單日收入破百萬美金:AI視頻爆發後,我終於理解了為什麼創作者都選擇「哩布哩布 LibTV」
整理版優先睇
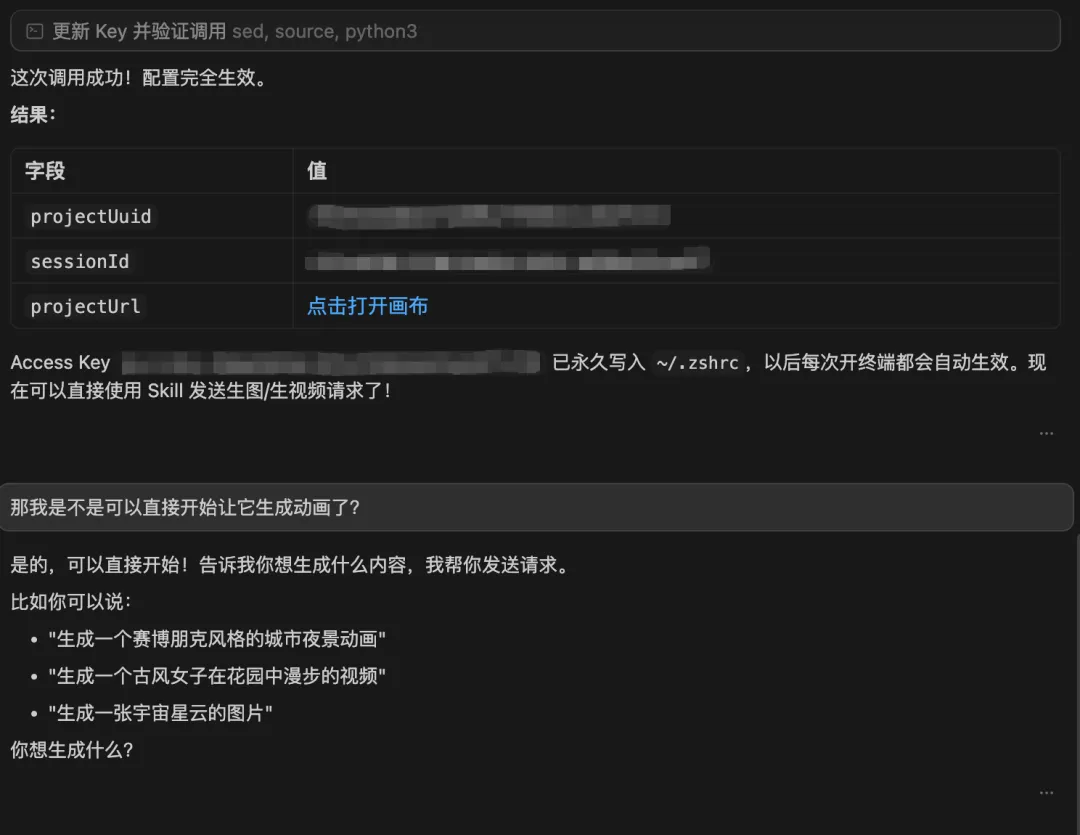
LibTV 將 AI 視頻創作從「抽卡」變為「工業流程」,單日收入破百萬美金背後係生產力升級
呢篇文章係角落君嘅親身經驗分享。佢一直有玩 AI 影片創作,最近發現 AI 影片開始大爆發,但同時遇到一個大問題:工具太多,流程太散。佢要用 MidJourney、Seedance、可靈等唔同平台,來回搬素材、改格式,好似做製片主任咁,創作效率好低。
角落君留意到 LibTV 唔係一般嘅影片生成器,而係一個「AI 影片片場」。佢將劇本、分鏡、角色、模型調用、影片生成全部放喺同一個工作區,仲推出 Creator + Agent 雙入口模式:人類可以用可視化界面創作,AI Agent 可以透過 Skill 自己搭節點、組織素材、生成影片。呢種「人負責意圖,Agent 負責流程」嘅模式,正正解決咗現時 AI 影片創作最大嘅痛點。
整體結論係:AI 影片工具正從「單點生成」走向「流程生產」。LibTV 嘅價值唔係某一款模型最強,而係佢嘅組織能力——將分鏡管理、角色鎖定、模型切換、素材複用整合成一套穩定流程。角落君認為,呢先係持續產出高質素 AI 影片嘅核心,而唔係靠一次靈感爆發。
- AI 影片創作最大痛點係工具太散,流程太亂,創作者變咗搬運工;LibTV 用單一平台整合劇本、分鏡、角色、模型,解決效率問題。
- LibTV 嘅 Creator + Agent 雙入口係最大亮點:人類定意圖,Agent 自動搭節點、生成影片,大幅降低流程管理成本。
- 分鏡組功能解決鏡頭管理問題:可將多張圖片一鍵轉成分鏡組、智能切分、導出 4K 大圖,適合短劇、廣告等需要標準化流程嘅場景。
- LibTV 係聚合式影片平台,支援 Seedance、可靈等多個模型,創作者可按任務選擇最合適嘅能力,唔使逐個工具訂閲同切換。
- 真正持續產出高質素影片嘅關鍵係穩定流程,唔係單次靈感;LibTV 將創作從「抽卡遊戲」推向工業化,讓創作者專注創意。
LibTV 官網
人類創作者使用 LibTV 嘅可視化界面創作平台
LibTV Skills(GitHub)
用於 AI Agent 調用 LibTV 能力嘅 Skill 集合,可讓 Agent 自行搭建節點、生成影片
AI 影片創作最大障礙:唔係模型唔夠勁,而係流程太散
角落君觀察到,依家 AI 影片雖然開始爆,但創作者要應付好多個平台:MidJourney 做創意、Nano Banana 做精修、Seedance 做鏡頭、可靈做穩定生成……每個工具都要開一個瀏覽器分頁,素材喺之間搬來搬去。
創作者變咗製片主任,來回傳話、搬素材、改格式、調順序
佢用自己做「像素版打飛機」嘅經驗說明:先用 GPT 想設定,再用圖像模型做界面,然後用 Seedance 做轉場,最後剪輯拼埋——每一步都要手動接駁。
LibTV 嘅答案:一個 AI 影片片場,而唔係又一個生成器
角落君發現 LibTV 唔係普通嘅影片生成平台,而係一個「片場」——將劇本、分鏡、角色、畫面、鏡頭、模型調用、影片生成整合喺同一個工作區。
LibTV 嘅核心價值係組織能力,將合適嘅模型放到合適嘅位置
佢特別提到三個重點功能:分鏡組可以將多張圖片一鍵轉成分鏡組,仲可以導出 4K 大圖,對短劇、廣告好實用;Creator + Agent 雙入口係最有想象力的部分;聚合式影片平台令創作者唔使逐個工具訂閲。
- 1 分鏡組:解決鏡頭管理問題,支援一鍵轉換、智能切分、重新組織宮格、導出序號大圖
