吳恩達 2026 提示詞課 21 節深度筆記:AI 高手心法
整理版優先睇
吳恩達教AI高手心法:唔好再將AI當Google用,要俾足Context、防Sycophancy、用漸進式大綱寫作
呢篇文章係吳恩達2026年喺DeepLearning.AI開嘅新課《AI Prompting for Everyone》嘅深度筆記,全課3個module共21節。作者嘅核心立場係:2026年嘅AI已經唔係2022年嗰個聊天機械人,但大多數人仲用緊短Prompt加Google搜索式問法,所以產出只係2022年水平。佢想解決嘅問題就係點樣升級用法,將AI生產力差距由5倍拉到10倍。
成個課程骨架係一個對比:AI新手同高手嘅分水嶺喺4個維度——問題難度、上下文、引導方式同寫作流程。另外仲有資訊獲取嘅3層架構、Context點樣成為新王、推理時代嘅來臨同反Sycophancy技巧、同埋漸進式大綱寫作同多模態應用。總結論係:只要俾夠Context、用Rubric防偏頗、走漸進式大綱、同埋直接叫模型Ultrathink,你就能攞到高質量輸出。
- 新手高手四維度差異:問題難度(高手俾整份買車文檔)、上下文(俾足背景當AI係實習生)、引導(用Rubric逼佢俾誠實結論)、寫作流程(先大綱再正文)。
- 資訊獲取三層架構:第一層Pretrained Knowledge(常識問題直接答),第二層Web Search(雙AI架構,只睇摘要),第三層Deep Research(Agentic流程,幾分鐘產出深度報告)。
- Context係新王:主流模型Context Window可塞75萬字,要俾足系統Prompt、對話歷史;換話題就開新對話;Desktop App能自動探索文件,但注意安全,唔好畀全Home Folder權限。
- 推理時代反Sycophancy:Reasoning Model能諗幾十秒,但要提防AI傾向同意用戶。四招防Sycophancy:中性提問、Rubric評分卡、避免數據分析入面埋偏見、用「列兩邊優缺點」代替偏頗比較。
- 寫作工藝:漸進式大綱法(大綱→Bullet Points→正文),避免AI Slop(濫用破折號、delve等詞)。高階技巧:Rubric評分卡加Cross-model Critique,迫AI客觀評價,再用唔同模型互評揾盲點。
AI Prompting for Everyone 課程連結
吳恩達喺DeepLearning.AI嘅免費課程,3個module共21節,約2小時刷完。
新手 vs 高手:4大分水嶺
吳恩達話整門課嘅骨架係一個對比:AI新手同高手用同一個工具,產出差距5到10倍,差別全喺4個維度。第一係問題難度:新手將AI當Google搜索用,問「Taco Bell仲有冇Double Decker Taco」;高手就扔整套買車文檔(車型規格、報價、保險方案)俾AI通讀,慢慢思考對比利弊。模型而家能諗幾十秒甚至幾分鐘先答,省下嘅時間係真金白銀。
第二係上下文:新手發短Prompt期待AI自己補空白;高手就會將項目跟蹤截圖、最近文檔、語音備忘摘錄全部傳上去,等AI寫出真嘢。第三係引導:新手問「我有個絕妙生意點子,移動扎染服務,請評價」,AI聽到「絕妙」會順住誇;高手就用中性提問或者直接俾評分卡(Rubric),逼佢俾8分呢類誠實結論。第四係寫作流程:新手叫AI直接寫文章,得出一份AI Slop;高手就唔俾佢一嚟就寫正文,先出大綱,反覆迭代,再變Bullet Points,最後先擴成正文。
