別把 Prompt 當 Skill:AgentUse 架構與四層解耦
整理版優先睇
別把Prompt當Skill:AgentUse四層架構透過知識解耦、協議標準化、客戶端瘦身同執行循環,令Agent從聊天機械人變成可反覆修正嘅數字員工。
呢篇文章係關於AgentUse架構,作者透過一個簡單嘅技能「玩轉易萬」嘅實際結構,帶出點樣先係一個合格嘅SKILL。傳統做法成日將腳本同文檔直接塞入Prompt,搞到token消耗大、知識過時、Agent亂作。作者想解決嘅問題係:Anthropic嘅SKILL標準只定義咗格式,但冇講點樣先令一個技能喺生產環境真係行得順。整體結論係:AgentUse四層架構——Agent、SKILL.md、客戶端腳本、服務端——透過知識解耦、協議標準化同客戶端瘦身,令Agent可以反覆修正,變成真正嘅數字員工。
四層架構嘅具體分工:Agent係大腦,只負責判斷調用咩技能同組織回答,唔直接存知識;SKILL.md係協議,為Agent提供標準工作流,例如玩轉易萬嘅協議只定義三步:列目錄、選文檔、取片段;客戶端腳本係執行層,得一條500行以下嘅Python檔案,淨係做翻譯HTTP請求嘅工作,所有繁重檢索、評分、截取都交畀服務端;服務端係真正承重點,負責全文檢索、段落評分、生成片段,確保Agent拎到嘅係精選內容。
呢套架構嘅因果鏈由知識解耦開始:將知識抽離到服務端,更新文檔唔使改Agent任何部分;繼而工具標準化,統一協議令Agent唔使摸索點用每個技能;然後客戶端無限瘦,本地算力唔再限制能力;最後Agent進入執行循環,可以「查目錄→選文檔→取內容→判斷→再取」,逐步逼近最佳答案。成個設計令Agent從單輪問答進化到可以自我修正。
- AgentUse架構核心係將技能分為四層:Agent(大腦)、SKILL.md(協議)、客戶端腳本(輕量執行)、服務端(承重),實現客戶端瘦、服務端胖。
- 傳統做法將知識塞入Prompt,token消耗大且知識過時;AgentUse由服務端預先檢索評分,Agent只拎精華片段,大幅減低浪費。
- 每個技能包必須包含標準協議SKILL.md,定義明確嘅工作流步驟,令Agent唔使估點用工具。
- 知識解耦係整個架構嘅基礎:更新文檔只需要改服務端,唔使改Agent、SKILL或客戶端腳本,維護成本極低。
- 開發者可以將呢個模式擴展到任何工具——搜索、數據庫、第三方API——每個技能寫一個SKILL加一段腳本,Agent就多一隻手。
AgentUse標準協議
AgentUse架構嘅完整協議說明
Yi-One桌面Agent
玩轉易萬所屬產品
內容結構
yidocs-fetcher/├──
SKILL.md ← 一份標準的工作流協議├── scripts/│ └── fetch_docs.py ← 一段輕量的客戶端腳本└── .env ← 指向一個獨立的文檔服務端傳統做法嘅問題同一個簡單技能嘅結構
如果你已經在用Skills標準畀Agent擴展能力,你大概踩過唔少坑。網上扒一段腳本,本應塞入scripts/,卻直接貼落Prompt。API文檔放啱references/,token都係嘩嘩燒。自己寫嘅SKILL.md得幾行調用說明,Agent成日作一段唔存在嘅接口。返回格式隨機、錯誤處理隨緣。你明明跟住標準做咗三層分離(SKILL.md / references / scripts),點解仲係唔順?問題唔喺「有冇」,而喺「夠唔夠格」。
問題唔喺「有冇」,而喺「夠唔夠格」
Anthropic嘅標準只教你Skill應該係點樣,冇教你一個真正喺生產環境行得順嘅Skill,佢嘅架構應該點設計。但有一個小技能,簡單到不得了——卻將呢啲問題嘅答案,全部寫喺佢嘅目錄結構入面。呢個技能叫「玩轉易萬」,係一個Yi-One產品嘅問答智能體。佢身上只掛載一個技能:yidocs-fetcher,功能係查產品文檔。
- yidocs-fetcher/
- ├── SKILL.md ← 一份標準嘅工作流協議
- ├── scripts/
- │ └── fetch_docs.py ← 一段輕量嘅客戶端腳本
- └── .env ← 指向一個獨立嘅文檔服務端
