別再瞎找需求了:我用 OpenClaw 搭了一套 11 步全自動挖掘系統
整理版優先睇
孟健用 OpenClaw 搭咗一套 11 步全自動需求挖掘系統,每日自動跑出機會清單
呢篇文章係由孟健分享嘅實戰經驗,佢用 OpenClaw 搭建咗一套全自動需求挖掘系統,每日朝早自動產出一份機會清單,幫獨立開發者解決「唔知做咩好」嘅問題。作者指出,2026 年開發者嘅核心瓶頸已經由「唔識做」轉向「唔知做乜」,而呢套系統嘅目的就係用 AI 幫手處理判斷之前嘅所有 dirty work——收集、清洗、驗證、分級,等人可以集中做決策。
整套系統總共有 11 步,分兩條發現入口(搜索 Trends 同社區信號),最後統一用一條判斷鏈嚟篩選。系統每日自動執行,成本大約每月 $60-90,比 Ahrefs 呢類工具平好多,但拎到嘅係每日更新、經過完整驗證嘅機會清單。作者強調,社區信號(HN、GitHub、Reddit)往往比搜索趨勢早 3-6 個月,但必須經過 Trends 驗證先可以納入 Shortlist,避免被 Reddit 嘅噪音誤導。
最終結論係:AI 最值錢嘅用法唔係代替你思考,而係幫你跑完思考之前嘅嗰啲 dirty work。Agent 負責跑數據,人負責做判斷,呢個先係正確嘅分工。
- 系統 11 步,兩個發現入口(搜索 Trends + 社區信號),一條統一判斷鏈,每日 cron job 自動執行。
- 新詞發現用 Google Trends 計算 3 個指標(avg_ratio、last_ratio、slope)過濾品牌詞、娛樂詞、成熟大詞。
- 老詞篩選從關鍵詞數據庫拎被低估嘅詞,按 search_volume / KD 排序,過濾難度低而搜索量高嘅機會。
- 社區信號層(HN、GitHub、Tavily)比搜索趨勢早 3-6 個月,但必須迴流到 Trends 驗證先入 Shortlist。
- SERP 競爭分析係最終把關,用大站/niche 比例決定是否可切入,成本每月 $60-90,比 Ahrefs 平而且每日更新。
系統背景同核心設計
大家好,我係孟健。我用 OpenClaw 搭咗一套全自動需求挖掘系統,每日朝早起身,手機度已經躺住一份機會清單。今日我會將整套系統嘅搭建思路、每一步點做、用咩工具、睇咩指標,全部拆開嚟講。你可以直接跟住嚟搭一套。
- 1 種子詞 → ① 新詞發現(Google Trends)→ ② 老詞篩選(關鍵詞數據庫)→ ③ 第一次合併
- 2 ④ Hacker News 信號掃描 → ⑤ GitHub 信號掃描 → ⑥ Tavily 社區驗證
- 3 ⑦ 社區詞 → Trends 橋接 → ⑧ 社區詞趨勢驗證 → ⑨ 第二次合併
- 4 ⑩ SERP 競爭分析 → ⑪ 最終分級 shortlist
種子詞、新詞發現同老詞篩選
所有需求挖掘嘅起點都係種子詞。種子詞唔係「你覺得咩好」,而係你要研究嘅品類表達。作者嘅做法係維護一個 seed_roots.json 文件,裏面有 127 個根詞,每日 pipeline 自動提取。
新詞發現用 Google Trends API(pytrends),批量查詢候選詞同基準詞("gpts")做趨勢對比,計算三個核心指標:avg_ratio、last_ratio、slope。判斷標準係:last_ratio > 6 且 slope > 0 係🔥強上升信號;avg_ratio > 3 且 last_ratio > avg_ratio 係📈穩步上升;slope < 0 且 last_ratio < avg_ratio 就📉在衰退,跳過。
老詞篩選從關鍵詞數據庫(DataForSEO Keywords Data API)拎被低估嘅成熟詞,過濾條件:月搜索量 > 1000、KD < 30、唔係品牌詞同導航詞。按 search_volume / KD 排序,機會最大嘅先行。
兩條線嘅候選詞合併後自動去重,保留兩邊嘅證據。
社區信號層:HN、GitHub、Tavily
呢 part 係整套系統最有差異化嘅部分。技術社區嘅討論往往比搜索趨勢早 3-6 個月。作者用 Algolia HN Search API 掃 Hacker News,用 GitHub Search API 掃新星 repo,用 Tavily Search API 驗證 Reddit 同 Product Hunt 嘅討論。
