在你看不見的地方,HeyGen 正在改寫 AI 視頻生成
整理版優先睇
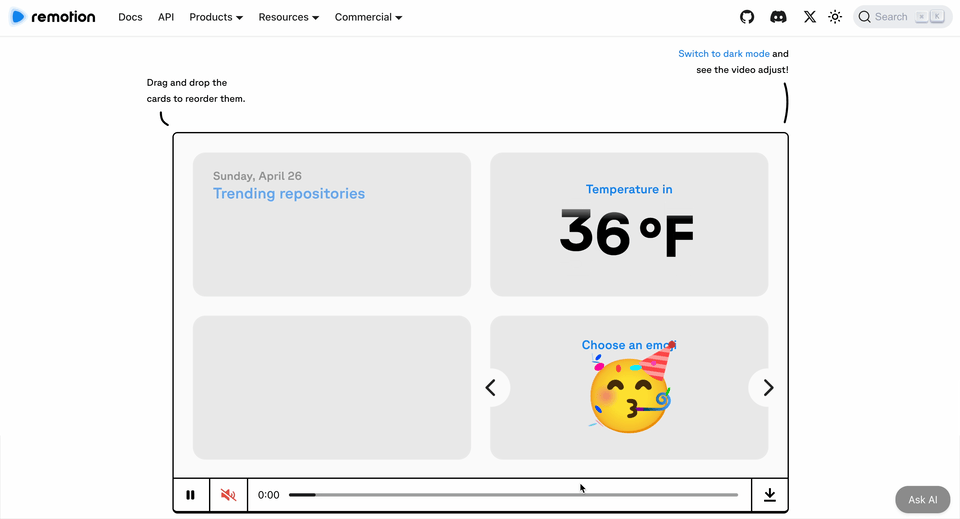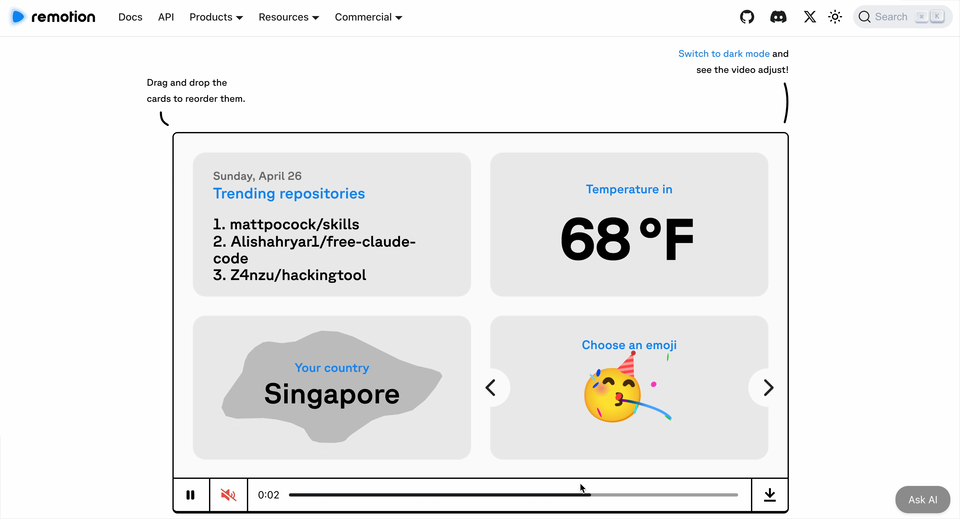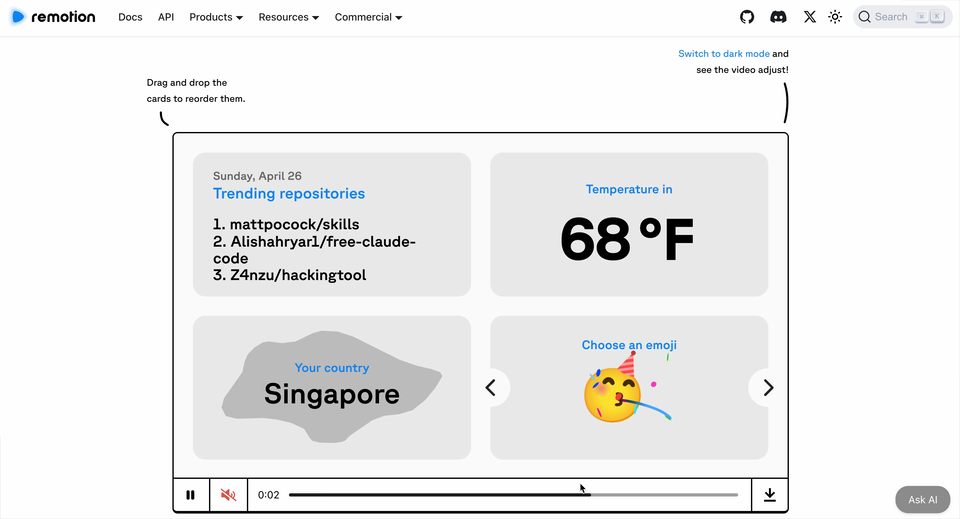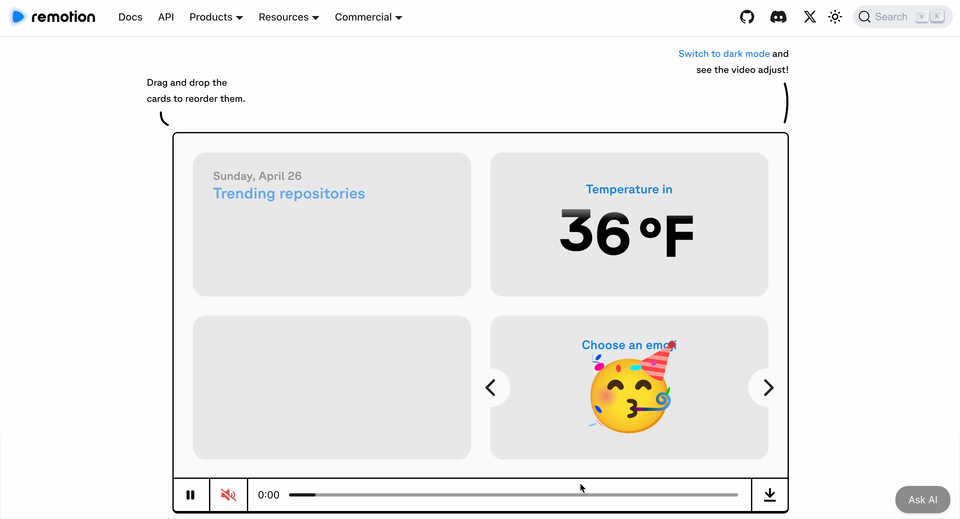
HeyGen 開源咗 Hyperframes,用代碼精確控制視頻,實現確定性、可控、批量生產。
呢篇文章出自 Daniel,佢係一位 AI 產品觀察者。文章嘅背景係 HeyGen 開源咗一個叫 Hyperframes 嘅視頻渲染框架,唔係靠生成式 AI 去畫面,而係用 HTML 代碼逐幀精確控制,目標係解決 AI 視頻生成入面常見嘅不可控、難批量嘅問題。作者親身試用 Hyperframes 配 Claude Code,示範由零開始做科普短片,同埋用同一模板批量生成多條角色介紹片,最後總結框架嘅優勢同限制。
作者指出,Hyperframes 嘅核心價值係確定性:改一處就係一處,唔會好似生成式工具咁次次都要重新賭博。純 HTML 底座對 AI 友好,成品率高,迭代快,特別適合需要同模板大量生產嘅場景。但係,自然語言描述精確空間關係帶寬唔夠,模型亦冇視覺反饋,所以最後 20% 嘅視覺微調仲係要靠人手,呢個係目前最大嘅瓶頸。
總括而言,Hyperframes 將視頻製作拉入咗 vibe coding 領域,令版本控制、批量生成、確定性復現變得可行。作者認為,代碼正成為 AI 理解同操控世界嘅通用語言,而下一個被 code 顛覆嘅創作媒介,可能就係視頻。
- Hyperframes 係用 HTML+CSS+JS 代碼精確控制每一幀嘅視頻生成框架,唔係靠 Diffusion 生成。
- 同純 prompt 生成嘅黑盒唔同,Hyperframes 提供確定性——改一處就一處,唔會隨機變動。
- 用 Claude Code 呢類 agent 搭配 Hyperframes,可以快速迭代,由粗糙到可用只需三四輪,約半個鐘。