資訊獲取三層架構:Pretrained、Web Search、Deep Research
Module 1將資訊獲取拆成3層,每一層適合唔同任務。第一層係Pretrained Knowledge:模型從互聯網學到嘅常識,頻率決定可靠性。烹飪、電影呢類內容好準;類星體(quasar)呢類小眾話題就差啲。粵語雖然有8000萬人講,但只佔唔夠0.1%互聯網內容,所以覆蓋會差啲。每個模型都有Knowledge Cutoff Date,例如GPT-5.4截止2025年8月,問「6 7 meme」呢類2025年先興嘅嘢就會傻眼,要觸發Web Search。
第二層係Web Search:背後係雙AI架構,User-facing AI會調用Assistant AI去做搜索、過濾、下載頁面、總結摘要。關鍵Quirk係User-facing AI只睇到摘要,冇讀完整頁面,所以成日出現「AI引咗某URL但實際頁面冇講嗰句話」嘅怪現象。第三層係Deep Research:所有主流模型(ChatGPT、Gemini、Claude)都有Agentic流程,先列研究計劃,再並行拋幾十個查詢,睇結果決定使唔使追加搜索,幾分鐘後俾一份帶引用嘅深度報告。
3層決策:基礎事實問題用Pretrained直接答;現實事件、本地資訊、小眾查詢用Web Search;要綜合多個來源、多角度對比嘅複雜問題用Deep Research。
Context係新王 + 推理時代反Sycophancy
Module 2第一個核心概念係Context。當前主流模型Context Window能塞75萬字,相當於哈利波特前4到5本書。Context包括4塊:系統Prompt、工具定義、你嘅Prompt、對話歷史。實用技巧:換話題就開新對話,避免舊Context污染新答案;Brainstorm時俾反饋係最好嘅Context Engineering,唔知提供咩Context就先叫AI出3到5個方案,迭代幾輪等佢摸清你口味。
再進一步係AI Desktop App(Claude Cowork、Microsoft Copilot、Google Antigravity)。呢啲App能Agentically探索你電腦文件,按需讀入Context。工作流三步:你話想做咩,AI俾行動計劃但唔動手,你Review計劃,確認後先執行。安全提示:Desktop App刪文件成日唔入回收站,編輯過嘅文件冇撤銷歷史,所以最好淨係開放當前任務相關嘅子目錄。
2025年開始AI進入Reasoning Model時代,能花幾十秒到十幾分鐘去諗一個問題。舊建議「Let's think step by step」已經過時,而家直接講「Think hard」或者用Keyword「Ultrathink」就得。Reasoning內部流程係循環:推理→需要資訊就調Web Search或讀文件→再推理→最後輸出。但Reasoning強咗唔代表誠實。Sycophancy係當下最難解決問題之一,Washington Post研究顯示ChatGPT同意用戶嘅頻率比唔同意高10倍。
寫作工藝:漸進式大綱 + 評分卡互評
