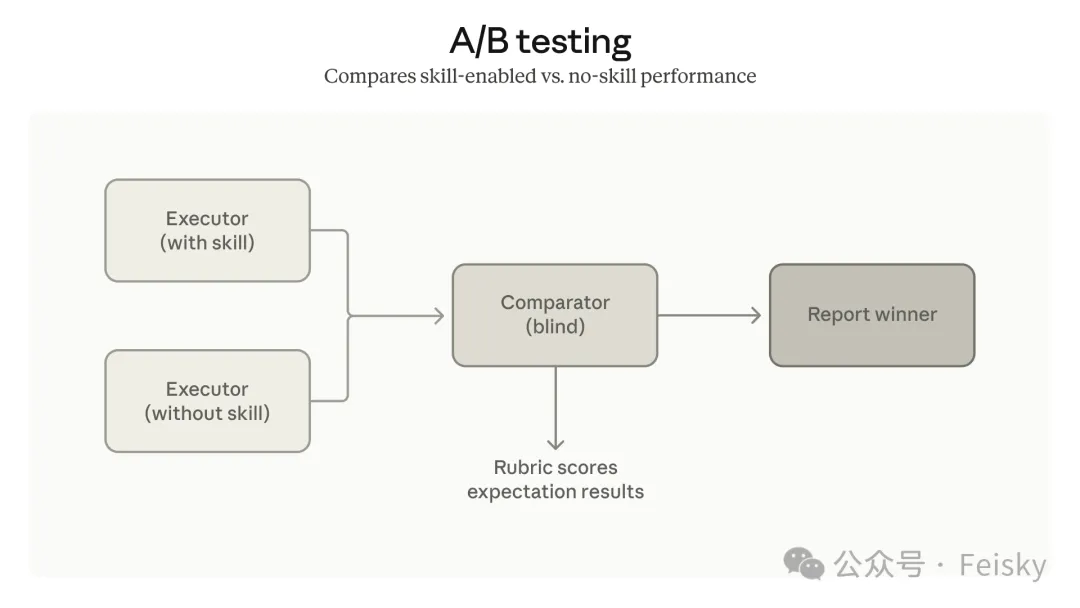
多Agent並行跑eval,每個Agent獨立上下文,仲有comparator agent做A/B對比,盡量排除評估偏差。
總結:畀你嘅Skill加個eval
作者認為下次寫Skill,少靠感覺,加個eval驗一驗。唔需要多複雜,一條提示詞、一段預期描述就夠。跑一次,可能會發現啲你冇意識到嘅問題。
Eval框架恰好在往what描述方向走,呢個描述本身可能就係未來形態嘅Skill。
- 能力補充型Skill要留意隨模型升級變得多餘;流程編排型要驗證步驟執行。
- 設計eval係將期望講清楚嘅過程,幫助釐清模糊預期。