- 適合批量生產:同一模板換素材,20分鐘生成4個風格統一嘅角色介紹視頻。
- 侷限:自然語言描述精確空間關係效率低,模型冇視覺反饋迴路傾向保守,最後20%視覺微調要靠人手做。
內容片段
使用Hyperframes做一個播客金句&開場的視頻,橫版16:9素材:(視頻地址及文字)佈局:類似聚光燈,深綠色背景上,一個圓形框住視頻裏的嘉賓,圓形下方是嘉賓的名字和title,旁邊用大字展示金句。三個素材的人像和文字位置要各不相同,以保證畫面的多樣性。動畫:圓和文字從側方偏移滑入,文字隨着視頻節奏逐句出現。轉場:clip 之間用簡潔的轉場。視頻生成嘅另一條路線
HeyGen 喺 4 月開源咗 Hyperframes,一個基於 HTML 嘅視頻渲染框架。佢唔係生成畫面,而係用代碼變成幀率穩定、動畫流暢嘅視頻文件。關鍵詞三個:確定、可控、批量生產。
呢條路線同 Seedance、可靈呢啲生成式工具好唔同。生成式係黑盒,每次輸出都係一次賭博;而 Hyperframes 係逐幀精確控制,改 CSS 就改顏色,改時間就改動畫,同一段碼每次渲染結果一模一樣。
低成本、可控性:由醜PPT到能發出去
作者用 Claude Code 配 Opus 4.6 做測試,第一條指令係做一個 9:16 TikTok 短片介紹 DeepSeek V4 同 V3 嘅分別。Claude Code 自己去搜資料、用 Kokoro 生成語音、設計視覺,輸出一個 HTML 文件。Hyperframes 內置 強制校驗機制,內容溢出、對比度唔夠呢啲問題會喺渲染前就被攔住。
初版效果簡單,似會動嘅 PPT,配色醜,默認英文。但只俾一句指令,呢個起點算合格。跟住作者開始調,改配色、換語言、修正事實錯誤,每輪微調約五分鐘。三四輪之後,效果已經由「醜 PPT」變成「能發出去」,累計半個鐘。呢個 迭代速度 已經比拖剪映快,而且完全冇軟件上手門檻。
批量生產與視覺微調嘅現實
作者再測試批量生產:用同一套模板,做 三麗鷗家族 四個角色嘅介紹片。每個角色有自己嘅配色同動態背景,共用模板結構。從準備素材到四條片出完,約20分鐘。呢種 同模板換內容</highlight> 嘅效率碾壓手工。
