同一個大模型,為什麼到了Claude Code裏就像開了掛?
整理版優先睇
Harness(框架)先係決定Agent表現嘅關鍵,唔係模型本身
呢篇文章引用Sebastian Raschka(《從零構建大語言模型》作者)嘅分析,拆解點解同一個Claude模型喺網頁聊天框同Claude Code嘅表現相差咁遠。作者指出,秘密唔喺模型,而係包裹模型嘅嗰層「Harness」(框架)。Harness就好似電腦嘅操作系統,決定咗LLM呢粒CPU點樣調用工具、管理上下文、處理錯誤,甚至點樣分工。
Harness主要由五個核心組件構成:Tool Use Loop(諗→做→睇→再諗嘅循環)、Tool System(預定義工具清單)、Context Assembly(開工前收集穩定資訊)、Context Management(壓縮剪裁防止上下文膨脹)同I/O Layer(輸入輸出同權限確認)。呢啲組件加埋,令到Agent唔單止係問答機器,而係一個真正可以自動完成複雜任務嘅系統。
作者又用自己寫嘅600行Mini Coding Agent同Claude Code嘅20萬行做對比,話「能用」同「好用」之間嘅距離就係Harness打磨嘅功夫。而家Anthropic仲直接推出Managed Agents,將Harness層一鍵打包,連部署、記憶、容錯都內置好。作者最後反思:當模型同Harness都俾巨頭標準化,真正嘅競爭力可能係垂直行業深度、私有數據、安全合規,同埋獨一無二嘅用戶體驗。
- Harness(框架)係決定Agent表現嘅關鍵因素,比LLM模型本身更重要。
- Harness嘅核心係Tool Use Loop,令Agent可以實際執行命令並獲取結果,唔似普通聊天機器人得個講字。
- Harness分五大組件:Tool Use Loop、Tool System、Context Assembly、Context Management、I/O Layer,各自解決唔同問題。
- 最小可行Harness只需600行Python,但Claude Code寫咗20萬行,反映「能用」到「好用」嘅巨大差距。
- Anthropic推出Managed Agents,將Harness層一鍵打包,創業團隊嘅基建壁壘正在消失;未來應轉向創造獨一無二嘅體驗。
Harness係乜?用類比秒懂
LLM就係一台發動機,Agent係裝咗底盤輪子嘅自動駕駛汽車,而Harness就係車架、變速箱同導航系統。
作者用呢個類比解釋:用戶唔係司機,而係乘客——你只需要講「去機場」,Agent自己搞掂。Harness就係確保引擎可以真正上路嘅一切配套。
呢個比喻令讀者一睇就明:模型層面嘅差距越來越細,真正拉開距離嘅係Harness呢層嘅設計同執行。
拆開Harness:5個核心組件
Claude Code嘅51萬行代碼入面,Harness嘅骨架可以歸納為五個部分。每一個都係令Agent由「問答機」進化成「自動駕駛」嘅關鍵。
