刪掉全部手工特徵,X把推薦系統的完整代碼放出來了
整理版優先睇
xAI 全面開源推薦系統 X-Algorithm,從架構到可運行代碼,並揭示其核心設計:刪除所有手工特徵,改用 Grok Transformer 直接學習用戶行為。
呢篇文章講述 xAI 喺 2026 年 1 月首次開源推薦系統骨架之後,相隔四個月再次重大更新,直接將端到端推理管道、預訓練模型、廣告混合系統同內容理解模塊全部放上 GitHub。作者從技術角度整理咗呢次更新嘅重點,幫助讀者理解 xAI 點樣設計一套現代推薦系統。
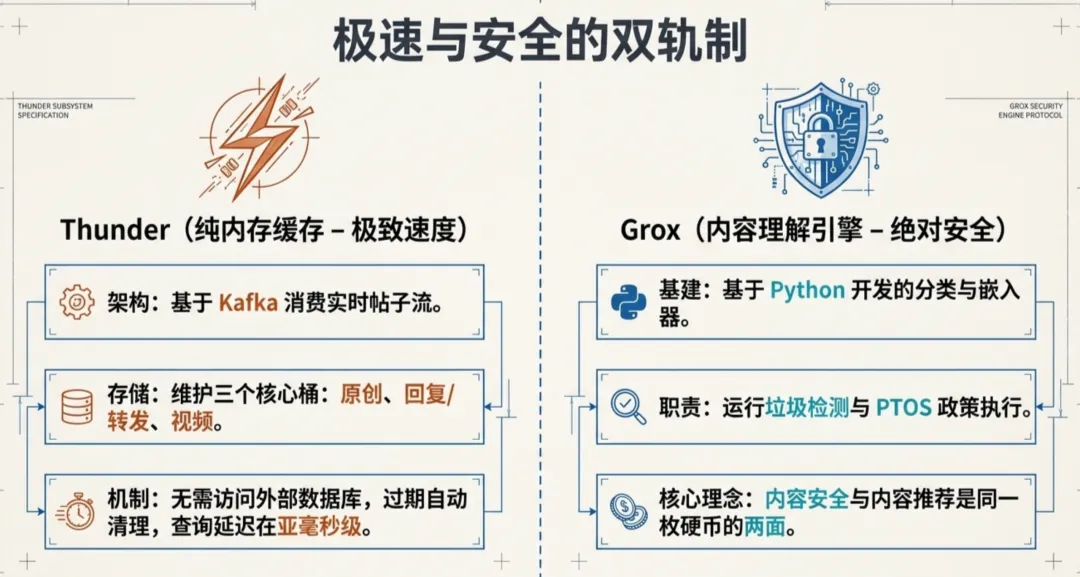
文章首先交代背景:xAI 開源嘅 x-algorithm 倉庫已經有 16779 粒星,主語言係 Rust,協議係 Apache-2.0。最初只係一個「代碼骨架」,想跑起嚟要自己準備模型同管道;而家就完全唔同,可以直接運行。作者將系統比喻成一個餐廳後廚,拆解咗四個核心組件:Home Mixer(主廚)、Thunder(冷藏櫃)、Phoenix(評判)同 Grox(質檢員)。每一個組件嘅職責同實現細節都講得好清楚,例如 Home Mixer 嘅七步流水線、Thunder 嘅純內存存儲、Phoenix 嘅 Grok-based transformer 排序,同埋新增嘅 Grox 內容質檢。
最令作者在意嘅一個設計決策係:xAI 刪除曬所有手工特徵同大部分啓發式規則,改為用 Grok transformer 直接從用戶互動序列學習,同時預測 15 種互動行為。呢種做法嘅哲學係「與其讓工程師猜測咩特徵重要,不如讓模型自己學」。文章最後分析咗 xAI 嘅開源策略:雖然開源推薦系統會暴露商業機密,但 xAI 喺社交廣告市場份額較細,開源帶嚟嘅人才吸引效應同品牌透明度價…
- xAI 完全開源推薦系統 X-Algorithm,從骨架到可運行,包含端到端管道、預訓練模型、廣告混合系統同內容理解模塊。
- 系統架構四大組件:Home Mixer(編排層)、Thunder(內存帖子存儲)、Phoenix(基於 Grok Transformer 嘅檢索排序)、Grox(內容質檢,今次新增)。
- 最核心設計:刪除所有手工特徵,Transformer 直接從用戶行為序列學習,同時預測 15 種互動行為(包括負向行為)。
- 技術選型全 Rust 加 Grok Transformer,展現 LLM 同推薦系統嘅垂直整合,同 OpenAI 將 GPT 塞入 Codex 嘅邏輯一脈相承。
- 開源策略:損失競爭優勢但獲得人才、生態同品牌透明度;開源版本係縮小版,生產模型規模大得多,社區已有人製作瀏覽器端 demo。
X-Algorithm 交互式 Demo
瀏覽器端體驗推薦系統運作邏輯
xai-org/x-algorithm GitHub 倉庫
