卡帕西 LLM Wiki 的V2版本來了,由Rohit Ghumare發佈,解決工程化問題。
整理版優先睇
LLM Wiki V2 加入知識生命週期同工程化,解決原版知識過期問題
呢篇文章係關於 Rohit Ghumare 基於 Andrej Karpathy 原始 LLM Wiki 推出嘅擴展版 V2。Rohit 本身仲有兩個高星 GitHub 項目:agentmemory(畀 coding agent 用嘅持久記憶引擎)同 ai-engineering-from-scratch(開源 AI 工程課程)。原版 LLM Wiki 假設寫入嘅知識會長期有效,但現實係知識會過期。V2 嘅核心就係要解決呢個問題,加入工程化思維:知識生命週期、可信度、知識圖譜、混合檢索、自動化 hooks、質量控制同審計隱私。
V2 認為知識需要帶狀態:confidence、last_confirmed、superseded、stale、review_required。佢用 YAML 元數據管理知識狀態,令 Agent 更新時要判斷結論仲有冇效。同時將事實判斷拆成結構化記錄,記錄點知、幾可靠、幾時確認過、有冇被推翻。仲有 typed knowledge graph,唔只係「相關」,而係明確關係類型,例如 uses、depends_on、contradicts,等 Agent 可以推理。
V2 強調自動化 hooks 減少人工操作,例如攝入資料、更新頁面、跑 lint 都自動化。質量控制方面,直接寫入 AGENTS.md 或 CLAUDE.md 設定規則。仲有 crystallization 概念,將成個研究、調試過程…
- 原版 LLM Wiki 假設知識長期有效,但 V2 指出知識有生命週期,需要狀態管理(confidence、stale、superseded 等)。
- V2 用 YAML 元數據嵌入 Markdown,令 Agent 更新時識判斷結論有效性,唔會盲目保留舊資料。
- 從雙鏈升級到 typed knowledge graph,關係類型包括 uses、depends_on、contradicts,令 Agent 可以推理而非簡單搜尋。
- 加入混合檢索(關鍵詞 + 語義 + 圖譜),減少 index.md 嘅上下文負擔,適合大型知識庫。
- 引入 crystallization 概念,將除錯、評測等過程壓縮成可複用知識,實現知識複利,而家唔使每次重頭開始。
LLM Wiki V2 Gist
Rohit Ghumare 寫嘅擴展版 LLM Wiki,包含完整概念同實作建議。
agentmemory
畀 coding agent 用嘅持久記憶引擎,可以外掛畀 Claude Code、Codex 等 Agent,解決跨 session 記憶問題。
ai-engineering-from-scratch
開源 AI 工程課程倉庫,Rohit 另一個高星項目。
V2 點解要存在?原版假設知識永遠有效
原版 LLM Wiki 有一個隱藏假設:寫入嘅內容會長期有效。但現實唔係咁。Rohit 指出,真實知識有生命週期:啱啱發現嘅 bug 比六個月前嘅 bug 更重要;被驗證過 12 次嘅模式比只出現一次嘅觀察更可靠;新資料可能會削弱甚至推翻舊結論。所以 V2 嘅核心問題就係:知識會過期,要管理佢嘅狀態。
知識有生命週期,唔係永遠正確
用 YAML 元數據管理知識狀態
最小實現唔需要數據庫,直接喺 Markdown 加一層 YAML 元數據就得。Agent 更新頁面時要判斷:呢個結論仲有效嗎?有冇新來源支持?有冇相反證據?要唔要人工複核?咁樣知識庫就開始有生命週期。
---
status: confirmed
confidence: high
last_confirmed: 2024-03-07
sources:
- https://example.com/paper
---另外,可以將事實判斷拆成核心結論庫,每條結論都係結構化記錄,例如:結論內容、來源、可信度、確認日期、是否被替代。咁樣普通筆記只記「我知道咩」,V2 試圖記「我點解知、有幾可靠、幾時確認過、有冇被推翻」。
從「我知道咩」升級到「我點解知」
從雙鏈升級到 typed graph
Obsidian 呢類工具嘅雙鏈只係表示「相關」,例如 [[Claude Code]] [[Codex]]。但 V2 需要表達「點樣相關」。所以佢引入 typed knowledge graph,關係類型可以係:uses、depends_on、contradicts、caused_by、fixed_by、superseded_by。咁樣 Agent 就可以沿住關係推理:邊個工具依賴邊個?邊個結論推翻咗舊結論?邊個錯誤被邊個方案修復?