- 1 Hacker News 掃描:用 Algolia 搜最近 30 日嘅帖子同評論,睇提及次數、討論深度、情緒。例子:"ai humanizer" 喺 HN 被高頻提到之前,Trends 上只係一條微弱上升線。
- 2 GitHub 掃描:掃最近新增 star 快嘅 repo,提取命名、topic、description。一個 repo 名就係一個需求嘅產品化表達。
- 3 Tavily 社區驗證:搜 Reddit、Product Hunt 嘅討論,瞭解用戶痛點、比較工具、抱怨啲咩。用 Tavily 代替 Reddit API 因為更省事。
SERP 競爭分析同最終分級
候選詞經過趨勢驗證同社區驗證後,仲差最關鍵一刀:SERP 競爭格局分析。用 DataForSEO SERP API 拉前 10 結果,將每個域名分類成「大站」或「niche 站」,計比例。作者維護咗 30+ 個大站列表(Wikipedia、Amazon、YouTube、Reddit、Forbes、PCMag、CNET、G2、Capterra、OpenAI、Anthropic、Figma、Canva、Adobe、Grammarly、Turnitin 等)。
判斷標準:niche ≥ 7 : big ≤ 3 🟢 SERP 對小站友好,值得繼續;niche 5-6 : big 4-5 🟡 有一定空間可觀察;niche ≤ 4 : big ≥ 6 🔴 大站鎖死,唔值得做。
最終所有詞過完整鏈路後分三類:✅ 值得繼續(SERP 可切入 + 至少兩個維度證據),⚠️ 可觀察(信號唔夠硬),❌ 唔值得做。呢輪從幾百個種子詞最後產出 13 個值得繼續,3 個可觀察。
ai character generator:月搜 22,200,KD 19,niche 7 : big 3 → ✅
email generator:last_ratio 6.25x,niche 7 : big 2 → ✅
ai detector:niche 3 : big 7 → ❌ 大站鎖死
成本、搭建指引同結語
整套系統喺 OpenClaw 上跑,腳本結構清楚:主編排腳本調用 11 個子腳本,每個步驟輸出存到 data/pipeline_results/,最終 shortlist 存到 reports/。OpenClaw cron 配置每日自動執行,結果自動發到 Telegram 羣。
scripts/
├── run_full_keyword_research_pipeline.py # 主編排腳本
├── run_new_word_pipeline.py # 新詞發現
├── run_old_word_pipeline.py # 老詞篩選
├── merge_keyword_candidates.py # 候選詞合併
├── run_hn_signal_scan.py # HN 掃描
├── run_github_signal_scan.py # GitHub 掃描
├── run_tavily_community_scan.py # Tavily 社區驗證
├── build_trend_candidates_from_community.py # 社區→Trends 橋接
├── run_community_trend_validation.py # 社區詞趨勢驗證
├── run_keyword_research_review.py # SERP 分析
├── build_final_keyword_shortlist.py # 最終分級
└── keyword_pipeline_common.py # 公共函數實際成本:每日一次大約 $2-3,一個月 $60-90。比 Ahrefs 標準訂閲($99/月)平,仲要係每日更新。DataForSEO 註冊送 $50 免費額度,夠免費跑半個多月。要自己搭嘅話,需要:OpenClaw 部署好(一台 VPS 即可)、DataForSEO 賬號、Tavily API Key、Google 賬號(pytrends 免費)、一份種子詞列表(20-50 個起步)、Python 環境。
大家好,我係孟健。