X 推薦系統開源代碼,主語言 Rust,Apache-2.0 協議
開源歷程:從骨架到完整系統
今日 GitHub 熱榜上,xai-org/x-algorithm 倉庫又跳到前排,16779 粒星,2894 個 fork,主語言 Rust。距離 1 月 19 號第一次開源已經過去將近四個月。嗰次放出嘅係一個「代碼骨架」,有興趣嘅人可以睇明架構,但想跑起嚟要自己準備模型、自己搭 pipeline。
今次更新唔同,xAI 直接將端到端推理管道、預訓練模型、廣告混合系統、內容理解模塊全部推咗上嚟。
從「你可以睇我嘅設計圖」到「你可以直接將呢套系統跑起嚟」,呢個跨度比好多人預想嘅要大。
四大組件:後廚、冷藏櫃、評判、質檢員
成個推薦系統嘅架構可以咁樣理解:想像一個餐廳嘅後廚,Home Mixer 係主廚,負責統籌所有菜品嘅出餐順序;Thunder 係冷藏櫃,裏面存住你關注嘅人最近嘅帖子,隨時拎出嚟;Phoenix 係評判,試一啖就知呢道菜你會唔會鍾意;Grox 係質檢員,檢查食材有冇過期、有冇變質。呢四個組件各司其職,組合起嚟就係你喺 X 上刷到嘅每一條 For You 內容嘅完整旅程。
Home Mixer 用 Rust 寫,通過 gRPC 對外暴露 ScoredPostsService 接口。
- 1 每次你打開 X 刷新 feed,一個請求打到 Home Mixer,佢就開始七步流水線:先做 Query Hydration,補齊你嘅上下文(關注話題、starter pack、最近睇過嘅帖子、IP、互關等)。
- 2 並行從兩個來源拉候選帖子:Thunder 畀出你關注帳號嘅近期帖子,Phoenix Retrieval 從全局語料庫撈可能感興趣嘅內容。
- 3 拿到候選之後進入 Hydration 階段,補充元數據(互動數、品牌安全信號、語言標記、媒體類型、互關分數)。
- 4 再過 Filtering,刪走重複、過期、自己發嘅、自己屏蔽嘅人嘅帖子。
- 5 最後 Scoring 同 Selection:Phoenix transformer 打分,按分數排序,取 top K,再做一輪最終可見性檢查,你嘅 feed 就出嚟。成個過程喺亞毫秒級別完成。
Thunder 係純內存帖子存儲系統,查詢延遲亞毫秒級,唔需要訪問任何外部數據庫。
Thunder 嘅職責好單純:Kafka 消費實時帖子流,按用戶維度維護三個桶(原創帖子、回覆同轉發、視頻帖子)。佢只存「近期」帖子,超過保留期自動清理,好似一個容量有限嘅收件箱。
Phoenix 係成個系統最核心嘅 ML 組件,分兩階段工作:檢索用兩塔模型,排序用 Grok-based transformer。
- 檢索階段:User Tower 將用戶特徵同互動歷史編碼成向量,Candidate Tower 將所有帖子編碼成向量,做點積相似度搜索。
