回敬 Codex,Claude Code 推出 /goal 功能,不幹完不睡覺
整理版優先睇
Claude Code 推出 /goal 功能,設定目標後唔完成唔停手
呢篇文章講述 Claude Code 喺 2.1.139 版本推出嘅 /goal 命令。作者先交代功能靈感來自 Ralph Loop 模式,一個俾 Agent 設定目標、失敗就重來直到完成嘅循環。新功能讓 Claude 跨多個回合持續工作,每輪結束由獨立模型評估係咪達成,未達成就繼續。作者特別強調 Claude Code 同 Codex 嘅關鍵差異在於「裁判分離」——用輕量模型 Haiku 做評估,避免工作模型自我判斷嘅偏誤。
文章仲提出目標條件嘅三要素:可衡量終態、驗證方式、約束條件,並指出 /goal 同 auto mode 配合可以實現完全自動化。最後作者將 /goal 提升到「編程即訓練」嘅層次,認為呢個功能自動化咗訓練循環,令開發者嘅重心由寫代碼轉為定義優化目標同驗證標準。整體結論係:/goal 唔單止係一個實用工具,仲改變咗我哋同代碼嘅關係。另外文章仲介紹咗一啲同版本功能,例如 Agent View 同系統提示詞壓縮改為靜默執行,同埋修復多個 bug。
- /goal 命令讓 Claude 跨多輪自動工作直到目標達成,適合自動化重複性任務。
- 設定條件要用可衡量終態(如測試通過)、驗證方式(如退出碼)同約束(如唔改其他檔案)。
- Claude Code 用獨立小模型 Haiku 做評估,避免「既當運動員又當裁判」嘅偏誤,比 Codex 更穩陣。
- /goal 配合 auto mode 可以實現無人值守開發,開發者只需定義目標,其餘交俾 Agent 循環。
- 寫目標條件要具體可驗證,例如「所有測試通過且 lint 無錯誤」,避免模糊陳述。
Claude Code /goal 文檔
/goal 命令的官方文檔
Claude Code Changelog 2.1.139
版本更新日誌
互相致敬:/goal 的由來
繼 Codex 推出 /goal 之後,Claude Code 喺 2.1.139 版本都上線咗同名功能。呢個功能嘅靈感來自社區入面嘅 Ralph Loop,一種俾 Agent 設定目標、失敗就重來、唔達成唔停嘅循環模式。
Ralph Loop 個名來自《辛普森一家》嘅 Ralph Wiggum,一個「無知、執着、樂觀」嘅角色。