- 1 Tool Use Loop(心臟):諗→做→睇→再諗嘅循環。Agent唔係淨係建議,而係真係執行命令兼睇結果。核心只需20行code,但冇咗佢LLM只係問答機器。
- 2 Tool System(手腳):提供預定義工具清單,例如讀文件、寫代碼、跑命令。框架會檢查工具名、參數、權限,唔畀模型任意發揮。
- 3 Context Assembly(大腦輸入):開工前自動蒐集Git分支、項目結構、README等「穩定事實」,做曬緩存,避免每輪重新建構。
- 4 Context Management(容量管理):壓縮長輸出、剪裁早期事件、對舊文件去重,防止聊廿輪就上下文爆煲。呢啲「無聊」工序直接影響模型表現。
- 5 I/O Layer(嘴和耳朵):處理輸入輸出同權限確認。將狀態分為工作記憶(跨輪次重要資訊)同完整會話紀錄(可恢復),所以你可以接住上次工作繼續。
呢五個組件加埋,就係Harness嘅完整架構。作者特別強調Context Management係被低估嘅部分,好多表面嘅「模型質量」實際上都係上下文質量。
600行 vs 20萬行:從「能用」到「好用」嘅距離
Sebastian Raschka用純Python寫咗一個Mini Coding Agent,證明最小可行Harness只需要大約600行代碼。而Anthropic嘅Claude Code寫咗20萬行。
呢個差距反映咗乜?就係MCP生態、Skill系統、安全機制、子Agent委託、UI打磨——呢啲先係令Agent由「用到」變成「好用」嘅關鍵。
子Agent係一個特別有意思嘅能力:主Agent可以將工作拆成子任務並行處理,例如「邊個文件定義咗呢個函數」、「呢個配置講咗咩」。子Agent繼承部分上下文,但喺更嚴格嘅邊界(例如唯讀、限制遞歸深度)下運行。
巨頭下場:Harness被一鍵打包
正當大家仲討論緊Harness有幾重要嘅時候,Anthropic直接推出Managed Agents——將伺服器部署、安全沙箱、上下文管理、記憶儲存、循環調度、報錯重試、權限管控等底層基建全部內置。
你只需要喺聊天打一句「做競品價格監控、每日自動爬取、異常告警發報告」,就自動生成一個可落地嘅全自動Agent,開箱即用,零底層運維。
作者分析呢個動作嘅策略:前腳封鎖第三方生態將工具調用入口握喺自己手,後腳用官方託管Agent補齊全鏈路能力,將流量、算力、執行環境全部閉環。
對創業團隊嚟講,Harness層嘅基建壁壘正在急速消失——官方已經幫你搞掂曬,你唔使再從頭卷底層。
反思:未來應該卷邊一層?
作者提出一個殘酷問題:模型層大廠自己卷、Harness層官方內置、MCP同Skill層遲早俾LLM吸收埋,我哋仲可以卷啲乜?
- 1 垂直行業深度場景:通用Harness解決唔到嘅行業Know-How,雖然通用模型慢慢都會吸收。
- 2 高壁壘私有數據:模型再強都冇你手上嘅獨有數據。