我用 OpenClaw 整咗一套全自動需求挖掘系統,每日朝早起身,手機上面已經有一份機會清單。
今日我會將成個系統嘅搭建思路、每一步點做、用咩工具、睇咩指標,全部拆開嚟講。你睇完之後可以直接跟住整一套。
先講結論:呢套系統一共有 11 步,兩個發現入口(搜尋 + 社區),一條統一判斷鏈。行喺 OpenClaw 上面,一個 cron job 每日自動執行。
種子詞
→ ① 新詞發現(Google Trends)
→ ② 老詞篩選(關鍵詞數據庫)
→ ③ 第一次合併
→ ④ Hacker News 信號掃描
→ ⑤ GitHub 信號掃描
→ ⑥ Tavily 社區驗證
→ ⑦ 社區詞 → Trends 橋接
→ ⑧ 社區詞趨勢驗證
→ ⑨ 第二次合併
→ ⑩ SERP 競爭分析
→ ⑪ 最終分級 shortlist
下面一步一步拆開嚟講。
01 第一步:準備種子詞
所有需求挖掘嘅起點都係種子詞。種子詞唔係「你覺得乜嘢好」,而係你要研究嘅品類表達。
點樣揀種子詞:
你正在做嘅領域嘅核心詞(例如做 AI 工具站,種子詞就係 ai generator、ai detector、ai editor 呢一類) 競爭對手嘅核心關鍵詞(去 Ahrefs/Semrush 睇競爭對手排名前面嘅詞) 用戶喺搜尋框裏面實際打嘅表達(Google Suggest、Answer the Public)
我嘅做法:維護一個 seed_roots.json 檔案,入面放咗 127 個根詞。每日 pipeline 行嘅時候會自動由呢度攞。
種子詞唔需要好多,但要覆蓋你關心嘅品類。後面嘅 pipeline 會自動幫你擴展。
02 新詞發現:用 Google Trends 揾緊係度起勢嘅表達
呢一步嘅目標係:由海量候選詞入面,揾到搜尋熱度緊係度上升嘅新表達。
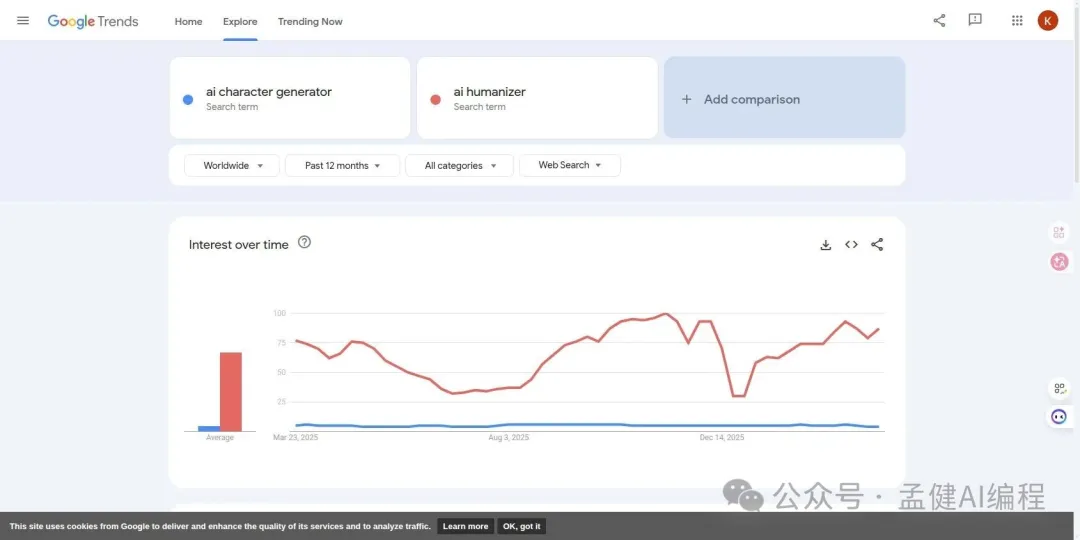
具體操作:
用 Google Trends API(pytrends 庫)批量查詢候選詞 每個詞同一個基準詞(我用嘅係「gpts」)做趨勢對比 計三個核心指標: - avg_ratio
:過去 12 個月平均搜尋量 / 基準詞平均搜尋量 - last_ratio
:最近一個月嘅比值(判斷當前勢頭) - slope
:趨勢斜率(正=喺度升,負=喺度跌)
判斷標準:
last_ratio > 6 而且 slope > 0:🔥 強上升信號 avg_ratio > 3 而且 last_ratio > avg_ratio:📈 穩步上升 slope < 0 而且 last_ratio < avg_ratio:📉 喺衰退,跳過
自動過濾三類噪音:
品牌詞(DeepSeek、ChatGPT、Midjourney)→ 呢啲係人哋嘅流量,唔係你嘅機會 娛樂詞(taylor swift、minecraft)→ 同你嘅業務無關 成熟大詞(free vpn、pdf converter)→ 已經競爭到極致
我嘅參數:每輪查詢 54 組 Trends 數據,攞 top 80 個候選詞進入下一步。
03 老詞篩選:由關鍵詞數據庫入面揾被低估嘅成熟詞
新詞線揾嘅係「緊係度升嘅」,老詞線揾嘅係「已經有量但競爭冇咁激烈嘅」。
數據源:關鍵詞數據庫(我用嘅係 DataForSEO 嘅 Keywords Data API,你都可以用 Ahrefs API 或 Semrush API)。
點樣篩:
由 127 個種子根詞出發,每個根詞攞 20 個相關詞 按以下條件過濾: 月搜尋量 > 1000(太細嘅唔值得做) KD(關鍵詞難度)< 30(太難嘅打唔過) 唔係品牌詞 唔係純導航詞(例如「gmail login」) 按 search_volume / KD 嘅比值排序——搜尋量越高、難度越低嘅詞,機會越大
我嘅參數:127 個根詞 × 20 個/根 = 最多 2540 個候選,過濾後通常剩 200-400 個。
04 第一次合併:新詞 + 老詞去重
兩條線嘅候選詞合併到一個池入面,自動去重。
呢一步好簡單但好必要。因為同一個詞可能同時被新詞線同老詞線發現,合併後保留兩邊嘅證據,唔重複計算。
05 社區信號層:HN、GitHub、Reddit
呢個係成個系統最有差異化嘅部分。技術社區嘅討論往往比搜尋趨勢早 3-6 個月。
