卡帕西又提出了個新概念,對我們有什麼啓發?
整理版優先睇
卡帕西 LLM-Wiki 概念:知識管理新方向,但要注意思考不可外包
呢篇文章係關於卡帕西最近提出嘅LLM-Wiki概念,佢係一個用AI幫手整理個人知識庫嘅框架。作者自己都有研究AI同知識管理,佢覺得呢個概念有參考價值,但同時有個大問題:如果乜都交俾AI整理,自己就可能失去思考同判斷嘅機會。整體嚟講,作者建議我哋要分清楚邊啲可以外包俾AI,邊啲一定要自己嚟。
LLM-Wiki嘅架構分為三層:原始資料庫收藏所有文章筆記,AI只能讀不能改;維基庫由AI提煉整理成Markdown文件,仲會維護索引,建立文檔之間嘅聯繫;規則庫定義AI嘅處理規則同邊界。咁樣知識就被關聯起來,唔似傳統RAG每次由頭檢索。
不過,作者提醒,如果全部文檔都由AI輸出,自己只係提問,好容易俾AI引導,失去獨立判斷。維基庫八成內容係AI做,人嘅參與感好弱,對成長反而有害。所以關鍵係要釐清邊界:整理可以外包,思考唔得。
- LLM-Wiki 將 AI 融入知識管理,但不宜完全依賴 AI 整理,否則削弱思考
- 架構三層:原始資料庫、維基庫(AI 持續更新)、規則庫(定義邊界)
- 相比傳統 RAG,維基庫係持久化知識,唔係每次重新檢索,仲會累積衝突同交叉引用
- 可以借鑑剪藏流程(Obsidian Web Clipper)同索引機制,但需保留人的主體性
- 先釐清邊界:知識整理可外包,思考與判斷必須親力親為
qmd - 本地 Markdown 搜索引擎
專為 Markdown 文件設計嘅本地搜索引擎,支援混合 BM25 與向量搜索,可作 MCP 服務端,適合大型知識庫
卡帕西 LLM-Wiki 原文 Gist
卡帕西提出 LLM-Wiki 概念嘅原始文件,詳細描述架構、工作流程同哲學
卡帕西嘅新概念:LLM-Wiki
卡帕西最近喺推特提出 LLM-Wiki 概念,即刻引起熱議。佢係一個將 AI 融入知識管理嘅框架,架構分三層:原始資料庫、維基庫同規則庫。
原始資料庫係所有文檔嘅源頭,AI 只能讀取唔可以修改。維基庫由 AI 從原始資料提煉成 Markdown 文件,仲會維護索引文檔,建立文檔之間嘅聯繫,解決傳統 RAG 每次對話都從零檢索嘅問題。規則庫就定義 AI 嘅處理邊界同工作流程。
整體流程係:你喺瀏覽器一鍵剪藏到原始資料庫,AI 自動讀取、整理、更新維基庫,你只需對話思考,新沉澱會寫回維基庫,仲會定期巡檢。
對我哋有咩啟發?