但落到實際生產,Hyperframes 仍然有侷限。第一,自然語言描述空間關係帶寬唔夠——例如播客金句片入面,想框住特定範圍嘅人像,用語言講「向左啲」「大啲」係無底洞,一定要手動改 HTML 數值。第二,模型冇視覺反饋迴路,自己睇唔到渲染結果,傾向保守,成日要人 push 「再複雜啲」。呢兩點疊加,令到最後20%嘅視覺微調一定要人手介入。
- 1 確定性:改一處就一處,唔怕隨機變動
- 2 純 HTML 底座對 AI 友好,成品率高
- 3 迭代快,五分鐘一輪,三四輪就能用
- 4 適合批量生產,系列化內容效率高
- 最後20%視覺微調仍要人手,空間位置同動畫程度難用語言講清
- 自然語言描述精確空間關係效率低,遠不如 GUI 直接拖
- 模型傾向保守,需要反覆 push 先達標
- HTML+CSS 動畫表現力有天花板,做唔到寫實電影級畫面
Vibe Coding 進入視頻領域
Hyperframes 本質上係將視頻拉入咗 vibe coding 領域:版本控制、批量生成、確定性復現。作者全程用 Claude Code,佢唔係一個視頻製作 agent,而係一個通用 coding agent,只不過今次寫嘅 code 會被渲染成視頻。
HeyGen 做 Hyperframes 背後有商業邏輯:佢哋核心產品係 AI 數字人,之前用 Remotion 組裝視頻,但 Remotion 係商業授權且用 React,對 AI 唔夠友好。Hyperframes 砍掉 React,用純 HTML,對 AI 準確率高好多。而且框架免費,數字人組件收費,呢個係平台策略——誰定義咗基礎設施接口,誰就擁有平台地位。
確定、可控、批量生產

👦🏻 作者: Daniel
🥷 編輯: Koji
🧑🎨 排版: Zeooo

4月,HeyGen 發佈咗 Hyperframes,一個基於 HTML 嘅視頻渲染框架。佢唔生成畫面,而係令代碼變成幀率穩定、動畫流暢、可以直接上傳播放嘅視頻文件。關鍵詞三個:確定、可控、批量生產。
唔係通過 Diffusion 去生成,而係通過代碼逐幀精確控制畫面。