你可能覺得呢個冇咩大不了——一個技能包唔係都係咁樣㗎咩?唔係。大多數所謂嘅「SKILL」只係將一堆命令堆埋一齊。而呢個技能嘅設計,啱啱好對應咗一套標準體系:AgentUse架構。
AgentUse四層架構:各司其職
Agent同技能之間,從來唔係「你隨便調用我」咁簡單。AgentUse將呢件事拆成四層,每層各司其職。
- 1 第一層係Agent,即係大腦。佢只做兩件事:判斷應該調用咩技能,然後根據返回嘅結果組織回答。佢唔存知識,唔跑計算。就好似一個項目經理——知道邊個做嘢,但唔自己做。
- 2 第二層係SKILL.md,一份標準嘅協議。Agent讀到佢,就知道呢個技能應該點用。例如yidocs-fetcher協議只定義三步:列出有咩文檔可用、揀一篇文檔用用戶問題去查、從返回嘅片段整理答案。三步行完,任務完成。Agent唔使估——跟住協議行。
- 3 第三層係客戶端腳本,即係執行層。一個唔夠500行嘅Python檔案,做嘅嘢極之單純:將Agent嘅意圖翻譯成HTTP請求,Send出去,等結果返嚟。佢唔解析文檔、唔算分、唔檢索——呢啲嘢佢一件都唔做。佢只係一個跑腿嘅。
- 4 第四層係服務端,真正嘅承重點。文檔存在邊?服務端。全文檢索邊個做?服務端。段落評分、片段截取、圖片連結生成——全部係服務端負責。客戶端淨係Send一個請求,服務端將加工好嘅結果畀返嚟。Agent拎到嘅永遠係精選後嘅片段,唔係整篇文檔。
四層架構嘅因果鏈:從知識解耦到執行循環
呢套架構唔係並列解決四個問題,而係一條鏈上嘅四個環。一切由知識解耦開始。傳統將文檔塞入Prompt,知識就係Agent嘅一部分。知識一過時,Agent就開始亂講。AgentUse將知識抽離到服務端:更新文檔唔使改Agent、唔使改SKILL、唔使改腳本。Agent嘅行為同知識之間,第一次有咗明確嘅邊界。
知識解耦係基礎:更新文檔唔使改Agent
呢個邊界一確立,下一環自動解鎖——工具標準化。知識喺服務端,Agent透過咩訪問佢?一個統一嘅協議。SKILL.md就係呢份協議。以前畀Agent接工具,佢唔知幾時調用、傳咩參數、期望咩輸出。而家每個技能都有同一份「說明書」,Agent唔使摸索。
工具標準化:統一協議令Agent唔使摸索
協議統一之後,第三環水到渠成——客戶端無限瘦。既然服務端承擔檢索、評分、解析,客戶端腳本就淨係做一件事:Send請求、收結果。你嘅Agent跑喺一部樹莓派上,都可以調用一個喺雲端處理海量文檔嘅技能。客戶端嘅能力唔再被本地算力限制。
客戶端無限瘦:本地算力唔再限制能力
而前三環嘅終點,係第四環——Agent進入真正嘅執行循環。唔再係「你問我答」。Agent喺「查目錄→揀文檔→取內容→判斷→再取→回答」嘅循環入面不斷修正,逼近最佳答案。知識解耦畀咗佢可更新嘅知識源,協議標準化畀咗佢可預測嘅調用方式,輕量客戶端畀咗佢無限擴展嘅能力——三層合力,先令Agent從聊天機械人變成可以反覆嘗試、自我修正嘅數字員工。
一個技能只係開始:適用所有類型AI智能體
「玩轉易萬」只有一個技能,但佢背後嗰條管道——協議、執行、服務——適用於所有類型嘅AI智能體。一個SKILL就畀Agent長出一隻手。
- Agent需要搜索能力?寫一個SKILL,配一段爬蟲腳本,對接搜索API。
- Agent需要操作數據庫?寫一個SKILL,配一段ORM腳本,對接數據庫實例。
- Agent需要飛書文檔、GitHub Issues、Jira任務、Slack消息……一個SKILL,畀Agent長出一隻手。
咪當 Prompt 係 Skill:AgentUse 架構同四層解耦
如果你已經用緊 Skills 標準嚟幫 Agent 擴展能力——你大概中過唔少伏。
喺網上抄一段 script,本來應該放入 scripts/,但係就咁貼落 Prompt 度。API 文件就放啱咗 references/,token 都係嘩嘩咁燒。自己寫嘅 SKILL.md 得幾行 calling 說明,Agent 成日作一段唔存在嘅 interface。return 格式亂咁嚟、error handling 隨緣。
你明明跟住標準做咗三層分離(SKILL.md / references / scripts),點解都係唔順?
