前 OpenAI CTO Mira 的新公司發了第一個產品,驗證了我之前關於 AI 自動化的一個思考
整理版優先睇
前 OpenAI CTO Mira 新公司 Thinking Machines 發表全雙工交互模型,以 200 毫秒交互週期打破 AI UI 測試嘅回合制瓶頸
作者係一位關注 AI 自動化嘅業界人士,佢一直思考點解 AI 加持嘅 UI 測試一直冇辦法好似 API 自動化咁大面積鋪開。佢認為核心瓶頸係一個字:慢。現有方案都要截圖、發俾大模型、等十幾秒甚至一分鐘回覆,複雜流程根本跑唔起。佢設想一個跳過截圖、直接餵連續視頻流嘅方向,讓 AI 實時睇、實時諗、即時操作。
今日前 OpenAI CTO Mira Murati 嘅新公司 Thinking Machines Lab 發佈第一個產品「交互模型」,正正同佢設想嘅路徑一致。呢間公司今年 2 月成立,CTO 係 PyTorch 創作者 Soumith Chintala,種子輪拎咗 20 億美金,a16z、Nvidia、AMD 都有份。佢哋嘅交互模型係全雙工,200 毫秒一個交互週期,音頻視頻直接透過輕量嵌入層進入模型,唔使傳統預處理編碼器,所以速度同人類神經反應同一量級。基準測試顯示 Thinking Machines 對話響應延遲 0.40 秒,質量評分 77.8,遠遠拋離 Google Gemini(0.57 秒、54.3 分)同 OpenAI GPT-realtime(1.18 秒、46.8 分)。後台仲有一個推理模型處理複雜任務,所有模態一體化訓練,冇 Agent 腳手架串聯嘅額外延遲。
官方演示兩分幾鐘,三個人輪流互動:第一個人叫 AI 記住「friend」任務,第二個人用印地語講嘢要求即時翻英文,第三個人問聽覺視覺反…
- 全雙工交互模型以 200 毫秒響應速度,打破 AI UI 測試一直以嚟嘅回合制瓶頸(每輪十幾秒),令 AI 可以好似真人測試員咁連續操作。
- Thinking Machines 嘅架構分前台交互模型同後台推理模型,前台每 200 毫秒一個處理節點,直接透過輕量嵌入層食入音視頻,唔經傳統編碼器,所以延遲極低。
- 基準測試全面領先:對話響應延遲 0.40 秒(Gemini 0.57,GPT 1.18),質量評分 77.8(Gemini 54.3,GPT 46.8),速度同質量同時有明顯優勢。
- 演示展示咗多任務並行能力:同時記住「friend」任務、即時翻譯印地語、搜尋資料畫圖表,仲可以被打斷同臨時追問,體驗似打電話多過似發語音。
- 呢個技術方向直接指向 AI UI 測試自動化嘅拐點:從截圖回合制轉向即時視頻流,browser 自動化同 computer use 嘅效率都將極大提升,預計 2026 年內會見到落地成果。
UI 測試自動化嘅真正瓶頸:慢
作者一直諗,點解 AI 加持嘅 UI 測試(無論 web 定 app)冇辦法好似 API 自動化咁大面積鋪開?佢反覆分析後認為核心瓶頸係一個字:慢。
而家所有 AI UI 測試方案底層邏輯都一樣:截一張屏幕圖,發俾大模型,等佢睇完、想完、回覆;再截一張,再發,再等。每一輪交互模型思考時間少則十幾秒,多則一分鐘。一個稍微複雜嘅用戶流程,二十幾步操作落嚟,光等模型回覆就要幾分鐘。
而一個熟練嘅點工,喺單個用例執行速度上,一定係碾壓視覺 UI 自動化。所以作者一直琢磨一個方向:有冇可能跳過截圖呢個環節,直接俾 AI 餵一條連續嘅視頻流?