作者認為卡帕西嘅工作流有個值得借鑑嘅地方:用 Obsidian Web Clipper 插件一鍵剪藏,好方便。但更大嘅反思係:如果全部文檔交俾 AI 輸出,自己只係提問,好容易俾 AI 過度諂媚,失去獨立判斷。
作者之前寫過文章強調:知識整理可以外包,但思考本身唔得。維基庫八成內容係 AI 做,人嘅參與感好弱,美其名曰共創,實際上放棄咗主體性。呢個邊界需要持續探索,目前未有好答案。
先釐清邊界:知識整理可外包,思考與判斷必須親力親為
作者提到,對大部分人嚟講,個人知識庫唔會超過 100 萬 token,主流 AI 模型上下文食得落,用索引加漸進式加載已經夠用,唔一定需要本地 RAG 引擎。好似 Claude Code 用 grep 搜關鍵詞反而更精準。
實際應用建議
如果你想嘗試呢個概念,可以先從簡單工具入手。用 Obsidian 加 Web Clipper 插件,建立一個原始資料庫。然後叫 AI 幫你整理成維基庫,但一定要自己參與閲讀同引導,唔好完全交俾 AI。
- 用 Obsidian Web Clipper 一鍵剪藏網頁文章,轉成 Markdown 存入原始資料庫
- 建立一個 index.md 檔案,由 AI 幫你更新索引,記錄每個頁面嘅連結同摘要
- 每次加入新資料,叫 AI 讀取並更新相關頁面,但你要審閲 AI 寫嘅摘要,確保自己理解
- 定期叫 AI 做 lint 檢查,找出矛盾、孤島頁面同遺漏嘅交叉引用
- 如果知識庫好大(超過幾百個頁面),可以考慮用 qmd 呢類本地搜索引擎

最近在推特上,卡帕西的一條推文又火了。
我還刷到條挺有意思的推文,他說卡帕西絕對是 AI 界的焦慮之王。仔細想想還是有點道理的——每次卡帕西只要一出什麼新概念,推特上的討論熱度就直接拉滿哈哈。
這次他提出了 LLM-Wiki 的概念,我理解就是個知識管理工具,把 AI 融入到知識管理中,也是我一直在探索的方向。
什麼是LLM-Wiki
LLM-Wiki 的架構分為三層:
第一層是原始資料庫
你所有收藏的文章、論文、筆記,全部堆在這裏。AI 只能讀它,不能修改,這是所有文檔的源頭,有點像我每日覆盤工作流,利用了備忘錄保留原始記錄。
第二層是維基庫
AI 會從原始資料裏提煉,整理成對應的Markdown 文件,同時它會維護一個索引文檔,建立文檔之間的聯繫。
這是為了解決什麼問題呢?
之前像ima這種rag知識庫,每次對話都是從 0 到 1 去檢索,AI完全不知道各個內容之間有什麼關係,也不知道歷史的上下文,通過維基庫這種機制,知識就被關聯起來了。
第三層是規則庫
定義了 AI 應該怎麼處理事情、哪些不能做、邊界在哪裏。
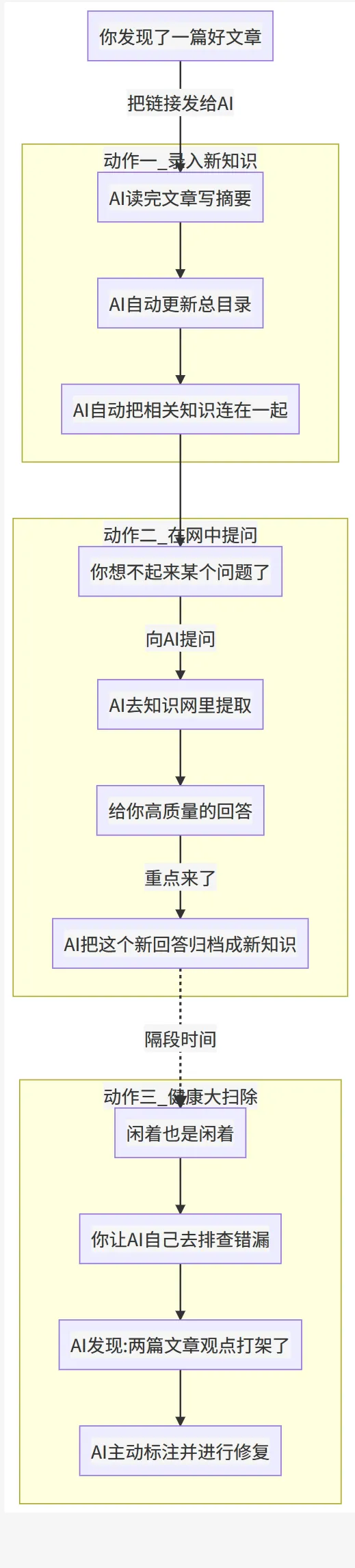
整體運行流程就是:你在瀏覽器裏看到好文章,一鍵剪藏到原始資料庫,AI 自動去讀、去整理、去更新維基庫,苦活累活都是AI幹,你只需要跟 AI 對話和思考,有新的沉澱就會被寫回維基庫,它還會定期巡檢知識庫。
之前在我的每日覆盤工作流裏,也建了一個索引文件,把過去6年的覆盤全部在一個索引文件裏面,包括其它的素材庫,也是這樣處理,借鑑了漸進式加載的思路,只不過卡帕西擴大到了整個知識管理。
不過,不同的是他還引入了一個本地的 RAG 引擎,當數據庫特別大的時候,就可以利用在本地做混合語義搜索,我把他用的這個項目連結也放在這裏:https://github.com/tobi/qmd