- 排序階段:從 Grok-1 開源版本移植嘅 transformer,專為推薦場景適配。關鍵設計係 Candidate Isolation——每條帖子只能關注用戶上下文,唔可以睇隔籬嘅帖子,確保公平獨立評分。
Grox 係今次新增嘅模塊,用 Python 寫,專門做內容理解:分類器、嵌入器、任務執行引擎,負責垃圾檢測、帖子分類、PTOS 政策執行。
Grox 嘅存在說明一個問題:推薦系統唔只係「揾用戶鍾意嘅嘢」,重要「過濾用戶唔應該睇到嘅嘢」。內容安全同內容推薦係同一枚硬幣嘅兩面。
最反直覺嘅設計:刪除所有手工特徵
Grok transformer 直接從你嘅互動序列學習:你點讚過咩、回覆過咩、轉發過咩、睇咗幾耐、有冇點進作者主頁、有冇舉報、有冇屏蔽。
原始行為數據直接灌入 transformer,讓佢自己學出咩係「相關」。Phoenix transformer 同時預測 15 種互動行為嘅概率:點讚、回覆、轉發、引用、點擊、點進主頁、睇視頻、展開圖片、分享、停留時長、關注作者,加上四個負向行為(不感興趣、屏蔽作者、靜音作者、舉報)。最終分數係加權求和,正向行為權重為正,負向行為權重為負。
- 呢個設計嘅哲學:與其讓工程師猜測「咩特徵重要」,不如讓模型直接從行為數據學。手工特徵係人認知嘅投影,而 transformer 嘅學習能力遠超人類嘅特徵構造能力。
- 代價:模型需要大量數據先訓練得好,算力成本高,推理延遲比傳統方案大。但對於 X 呢種體量嘅平台,呢啲代價付得起。
全 Rust 加 Grok Transformer:技術選型嘅啟示
主語言係 Rust,唔係 Python、Java 或 Go。Rust 喺推薦系統領域唔算主流,大多數公司用 Python(模型訓練同推理)或者 Java/Go(在線服務)。Rust 嘅優勢係性能同內存安全,劣勢係生態同開發效率。xAI 揀 Rust,說明佢哋對極致性能有執念,同時有能力養一支夠強嘅 Rust 工程團隊。
Grok transformer 嘅使用更值得玩味:xAI 將自己嘅 LLM 技術直接降維用喺推薦場景,唔係用通用推薦模型框架,而係將 Grok-1 嘅 transformer 實現搬過嚟做改造。
呢意味着 LLM 同推薦系統喺 xAI 內部唔係兩條平行線,而係同一條技術棧嘅唔同切面。呢種垂直整合嘅思路,同 OpenAI 將 GPT 塞入 Codex、Anthropic 將 Claude 塞入編碼工具嘅邏輯一脈相承。大模型公司正喺度將自家模型嘅能力鋪滿所有用得着嘅場景。
生態發酵:從代碼到社區 Demo
社區已經有人做咗瀏覽器端嘅交互式 demo,放喺 prabal.ca/x-algorithm/,你可以直接喺網頁上體驗呢套推薦系統嘅運作邏輯。開源四個月,從代碼骨架到可運行系統,再到社區自發做 demo,呢個生態發酵嘅速度本身就係一種信號。