Thinking Machines 嘅全雙工交互模型
今日前 OpenAI CTO Mira Murati 嘅新公司 Thinking Machines Lab 發佈第一個產品「交互模型」,同作者設想嘅方向幾乎一模一樣。
呢間公司今年 2 月成立,CTO 係Soumith Chintala(PyTorch 創作者),種子輪拎咗 20 億美金,估值 120 億,a16z、Nvidia、AMD 都有份。
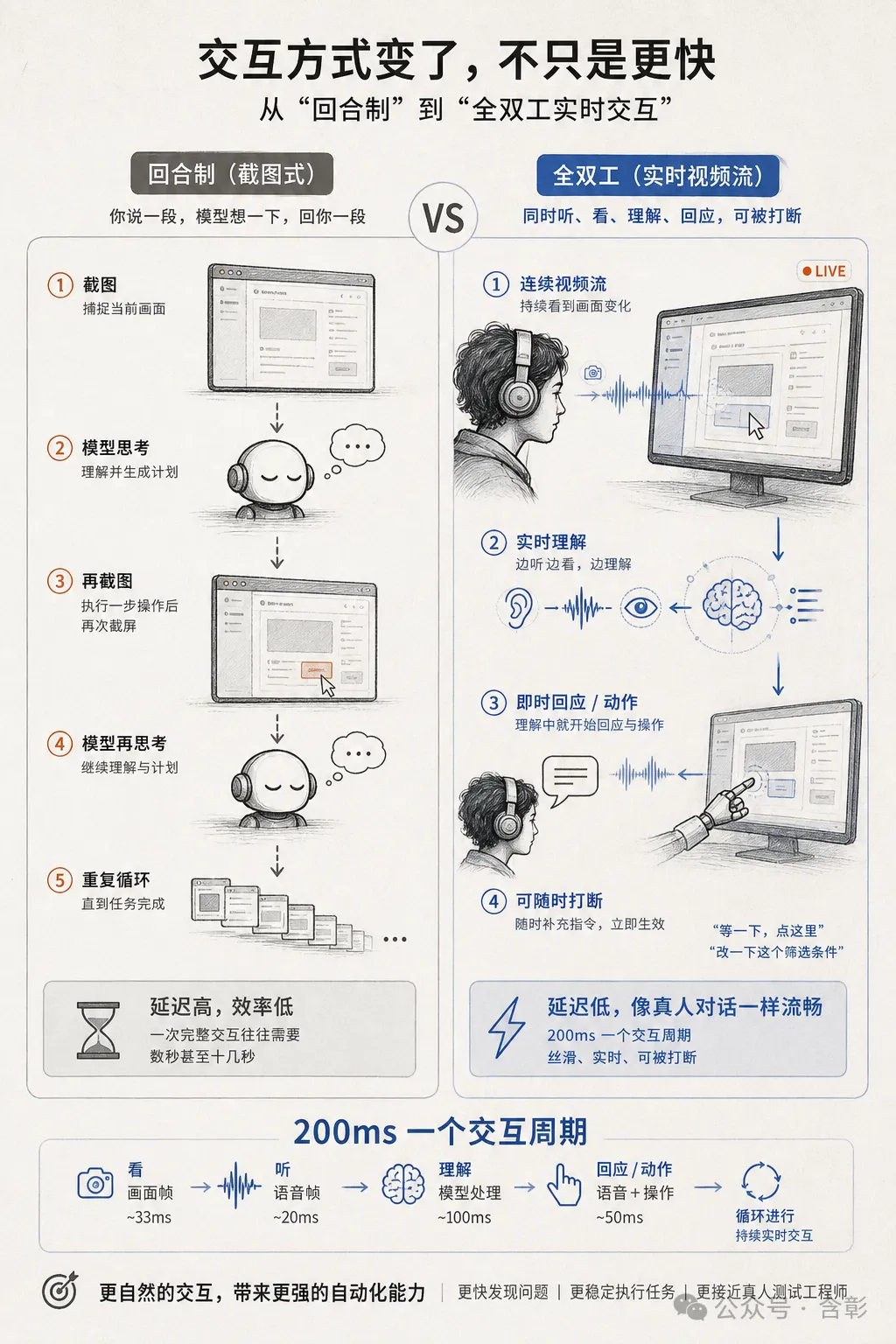
佢哋管第一個產品叫「交互模型」,個名起得精準,因為佢同我哋而家用嘅大模型(ChatGPT、Claude、Gemini)喺交互方式上有一個根本嘅分別:而家嘅模型係回合制</highlight-inline>,你講一段,佢諗嚇,回你一段;Thinking Machines 嘅模型係全雙工</highlight-inline>,你同佢講嘢嗰陣,佢同時喺聽你講嘢、喺睇你嘅畫面,一邊理解一邊就開始回應,你可以隨時打斷佢。
架構分前台同後台兩層。前台係交互模型本體,一直喺線,每 200 毫秒一個處理節點,同時接收輸入、產出一小段輸出。200 毫秒係咩概念?人類聽到聲音嘅反應時間約 140-170 毫秒,見到畫面嘅反應時間約 180-250 毫秒。呢個模型嘅交互速度已經同你嘅神經反應喺同一個量級。
點解可以咁快?因為佢嘅音頻同視頻信號唔需要經過傳統嘅預處理編碼器,直接通過一個輕量級嵌入層就入到模型核心入面,少咗中間環節,延遲自然就落嚟。
效果方面,佢哋發咗基準測試數據:對話響應延遲 Thinking Machines 係 0.40 秒,同場景下 Google Gemini 係 0.57 秒,OpenAI GPT-realtime 係 1.18 秒。質量評分 Thinking Machines 拎咗 77.8,Gemini 54.3,GPT 46.8。作者認為呢組數字相當有說服力,速度同質量同時拉開差距。