不過,講真,對大部分人來說,這玩意不一定用得上,我們的個人知識庫,大概率是不會超過 100 萬 token ,當前主流的AI模型上下文一般都能吃得下,用索引加漸進式加載去處理,完全應付得了。
像 Claude Code 也沒有完全依賴 RAG 引擎,而是用了 grep 這類命令行工具去搜索關鍵詞,反而更精準。所以只有當知識庫膨脹到非常大的時候,這類本地RAG 才有用武之地。
對我們有什麼啓發?
他的這套工作流,對我來說,有個值得借鑑的地方,在於他用了Obsidian Web Clipper這個瀏覽器插件去做剪藏,一鍵就能把看到的好文章收進自己的倉庫,這還挺方便的,因為有時候我也會收藏許多不錯的文章,留着以後查閲。
但是,他的這個思路,有個讓我覺得值得商榷的地方。
當我們把所有文檔都交給 AI 去輸入和輸出,自己只是通過提問和它對話——看起來好像在做思考、在做提問。
但你要知道,AI 有時候是挺過度諂媚的,而且它會把人帶到溝裏去。你去提問,很難保證自己不被它引導着走,除非你有非常強的獨立判斷能力。
之前我也寫過一篇文章專門聊過這個——我們得分清楚,哪些事情是應該"外包"給 AI 的,哪些事情是不能讓 AI 替我們做的。知識的整理可以外包,但思考本身不行。
維基庫的文檔全部都是 AI 整理的,我們人在裏面的參與感其實非常弱。美其名曰是你和 AI 共創的,但實際上 80% 的內容都是 AI 在做。對我們自己的成長來說,可能反而有害,這是放棄了自己的主體性。
這件事情的邊界,需要我們持續探索,目前我也沒有一個好的答案。與其跟着卡帕西的節奏焦慮,不如先想清楚自己想要什麼。
最後我把卡帕西的原文翻譯貼在下面,感興趣的可以去看看第一手信息~
全文翻譯如下:
原文連結:
https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
附全文翻譯:
LLM Wiki(大語言模型維基)
這是一種利用大語言模型(LLM)構建個人知識庫的全新模式。
這是一個“思路文件”,你可以直接把它複製粘貼給你的 LLM 智能體(比如 OpenAI Codex、Claude Code、OpenCode / Pi 等等)。它的目的是傳達高維的宏觀理念,而具體的細節則需要你的智能體與你協作,共同搭建完成。
核心理念
大多數人使用含有文檔的 LLM 時,體驗都很像 RAG(檢索增強生成):你上傳一堆文件,LLM 在你提問時找出相關的片段,然後生成一個回答。這個方法確實管用,但問題在於,LLM 每次回答問題時都在從零開始重新發現知識。這裏面沒有任何沉澱。如果你問了一個需要綜合五份文檔才能得出結論的微妙問題,LLM 每次都必須重新去海底撈針並拼湊碎片。沒有任何東西被構建積累起來。NotebookLM、ChatGPT 的文件上傳功能以及市面上絕大多數的 RAG 系統,都是這麼運作的。
但這裏的思路截然不同。這裏的目標不再是在提問時從原始文檔中臨時檢索,而是讓 LLM 循序漸進地構建並維護一個持久的維基知識庫——這是一種由 Markdown 文件組成的、結構化且相互連結的集合,它橫亙在你與原始資料之間。
當你加入一份新的資料時,LLM 並不是僅僅給它做個索引留着以後檢索用。它會真正地去閲讀、提取關鍵信息,並將其無縫融入到現有的維基體系中——更新實體頁面、修訂主題總結、標註出新數據與舊觀點衝突的地方、進一步加強或質疑那些正在演變成型的綜合推論。知識只需被提取和編譯一次,然後就會被持續保持更新,而不是每次提問都重新推導一遍。