- 2 Creator + Agent 雙入口:人類用可視化界面,AI Agent 透過 Skill 自己搭節點、生成影片
- 3 聚合式平台:整合 Seedance、可靈等模型,按任務選擇最合適嘅能力,唔使切換工具
Agent 模式:人負責意圖,Agent 負責流程
角落君認為 LibTV 最與別不同嘅係 Agent 模式。人類創作者可以畀一個指令,例如「做一個皮克斯風格嘅女孩一日」,然後 Agent 會自己拆流程:角色設定、關鍵圖生成、分鏡組建、模型選擇、影片生成——全部自動化。
你唔使再卡喺「呢個素材放邊」、「劇本點做」、「分鏡點畫」呢啲瑣碎嘢
佢形容呢種方式係「下一代創作方式」:人負責靈感、審美同判斷,Agent 負責流程、節點同執行。角落君自己係一個「唔識寫 code 嘅開發者」,呢種模式對佢特別有吸引力。
單日收入破百萬美金:AI 影片已進入真實生產
角落君提到一段重要數據:LibTV 上線一個月單日收入破百萬美金。呢個數字代表 AI 影片唔再只係創作者嚐鮮,而係短劇公司、廣告團隊、內容博主願意真金白銀投入嘅生產工具。
LibTV 解決嘅係生產力需求,而唔係玩具需求
佢觀察到,好多抖音百萬播放嘅 AI 影片,背後唔係神級提示詞,而係一套穩定嘅工業流程:確定題材 → 拆分鏡 → 角色場景 → 生成關鍵幀 → 跑影片 → 剪輯 → 覆盤數據。呢個流程一旦跑通,下一條影片就唔係從零開始。
- 流程標準化:角色設定、分鏡拆解、鏡頭生成、版本管理、素材複用、團隊協作缺一不可
- 創作者回歸創意:當流程變順,先有時間諗清楚故事、節奏同鏡頭
- LibTV 嘅方向:將 AI 影片從「抽卡遊戲」推向「工業流程」
有組織嘅創作,先係 AI 影片未來
角落君總結,過去一年 AI 影片模型越嚟越強,但流程越嚟越散。一條影片要解決十幾個問題,創作者真正需要嘅係一個能承載完整流程嘅工作區。
LibTV 冇將創作者變成提示詞機器,而係幫佢哋搭一個片場
佢認為 LibTV 嘅貢獻係將創作從單點生成拉回完整流程:人類負責靈感、審美同判斷,Agent 負責流程、節點同執行,模型負責將畫面變出來。呢三件事如果配合得好,AI 影片嘅生產方式會完全唔同。

人類創作者㩒呢度:LibTV 官網
https://www.liblib.tv/
關於影片創作嘅 Skills 喺呢度(最近又更新咗,簡直勁到離譜)
https://github.com/libtv-labs/libtv-skills
呢排我刷抖音有個好明顯嘅感覺:
AI 影片真係開始爆咗。
以前刷到 AI 影片,好多都仲停留喺「睇個新鮮」嘅階段。人物會飄,鏡頭會矇,故仔都成日好似發夢咁斷片。
但而家唔同曬。AI 嘅短劇有時都可以令我欲罷不能,例如……
「有一個人前來買瓜」、「生異形嗎」系列……

每日都有一大堆買瓜影片……
誇張啲講,而家每刷三個影片,就可能見到一個完成度好高嘅 AI 內容。有短劇,有遊戲演示,有裝修延時攝影,有產品廣告,仲有嗰啲一眼睇過去就知花咗唔少心思嘅視覺短片。
而且今次我留意到一個好得意嘅現象:好多高質量 AI 影片作品,背後都開始出現 LibTV 嘅影子。
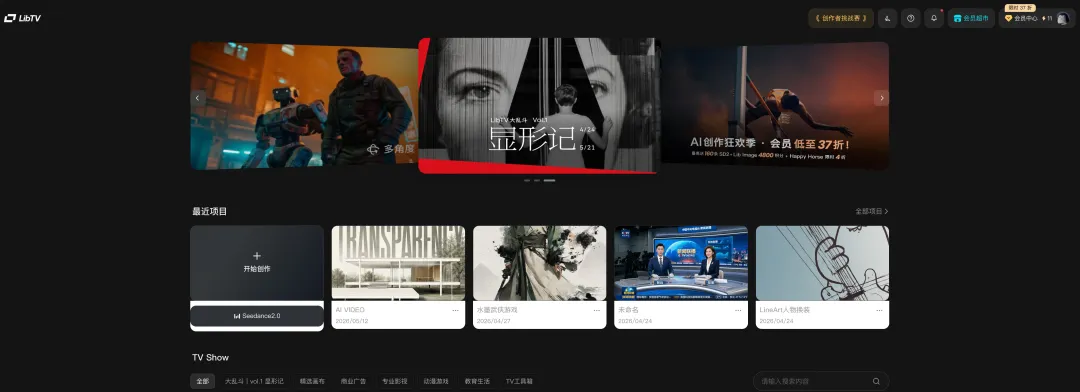
唔講唔得,而家嘅 LibTV 越來越好用,由一開始嗰陣仲有啲小功能間中會有瑕疵,然後就係佢超高嘅更新頻率
成日我做做嚇,就發現螢幕下面提你「又有新版本啦」……而呢啲提醒幾乎日日都見到。(程序員大佬們太辛苦啦)
講真,我第一次意識到呢個變化嘅時候,心態都幾複雜。畢竟 LibTV 啱啱上線嗰陣,角落我就已經猛咁推薦過!