- 3 企業私有化部署:安全合規係硬需求,係苦力活但永遠有人需要。
- 4 落地定製交付服務:最後一公里永遠需要人嚟做。
作者嘅最終結論係:唔好再諗「卷邊一層」,而係要諗「我能創造乜嘢獨一無二嘅體驗」。技術棧會俾人抹平,但審美、判斷力、對特定人羣嘅深度理解——呢啲係大模型學唔走嘅。
秘密唔係喺模型,而係喺Harness?
你有冇呢種感覺:同一個Claude模型,喺網頁聊天框裏面寫代碼平平無奇,但係一到咗Claude Code,突然之間就似開咗掛咁?
唔係錯覺。差距係真實存在嘅。
但秘密唔係喺模型本身——而係喺包住模型嘅嗰層「框架」(Harness)。
一個比喻,秒明Harness
用一個你一定明嘅比喻:
LLM就係一部引擎。單缸細引擎,識轉但係跑唔遠。 推理模型係V6渦輪增壓,夠力但又貴又重。 Agent呢?係俾引擎裝上底盤、車輪、車架,變成一架自動駕駛車。
關鍵嚟喇——用戶唔係司機,用戶係乘客。你淨係需要講「去機場」,Agent自己揸車。呢個先係Agent嘅本質:你畀目標,佢自己決定點樣到達。
而Harness(框架)就係呢架車嘅底盤、波箱、導航系統——係令到引擎真正可以上路嘅一切。

再換個比喻:Harness係Agent嘅「操作系統」
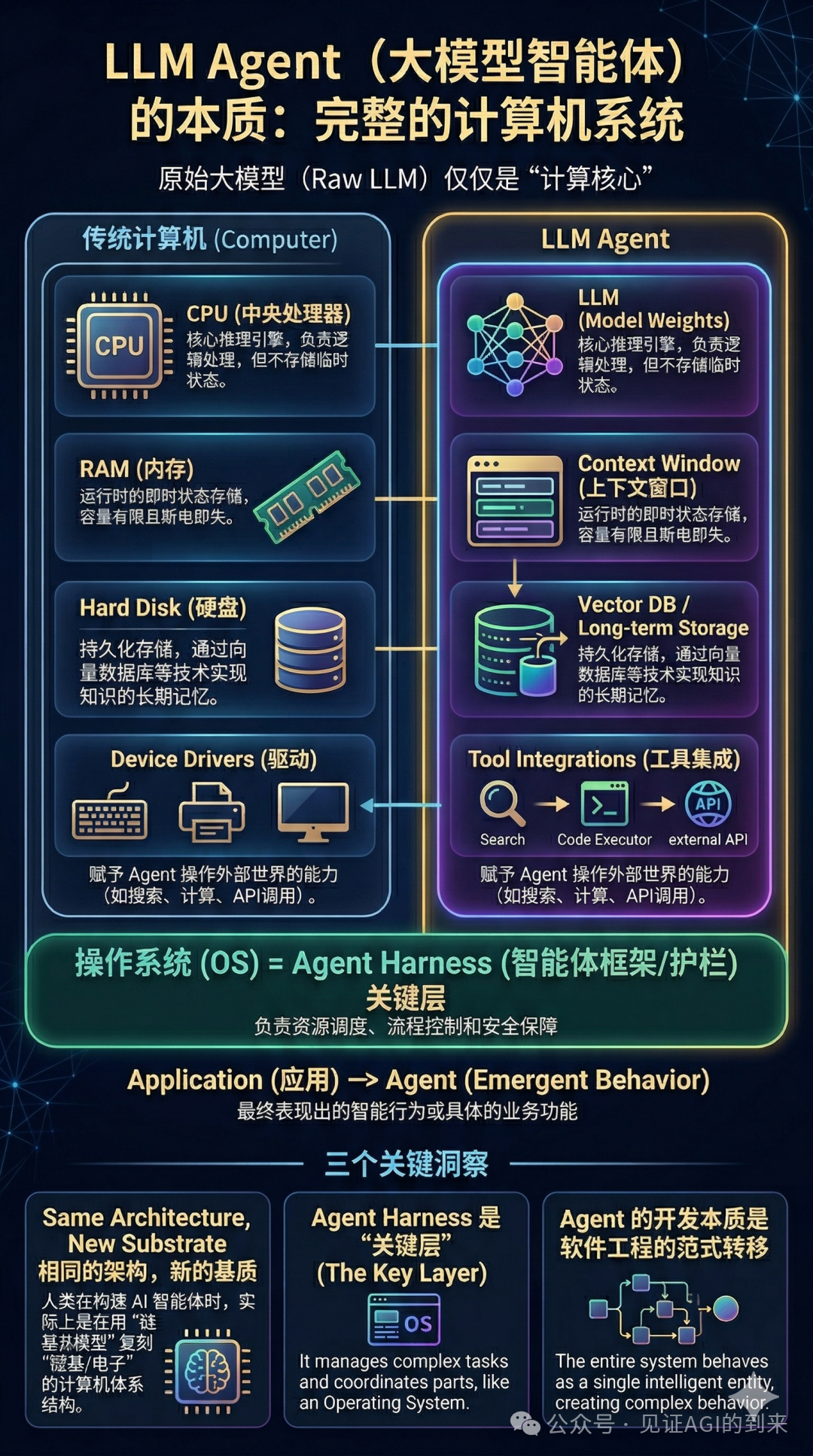
換一個電腦比喻:一部電腦 = 一個Agent。
LLM = CPU:核心計算引擎,淨係負責推理運算,本身唔存任何狀態。呢一層雖然仲有差距,但愈嚟愈細。 Tools(工具)= 外設:搜尋係鍵盤,代碼執行係滑鼠,API調用係打印機。冇外設,CPU再勁都感知唔到、操控唔到外部世界。 Context Window = 記憶體(RAM):運行時嘅即時狀態,會話一完,全部清零。 向量數據庫 = 硬碟:真正嘅長期記憶放喺呢度,斷電唔會丟。 Harness = 操作系統:呢個先係核心。佢決定:幾時用邊個外設、塞啲乜嘢記憶、失敗咗點樣重試、多個Agent點樣分工。
冇操作系統,CPU就係一塊發熱嘅鐵。
點解Harness先係真正嘅差距?
Sebastian Raschka(《從零構建大語言模型》作者)最近寫咗一篇深度文章,拆解咗編碼Agent嘅核心組件。佢嘅核心觀點係:
「因為而家各家LLM嘅基礎版本能力非常相似,框架往往變成令一個LLM比另一個表現更好嘅決定性因素。」
換句話講,GPT-5.4、Claude Opus 4.6、GLM-5呢啲模型嘅裸實力差距冇咁大。真正拉開差距嘅,係邊個嘅Harness做得更好。
編碼工作只有一部分係關於「下一個token生成」嘅。更大嘅一部分係:倉庫導航、文件搜尋、函數查找、diff應用、測試執行、錯誤檢查,同埋將所有相關資訊保持喺上下文中。程序員都知道呢個有幾咁花腦力——呢個就係點解我哋唔鍾意喺編碼時被打斷。
Harness幫模型擔起咗呢啲「腦力活」。
拆開Harness,入面到底有啲乜?