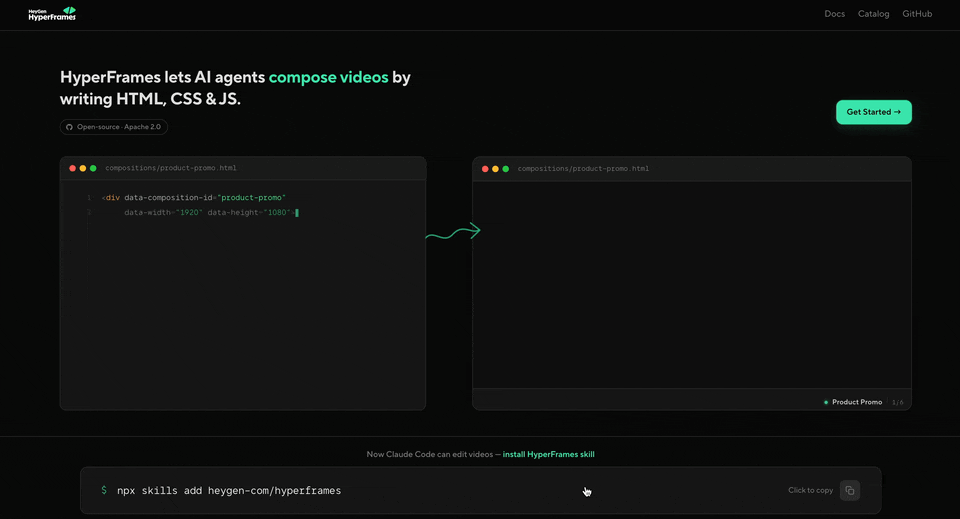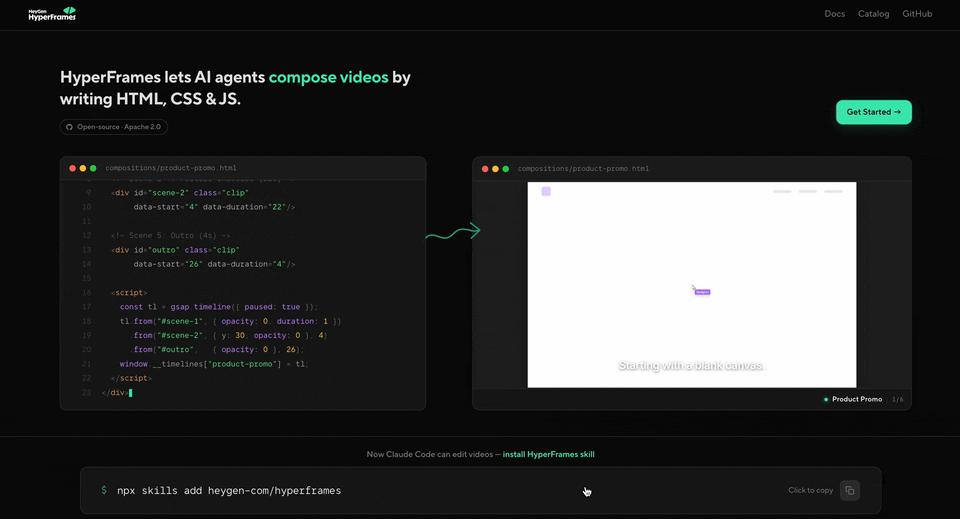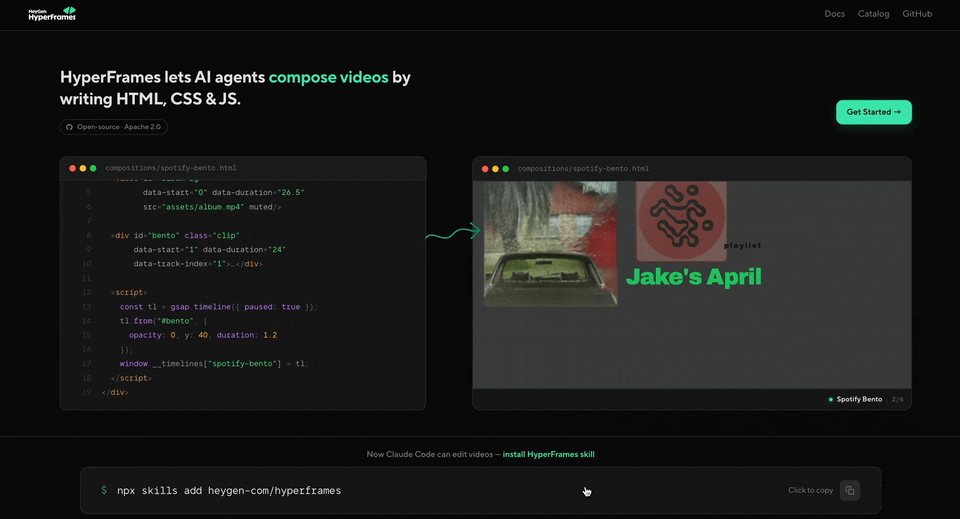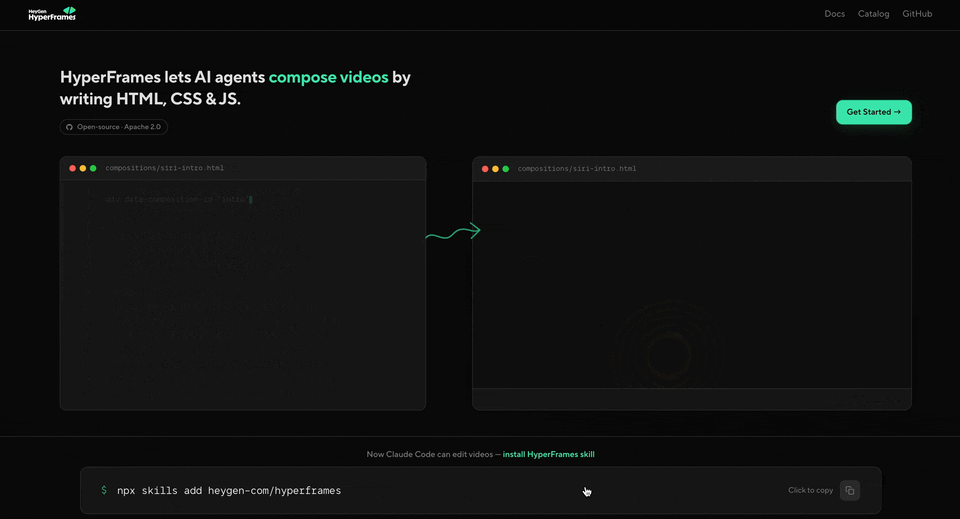
喺 Hyperframes 之前,呢個領域最重要嘅項目係 Remotion。2021 年發佈,思路好優雅:用最經典嘅前端框架 React 寫視頻,每一幀係一個組件,時間軸上嘅每一秒都係代碼可控嘅。
Remotion 做得唔錯,都有唔少付費用戶。但 HeyGen 自己大量使用 Remotion 之後,覺得唔夠用,於是從頭寫咗 Hyperframes,然後開源。
點解唔夠用?點解要重新造一個輪子?呢個係理解 Hyperframes 最重要嘅問題。先睇下佢用起上嚟到底點樣。
啟動方法好簡單。運行一行命令將 Hyperframes 嘅 skill 裝入你嘅 AI agent(Claude Code、Codex、OpenClaw 都得),初始化一個項目目錄,之後就完全用自然語言交互。
我用 Claude Code 配 Opus 4.6 做測試。第一條指令:
做一個 9:16 的 TikTok 風格短視頻,給外行人介紹 DeepSeek V4 和 V3 的區別,大概 30 秒,畫面要有 DeepSeek 的視覺特徵,動畫有彈性,加上語調專業的 TTS。
呢個模擬嘅係一個好真實嘅場景:我想快脆做一個科普視頻俾大眾睇,冇乜點動腦寫 prompt,都冇規定視頻裏面每個部分講咩、點樣講,全部俾 AI 自己嚟做,成本可以低到咩程度?
Claude Code 自己去搜索咗 DeepSeek V4 嘅資料,用 Kokoro 生成咗語音,做咗視覺設計,輸出咗一個 HTML 文件。
呢度有一個值得注意嘅細節:Hyperframes 內置咗強制校驗機制。HTML 生成後會自動檢查格式規範,內容溢出、對比度唔夠搞到文字睇唔清,呢啲問題會喺渲染前就被攔住。出品至少係「可睇」嘅,唔會出現排版亂咗嘅情況。
效果比較簡單,基本係幾頁帶文字同過渡動畫嘅畫面,似一個會鬱嘅 PPT。配色都偏醜,而且默認用咗英文。不過只俾咗一句指令,冇做任何調優,呢個起點算合格。