開發者 Geoffrey Huntley 用呢個名命名咗 Agent 循環模式:俾 Agent 設定一個目標,讓佢自己不斷迭代,失敗咗就重來,直到目標達成。
定好目標就開跑
喺 Claude Code 輸入 /goal test/auth 下所有測試通過,lint 乾淨,回車後 Claude 就開始幹活。每完成一輪,系統自動判斷目標是否達成,未達成繼續,達成自動停止。
運行時界面會顯示一個 ◎ /goal active 狀態面板,實時展示已運行時間、輪次數同 token 消耗。
- /goal:唔加參數,查看當前目標狀態、輪次、token 消耗同最新評估理由
- /goal clear:清除目標(stop、off、reset、cancel 都得)
- 目標可以跨會話保持,用 --resume 或 --continue 重新打開上次會話會自動恢復
仲有一個好用嘅姿勢:喺非交互模式下直接跑 claude-p "/goal CHANGELOG.md 裏有本週每個合併 PR 嘅記錄",一條命令跑到完成,甚至可以直接接入 CI 管道用。
裁判分離:關鍵設計差異
呢度係 Claude Code 同 Codex 之間最關鍵嘅設計差異。Codex 讓工作模型自己做「完成審計」,每輪結束後注入指令要求模型拆目標成檢查清單,逐項驗證。即係做嘢嘅人同時係驗收嘅人。
點解要咁設計?因為一個模型自己判斷「我做完了沒」,好容易將「我產出了嘢」等同於「我達成咗目標」。測試通過就覺得功能完成,代碼寫完就覺得需求滿足。呢個係 Agent 循環中最隱蔽嘅失敗模式之一。
用獨立模型做評估,多咗一層制衡,而且 Haiku 係輕量模型,token 成本基本可以忽略。
呢個設計令 Claude Code 喺可靠性上比 Codex 更勝一籌。
目標條件三要素
官方文檔建議寫目標條件嗰陣,要包含三個要素。
- 1 一個可衡量嘅終態:測試結果、構建退出碼、文件數量、隊列清空等
- 2 一個驗證方式:點證明完成,例如 npm test 退出碼為 0 或 git status 乾淨
- 3 唔可以破壞嘅約束:過程中唔可以動啲乜,例如唔修改其他測試檔案
條件最長支援 4000 個字符。想限制運行時長可以直接寫入條件,例如「20 輪後如果未完成就停」。
評估模型只能睇 Claude 喺對話中展示嘅嘢,所以目標條件要寫成 Claude 自己輸出可以證明嘅形式。例如「所有測試通過」係好條件,但「代碼質量提升咗」太模糊。
目前 Claude Code 有三種持續工作方式:/goal(條件觸發)、/loop(定時觸發)、Stop hook(腳本或 prompt 決定)。