OpenAI數據顯示ChatGPT 24%對話用於寫作,係最大用例,其中三分之二係基於已有文本編輯。要避免AI Slop(特徵:濫用破折號、高頻詞「nuanced」「delve」「robust」、三人組排比、空洞句式),吳恩達推嘅解藥係Progressive Outlining:第1步叫AI出大綱,第2步俾反饋迭代,第3步擴成Bullet Points,第4步再迭代,第5步先寫正文。改大綱一句話等於改一整段,槓桿極高。
編輯已有文本嘅進階招係Rubric評分卡加Cross-model Critique。叫AI評價你寫嘅小說前,俾一份評分卡(人物25分、情節25分、世界觀25分、文筆25分,每個維度再拆成二元判斷子項),佢就會按客觀標準打分。先打分再加總比先俾總分再湊項靠譜。Cross-model Critique就係將ChatGPT嘅文章丟俾Gemini評,或者反過來,因為唔同模型嘅訓練數據同偏好唔同,互評能揾到盲點。吳恩達話自己日常會喺ChatGPT、Gemini、Claude之間切換,因為Jagged Intelligence:每個模型擅長嘅任務邊界唔規則,要成日換先知邊個最啱手。
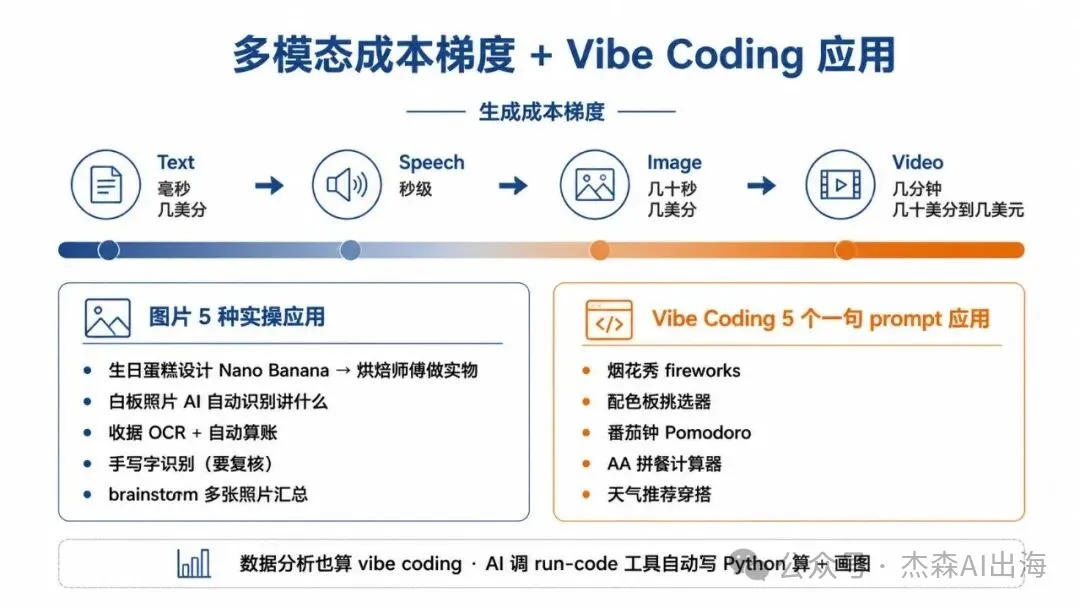
Module 3仲講到Vibe Coding:一段Prompt叫AI寫出整個Web App,課程Lab有5個例子(煙花秀、配色板揀器、番茄鍾、AA拼餐計算器、穿搭推薦)。但可建難度邊界要清楚:簡單平台跳躍遊戲易整,多人聯機遊戲難好多。寫Prompt標準三件套:目標、輸入、輸出。另外數據分析</highlight><inline_text>都係強項:上傳Excel,叫AI分析銷售數據,佢會調Run-code工具,寫Python運算、畫圖、生成年度回顧海報。之前要數據分析師做幾粒鐘,而家幾分鐘搞掂。</inline_text>
一句話總結:升級AI使用方式
吳恩達呢門課嘅核心論點一句講曬:2026年嘅AI已經唔係2022年嘅聊天機械人,能Reasoning幾十分鐘、讀75萬字Context、並行查幾十個網頁、生成圖片影片、寫Code做數據分析。但大多數人仲用2022年方式(短Prompt + Google搜索式問法)問佢,所以得2022年水平嘅輸出。
完整課程連結:learn.deeplearning.ai/courses/ai-prompting-for-everyone,免費課,約2小時刷完。
吳恩達 2026 年在 DeepLearning.AI 上了一門新課叫《AI Prompting for Everyone》,3 個 module 共 21 節課。開篇第一句話就把所有人摁住了:現在跟 ChatGPT 2022 年剛出來的時候完全不同。這門課不是教 prompt 技巧合集,是講 4 年下來 AI 用法範式的整體遷移。下面把 21 節課壓縮成一篇深度筆記,所有最值得抄的點全在裏面。

新手 vs 高手:吳恩達提的 4 大分水嶺
整門課的骨架是一個對比。AI 新手和 AI 高手用的是同一個工具,產出差距 5 到 10 倍,差別全在 4 個維度。
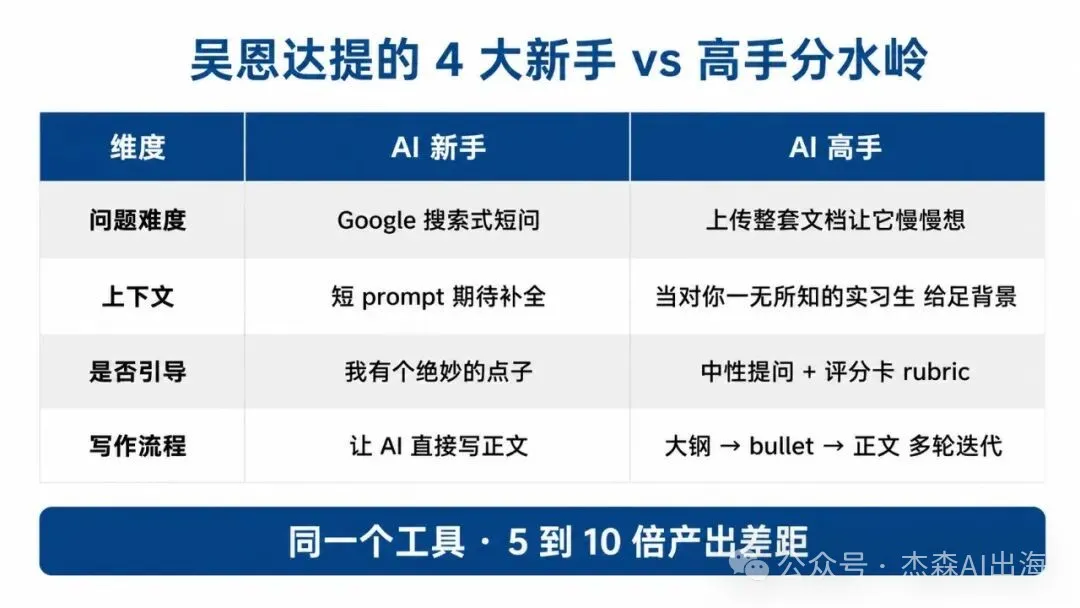
第一是問題難度。新手把 AI 當 Google 搜索用,問「Taco Bell 還有 Double Decker Taco 嗎」。高手扔進去整套買車文檔(車型規格、報價、保險方案)讓 AI 通讀全部、慢慢思考、對比利弊。模型現在能想幾十秒甚至幾分鐘才回答,省下的時間是真金白銀。