推薦系統呢個領域,學術界同工業界之間有一道好深嘅牆。論文裏面睇到方法論,但睇唔到工程細節。xAI 今次將牆推倒咗一大片。
不管你用唔用 X,呢套代碼都係學習推薦系統架構嘅絕佳教材。黑箱打開之後,就冇秘密喇。
今日打開 GitHub 熱榜,xai-org/x-algorithm 倉庫個名又跳咗去前排。16779粒星,2894個 fork,主要用 Rust,Apache-2.0 協議。
距離1月19號第一次開源已經過咗差唔多四個月。嗰次放出嚟嘅係一個「代碼骨架」,有興趣嘅人可以睇得明架構,但係想跑得起就要自己準備模型、自己搭 pipeline。今日呢次更新唔同。xAI 直接將端到端嘅推理管道、預訓練模型、廣告混合系統、內容理解模塊全部推咗上嚟。
由「你可以睇我嘅設計圖」到「你可以直接將呢套系統跑起」,呢個跨度,比好多人預想嘅要大。
回顧一下時間線。2026年1月,xAI 首次公開 x-algorithm 倉庫,放出咗 For You 推薦系統嘅核心代碼,包括 Home Mixer 編排層、Thunder 內存帖子存儲、Phoenix 檢索排序模塊,仲有一套可複用嘅 Candidate Pipeline 框架。
代碼喺度,邏輯喺度,但係缺咗關鍵嘅嘢。冇可運行嘅端到端推理管道,檢索同排序要分別啟動兩個腳本。冇預訓練模型產物,你要自己訓練。冇內容理解模塊,垃圾檢測同帖子分類呢啲能力只能想象。冇廣告系統,而廣告正係任何社交平台推薦系統嘅命脈。
當時嘅 Hacker News 討論帖攞到125個 upvote 同65條評論。社區嘅反應好典型,興奮還興奮,但係「跑唔跑得起」呢個問題始終吊住。
四個月後嘅今日,呢啲吊住嘅問題有咗答案。
四大組件,四個角色
整個推薦系統嘅架構可以咁樣理解。想像一個餐廳嘅廚房後面,Home Mixer 係主廚,負責統籌所有菜式嘅出餐順序。Thunder 係冷藏櫃,裏面存咗你關注嘅人最近發嘅帖子,隨時攞來用。Phoenix 係評判,試一啖就知道呢道菜你會唔會鍾意。Grox 係質檢員,檢查食材有冇過期、有冇變質。
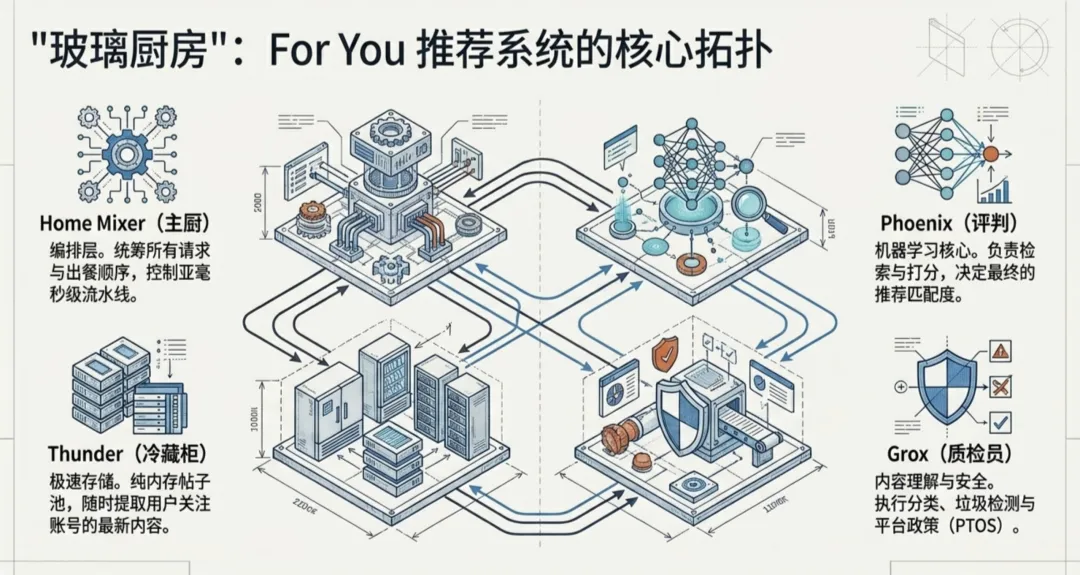
呢四個組件各司其職,組合起嚟就係你喺 X 上面碌到嘅每一條 For You 內容嘅完整旅程。
Home Mixer:廚房主廚
Home Mixer 用 Rust 寫嘅,通過 gRPC 對外暴露一個 ScoredPostsService 接口。每次你打開 X 更新 feed,一個請求打到 Home Mixer,佢就開始咗七步流水線。
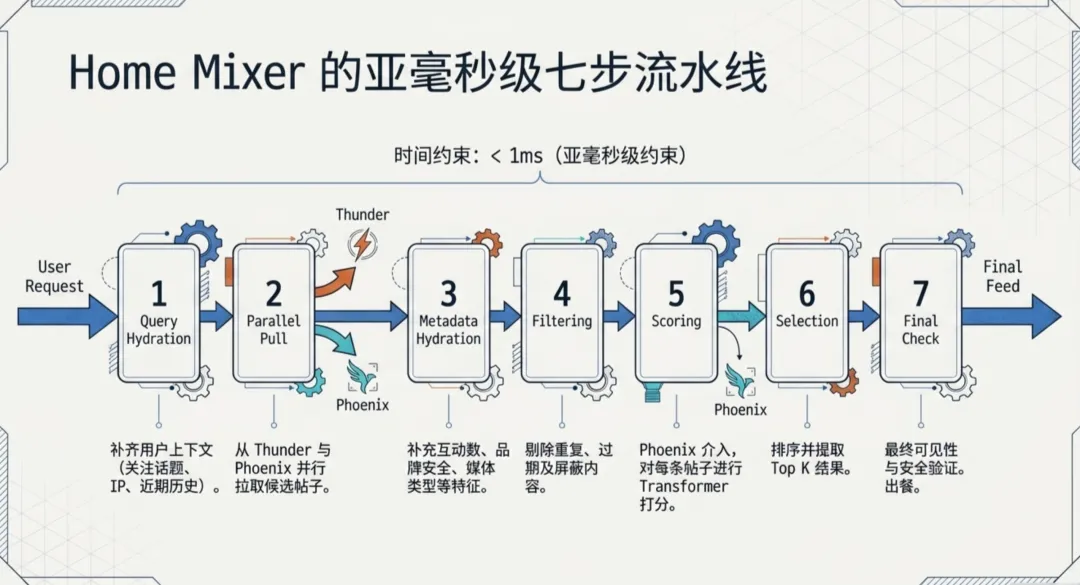
