別再 Prompt 完就點 Accept
整理版優先睇
由 Vibe Coding 轉向 Agentic Engineering:先寫 Spec 再讓 AI 鬱手,先係生產環境嘅正確做法
呢篇文章係作者分享佢用 Claude Code 嘅親身經驗。佢一開始嘅流程係「寫 Prompt → 等 AI 改 → 睇落行得就 Accept」,喺個人工具好爽,但一放落生產項目就出事:AI 好識補局部代碼,但唔一定明系統邊界。
作者引用 Karpathy 喺 Sequoia Ascent 嘅分法,將用 AI 寫 code 分做 Vibe Coding(適合原型同個人工具)同 Agentic Engineering(適合認真交付嘅軟件項目)。兩者嘅分別唔係用唔用 AI,而係你有冇將 AI 當做一個需要邊界嘅初級工程師。Karpathy 舉咗個 Stripe 購買記錄同 Google 賬號匹配嘅例子,代理用 email 做匹配好合理但好危險,因為付款 email 同登入 email 可以唔同。真正問題係 Spec 冇話俾 AI 知邊啲字段代表身份、邊啲只能用嚟聯絡。
整體結論係:喺生產項目,你一定要先寫一個短 Spec(目標、非目標、數據邊界、邊界案例、驗收標準),等 AI 出 Plan,然後小步實現,Review 嗰陣要盯緊身份、權限、付款冪等呢啲系統設計位,仲要將犯過嘅錯誤沉澱做 Eval 建立反饋迴路。作者最後提供咗一個簡單判斷:如果段 code 出錯會傷到用戶、錢、數據、信譽,就唔好靠感覺 Accept,要行 Agentic Engineering。
- Vibe Coding 適合原型同個人工具,Agentic Engineering 先適合生產環境;關鍵係要為 AI 設定明確邊界。
- 先寫簡短 Spec(目標、非目標、數據邊界、邊界案例、驗收標準),令 AI 唔使靠估。
- 等 AI 出 Plan 再改 Code,避免 Plan 繞過系統邊界,否則後續 Code 靚都冇用。
- Review Code 要重點盯系統設計位(身份、權限、冪等、回滾、日誌),命名格式可以放手。