後台仲有一個推理模型,專門處理需要深度思考嘅活:複雜推理、工具調用、長上下文理解都交俾佢。前台模型會喺合適嘅時候將後台嘅計算結果自然帶入對話,唔會突然彈一段唔相關嘅內容。最重要嘅係:所有模態都訓練喺同一個模型,冇用 Agent 腳手架將幾個唔同模型串埋。呢個區別好關鍵,串模型每切一次模態就多一層延遲,一體化模型冇呢個損耗。
演示影片:多任務並行嘅實時互動
官方演示片兩分幾鐘,作者反覆睇咗好幾遍。三個人輪流同 AI 互動:
- 1 第一個人叫 AI 記低:等下我有兩個朋友會入畫面,每次有人入嚟你就講 friend。AI 記住咗,然後一邊正常傾偈,一邊喺有人走入畫面時準確喊出 friend。
- 2 第二個人入嚟後直接用印地語講嘢,叫 AI 即時翻成英文。AI 就一邊聽印地語一邊吐英文,同時仲冇唔記之前個 friend 任務。
- 3 第三個人問人類聽覺、視覺、觸覺反應時間分別幾多。AI 搜完拎到數據,對方話幫我畫個柱狀圖。AI 一邊生成圖表,對方又追問點解聽覺快過視覺,AI 一邊畫圖一邊回答,兩件事同時做曬。
仔細諗嚇呢個場景:三個人,兩種語言,視頻畫面實時識別,搜尋,圖表,翻譯,多任務並行。中間仲夾着打斷同臨時追問。成個過程幾乎冇可感知嘅停頓。
對 AI UI 測試自動化嘅啟示:從回合制到即時視頻流
返到開頭問題:AI 做 UI 測試嘅瓶頸本質上係延遲。模型每輪交互十幾秒,複雜流程根本跑唔起。但如果交互週期變成 200 毫秒呢?你幾乎感知唔到延遲,AI 可以好似一個真人測試工程師咁,盯住屏幕連續操作,實時判斷。唔使截圖,唔使等十幾秒。
再擴展一下,成個browser 自動化、computer use,甚至同 LLM 交互本身,都可能迎來極大嘅效率飛躍。而呢一日,應該都唔遠啦。
共勉:認出風暴,激動如大海
2026 年一眨眼快過半,每日都係 AI 變革、生產力爆炸,無論係公司、團隊定個人,好似都喺焦慮中飛速蜕變。最後送俾大家作者好喜歡嘅一句話:我認出風暴,而激動如大海。《預感》裏爾克。
AI 加持嘅 UI 測試,無論係 web 定 app,點解一直都冇辦法好似 API 自動化咁大面積鋪開?