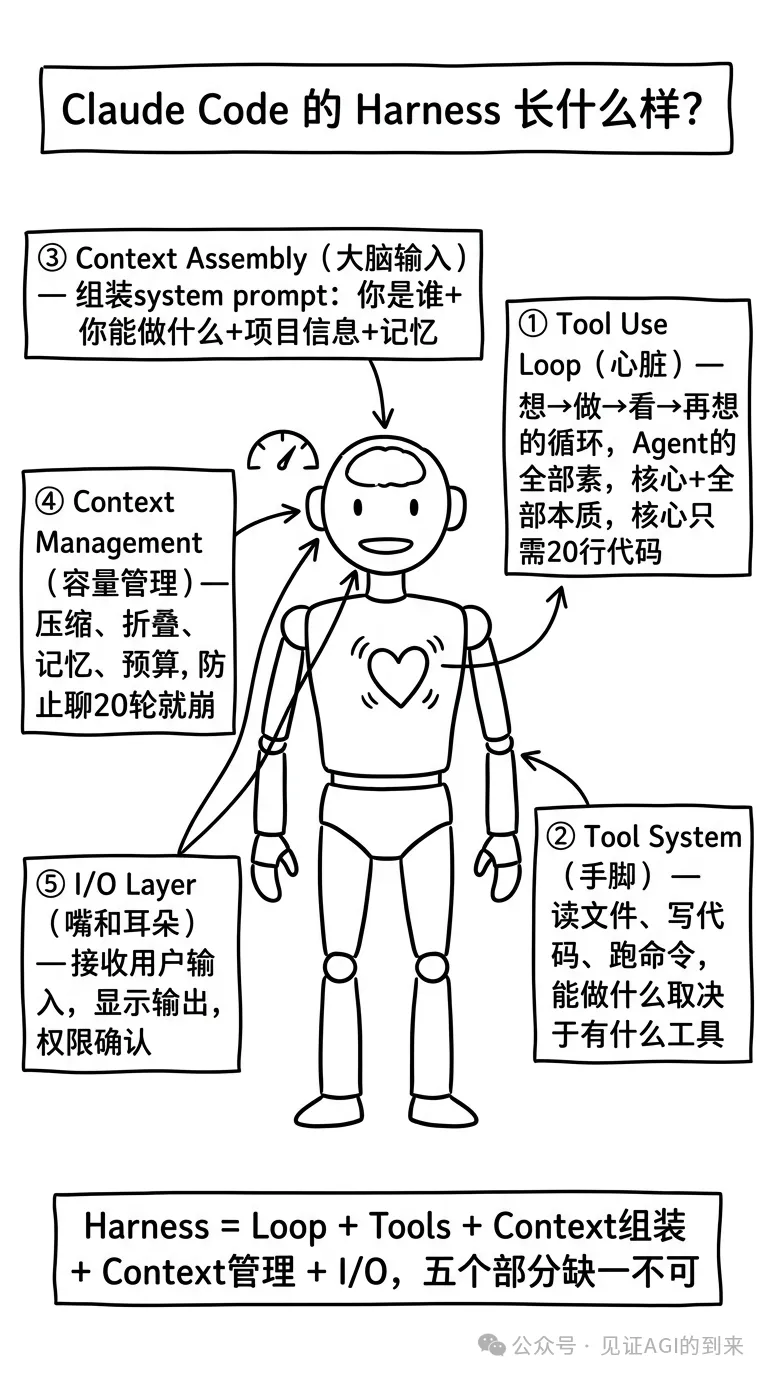
拆開Claude Code嘅51萬行代碼,真正嘅Harness骨架可以歸納為5個核心部分:
1. Tool Use Loop(心臟)
諗 → 做 → 睇 → 再諗嘅循環。呢個係Agent同普通聊天機器人嘅本質區別。普通模型只能用文字「建議」命令,而Agent框架入面嘅LLM能夠實際執行命令並攞到結果。模型發出結構化動作,框架驗證佢,可選地請求批准,執行佢,並將結果反饋返去循環。核心只需要20行代碼,但冇佢LLM就只係個問答機器。
2. Tool System(手腳)
讀文件、寫代碼、執行命令、搜尋倉庫——做到啲乜取決於有咩工具。框架唔會畀模型即興發揮任意語法,而係提供一個預定義嘅、有明確輸入同明確邊界嘅命名工具列表。每次模型請求執行操作時,運行時會檢查:呢個係已知工具嗎?參數有效嗎?需要用戶批准嗎?路徑喺工作區內嗎?只有檢查通過先至會真正執行。
3. Context Assembly(大腦輸入)
話畀LLM知你係邊個、做到啲乜、個項目係點樣。Agent喺開始工作之前就預先收集資訊——Git分支、項目結構、README、配置文件——作為「穩定事實」,咁樣佢就唔會每次提示都從零開始。智能運行時仲會將呢啲穩定資訊整成可緩存嘅前綴,避免每輪都重建,大幅節省計算資源。
4. Context Management(容量管理)
壓縮、摺疊、記憶,防止傾20輪就冧。編碼Agent比普通聊天更容易上下文膨脹——重複嘅文件讀取、冗長嘅工具輸出、日誌堆積。好嘅框架至少用兩種策略:裁剪(縮短長輸出)同會話記錄縮減(保持近期事件豐富,積極壓縮早期事件)。仲會對舊嘅文件讀取去重,避免模型反覆睇到相同內容。呢個係被低估嘅「無聊」部分——好多表面嘅「模型質量」實際上係上下文質量。