問題唔係在於「有冇」,而係「夠唔夠格」。
Anthropic 嘅標準只係話俾你知 Skill 應該係點樣,冇話俾你知一個真係可以喺生產環境運行嘅 Skill,佢嘅架構應該點樣設計。SKILL.md 點寫先算係協議?references 點存先算係解耦?scripts 有幾瘦先算係輕量?
呢啲標準冇詳細講。但有一個小技能,簡單到不得了——但係將呢啲問題嘅答案,全部寫曬喺佢嘅目錄結構度。
一個簡單到唔起眼嘅小技能
佢叫「玩轉易萬」,係一個 Yi-One 產品嘅問答智能體。
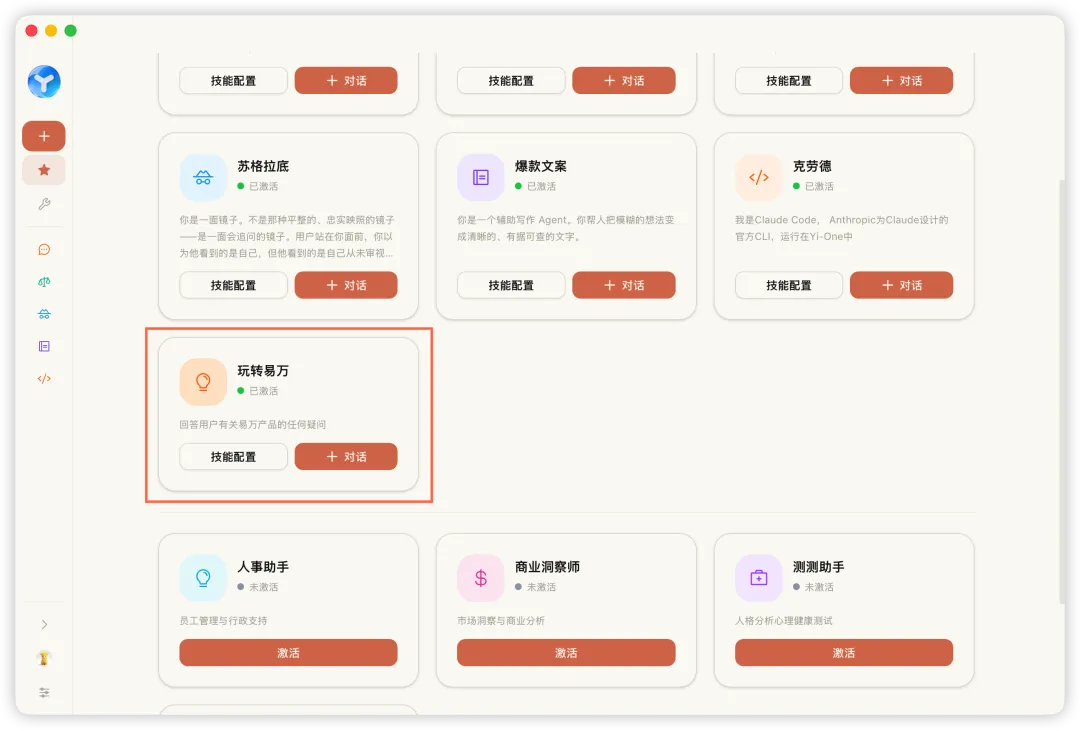
Prompt 冇乜特別——身份係「產品小助手」,語氣陽光熱情,規矩係「技能優先、文件優先」。講到尾,就係個標準嘅客服 bot。
佢身上只掛咗一個技能:yidocs-fetcher。功能都好單一:查 Yi-One 產品文件。
冇喇。就得一個技能,一個身份,一個目的。
但就係呢個簡單到容易被忽略嘅小技能,佢嘅內部結構係咁樣:
你可能覺得冇咩大不了——一個技能包唔係都係咁嘅樣?唔係。大多數所謂嘅「SKILL」只係將一大堆 command 堆埋一齊。而呢個技能嘅設計,啱啱好完美對應咗一套標準體系:AgentUse 架構。
AgentUse 架構:四層點樣各司其職
Agent 同技能之間,從來唔係「你隨便 call 我」咁簡單。AgentUse 將呢件事拆成四層:
第一層係 Agent,亦即係大腦。 佢淨係做兩件事:判斷應該 call 咩技能,然後根據 return 嘅結果組織答案。唔儲存知識,唔執行計算。就好似一個 project manager——知道揾邊個做嘢,但唔自己做。
第二層係 SKILL.md,一份標準嘅協議。 Agent 讀到佢,就知道呢個技能點樣用。yidocs-fetcher 嘅協議只定義咗三步:第一步,列出有邊啲文件可以用;第二步,揀定某篇文件,用用戶嘅問題去查;第三步,從 return 嘅片段中整理答案。三步行完,任務完成。Agent 唔使估——跟住協議行。
第三層係客戶端腳本,亦即係執行層。 一個唔夠 500 行嘅 Python file,做嘅嘢極之單純:將 Agent 嘅意圖翻譯成 HTTP request,send 出去,等結果返嚟。佢唔解析文件、唔計分、唔檢索——嗰啲嘢佢一件都唔做。佢只係一個跑腿嘅。
第四層係服務端,真正嘅承重點。 文件存在邊度?服務端。全文檢索邊個做?服務端。段落評分、片段截取、圖片連結生成——全部都係服務端負責。客戶端只係 send 一個 request,服務端將加工好嘅結果 end 返嚟。Agent 拎到嘅永遠係精選後嘅片段,唔係成篇文件。
呢個就係 AgentUse 架構嘅核心概念:
客戶端瘦,服務端肥。重嘅工作全部下沉到服務端,客戶端永遠輕量,但能力無限擴展。
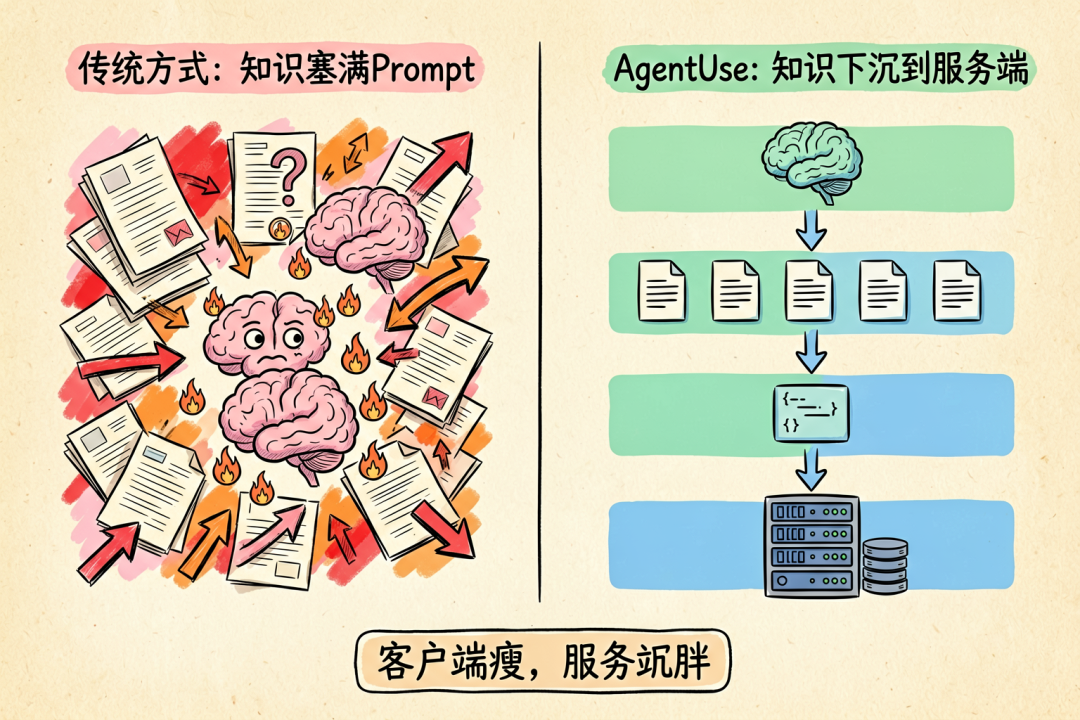