雙鏈只係「相關」,typed graph 講「點樣相關」
- uses:A 使用 B
- depends_on:A 依賴 B
- contradicts:A 同 B 矛盾
- fixed_by:問題 A 被方案 B 解決
- superseded_by:結論 A 被結論 B 取代
混合檢索:唔再靠單一 index.md
原版 LLM Wiki 靠 index.md 做入口,細規模好好用。但頁面一多,index 就會變成上下文負擔。V2 建議用混合檢索:關鍵詞搜到「Claude Code」,向量搜到「AI coding agent」,圖譜再擴展到「agentmemory / MCP / hooks」。
混合檢索:關鍵詞 + 語義 + 圖譜
如果用 Markdown/Obsidian,可以接 QMD 呢類工具做查詢層:search(關鍵詞)、vsearch(語義)、query(混合+重排)。V2 嘅核心思路就係:Wiki 負責沉澱知識,檢索層負責幫 Agent 揾正確上下文。
QMD 工具提供三種查詢能力
自動化 hooks 同質量控制,實現知識複利
V2 引入事件驅動流程,減少人工操作:攝入資料、更新頁面、整理結論、跑 lint、寫 log 全部自動化。質量控制方面,直接寫入 AGENTS.md 或 CLAUDE.md 設定規則,避免 LLM 污染同幻覺。
Rohit 嘅 agentmemory 項目就係呢種思維嘅工程實現:畀 AI coding agent 一個本地持久記憶層,解決每個 session 都要重複解釋嘅問題。將 Obsidian 做前端,agentmemory 做後端,就係一條完整鏈路:Wiki 沉澱知識,記憶層畀 Agent 用。
agentmemory:持久記憶引擎,解決 Agent 跨 session 失憶
LLM Wiki V2
LLM Wiki V2 不是Karpathy官方發佈嘅第二版。佢係 Rohit Ghumare 根據 Karpathy 原始 LLM Wiki gist 寫出嚟嘅擴展版。
原版核心係:raw sources + wiki + schema,ingest + query + lint。V2 喺呢個基礎上補咗工程層:記憶生命週期、可信度、知識圖譜、混合檢索、自動化 hooks、質量檢查、審計同私隱。
Rohit 係邊個?佢仲有兩個 GitHub 高星項目你應該聽過:
agentmemory:23.3k stars,coding agent 持久記憶引擎
ai-engineering-from-scratch:34.3k stars,開源 AI Engineering 課程倉庫
V2 嘅核心問題:知識會過期
原版 LLM Wiki 有一個默認假設:寫入 Wiki 嘅內容長期有效。V2 認為呢個假設唔成立。
真實知識有生命週期:
剛發現的 bug,比 6 個月前的 bug 更重要
被驗證 12 次的模式,比只出現 1 次的觀察更可靠
新資料可能會削弱舊結論,甚至直接推翻舊結論所以 V2 增加咗:confidence、last_confirmed、superseded、stale、review_required。
即係話,知識頁唔再只係 Markdown。佢要帶狀態、來源、時間同可信度。