5. I/O Layer(嘴同耳)
接收輸入、顯示輸出、權限確認。Agent將狀態分為兩層:工作記憶(小型精煉狀態,跨輪次保持重要資訊)同完整會話記錄(所有用戶請求、工具輸出同LLM響應嘅完整歷史)。關閉Agent之後可以恢復,呢個就係點解你可以接住上次嘅工作繼續。
最震撼嘅對比:600行 vs 20萬行
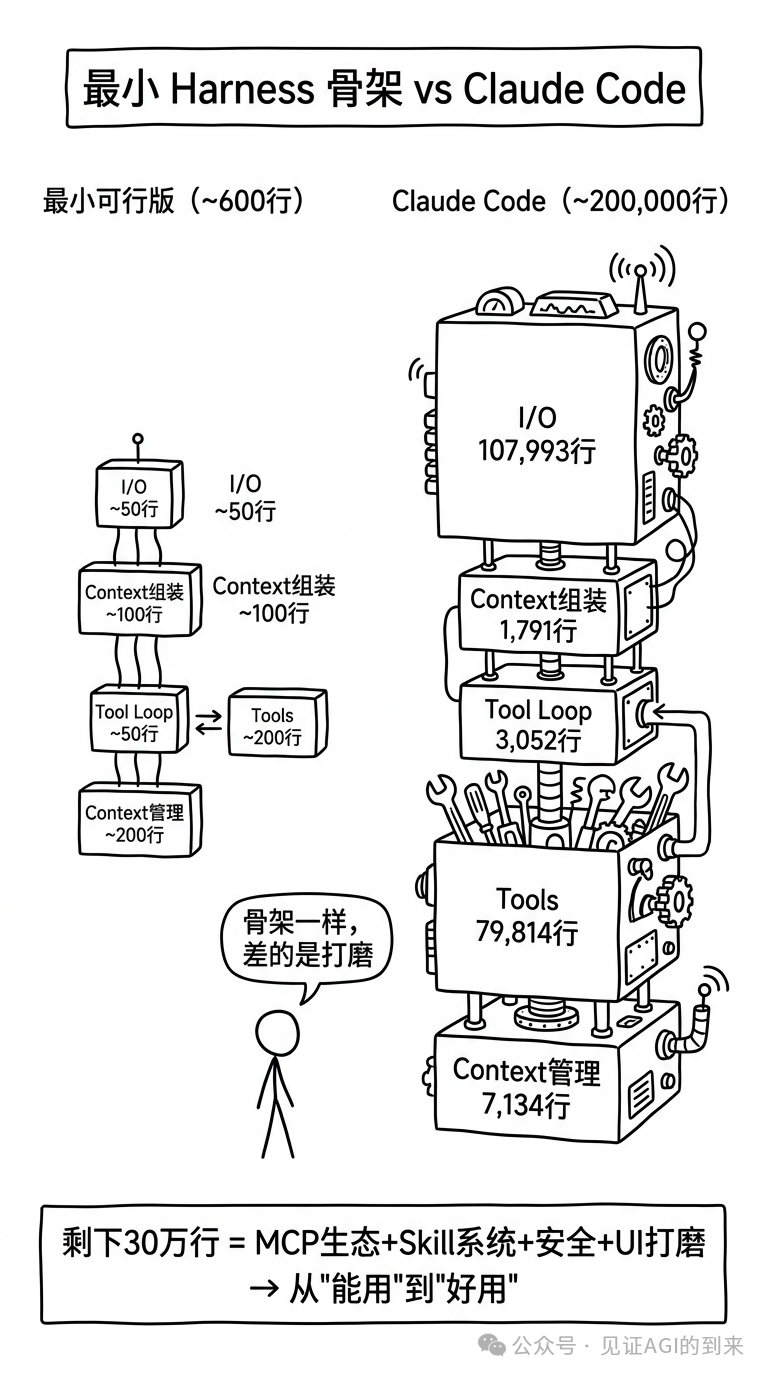
Sebastian Raschka自己用純Python寫咗一個Mini Coding Agent,證明咗一個最小可行嘅Harness只需要大概600行代碼。
而Claude Code寫咗20萬行。
淨低嘅差距係乜?MCP生態、Skill系統、安全機制、子Agent委託、UI打磨——從「用到」到「好用」嘅距離。
子Agent係一個特別有意思嘅能力:主Agent可以將某啲工作拆分做子任務並行處理,好似「邊個文件定義咗呢個函數」、「呢個配置講咗啲乜」。子Agent繼承足夠嘅上下文以發揮作用,但係喺比主Agent更嚴格嘅邊界內運行——通常係唯讀嘅,而且限制遞歸深度。
巨頭落場:Harness正被一鍵打包
就喺我哋仲喺度討論Harness有幾重要嘅時候,Claude直接掟出咗王炸——Managed Agents(託管智能體)。
以前做Agent創業,團隊大半精力都喺度捲底層基建:服務器部署、安全沙箱、上下文管理、記憶存儲、循環調度、報錯重試、運行監控、權限管控……淨係想Agent行得穩定,就要用幾個月研發。
而家Anthropic一步全部打包內置:自帶24小時離線運行、跨週期長記憶、可視化儀錶板、自動容錯自癒,官方Harness編排引擎直接配齊。你只需要傾偈寫一句需求:「做競品價格監控、每日自動爬取、異常警報出報告」。
