又一個神級 Skill 開源了。
整理版優先睇
Ian Xiaohei Illustrations:AI 幫你將文章認知錨點畫成怪誕手繪線稿,唔係普通配圖咁簡單
呢篇文章係由 ByteDance 產品設計師 Ian 分享嘅開源項目 Ian Xiaohei Illustrations。作者發現傳統配圖方式——揾圖片耗時長而且同觀點無關,所以佢用設計思維同審美品味,整咗一套可複製嘅系統:畀 AI 分析文章嘅認知錨點,再畫成 16:9 白底手繪線稿,主角係一個叫「小黑」嘅荒誕角色。整體結論係:與其求其配圖,不如用 AI 幫手提煉觀點並視覺化,令讀者記得張圖而唔係文字。
呢套系統唔係單純「配一張靚圖」,而係要將文章入面一個重要嘅認知動作畫出嚟——可能係判斷、流程、結構、狀態或者隱喻。小黑必須承擔核心動作,唔係裝飾;畫面風格好剋制:純白背景、黑色細線手繪、留白多,主體只佔三分之二左右,奇怪有趣但唔幼稚。
文章仲詳細講咗三種使用模式(配圖規劃、直接生成、單圖生成)、工作原理、限制同適用場景,最後提醒讀者:工具負責生產,判斷負責選擇——邊度配圖、用咩圖最恰當,呢種判斷仍然好有價值。
- Ian Xiaohei Illustrations 係一個為中文文章生成正文配圖嘅開源 AI 技能,23 日攞咗 5300 幾粒 Star。
- 佢唔係隨機配圖,而係先分析文章嘅認知錨點(判斷、流程、結構、狀態、隱喻),然後用角色「小黑」將嗰個認知動作畫出嚟。
- 小黑唔係吉祥物,必須承擔核心動作;如果冇咗小黑畫面仍然成立,就代表佢太裝飾——係作者 Ian 定嘅嚴格規則。
- 視覺風格好剋制:純白背景、黑色手繪線稿、幼線、微抖,主體只佔畫面四分之三到三分之二,奇怪有趣但唔賣萌。
- 目前只適用於中文文章配圖,唔適合商業插畫、品牌 KV 或者精緻扁平插畫;生成嘅圖片會自動保存到 workspace/assets 文件夾。
Ian Xiaohei Illustrations Skill
複製倉庫並將 skill 放入 Codex skills 目錄,然後用指令 Use $ian-xiaohei-illustrations 為中文文章生成配圖。
GitHub 開源地址