用 YAML 管理知識狀態
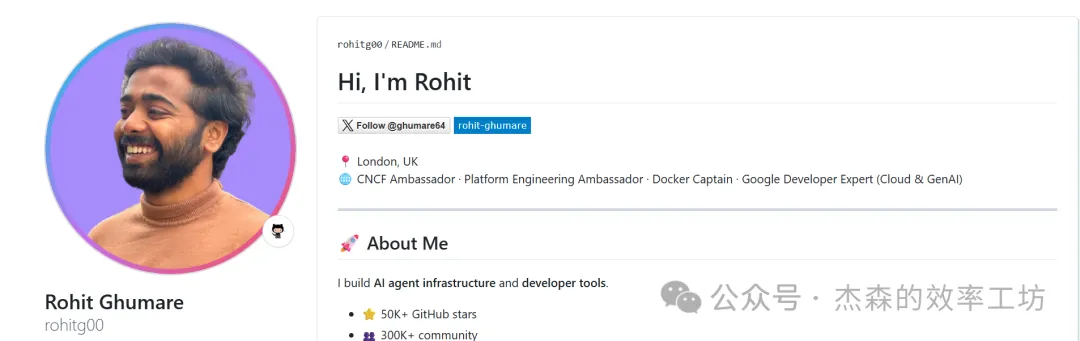
最細實現唔需要數據庫。喺 Markdown 加一層元數據:
咁樣 Agent 喺更新頁面時,就要判斷:呢個結論仲有效嗎?有冇新來源支持?有冇相反證據?使唔使人工複核?呢個就係 V2 最重要嘅變化之一:知識庫開始有「生命週期」。
將事實判斷拆出嚟
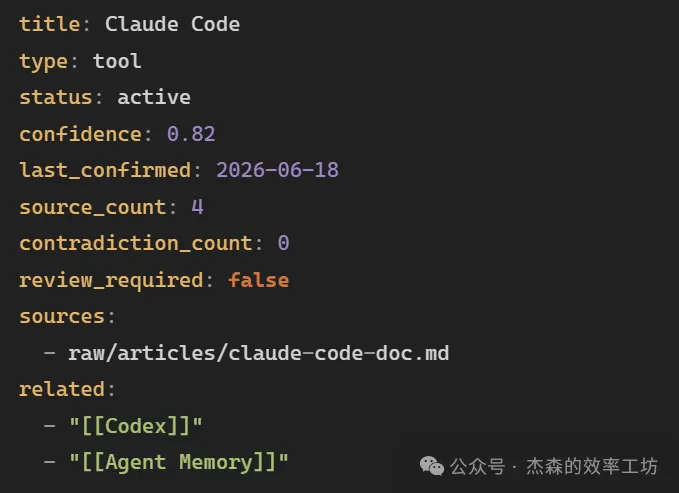
如果要更加工程化,可以維護一個核心結論庫。每個關鍵結論都係一條結構化記錄:
咁樣做嘅好處係:可以檢索、更新、降權、標記過期、被新結論替代。普通筆記只記錄「我知道啲乜」。V2 試圖記錄:我點解知道、呢個結論有幾可靠、佢幾時被確認過、佢係咪已經被推翻。
從普通雙鏈升級到 typed graph
Obsidian 嘅雙鏈只能表示「相關」。例如:
[[Claude Code]] [[Codex]] [[Agent Memory]]但 V2 需要表達「點樣相關」。所以佢引入 typed knowledge graph:

關係類型可以係:uses、depends_on、contradicts、caused_by、fixed_by、superseded_by。呢個會令 Agent 唔只係「搜到頁面」。而係可以沿着關係推理:邊個工具依賴邊個?邊個結論推翻咗舊結論?邊個錯誤俾邊個方案修復?
index.md 嘅侷限性
原版 LLM Wiki 依賴 index.md。細規模好好用:Agent 先讀 index.md,再進入相關頁面。但頁面多咗之後,index 會變成上下文負擔。
V2 嘅建議係混合檢索:

最細實現可以咁理解:關鍵詞搜到「Claude Code」,向量搜到「AI coding agent」,圖譜再擴展到「agentmemory / MCP / hooks」。呢個比單純向量 RAG 更適合長期知識庫。
檢索層實現
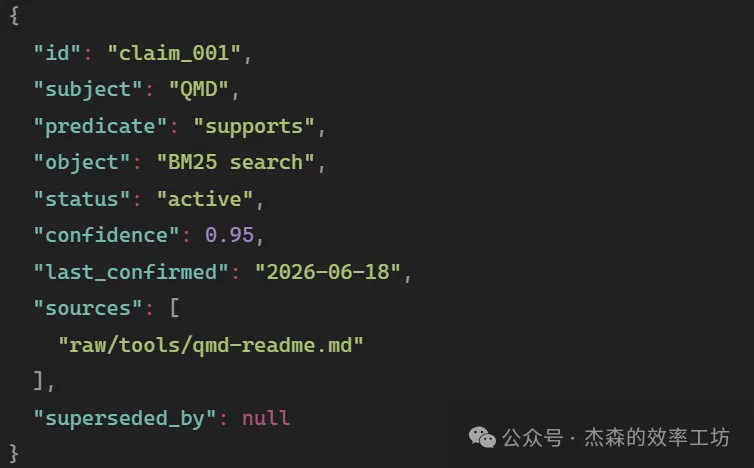
如果用 Markdown / Obsidian 做 Wiki,可以接一個本地搜索層。例如 QMD 呢類工具:
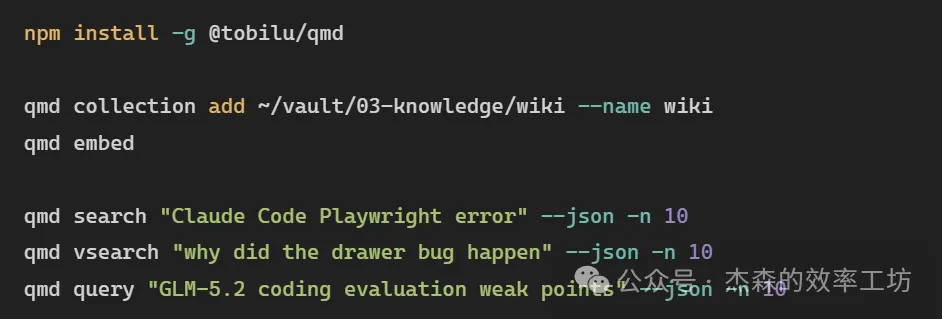
三種查詢對應三類能力:search-關鍵詞檢索,vsearch-語義檢索,query-混合檢索 + 重排。
呢個就係 V2 嘅核心思路:Wiki 負責沉澱知識,檢索層負責幫 Agent 揾到正確上下文。
V2 更加強調自動化 hooks:
原版好多動作要手動觸發:攝入資料、更新頁面、整理結論、跑 lint、寫 log。
V2 認為咁樣好難長期堅持。所以佢引入事件驅動流程:

重點係減少人工記錄。
然後就係最重要嘅質量把控:
LLM 自動寫 Wiki,最大風險係污染、AI幻覺。所以 V2 需要質量把控。
可以直接寫入 AGENTS.md或CLAUDE.md:
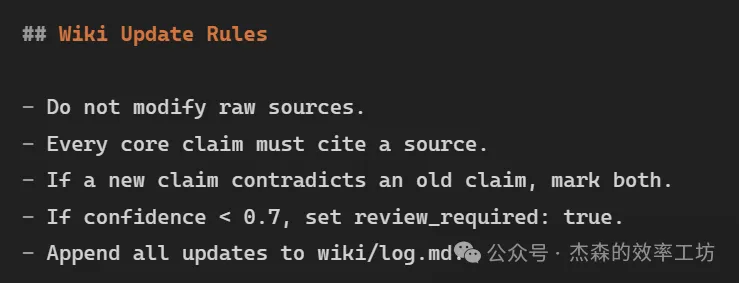
Crystallization:將過程沉澱成知識:
V2 仲有一個重要概念:crystallization。唔係淨係保存最終答案。而係將一次完整研究、調試、評測過程,壓縮成可複用知識。