一句話生成可落地全自動Agent,開箱即用,零底層運維。Harness呢一層全部包曬,畀錢用就得。
前腳啱啱封鎖第三方生態,將工具調用入口牢牢揸喺自己手度;後腳官方託管Agent直接補齊全鏈路能力,將流量、算力、執行環境全部閉環。
問題:我哋到底應該發展邊一層?
行業現狀愈嚟愈殘酷:
模型層——大廠自己捲,我哋捲唔鬱 Harness層——官方正喺度一鍵內置,創業團隊最核心嘅壁壘正喺度消失 MCP/Skill/工具層——將來一定會畀LLM吸收咗,畢竟都會傳過去,都冇乜壁壘,半年後Skill唔使寫,大模型都知咗
我哋而家做Agent,其實係基於大模型重新發明自己業務嘅「操作系統」。一聽係做操作系統,好似每一層都有好多嘢可以做——上下文管理、各種MCP、Skill編排——幹勁十足。
但冷靜諗下:模型捲完、Harness基建捲完、MCP同Skill都俾LLM吞埋,AI行業跟住我哋到底仲可以捲啲乜?
或者答案喺呢幾個方向:
•垂直行業深度場景——通用Harness解決唔到嘅行業Know-How
感覺通用慢慢都喺度吸收垂直數據,只要你用,就會被吸收。
•高壁壘私有數據——模型再勁都冇你嘅數據
愈嚟愈薄。
•企業私有化部署——安全合規係剛需
存在,苦力活。
•落地定製交付服務——最後一公里永遠需要人
真正值得反思嘅係:當每一層基礎設施都喺度畀巨頭吞噬嘅時候,或者我哋唔應該再諗「捲邊一層」,而應該諗「我能創造啲乜獨一無二嘅體驗」。技術棧會被抹平,但審美、判斷力、對特定人羣嘅深度理解——呢啲係大模型學唔走嘅。
一句話:引擎標配之後,但當車都變成標配嘅時候,真正嘅競爭力係——自動駕駛?定係乜。
#AI編程#ClaudeCode#Agent#大模型#Harness#編碼Agent#ManagedAgents
秘密不在模型,在Harness?