這就是最關鍵的區別:這個維基是一個持久存在且不斷複利增值的產物。 交叉引用已經在那裏了;矛盾和衝突已經被標紅了;總結與提煉已經囊括了你讀過的所有心血。你每多加一份資料、多問一個問題,這個知識庫就變得更豐滿一分。
你幾乎永遠不需要自己去寫這個維基——所有的撰寫和維護工作都由 LLM 包攬。你只負責發掘資料、探索方向,並提出正確的問題。LLM 則攬下了所有的“苦力活”:總結摘要、互相連結、歸檔整理以及瑣碎的記賬工作,正是這些苦力活讓一個知識庫能夠隨着時間推移真正派上用場。在實際操作中,我把 LLM 智能體開在一邊,把 Obsidian 開在另一邊。LLM 根據我們的對話修改文件,而我則實時在旁邊瀏覽結果——點一點連結、看看關係圖譜、讀讀更新後的頁面。在這套機制裏,Obsidian 是 IDE 編程環境,LLM 是程序員,而維基就是代碼庫。
這種模式可以應用在很多不同的場景中。舉幾個例子:
- 個人成長:追蹤你自己的目標、健康、心理狀態和自我提升——也就是把日記、文章、播客筆記分類歸檔,隨着時間推移,拼湊出一個關於你自己的結構化全貌。
- 深度研究:花幾周甚至幾個月的時間在一個主題上深挖——閲讀論文、文章、報告,並逐步建立一個有着不斷演進論點的全面知識庫。
- 讀一本書:一邊讀一邊記錄每一章的內容,為人物、主題、劇情線以及它們的相互關係建立專門的頁面。當你讀完這本鉅著,你就會得到一本內容詳實的伴讀維基。想想《托爾金網關》(Tolkien Gateway)那樣的粉絲維基手冊吧——靠着志願者們長年累月的添磚加瓦,成千上萬個頁面將角色、地點、事件、語言交織在一起。現在,你在閲讀時也能憑一己之力構建一個類似的體系,而 LLM 會替你搞定所有的內容連結和日常維護。
- 商業/團隊協同:一個由 LLM 維護的內部百科資源庫。餵給它的“飼料”可以是你 Slack 裏的聊天記錄、會議轉錄、項目進展報告以及客戶電話錄音。或許可以再加上人工審核環節把把關。這個資源庫永遠不會落伍過時,因為 LLM 承擔了團隊裏誰都不願意去幹的維護清理工作。
- 競品分析、盡職調查、旅行規劃、課程筆記、興趣深挖——在任何需要隨着時間推移不斷積累知識,並且希望這些知識被井井有條地組織起來而不是散落一地的地方,它都能大顯身手。
架構組成
整個系統分為三大層:
原始資料庫(Raw sources)——這是你精心挑選的原始文檔池。文章、學術論文、高清圖片、數據表格都在這裏。它們是不可變的(immutable)——LLM 只對它們進行讀取,絕不加以絲毫篡改。這是你唯一的“真相源”。
維基庫(The wiki)——這是一個由 LLM 自動生成的 Markdown 文件夾。裏面包含了摘要總結、實體介紹、概念解讀、多維對比、內容總覽以及深度提煉。LLM 擁有這一層的絕對控制權。它在這裏新建頁面、當新資料湧入時更新內容、維護錯綜複雜的交叉引用,並確保所有信息的一致性。你負責讀它;LLM 負責寫它。
規則圖紙(The schema)——這是一份特定的文檔(對於 Claude Code 來說可能是 CLAUDE.md,對於 Codex 來說可能是 AGENTS.md),用來告訴 LLM 這個維基是如何搭建的、有哪些約定俗成的規矩,以及在攝入資料、解答疑問或日常維護時應該遵循什麼樣的工作流。這是最核心的配置文件——正是它讓 LLM 變成了一個嚴絲合縫的維基大管家,而不是個只會陪你聊天的通用機器人。在探索不同領域的過程中,你和 LLM 會共同打磨並進化這份文件。