項目基於 MIT 協議開放,可以睇源碼同文檔。
內容結構
git clone
https://github.com/helloianneo/ian-xiaohei-illustrations.gitmkdir -p "${CODEX_HOME:-$HOME/.codex}/skills"cp -R ./ian-xiaohei-illustrations "${CODEX_HOME:-$HOME/.codex}/skills/"項目背景與核心概念
呢個項目叫 Ian Xiaohei Illustrations,係一個開源 AI 技能,專門幫中文文章生成正文配圖。作者 Ian 喺 ByteDance 做產品設計,佢寫文需要配圖時發現傳統做法有兩個死穴:揾圖片耗時長,而且配圖同觀點無關。
所以佢將設計思維同審美品位變成一套可複製嘅系統:唔係要幅圖「靚」,而係要 AI 從文章揀一個認知錨點(判斷、流程、結構、狀態、隱喻),然後畫成 16:9 白底手繪線稿。主角係一個叫 「小黑」嘅角色——黑色身體、白色眼睛、幼細腿、空洞表情,充滿荒誕感。
小黑角色規則與視覺風格
- 1 小黑唔係吉祥物:README 清楚講明,佢唔係貼紙、唔係裝飾,係認真參與系統運轉嘅荒誕工作者。
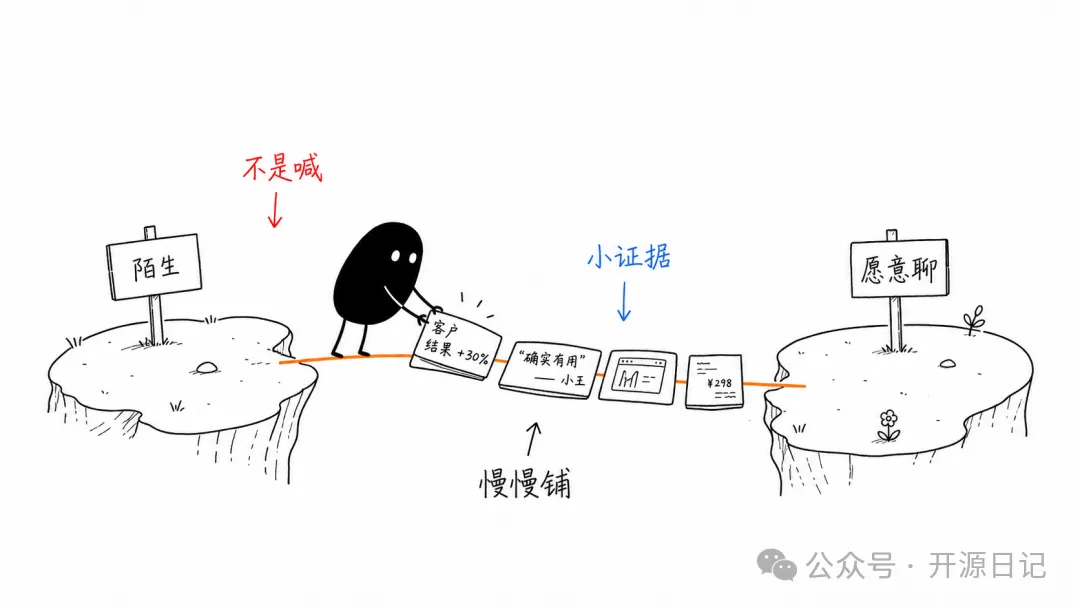
- 2 小黑必須承擔核心動作:例如要表達「信任唔係喊出嚟,係一塊塊用證據鋪設」,小黑就拎住木樁邊行邊鋪;想法由模糊變清晰,小黑就會被放入想法壓機壓實提純。
- 3 視覺風格好剋制:純白背景,不要紙紋、米色、陰影、漸變;黑色手繪線稿、幼線、微抖;留白多,主體只佔畫面四分之三到三分之二。整體感覺奇怪、有趣、清新,但唔幼稚亦唔賣萌。
呢種風格令每張圖都似一幅獨立嘅怪誕插畫,而且因為線條簡單,讀者好易記住個意象。
三種使用模式與工作原理
技能支援三種模式:配圖規劃模式只輸出 shot list,唔生成實際圖片;直接生成模式一次過出 4-8 張 PNG;單圖生成模式就係逐個概念生成一張。所有圖片會自動保存到 workspace/assets 文件夾。