Hacker News 掃描:
工具:Algolia HN Search API(免費,唔需要 key) 方法:用候選詞搜尋最近 30 日嘅帖同評論 睇咩:提及次數、討論深度(評論數)、情緒(正面討論 vs 吐槽) 真實例子:我喺 HN 上面發現「ai humanizer」呢個詞被高頻提到之前,Google Trends 上面佢仲係一條微弱嘅上升線
GitHub 掃描:
工具:GitHub Search API 方法:掃最近新增 star 快嘅 repo,提取命名、topic、description 價值:一個 repo 嘅名就係一個需求嘅產品化表達。例如一個 repo 叫「ai-tattoo-generator」,咁「ai tattoo generator」就係一個候選關鍵詞
Tavily 社區驗證:
工具:Tavily Search API($1 可以 search 1000 次) 方法:對候選詞搜 Reddit、Product Hunt 嘅討論 睇咩:用戶喺討論咩痛點?喺比較咩工具?喺抱怨咩? 點解唔直接用 Reddit API:Reddit API 限制多同唔穩定,Tavily 做間接抓取更省事
🔴 關鍵設計:社區詞唔直接入 shortlist。
呢個係好多人會犯嘅錯。Reddit 上面熱議唔代表有搜尋量,GitHub 上面火唔代表 SERP 可切入。
所以我設計咗一個「迴流」機制——
06 社區詞迴流驗證:補詞可以,但必須行驗證
社區發現嘅候選詞,會被重新送回 Google Trends 做趨勢驗證。
具體流程:
build_trend_candidates_from_community.py:由 HN/GitHub/Tavily 嘅結果提取候選關鍵詞 run_community_trend_validation.py:跟新詞線用同一套 Trends 邏輯驗證(avg_ratio、last_ratio、slope) 驗證通過嘅詞併入主候選池(第二次 merge)
點解要咁設計:
來源可以好多,但判斷標準必須統一。唔理詞係由 Trends 發現嘅定係由 Reddit 撈到嘅,最後都要過同一條驗證鏈。
呢步嘅意義:社區層既可以補詞,亦必須將補出嚟嘅詞迴流到統一判斷鏈路。
07 SERP 主判斷:邊個喺前排決定一切
到呢一步,候選詞已經經過咗趨勢驗證 + 社區驗證。但仲差最關鍵嘅一刀:SERP 競爭格局分析。
工具:DataForSEO SERP API($0.002/次查詢,好平)
點樣判斷:
拉前 10 個搜尋結果 將每個域名分類成「大站」或「niche 站」 算比例
大站列表(我維護咗 30+ 個):
Wikipedia、Amazon、YouTube、Reddit、Forbes、PCMag、CNET、G2、Capterra、OpenAI、Anthropic、Figma、Canva、Adobe、Grammarly、Turnitin……
判斷標準:
今日墨探(我嘅市場 Agent)跑出嚟嘅真實結果:
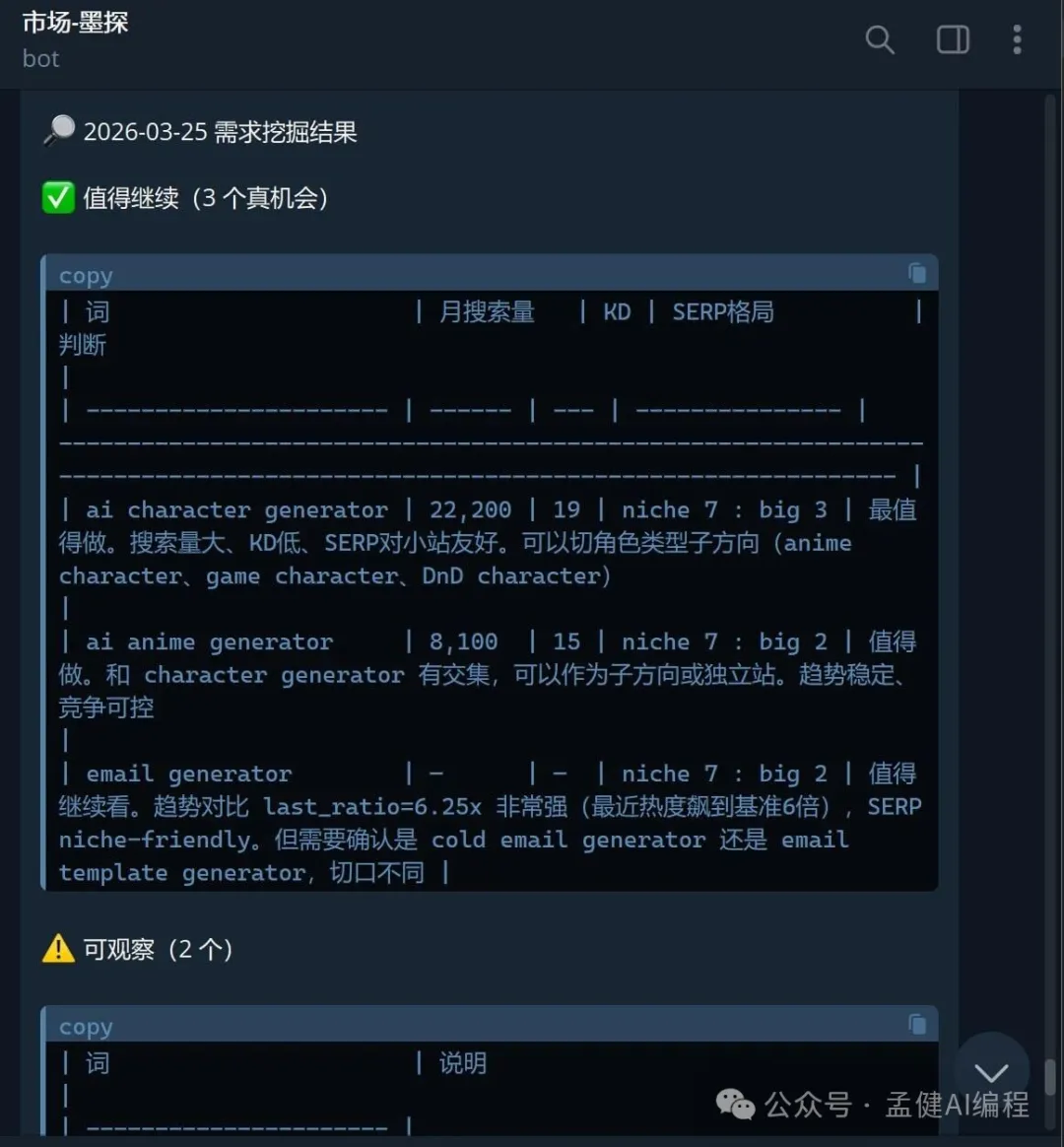
- ai character generator
:月搜 22,200,KD 19,niche 7 : big 3 → ✅ 最值得做,可以切角色類型子方向 - ai anime generator
:月搜 8,100,KD 15,niche 7 : big 2 → ✅ 值得做,趨勢穩定、競爭可控 - email generator
:last_ratio 6.25x(最近熱度飆到基準 6 倍),niche 7 : big 2 → ✅ 值得繼續睇 - ai detector
:niche 3 : big 7 → ❌ 大站鎖死 - free ai checker
:niche 2 : big 8 → ❌ 大站鎖死
08 最終分級:三個桶
所有詞過完整條鏈路後,被分成三類:
✅ 值得繼續:SERP 可切入 + 趨勢/數據/社區至少有兩個維度嘅證據。可以開始做產品規劃。
⚠️ 可觀察:有一定信號但證據唔夠硬,或者 SERP 競爭唔確定。放入觀察池,下星期再跑一次睇變化。
❌ 唔值得做:大站鎖死、品牌詞、娛樂噪音、或者趨勢緊係度跌。直接排除。