編程即訓練:深層影響
/goal 功能看起來簡潔,但佢改變咗一件根本性嘅事:你同代碼嘅關係。Keras 作者 François Chollet 話,足夠先進嘅 AI 編程本質上就係機器學習。
你寫需求文檔 = 定義 loss function;寫測試用例 = 準備驗證集;Agent 每輪迭代 = training step;最後產出嘅代碼庫 = 訓練好嘅模型權重。
一旦接受呢個等號,你花時間嘅地方就徹底變咗:唔再係寫代碼本身,而係「我嘅優化目標定對未?驗證標準夠唔夠嚴?約束條件會唔會令 Agent 揾捷徑?」。呢啲問題機器學習領域已經研究咗幾十年:過擬合、數據泄露、概念漂移……都係同樣嘅坑。
對開發者嚟講,真正要練嘅本事,已經唔係寫代碼,係諗清楚自己到底要乜,然後定義好驗收標準。
Codex 有 /goal,Claude Code 都有 /goal,兩家仲會繼續互相借鑑。而我哋要準備好迎接呢個新時代。
繼 Codex 之後,Claude Code 出咗 /goal 命令,設定完成條件,唔達目的就唔停。

五一假期嘅第一日,Codex 發佈咗同名嘅 /goal,而十日後,Claude Code 嘅版本都出咗。
呢個功能跟 2.1.139 版本發佈。畀 Claude 設一個目標條件,佢就會跨多個回合持續做嘢,每輪結束自動判斷係咪達成,未搞掂就繼續,直至完成咗先至停。
01互相致敬
Codex 嘅 /goal 上線嗰陣,靈感嚟自社區入面嘅 Ralph Loop,一種令 Agent 設定目標、失敗就重新嚟過、唔達成就唔停嘅循環模式。
呢度都再講下 Ralph Loop。
呢個名嚟自《阿森一族》入面嘅 Ralph Wiggum,嗰個「無知、執着、樂觀」嘅細路仔。開發者 Geoffrey Huntley 用佢個名命名咗一種 Agent 循環模式:畀 Agent 設定一個目標,等佢自己不斷迭代,失敗咗就重新嚟過,直到目標達成。
VentureBeat 甚至寫咗篇文章叫《Ralph Wiggum 點樣從阿森一族變成 AI 界最hit嘅名》。
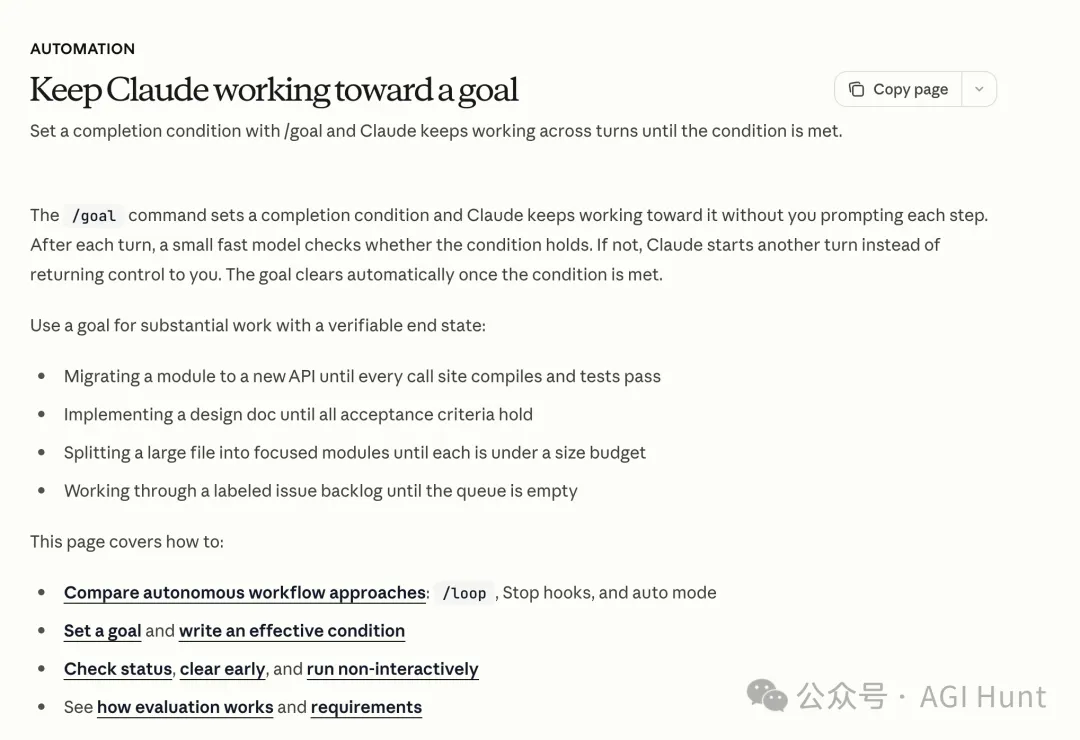
喺社區嘅原始實現入面,Ralph Loop 嘅做法比較「暴力」:每一輪結束之後,Agent 由頭開始一個新嘅上下文窗口,靠 git 記錄同進度檔案嚟保持記憶。
而 Ralph Loop 嘅最早實踐者,正正就係 Claude Code 嘅用戶們。