接下來我開始調。俾咗一段修改指令:
主配色換成白底藍黑字、更簡約高級的視覺風格;語言換成中文;解決字幕和語音的節奏錯位問題;轉場動畫換成更豐富的效果;關鍵詞出現時藍底高亮白字。
Claude Code 唔止改咗樣式。佢重新核實咗 V4 嘅技術參數,修正咗第一版裏面嘅幾個事實錯誤,例如將模糊嘅「計算量減少 73%」改咗做更準確嘅「注意力計算省 73%」,內容同形式一齊迭代咗。
再微調一輪:頂部加一個標題、將條狀圖換成環形圖、換咗一句太中二嘅口號、轉場動畫多樣化啲。每輪微調大概五分鐘。
調完嘅效果已經比較似樣了。從「醜 PPT」到「發得出去」,一共三四輪迭代,累計半粒鐘。 呢個成本已經比自己喺剪映裏面拖拽元素低,而且完全冇軟件嘅上手門檻。
科普視頻係「從零開始」,多少有啲粗糙。接下來試一個更接近實際生產嘅場景:提供一啲基礎素材同指令,同一套模板、同一個風格,批量生成一組系列視頻。
我揀咗三麗鷗家族做試驗,提前搜好咗美樂蒂、庫洛米、布丁狗、玉桂狗四個角色嘅圖片素材(PNG、GIF),然後俾咗一條比較詳細嘅指令:
四個視頻共用一套模板結構(出場→介紹→角色關係→系列結尾),但每個角色有自己的配色(粉、紫、黃、藍)和動態背景(格子、流星、圓點、條紋);圖片要保持無底 PNG 的透明狀態;標題用可愛卡通的字體加描邊;角色圖片要有輕微浮動的呼吸感動畫。

(我從網上扒嘅參考圖)
從準備素材到四個視頻全部出曬,大約20分鐘。效果如下:
喺成個體驗過程中,我覺得最值得講嘅唔係最終效果有幾好睇,而係工作方式嘅變化。
用 Sora 或者 Runway 生視頻,你面對嘅係一個黑盒:輸入 prompt,等輸出,唔滿意就換個 prompt 重新嚟,有時之前改過嘅嘢,重新輸出一次之後又改返轉頭。你冇辦法講「就呢個畫面,將左邊嗰個元素向右移啲」。每次重新生成都係一次完整嘅賭博。
Hyperframes 完全唔同。因為底層係 HTML 代碼,每一幀嘅每一個元素都係確定嘅。你可以直接叫 AI 改某一行 CSS,將標題顏色由藍色換成紅色,或者將某個動畫嘅時長由 2 秒改成 1.5 秒,然後重新渲染。