安裝方法係 clone 倉庫,將 skill 複製到 Codex skills 目錄,然後喺 Codex 輸入指令:Use $ian-xiaohei-illustrations 為呢篇中文文章設計並生成 5 張小黑怪誕正文配圖。
限制與適用場景
目前呢個技能只適用於中文文章配圖,如果你想用嚟做商業插畫、品牌 KV 或者精緻扁平插畫,就唔太適合。兒童卡通、可愛 IP、表情包風格都唔支援,亦輸出唔到 PPTX、PDF、Keynote、SVG、HTML 等格式。
另外,圖片入面嘅中文文字越少就越穩定,AI 圖像模型成日會出現錯誤文字、幻覺標籤、風格漂移或者多餘標題。如果中文錯得太多,可以減少標註詞之後重新生成。生成之後記住檢查。
反思與行動建議
最後作者拋咗個問題畀讀者:你平時寫文,會專門設計配圖,定係好似以前嘅佢咁求其揾張就算?呢個項目提供咗一個新思路:將觀點變成圖像,令讀者可能忘記文字,但記得張圖。
如果你係內容創作者、Blogger 或者產品文檔寫手,可以考慮將呢個技能整合入你嘅工作流。GitHub 上以 MIT 協議開源,有興趣嘅可以去睇源碼同文檔。
又一個神級 Skill 開源咗啦。
23 日攞咗 5300 幾個 Star,淨係做一件事:幫中文文章生成正文配圖。
項目叫 Ian Xiaohei Illustrations,其實就係幫中文文章配插圖嘅一個 AI 能力。
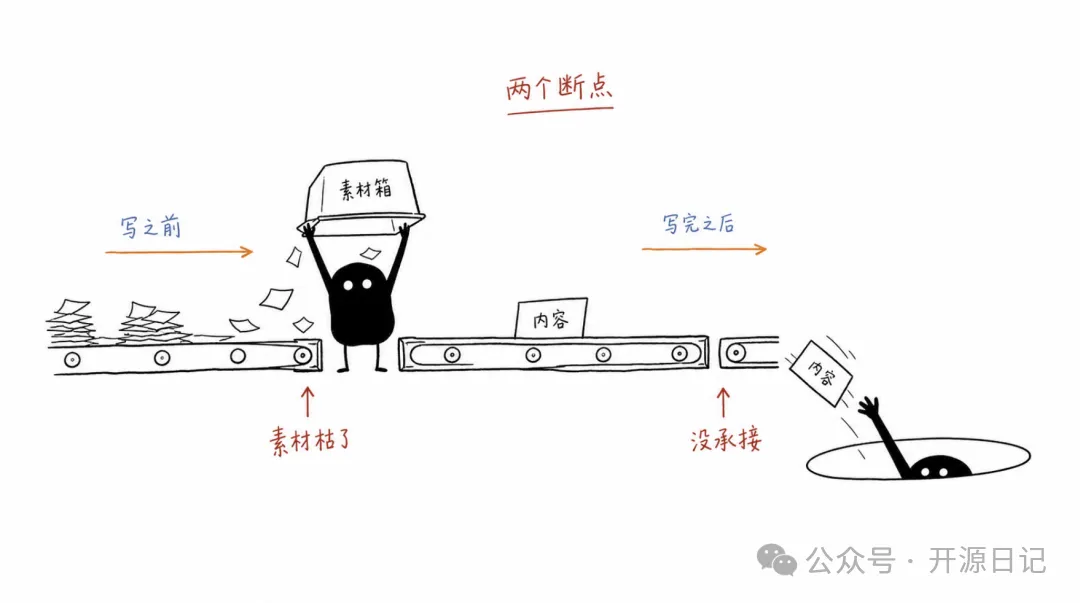
同一般繪圖軟件唔同嘅係,佢唔會隨便幫你生成一幅「好」嘅圖像。
佢首先確定你篇文章入面有邊啲認知錨點,然後從中揀一個作為判斷、流程、結構、狀態或者隱喻,並且畫成一幅 16:9 嘅白底手繪線稿。
有趣嘅係,唔係幫你「配一張圖」,而係要令 AI 將文章中一個重要嘅認知動作畫出嚟。
呢個項目嘅作者係 Ian,喺 ByteDance 做產品設計。
佢喺寫文章需要配圖嘅時候發現傳統嘅兩種方式有缺陷:揾圖片好花時間,而且配圖同觀點無關。
所以佢就將設計思維、審美品味做成咗一套可以複製嘅系統。
佢嘅核心 IP 係「小黑」,一個有性格嘅角色。
01 小黑唔係吉祥物。
黑色嘅身體、白色嘅眼睛、幼幼嘅腳、空洞嘅表情嘅小角色,喺 README 入面都講得好清楚,呢個並唔係貼紙,亦唔係用嚟裝飾嘅。