呢度有啲得意嘅係,OpenAI 嘅 Codex 發佈 /goal 嘅時候,明確話靈感嚟自 Claude 生態嘅 Ralph 腳本。咁 Claude Code 而家出 /goal,點解唔話自己都係學緊 Codex 呢……?
而就在 Codex 推出 /goal 之後冇幾耐,OpenAI 又畀 Codex 加咗寵物功能,一個懸浮喺桌面上面嘅狀態小組件,顯示任務進度,可以互動,可以點擊跳返主界面。呢個功能……都係受 Claude Code 嘅寵物功能啟發嘅。
噉樣嘅互相「借鑑」,對我哋嚟講,都唔係一件壞事。
02set好目標就開跑
喺 Claude Code 入面輸入:
●●●
/goal test/auth 下所有測試通過,lint 乾淨└
一個回車之後,Claude 就開始做嘢喇。
每完成一輪,系統自動判斷目標係咪達成。未達成,繼續下一輪;達成咗,自動停止。
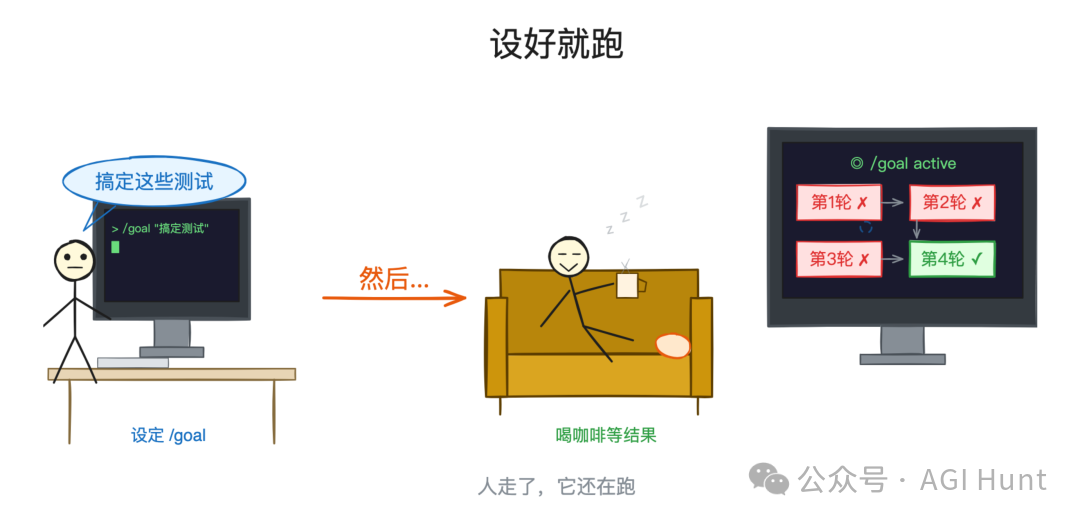
運行期間,界面上會顯示一個 ◎ /goal active 嘅狀態面板,實時展示已運行時間、輪次數同 token 消耗。
幾個輔助命令:
• /goal:唔加參數,睇當前目標嘅狀態、輪次、token 消耗同最新嘅評估理由
• /goal clear:清除目標(stop、off、reset、cancel 都得)
目標仲可以跨會話保持。用 --resume 或 --continue 重新打開上次嘅會話,目標會自動恢復,輪次同 token 計數就會重新開始。
此外仲有個好用嘅方法係,喺非互動模式下直接跑:
●●●
claude-p "/goal CHANGELOG.md 裏有本週每個合併 PR 的記錄"└
一條命令,跑到完成為止。甚至仲可以直接接入 CI 管道入面用,都完全冇問題。
03裁判分離
呢個係 Claude Code 同 Codex 之間最關鍵嘅設計差異。
Codex 嘅做法係叫工作模型自己做「完成審計」:每輪結束之後,系統注入一條指令,要求模型將目標拆解成檢查清單,逐項驗證。
做嘢嘅人,同時都係驗收嘅人。
而 Claude Code 換咗個思路。
做嘢嘅歸做嘢,驗收嘅歸驗收。
每輪結束之後,系統將目標條件同對話記錄發畀一個獨立嘅細模型(預設係 Haiku),由佢嚟判斷條件係咪滿足。如果未滿足,佢仲會返一段理由,話畀主模型知邊度仲差,作為下一輪嘅方向指引。
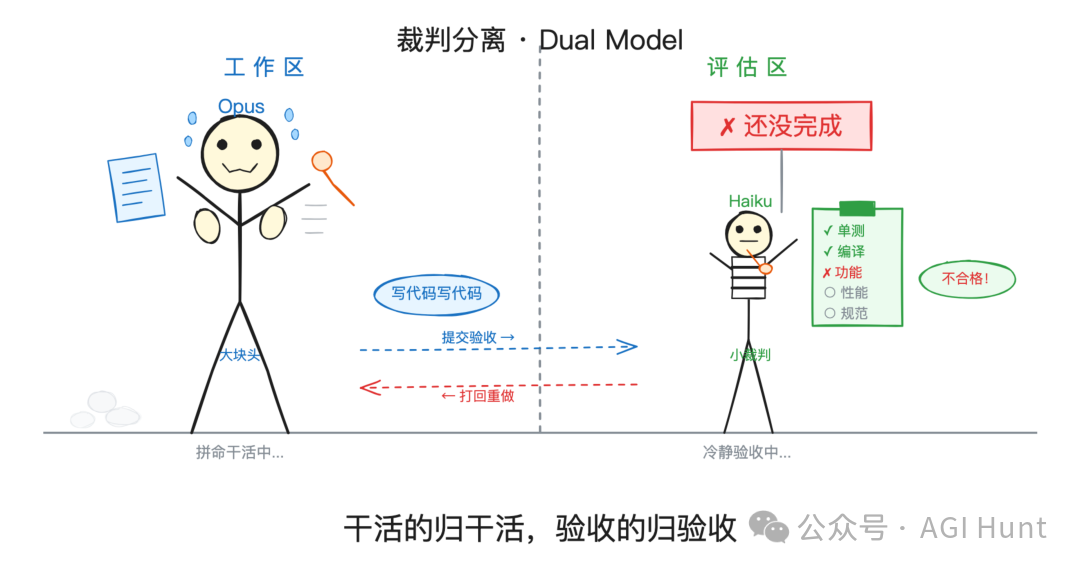
點解要咁樣設計呢?