你有沒有這種感覺:同一個Claude模型,在網頁聊天框裏寫代碼平平無奇,但到了Claude Code裏,突然就像開了掛一樣?
不是錯覺。差距是真實存在的。
但秘密不在模型本身——在於包裹模型的那層"框架"(Harness)。
一個類比,秒懂Harness
用一個你一定能理解的類比:
LLM就是一台發動機。單缸小引擎,能轉但跑不遠。 推理模型是V6渦輪增壓,動力猛但又貴又重。 Agent呢?是給引擎裝上底盤、輪子、車架,變成一輛自動駕駛汽車。
關鍵來了——用戶不是駕駛員,用戶是乘客。你只需要說"去機場",Agent自己開車。這才是Agent的本質:你給目標,它自己決定怎麼到達。
而Harness(框架)就是這輛車的底盤、變速箱、導航系統——是讓發動機真正能上路的一切。
再換個比喻:Harness是Agent的"操作系統"
換一個計算機:一台電腦 = 一個Agent。
LLM = CPU:核心計算引擎,只負責推理運算,本身不存任何狀態。這一層雖然還有差距,但越來越小。 Tools(工具)= 外設:搜索是鍵盤,代碼執行是鼠標,API調用是打印機。沒有外設,CPU再強也感知不了、操控不了外部世界。 Context Window = 內存(RAM):運行時的即時狀態,會話一結束,全部清零。 向量數據庫 = 硬盤:真正的長期記憶放在這裏,斷電不丟。 Harness = 操作系統:這才是核心。它決定:什麼時候調哪個外設、塞哪些記憶、失敗了怎麼重試、多個Agent怎麼分工。
沒有操作系統,CPU就是一塊發熱的鐵。
為什麼Harness才是真正的差距?
Sebastian Raschka(《從零構建大語言模型》作者)最近寫了一篇深度文章,拆解了編碼Agent的核心組件。他的核心觀點是:
"由於現在各家LLM的基礎版本能力非常相似,框架往往成為讓一個LLM比另一個表現更好的決定性因素。"
換句話說,GPT-5.4、Claude Opus 4.6、GLM-5這些模型的裸實力差距沒那麼大。真正拉開差距的,是誰的Harness做得更好。
編碼工作只有一部分是關於"下一個token生成"的。更大的一部分是:倉庫導航、文件搜索、函數查找、diff應用、測試執行、錯誤檢查,以及將所有相關信息保持在上下文中。程序員都知道這有多費腦力——這就是為什麼我們不喜歡在編碼時被打斷。
Harness替模型承擔了這些"腦力活"。
拆開Harness,裏面到底有什麼?