係正在認真參與系統運轉嘅荒誕工作者。
02 小黑一定要承擔核心動作。
譬如話要表達出「信任唔係叫出嚟嘅,而係通過一塊塊咁用證據去鋪設」嘅意思嘅時候,小黑就攞住一條信任橋嘅木樁,喺路邊行邊講。
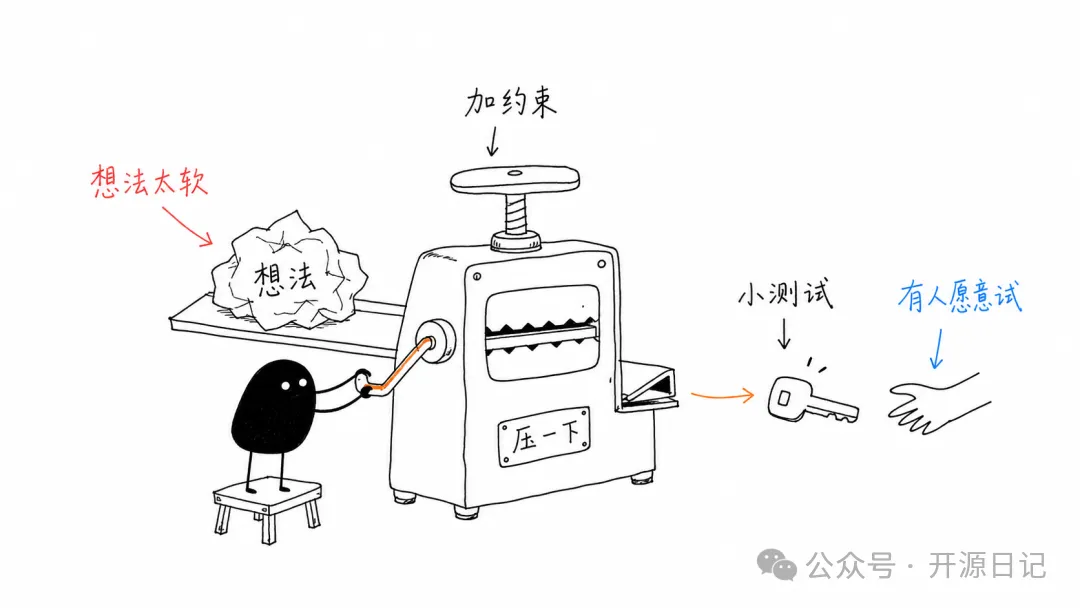
當你要表達「想法由模糊變清晰」嘅時候,小黑就會被放喺想法壓機之下,經過被壓、提純同磨礪嘅過程。
03 拎走小黑畫面仍然完全成立,表示小黑太裝飾性啦。
呢個就係 Ian 俾自己定嘅規則。小黑要承擔主要工作,而唔係淨係企喺度賣萌。
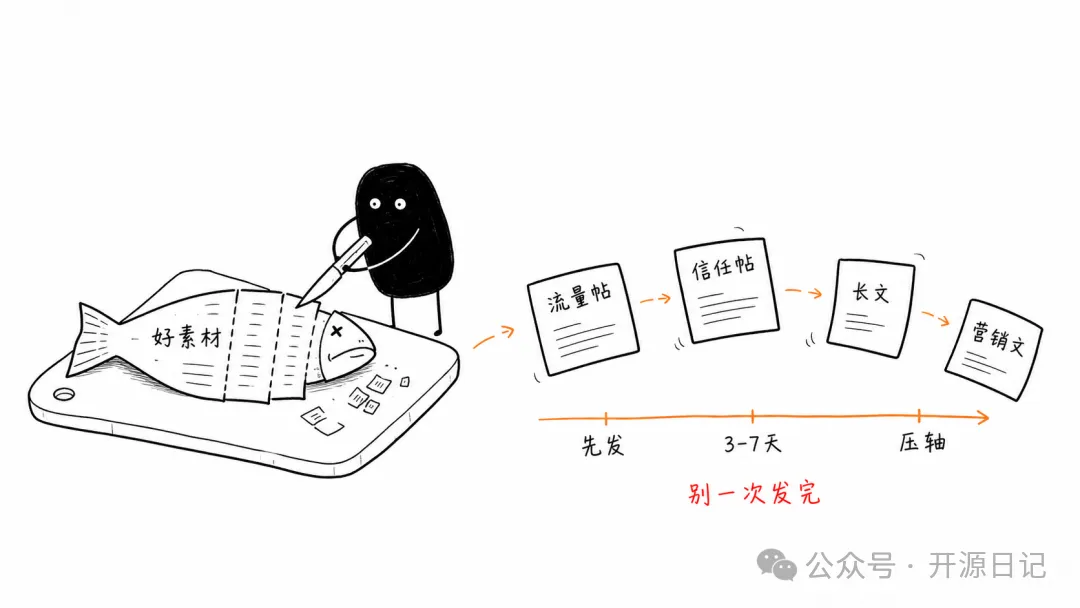
04 視覺風格好剋制。
純白背景,唔要紙紋、米色、陰影、漸變。
黑手繪線稿、幼線、微微抖動。
留白較多,主體只佔畫面嘅四分之三到三分之二左右。奇怪、有趣、清新,但係唔幼稚亦唔賣萌。
05 支援三種使用模式。
配圖規劃模式只輸出 shot list,直接生成模式直接生成 4-8 張 PNG,單圖生成模式係單一個概念生成一張圖。
生成嘅圖片會自動被保存到 workspace/assets 資料夾入面。
到呢度我哋再簡單講嚇原理。
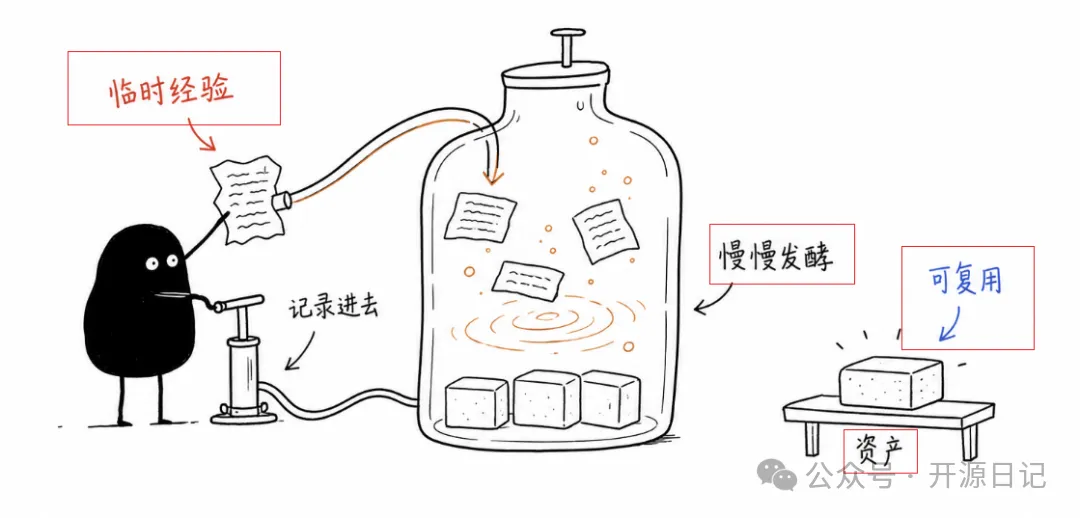
呢個技能嘅工作原理好簡單。
將文章俾佢,佢就會先分析出邊度可以配圖,並且輸出一個 shot list,每張圖只講一個認知錨點。
可能係某個判斷,都可能係一個流程嘅結構,或者係某種隱喻。
然後幫每個錨點都創建咗一個低級、荒誕嘅物理環境,喺入面令小黑工作。
生成嘅圖片係 16:9 橫版白底手繪線稿,並配有少量紅、橙、藍三色嘅手寫批註。
一張圖只表達一個意思,唔做PPT信息圖、唔寫說明書。
睇完呢啲,你可能想試嚇。
Clone 倉庫,複製 skill 到 Codex skills 目錄。
git clone https://github.com/helloianneo/ian-xiaohei-illustrations.git
mkdir -p "${CODEX_HOME:-$HOME/.codex}/skills"