叫一個模型自己判斷「我做完成未」,佢好容易將「我產出咗嘢」等同於「我達成咗目標」。
測試通過咗就覺得功能完成咗,代碼寫完咗就覺得需求滿足曬。其實呢個係 Agent 循環中最隱蔽嘅失敗模式之一。
用一個獨立嘅模型嚟做評估,會多咗一層制衡。
當然唔可以畀模型又做運動員,又做裁判。
而且評估用嘅係 Haiku 嘅輕量模型,token 成本基本可以忽略。
04目標制定
官方文件畀咗啲寫目標條件嘅建議。
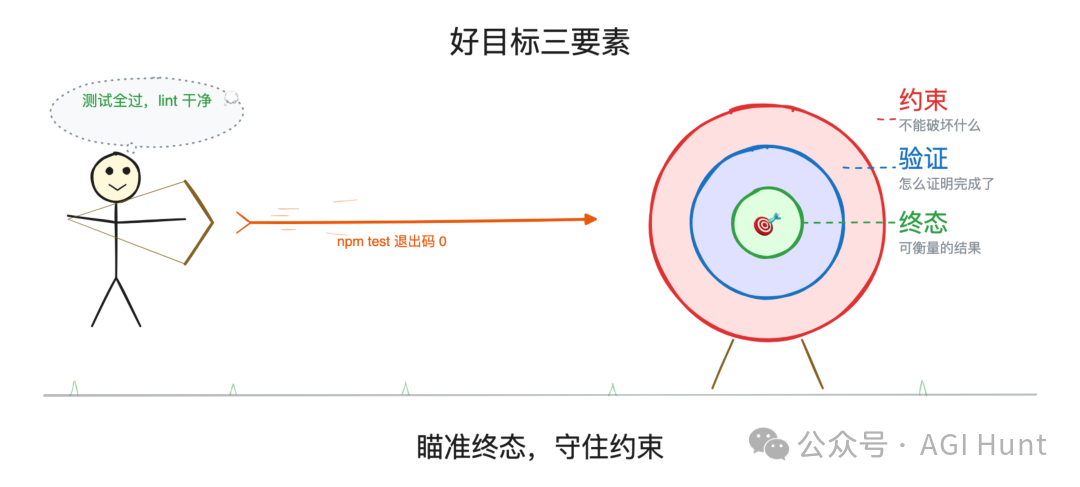
一個好嘅目標條件,通常有三個要素:
• 一個可衡量嘅終態:測試結果、構建退出碼、檔案數量、隊列清空
• 一個驗證方式:點證明完成咗,例如「npm test 退出碼為 0」或「git status 乾淨」
• 唔可以破壞嘅約束:過程入面唔可以鬱啲乜,例如「唔修改其他測試檔案」
條件最長支援 4000 個字符。
仲有個技巧,想限制運行時長嘅話,可以直接寫入條件入面,例如「20 輪後如果未完成就停低」。評估模型每輪都會根據對話內容嚟判斷呢個限制係咪觸發咗。
呢度有個限制係:評估模型唔可以獨立運行命令或讀檔案,佢只可以睇 Claude 喺對話中展示出嚟嘅嘢。所以目標條件要寫成 Claude 自己嘅輸出可以證明嘅形式。
例如「所有測試通過」就係個好條件,因為 Claude 會去行測試,結果自然會出現喺對話入面。但「代碼質量提升咗」就太模糊喇,評估模型冇辦法判斷。
05三條路
Claude Code 而家有三種令 Agent 持續做嘢嘅方式:
/goal | ||
/loop | ||
/goal 同 auto mode 配合起來,效果應該係最好嘅。
auto mode 解決「每次工具調用都要㩒確認」嘅問題,/goal 解決「每輪結束都要手動 send message」嘅問題。
兩個一齊開,你只需要定義目標,然後,可以去飲咖啡喇。
06同版本功能
2.1.139 仲帶咗唔少其他更新。