日常操作流程
攝入資料(Ingest)。 你把一份新資料丟進原始資料庫,並吩咐 LLM 處理它。一個典型的工作流是這樣的:LLM 通讀資料,與你探討其中的核心要點,在維基庫裏寫下一篇摘要頁,更新索引目錄,去維基中找到相關的實體和概念頁進行同步更新,最後在操作日誌裏記上一筆。單獨的一份資料可能就會觸發 10 到 15 個頁面的更新動作。就我個人而言,我更喜歡一次只喂一份資料,並全程參與互動——我會閲讀它寫的摘要,檢查更新的內容,並引導 LLM 明確哪些點應當被重點突出。但如果你不想這麼麻煩,也可以在較少監督的情況下讓它一次性批量吞噬海量資料。完全取決於你想怎麼玩,只要把這套符合你風格的流程寫進“規則圖紙”裏,以後的會話它就會照辦。
提問檢索(Query)。 你向維基庫提出各種問題。LLM 會搜索相關頁面,仔細閲讀,並綜合成一份帶有引用來源的解答。根據你問題的不同,答案的形式也會千變萬化——它可以是一頁 Markdown 文檔、一張對比表格、一套幻燈片(Marp格式)、一幅圖表(matplotlib),甚至是一個無窮畫布(canvas)。這裏有個非常關鍵的洞察:絕妙的回答本身就可以作為新的頁面被歸檔回維基體系中。 你要求做的一次精妙對比、一份深度分析,或者你偶然發現的某種聯繫——這些都是極具價值的思想結晶,絕不應該眼睜睜看着它們消失在聊天的歷史記錄裏。只有這樣,你的探索才能像那些被攝入的資料一樣,在知識庫中沉澱複利。
排障巡檢(Lint)。 每隔一段時間,就叫 LLM 給維基做個體檢。讓它找找看:頁面之間有沒有自相矛盾的地方?有沒有哪些陳舊的觀點已經被新進來的資料給推翻了?是否存在沒有任何外部連結指向的“孤島”頁面?是不是有些重要概念被反覆提及卻連自己專屬的詞條頁都沒有?有沒有遺漏的交叉引用?或者哪裏有缺漏,正好可以用全網搜索補上?LLM 非常擅長提出新的探究方向和值得尋找的新資料。正是這種日常巡檢,保證了維基在野蠻生長的同時依然保持着勃勃生機。
索引與日誌記錄
如果你希望 LLM(以及你本人)在這個不斷膨脹的維基宇宙裏不迷路,有兩個至關重要的特殊文件。它們各司其職:
index.md 是以內容為導向的。就像是整個維基的一張商品目錄清單——每一個頁面都被羅列在這裏,配有一個超連結、一句精煉的內容總結,有時還會附加上日期或資料來源數等元數據。它是按類別分門別類整理的(比如實體、抽象概念、資料來源等)。LLM 在每次攝入新資料時都會更新這份目錄。當面對你的提問時,LLM 會拔出目錄看一眼,挑出相關的頁面,再深深地鑽進去。在中小等規模下(大概 100 份素材,幾百個頁面),這套玩法效果出奇的好,完全沒必要去搞那些基於向量嵌入(embedding)的重型 RAG 檢索設備。
log.md 則是以時間線為導向的。這是一份“只增不減”的絕密檔案,記錄了什麼時間發生了什麼事——包括攝入資料、回答提問以及日常巡檢。這裏有一個實用的小竅門:如果所有的記錄條目都用一個固定格式開頭(比如 ## [2026-04-02] ingest | Article Title),這份日誌就能被簡單的 Unix 命令行工具極速解析出來——敲一行 grep "^## \[" log.md | tail -5,你立馬就能調出最近的 5 條動靜。日誌給了你一張清晰的維基進化時間表,也同時能幫助 LLM 快速搞明白你倆最近到底揹着它幹了些什麼。