先做 Query Hydration,將你嘅上下文補齊。你關注咗邊啲話題,你喺邊啲 starter pack 裏面,你最近睇過邊啲帖子,你嘅 IP 喺邊,你同邊個互相關注。呢啲資訊全部灌入去,作為後續所有決策嘅基礎。
然後並行咁由兩個來源拉候選帖子。Thunder 畀出你關注賬號嘅近期帖子,Phoenix Retrieval 由全局語料庫裏面揾可能感興趣嘅內容。攞到候選之後,進入 Hydration 階段,畀每條帖子補充元數據,互動數、品牌安全信號、語言標記、媒體類型、互關分數。再過一次 Filtering,將重複嘅、過期嘅、你自己發嘅、你屏蔽咗嘅人嘅帖子全部去掉。
最後係 Scoring 同 Selection,Phoenix transformer 畀每條帖子打分,按分數排序,取 top K,再做一輪最終可見性檢查,你嘅 feed 就出咗嚟。
成個過程講起嚟長,實際上喺亞毫秒級別完成。
Thunder:超高速收件箱
Thunder 嘅職責好單純。佢係一個純內存嘅帖子存儲系統,Kafka 消費實時帖子流,按用戶維度維護三個桶,原創帖子、回覆同轉發、視頻帖子。查詢延遲喺亞毫秒級別,唔需要訪問任何外部數據庫。
之所以做到咁快,係因為佢只存「近期」嘅帖子。超過保留期嘅帖子會自動清理。呢個就好似一個容量有限嘅收件箱,只放最新鮮嘅嘢,舊嘅直接歸檔。
Phoenix:會讀心嘅評判
Phoenix 係整個系統最核心嘅 ML 組件,分兩階段工作。
第一階段係檢索。用兩塔模型,一個 User Tower 將你嘅特徵同互動歷史編碼成一個向量,一個 Candidate Tower 將所有帖子編碼成向量。兩個向量做點積相似度搜索,由全局語料庫裏面揾出最相關嘅帖子。
第二階段係排序。呢一步用 Grok-based transformer,唔係隨便一個 transformer,係由 Grok-1 開源版本移植過嚟,專門為推薦場景做咗適配。
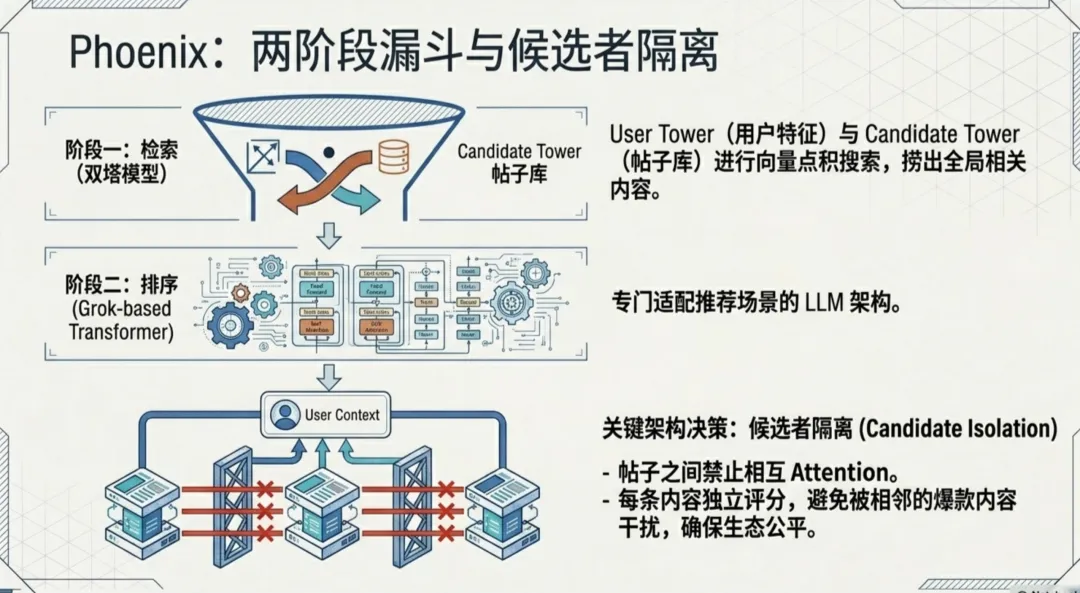
呢度有一個好關鍵嘅設計決策。候選帖子之間唔可以相互 attention。每條帖子只能關注用戶上下文,唔可以去睇隔籬嘅帖子講乜。呢個叫 Candidate Isolation,目的係確保每條帖子都被公平獨立咁評分,唔會因為隔籬有一條爆款內容就被壓低分數。
Grox:新增嘅質檢員
呢次更新新加嘅 Grox 模塊,用 Python 寫,專門做內容理解。佢提供分類器、嵌入器同任務執行引擎,可以跑垃圾檢測、帖子分類、PTOS 政策執行呢啲工作。
Grox 嘅存在說明一個問題。推薦系統唔止係「揾用戶鍾意嘅嘢」,仲要「過濾用戶唔應該見到嘅嘢」。內容安全同內容推薦係同一枚硬幣嘅兩面。
最反直覺嘅設計:刪曬所有手工特徵
成個系統裏面最令我留意嘅,唔係架構有幾複雜,而係一個看似簡單嘅決策。
