別再把資料丟進收藏夾了,我開源了知識庫工具AIWiki,一鍵擁有Karpathy的LLM Wiki和Dan Koe的內容積木思路的AI知識庫
整理版優先睇
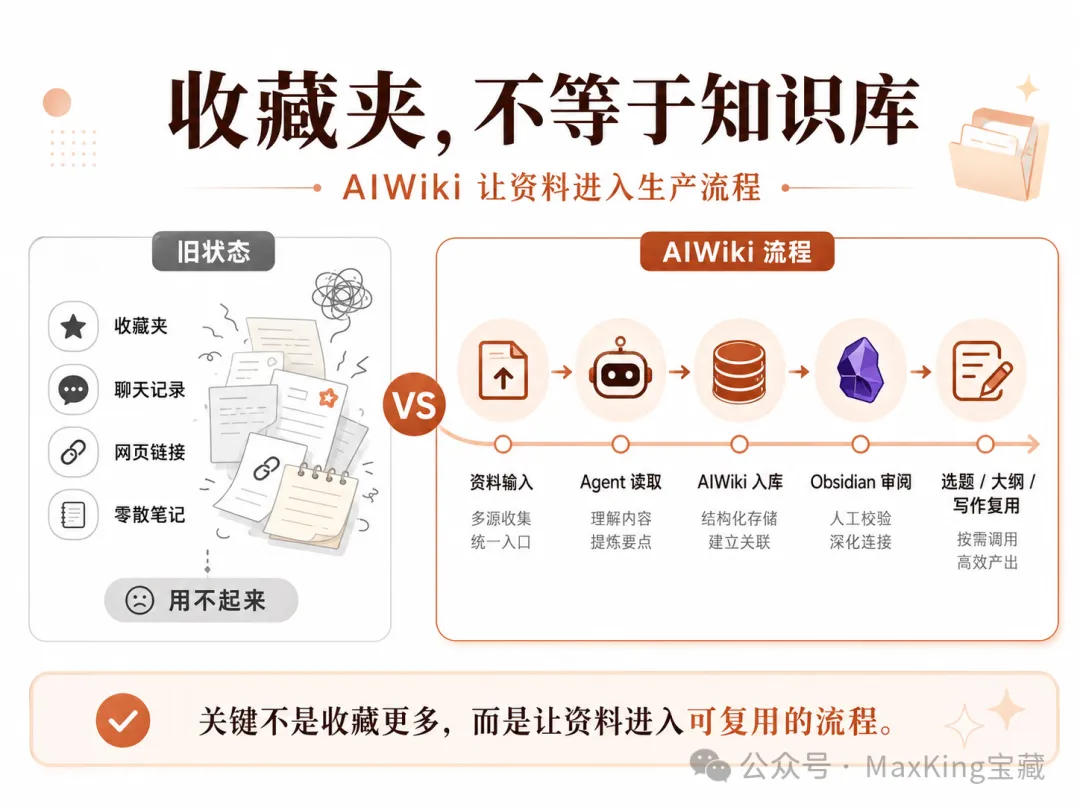
AIWiki開源工具:將收藏資料變成可複用嘅內容資產,從LLM Wiki同內容積木思路出發,建立完整入庫工作流
Max King係全棧開發者同AI重度用戶,佢發現自己成日收藏資料但最後都用唔到,問題唔係資料唔夠,而係資料冇進入生產流程。佢認為真正需要嘅唔係更快嘅總結,而係一套將資料從「睇過」變成「可複用」嘅入庫流程。
受Karpathy嘅LLM Wiki(編譯式知識庫)同Dan Koe嘅內容積木思路啟發,佢開發咗開源工具AIWiki。LLM Wiki強調原始資料經LLM編譯成長期維護嘅Wiki,內容積木則係將好內容拆成觀點、案例等創意積木再重組。AIWiki唔係簡單拼接,而係重新組織成一條可執行嘅個人工作流:Agent-first、唔急生成正式Wiki、輕Schema約束、面向內容再生產。
AIWiki一次入庫會生成原始記錄、Source Card、Claim建議、創意素材、選題候選、草稿大綱等,令資料真係進入知識庫。工具基於Obsidian,生成本地Markdown文件。目前正在做共創測試,作者想驗證安裝同使用流程,邀請有興趣嘅人一齊測試。最終目標係幫助建立穩定嘅資料生產流程,從收藏到入庫,再到選題同輸出。
- 結論:收藏夾只係資料堆,要令資料進入生產流程先有用。