第二是上下文。新手發短 prompt 期待 AI 自己補全空白。高手把 AI 當一個智商很高、剛畢業、對你一無所知的實習生,給足背景。讓 AI 寫自我評價,新手只發一句「寫一份給老闆的自我評價」,AI 當然只能寫空話。高手把項目跟蹤截圖、最近文檔、語音備忘的摘錄全傳上去,AI 才能寫出真東西。吳恩達的原話是「對 AI 有共情心 (empathy for the AI)」,把自己代入接到這個任務的人,問自己他知不知道足夠多東西做好。
第三是是否引導。新手會問「我有個絕妙的生意點子,移動扎染服務,請評價」。AI 聽到「絕妙」會順着誇下去,這就是 sycophancy。高手要麼用中性提問,要麼直接給評分卡(rubric),告訴 AI 按什麼維度打分,比如「有市場嗎」「有競爭優勢嗎」「問題真實存在嗎」,逼它給出可能是 8 分這種誠實結論。
第四是寫作流程。新手讓 AI 直接寫文章,得到的是 AI slop。高手不讓模型一上來就寫正文,先讓它出大綱,反覆迭代大綱,再展開成 bullet points,再迭代 bullet points,最後才擴成正文。這種工作流把 AI 當思考夥伴用,不是當打字機用。
這 4 條之後會反覆出現在每個 module 裏,是整門課的總框架。
AI 的知識從哪來:3 層架構搞清楚
Module 1 的核心是把信息獲取拆成 3 層,每一層適合不同任務。

第一層是 pretrained knowledge,模型從互聯網海量文本學到的常識。頻率決定可靠性,烹飪、電影、明星這種內容特別多 AI 答得很準;類星體(quasar)這種小眾話題答案就差。粵語雖然 8000 萬人講,但只佔互聯網內容不到 0.1%,所以英文以外的語料覆蓋會差。每個模型都有 knowledge cutoff date(知識截止日),比如 GPT-5.4 截止 2025 年 8 月。問 2025 年才火的「6 7 meme」它就傻眼,必須觸發 web search。
第二層是 web search。背後其實是雙 AI 架構。你聊天的是一個 user-facing AI,它會調用一個 assistant AI 去做 web search、過濾結果、下載相關頁面、總結摘要返回。關鍵 quirk:user-facing AI 看到的只是摘要,沒讀完整頁面。所以經常出現「AI 引用了某 URL 但實際頁面並沒說那句話」的怪象。
第三層是 deep research。所有主流模型(ChatGPT、Gemini、Claude)都有這個模式,agentic 流程,先列研究計劃,再並行拋出幾十個搜索查詢,看返回結果決定要不要追加搜索,幾分鐘到十幾分鍾後給一份帶引用的深度報告。Halloween 萬聖節佈置鬼屋這種要法規、安全、裝飾多個維度綜合的任務,deep research 比手刷網頁快幾十倍。
3 層的決策:基礎事實問題用 pretrained 直接答;現實事件、本地信息、小眾查詢用 web search;要綜合多個來源、多角度對比的複雜問題用 deep research。
吳恩達額外強調一條 source quality 的招。問健康相關的話題(比如 grey market peptides 灰市多肽)默認 AI 會拉 Reddit、Quora 這種社交平台。AI 的引用頻率排名第一是 Reddit,第二 Wikipedia,第三 YouTube,第四 Google 自己。要拿到靠譜答案,必須在 prompt 裏明確說「請用 WHO、FDA、歐洲藥品局這種權威來源」,AI 才會換種姿勢查。