一方面係興奮:終於唔係「AI 得唔得整影片」嘅問題,而係「AI 影片點樣整得更好」嘅問題。
另一方面都有啲崩潰:工具太多啦。
MidJourney、Nano Banana、GPT、Seedance、可靈、即夢、Veo……每個平台都有自己嘅脾氣。你要製作一條完整嘅影片,可能要喺好幾個工具之間來回搬素材。
圖片喺呢度生成,人物喺嗰邊修,分鏡又換一個工具,影片再掉俾另一個平台,最後剪輯仲要自己搞。
AI 影片嘅門檻,好似降低咗。
但真正做起上嚟,流程反而變複雜咗。
亦都係喺呢個時候,我開始認真睇哩布哩布新推出嘅 LibTV。
唔係又一個影片生成器,而係一個「片場」
先講結論。
我一開始以為 LibTV 只係哩布哩布整嘅影片生成平台,類似「將圖片賽道嘅能力搬去影片賽道」。
但用落之後,我覺得呢個理解太淺啦。
LibTV 更加似一個 AI 影片片場。
佢唔係淨係負責「生成一段影片」,而係將劇本、分鏡、角色、畫面、鏡頭、模型調用、影片生成呢啲環節,盡量放喺同一個工作區裏面。

片場嘅工作真係非常複雜!
因為而家 AI 影片創作最大嘅問題,已經唔係「有冇模型可以鬱得鬱」。
Seedance 好勁,可靈亦好穩定。唔同模型各自有自己嘅優勢。
真正麻煩嘅係:你點樣將呢啲能力組織成一條可控嘅生產流程。

呢個就係「流」,好似線性嘅流程同網狀嘅輻射形成嘅完整工作流
我之前做「像素版打飛機」嘅時候,流程大概係咁:
先用 GPT 諗遊戲設定,再用圖像模型做飛機選擇界面、像素戰鬥界面、3A 空戰畫面,然後用 Seedance 做風格轉場,最後再剪輯拼埋一齊。
做「水墨武俠遊戲」嘅時候都差唔多。
角色設定一套工具,圖像清洗一套工具,場景圖一套工具,視頻生成一套工具。每一步都可以做,但每一步之間都要我手動駁。
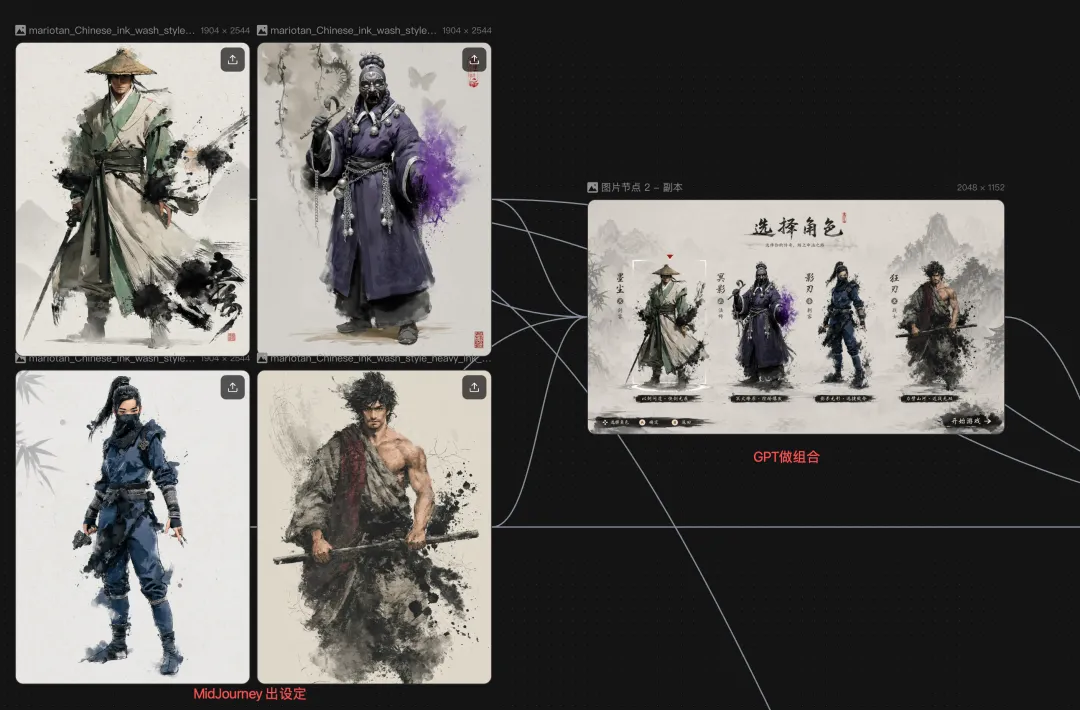
呢個似乜嘢呢?
MidJourney 似創意總監,特別擅長俾你一個「嘩」嘅方向。雖然有時控制唔到,但審美確實仲係最好
Nano Banana 似精修師傅,可以將細節、人物、畫面清理得更穩定。但係審美同 MJ 嘅差距都幾大
GPT 似一個平衡型策劃,文案、流程、邏輯都可以幫你捋順。
Seedance 同可靈似唔同風格嘅攝影師,一個擅長某啲鏡頭語言,一個喺穩定性上好打得。
但問題係:呢啲人都好勁,但唔喺同一個片場。
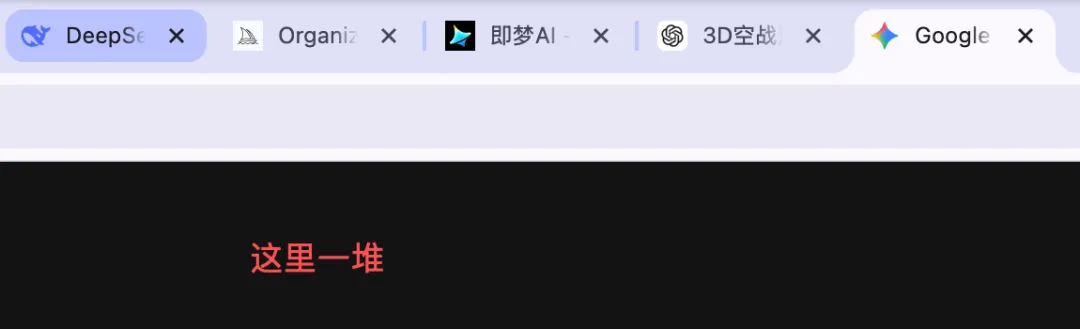
如果你唔用聚合類嘅平台,好似你隨便出啲嘢,你就需要開咁多個網頁,你睇我呢度我平時要開一堆網頁……
你作為創作者,就變成咗嗰個來回傳話、搬素材、改格式、調順序嘅製片主任。
LibTV 想解決嘅,就係呢個問題。
2026 年,哩布哩布切到影片賽道
哩布哩布之前喺國內 AI 圖片創作圈已經好有存在感。
模型、工作流、創作者生態,呢啲都係佢原本嘅優勢。
但 2026 年呢個節點好特殊。
AI 內容由圖片搬去影片,速度快過好多人想像。短劇公司喺用,廣告團隊喺用,內容博主都喺用。根據今次 Brief 嘅資訊,LibTV 上線一個月,單日收入已經破百萬美金。
呢個都係哩布哩布好關鍵嘅一次轉身:由圖片賽道裏面嘅國內應用獨角獸,正式切到影片賽道,而且一上嚟就展示出好強嘅競爭力。至少喺我觀察到嘅 AI 影片創作圈裏面,LibTV 已經越來越似國內 AI 影片製作嘅第一選擇。
呢個數字都幾嚇人。
佢說明 AI 影片唔只係「創作者試新嘢」,而係已經進入真實生產。
更直接啲講,短劇公司願意俾錢,說明佢解決嘅唔係玩具需求,而係生產力需求。
呢個都係點解我覺得 LibTV 呢個產品值得單獨寫一篇。
佢背後反映嘅係一個趨勢:
AI 影片工具正喺度由「單點生成」走向「流程生產」。
以前我哋關心嘅係「呢個模型得唔得生成 5 秒影片」。
而家真正做內容嘅人關心嘅係:
角色得唔得保持一致?