對比嚇傳統做法:Agent 直接將成篇文件塞落 Prompt,token 嘩嘩咁燒,LLM 自己做「閲讀理解」。AgentUse 嘅做法係:服務端已經讀完、揀好、裁好,Agent 淨係拎最精華嘅幾個片段。
一條完整鍊路:當用戶問「飛書點樣接入?」
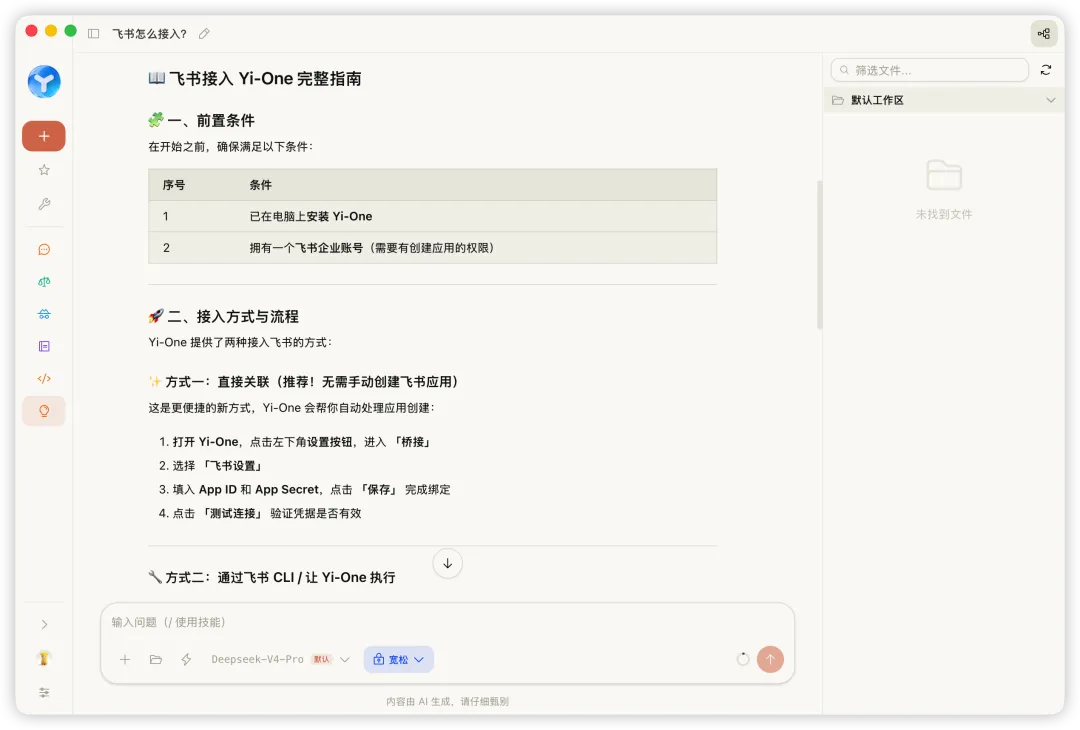
用戶拋出呢個問題嘅時候,四層依次激活:
第一步,列目錄。 Agent 判斷呢個係產品使用問題,call yidocs-fetcher。客戶端腳本向服務端請求文件目錄,return 100 幾篇文件清單。Agent 睇咗一眼,鎖定「飛書集成指南」。
第二步,拎內容。 Agent 將文件標識同問題 send 俾服務端。服務端拎出 Markdown 全文,智能切分、逐段評分,return 最相關嘅 5 個片段。
第三步,生成答案。 Agent 拎到結構化結果——標題、章節、引用內容、相關度評分——根據呢啲嘢組織答案,標明出處,分步說明。
答案唔夠充分?Agent 返去第一步,換篇文件再嚟一次。呢個唔係「一次問答」,係循環:判斷→call→拎結果→評估→再決定。
注意:Agent 揀中咗嗰篇文件,唔係靠關鍵詞匹配,係睇完 100 幾篇目錄之後自己判斷嘅。Agent 支配緊工具,唔係工具支配緊 Agent。
大腦決策,協議調度,腳本傳話,服務端扛嘢。四層各司其職。
呢套架構到底解決咗啲咩?