呢輪由幾百個種子詞最後產出:13 個值得繼續,3 個可觀察,其餘全部淘汰。
09 喺 OpenClaw 上面點樣跑
腳本結構:
scripts/
├── run_full_keyword_research_pipeline.py # 主編排腳本
├── run_new_word_pipeline.py # 新詞發現
├── run_old_word_pipeline.py # 老詞篩選
├── merge_keyword_candidates.py # 候選詞合併
├── run_hn_signal_scan.py # HN 掃描
├── run_github_signal_scan.py # GitHub 掃描
├── run_tavily_community_scan.py # Tavily 社區驗證
├── build_trend_candidates_from_community.py # 社區→Trends 橋接
├── run_community_trend_validation.py # 社區詞趨勢驗證
├── run_keyword_research_review.py # SERP 分析
├── build_final_keyword_shortlist.py # 最終分級
└── keyword_pipeline_common.py # 公共函數
主腳本 run_full_keyword_research_pipeline.py 按順序調用 11 個子腳本,每一步嘅輸出存到 data/pipeline_results/,最終 shortlist 存到 reports/。
OpenClaw cron 配置:
我俾市場 Agent(墨探)配咗一個 daily cron job。每日朝早自動跑完整條鏈路,跑完後自動將結果發到 Telegram 羣入面。
每一步用嘅外部 API 同實際費用:
成套 pipeline 跑一次嘅實際成本大約 $2-3。 每日跑一次,一個月都係 $60-90——比一個 Ahrefs 標準訂閲($99/月)仲平,但你得到嘅係每日更新、經過完整驗證嘅機會清單。
DataForSEO 註冊送 $50 免費額度,夠你免費跑半個多月。
10 你自己搭需要咩
如果你想跟住搭一套,需要準備嘅嘢:
- OpenClaw 部署好
(一台 VPS 就得) - DataForSEO 賬號
(註冊送 $50 額度,夠用好耐) - Tavily API Key
($1 = 1000 次搜尋) - Google 賬號
(pytrends 免費用) - 一份種子詞列表
(你嘅業務領域嘅核心關鍵詞,20-50 個起步) - Python 環境
(腳本都係 Python 寫嘅)
唔需要 Ahrefs 或 Semrush 嘅高價訂閲(嗰兩個分別係 $99/月同 $129/月起步)。成個系統嘅數據源成本每個月唔到 $12。DataForSEO 註冊就送 $50 額度,夠你跑大半年。
最後
2026 年,獨立開發者嘅核心瓶頸正喺度由「唔識做」轉向「唔知做咩」。
AI 令寫程式變容易咗,令做設計變容易咗。但「揾到一個值得做嘅方向」呢件事,仲係要靠判斷力。而判斷力需要數據支撐。
呢套系統做嘅嘢就係:令 AI 幫你跑完判斷之前嘅所有 dirty work——收集、清洗、驗證、分級——你只需要睇結論、做決策。
Agent 跑數據,人做判斷。呢個先係正確嘅分工。
AI 最值錢嘅用法,唔係幫你思考,係幫你跑完思考之前嘅嗰啲 dirty work。
你而家係點樣揾需求嘅?留言區傾,我每條都睇。
🚀 想同更多 AI 愛好者交流,共同成長嗎?
📚 精選文章推薦
40 蚊/月用 4 個程式模型,我唔想再搞嚟搞去 128K Star 嘅開源 AI 程式 Agent,逼到 Anthropic 要發律師信 微信官方出手了:一條命令,OpenClaw 直接接入微信 設計師嚇親:Google Stitch 一出,Figma 兩日跌咗 12% OpenAI 收購 Astral:AI 程式唔止寫程式了,佢開始食曬成條 Python 工具鏈 我出書了:《OpenClaw 極簡入門與應用》,36 個案例手把手教你搭 AI 團隊 我用 OpenClaw 令 11 個 Agent 喺羣入面開會,覆盤自己就變強了 Creem 被封了! 得物前端部門,冇咗 3月破局行動:OpenClaw 兩場訓練營,7000人報名