同樣嘅代碼,每次渲染出嚟嘅視頻係一模一樣嘅。 呢個意味住你可以大膽修改細節,唔使擔心改一個地方、另一個地方莫名其妙變咗。
Hyperframes 同純 prompt 驅動嘅視頻生成工具,類似於用代碼寫定嘅 workflow 同模型通過自然語言理解嘅 skill,前者更穩定可控,後者靈活性同上限更高。喺當前階段兩種路徑並存。
如果你嘅需求係同模板批量生產內容,Hyperframes 呢種路徑會更適合。
另外,以上我手搓嘅兩個視頻仍然粗糙。Hyperframes 官方提供咗一啲成品模板,如果之後使用嘅社羣壯大起嚟,一定都會有開發者貢獻更多模板,同 PPT 模板生態一樣。

不過落到實際嘅生產環境裏面,Hyperframes 嘅侷限性依然存在。
前面提過,Hyperframes 嘅代碼成品率好高,HTML 層面幾乎唔出結構性錯誤。但「代碼行得通」同「畫面好睇」之間仍然有距離。
對於複雜嘅畫面構成同精緻嘅動效,哪怕已經用自然語言進行咗詳細描繪,效果同預期之間仍然會出現落差。呢種落差來自兩個唔同層面嘅侷限性。
第一類侷限性係自然語言描述空間關係嘅帶寬有限。 例如我叫佢生成十字路口播客嘅嘉賓金句剪輯(金句 clip 係我手工剪嘅):
使用Hyperframes做一個播客金句&開場的視頻,橫版16:9
素材:(視頻地址及文字)
佈局:類似聚光燈,深綠色背景上,一個圓形框住視頻裏的嘉賓,圓形下方是嘉賓的名字和title,旁邊用大字展示金句。三個素材的人像和文字位置要各不相同,以保證畫面的多樣性。
動畫:圓和文字從側方偏移滑入,文字隨着視頻節奏逐句出現。
轉場:clip 之間用簡潔的轉場。
呢個動畫本身唔難,但畫面嘅位置、縮放點樣設置,先至可以啱啱框住我想要嘅範圍,呢個我係冇辦法用語言同 Claude 講清楚嘅——「向左啲」「再大啲」係一個無底洞。我只能手動一點點調 HTML 裏面嘅數值,調完之後重新渲染睇結果,呢個係最費時間嘅一步。
呢個唔係模型嘅能力問題,而係自然語言本身喺描述精確空間關係時帶寬唔夠,效率比不上 GUI 界面,手動直接拖拽移動。
第二類侷限性係模型冇視覺反饋迴路,無法自判效果係咪達標。 例如我叫佢生成一個十字路口播客嘅動畫,prompt 如下:
使用Hyperframes做一個十字路口播客的動畫視頻,橫版16:9
播客名稱:十字路口,意為“站在科技與人文的十字路口”
播客logo:(圖片)
畫面佈局:背景,使用播客主題深綠色,佈滿複雜密集的線路,類似交通道路,又類似電路板和生長的樹枝,有曲有直。線路之間有豐富的幾何圖形不規則地排列做點綴,顯示出生命力。前景,畫面上半部分是logo,下半部分是播客名和slogan。前景的圖像都使用淺綠色
動畫:背景,從純深綠色開始,道路快速從中心向四周延伸,同時裝飾的幾何元素隨着道路生長而出現。前景,從一串大小不一的圓形組成的漩渦/波紋開始,波紋旋轉消失後,logo和文字快速彈出。前景和背景的動畫同時結束,結束後畫面靜止不變,總時長2s.整體動畫儘可能地跳躍、誇張、活潑、有生命力。
初版生成嘅畫面十分粗糙同簡單,喺多次反覆追加「更複雜」之後,模型先終於將初始 prompt 裏面已經寫明嘅「複雜」「繁多」「誇張」落實到位。換句話講,要求由一開始就寫咗喺度,但模型自動降級咗。
成品如下:
呢個係因為語言模型冇辦法真正「睇」到渲染結果。佢唔知道自己寫出嚟嘅代碼喺視覺上係咩效果,所以就冇辦法判斷「夠唔夠複雜」「夠唔夠誇張」。
佢傾向於生成保守、安全嘅版本,因為佢冇反饋信號嚟校準自己對「程度」嘅理解。
兩類侷限性疊加埋一齊,意味着目前 Hyperframes 嘅工作流裏面仍然存在一個必須人工介入嘅環節:視覺微調。
AI 可以快速生成 80% 嘅效果,但最後嗰 20%,位置啱唔啱、動畫夠唔夠複雜、整體感覺到冇到位,仍然需要人望住畫面手動調參數。 呢個環節嘅效率,決定咗佢可唔可以真正取代傳統視頻製作流程。
理解咗體驗,再嚟睇背後嘅商業邏輯。
HeyGen 係做 AI 數字人嘅公司,核心產品係你上傳一段文字,佢幫你生成一個數字人講嘢嘅視頻。
背後嘅流程大概係:先用 AI 生成數字人嘅臉部動畫同口型,然後將呢啲素材組裝成一個完整嘅視頻,加上背景、字幕、轉場、logo。
呢個組裝環節,HeyGen 之前一直用緊 Remotion。但 Remotion 有一個現實問題:佢係商業授權嘅。
但慳錢只係表面原因。更深層嘅原因係,Remotion 係為人設計嘅。