返去開頭提出嘅問題——一個真正合格嘅 SKILL,到底應該係點樣?
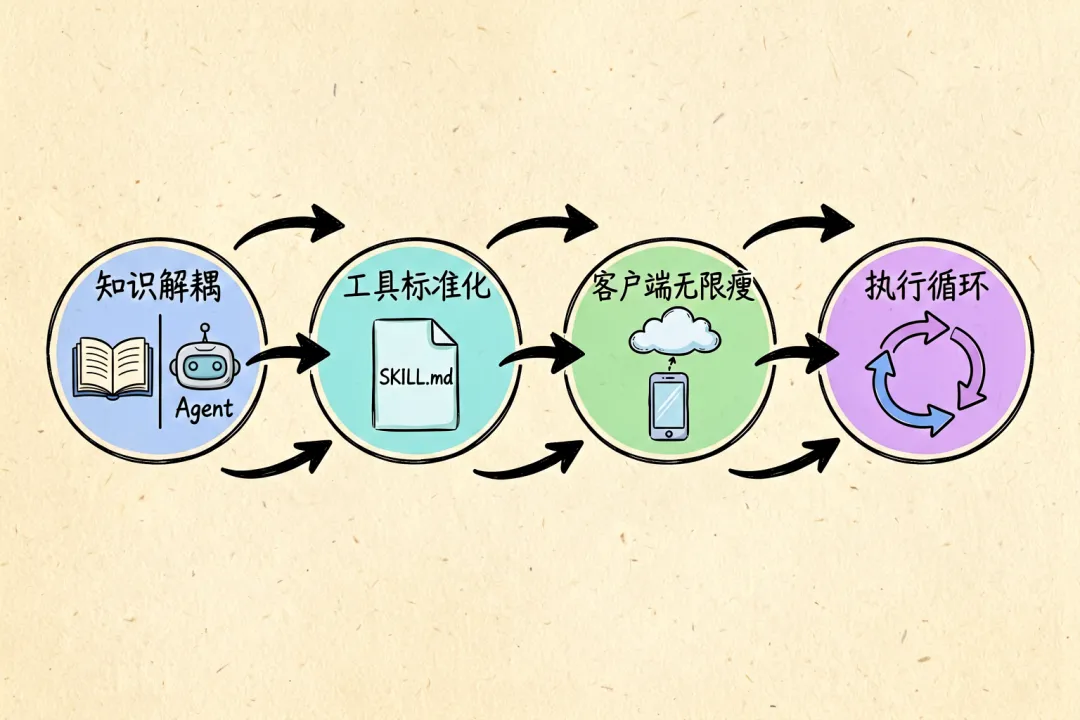
表面睇,AgentUse 解決咗「知識過時」「工具黑盒」「客戶端臃腫」「單輪問答」四個問題。但佢哋唔係並列嘅——佢哋係一條鏈上面嘅四個環。
一切從知識解耦開始。
傳統做法係將文件塞落 Prompt——知識就係 Agent 嘅一部分。知識一過時,Agent 就開始亂講。AgentUse 將知識抽離到服務端:更新文件唔需要改 Agent、唔需要改 SKILL、唔需要改腳本。Agent 嘅行為同知識之間,第一次有咗明確嘅邊界。
呢個邊界一確立,下一環自動解鎖——工具標準化。
知識喺服務端,Agent 通過咩嚟訪問佢?一個統一嘅協議。SKILL.md 就係呢份協議。以前俾 Agent 接工具,佢唔知應該幾時 call、傳咩 parameters、期望咩 output。而家每個技能都有同一份「說明書」,Agent 唔需要摸索。
協議統一之後,第三環水到渠成——客戶端無限瘦。
既然服務端承擔咗檢索、評分、解析,客戶端腳本就只需要做一件事:send request、收結果。你嘅 Agent 喺一部樹莓派上面行,都可以 call 一個喺雲端行嘅、處理大量文件嘅技能。客戶端嘅能力唔再被本地運算力限制。
而前三環嘅終點,係第四環——Agent 進入真正嘅執行循環。
唔再係「你問我答」。Agent 喺「查目錄→揀文件→拎內容→判斷→再拎→回答」嘅循環入面不斷修正,逼近最佳答案。知識解耦俾咗佢可更新嘅知識源,協議標準化俾咗佢可預測嘅 call 方式,輕量客戶端俾咗佢無限擴展嘅能力——三層合力,先至令到 Agent 從聊天機械人變成可以反覆嘗試、自我修正嘅數碼員工。
一個技能只係一個開始
「玩轉易萬」得一個技能,但佢背後嗰條管道——協議、執行、服務——適用於所有類型嘅 AI 智能體:

Agent 需要搜索能力?寫一個 SKILL,配一段爬蟲 script,對接搜索 API。 Agent 需要操作 database?寫一個 SKILL,配一段 ORM script,對接 database instance。 Agent 需要飛書文件、GitHub Issues、Jira 任務、Slack 消息……一個 SKILL,令 Agent 生多隻手。
AgentUse 唔係俾緊你一個工具,係俾緊你一套 「令 Agent 生出手」嘅方法論。
當你嘅 Agent 唔再係一個淨係識得傾偈嘅知識庫,而係一個可以查文件、搜網頁、操作 database、send 消息嘅數碼員工——
咁先係 Agent 應該有嘅樣。
AgentUse 標準協議: agent-use.zerone.life
Yi-One 桌面 Agent: www.yioneai.cn
別把 Prompt 當 Skill:AgentUse 架構與四層解耦
如果你已經在用 Skills 標準給 Agent 擴展能力——你大概踩過不少坑。