大家好,我是孟健。
我用 OpenClaw 搭了一套全自動需求挖掘系統,每天早上醒來,手機上已經躺着一份機會清單。
今天把整套系統的搭建思路、每一步怎麼做、用什麼工具、看什麼指標,全部拆開講。你看完之後可以直接照着搭一套。
先說結論:這套系統一共 11 步,兩個發現入口(搜索 + 社區),一條統一判斷鏈。跑在 OpenClaw 上,一個 cron job 每天自動執行。
種子詞
→ ① 新詞發現(Google Trends)
→ ② 老詞篩選(關鍵詞數據庫)
→ ③ 第一次合併
→ ④ Hacker News 信號掃描
→ ⑤ GitHub 信號掃描
→ ⑥ Tavily 社區驗證
→ ⑦ 社區詞 → Trends 橋接
→ ⑧ 社區詞趨勢驗證
→ ⑨ 第二次合併
→ ⑩ SERP 競爭分析
→ ⑪ 最終分級 shortlist
下面一步一步拆。
01 第一步:準備種子詞
所有需求挖掘的起點都是種子詞。種子詞不是"你覺得什麼好",而是你要研究的品類表達。
怎麼選種子詞:
你正在做的領域的核心詞(比如做 AI 工具站,種子詞就是 ai generator、ai detector、ai editor 這一類) 競品的核心關鍵詞(去 Ahrefs/Semrush 看競品排名靠前的詞) 用戶在搜索框裏實際打出來的表達(Google Suggest、Answer the Public)
我的做法:維護一個 seed_roots.json 文件,裏面放了 127 個根詞。每天 pipeline 跑的時候自動從這裏面取。
種子詞不需要很多,但要覆蓋你關心的品類。後面的 pipeline 會自動幫你擴展。
02 新詞發現:用 Google Trends 找正在起勢的表達
這一步的目標是:從海量候選詞裏,找到搜索熱度正在上升的新表達。
具體操作:
用 Google Trends API(pytrends 庫)批量查詢候選詞 每個詞跟一個基準詞(我用的是 "gpts")做趨勢對比 算三個核心指標: - avg_ratio
:過去 12 個月平均搜索量 / 基準詞平均搜索量 - last_ratio
:最近一個月的比值(判斷當前勢頭) - slope
:趨勢斜率(正=在漲,負=在跌)
判斷標準:
last_ratio > 6 且 slope > 0:🔥 強上升信號 avg_ratio > 3 且 last_ratio > avg_ratio:📈 穩步上升 slope < 0 且 last_ratio < avg_ratio:📉 在衰退,跳過
自動過濾三類噪音:
品牌詞(DeepSeek、ChatGPT、Midjourney)→ 這是別人的流量,不是你的機會 娛樂詞(taylor swift、minecraft)→ 跟你的業務無關 成熟大詞(free vpn、pdf converter)→ 已經卷到極致
我的參數:每輪查詢 54 組 Trends 數據,取 top 80 個候選詞進入下一步。
03 老詞篩選:從關鍵詞數據庫裏找被低估的成熟詞
新詞線找的是"正在漲的",老詞線找的是"已經有量但競爭沒那麼激烈的"。
數據源:關鍵詞數據庫(我用的是 DataForSEO 的 Keywords Data API,你也可以用 Ahrefs API 或 Semrush API)。
怎麼篩:
從 127 個種子根詞出發,每個根詞取 20 個相關詞 按以下條件過濾: 月搜索量 > 1000(太小的不值得做) KD(關鍵詞難度)< 30(太難的打不過) 不是品牌詞 不是純導航詞(比如"gmail login") 按 search_volume / KD 的比值排序——搜索量越高、難度越低的詞,機會越大
我的參數:127 個根詞 × 20 個/根 = 最多 2540 個候選,過濾後通常剩 200-400 個。
04 第一次合併:新詞 + 老詞去重
兩條線的候選詞合併到一個池子裏,自動去重。
這一步很簡單但很必要。因為同一個詞可能同時被新詞線和老詞線發現,合併後保留兩邊的證據,不重複計算。
05 社區信號層:HN、GitHub、Reddit
這是整套系統最有差異化的部分。技術社區的討論往往比搜索趨勢早 3-6 個月。