分鏡得唔得管理清楚?
素材得唔得重用?
模型得唔得自由切換?
人類創作者同 AI Agent 得唔得一齊開工?
LibTV 嘅答案,係將呢啲嘢放喺同一個系統裏面。

由人物到結果,完全唔走樣,係因為有強大嘅素材庫同鎖定系統
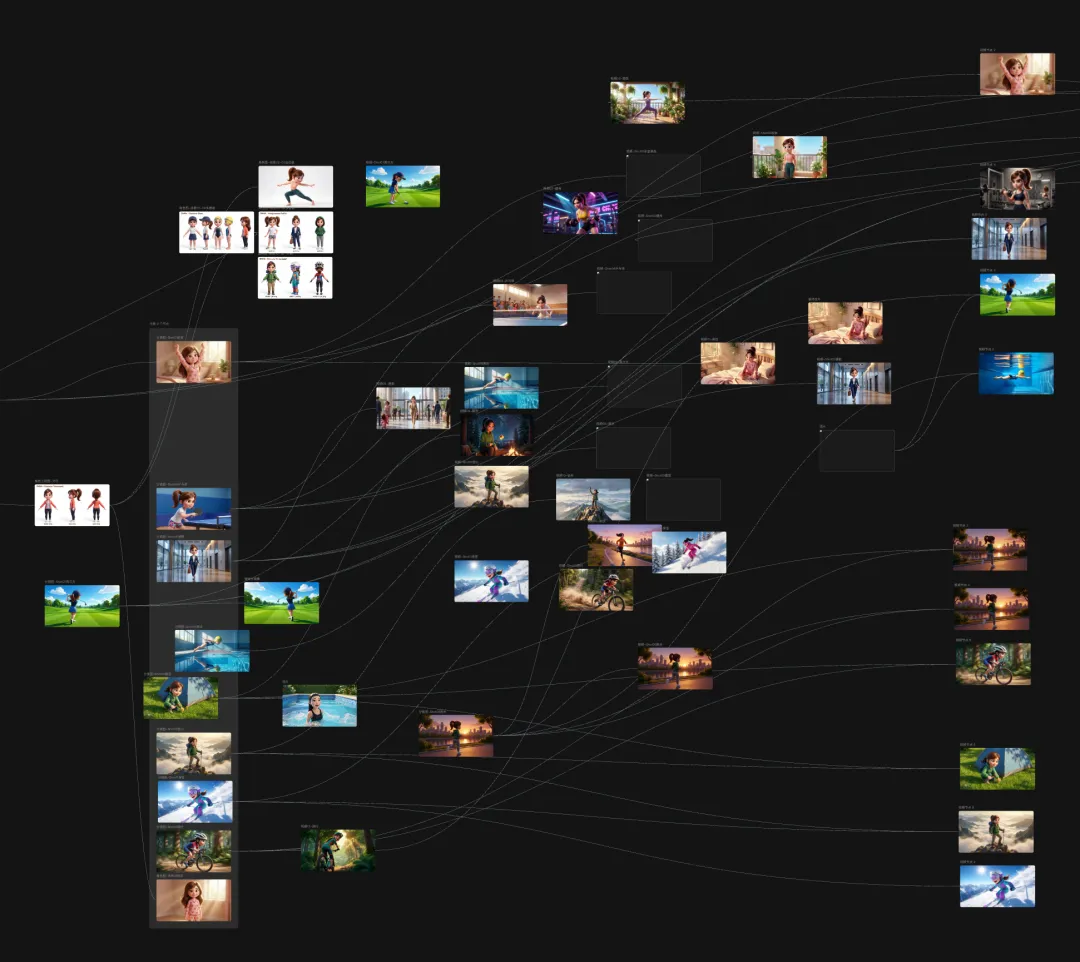
出到最後,人物嘅形態同五官仲係可以確認係同一個人

而你知道嗎,啱啱上面呢個案例,係純 Agent 搞出嚟嘅
LibTV Agent:令 AI 自己搭節點做影片,呢個先係最 coooool 嘅地方
如果 LibTV 只係俾人類創作者做一個更好嘅影片畫布,咁佢已經好有價值。例如我嘅水墨遊戲好評率都唔錯㗎~
但真正令我覺得有趣嘅,係佢對未來影片創作嘅範式:
Agent 模式
呢個都係我覺得 LibTV 喺行業裏面比較新嘅地方。
佢唔係淨係俾人用,亦俾 AI Agent 用。
人類創作者可以打開 LibTV 官網,用可視化界面創作。
Agent(即係你嘅各種龍蝦)就可以透過 Skill 調用 LibTV 嘅能力,自己搭建節點、組織素材、生成分鏡、繼續出影片。
呢件事有啲似乜嘢?