進階:CLI(命令行)工具
當你在這條路上走得越來越深,你可能想要搗鼓一些小巧的自動化工具,好讓 LLM 在搬起這些維基磚塊時更利索。最直接的莫過於給維基配個專門的搜索引擎——在小範圍折騰時,一份 index 索引文件就綽綽有餘了;但隨着你的知識庫日益龐大,一個正經的搜索引擎絕對是剛需。qmd 就是個非常棒的選擇:它是一個專門針對 Markdown 文件的本地搜索引擎,集成了混合 BM25 與向量搜索技術,以及依靠大模型進行結果重排序,所有的計算統統在本地設備上跑完,絕不外泄。它不僅提供了一個能讓 LLM 隨時丟腳本跑的命令行界面(CLI),更備有 MCP 服務端,好讓你的 LLM 能把它當成一種原生的技能工具來耍。當然,你也可以拉着 LLM 一同用最隨性的“神打編程”(vibe-code)手搓一個最簡陋的搜索查找小腳本應急。
行家秘籍與小貼士
- Obsidian Web Clipper 是一款瀏覽器插件能把網頁文章絲滑地轉成 Markdown 格式。在你想把漫天飛舞的網絡文章粗暴地塞進“原始資料庫”時,這玩意兒就是你的最佳捕手。
- 把圖片老老實實扒到本地。 在 Obsidian 設置 → “文件與連結(Files and links)”選項裏,將“附件文件夾路徑(Attachment folder path)”卡死為一個固定目錄(比如
raw/assets/)。接着去設置 → “快捷鍵(Hotkeys)”搜 "Download",選擇那個 "Download attachments for current file(下載當前文件的全部附件)",並給它綁上快捷鍵(比如 Ctrl+Shift+D)。每次剪藏完一篇大作,反手一套快捷鍵,所有外鏈圖片都會被乖乖下載到你的本地硬盤上。這雖然是選做題但相當滋潤——它能讓 LLM 省去面對滿屏破圖空流淚的窘境,直接閲覽並引用純本地的老婆圖片。不過請注意,以現在的 LLM 能力來說,它們沒辦法一次性掃完混雜着本地圖片的 Markdown 文本——通常的應對方法是讓 LLM 先通篇讀文字,回頭再單獨開小窗仔細端詳那些參考圖片來惡補上下文。它可能有點笨拙繁瑣,但確實能用。 - Obsidian 的全局關係圖譜(graph view) 是你能一覽維基真身的最強利器——看清楚誰和誰在一起、誰是流量大V的中心樞紐、又有誰是被遺忘在角落的孤魂野鬼。
- Marp 是一套基於 Markdown 語法的幻燈片神器體系。Obsidian 裏面也有它的插件。直接拿維基知識庫搓出演示PPT?靠它就對了。
- Dataview 是個極其強悍的 Obsidian 數據視圖插件,專治各種頁面元信息(frontmatter)查詢。如果你吩咐 LLM 在每個維基頁面頂部乖乖加上 YAML 數據頭(打標籤、寫日期、記資料數),Dataview 就能立刻在你的指令下生成隨時變動更新的魔法表格和動態清單。
- 別忘了,整個維基歸根結底只是一大灘套着 Git 殼子的 Markdown 文件堆。只要加上 Git,時光倒流的版本控制、多線開花的分支系統以及大鍋飯式的多人協作,你統統白嫖到了。
它為什麼能成?