cp -R ./ian-xiaohei-illustrations "${CODEX_HOME:-$HOME/.codex}/skills/"
然後喺 Codex 入面輸入:
Use $ian-xiaohei-illustrations 為這篇中文文章設計並生成 5 張小黑怪誕正文配圖。
到呢度缺點都同大家提一提。
目前佢只適用於中文字文章嘅配圖,如果要用佢嚟做商業插畫、品牌 KV 或者精緻扁平插畫就唔係咁適合。
兒童卡通、可愛 IP、表情包風格唔支援,或者需要嚴格可編輯矢量源檔案嘅項目,呢個產品都做唔到。
預設情況下唔輸出 PPTX、PDF、Keynote、SVG、HTML 等格式。
另外圖片中出現嘅中文文字越少就越穩定,AI 圖像模型會出現錯誤嘅文字、幻覺標籤、風格漂移或者多餘嘅標題等現象,喺生成之後要檢查。
如果中文錯誤好多嘅話,可以減少標註詞之後再重新生成。
寫喺最後
以前揾配圖,我會喺 Unsplash 上搜關鍵詞嚟攞圖片。
揭幾頁,覺得差唔多就將佢哋放落去。
直到見到 Ian Xiaohei Illustrations,先發現自己一路以嚟將配圖當裝飾。
唔揾圖片,喺文章入面提煉出主要觀點,再將佢哋變成人哋容易記住嘅形象。
好多時候,讀者唔記得文字,但係記得嗰張圖。
呢樣令我想起一件事:
AI 生成嘅內容越來越容易,但係喺邊度配圖片、用咩嘢圖片最恰當呢啲判斷仍然好有價值。
工具負責生產,判斷負責選擇。
你哋平時寫文章,會專門設計配圖㗎?
定係好似以前嘅我咁,揾張差唔多嘅就用咗?
項目基於 MIT 協議開放,有興趣嘅同學可以去 GitHub 倉庫睇嚇源碼同文檔。
開源地址:https://github.com/helloianneo/ian-xiaohei-illustrations
既然睇到呢度,歡迎順手讚好、在看、轉發,都可以俾我一個星標⭐,接收最新嘅文章,我哋下期見!
又一個神級 Skill 開源了。
23 天拿了 5300 多個 Star,只做一件事:給中文文章生成正文配圖。
項目名叫 Ian Xiaohei Illustrations,其實就是給中文文章配上插圖的一個AI能力。
與一般的繪圖軟件不同的是,它並不會隨意地為你產生一幅“好”的圖像。