以前你係導演,AI 係攝影師。
你同佢講:「幫我拍呢個鏡頭。」
而家你可以令一個 Agent 做執行導演。
你同佢講:「幫我做一個 Pixar 風格嘅一個女仔嘅一日」
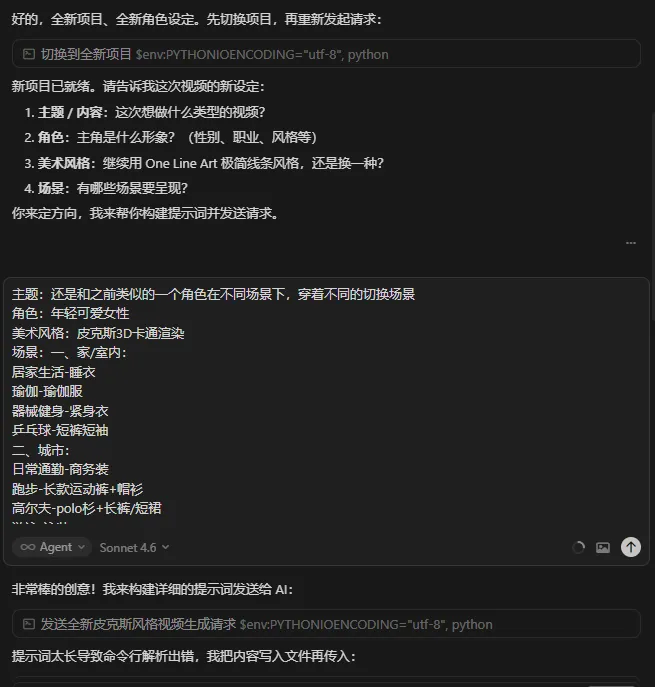
然後佢自己開始拆流程:
角色設定點樣做?
需要幾張關鍵圖?
邊啲圖要放進分鏡組?
邊啲節點負責生成畫面?
邊啲節點負責生成影片?
邊度需要用 Seedance,邊度需要換另一個模型?
成個過程如果錄低佢,會非常有趣。
你見到嘅唔係「AI 輸出一段文字」,而係一個 Agent 喺畫布上面自己搭節點、連流程、生成素材、推進影片。
你睇佢幫我寫嘅設定幾詳細~

講真,呢個比單純展示一個完成片更加有衝擊力。
因為佢展示嘅係下一代創作方式:
人負責意圖,Agent 負責流程。
人唔使再卡喺「呢個素材放邊度」、「劇本點樣做」、「分鏡點樣畫」、「呢張圖使唔使重新改名」呢啲瑣碎事裏面。
你更加似係喺度提需求、睇片、改方向。
呢個對我呢種「唔識 code 嘅開發者」嚟講,特別有吸引力。
因為我太熟呢種感覺啦。
以前做工具,我負責諗,AI 負責寫。
而家做影片,都開始變成:
我負責諗,Agent 負責搭。
呢度嘅成品片睇呢度:
LibTV 目前最值得睇嘅三個功能
如果只揀幾個點,我會重點睇呢三個。
分鏡組
啱啱已經講過,佢嘅價值唔在於「將圖片排整齊」咁簡單。
佢真正解決嘅係 AI 影片裏面嘅鏡頭管理問題。
多選圖片可以一鍵轉成分鏡組。
已經有嘅宮格可以切分成分鏡組。
已經有嘅組都可以智能轉換成分鏡組。
最後仲可以一鍵導出連序號嘅 4K 大圖。
對做短劇、廣告、遊戲演示、教學影片嘅人嚟講,呢個功能非常必要。
因為你終於可以將「呢條影片點樣拍」變成一張清清楚楚嘅視覺表。
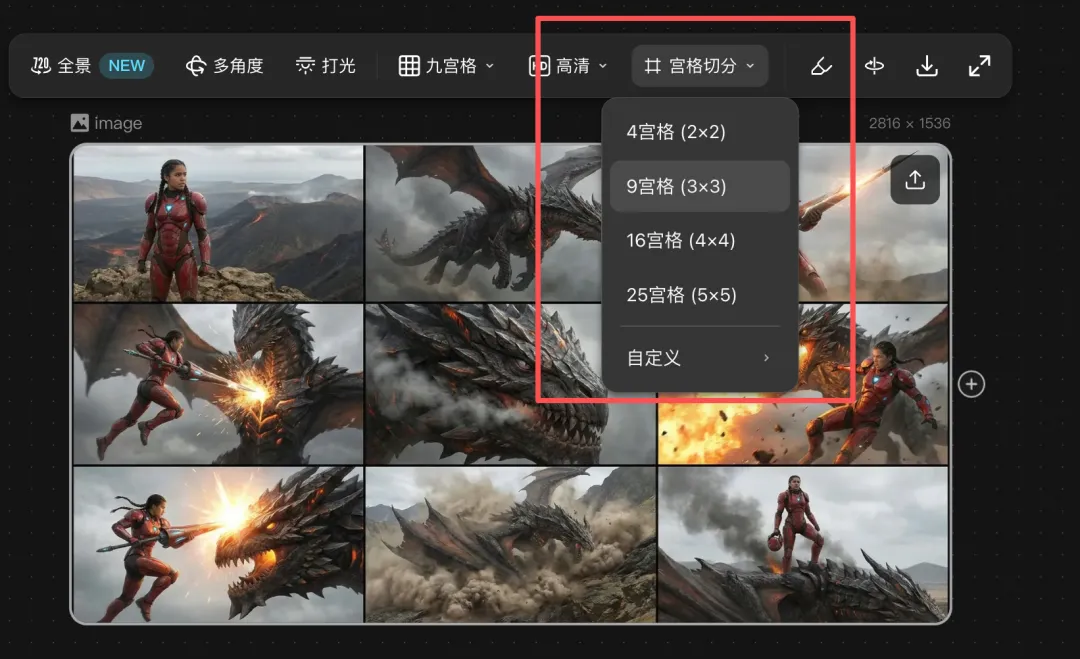
用宮格切分,就可以見到
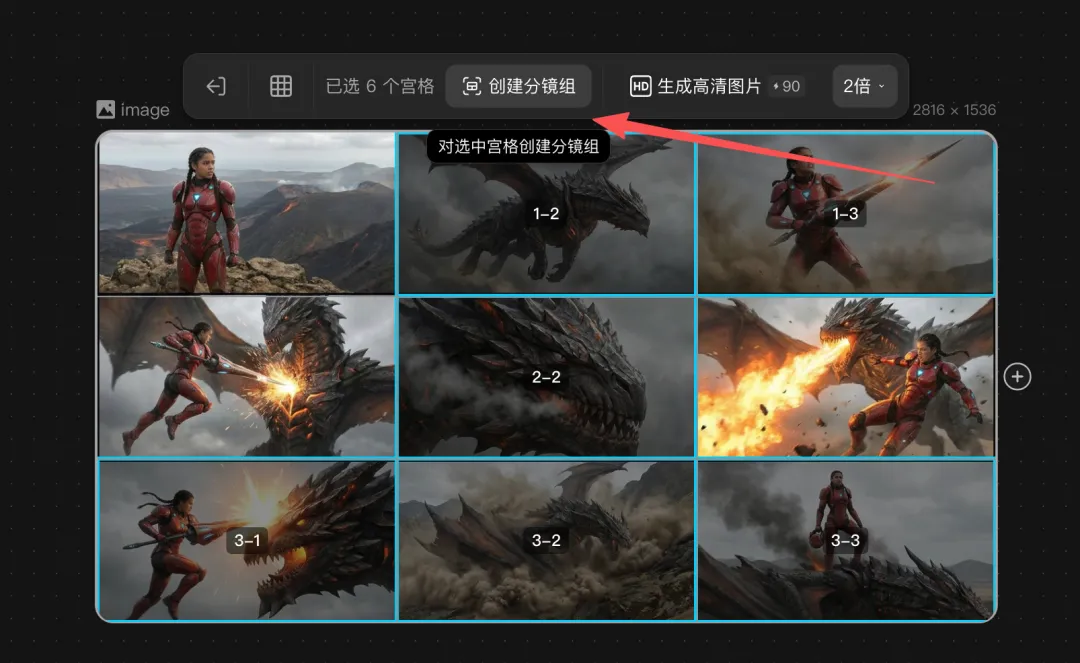

Creator + Agent 雙入口
呢個我覺得係 LibTV 最有想像力嘅地方。
絕大多數 AI 創作工具,本質上都係俾人類設計嘅。
人打開網頁,輸入提示詞,撳生成,下載結果。
但 LibTV 同時喺度俾 Agent 設計入口。
呢個意味住佢唔係淨係想做一個工具,而係想成為一個俾人類同 AI 都可以調用嘅影片生產系統。
短期睇,呢個會令自動化創作更方便。
長期睇,佢可能會改變創作者同工具之間嘅關係。
我哋唔再只係「用工具」,而係喺指揮一組會自己行動嘅創作節點。
聚合式影片平台就係生產力
而家影片模型太多啦。
可靈有可靈嘅優勢,Seedance 有 Seedance 嘅優勢,唔同模型適合嘅鏡頭、風格、節奏都唔一樣。今日出咗快樂馬,聽日又唔知會嚟啲乜,一個月各種亂七八糟嘅訂閲費唔知要用幾多……錢使咗,麻煩嘢仲一大堆,各個工具來回切,瀏覽器窗口開咗差唔多兩排啦……
聚合平台嘅意義就喺呢度出現。
佢唔係幫某一個模型贏,而係令創作者根據任務揀最合適嘅能力。
有啲鏡頭需要更強嘅運動控制,有啲鏡頭需要更好嘅角色穩定性,有啲鏡頭需要更強嘅風格化表達,有啲鏡頭只係需要快啲試錯。
真正嘅影片生產力,唔係某一個模型最強,而係你識唔識得將合適嘅模型放喺合適嘅位置。
LibTV 嘅價值,正正喺呢個「組織能力」上面。
點解好多百萬播放嘅 AI 影片,會嚟自呢類平台?
我之前成日覺得,爆款 AI 影片靠嘅係單點能力。
例如一個特別炸裂嘅模型,一個特別離譜嘅提示詞,一個特別會抽卡嘅創作者。