Agent View 出咗(研究預覽),輸入 claude agents 就可以睇到所有會話嘅列表,正在行嘅、等你回覆嘅、已經完成嘅,一屏睇曬。
系統提示詞嘅壓縮變成咗靜默執行。以前長對話觸發上下文壓縮嗰陣會有提醒,而家唔會喇。
呢個改動,仲喺社區引發咗一啲討論。有人擔心取消壓縮提醒之後,關鍵資訊被 cut 咗你都唔知,Agent 嘅行為可能莫名其妙咁漂移。亦有人指出,新版嘅壓縮提示詞會要求模型「保留敏感嘅用戶指令」,算係喺機制上做咗補償。
另外仲修咗 30 幾個 bug,包括憑證過期導致嘅死鎖、MCP 服務器記憶體洩漏(加咗 16MB 上限)、深色主題下連結顏色睇唔清等問題。
07寫程式即係訓練
回到 /goal 本身。
功能睇落好簡潔:設定目標,循環執行,條件滿足就停。
但如果我哋將視角拉遠一步,佢其實喺改變一件根本性嘅事情:你同代碼嘅關係。
Keras 嘅作者 François Chollet 最近寫咗一段話,大意係:足夠先進嘅 AI 寫程式,本質上就係機器學習。見我前文:AI 寫程式嘅本質,就係機器學習
仔細諗下,確實係咁。
你寫需求文件,相當於定義 loss function。你寫測試用例,相當於準備驗證集。Agent 每一輪迭代,就係一個 training step。最後產出嘅代碼庫,就係訓練好嘅模型權重。
你會部署佢,但未必會逐行去讀佢。
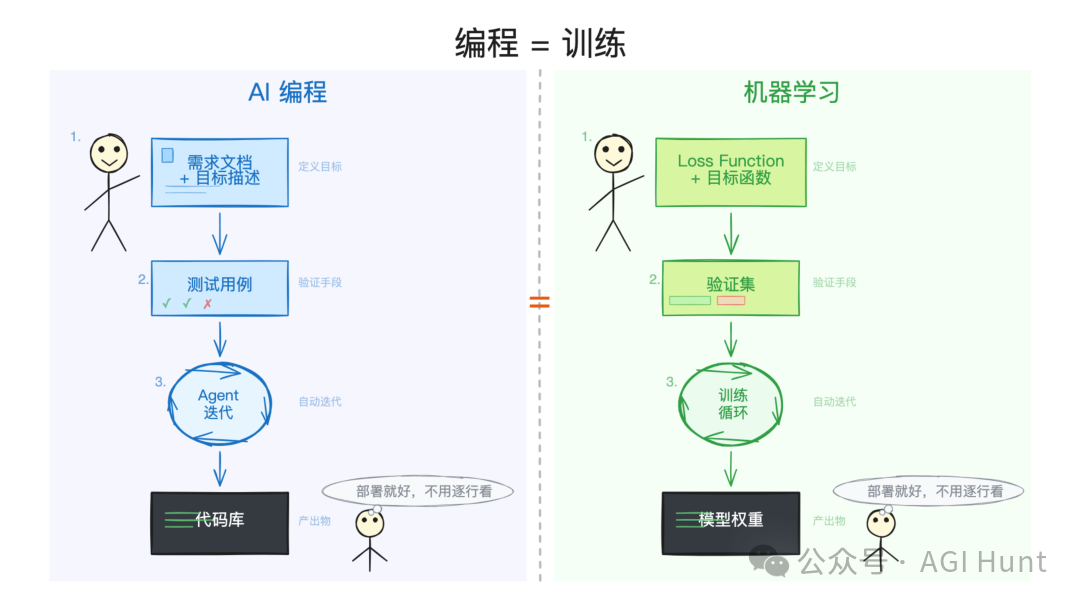
而 /goal 做嘅嘢,就係將呢個「訓練循環」正式自動化咗。你設定優化目標,劃定搜索空間嘅約束,然後令一個優化過程自動迭代,直到目標收斂。
我甚至覺得,可以直接寫低呢個公式:
●●●
model.fit() = /goal└
而一旦接受咗呢個等號,你花時間嘅地方就徹底變咗。
唔再係寫代碼本身。
而係:我嘅優化目標 set 啱咗未?我嘅驗證標準夠唔夠嚴?我嘅約束條件會唔會令 Agent 揾到某個投機取巧嘅捷徑,測試全部過但邏輯其實係歪嘅?