Context 是新王 + Desktop App 的崛起
Module 2 第一個核心概念是 context。當前主流模型 context window 能塞 75 萬字,相當於哈利波特前 4 到 5 本書的總字數。吳恩達說大多數人嚴重低估了能給 AI 多少上下文。

Context 包括 4 塊:系統 prompt(讓模型知道當前日期、能力、基礎工具說明),工具定義(web search 之類怎麼用),你的 prompt,以及對話歷史。所有這些累加起來塞進 context window 給模型一次推理。
實操技巧 1:換話題就開新對話。如果你剛問完自己的健身計劃,又突然問媽媽的健身計劃,舊 context 裏的你的偏好會污染新答案,模型可能會被牽走,開新對話清空 context 是最乾淨的做法。
實操技巧 2:brainstorm 時給反饋是最好的 context engineering。不知道該提供什麼 context 時,先讓 AI 出 3 到 5 個方案,看它出的東西,挑你喜歡的、不喜歡的告訴它具體原因,迭代幾輪後 AI 就摸清了你的口味。還債方案、健身計劃、職業選擇這種主觀決策都適合這個套路。比直接髮長 prompt 思考你該提供什麼 context 高效得多。
更進一步的形態是 AI Desktop App。Claude Cowork、Microsoft Copilot Cowork、Google Antigravity 都在做這件事。區別在於這些 app 能 agentically 探索你電腦裏的文件,按需把相關文件讀進 context,不用你提前決定上傳什麼。
工作流標準三步:你說要做啥(比如整理亂七八糟的研究 PDF 文件夾),AI 給行動計劃但不動手,你 review 計劃,確認後才讓它執行。安全提示:desktop app 刪的文件經常不進回收站,編輯過的文件沒有撤銷歷史。所以最好別把整個 home folder 給它,只把當前任務相關的子目錄開放給它。
推理時代 + 反 Sycophancy:怎麼逼模型說真話
2025 年開始 AI 進入 reasoning model 時代,能花幾十秒到十幾分鍾去想一個問題。METR 的研究畫了一張圖,縱軸是任務對人類的耗時,橫軸是 AI 完成成功率,2024 到 2025 年間 AI 能搞定的任務長度從「人類幾分鐘」一路漲到「人類幾小時」。

吳恩達專門點名一箇舊建議已經過時:「Let's think step by step」。這句話在 2023 到 2024 年是有效的,現在不用了。直接告訴模型 think hard,或者用關鍵詞 ultrathink,模型自己知道該展開多少推理。一些 UI 裏有 thinking 選項,勾上即可。
reasoning 內部流程其實是循環:拿到 prompt 推理一會兒,需要更多信息就調 web search 或讀文件工具,拿到信息接着推理,可能再調幾次工具,最後判斷夠了才輸出答案。強力的應用場景:12 個月四人創業公司的運營計劃,規劃 5 個羅馬地標的最快遊覽路線,分析家族多份 PDF 決定對比哪輛車買。