xAI 喺 README 裏面寫得好直接,「We have eliminated every single hand-engineered feature and most heuristics from the system.」
刪曬全部手工特徵。刪咗大部分啓發式規則。
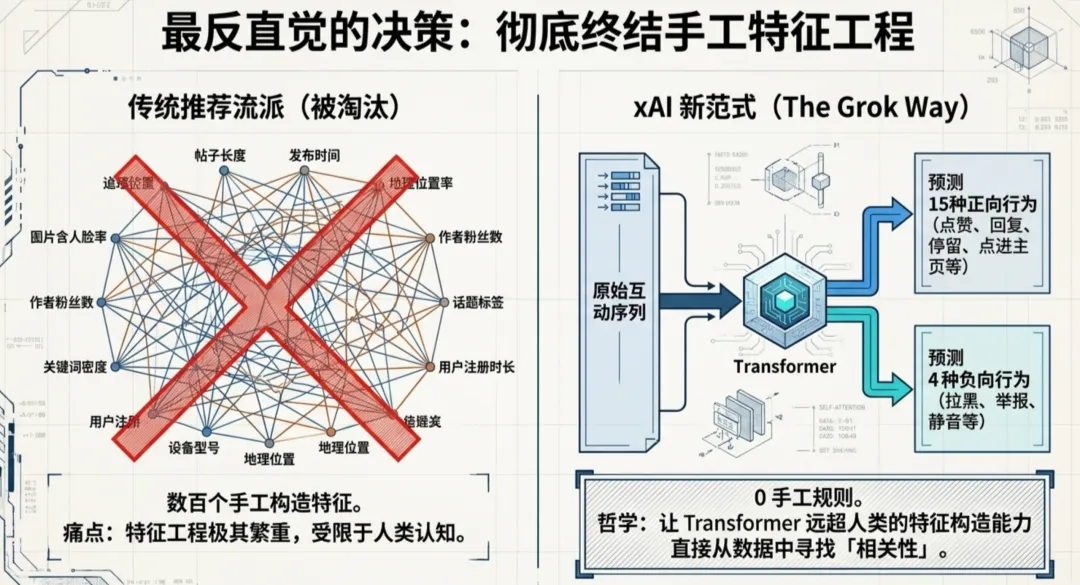
傳統推薦系統係點樣?工程師團隊花大量時間構造特徵,帖子長度、發佈時間、作者粉絲數、歷史互動率、圖片有冇人臉、係咪帶連結,幾十上百個特徵手工拼埋,餵畀模型。特徵工程本身已經係一個巨大嘅工程。
X 嘅做法係,將呢啲全部砍咗。Grok transformer 直接由你嘅互動序列裏面學習,你點讚過乜、回覆過乜、轉發過乜、睇過幾耐、有冇㩒入作者主頁、有冇舉報、有冇屏蔽。呢啲原始行為數據直接灌入 transformer,等佢自己學出乜嘢係「相關」。
Phoenix transformer 同時預測15種互動行為嘅概率。點讚、回覆、轉發、引用、點擊、㩒入主頁、睇視頻、展開圖片、分享、停留時長、關注作者,仲有四個負向行為,唔感興趣、屏蔽作者、靜音作者、舉報。
最終分數係一個加權求和,正向行為權重為正,負向行為權重為負。
呢個設計嘅哲學好清晰。與其讓工程師猜測「乜嘢特徵重要」,不如讓模型直接從行為數據裏面學。手工特徵係人類認知嘅投影,而 transformer 嘅學習能力遠超人類嘅特徵構造能力。
當然,代價都好明顯。模型需要大量數據先至可以訓練好,算力成本高,推理延遲都比傳統方案大。但對於 X 呢種體量嘅平台,呢啲代價畀得起。
全 Rust 加 Grok transformer,呢套技術選型說明乜嘢
主要語言係 Rust,唔係 Python,唔係 Java,唔係 Go。
Rust 喺推薦系統領域唔算主流選擇。大多數公司嘅推薦系統一係用 Python(模型訓練同推理),一係用 Java/Go(在線服務)。Rust 嘅優勢在於性能同內存安全,劣勢在於生態同開發效率。xAI 選擇 Rust,說明佢哋對極致性能有執念,同時亦說明佢哋有能力養一支足夠強嘅 Rust 工程團隊。
Grok transformer 嘅使用更值得玩味。xAI 將自己嘅 LLM 技術直接降維用喺推薦場景,唔係用通用嘅推薦模型框架,而係將 Grok-1 嘅 transformer 實現搬過嚟做改造。呢個意味住 LLM 同推薦系統喺 xAI 內部唔係兩條平行線,而係同一條技術棧嘅唔同切面。
呢種垂直整合嘅思路,同 OpenAI 將 GPT 塞入 Codex、Anthropic 將 Claude 塞入編碼工具嘅邏輯一脈相承。大模型公司正在將自家模型嘅能力鋪滿所有用得着嘅場景。
開源到呢個程度,Meta 同 TikTok 敢唔敢
回到最根本嘅問題。點解 Meta 唔開源 Instagram 嘅推薦算法?點解字節跳動唔開源 TikTok 嘅推薦系統?