但睇多咗之後,我慢慢改變咗睇法。
真正可以持續產出高質量影片嘅人,靠嘅唔係一次靈感爆發,而係一套穩定流程。
短劇公司點解會用呢類工具?
因為佢哋需要嘅唔係「偶然出一條神片」,而係每日都可以推進內容。
角色設定、分鏡拆解、鏡頭生成、版本管理、素材重用、團隊協作,呢啲聽落唔似「生成一條震撼影片」咁性感,但佢哋先係生產力。
好多抖音過百萬播放嘅 AI 影片,背後唔一定係某一個神級提示詞。
更加可能係一套不斷迭代嘅流程:
先確定題材,再拆分鏡,再做角色同場景,再生成關鍵幀,再跑影片,再剪輯,再檢討數據。
呢個流程一旦行得通,下一條影片就唔係由零開始。
呢個都係點解我覺得 LibTV 嘅方向好正確。
佢將 AI 影片由「抽卡遊戲」推去「工業流程」。
當然,呢度唔係話創意唔重要。
啱啱相反。
當流程變順之後,創作者先可以將精力放返落創意度。
唔使將成晚時間用喺素材搬運同工具切換,先有時間諗清楚故仔、節奏同鏡頭。
寫喺最後:AI 影片正喺度進入「有組織嘅創作」
過去一年,AI 影片俾我嘅感覺一直都係:模型越來越強,但流程越來越散。
每個工具都可以解決一個問題,但一條影片需要解決十幾個問題。
所以創作者真正需要嘅,唔單止係更強嘅生成能力,而係一個可以承載完整流程嘅工作區。
呢個都係點解我覺得哩布哩布切入 LibTV 呢件事好值得關注。
佢唔係由零開始做影片,而係帶住哩布哩布原本喺模型、創作者生態、工作流上面嘅積累,切進一個正在爆發嘅賽道。
由圖片到影片,呢次係一個好自然但亦好關鍵嘅轉移。
如果話過去 AI 圖片工具解決嘅係「我識唔識做出一張圖」。
咁 AI 影片工具要解決嘅就係:
我識唔識持續做出一套內容。
LibTV 而家俾出嘅答案,係 Creator + Agent 雙入口,係分鏡組,係聚合式模型能力,係將創作由單點生成拉返完整流程。
呢個都係我最鍾意佢嘅地方。
佢冇將創作者變成提示詞機器,而係更加似幫創作者搭一個片場。
人類負責靈感、審美同判斷。
Agent 負責流程、節點同執行。
模型負責將畫面變出嚟。
呢三件事如果真係可以配合到,AI 影片嘅生產方式會變得完全唔同。歡迎一齊做啲唔同嘅嘢
https://www.liblib.tv/

人類創作者點這裏:LibTV 官網
https://www.liblib.tv/
關於視頻創作的Skills在這裏(最近又更新了,簡直強的可怕)
https://github.com/libtv-labs/libtv-skills
這段時間,我刷抖音有個很明顯的感覺:
AI 視頻真的開始爆了。
以前刷到 AI 視頻,很多還停留在“看個新鮮”的階段。人物會飄,鏡頭會糊,故事也經常像做夢一樣斷片。
但現在不一樣了。AI的短劇有時候都能讓我欲罷不能,比如……
“有一個人前來買瓜”,“生異形嗎”系列……
每天都有一堆買瓜視頻……
誇張一點說,現在每刷三個視頻,就可能看到一個完成度很高的 AI 內容。有短劇,有遊戲演示,有裝修延時攝影,有產品廣告,還有那種一眼看過去就知道花了不少心思的視覺短片。
而且這次我注意到一個很有意思的現象:很多高質量 AI 視頻作品,背後都開始出現 LibTV 的影子。
不得不說現在的LibTV越來越好用了,從開始的時候還有一些小功能有些時候有瑕疵,然後就是它超高的更新頻率
經常我做着做着,就發現屏幕下面提醒你“又有新版本了”……而這種提醒幾乎天天都能看得到。(程序員大佬們太辛苦了)
說實話,我第一次意識到這個變化的時候,心態還挺複雜。畢竟在LibTV剛上線的時候,角落我就給大家猛猛推薦過!