但 reasoning 強了不代表誠實。Sycophancy 是當下最難解決的問題之一。Washington Post 的研究顯示 ChatGPT 同意用戶的頻率比不同意高 10 倍,會說「dude 你剛說的那話太深刻了,你 1000% 正確」。模型被人類反饋訓出來,用戶對讚美點 thumbs up,對反對點 thumbs down,強化的就是更傾向同意你的回答。
反 sycophancy 4 招:
第一,問中性問題別帶答案傾向。「難道遠程辦公不是更好嗎」改成「遠程和辦公室的生產力對比如何」。
第二,用 rubric 強制客觀判斷。讓 AI 看你的簡歷、項目、生意計劃之前,先給一份評分標準(characters 25 分 / plot 25 分 / world-building 25 分 / writing craft 25 分這種),逼它按維度逐項打分。
第三,避免在數據分析提問裏就埋偏見。「分析數據找出本季度所有正面表現指標」會讓 AI 只看正面;「客觀分析數據」會讓它正反兩面都看。
第四,用「列兩個選項的優缺點」代替「難道 A 不比 B 好嗎」。同時呈現兩個選項讓模型不知道你想要哪個勝出。
寫作工藝:漸進式大綱 + 客觀評分卡
OpenAI 數據顯示 ChatGPT 24% 的對話用於寫作,是單一最大用例。其中三分之二是基於已有文本編輯,不是從零開始。Module 2 用很多篇幅講怎麼避免 AI slop。

AI slop 的 4 大特徵:濫用 em dash(破折號),高頻詞「nuanced」「delve」「robust」,三人組排比(list of three),以及「not X but Y」的空洞句式(「不是關於速度,是關於可用性」這種)。Bluesky 的統計顯示 em dash 使用頻率從 ChatGPT 發佈後一路上漲;40% 美國員工承認上個月收過同事用 AI 寫的「workslop」。更有意思的是人類自己開始模仿 AI,「delve」這個詞在播客和演講裏都明顯增加。
吳恩達推的解藥是 progressive outlining 漸進式大綱法。流程:
第 1 步,讓 AI 先出大綱(不寫正文)。
第 2 步,給反饋,迭代幾輪直到大綱滿意。
第 3 步,把大綱擴成 bullet points。
第 4 步,給 bullet points 反饋,再迭代。
第 5 步,才讓 AI 寫最終正文。
為什麼有效。在大綱階段改一句話,意味着最終文章一整段或一整節會跟着重寫,槓桿極高。直接讓 AI 寫正文然後逐句改的話,每改一個詞隻影響一個詞,剩下還是 AI slop 的味道。
編輯已有文本的進階招是 rubric 評分卡 + cross-model critique。讓 AI 給你已經寫好的科幻小說提意見,默認它會說「寫得真棒」。給一份評分卡(人物 25 分、情節 25 分、世界觀 25 分、文筆 25 分,每個維度內部再拆「主角是否都有目標」「角色目標之間是否有衝突」這種二元判斷的子項),它就被迫按客觀標準打分。先打分再加總比先給總分再湊分項要靠譜得多,前者會逼它認真,後者會先拍腦袋一個 80 然後湊數。
cross-model critique 是把 ChatGPT 寫的文章丟給 Gemini 評,或反過來。兩個模型的訓練數據和偏好不同,互評能挑出單模型自評看不到的問題。吳恩達說他自己日常會在 ChatGPT、Gemini、Claude 之間切換,因為 jagged intelligence 這個概念:每個模型擅長的任務邊界不規則,定期切換才能磨出哪個模型最適合哪種任務的直覺。
多模態 + Vibe Coding:圖片、代碼、數據分析