Hacker News 掃描:
工具:Algolia HN Search API(免費,不需要 key) 方法:用候選詞搜索最近 30 天的帖子和評論 看什麼:提及次數、討論深度(評論數)、情緒(正面討論 vs 吐槽) 真實例子:我在 HN 上發現 "ai humanizer" 這個詞被高頻提到之前,Google Trends 上它還只是一條微弱的上升線
GitHub 掃描:
工具:GitHub Search API 方法:掃最近新增 star 快的 repo,提取命名、topic、description 價值:一個 repo 的名字就是一個需求的產品化表達。比如一個 repo 叫 "ai-tattoo-generator",那 "ai tattoo generator" 就是一個候選關鍵詞
Tavily 社區驗證:
工具:Tavily Search API($1 可以搜 1000 次) 方法:對候選詞搜 Reddit、Product Hunt 的討論 看什麼:用戶在討論什麼痛點?在比較什麼工具?在抱怨什麼? 為什麼不直接用 Reddit API:Reddit API 限制多且不穩定,Tavily 做間接抓取更省事
🔴 關鍵設計:社區詞不直接進 shortlist。
這是很多人會犯的錯。Reddit 上熱議不代表有搜索量,GitHub 上火不代表 SERP 可切入。
所以我設計了一個"迴流"機制——
06 社區詞迴流驗證:補詞可以,但必須走驗證
社區發現的候選詞,會被重新送回 Google Trends 做趨勢驗證。
具體流程:
build_trend_candidates_from_community.py:從 HN/GitHub/Tavily 的結果中提取候選關鍵詞 run_community_trend_validation.py:跟新詞線用同一套 Trends 邏輯驗證(avg_ratio、last_ratio、slope) 驗證通過的詞併入主候選池(第二次 merge)
為什麼要這麼設計:
來源可以很多,但判斷標準必須統一。不管詞是從 Trends 發現的還是從 Reddit 撈到的,最後都要過同一條驗證鏈。
這步的意義:社區層既能補詞,也必須把補出來的詞迴流到統一判斷鏈路。
07 SERP 主判斷:誰在前排決定一切
到這一步,候選詞已經經過了趨勢驗證 + 社區驗證。但還差最關鍵的一刀:SERP 競爭格局分析。
工具:DataForSEO SERP API($0.002/次查詢,很便宜)
怎麼判斷:
拉前 10 的搜索結果 把每個域名分類成"大站"或"niche 站" 算比例
大站列表(我維護了 30+ 個):
Wikipedia、Amazon、YouTube、Reddit、Forbes、PCMag、CNET、G2、Capterra、OpenAI、Anthropic、Figma、Canva、Adobe、Grammarly、Turnitin……
判斷標準:
今天墨探(我的市場 Agent)跑出來的真實結果:
- ai character generator
:月搜 22,200,KD 19,niche 7 : big 3 → ✅ 最值得做,可以切角色類型子方向 - ai anime generator
:月搜 8,100,KD 15,niche 7 : big 2 → ✅ 值得做,趨勢穩定、競爭可控 - email generator
:last_ratio 6.25x(最近熱度飆到基準 6 倍),niche 7 : big 2 → ✅ 值得繼續看 - ai detector
:niche 3 : big 7 → ❌ 大站鎖死 - free ai checker
:niche 2 : big 8 → ❌ 大站鎖死
08 最終分級:三個桶
所有詞過完整條鏈路後,被分成三類:
✅ 值得繼續:SERP 可切入 + 趨勢/數據/社區至少有兩個維度的證據。可以開始做產品規劃。
⚠️ 可觀察:有一定信號但證據不夠硬,或者 SERP 競爭不確定。放進觀察池,下週再跑一次看變化。
❌ 不值得做:大站鎖死、品牌詞、娛樂噪音、或者趨勢在下降。直接排除。
這輪從幾百個種子詞最後產出:13 個值得繼續,3 個可觀察,其餘全部淘汰。