- 將錯例沉澱做 Eval/測試,建立反饋迴路,下次 AI 再犯會自動被擋住。
內容片段
目標:用戶完成 Stripe 支付後,正確解鎖當前應用賬號。非目標:這次不改登錄流程,不合並歷史賬號。身份規則:應用內用戶身份只看 internal_user_id。Stripe email 只能作為聯繫信息,不能作為賬號匹配主鍵。邊界案例:支付郵箱和登錄郵箱不同。同一個用戶重複收到 webhook。Stripe 回調延遲或重放。用戶支付成功但本地寫庫失敗。驗收:有單元測試覆蓋郵箱不一致的情況。webhook 處理必須冪等。失敗時能重試,不重複發權益。由 Vibe Coding 到 Agentic Engineering:AI 唔係萬能寫手
作者以前用 Claude Code 最常見嘅三步:寫 Prompt → 等佢改 → 睇落行得就 Accept。做個人工具好爽,但一放落生產項目,問題就出曬嚟:AI 好識補局部代碼,但唔一定明你個系統邊界。
Karpathy 喺 Sequoia Ascent 分咗兩類:Vibe Coding 適合原型同個人工具,Agentic Engineering 適合認真交付嘅軟件項目。
佢哋嘅差別唔係用唔用 AI,而係你有冇將 AI 當一個需要邊界嘅初級工程師。Karpathy 舉咗個親身例子:佢個代理想將 Stripe 購買記錄同 Google 賬號對上,代理用咗 email 匹配——好合理,但都好危險。
Spec-First 實戰:目標、非目標、邊界、驗收
作者而家更願意先寫一個好短嘅 Spec,再讓 AI 鬱手。唔好寫大文檔,淨係寫今次改動需要嘅內容。
- 1 目標:明確呢次改動要做嘅嘢,例如「用戶完成 Stripe 付款後正確解鎖當前應用賬號」。
- 2 非目標:講清今次唔做嘅嘢,例如「唔改登錄流程、不合併歷史賬號」。
- 3 數據邊界:定義身份規則,例如「應用內用戶身份只睇 internal_user_id;Stripe email 只能做聯絡信息,唔可以做賬號匹配主鍵」。