網上扒一段腳本,本該塞進 scripts/,卻直接往 Prompt 裏一貼。API 文檔倒是放對了 references/,token 還是嘩嘩燒。自己寫的 SKILL.md 就幾行調用說明,Agent 動不動編一段不存在的接口。返回格式隨機、錯誤處理隨緣。
你明明照着標準做了三層分離(SKILL.md / references / scripts),為什麼還是不順?
問題不在"有沒有",而在"夠不夠格"。
Anthropic 的標準只告訴你 Skill 應該長什麼樣,沒告訴你一個真正能在生產環境跑起來的 Skill,它的架構應該怎麼設計。SKILL.md 怎麼寫才算協議?references 怎麼存才算解耦?scripts 多瘦才算輕量?
這些標準沒細說。但有一個小技能,簡單得不能再簡單——卻把這些問題的答案,全寫在它的目錄結構裏了。
一個簡單到不起眼的小技能
它叫「玩轉易萬」,是一個 Yi-One 產品的問答智能體。
提示詞沒什麼特別的——身份是"產品小助手",語氣陽光熱情,規則是"技能優先、文檔優先"。說白了,就是個標準的客服 bot。
它身上只掛載了一個技能:yidocs-fetcher。功能也很單一:查 Yi-One 產品文檔。
沒了。就這一個技能,一個身份,一個目的。
但就是這個簡單到容易被忽略的小技能,它的內部結構長這樣:
你可能覺得這沒什麼大不了的——一個技能包不都長這樣嗎?不。大多數所謂的"SKILL"只是把一堆命令堆在一起。而這個技能的設計,恰好完美對應了一套標準體系:AgentUse 架構。
AgentUse 架構:四層如何各司其職
Agent 和技能之間,從來不是"你隨便調用我"這麼簡單。AgentUse 把這件事拆成了四層:
第一層是 Agent,也就是大腦。 它只做兩件事:判斷該調用什麼技能,然後根據返回的結果組織回答。不存知識,不跑計算。就像一個項目經理——知道找誰幹活,但不自己幹。
第二層是 SKILL.md,一份標準的協議。 Agent 讀到它,就知道這個技能該怎麼用。yidocs-fetcher 的協議只定義了三步:第一步,列出有哪些文檔可用;第二步,選定某篇文檔,用用戶的問題去查;第三步,從返回的片段中整理答案。三步走完,任務完成。Agent 不用猜——照着協議走。
第三層是客戶端腳本,也就是執行層。 一個不到 500 行的 Python 文件,做的事極其單純:把 Agent 的意圖翻譯成 HTTP 請求,發出去,等結果回來。它不解析文檔、不算分、不檢索——那些活它一件都不幹。它只是一個跑腿的。
第四層是服務端,真正的承重點。 文檔存在哪?服務端。全文檢索誰做?服務端。段落評分、片段截取、圖片連結生成——全是服務端在扛。客戶端只發一個請求,服務端把加工好的結果端回來。Agent 拿到的永遠是精選後的片段,不是整篇文檔。
這就是 AgentUse 架構的核心理念:
客戶端瘦,服務端胖。繁重的工作全部下沉到服務端,客戶端永遠輕量,但能力無限擴展。
對比一下傳統方式:Agent 直接把整篇文檔塞進 Prompt,token 嘩嘩地燒,LLM 自己去做"閲讀理解"。AgentUse 的做法是:服務端已經讀完了、選好了、裁好了,Agent 只拿最精華的幾個片段。
一條完整鏈路:當用戶問"飛書怎麼接入?"