- 方法:AIWiki以Agent-first處理輸入,生成多種中間產物(資料卡、選題、大綱),再寫入Obsidian。
- 差異:有別於一般AI總結留下聊天記錄,AIWiki將結果結構化入庫,可審閲同覆盤。
- 啟發:Karpathy嘅LLM Wiki教識我哋編譯式知識庫,Dan Koe嘅內容積木教識我哋拆解重組創意。
- 可行動點:而家可以參與共創測試,揀一篇收藏文章跑一次完整流程。
收藏越多,反而越寫唔出嚟
Max King以前同好多人一樣,見到好文章就收藏,公眾號、瀏覽器、微信、Obsidian都存。當時覺得呢篇以後肯定用得着,但真實情況係收藏完就冇然後。等到要寫文章、做選題嘅時候,又要重新去翻聊天記錄同收藏夾。
很多人不是缺資料,而是資料沒有進入生產流程
問題唔係資料少,而係資料只係被「存起咗」,冇被整理、拆解、歸檔,亦冇變成可以複用嘅素材。
收藏夾越來越滿,腦子反而越來越亂
受LLM Wiki同內容積木啟發
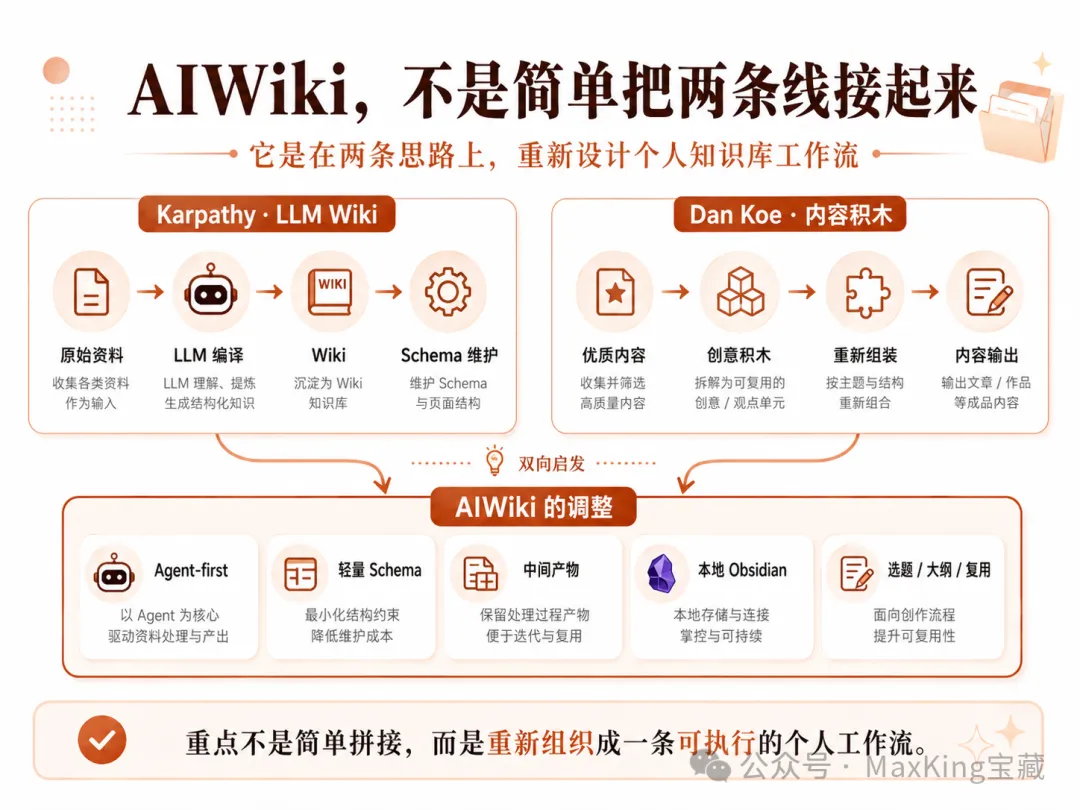
AIWiki唔係憑空想出嚟,背後有兩條重要嘅方法線。第一條係Karpathy提到嘅LLM Wiki。佢唔係簡單將資料掉畀AI問答,而係將原始資料畀LLM讀取、整理、交叉關聯,然後編譯成一個可以長期維護嘅Wiki。
LLM Wiki的關鍵不是總結,而是編譯
第二條係Dan Koe嘅內容生產方法。佢嘅啟發唔係改標題,而係將一個好嘅內容拆成觀點、案例、比喻、結構等「創意積木」,再結合自己經驗重新組裝成新表達。
內容積木:拆解好內容,再重組成自己嘅表達