拆開Claude Code的51萬行代碼,真正的Harness骨架可以歸納為5個核心部分:
1. Tool Use Loop(心臟)
想 → 做 → 看 → 再想的循環。這是Agent和普通聊天機器人的本質區別。普通模型只能用文字"建議"命令,而Agent框架中的LLM能實際執行命令並獲取結果。模型發出結構化動作,框架驗證它,可選地請求批准,執行它,並將結果反饋回循環。核心只需20行代碼,但沒有它LLM就只是個問答機器。
2. Tool System(手腳)
讀文件、寫代碼、跑命令、搜索倉庫——能做什麼取決於有什麼工具。框架不會讓模型即興發揮任意語法,而是提供一個預定義的、有明確輸入和明確邊界的命名工具列表。每次模型請求執行操作時,運行時會檢查:這是已知工具嗎?參數有效嗎?需要用戶批准嗎?路徑在工作區內嗎?只有檢查通過才會真正執行。
3. Context Assembly(大腦輸入)
告訴LLM你是誰、能做什麼、項目長什麼樣。Agent在開始工作之前就預先收集信息——Git分支、項目結構、README、配置文件——作為"穩定事實",這樣它不會每次提示都從零開始。智能運行時還會把這些穩定信息做成可緩存的前綴,避免每輪都重建,大幅節省計算資源。
4. Context Management(容量管理)
壓縮、摺疊、記憶,防止聊20輪就崩。編碼Agent比普通聊天更容易上下文膨脹——重複的文件讀取、冗長的工具輸出、日誌堆積。好的框架至少用兩種策略:裁剪(縮短長輸出)和會話記錄縮減(保持近期事件豐富,積極壓縮早期事件)。還會對舊的文件讀取去重,避免模型反覆看到相同內容。這是被低估的"無聊"部分——很多表面上的"模型質量"實際上是上下文質量。
5. I/O Layer(嘴和耳朵)
接收輸入、顯示輸出、權限確認。Agent將狀態分為兩層:工作記憶(小型精煉狀態,跨輪次保持重要信息)和完整會話記錄(所有用戶請求、工具輸出和LLM響應的完整歷史)。關閉Agent後可恢復,這就是為什麼你能接着上次的工作繼續。
最震撼的對比:600行 vs 20萬行
Sebastian Raschka自己用純Python寫了一個Mini Coding Agent,證明了一個最小可行的Harness只需要約600行代碼。
而Claude Code寫了20萬行。
剩下的差距是什麼?MCP生態、Skill系統、安全機制、子Agent委託、UI打磨——從"能用"到"好用"的距離。
子Agent是個特別有意思的能力:主Agent可以把某些工作拆分為子任務並行處理,比如"哪個文件定義了這個函數"、"這個配置說了什麼"。子Agent繼承足夠的上下文以發揮作用,但在比主Agent更嚴格的邊界內運行——通常是隻讀的,且限制遞歸深度。
巨頭下場:Harness正在被一鍵打包
就在我們還在討論Harness有多重要的時候,Claude直接甩出了王炸——Managed Agents(託管智能體)。
以前做Agent創業,團隊大半精力都在卷底層基建:服務器部署、安全沙箱、上下文管理、記憶存儲、循環調度、報錯重試、運行監控、權限管控……光是把Agent跑穩定,就要耗掉幾個月研發。
現在Anthropic一步全部打包內置:自帶24小時離線運行、跨週期長記憶、可視化儀表盤、自動容錯自愈,官方Harness編排引擎直接配齊。你只需要聊天寫一句需求:"做競品價格監控、每日自動爬取、異常告警發報告"。
一句話生成可落地全自動Agent,開箱即用,零底層運維。Harness這一層全包了,付錢用就行了。
前腳剛封鎖第三方生態,把工具調用入口牢牢握在自己手裏;後腳官方託管Agent直接補齊全鏈路能力,把流量、算力、執行環境全部閉環。
問題:我們到底該發展哪一層?
行業現狀越來越殘酷:
模型層——大廠自己卷,我們卷不動 Harness層——官方正在一鍵內置,創業團隊最核心的壁壘正在消失 MCP/Skill/工具層——未來一定也會被LLM吸收掉,畢竟都會傳過去,也沒什麼壁壘,半年後Skill也不用寫,大模型都知道了
我們現在做Agent,其實是在基於大模型重新發明自己業務的"操作系統"。一聽是做操作系統,好像每一層都有很多事情可以做——上下文管理、各種MCP、Skill編排——幹勁十足。
但冷靜想想:模型卷完、Harness基建卷完、MCP與Skill也被吞進LLM,AI行業接下來我們到底還能卷什麼?
也許答案在這幾個方向:
•垂直行業深度場景——通用Harness解決不了的行業Know-How
感覺通用慢慢也在吸收垂直數據,只要你用,就會被吸收。
•高壁壘私有數據——模型再強也沒有你的數據
越來越薄。
•企業私有化部署——安全合規是剛需
存在,苦力活。
•落地定製交付服務——最後一公里永遠需要人
真正值得反思的是:當每一層基礎設施都在被巨頭吞噬的時候,也許我們不該再想"卷哪一層",而該想"我能創造什麼獨一無二的體驗"。技術棧會被抹平,但審美、判斷力、對特定人羣的深度理解——這些是大模型學不走的。
一句話:發動機標配後,但當車也變成標配的時候,真正的競爭力是——自動駕駛?還是什麼。
#AI編程#ClaudeCode#Agent#大模型#Harness#編碼Agent#ManagedAgents