它首先確定你的文章裏有哪些認知錨點,然後從中選擇一個作為判斷、流程、結構、狀態或者隱喻,並且把它畫成一幅 16:9 的白底手繪線稿。
有趣的是,並不是為你“配一張圖”,而是要讓 AI 把文章中一個重要的認知動作畫出來。
這個項目的作者是 Ian,在 ByteDance 做產品設計。
他在寫文章需要配圖時發現傳統的兩種方式存在缺陷:找圖片耗時長,而且配圖和觀點無關。
因此他就把設計思維、審美品位做成了一套可複製的系統。
它的核心 IP 是"小黑",一個有性格的角色。
01 小黑不是吉祥物。
黑色的身體、白色的眼睛、細細的腿、空洞的表情的小角色,在README裏也說得很清楚,這個並不是貼紙,也不是用來裝飾的。
是正在認真參與系統運轉的荒誕工作者。
02 小黑必須承擔核心動作。
比如說要表達出“信任不是喊出來的,而是通過一塊塊地用證據去鋪設”的意思的時候,小黑就拿着一根信任橋的木樁,在路上邊走邊說。
當你要表達“想法由模糊變清晰”的時候,小黑就會被放在想法壓機之下,經過被壓、提純和磨礪的過程。
03 去掉小黑畫面仍然完全成立,說明小黑太裝飾了。
這就是Ian給自己制定的規則。小黑要承擔主要工作,而不僅僅是站那兒賣萌。
04 視覺風格很剋制。
純白背景,不要紙紋、米色、陰影、漸變。
黑手繪線稿、細線、微抖。
留白較多,主體只佔畫面的四分之三到三分之二左右。奇怪、有趣、清新,但是不幼稚也不賣萌。
05 支持三種使用模式。
配圖規劃模式只輸出shot list,直接生成模式直接生成4-8張PNG,單圖生成模式是單個概念生成一張圖。
生成的圖片會自動被保存到workspace/assets文件夾裏。
到這我們再簡單說一下原理
該技能的工作原理很簡單。
把文章給它,它就會先分析出哪裏可以配圖,並且輸出一個shot list,每張圖只講一個認知錨點。
可能是某個判斷,也可能是一個流程的結構,或者是某種隱喻。
然後給每個錨點都創建了一個低級、荒誕的物理環境,在其中讓小黑工作。
生成的圖片為16:9橫版白底手繪線稿,並配有少量紅、橙、藍三色的手寫批註。
一張圖只表達一個意思,不做PPT信息圖、不寫說明書。
看完這些,你可能想試試