我們真正需要的,不是一個更會總結的聊天框,而是一套能把資料長期編譯成知識庫的工作流
AIWiki:將資料入庫變成內容資產
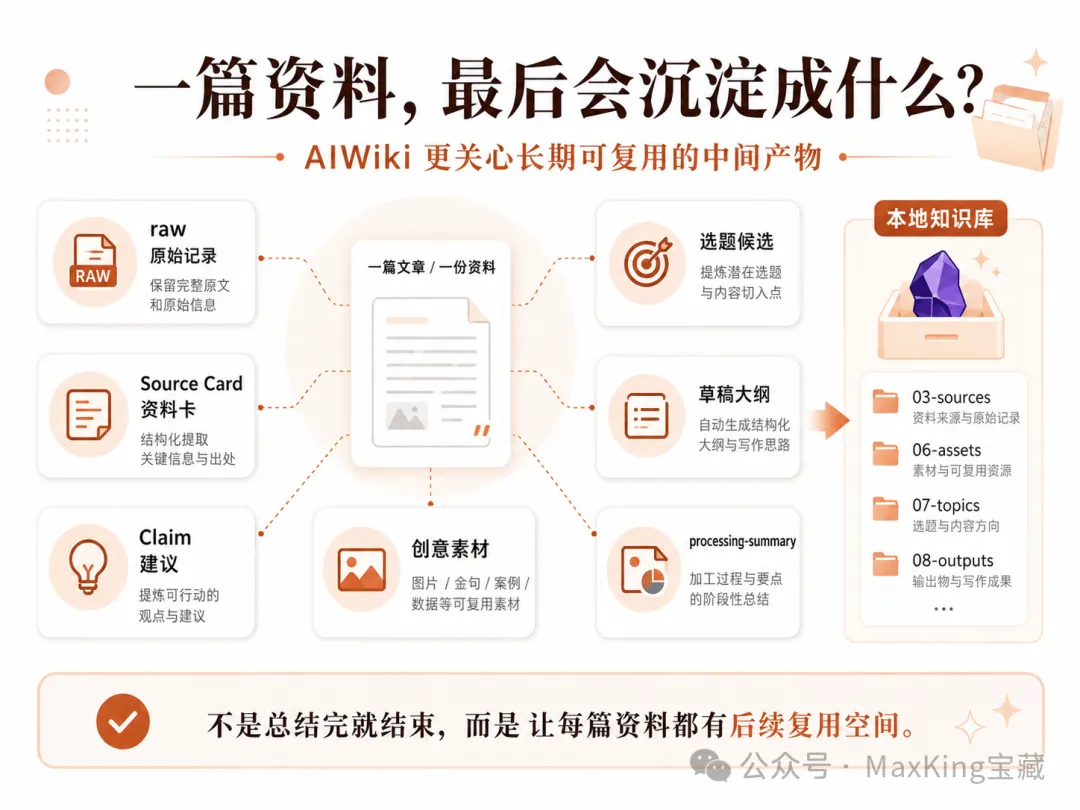
基於呢個思路,Max King開發咗開源工具AIWiki。佢前半段解決資料點樣入庫:宿主Agent讀取網頁內容,AIWiki生成資料卡同處理記錄,再寫入本地Obsidian知識庫。
- 原始記錄:方便追溯來源
- Source Card:方便快速理解文章
- Claim建議:方便後面做觀點同證據管理
- 創意素材:方便未來寫作時調用
- 選題候選:持續產生內容方向
- 草稿大綱:將資料轉成輸出
呢啲產物令一篇文章唔係「被總結咗一下」,而係真係進入咗你嘅知識庫。
不是被總結了一下,而是真的進入了你的知識庫
選擇Obsidian係因為個人知識庫唔應該完全依賴在線平台,本地Markdown文件自己可控,目錄結構清楚。
個人知識庫呢件事,唔應該完全依賴某一個在線平台
AIWiki不是萬能工具,唔會繞過登錄牆、付費牆
共創測試:一齊跑通第一篇入庫
而家AIWiki已經開源並發佈到npm,Max King正在做第一輪共創測試。測試唔追求功能多,重點係令真實用戶跑通自己嘅第一篇資料入庫。
- 1 安裝順唔順?Node環境會唔會卡住?
- 2 Obsidian路徑點樣配置最舒服?
- 3 Agent調用AIWiki係咪順手?
- 4 生成嘅資料卡、選題同大綱有冇用?
- 5 邊啲字段應該保留,邊啲其實冇必要?