呢啲問題,機器學習領域已經研究咗幾十年喇。過擬合、數據洩漏、概念漂移……都係同樣嘅坑。
Codex 有 /goal,Claude Code 都有咗 /goal。兩家仲會繼續互相「借鑑」落去。
而對我哋嚟講,真正要練嘅本領,已經唔係寫代碼喇。
係諗清楚自己到底要啲乜,然後,定義好驗收標準。
剩下嘅,交畀訓練循環。
◇ ◆ ◇
相關連結:
https://code.claude.com/docs/en/goal
https://github.com/anthropics/claude-code/blob/main/CHANGELOG.md#21139
繼 Codex 之後,Claude Code 上線了 /goal 命令,設定完成條件,不達目的就不停。
五一假期的第一天,Codex 發佈了同名的 /goal,而十天後,Claude Code 的版本也來了。
這個功能隨 2.1.139 版本發佈。給 Claude 設一個目標條件,它就跨多個回合持續工作,每輪結束自動判斷是否達成,沒搞定就繼續,直至完成了才會停。
01互相致敬
Codex 的 /goal 上線時,靈感來自社區裏的 Ralph Loop,一種讓 Agent 設定目標、失敗就重來、不達成就不停的循環模式。
這裏也再聊一下 Ralph Loop。
這個名字來自《辛普森一家》裏的 Ralph Wiggum,那個「無知、執着、樂觀」的小男孩。開發者 Geoffrey Huntley 用他的名字命名了一種 Agent 循環模式:給 Agent 設定一個目標,讓它自己不斷迭代,失敗了就重來,直到目標達成。
VentureBeat 甚至寫了篇文章叫《Ralph Wiggum 如何從辛普森一家變成 AI 界最火的名字》。
在社區的原始實現裏,Ralph Loop 的做法比較「暴力」:每一輪結束後,Agent 從頭開始一個新的上下文窗口,靠 git 記錄和進度文件來保持記憶。
而 Ralph Loop 的最早實踐者,恰恰是 Claude Code 的用戶們。
這裏有點意思的是,OpenAI 的 Codex 發佈 /goal 的時候,明確說靈感來自 Claude 生態的 Ralph 腳本。那 Claude Code 現在出 /goal,為什麼不說自己也是在學 Codex 呢……?
而就在 Codex 推出 /goal 之後沒幾天,OpenAI 又給 Codex 加了寵物功能,一個懸浮在桌面上的狀態小組件,顯示任務進度,能互動,能點擊跳回主界面。這個功能……也是受 Claude Code 的寵物功能啓發的。
這樣的互相「借鑑」,對我們來說,倒也不是個壞事。
02定好目標就開跑
在 Claude Code 裏輸入:
●●●
/goal test/auth 下所有測試通過,lint 乾淨└
一個回車後,Claude 就開始幹活了。
每完成一輪,系統自動判斷目標是否達成。沒達成,繼續下一輪;達成了,自動停止。
運行過程中,界面上會顯示一個 ◎ /goal active 的狀態面板,實時展示已運行時間、輪次數和 token 消耗。
幾個輔助命令:
• /goal:不加參數,查看當前目標的狀態、輪次、token 消耗和最新的評估理由
• /goal clear:清除目標(stop、off、reset、cancel 也都行)
目標還能跨會話保持。用 --resume 或 --continue 重新打開上次的會話,目標會自動恢復,輪次和 token 計數則重新開始。
此外還有個好用的姿勢是,在非交互模式下直接跑:
●●●
claude-p "/goal CHANGELOG.md 裏有本週每個合併 PR 的記錄"└
一條命令,跑到完成為止。甚至還可以直接接進 CI 管道里用,也完全沒有問題。
03裁判分離
這是 Claude Code 和 Codex 之間最關鍵的設計差異。
Codex 的做法是讓工作模型自己做「完成審計」:每輪結束後,系統注入一條指令,要求模型把目標拆解成檢查清單,逐項驗證。
幹活的人,同時也是驗收的人。
而 Claude Code 換了個思路。
幹活的歸幹活,驗收的歸驗收。
每輪結束後,系統把目標條件和對話記錄發給一個獨立的小模型(默認是 Haiku),由它來判斷條件是否滿足。如果沒滿足,它還會返回一段理由,告訴主模型哪裏還差,作為下一輪的方向指引。
為什麼要這麼設計呢?