用戶拋出這個問題時,四層依次激活:
第一步,列目錄。 Agent 判斷這是產品使用問題,調用 yidocs-fetcher。客戶端腳本向服務端請求文檔目錄,返回 100 多篇文檔清單。Agent 掃了一眼,鎖定"飛書集成指南"。
第二步,取內容。 Agent 把文檔標識和問題發給服務端。服務端取出 Markdown 全文,智能切分、逐段評分,返回最相關的 5 個片段。
第三步,生成回答。 Agent 拿到結構化結果——標題、章節、引用內容、相關度評分——據此組織回答,標註出處,分步說明。
答案不夠充分?Agent 回到第一步,換篇文檔再來一遍。這不是"一次問答",是循環:判斷→調用→取結果→評估→再決定。
注意:Agent 選中那篇文檔,不是靠關鍵詞匹配,是看完 100 多篇目錄後自己判斷的。Agent 在支配工具,不是工具在支配 Agent。
大腦決策,協議調度,腳本傳話,服務端扛活。四層各司其職。
這套架構到底解決了什麼?
回到開頭提的問題——一個真正合格的 SKILL,到底應該長什麼樣?
表面上看,AgentUse 解決了"知識過時""工具黑盒""客戶端臃腫""單輪問答"四個問題。但它們不是並列的——它們是一條鏈上的四個環。
一切從知識解耦開始。
傳統做法是把文檔塞進 Prompt——知識就是 Agent 的一部分。知識一過時,Agent 就開始胡說。AgentUse 把知識抽離到服務端:更新文檔不需要改 Agent、不需要改 SKILL、不需要改腳本。Agent 的行為和知識之間,第一次有了明確的邊界。
這個邊界一確立,下一環自動解鎖——工具標準化。
知識在服務端,Agent 通過什麼訪問它?一個統一的協議。SKILL.md 就是這份協議。以前給 Agent 接工具,它不知道該什麼時候調用、傳什麼參數、期望什麼輸出。現在每個技能都有同一份"說明書",Agent 不需要摸索。
協議統一之後,第三環水到渠成——客戶端無限瘦。
既然服務端承擔了檢索、評分、解析,客戶端腳本就只需要做一件事:發請求、收結果。你的 Agent 跑在一台樹莓派上,也能調用一個跑在雲端的、處理海量文檔的技能。客戶端的能力不再被本地算力限制。
而前三環的終點,是第四環——Agent 進入真正的執行循環。
不再是"你問我答"。Agent 在"查目錄→選文檔→取內容→判斷→再取→回答"的循環裏不斷修正,逼近最佳答案。知識解耦給了它可更新的知識源,協議標準化給了它可預測的調用方式,輕量客戶端給了它無限擴展的能力——三層合力,才讓 Agent 從聊天機器人變成了能反覆嘗試、自我修正的數字員工。
一個技能只是一個開始
「玩轉易萬」只有一個技能,但它背後的那條管道——協議、執行、服務——適用於所有類型的 AI 智能體:
Agent 需要搜索能力?寫一個 SKILL,配一段爬蟲腳本,對接搜索 API。 Agent 需要操作數據庫?寫一個 SKILL,配一段 ORM 腳本,對接數據庫實例。 Agent 需要飛書文檔、GitHub Issues、Jira 任務、Slack 消息……一個 SKILL,給 Agent 長出一隻手。
AgentUse 不是在給你一個工具,是在給你一套 "讓 Agent 長出手"的方法論。
當你的 Agent 不再是一個只會聊天的知識庫,而是一個能查文檔、搜網頁、操作數據庫、發消息的數字員工——
那才是 Agent 該有的樣子。
AgentUse 標準協議: agent-use.zerone.life
Yi-One 桌面 Agent: www.yioneai.cn