如果你都有用Obsidian、Agent、AI知識庫,或者成日收藏資料但用唔起,可以揀一篇自己收藏嘅文章,跟住流程跑一次。
更關心的是你有沒有安裝成功,被哪一步卡住了
不是為了證明它已經完美,而是希望和第一批用戶一起,把這套 AI 知識庫入庫流程跑順
哈囉,大家好,我係 Max King。
我以前有個習慣:見到一篇好嘅文章,就會先收藏。
公眾號會收藏嚇,瀏覽器又收藏嚇,微信轉發俾自己,Obsidian 都有時存低啲。
當時覺得:呢篇第時一定用得着,呢個觀點唔錯,之後可以寫文章,呢個案例好好,之後做選題都用得。
但真實情況係,收藏完之後,基本上就冇咗下文。
等到真係要寫文章、做選題、整理方案嘅時候,又係重新去翻聊天記錄,重新打開收藏夾,重新揾返嗰篇「我記得之前睇過」嘅文章。
好多人唔係唔夠資料,而係資料冇進入生產流程。
資料明明好多,但真係用得着嘅好少。收藏夾越嚟越滿,個腦反而越嚟越亂。
01
-MaxKing.cc-
收藏越多,反而越寫唔到出嚟
呢幾年資訊真係太多喇。
每日都有新嘅 AI 工具、新嘅工作流程、新嘅項目、新嘅觀點。尤其係做內容、做產品、做知識庫嘅人,好容易進入一種狀態:
見到咩都覺得有用。
但係真係要用嘅時候,又唔知由邊度開始。
我以前都以為問題係「資料仲未夠多”。
所以見到好嘅內容就不停收藏,見到人哋推薦嘅資料就繼續保存,見到一個項目就先 Star,見到一篇長文就掉咗入稍後閲讀先。
但時間耐咗就會發現,問題根本唔係資料少。
資料只係俾你「儲存咗」,但冇被整理、冇被拆解、冇被歸檔,亦都冇變成選題同可以重用嘅素材。
所以你收藏嘅唔係知識庫。
好多時候,只係一個越嚟越大嘅資料堆。
02
-MaxKing.cc-
AI 總結有用,但仲未夠
後嚟有咗 AI,情況好咗少少。
一篇文章太長,可以叫 AI 總結。一個網頁太複雜,可以叫 AI 提煉重點。一個項目睇唔明,可以叫 AI 幫你拆結構。
呢樣確實有用。
但係我慢慢發現,AI 總結都有一個問題:
總結完之後,佢仲係留喺聊天記錄嗰度。
今日總結咗一篇,聽日總結咗一篇,後日又叫 AI 拆咗一個 GitHub 項目。
每次睇落都好似好清楚,但過幾日再揾返,都係好難重用。
因為佢冇進入一個穩定嘅知識庫結構入面。
冇來源記錄,冇資料卡,冇選題沉澱,冇大綱沉澱,亦都冇後續覆盤。
所以我後嚟意識到,真正需要解決嘅唔係「AI 識唔識得總結」。
而係:總結之後,資料要去邊度?佢點樣沉澱?之後點樣再被使用?
03
-MaxKing.cc-
真正缺嘅係一套入庫流程
唔係每一篇文章都要變成正式筆記,亦都唔係每一個連結都要變成完整 Wiki 頁面。
但至少要有個流程,將資料由「睇過」變成「可以用得返」。
例如一篇文章入咗嚟之後,最好可以自動變成呢啲嘢:
資料輸入
↓
AI 處理
↓
結構化入庫
↓
Obsidian 審閲
↓
選題 / 大綱 / 寫作重用
原始內容要保留,方便之後追溯。
核心觀點要抽返出嚟,方便快速回顧。
有價值嘅句子、案例、角度,要變成素材。
如果適合寫文章,要生成選題;如果選題比較明確,仲可以生成文章大綱。
呢個先至係我想要嘅 AI 知識庫。
唔係一個更大嘅收藏夾,而係一套可以將資料慢慢變成內容資產嘅工作流程。
04
-MaxKing.cc-
呢個思路唔係憑空諗出嚟嘅
AIWiki 唔係我求其諗出嚟嘅。
佢背後有兩條線,對我好有影響。
一條係 Karpathy 提到嘅 LLM Wiki。
我理解嘅 LLM Wiki,唔係簡單嘅「將資料掉俾 AI 問答」,亦唔係普通嘅 RAG。
普通 RAG 比較似:你將資料放咗入去,等你問嘅時候,系統先去揾相關片段,然後臨時砌一個答案。
呢個方法當然有用。但問題係,每次問問題,AI 都好似喺度重新翻資料。
佢冇真正將知識沉澱落嚟,亦都冇形成一個會長期變厚、會不斷更新、會互相關聯嘅知識結構。
原始資料
↓
LLM 讀取、整理、交叉關聯
↓
編譯成可以維護嘅 Wiki
↓
用 Schema 約束結構同規則
呢度我覺得最關鍵嘅唔係「總結」,而係 編譯。
原始資料係 raw source。LLM 唔單止係抽幾句說話,而係將資料編譯成一個可以長期維護嘅 Wiki。