維護一個個人知識庫最痛苦的從來不是那些閲讀和思考本身的重體力活——而是那些為了記賬所耗費的微小精力。去挨個更新錯綜複雜的交叉跳轉連結、保持全網所有的摘要簡介隨時在線、在某處新知識推翻了老舊觀點時還得記得回去做修改備註,更別提要在幾十甚至成百頁面裏強制維持那脆弱的一致性。這也是為什麼幾乎所有人類最後都無奈拋棄了那些他們親手建起來的維基,因為維護這攤爛攤子的成本,早遠遠超過了它所帶來的那點可憐巴巴的價值。
但 LLM 會不一樣。LLM 不嫌煩、不犯懶、永遠不會忘記更新哪怕一條狗子才會去點開的交叉引用,並且一記穿心可以連擊操作並改動 15 個文件。因為在有了 LLM 的加持之後,維基庫能永葆青春的原因無比簡單——那點原來壓垮人的維護成本幾乎已經被歸零了。
人類唯一的職責,只剩下精心挑選要餵給機器的口糧素材、指引它的分析探究方向、去問那些真正能發人深省的好問題,並在腦中認真思考——這所有的一切,到底意味着什麼。剩下的所有的雜活、累活、髒活,全是 LLM 的。
追根溯源,這個構想在精神內核上,與早在 1945 年範內瓦·布什(Vannevar Bush)提出的麥梅克斯(Memex)機器概念幾乎不謀而合——那也是一個極具私人色彩的、被精心呵護篩選的知識儲存重器,文獻孤島之間有着緊密聯結的聯想之徑。布什當年的藍圖,其實更像是這種基於本機的互聯,而不是後來網絡世界發展成的那個充滿廣告和推薦流的怪胎:它私人隱秘、充滿主動的篩選,並且文檔之間相互連結編織出的那種紐帶,絲毫不亞於文檔本所具有的價值。
他當年唯一沒能解開的死局,就是“到底是誰來做這個圖書管理員去維護這個聯想體系”。而現在,LLM 替他接下了這份差事。
寫在最後
這篇文檔,我是刻意把它寫得很抽象的。它意在描繪一種輪廓和可能,而不是給你扔一堆僵硬的代碼和刻板的實現。那究竟最後它長啥樣——具體的目錄層級怎麼搞、規則圖紙上寫哪些天條、界面的格局排布長短几何乃至使用哪些順手的工具——這一切的定奪權全部都在你的探索領域、你個人的口味偏好,以及你最終翻了哪個牌子的 LLM 智能體。
上面說的每一條,全都是選填項、都可以隨插隨拔——只拿那些你覺得趁手的即可當即開工,對那些看着就不爽的雞肋直接無腦跳過不看。
舉個例子:萬一你所有的原始素材全都是純文本?那你簡直可以把圖片處理那段當成空氣;甚至有可能你目前的維基盤子實在太小巧,以至於那個小破 index 索引文件本身就成了你的全世界,壓根犯不着再去裝個什麼全宇宙搜索大炮;又或者你這輩子都壓根對花裏胡哨的幻燈片簡報不屑一顧,眼裏只容得下那些黑白分明的 markdown 極簡頁面;還或者在此之外,你需要一份只屬於你獨家定製的另類報告呈現形式呢。
你真正該怎樣去把玩這個體系的方式,就是痛快地把這份文檔直接拍在你的 LLM 智能體桌子上,然後跟它商量着幹,一邊摩擦一邊打磨出一個量身為你訂做的、獨一無二的全新知識宇宙。這份文檔身上唯一揹着的宿命和任務,就是將這種理念傳遞到你的心智裏。剩下該怎麼搞,你的 LLM 會自動給你包辦明白的。