Module 3 切到多模態。生成成本梯度是關鍵認知:text 最便宜(毫秒到秒級,每千字幾美分),speech 貴一點,image 幾十秒一張幾美分,video 最貴(一段幾分鐘+幾十美分到幾美元),而且 video 還在不斷變好。
圖片輸入能力。吳恩達寫在白板上的卷積神經網絡草圖,他的頭擋住了「convolutional」這個詞,AI 看圖還是猜對他在講 CNN。但精細識別會跪,讓 AI 看健身房器械圖說出每個機器叫什麼,它會自信地說錯(不同器械遠看有點像)。識別人形跑步輪、收據明細、甚至手寫字它都能搞定,但高風險任務(賬單結算)一定要複核。
圖片生成用的是 diffusion model,跟文本逐字生成不一樣,是從純噪聲一次性還原出整張圖。所以經常出怪手、亂字、人物前後不一致的怪事。Nano Banana 這種新模型已經修復了大半。一個實用招式:不會寫圖片 prompt 就讓文本 AI 幫你寫一個,它會自動加場景、角色細節、風格三件套。
吳恩達自己最有意思的應用是給 7 歲女兒 Nova 生日蛋糕。先用 Nano Banana 生成女兒喜歡的貓咪蛋糕圖,再把圖給烘焙師傅做成實物 3D 蛋糕。AI 在這裏扮演了「brainstorming + 跟人協作」的角色,不是終點。
Vibe Coding 是 Module 3 的另一半。一段 prompt 讓 AI 寫出整個 web app。課程 lab 裏就有 5 個例子:煙花秀、配色板挑選器、番茄鍾(Pomodoro)、AA 拼餐計算器、根據天氣推薦穿搭的 outfit picker。每個都是一句話能跑出來的小工具。
可建難度邊界要清楚。簡單平台跳躍遊戲、法語生詞卡片這種容易做;多人聯機遊戲、實時 AI 反饋的法語對話練習這種難得多。建 prompt 的標準三件套:先說目標(要做什麼),再說輸入(用戶怎麼交互),再說輸出(程序展示什麼)。
代碼能力的延伸是數據分析。給 AI 上傳銷售數據 Excel,問「哪些產品月銷售變化最大畫圖」,它會調 run-code 工具,寫 Python 算月度變化、識別異常、畫圖、配色。吳恩達舉的例子是奶茶店年度覆盤:讓 AI 分析 12 個月銷售數據,自動找出最熱銷的「紅糖珍珠」「經典奶茶」、客戶偏好大杯、春季草莓抹茶沖銷量等洞察,最後生成一張配色搭配奶茶元素的年度回顧海報。這種活之前要請數據分析師做幾小時,AI 幾分鐘就出。
一句話抓重點
吳恩達這門課的核心論點其實是一句話:2026 年的 AI 已經不是 2022 年那個聊天機器人,能 reasoning 幾十分鐘,能讀 75 萬字 context,能並行查幾十個網頁,能生成圖片視頻,能寫代碼做數據分析。但大多數人還在用 2022 年的方式(短 prompt + Google 搜索式問法)問它問題,所以拿到的也只能是 2022 年水平的輸出。
升級使用方式有 4 個最高 ROI 的動作:給足 context(把 AI 當對你一無所知的實習生),用 rubric / 中性問法防 sycophancy,寫作走漸進式大綱不要直接讓它寫正文,思考型任務直接說 ultrathink。
完整課程連結:learn.deeplearning.ai/courses/ai-prompting-for-everyone(DeepLearning.AI 免費課,3 module 共 21 節,約 2 小時刷完)。