讓一個模型自己判斷「我做完了沒」,它很容易把「我產出了東西」等同於「我達成了目標」。
測試通過了就覺得功能完成了,代碼寫完了就覺得需求滿足了。這其實是 Agent 循環中最隱蔽的失敗模式之一。
用一個獨立的模型來做評估,會多了一層制衡。
當然不能讓模型既當運動員,又當裁判。
而且評估用的是 Haiku 的輕量模型,token 成本基本可以忽略。
04目標制定
官方文檔給了一些寫目標條件的建議。
一個好的目標條件,通常有三個要素:
• 一個可衡量的終態:測試結果、構建退出碼、文件數量、隊列清空
• 一個驗證方式:怎麼證明完成了,比如「npm test 退出碼為 0」或「git status 乾淨」
• 不能破壞的約束:過程中不能動什麼,比如「不修改其他測試文件」
條件最長支持 4000 個字符。
還有個技巧,想限制運行時長的話,可以直接寫進條件裏,比如「20 輪後如果沒完成就停下來」。評估模型每輪都會根據對話內容來判斷這個限制是否觸發了。
這裏有個限制是:評估模型不能獨立運行命令或讀文件,它只能看 Claude 在對話中展示出來的東西。所以目標條件得寫成 Claude 自己的輸出能證明的形式。
比如「所有測試通過」就是個好條件,因為 Claude 會去跑測試,結果自然會出現在對話裏。但「代碼質量提升了」就太模糊了,評估模型沒法判斷。
05三條路
Claude Code 現在有三種讓 Agent 持續工作的方式:
/goal | ||
/loop | ||
/goal 和 auto mode 配合起來,效果應該是最好的。
auto mode 解決「每次工具調用都要點確認」的問題,/goal 解決「每輪結束都要手動發消息」的問題。
兩個一起開,你只需要定義目標,然後,可以去喝咖啡了。
06同版本功能
2.1.139 還帶了不少其他更新。
Agent View 上線了(研究預覽),輸入 claude agents 就能看到所有會話的列表,正在跑的、等你回覆的、已經完成的,一屏瞭然。
系統提示詞的壓縮變成了靜默執行。以前長對話觸發上下文壓縮時會有提醒,現在不會了。
這個改動,還在社區引發了一些討論。有人擔心取消壓縮提醒之後,關鍵信息被裁掉了你都不知道,Agent 的行為可能莫名其妙地漂移。也有人指出,新版的壓縮提示詞會要求模型「保留敏感的用戶指令」,算是在機制上做了補償。
另外還修了 30 多個 bug,包括憑證過期導致的死鎖、MCP 服務器內存泄漏(加了 16MB 上限)、深色主題下連結顏色看不清等問題。
07編程即訓練
回到 /goal 本身。
功能看起來很簡潔:設定目標,循環執行,條件滿足就停。
但如果我們把視角拉遠一步,它其實在改變一件根本性的事情:你和代碼的關係。
Keras 的作者 François Chollet 最近寫了一段話,大意是:足夠先進的 AI 編程,本質上就是機器學習。見我前文:AI 編程的本質,就是機器學習
仔細想想,確實如此。
你寫需求文檔,相當於定義 loss function。你寫測試用例,相當於準備驗證集。Agent 每一輪迭代,就是一個 training step。最後產出的代碼庫,就是訓練好的模型權重。
你會部署它,但未必會逐行去讀它。
而 /goal 做的事情,就是把這個「訓練循環」正式自動化了。你設定優化目標,劃定搜索空間的約束,然後讓一個優化過程自動迭代,直到目標收斂。
我甚至覺得,可以直接寫下這個公式:
●●●
model.fit() = /goal└
而一旦接受了這個等號,你花時間的地方就徹底變了。
不再是寫代碼本身。
而是:我的優化目標定對了嗎?我的驗證標準夠不夠嚴?我的約束條件會不會讓 Agent 找到某個投機取巧的捷徑,測試全過但邏輯其實是歪的?
這些問題,機器學習領域已經研究了幾十年了。過擬合、數據泄露、概念漂移……都是同樣的坑。
Codex 有 /goal,Claude Code 也有了 /goal。兩家還會繼續互相「借鑑」下去。
而對我們來說,真正要練的本事,已經不是寫代碼了。
是想清楚自己到底要什麼,然後,定義好驗收標準。
剩下的,交給訓練循環。
◇ ◆ ◇
相關連結:
https://code.claude.com/docs/en/goal
https://github.com/anthropics/claude-code/blob/main/CHANGELOG.md#21139