我之前反覆諗過呢個問題。諗嚟諗去,核心瓶頸都係一個字,慢。
而家所有 AI UI 測試方案,底層邏輯都一樣。截一張螢幕圖,send 俾大模型,等佢睇完、諗完、回覆,再截一張,再 send,再等。每一輪交互,模型思考時間少則十幾秒,多則一分鐘。你要跑一個稍微複雜啲嘅用戶流程,廿幾步操作行落嚟,淨係等模型回覆就要幾分鐘。
而作為一個熟練嘅點工,喺單個用例執行速度上,一定係碾壓視覺UI自動化嘅。
所以我一直喺度琢磨一個方向。有冇可能跳過截圖呢個環節,直接俾 AI feed 一條連續嘅視頻流?好似直播推流咁,畫面連續不斷,後面接一個能處理流式輸入嘅大模型,等佢實時睇,實時諗,直接鬱手。
本質都係視頻抽幀,如果有一個大模型嘅延遲做到幾百毫秒級,咁就同人類嘅肉眼冇分別。
然後今日,前 OpenAI CTO Mira Murati 嘅新公司 Thinking Machines,出咗佢哋第一個產品。
呢個嘢,同我之前設想嘅方向幾乎一模一樣。
Thinking Machines 嘅官方演示視頻,兩分幾鐘,建議完整睇一次。
Thinking Machines 嘅「交互模型」
先講講呢間公司。Thinking Machines Lab 今年 2 月成立,創辦人係前 OpenAI CTO Mira Murati,CTO 係 Soumith Chintala,就係做 PyTorch 嗰位,之前喺 Meta。種子輪拎咗 20 億美金,估值 120 億。a16z、Nvidia、AMD 都有投資。
呢個陣容你品一品。
佢哋叫自己第一個產品做「交互模型」(Interaction Model)。呢個名起得精準,因為佢同我哋而家用嘅大模型喺交互方式上有一個根本嘅唔同。
而家嘅大模型,ChatGPT、Claude、Gemini,交互方式本質上都係回合制嘅。你講一段,模型諗一下,回你一段。你再講,佢再回。好似發微信語音咁,一來一回,一來一回。
Thinking Machines 呢個模型係全雙工嘅。你同佢講嘢嘅時候,佢同時喺度聽你講嘢、睇緊你嘅畫面,一邊理解一邊就開始回應。你可以隨時打斷佢,隨時補充內容,佢唔會死等你講完先開始處理。
體驗上更加似打電話。
200 毫秒一個交互週期
佢嘅架構分前台同後台兩層。
前台係交互模型本體,一直 online。每 200 毫秒作為一個處理節點,同時接收輸入、產出一小段輸出。
200 毫秒咩概念?人類聽到聲音嘅反應時間大概 140 到 170 毫秒,見到畫面嘅反應時間大概 180 到 250 毫秒。呢個模型嘅交互速度,已經同你嘅神經反應喺同一個量級。
點解可以咁快?因為佢嘅音頻同視頻信號唔需要經過傳統嘅預處理編碼器,直接透過一個輕量級嘅嵌入層就入到模型核心裏面。少咗中間環節,延遲自然就低咗。
效果點樣呢。佢哋發咗基準測試數據,對話響應延遲 Thinking Machines 係 0.40 秒,同場景下 Google Gemini 係 0.57 秒,OpenAI 嘅 GPT-realtime 係 1.18 秒。質量評分佢哋拎咗 77.8,Gemini 54.3,GPT 46.8。
我真係覺得呢組數字相當有說服力,速度同質量同時拉開咗差距。
後台仲有一個推理模型,專門處理需要深度思考嘅嘢,複雜推理、工具調用、長上下文理解都交俾佢。前台模型會喺合適嘅時候將後台嘅計算結果自然地帶入對話裏面,唔會突然彈出一段無關嘅內容。
你最尾感受到嘅,就係一個既可以秒級回應你講嘅嘢,又可以扛得住重嘢嘅 AI。
仲有一點,所有模態都訓練喺同一個模型裏面,冇用 Agent 腳手架將幾個唔同嘅模型串埋一齊。呢個分別好關鍵,串模型每次切模態就多一層延遲。一體化模型冇呢個損耗。
演示視頻我反覆睇咗好多次
佢哋放咗一段兩分幾鐘嘅演示視頻。
三個人輪流同 AI 互動。第一個人一嚟就俾 AI 佈置咗一個任務,等陣我有兩個朋友會入畫面,每次有人入嚟你就講 friend。AI 記住咗。然後一邊正常傾偈,一邊喺有人行入畫面時準確喊出 friend。