推薦算法係社交平台最核心嘅商業機密之一。佢直接決定咗用戶停留時長、廣告收入、內容生態嘅健康度。將呢樣嘢開源,等於將底牌亮畀競爭對手。
xAI 嘅開源策略可能有幾層考量。X 喺社交廣告市場嘅份額遠不如 Meta 同 TikTok,開源嘅競爭損失相對較細。但通過開源獲得嘅人才吸引效應、開發者生態構建、以及「透明度」呢個品牌敍事嘅價值,可能遠大於閉源嘅收益。
而且 3GB 嘅預訓練 mini 模型只係一個縮小版,256維嵌入、4個注意力頭、2層 transformer。真正嘅生產模型規模肯定大得多。開源嘅係「方法論同架構」,唔係「直接可以替換生產環境嘅模型」。呢層微妙嘅信息差,xAI 把握得好精準。
社區裏面已經有人做咗瀏覽器端嘅交互式 demo,放喺 prabal.ca/x-algorithm/。你可以直接喺網頁上體驗呢套推薦系統嘅運作邏輯。
開源四個月,由代碼骨架到可運行系統,再到社區自發做 demo,呢個生態發酵嘅速度,本身就係一種信號。
推薦系統呢個領域,學術界同工業界之間有一道好深嘅牆。論文裏面睇得到方法論,但係睇唔到工程細節。xAI 呢次將牆推倒咗一大片。無論你用唔用 X,呢套代碼都係學習推薦系統架構嘅絕佳教材。
Macaron 🧁 | 黑箱打開咗之後,就冇秘密喇。
今天打開 GitHub 熱榜,xai-org/x-algorithm 倉庫的名字又跳到了前排。16779顆星,2894個 fork,主語言 Rust,Apache-2.0 協議。
距離1月19號第一次開源已經過去將近四個月。那次放出來的是一個「代碼骨架」,有興趣的人可以看懂架構,但想跑起來得自己準備模型、自己搭 pipeline。今天這次更新不一樣。xAI 直接把端到端的推理管道、預訓練模型、廣告混合系統、內容理解模塊全部推了上來。
從「你可以看我的設計圖」到「你可以直接把這套系統跑起來」,這個跨度,比很多人預想的要大。
回溯一下時間線。2026年1月,xAI 首次公開 x-algorithm 倉庫,放出了 For You 推薦系統的核心代碼,包括 Home Mixer 編排層、Thunder 內存帖子存儲、Phoenix 檢索排序模塊,以及一套可複用的 Candidate Pipeline 框架。
代碼在,邏輯在,但缺了關鍵的東西。沒有可運行的端到端推理管道,檢索和排序要分別啓動兩個腳本。沒有預訓練模型產物,你得自己訓練。沒有內容理解模塊,垃圾檢測和帖子分類這些能力只能想象。沒有廣告系統,而廣告恰恰是任何社交平台推薦系統的命脈。
當時的 Hacker News 討論帖拿到了125個 upvote 和65條評論。社區的反應很典型,興奮歸興奮,但「能跑嗎」這個問題始終懸着。
四個月後的今天,這些懸着的問題有了答案。
四大組件,四個角色
整個推薦系統的架構可以這樣理解。想象一個餐廳的後廚,Home Mixer 是主廚,負責統籌所有菜品的出餐順序。Thunder 是冷藏櫃,裏面存着你關注的人最近發的帖子,隨時取用。Phoenix 是評判,嘗一口就知道這道菜你會不會喜歡。Grox 是質檢員,檢查食材有沒有過期、有沒有變質。
這四個組件各司其職,組合起來就是你在 X 上刷到的每一條 For You 內容的完整旅程。
Home Mixer:後廚主廚
Home Mixer 用 Rust 寫的,通過 gRPC 對外暴露一個 ScoredPostsService 接口。每次你打開 X 刷新 feed,一個請求打到 Home Mixer,它就開始了七步流水線。
先做 Query Hydration,把你的上下文補齊。你關注了哪些話題,你在哪些 starter pack 裏,你最近看過哪些帖子,你的 IP 在哪,你跟誰互關。這些信息全部灌進去,作為後續所有決策的基礎。
然後並行地從兩個來源拉候選帖子。Thunder 給出你關注賬號的近期帖子,Phoenix Retrieval 從全局語料庫裏撈可能感興趣的內容。拿到候選之後,進入 Hydration 階段,給每條帖子補充元數據,互動數、品牌安全信號、語言標記、媒體類型、互關分數。再過一 Filtering,把重複的、過期的、你自己發的、你屏蔽的人的帖子全部去掉。
最後是 Scoring 和 Selection,Phoenix transformer 給每條帖子打分,按分數排序,取 top K,再做一輪最終可見性檢查,你的 feed 就出來了。
整個過程說起來長,實際上在亞毫秒級別完成。
Thunder:超高速收件箱
Thunder 的職責很單純。它是一個純內存的帖子存儲系統,Kafka 消費實時帖子流,按用戶維度維護三個桶,原創帖子、回覆和轉發、視頻帖子。查詢延遲在亞毫秒級別,不需要訪問任何外部數據庫。
之所以能做到這麼快,是因為它只存「近期」的帖子。超過保留期的帖子會被自動清理。這就像一個容量有限的收件箱,只放最新鮮的東西,舊的直接歸檔。
Phoenix:會讀心的評判
Phoenix 是整個系統最核心的 ML 組件,分兩階段工作。
第一階段是檢索。用兩塔模型,一個 User Tower 把你的特徵和互動歷史編碼成一個向量,一個 Candidate Tower 把所有帖子編碼成向量。兩個向量做點積相似度搜索,從全局語料庫裏撈出最相關的帖子。