- 4 邊界案例:列出明顯嘅特殊情況,例如「付款 email 同登錄 email 唔同、重複 webhook、支付成功但寫庫失敗」。
- 5 驗收標準:要求有單元測試覆蓋 email 不一致、webhook 處理必須冪等、失敗時能重試唔重複發權益。
呢段 Spec 唔長,但會明顯改變 AI 寫嘅 Code——佢唔會再從「email 最容易匹配」開始猜,而係跟住你畀嘅身份規則做設計。
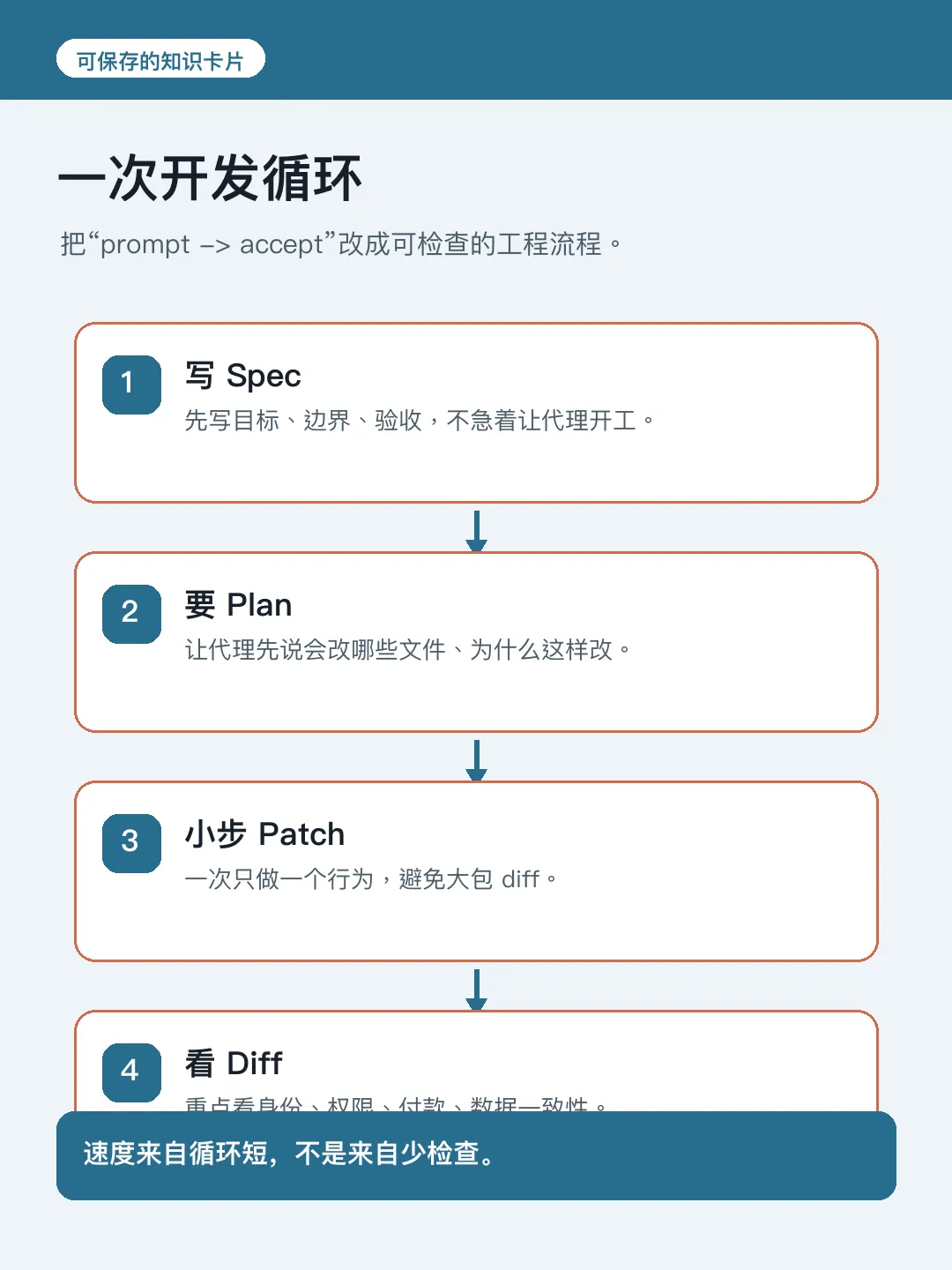
Plan、小步實現、Review 點睇位
作者嘅實際流程會拆成幾步:先寫 Spec,然後讓 AI 出 Plan。Plan 要列出準備改邊啲文件、點解要改、邊啲位唔確定。呢一步好關鍵:如果 Plan 已經繞過系統邊界,後面 Code 寫得幾靚都冇用。
接着先小步實現,一次只改一個行為,唔好讓 AI 順手重構、改樣式、或者「優化相關 Code」。
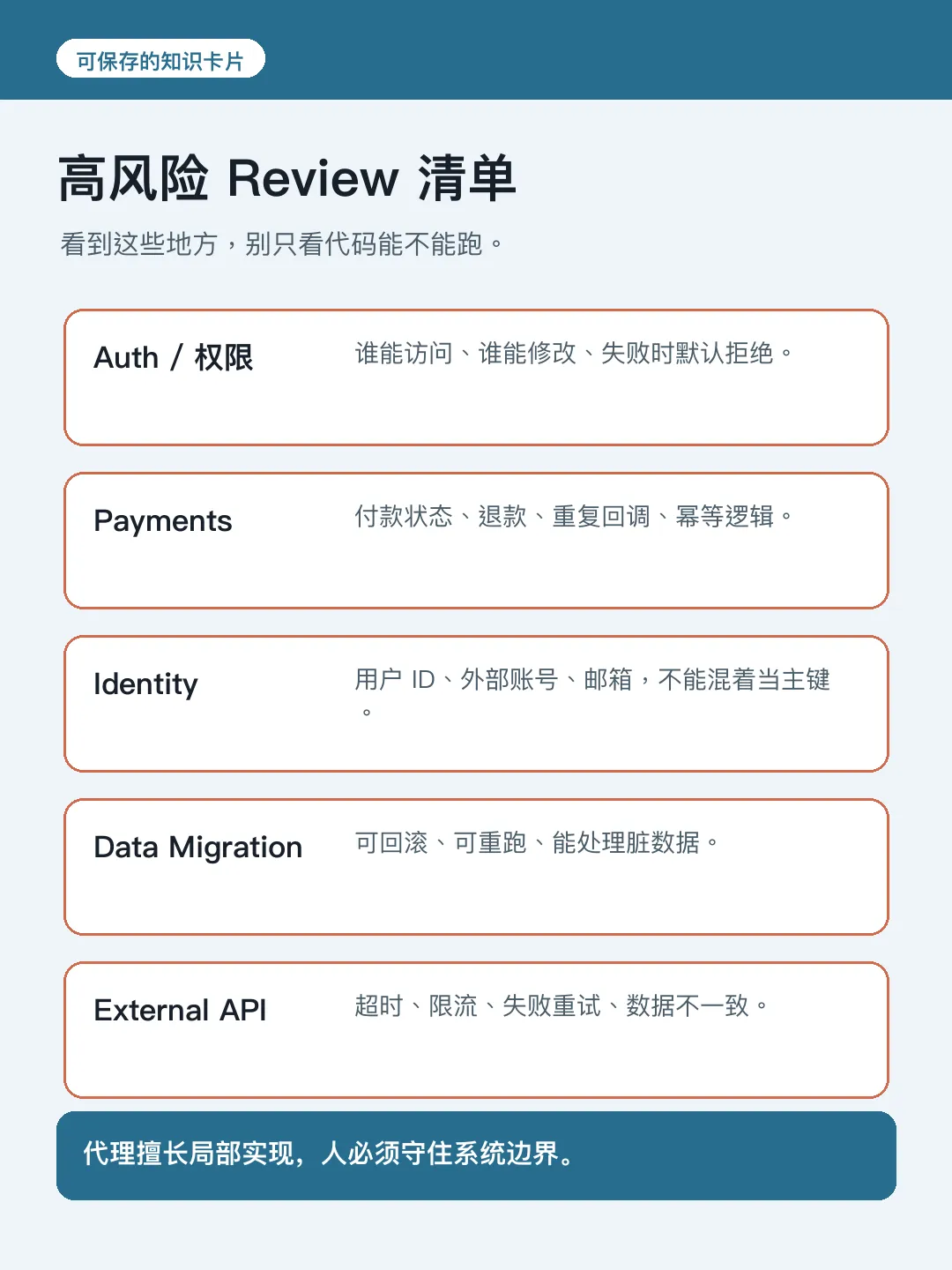
AI 好容易將一個清楚任務擴大成一大坨 Diff,Diff 一大人類就懶得睇,生產事故就跟住嚟。睇 Diff 嘅時候要區分輕重:命名、格式、細函數點拆可以放手,但要盯緊系統設計位。
- 身份有冇混亂?
- 權限有冇漏咗?
- 付款邏輯係咪冪等?
- 外部 API 失敗點算?
- 數據遷移可唔可以回滾?
- 日誌會唔會泄露用戶信息?
呢啲唔係模型識唔識寫 Code 嘅問題,係系統設計問題,人一定要睇。
反饋迴路:將錯例沉澱做 Eval
仲有一個好易忽略嘅動作:將錯例沉澱做 Eval。例如今次發現「支付 email 同登錄 email 唔同」會出問題,唔好淨係記喺腦,寫成測試。下次代理再碰付款邏輯,呢個測試會自動擋住佢。
當然,唔係所有嘢都要咁重。寫週報腳本、做細 Demo、俾自己搭臨時工具,完全可以 Vibe Coding,錯咗冇乜嘢。但只要碰到認證、付款、權限、私隱、數據遷移、客戶生產環境,就唔好再靠感覺 Accept。
簡單判斷:段 Code 出錯會唔會傷到用戶、錢、數據、信譽?如果唔會,快啲;如果會,先寫 Spec。