第二個人入嚟之後直接用印地語講嘢,叫 AI 實時翻譯做英文。AI 就一邊聽印地語一邊吐出英文,同時仲冇唔記得之前嗰個 friend 任務。
第三個人問咗一個問題,人類聽覺、視覺、觸覺嘅反應時間分別係幾多。AI 搜完拎到數據,對方話幫我畫個柱狀圖。AI 喺生成圖表嘅同時,對方又追問咗一個問題,點解聽覺比視覺快。AI 一邊畫圖一邊回答,兩件事同時做曬。
你仔細諗諗呢個場景。三個人,兩種語言,視頻畫面實時識別,搜索,圖表,翻譯,多任務並行。中間仲夾雜住打斷同臨時追問。
成個過程幾乎冇可感知嘅停頓。
返去 AI 做 UI 測試呢件事
返去開頭嘅問題。
AI 做 UI 測試嘅瓶頸,本質上就係延遲。模型每輪交互十幾秒,複雜流程就根本 run 唔起。
但如果交互週期變成 200 毫秒呢。
200 毫秒,你幾乎感知唔到延遲。AI 可以好似一個真人測試工程師咁,睇住螢幕連續操作,實時判斷。唔使截圖,唔使等十幾秒。同人操作冇乜分別。
我之前設想嘅嗰條路,俾 AI 一條實時視頻流,等佢好似睇直播咁去理解同操作 UI。Thinking Machines 今日喺技術層面證明咗呢條路行得通。
由技術可行到工程落地中間肯定仲有距離。但方向已經好清楚。AI UI 測試嘅下一個突破點,大概率喺交互範式本身。由回合制轉到實時,由截圖轉到視頻流。
回合制被打破咗嗰日,UI 測試自動化嘅拐點可能就真係嚟咗。
再擴展一下,成個 browser 自動化、computer use,甚至同 LLM 交互本身,可能都將會迎來極大嘅效率飛躍。
而呢一日,應該都唔遠喇
2026年一眨眼都快過半,每日都係 AI 變革、生產力爆炸,無論係公司、團隊、個人,好似都喺焦慮中飛速蜕變。
最後送俾大家我最近好鍾意嘅一句話,共勉。
我認出風暴,而激動如大海。 *《預感》裏爾克*
AI 加持的 UI 測試,不管 web 還是 app,為什麼一直沒辦法像 API 自動化一樣大面積鋪開?
我之前反覆想過這個問題。想來想去,核心瓶頸還是一個字,慢。
現在所有 AI UI 測試方案,底層邏輯都一樣。截一張屏幕圖,發給大模型,等它看完、想完、回覆,再截一張,再發,再等。每一輪交互,模型思考時間少則十幾秒,多則一分鐘。你要跑一個稍微複雜點的用戶流程,二十幾步操作走下來,光等模型回覆就要幾分鐘。
而作為一個熟練的點工,在單個用例執行速度上,一定是碾壓視覺UI自動化的。
所以我一直在琢磨一個方向。有沒有可能跳過截圖這個環節,直接給 AI 喂一條連續的視頻流?就像直播推流一樣,畫面連續不斷,後面接一個能處理流式輸入的大模型,讓它實時看,實時想,直接動手。
本質還是視頻抽幀,如果有一個大模型的延遲能做到幾百毫秒級,那就跟人類的肉眼沒區別。
然後今天,前 OpenAI CTO Mira Murati 的新公司 Thinking Machines,發了他們的第一個產品。
這個東西,跟我之前設想的方向幾乎一模一樣。
Thinking Machines 的官方演示視頻,兩分多鐘,建議完整看一遍。
Thinking Machines 的「交互模型」
先說說這家公司。Thinking Machines Lab 今年 2 月成立,創始人是前 OpenAI CTO Mira Murati,CTO 是 Soumith Chintala,就是做 PyTorch 的那位,之前在 Meta。種子輪拿了 20 億美金,估值 120 億。a16z、Nvidia、AMD 都投了。
這個陣容你品一品。
他們管自己的第一個產品叫「交互模型」(Interaction Model)。這名字起得精準,因為它和我們現在用的大模型在交互方式上有一個根本的不同。
現在的大模型,ChatGPT、Claude、Gemini,交互方式本質上都是回合制的。你說一段,模型想一下,回你一段。你再說,它再回。就像發微信語音,一來一回,一來一回。