克隆倉庫,複製 skill 到 Codex skills 目錄。
git clone https://github.com/helloianneo/ian-xiaohei-illustrations.git
mkdir -p "${CODEX_HOME:-$HOME/.codex}/skills"
cp -R ./ian-xiaohei-illustrations "${CODEX_HOME:-$HOME/.codex}/skills/"
然後在 Codex 裏輸入:
Use $ian-xiaohei-illustrations 為這篇中文文章設計並生成 5 張小黑怪誕正文配圖。
到這裏缺點也給大家提提。
目前它只適用於中文字文章的配圖,如果要用它來做商業插畫、品牌KV或者精緻扁平插畫就不太合適了。
兒童卡通、可愛IP、表情包風格不支持,或者需要嚴格可編輯矢量源文件的項目,該產品也做不到。
默認情況下不輸出PPTX、PDF、Keynote、SVG、HTML等格式。
另外圖片中出現的中文文字越少就越穩定,AI圖像模型會出現錯誤的文字、幻覺標籤、風格漂移或者多餘的標題等現象,在生成之後要進行檢查。
如果中文錯誤很多的話,可以減少標註詞之後再重新生成。
寫在最後
以前找配圖,我會在Unsplash上搜索關鍵詞來獲取圖片。
翻幾頁,感覺差不多了就把它們放進去。
直到看到 Ian Xiaohei Illustrations,才發現自己一直把配圖當裝飾。
不找圖片,在文章裏提煉出主要觀點,再把它們變成人們容易記住的形象。
很多時候,讀者忘了文字,卻記得那張圖。
這讓我想到一件事:
AI生成的內容越來越容易了,但是在哪裏配上圖片、用什麼樣的圖片最恰當這樣的判斷仍然很有價值。
工具負責生產,判斷負責選擇。
你們平時寫文章,會專門設計配圖嗎?
還是像以前的我一樣,找張差不多的就用了?
項目基於 MIT 協議開放,感興趣的同學可以去 GitHub 倉庫看看源碼和文檔。
開源地址:https://github.com/helloianneo/ian-xiaohei-illustrations
既然看到這了,歡迎隨手點贊、在看、轉發,也可以給我個星標⭐,接收最新的文章,我們下期見!