將 AI 當初級工程師,唔係睇小佢,係正常工程管理。初級工程師可以寫好多 Code,但你唔會讓佢自己決定身份模型、付款邊界同數據遷移策略。AI 都一樣:讓佢快,但唔好讓佢靠估。
寫 prompt。
等佢改。
睇落好似行得通,就 accept。
做個人工具好爽。
但一放落生產項目,問題就出嚟:AI 好叻補局部碼,但未必明你個系統邊界。
Karpathy 喺 Sequoia Ascent 嘅 fireside 講咗一個分類,我覺得好有用。
vibe coding,適合原型同個人工具。
agentic engineering,適合認真交貨嘅軟件項目。
兩者分別唔係「用唔用 AI」。
分別係你有冇當 AI 係一個需要邊界嘅初級工程師。
Karpathy 舉過一個自己嘅例子。
佢個 agent 想將 Stripe 購買記錄同 Google 賬號對返。
Agent 用咗郵箱去配對。
咁樣好合理。
亦都好危險。
因為 Stripe 郵箱同 Google 登入郵箱可以唔係同一個。用戶用私人郵箱俾錢,用公司郵箱登入,完全正常。
呢度真正嘅問題,唔係 AI 寫錯咗一行碼。
係任務 spec 冇話畀佢知:咩字段可以代表身份,咩字段淨係用嚟聯絡用戶。
所以 spec-first 唔係形式。
佢係話畀 agent 知邊度唔可以估。
我而家更願意先寫一個好短嘅 spec,先至畀 agent 開工。
大概係咁樣:
目標:
用戶完成 Stripe 支付後,正確解鎖當前應用賬號。
非目標:
這次不改登錄流程,不合並歷史賬號。
身份規則:
應用內用戶身份只看 internal_user_id。
Stripe email 只能作為聯繫信息,不能作為賬號匹配主鍵。
邊界案例:
支付郵箱和登錄郵箱不同。
同一個用戶重複收到 webhook。
Stripe 回調延遲或重放。
用戶支付成功但本地寫庫失敗。
驗收:
有單元測試覆蓋郵箱不一致的情況。
webhook 處理必須冪等。
失敗時能重試,不重複發權益。
呢段嘢唔長。
但佢會明顯改變 agent 寫出嚟嘅碼。
佢唔會再由「郵箱最容易配對」開始估。