Schema 就負責約束呢個 Wiki 應該點樣組織、點樣命名、點樣維護、點樣繼續更新。
呢樣俾咗我一個好大嘅提醒:
我哋真正需要嘅,唔係一個更識得總結嘅聊天框,而係一套可以將資料長期編譯成知識庫嘅工作流程。
另一條線,係 Dan Koe 嘅內容生產方法。
Dan Koe 對我嘅啟發,唔係簡單嘅「點樣寫爆款標題」。
而係佢對內容嘅拆解方式。
一個好嘅內容,唔應該只係睇完就算。
佢裏面往往有好多可以拆出嚟嘅嘢:觀點、案例、比喻、結構、衝突、表達方式、選題角度。
呢啲嘢可以理解成 創意積木。
你唔係照搬人哋嘅內容,而係將好嘅內容拆成積木,再結合自己嘅經驗、項目、觀點,重新組裝成新嘅表達。
05
-MaxKing.cc-
AIWiki 唔係簡單拼埋兩套方法
呢度我覺得要講清楚。
AIWiki 唔係簡單咁將 Karpathy 嘅 LLM Wiki 同 Dan Koe 嘅內容積木拼埋一齊。
如果只係拼嚇,其實冇咩價值。
因為呢兩條線原本解決嘅問題唔完全一樣。
所以 AIWiki 做咗幾層調整。
AIWiki 做嘅 4 層調整
1. Agent-first:網頁讀取交俾 Agent,AIWiki 專注後半段入庫。
2. 唔急住生成正式 Wiki:先生成資料卡、素材、選題、大綱呢啲中間產物。
3. 輕 Schema 約束:用目錄、frontmatter、文件類型同處理記錄保持結構。
4. 面向內容再生產:唔單止沉澱資料,仲要令資料可以變成選題同大綱。
重點唔係「連接」,而係重新組合成一條可以執行嘅個人工作流程。
06
-MaxKing.cc-
所以我整咗 AIWiki
基於呢個思路,我做咗一個開源工具,叫 AIWiki。
佢唔係普通摘要工具,亦都唔係網頁爬蟲。
我更願意將佢理解成:
一個受 LLM Wiki 同內容積木方法啟發,但係面向個人知識庫同內容生產重新設計嘅開源工具。
佢前半段解決資料點樣入庫:
文章連結 / 網頁正文 / 收藏資料
↓
宿主 Agent 讀取內容
↓
AIWiki 生成資料卡同處理記錄
↓
寫入本地 Obsidian 知識庫
佢後半段解決資料點樣再用返:
資料卡
↓
創意素材
↓
選題候選
↓
文章大綱 / 寫作重用
呢個亦都係點解 AIWiki 唔係淨係輸出一段摘要。
一段摘要睇落好快,但好難長期重用。
咁樣一嚟,一篇文章就唔係「被總結咗一下」。
佢係真係入咗你個知識庫。
07
-MaxKing.cc-
點解我揀 Obsidian?
因為我一直覺得,個人知識庫呢樣嘢,唔應該完全依賴某一個在線平台。
好多資料、筆記、選題、想法,其實都屬於長期資產。
放喺本地,自己可控,之後想搬走都方便。
Obsidian 本身係 Markdown 檔案,目錄結構清楚,亦都適合做長期知識管理。
AIWiki 而家預設都係圍繞 Obsidian 嚟設計嘅。
佢會將資料寫成本地 Markdown 檔案,並且配合目錄結構、frontmatter 同 Dataview 看板,令你之後可以繼續審閲同整理。

當然,AIWiki 本質上生成嘅係 Markdown 同本地檔案結構。你唔一定要深度使用 Obsidian,但如果你本身已經用緊 Obsidian,佢會更順手。
08
-MaxKing.cc-
AIWiki 唔係萬能工具
呢度都要講清楚。
AIWiki 唔係萬能網頁爬蟲。
佢唔保證所有網站都可以讀取成功,亦都唔會去繞過登入牆、付費牆、反爬限制。
因為我唔想將佢做成一個周圍抓網頁嘅工具。
呢個方向好容易越做越複雜,亦都好容易偏離真正嘅目標。
09
-MaxKing.cc-
點解揀開源?
原因都好簡單。
呢類工具唔係我一個人閉門造車就可以做好嘅。
唔同嘅人資料來源唔一樣。
有人主要睇公眾號文章,有人主要睇英文技術文檔,有人整理 GitHub 項目,有人想做自媒體選題,有人想搭建自己嘅 Obsidian 知識庫,亦都有人想幫團隊做資料流轉。
如果唔俾真實用戶去試,好多問題根本發現唔到。
我而家最想驗證嘅問題
1. 安裝係咪複雜?Node 環境會唔會卡住?