一方面是興奮:終於不是“AI 能不能做視頻”的問題了,而是“AI 視頻怎麼做得更好”的問題。
另一方面也有點崩:工具太多了。
MidJourney、Nano Banana、GPT、Seedance、可靈、即夢、Veo……每個平台都有自己的脾氣。你要做一條完整的視頻,可能要在好幾個工具之間來回倒素材。
圖片在這裏生成,人物在那邊修,分鏡又換一個工具,視頻再丟給另一個平台,最後剪輯還得自己收拾。
AI 視頻的門檻,好像降低了。
但真正做起來,流程反而變複雜了。
也就是在這個時候,我開始認真看哩布哩布新推出的 LibTV。
不是又一個視頻生成器,而是一個“片場”
先說結論。
我一開始以為 LibTV 只是哩布哩布做的視頻生成平台,類似“把圖片賽道的能力搬到視頻賽道”。
但用下來之後,我覺得這個理解太淺了。
LibTV 更像是一個 AI 視頻片場。
它不是隻負責“生成一段視頻”,而是把劇本、分鏡、角色、畫面、鏡頭、模型調用、視頻生成這些環節,儘量放在同一個工作區裏。
片場的工作真的非常複雜!
因為現在 AI 視頻創作最大的問題,已經不是“有沒有模型能動起來”。
Seedance 很強,可靈也很穩。不同模型都有自己的優勢。
真正麻煩的是:你怎麼把這些能力組織成一條可控的生產流程。
這就是“流”,像線性的流程與網狀的輻射形成的完整的工作流
我之前做“像素版打飛機”的時候,流程大概是這樣的:
先用 GPT 想遊戲設定,再用圖像模型做飛機選擇界面、像素戰鬥界面、3A 空戰畫面,然後用 Seedance 做風格轉場,最後再剪輯拼起來。
做“水墨武俠遊戲”的時候也差不多。
角色設定一套工具,圖像清洗一套工具,場景圖一套工具,視頻生成一套工具。每一步都能做,但每一步之間都要我手動接。
這就像什麼呢?
MidJourney 像創意總監,特別擅長給你一個“哇塞”的方向。雖然有時候控不住,但審美確實還是最好
Nano Banana 像精修師傅,能把細節、人物、畫面清理得更穩。但是審美就離MJ的差距挺大的
GPT 像一個平衡型策劃,文案、流程、邏輯都能幫你捋順。
Seedance 和可靈像不同風格的攝影師,一個擅長某些鏡頭語言,一個在穩定性上很能打。
但問題是:這些人都很強,卻不在同一個片場。
如果你要是不用聚合類的平台,比如你隨便出點東西,你就得開這麼一堆的網頁,你看我這裏我平常得開一堆網頁……
你作為創作者,就成了那個來回傳話、搬素材、改格式、調順序的製片主任。
LibTV 想解決的,就是這個問題。
2026 年,哩布哩布切到了視頻賽道
哩布哩布之前在國內 AI 圖片創作圈已經很有存在感了。
模型、工作流、創作者生態,這些都是它原本的優勢。
但 2026 年這個節點很特殊。
AI 內容從圖片往視頻遷移,速度比很多人想象中更快。短劇公司在用,廣告團隊在用,內容博主也在用。根據這次 Brief 裏的信息,LibTV 上線一個月,單日收入已經破百萬美金。
這也是哩布哩布很關鍵的一次轉身:從圖片賽道里的國內應用獨角獸,正式切到視頻賽道,而且一上來就展示出很強的競爭力。至少在我觀察到的 AI 視頻創作圈裏,LibTV 已經越來越像國內 AI 視頻製作的第一選擇。
這個數字挺嚇人的。
它說明 AI 視頻不只是“創作者嚐鮮”,而是已經進入了真實生產。
更直接一點說,短劇公司願意掏錢,說明它解決的不是玩具需求,而是生產力需求。
這也是為什麼我覺得 LibTV 這個產品值得單獨寫一篇。
它背後反映的是一個趨勢:
AI 視頻工具正在從“單點生成”走向“流程生產”。
以前我們關心的是“這個模型能不能生成 5 秒視頻”。
現在真正做內容的人關心的是:
角色能不能保持一致?
分鏡能不能管理清楚?
素材能不能複用?
模型能不能自由切換?
人類創作者和 AI Agent 能不能一起幹活?
LibTV 的答案,是把這些東西放到同一個系統裏。
從人物到結果,完全不走樣,是因為有強大的素材庫和鎖定系統
出的最後,人物的形態和五官還是能夠確認是一個人的
而你知道嗎,剛剛上面這個案例,是純Agent搞出來的
LibTVAgent:讓 AI 自己搭節點做視頻,這才是最 coooool 的地方
如果 LibTV 只是給人類創作者做一個更好的視頻畫布,那它已經挺有價值了。比如我的水墨遊戲好評率還不錯哦~
但真正讓我覺得有意思的,是它對於未來視頻創作的範式:
Agent模式
這也是我覺得 LibTV 在行業裏比較新的地方。
它不是隻給人用,也給AI Agent 用。
人類創作者可以打開 LibTV 官網,用可視化界面創作。
Agent(也就是你的各種龍蝦) 則可以通過 Skill 調用 LibTV 的能力,自己搭建節點、組織素材、生成分鏡、繼續出視頻。
這件事有點像什麼?