例如,以我為例,做咗一次模型評測之後,Agent 唔只生成文章。而係生成:評測方法、命令流程、錯誤案例、修復經驗、指標口徑、下次複用模板。呢個對我呢類內容創作者好有價值。呢啲先係知識複利。
agentmemory:就係作者嗰個高星項目
對於 LLM Wiki V2,agentmemory 更加似佢嘅工程實現之一。
佢嘅定位係:Persistent memory for AI coding agents。即係俾 Codex、Claude Code、Hermes、OpenCode 呢類 Agent 外掛一個本地記憶層。
基本用法:
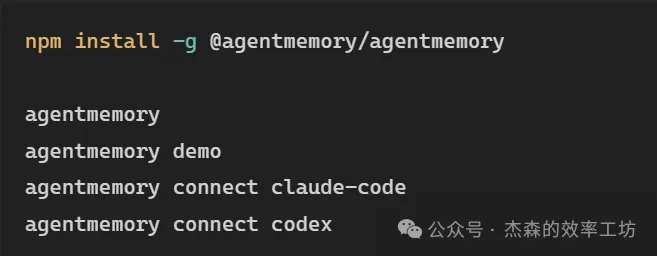
解決嘅問題係:每個 session 都要重複解釋項目結構,每次都要重新說明技術棧,Agent 記唔住之前踩過嘅坑,唔同 Agent 之間唔可以共享上下文。
同 Obsidian 結合,完整嘅鏈路

呢個比「將資料丟俾 RAG」更長期。亦都比「手動整理筆記」更適合 Agent 時代。
講白咗,V2 補上嘅就係:工程化問題。
Rohit 嘅原文地址:GitHub Gist rohitg00/llm-wiki.md
LLM Wiki V2
LLM Wiki V2 不是卡帕西官方發佈的第二版。它是 Rohit Ghumare 基於卡帕西原始 LLM Wiki gist 寫出的擴展版。
原版核心是:raw sources + wiki + schema,ingest + query + lint。V2 在這個基礎上補了工程層:記憶生命週期、可信度、知識圖譜、混合檢索、自動化hooks、質量檢查、審計與隱私。
Rohit是誰?他還有兩個GitHub高星項目你多少聽過:
agentmemory:23.3k stars,coding agent 持久記憶引擎
ai-engineering-from-scratch:34.3k stars,開源 AI Engineering 課程倉庫
V2 的核心問題:知識會過期
原版 LLM Wiki 有一個默認假設:寫進 Wiki 的內容長期有效。V2 認為這個假設不成立。
真實知識有生命週期:
剛發現的 bug,比 6 個月前的 bug 更重要
被驗證 12 次的模式,比只出現 1 次的觀察更可靠
新資料可能會削弱舊結論,甚至直接推翻舊結論所以 V2 增加了:confidence、last_confirmed、superseded、stale、review_required。
也就是說,知識頁不再只是 Markdown。它要帶狀態、來源、時間和可信度。
用 YAML 管理知識狀態
最小實現不需要數據庫。在 Markdown 加一層元數據:
這樣 Agent 在更新頁面時,就要判斷:這個結論還有效嗎?有沒有新來源支持?有沒有相反證據?要不要人工複核?這就是 V2 最重要的變化之一:知識庫開始有“生命週期”。
把事實判斷拆出來
如果要更工程化,可以維護一個核心結論庫。每個關鍵結論都是一條結構化記錄:
這樣做的好處是:可以檢索、更新、降權、標記過期、被新結論替代。普通筆記只記錄“我知道什麼”。V2 試圖記錄:我為什麼知道、這個結論有多可靠、它什麼時候被確認過、它是否已經被推翻。