2. Obsidian 路徑點樣配置最舒服?
3. Agent 調用 AIWiki 係咪順手?
4. 生成嘅資料卡、選題同大綱有冇用?
5. 邊啲字段應該保留,邊啲其實冇必要?
呢啲問題,只有真實行過先知。
所以我將 AIWiki 開源咗出嚟,令有興趣嘅人可以直接試。
唔係為咗證明佢已經完美,而係希望同第一批用戶一齊,將呢套 AI 知識庫入庫流程行順。
10
-MaxKing.cc-
我希望佢最終解決啲乜嘢問題?
我希望 AIWiki 最終解決嘅,唔止係「幫你總結一篇文章」。
而係幫你建立一套更穩定嘅資料生產流程。
之後你見到一篇文章,唔再淨係收藏,而係可以令佢入咗你個知識庫。
一篇文章
↓
資料卡
↓
選題
↓
文章大綱
↓
長期內容資產
長遠落嚟,你個知識庫就唔止係儲資料,而係不斷生成可以重用嘅內容資產。
呢個亦都係我做 AIWiki 嘅核心原因。
我唔想再將資料一篇篇咁掉入收藏夾,然後以後都唔睇。
我想令資料真正流動起嚟。
由收藏,到入庫;由入庫,到選題;由選題,到大綱;由大綱,到輸出。
而家正在做共創測試
目前 AIWiki 已經開源,亦都發佈咗上 npm。
而家我正做緊第一輪共創測試。呢輪測試唔追求功能多,亦唔追求流程睇落有幾高級。
重點得一樣嘢:令真實用戶行通自己嘅第一篇資料入庫。
如果你都用緊 Obsidian、Agent、AI 知識庫,或者成日收藏資料但用唔返,可以 send 私訊俾我:AIWiki,睇嚇項目地址同共創說明。

期待你嘅參與
如果你願意測試,可以揀一篇自己收藏咗好耐嘅文章,或者一篇最近覺得有價值嘅資料,叫 AIWiki 行一次完整流程。
我更關心嘅係:
1. 你有冇安裝成功?
2. 俾邊一步卡住咗?
3. 生成嘅資料卡、素材、選題、大綱有冇用?
我之後會揀一啲典型問題,匿名整理成文章繼續覆盤。
下一篇預告
下一篇我會繼續拆:AIWiki 點樣由一篇文章連結開始,行通第一次 Obsidian 知識庫入庫。
- END -
關於 MaxKing 寶藏
我係 MaxKing,全棧開發者、量化交易實踐者,亦係 AI 重度用戶。呢度分享嘅唔係遙遠概念,而係我喺真實使用、搭建同踩坑之後留下嘅判斷。
之後我會繼續記錄 AI 點樣進入真實開發、產品交付、知識管理同自動化工作流程。
哈嘍,大家好,我是 Max King。
我以前一直有個習慣:看到一篇不錯的文章,先收藏。
公眾號收藏一下,瀏覽器收藏一下,微信裏轉發給自己,Obsidian 裏也偶爾存一點。
當時的感覺是:這篇以後肯定用得上,這個觀點不錯,以後可以寫文章,這個案例很好,後面做選題能用。
但真實情況是,收藏完之後,基本就沒有然後了。
等到真正要寫文章、做選題、整理方案的時候,還是重新去翻聊天記錄,重新打開收藏夾,重新找那篇“我記得之前看過”的文章。
很多人不是缺資料,而是資料沒有進入生產流程。
資料明明很多,但真正能用的很少。收藏夾越來越滿,腦子反而越來越亂。
01
-MaxKing.cc-
收藏越多,反而越寫不出來
這幾年信息確實太多了。
每天都有新的 AI 工具、新的工作流、新的項目、新的觀點。尤其是做內容、做產品、做知識庫的人,很容易進入一種狀態:
看到什麼都覺得有用。
但真正要用的時候,又不知道從哪裏開始。
我以前也以為問題是“資料還不夠多”。
所以看到好的內容就繼續收藏,看到別人推薦的資料就繼續保存,看到一個項目就先 Star,看到一篇長文就先丟進稍後閲讀。
但時間久了會發現,問題根本不是資料少。
資料只是被你“存起來了”,但沒有被整理、沒有被拆解、沒有被歸檔,也沒有變成選題和可以複用的素材。
所以你收藏的不是知識庫。
很多時候,只是一個越來越大的資料堆。
02
-MaxKing.cc-
AI 總結有用,但還不夠
後來有了 AI,情況好了一點。
一篇文章太長,可以讓 AI 總結。一個網頁太複雜,可以讓 AI 提煉要點。一個項目看不懂,可以讓 AI 幫你拆結構。
這確實有用。
但我慢慢發現,AI 總結也有一個問題:
總結完之後,它還是留在聊天記錄裏。
今天總結了一篇,明天總結了一篇,後天又讓 AI 拆了一個 GitHub 項目。
每次看起來都挺清楚,但過幾天再找,還是很難複用。
因為它沒有進入一個穩定的知識庫結構裏。
沒有來源記錄,沒有資料卡,沒有選題沉澱,沒有大綱沉澱,也沒有後續覆盤。
所以我後來意識到,真正需要解決的不是“AI 會不會總結”。
而是:總結之後,資料要去哪裏?它怎麼沉澱?以後怎麼再被使用?