第二階段是排序。這一步用 Grok-based transformer,不是隨便一個 transformer,是從 Grok-1 開源版本移植過來的,專門為推薦場景做了適配。
這裏有一個很關鍵的設計決策。候選帖子之間不能相互 attention。每條帖子只能關注用戶上下文,不能去看旁邊的帖子在說什麼。這叫 Candidate Isolation,目的是確保每條帖子都被公平獨立地評分,不會因為隔壁有一條爆款內容就被壓低分數。
Grox:新增的質檢員
這次更新新加的 Grox 模塊,用 Python 寫,專門做內容理解。它提供分類器、嵌入器和任務執行引擎,能跑垃圾檢測、帖子分類、PTOS 政策執行這些活。
Grox 的存在說明一個問題。推薦系統不只是「找用戶喜歡的東西」,還要「過濾用戶不該看到的東西」。內容安全和內容推薦是同一枚硬幣的兩面。
最反直覺的設計:刪掉所有手工特徵
整個系統裏最讓我在意的,不是架構有多複雜,而是一個看似簡單的決策。
xAI 在 README 裏寫得很直接,「We have eliminated every single hand-engineered feature and most heuristics from the system.」
刪掉了全部手工特徵。刪掉了大部分啓發式規則。
傳統推薦系統長什麼樣?工程師團隊花大量時間構造特徵,帖子長度、發佈時間、作者粉絲數、歷史互動率、圖片有沒有人臉、是不是帶連結,幾十上百個特徵手工拼起來,餵給模型。特徵工程本身就是一個巨大的工程。
X 的做法是,把這些全砍了。Grok transformer 直接從你的互動序列裏學習,你點贊過什麼、回覆過什麼、轉發過什麼、看過多久、有沒有點進作者主頁、有沒有舉報、有沒有屏蔽。這些原始行為數據直接灌進 transformer,讓它自己學出什麼是「相關」。
Phoenix transformer 同時預測15種互動行為的概率。點贊、回覆、轉發、引用、點擊、點進主頁、看視頻、展開圖片、分享、停留時長、關注作者,還有四個負向行為,不感興趣、屏蔽作者、靜音作者、舉報。
最終分數是一個加權求和,正向行為權重為正,負向行為權重為負。
這個設計的哲學很清晰。與其讓工程師猜測「什麼特徵重要」,不如讓模型直接從行為數據裏學。手工特徵是人認知的投影,而 transformer 的學習能力遠超人類的特徵構造能力。
當然,代價也很明顯。模型需要大量數據才能訓練好,算力成本高,推理延遲也比傳統方案大。但對於 X 這種體量的平台,這些代價付得起。
全 Rust 加 Grok transformer,這套技術選型說明什麼
主語言是 Rust,不是 Python,不是 Java,不是 Go。
Rust 在推薦系統領域不算主流選擇。大多數公司的推薦系統要麼用 Python(模型訓練和推理),要麼用 Java/Go(在線服務)。Rust 的優勢在性能和內存安全,劣勢在生態和開發效率。xAI 選擇 Rust,說明他們對極致性能有執念,同時也說明他們有能力養一支足夠強的 Rust 工程團隊。
Grok transformer 的使用更值得玩味。xAI 把自己的 LLM 技術直接降維用在推薦場景,不是用通用的推薦模型框架,而是把 Grok-1 的 transformer 實現搬過來做改造。這意味着 LLM 和推薦系統在 xAI 內部不是兩條平行線,而是同一條技術棧的不同切面。
這種垂直整合的思路,和 OpenAI 把 GPT 塞進 Codex、Anthropic 把 Claude 塞進編碼工具的邏輯一脈相承。大模型公司正在把自家模型的能力鋪滿所有能用得上的場景。
開源到這個程度,Meta 和 TikTok 敢嗎
回到最根本的問題。為什麼 Meta 不開源 Instagram 的推薦算法?為什麼字節跳動不開源 TikTok 的推薦系統?
推薦算法是社交平台最核心的商業機密之一。它直接決定了用戶停留時長、廣告收入、內容生態的健康度。把這個東西開源,等於把底牌亮給競爭對手。
xAI 的開源策略可能有幾層考量。X 在社交廣告市場的份額遠不如 Meta 和 TikTok,開源的競爭損失相對較小。但通過開源獲得的人才吸引效應、開發者生態構建、以及「透明度」這個品牌敍事的價值,可能遠大於閉源的收益。
而且 3GB 的預訓練 mini 模型只是一個縮小版,256維嵌入、4個注意力頭、2層 transformer。真正的生產模型規模肯定大得多。開源的是「方法論和架構」,不是「直接能替換生產環境的模型」。這層微妙的信息差,xAI 把握得很精準。
社區裏已經有人做了瀏覽器端的交互式 demo,放在 prabal.ca/x-algorithm/。你可以直接在網頁上體驗這套推薦系統的運作邏輯。
開源四個月,從代碼骨架到可運行系統,再到社區自發做 demo,這個生態發酵的速度,本身就是一種信號。
推薦系統這個領域,學術界和工業界之間有一道很深的牆。論文裏能看到方法論,但看不到工程細節。xAI 這次把牆推倒了一大片。不管你用不用 X,這套代碼都是學習推薦系統架構的絕佳教材。
Macaron 🧁 | 黑箱打開後,就沒有秘密了