從普通雙鏈升級到 typed graph
Obsidian 的雙鏈只能表示“相關”。比如:
[[Claude Code]] [[Codex]] [[Agent Memory]]但 V2 需要表達“怎麼相關”。所以它引入 typed knowledge graph:
關係類型可以是:uses、depends_on、contradicts、caused_by、fixed_by、superseded_by。這會讓 Agent 不只是“搜到頁面”。而是能沿着關係推理:哪個工具依賴誰?哪個結論推翻了舊結論?哪個錯誤被哪個方案修復?
index.md 的侷限性
原版 LLM Wiki 依賴 index.md。小規模很好用:Agent 先讀 index.md,再進入相關頁面。但頁面多了以後,index 會變成上下文負擔。
V2 的建議是混合檢索:
最小實現可以這樣理解:關鍵詞搜到“Claude Code”,向量搜到“AI coding agent”,圖譜再擴展到“agentmemory / MCP / hooks”。這比單純向量 RAG 更適合長期知識庫。
檢索層實現
如果用 Markdown / Obsidian 做 Wiki,可以接一個本地搜索層。例如 QMD 這類工具:
三種查詢對應三類能力:search-關鍵詞檢索,vsearch-語義檢索,query-混合檢索 + 重排。
這就是 V2 的核心思路:Wiki 負責沉澱知識,檢索層負責幫 Agent 找到正確上下文。
V2 更強調自動化 hooks:
原版很多動作要手動觸發:攝入資料、更新頁面、整理結論、跑 lint、寫 log。
V2 認為這樣很難長期堅持。所以它引入事件驅動流程:
重點是減少人工記錄。
然後就是最重要的質量把控:
LLM 自動寫 Wiki,最大風險是污染、AI幻覺。所以 V2 需要質量把控。
可以直接寫進 AGENTS.md或CLAUDE.md:
Crystallization:把過程沉澱成知識:
V2 還有一個重要概念:crystallization。不是隻保存最終答案。而是把一次完整研究、調試、評測過程,壓縮成可複用知識。
比如,以我為例,做了一次模型評測後,Agent 不只生成文章。而是生成:評測方法、命令流程、錯誤案例、修復經驗、指標口徑、下次複用模板。這對我這樣的內容創作者很有價值。這才是知識複利。
agentmemory:就是作者那個高星項目
對於LLM Wiki V2, agentmemory 更像它的工程實現之一。
它的定位是:Persistent memory for AI coding agents。也就是給 Codex、Claude Code、Hermes、OpenCode 這類 Agent 外掛一個本地記憶層。
基本用法:
解決的問題是:每個 session 都要重複解釋項目結構,每次都要重新說明技術棧,Agent 記不住之前踩過的坑,不同 Agent 之間不能共享上下文。
與 Obsidian 結合,完整的鏈路
這比“把資料丟給 RAG”更長期。也比“手動整理筆記”更適合 Agent 時代。
說白了,V2補上的就是:工程化問題。
Rohit 的原文地址:GitHub Gist rohitg00/llm-wiki.md