03
-MaxKing.cc-
真正缺的是一套入庫流程
不是每一篇文章都要變成正式筆記,也不是每一個連結都要變成完整 Wiki 頁面。
但至少要有一個流程,把資料從“看過”變成“可複用”。
比如一篇文章進來之後,最好能自動變成這些東西:
資料輸入
↓
AI 處理
↓
結構化入庫
↓
Obsidian 審閲
↓
選題 / 大綱 / 寫作複用
原始內容要保留,方便以後追溯。
核心觀點要提出來,方便快速回看。
有價值的句子、案例、角度,要變成素材。
如果適合寫文章,要生成選題;如果選題比較明確,還可以生成文章大綱。
這才是我想要的 AI 知識庫。
不是一個更大的收藏夾,而是一套能把資料慢慢變成內容資產的工作流。
04
-MaxKing.cc-
這個思路不是憑空想的
AIWiki 不是我拍腦袋想出來的。
它背後有兩條線,對我影響很大。
一條是 Karpathy 提到的 LLM Wiki。
我理解的 LLM Wiki,不是簡單的“把資料丟給 AI 問答”,也不是普通的 RAG。
普通 RAG 更像是:你把資料放進去,等你提問的時候,系統再去找相關片段,然後臨時拼一個答案。
這個方法當然有用。但問題是,每次問問題,AI 都像是在重新翻資料。
它沒有真正把知識沉澱下來,也沒有形成一個會長期變厚、會不斷更新、會彼此關聯的知識結構。
原始資料
↓
LLM 讀取、整理、交叉關聯
↓
編譯成可維護的 Wiki
↓
用 Schema 約束結構和規則
這裏面我覺得最關鍵的不是“總結”,而是 編譯。
原始資料是 raw source。LLM 不只是摘幾句話,而是把資料編譯成一個可以長期維護的 Wiki。
Schema 則負責約束這個 Wiki 應該怎麼組織、怎麼命名、怎麼維護、怎麼繼續更新。
這給了我一個很大的提醒:
我們真正需要的,不是一個更會總結的聊天框,而是一套能把資料長期編譯成知識庫的工作流。
另一條線,是 Dan Koe 的內容生產方法。
Dan Koe 對我的啓發,不是簡單的“怎麼寫爆款標題”。
而是他對內容的拆解方式。
一個好的內容,不應該只是看完就過去了。
它裏面往往有很多可以拆出來的東西:觀點、案例、比喻、結構、衝突、表達方式、選題角度。
這些東西可以理解成 創意積木。
你不是照搬別人的內容,而是把好的內容拆成積木,再結合自己的經驗、項目、觀點,重新組裝成新的表達。
05
-MaxKing.cc-
AIWiki 不是簡單拼接兩套方法
這裏我覺得要說清楚。
AIWiki 不是簡單地把 Karpathy 的 LLM Wiki 和 Dan Koe 的內容積木拼在一起。
如果只是拼一下,其實沒什麼價值。
因為這兩條線原本解決的問題不完全一樣。
所以 AIWiki 做了幾層調整。
AIWiki 做的 4 層調整
1. Agent-first:網頁讀取交給 Agent,AIWiki 專注後半段入庫。
2. 不急着生成正式 Wiki:先生成資料卡、素材、選題、大綱這些中間產物。
3. 輕 Schema 約束:用目錄、frontmatter、文件類型和處理記錄保持結構。
4. 面向內容再生產:不僅沉澱資料,還要讓資料能變成選題和大綱。
重點不是“連接”,而是重新組織成一條可執行的個人工作流。
06
-MaxKing.cc-
所以我做了 AIWiki
基於這個思路,我做了一個開源工具,叫 AIWiki。
它不是普通摘要工具,也不是網頁爬蟲。
我更願意把它理解成:
一個受 LLM Wiki 和內容積木方法啓發,但面向個人知識庫和內容生產重新設計的開源工具。
它前半段解決資料怎麼入庫:
文章連結 / 網頁正文 / 收藏資料
↓
宿主 Agent 讀取內容
↓
AIWiki 生成資料卡和處理記錄
↓
寫入本地 Obsidian 知識庫
它後半段解決資料怎麼再使用:
資料卡
↓
創意素材
↓
選題候選
↓
文章大綱 / 寫作複用
這也是為什麼 AIWiki 不是隻輸出一段摘要。
一段摘要看起來很快,但很難長期複用。
這樣一來,一篇文章就不是“被總結了一下”。
它是真的進入了你的知識庫。
07
-MaxKing.cc-
為什麼我選擇 Obsidian?