以前你是導演,AI 是攝影師。
你告訴它:“幫我拍這個鏡頭。”
現在你可以讓一個 Agent 當執行導演。
你告訴它:“幫我做一個皮克斯風格的一個女孩的一天”
然後它自己開始拆流程:
角色設定怎麼做?
需要幾張關鍵圖?
哪些圖要放進分鏡組?
哪些節點負責生成畫面?
哪些節點負責生成視頻?
哪裏需要用 Seedance,哪裏需要換另一個模型?
整個過程如果錄屏下來,會非常有意思。
你看到的不是“AI 輸出一段文字”,而是一個 Agent 在畫布上自己搭節點、連流程、生成素材、推進視頻。
你看它給我寫的設定多詳細~
說實話,這個比單純展示一個成片更有衝擊力。
因為它展示的是下一代創作方式:
人負責意圖,Agent 負責流程。
人不用再卡在“這個素材放哪兒”、“劇本怎麼做”、“分鏡怎麼畫”、“這個圖要不要重新命名”這種瑣碎事情裏。
你更像是在提需求、審片、改方向。
這對我這種“不會代碼的開發者”來說,特別有吸引力。
因為我太熟悉這種感覺了。
以前做工具,我負責想,AI 負責寫。
現在做視頻,也開始變成:
我負責想,Agent 負責搭。
這裏的成品片子看這裏:
LibTV 目前最值得看的三個功能
如果只挑幾個點,我會重點看這三個。
分鏡組
剛才已經講過,它的價值不在於“把圖片排整齊”這麼簡單。
它真正解決的是 AI 視頻裏的鏡頭管理問題。
多選圖片可以一鍵轉成分鏡組。
已有宮格可以切分成分鏡組。
已有組也能智能轉換成分鏡組。
最後還能一鍵導出帶序號的 4K 大圖。
對做短劇、廣告、遊戲演示、教程視頻的人來說,這個功能非常剛需。
因為你終於可以把“這一條視頻怎麼拍”變成一張清清楚楚的視覺表。
使用宮格切分,就能看到
Creator + Agent 雙入口
這個我覺得是 LibTV 最有想象力的地方。
絕大多數 AI 創作工具,本質上還是給人類設計的。
人打開網頁,輸入提示詞,點生成,下載結果。
但 LibTV 同時在給 Agent 設計入口。
這意味着它不是隻想做一個工具,而是想成為一個被人類和 AI 都能調用的視頻生產系統。
短期看,這會讓自動化創作更方便。
長期看,它可能會改變創作者和工具之間的關係。
我們不再只是“使用工具”,而是在指揮一組會自己行動的創作節點。
聚合式視頻平台就是生產力
現在視頻模型太多了。
可靈有可靈的優勢,Seedance 有 Seedance 的優勢,不同模型適合的鏡頭、風格、節奏都不一樣。今天出了快樂馬,明天又不知道還會來啥,一個月各種亂七八糟的訂閲費不知道要花多少……錢花了,麻煩的事還一大堆,各個工具來回切,瀏覽器窗口開了快兩排了……
聚合平台的意義在這裏就出來了。
它不是替某一個模型贏,而是讓創作者根據任務選擇最合適的能力。
有些鏡頭需要更強的運動控制,有些鏡頭需要更好的角色穩定性,有些鏡頭需要更強的風格化表達,有些鏡頭只是需要快速試錯。
真正的視頻生產力,不是某一個模型最強,而是你能不能把合適的模型放到合適的位置。
LibTV 的價值,正是在這個“組織能力”上。
為什麼很多百萬播放的 AI 視頻,會來自這類平台?
我之前一直覺得,爆款 AI 視頻靠的是單點能力。
比如一個特別炸裂的模型,一個特別離譜的提示詞,一個特別會抽卡的創作者。
但看多了之後,我慢慢改變了看法。
真正能持續產出高質量視頻的人,靠的不是一次靈感爆發,而是一套穩定流程。
短劇公司為什麼會用這類工具?
因為它們需要的不是“偶爾出一條神片”,而是每天都能推進內容。
角色設定、分鏡拆解、鏡頭生成、版本管理、素材複用、團隊協作,這些聽起來不如“生成一條震撼視頻”那麼性感,但它們才是生產力。
很多抖音破百萬播放的 AI 視頻,背後不一定是某一個神級提示詞。
更可能是一套不斷迭代的流程:
先確定題材,再拆分鏡,再做角色和場景,再生成關鍵幀,再跑視頻,再剪輯,再覆盤數據。
這個流程一旦跑通,下一條視頻就不是從零開始。
這也是為什麼我覺得 LibTV 的方向很對。
它把 AI 視頻從“抽卡遊戲”往“工業流程”推了一步。
當然,這裏不是說創意不重要。
恰恰相反。
當流程變順之後,創作者才能把精力重新放回創意上。
不用把一晚上耗在素材搬運和工具切換裏,才有時間想清楚故事、節奏和鏡頭。
寫在最後:AI 視頻正在進入“有組織的創作”
過去一年,AI 視頻給我的感覺一直是:模型越來越強,但流程越來越散。
每個工具都能解決一個問題,但一條視頻需要解決十幾個問題。
所以創作者真正需要的,不只是更強的生成能力,而是一個能承載完整流程的工作區。
這也是為什麼我覺得哩布哩布切入 LibTV 這件事很值得關注。
它不是從零開始做視頻,而是帶着哩布哩布原本在模型、創作者生態、工作流上的積累,切進了一個正在爆發的賽道。
從圖片到視頻,這是一次很自然但也很關鍵的遷移。
如果說過去 AI 圖片工具解決的是“我能不能做出一張圖”。
那麼 AI 視頻工具要解決的就是:
我能不能持續做出一套內容。
LibTV 現在給出的答案,是 Creator + Agent 雙入口,是分鏡組,是聚合式模型能力,是把創作從單點生成拉回完整流程。
這也是我最喜歡它的地方。
它沒有把創作者變成提示詞機器,而是更像在幫創作者搭一個片場。
人類負責靈感、審美和判斷。
Agent 負責流程、節點和執行。
模型負責把畫面變出來。
這三件事如果能真正配合起來,AI 視頻的生產方式會變得完全不一樣。歡迎一起做點不一樣的東西
https://www.liblib.tv/