09 在 OpenClaw 上怎麼跑
腳本結構:
scripts/
├── run_full_keyword_research_pipeline.py # 主編排腳本
├── run_new_word_pipeline.py # 新詞發現
├── run_old_word_pipeline.py # 老詞篩選
├── merge_keyword_candidates.py # 候選詞合併
├── run_hn_signal_scan.py # HN 掃描
├── run_github_signal_scan.py # GitHub 掃描
├── run_tavily_community_scan.py # Tavily 社區驗證
├── build_trend_candidates_from_community.py # 社區→Trends 橋接
├── run_community_trend_validation.py # 社區詞趨勢驗證
├── run_keyword_research_review.py # SERP 分析
├── build_final_keyword_shortlist.py # 最終分級
└── keyword_pipeline_common.py # 公共函數
主腳本 run_full_keyword_research_pipeline.py 按順序調用 11 個子腳本,每一步的輸出存到 data/pipeline_results/,最終 shortlist 存到 reports/。
OpenClaw cron 配置:
我給市場 Agent(墨探)配了一個 daily cron job。每天早上自動跑完整條鏈路,跑完後自動把結果發到 Telegram 羣裏。
每一步用的外部 API 和實際費用:
整套 pipeline 跑一次的實際成本大約 $2-3。 每天跑一次,一個月也就 $60-90——比一個 Ahrefs 標準訂閲($99/月)還便宜,但你拿到的是每天更新的、經過完整驗證的機會清單。
DataForSEO 註冊送 $50 免費額度,夠你免費跑半個多月。
10 你自己搭需要什麼
如果你想照着搭一套,需要準備的東西:
- OpenClaw 部署好
(一台 VPS 即可) - DataForSEO 賬號
(註冊送 $50 額度,夠用很久) - Tavily API Key
($1 = 1000 次搜索) - Google 賬號
(pytrends 免費用) - 一份種子詞列表
(你的業務領域的核心關鍵詞,20-50 個起步) - Python 環境
(腳本都是 Python 寫的)
不需要 Ahrefs 或 Semrush 的高價訂閲(那兩個分別是 $99/月和 $129/月起步)。整套系統的數據源成本每月不到 $12。DataForSEO 註冊就送 $50 額度,夠你跑大半年。
最後
2026 年,獨立開發者的核心瓶頸正在從"不會做"轉向"不知道做什麼"。
AI 讓寫代碼變容易了,讓做設計變容易了。但"找到一個值得做的方向"這件事,還是要靠判斷力。而判斷力需要數據支撐。
這套系統做的事情就是:讓 AI 幫你跑完判斷之前的所有髒活——收集、清洗、驗證、分級——你只需要看結論、做決策。
Agent 跑數據,人做判斷。這才是正確的分工。
AI 最值錢的用法,不是替你思考,是替你跑完思考之前的那些髒活。
你現在是怎麼找需求的?評論區聊,我每條都看。
🚀 想要與更多AI愛好者交流,共同成長嗎?
📚 精選文章推薦
40塊/月用4個編程模型,我不想再折騰了 128K Star 的開源 AI 編程 Agent,把 Anthropic 逼到發律師函了 微信官方出手了:一條命令,OpenClaw 直接接入微信 設計師慌了:Google Stitch 一出,Figma 兩天跌了 12% OpenAI 收購 Astral:AI 編程不止寫代碼了,它開始吃掉整條 Python 工具鏈 我出書了:《OpenClaw 極簡入門與應用》,36 個案例手把手教你搭 AI 團隊 我用 OpenClaw 讓 11 個 Agent 在羣裏開會,覆盤自己就變強了 Creem 被封了! 得物前端部門,沒了 3月破局行動:OpenClaw 兩場訓練營,7000人報名