因為我一直覺得,個人知識庫這件事,不應該完全依賴某一個在線平台。
很多資料、筆記、選題、想法,其實都屬於長期資產。
放在本地,自己可控,後面想遷移也方便。
Obsidian 本身就是 Markdown 文件,目錄結構清楚,也適合做長期知識管理。
AIWiki 現在默認也是圍繞 Obsidian 來設計的。
它會把資料寫成本地 Markdown 文件,並且配合目錄結構、frontmatter 和 Dataview 看板,讓你後面可以繼續審閲和整理。
當然,AIWiki 本質上生成的是 Markdown 和本地文件結構。你不一定非要深度使用 Obsidian,但如果你本來就在用 Obsidian,它會更順手。
08
-MaxKing.cc-
AIWiki 不是萬能工具
這裏也要說清楚。
AIWiki 不是萬能網頁爬蟲。
它不承諾所有網站都能讀取成功,也不會去繞過登錄牆、付費牆、反爬限制。
因為我不想把它做成一個到處抓網頁的工具。
這個方向很容易越做越複雜,也很容易偏離真正的目標。
09
-MaxKing.cc-
為什麼選擇開源?
原因也很簡單。
這類工具不是我一個人閉門造車就能做好的。
不同人的資料來源不一樣。
有的人主要看公眾號文章,有的人主要看英文技術文檔,有的人整理 GitHub 項目,有的人想做自媒體選題,有的人想搭自己的 Obsidian 知識庫,也有人想給團隊做資料流轉。
如果不讓真實用戶來跑,很多問題根本發現不了。
我現在最想驗證的問題
1. 安裝是不是複雜?Node 環境會不會卡住?
2. Obsidian 路徑怎麼配置最舒服?
3. Agent 調用 AIWiki 是否順手?
4. 生成的資料卡、選題和大綱有沒有用?
5. 哪些字段應該保留,哪些其實沒必要?
這些問題,只有真實跑起來才知道。
所以我先把 AIWiki 開源出來,讓感興趣的人可以直接試。
不是為了證明它已經完美,而是希望和第一批用戶一起,把這套 AI 知識庫入庫流程跑順。
10
-MaxKing.cc-
我希望它最終解決什麼問題?
我希望 AIWiki 最終解決的,不只是“幫你總結一篇文章”。
而是幫你建立一套更穩定的資料生產流程。
以後你看到一篇文章,不再只是收藏,而是可以讓它進入你的知識庫。
一篇文章
↓
資料卡
↓
選題
↓
文章大綱
↓
長期內容資產
長期下來,你的知識庫就不只是存資料,而是在不斷生成可複用的內容資產。
這也是我做 AIWiki 的核心原因。
我不想再把資料一篇篇丟進收藏夾裏,然後再也不看。
我想讓資料真正流動起來。
從收藏,到入庫;從入庫,到選題;從選題,到大綱;從大綱,到輸出。
現在正在做共創測試
目前 AIWiki 已經開源,也發佈到了 npm。
現在我正在做第一輪共創測試。這輪測試不追求功能多,也不追求流程看起來多高級。
重點就一件事:讓真實用戶跑通自己的第一篇資料入庫。
如果你也在用 Obsidian、Agent、AI 知識庫,或者經常收藏資料但用不起來,可以給我發送私信:AIWiki,查看項目地址和共創說明。
期待您的參與
如果你願意測試,可以先選一篇自己收藏很久的文章,或者一篇最近覺得有價值的資料,讓 AIWiki 跑一次完整流程。
我更關心的是:
1. 你有沒有安裝成功?
2. 被哪一步卡住了?
3. 生成的資料卡、素材、選題、大綱有沒有用?
我後面會挑一些典型問題,匿名整理成文章繼續覆盤。
下一篇預告
下一篇我會繼續拆:AIWiki 怎麼從一篇文章連結開始,跑通第一次 Obsidian 知識庫入庫。
- END -
關於 MaxKing寶藏
我是 MaxKing,全棧開發者、量化交易實踐者,也是 AI 重度用戶。這裏分享的不是遙遠概念,而是我在真實使用、搭建和踩坑後留下的判斷。
後面我會繼續記錄 AI 如何進入真實開發、產品交付、知識管理和自動化工作流。