佢會由你畀嘅身份規則開始設計。

我實際嘅流程而家會拆做幾個步驟。
先寫 spec。
只寫今次改動需要嘅內容,唔寫大文檔。
目標、非目標、數據邊界、邊界案例、驗收標準,呢五項夠用。
然後叫 agent 先出 plan。
唔好一嚟就叫佢改碼。
我會叫佢列出準備改邊幾個檔案、每個檔案點解要改、邊啲地方佢唔肯定。
呢一步好關鍵。
如果 plan 已經繞過咗系統邊界,後面啲碼寫得幾靚都冇用。
接着先叫佢逐步實現。
一次只改一個行為。
唔好叫佢順便重構,唔好叫佢順便改樣式,唔好叫佢「優化嚇相關碼」。
AI 好容易將一個清楚嘅任務擴大成一大堆 diff。
diff 一大,人就懶得睇。
人一懶,生產事故就嚟。
睇 diff 嘅時候,我唔會平均用力。
命名、格式、細函數點拆,呢啲可以放鬆啲。
我睇實嘅係幾類地方:
身份有冇混亂。
權限有冇漏。
俾錢邏輯有冇冪等。
外部 API 失敗點算。
數據遷移可唔可以回滾。
日誌入面會唔會洩漏用戶資訊。
呢啲唔係模型識唔識寫碼嘅問題。
呢啲係系統設計問題。
人一定要睇。
仲有一個容易被忽略嘅動作:將錯例沉澱成 eval。
例如今次發現「支付郵箱同登入郵箱唔同」會出問題。
唔好只係記喺腦入面。
將佢寫成測試。
下次 agent 再掂付款邏輯,呢個測試會自動擋住佢。
呢個就係反饋迴路。
冇反饋迴路,你每次都要靠記憶去 review。
靠記憶一定會漏。
有咗反饋迴路,agent 犯過一次錯,下一次就會俾工具捉到。
呢個亦係 agentic engineering 同 vibe coding 最大嘅分別。
vibe coding 係 prompt 完睇結果。
agentic engineering 係將人嘅判斷變成規則,再用規則約束下一次生成。
當然,唔係所有嘢都要咁重手。
你寫一個週報腳本。
你做一個小 demo。
你幫自己整一個臨時工具。
完全可以 vibe coding。
錯咗都冇乜所謂。
但只要掂到認證、付款、權限、私隱、數據遷移、客戶生產環境,就唔好再靠感覺 accept。

一個簡單判斷:
段碼出錯,會唔會傷到用戶、錢、數據、信譽?