Thinking Machines 的這個模型是全雙工的。你跟它說話的時候,它同時在聽你說話、在看你的畫面,一邊理解一邊就開始回應了。你可以隨時打斷它,隨時補充內容,它不會傻等你說完才開始處理。
體驗上更像打電話。
200 毫秒一個交互週期
它的架構分前台和後台兩層。
前台是交互模型本體,一直在線。每 200 毫秒作為一個處理節點,同時接收輸入、產出一小段輸出。
200 毫秒什麼概念?人類聽到聲音的反應時間大概 140 到 170 毫秒,看到畫面的反應時間大概 180 到 250 毫秒。這個模型的交互速度,已經和你的神經反應在同一個量級了。
為什麼能這麼快?因為它的音頻和視頻信號不需要經過傳統的預處理編碼器,直接通過一個輕量級的嵌入層就進到模型核心裏了。少了中間環節,延遲自然就下來了。
效果怎麼樣呢。他們發了基準測試數據,對話響應延遲 Thinking Machines 是 0.40 秒,同場景下 Google Gemini 是 0.57 秒,OpenAI 的 GPT-realtime 是 1.18 秒。質量評分他們拿了 77.8,Gemini 54.3,GPT 46.8。
我是真的覺得這組數字相當有說服力,速度和質量同時拉開了差距。
後台還有一個推理模型,專門處理需要深度思考的活兒,複雜推理、工具調用、長上下文理解都丟給它。前台模型會在合適的時候把後台的計算結果自然地帶進對話裏,不會突然蹦出一段不相關的內容。
你最終感受到的,就是一個既能秒級響應你說的話,又能扛住重活的 AI。
還有一點,所有模態都訓練在同一個模型裏,沒有用 Agent 腳手架把幾個不同的模型串起來。這個區別很關鍵,串模型每切一次模態就多一層延遲。一體化模型沒有這個損耗。
演示視頻我反覆看了好幾遍
他們放了一段兩分多鐘的演示視頻。
三個人輪流跟 AI 互動。第一個人上來就給 AI 佈置了一個任務,等下我有兩個朋友會進畫面,每次有人進來你就說 friend。AI 記住了。然後一邊正常聊着天,一邊在有人走進畫面時準確喊出 friend。
第二個人進來後直接用印地語說話,讓 AI 實時翻成英語。AI 就一邊聽印地語一邊往外吐英語,同時還沒忘記之前那個 friend 任務。
第三個人問了一個問題,人類聽覺、視覺、觸覺的反應時間分別是多少。AI 搜完拿到數據,對方說幫我畫個柱狀圖。AI 在生成圖表的同時,對方又追了一個問題,為什麼聽覺比視覺快。AI 一邊畫圖一邊回答,兩件事同時幹完。
你仔細想想這個場景。三個人,兩種語言,視頻畫面實時識別,搜索,圖表,翻譯,多任務並行。中間還夾着打斷和臨時追問。
整個過程幾乎沒有可感知的停頓。
回到 AI 做 UI 測試這件事
回到開頭的問題。
AI 做 UI 測試的瓶頸,本質上就是延遲。模型每輪交互十幾秒,複雜流程就根本跑不起來。
但如果交互週期變成 200 毫秒呢。
200 毫秒,你幾乎感知不到延遲。AI 可以像一個真人測試工程師一樣,盯着屏幕連續操作,實時判斷。不用截圖,不用等十幾秒。跟人在操作沒什麼兩樣。
我之前設想的那條路,給 AI 一條實時視頻流,讓它像看直播一樣去理解和操作 UI。Thinking Machines 今天在技術層面證明了這條路走得通。
從技術可行到工程落地中間肯定還有距離。但方向已經很清楚了。AI UI 測試的下一個突破點,大概率在交互範式本身。從回合制切到實時,從截圖切到視頻流。
回合制被打破的那天,UI 測試自動化的拐點可能就真的來了。
再擴展一下,整個browser自動化、computer use, 甚至跟LLM交互本身,可能都將迎來極大的效率飛躍。
而這一天,應該也不遠了
2026年一眨眼也快過半,每天都是AI變革、生產力爆炸、無論是公司、團隊、個人,好像都在焦慮中飛速蜕變。
最後送給大家我最近特別喜歡的一句話,共勉。
我認出風暴,而激動如大海。 *《預感》里爾克*