如果唔會,快啲。
如果會,先寫 spec。
將 AI 當初級工程師,唔係睇低佢。
呢個係正常嘅工程管理。
初級工程師可以寫好多碼。
但你唔會畀佢自己決定身份模型、付款邊界同數據遷移策略。
AI 都一樣。
叫佢快。
但唔好叫佢估。
寫 prompt。
等它改。
看起來能跑,就 accept。
做個人工具很爽。
但一放到生產項目,問題就出來了:AI 很會補局部代碼,不一定懂你的系統邊界。
Karpathy 在 Sequoia Ascent 的 fireside 裏講了一個分法,我覺得很有用。
vibe coding,適合原型和個人工具。
agentic engineering,適合認真交付的軟件項目。
兩者差別不是“用不用 AI”。
差別是你有沒有把 AI 當一個需要邊界的初級工程師。
Karpathy 舉過一個自己的例子。
他的代理想把 Stripe 購買記錄和 Google 賬號對上。
代理用了郵箱匹配。
這很合理。
也很危險。
因為 Stripe 郵箱和 Google 登錄郵箱可以不是同一個。用戶用個人郵箱付款,用公司郵箱登錄,完全正常。
這裏真正的問題,不是 AI 寫錯了一行代碼。
是任務 spec 沒有告訴它:什麼字段能代表身份,什麼字段只能用來聯繫用戶。
所以 spec-first 不是形式。
它是在告訴代理哪裏不能猜。
我現在更願意先寫一個很短的 spec,再讓代理動手。
大概長這樣:
目標:
用戶完成 Stripe 支付後,正確解鎖當前應用賬號。
非目標:
這次不改登錄流程,不合並歷史賬號。
身份規則:
應用內用戶身份只看 internal_user_id。
Stripe email 只能作為聯繫信息,不能作為賬號匹配主鍵。
邊界案例:
支付郵箱和登錄郵箱不同。
同一個用戶重複收到 webhook。
Stripe 回調延遲或重放。
用戶支付成功但本地寫庫失敗。
驗收:
有單元測試覆蓋郵箱不一致的情況。
webhook 處理必須冪等。
失敗時能重試,不重複發權益。
這段東西不長。
但它會明顯改變代理寫出來的代碼。
它不再從“郵箱最容易匹配”開始猜。
它會從你給的身份規則開始做設計。
我的實際流程現在會拆成幾步。
先寫 spec。
只寫這次改動需要的內容,不寫大文檔。
目標、非目標、數據邊界、邊界案例、驗收標準,這五項夠用了。
然後讓代理先出 plan。
不要一上來就讓它改代碼。
我會讓它列出準備改哪些文件、每個文件為什麼要改、哪些地方它不確定。
這一步很關鍵。
如果 plan 已經繞開了系統邊界,後面代碼寫得再漂亮也沒用。
接着才讓它小步實現。
一次只改一個行為。
不要讓它順手重構,不要讓它順手改樣式,不要讓它“優化一下相關代碼”。
AI 很容易把一個清楚任務擴大成一坨 diff。
diff 一大,人就懶得看。
人一懶,生產事故就來了。
看 diff 的時候,我不會平均用力。
命名、格式、小函數怎麼拆,這些可以稍微放手。
我盯的是幾類地方:
身份有沒有混。
權限有沒有漏。
付款邏輯有沒有冪等。
外部 API 失敗怎麼辦。
數據遷移能不能回滾。
日誌裏會不會泄露用戶信息。
這些不是模型能不能寫代碼的問題。
這是系統設計問題。
人必須看。
還有一個容易被忽略的動作:把錯例沉澱成 eval。
比如這次發現“支付郵箱和登錄郵箱不同”會出問題。
不要只在腦子裏記住。
把它寫成測試。
下次代理再碰付款邏輯,這個測試會自動擋住它。
這就是反饋迴路。
沒有反饋迴路,你每次都在靠記憶 review。
靠記憶一定會漏。
有了反饋迴路,代理犯過一次的錯,下一次就會被工具抓住。
這也是 agentic engineering 和 vibe coding 最大的差別。
vibe coding 是 prompt 完看結果。
agentic engineering 是把人的判斷變成規則,再讓規則約束下一次生成。
當然,不是所有東西都要這麼重。
你寫一個週報腳本。
你做一個小 demo。
你給自己搭一個臨時工具。
完全可以 vibe coding。
錯了也沒什麼。
但只要碰到認證、付款、權限、隱私、數據遷移、客戶生產環境,就不要再靠感覺 accept。
一個簡單判斷:
這段代碼出錯,會不會傷到用戶、錢、數據、信譽?
如果不會,快一點。
如果會,先寫 spec。
把 AI 當初級工程師,不是看不起它。
這是正常工程管理。
初級工程師可以寫很多代碼。
但你不會讓他自己決定身份模型、付款邊界和數據遷移策略。
AI 也一樣。
讓它快。
但別讓它猜。