Remotion 揀 React 作為技術底座,因為 React 係前端工程師最熟悉嘅框架。如果你嘅用戶係程序員,俾佢哋用最熟嘅工具就係最低摩擦嘅方案。
但 HeyGen 嘅場景變咗。喺佢哋嘅生產管線裏面,越來越多嘅視頻唔係人喺度寫代碼生成嘅,而係 AI agent 喺度調 API 自動生成嘅。
所以 Hyperframes 砍咗 React,回到最基礎嘅 HTML + CSS + JavaScript。對 AI 嚟講,生成一段純 HTML 比生成一個 React 組件樹準確率高出好多。
從商業模式上睇,Hyperframes 嘅組件目錄裏面有一個叫 HeyGen Avatar 嘅組件,用嚟嵌入 HeyGen 嘅數字人。框架免費,數字人收費。用咗呢個框架,自然就接入咗 HeyGen 嘅核心付費產品。
HeyGen 賭嘅係:喺 AI 視頻嘅世界裏面,雖然會大量用到 AIGC 生成嘅內容,但仍然需要一個結構化嘅、可控嘅代碼層嚟控制視頻嘅基本訊息、剪輯同畫面轉換。邊個定義咗呢層基礎設施嘅接口,邊個就擁有咗平台地位。
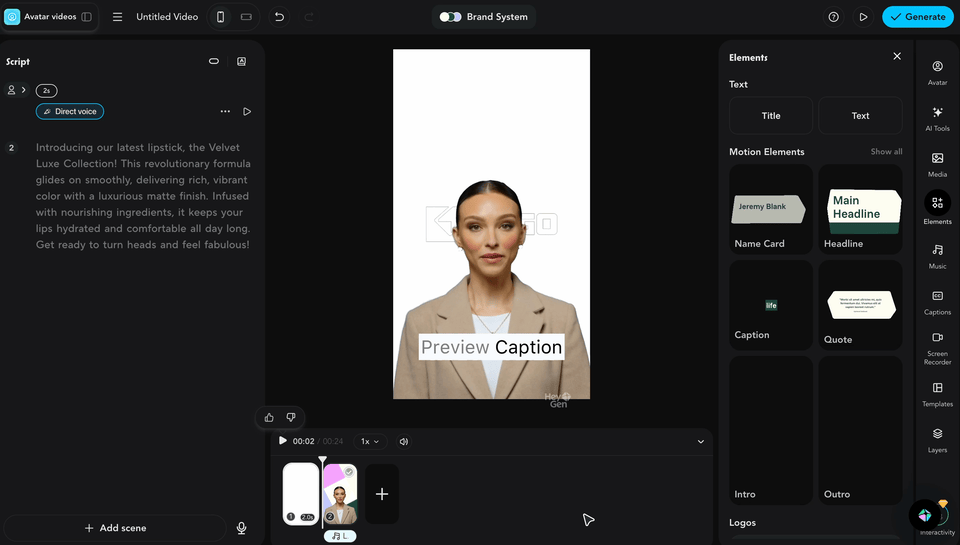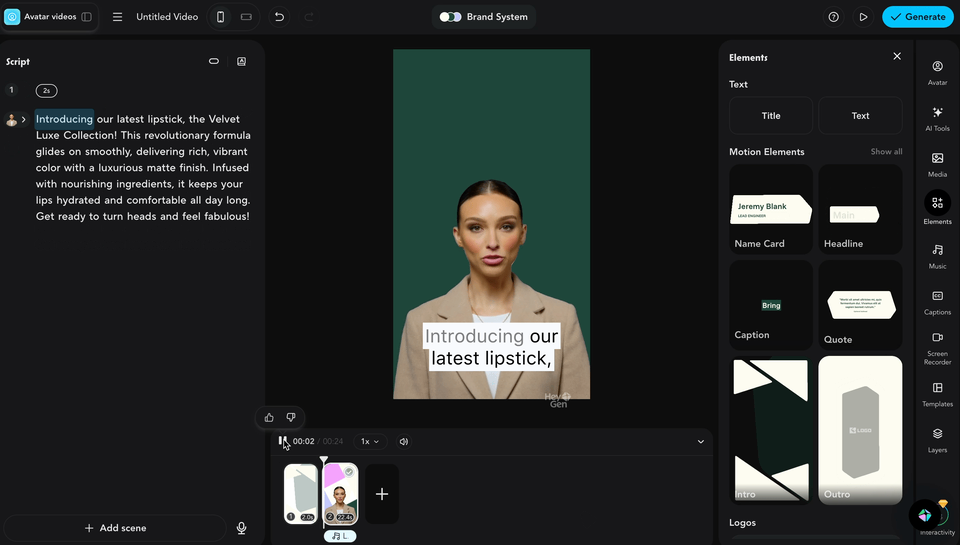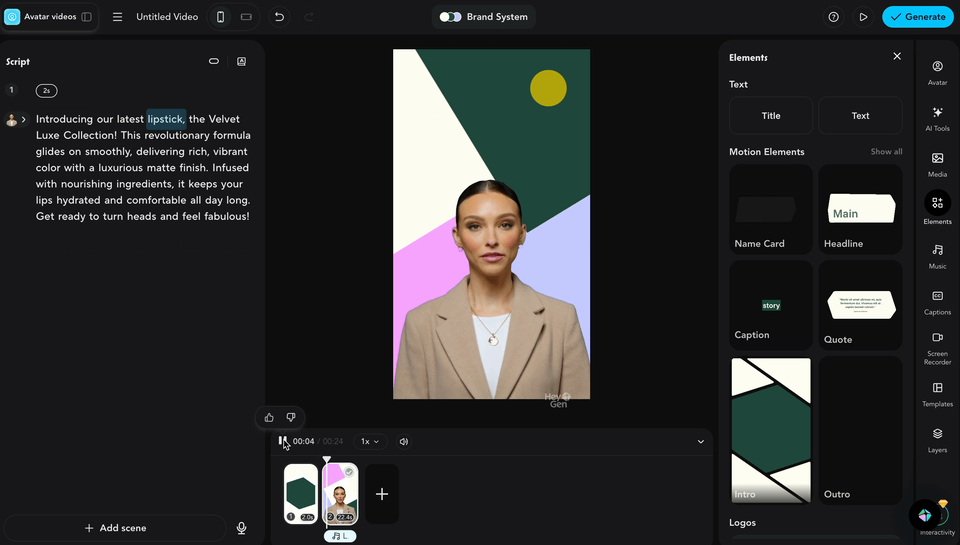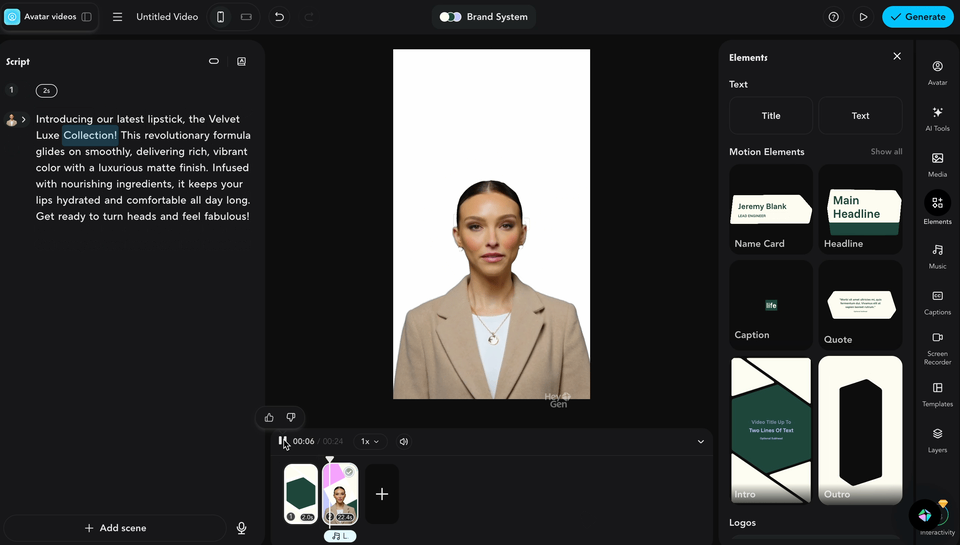
(hyperframes嘅動畫同數字人結合埋一齊嘅效果)
Hyperframes 本質上係將視頻拉咗入 vibe coding 嘅領域:版本控制、批量生成、確定性復現。
我喺體驗 Hyperframes 嘅全程都用緊 Claude Code,佢唔係一個視頻製作 agent,佢就係一個通用嘅 coding agent,只不過今次寫嘅代碼會被渲染成視頻。
agent 能力嘅邊界唔喺 agent 本身,而係喺佢可以調用嘅工具,代碼正在成為 AI 理解同操控世界嘅 lingua franca,換句話講,coding agent 就係通用 agent。
下一個被拉入代碼世界嘅創作媒介,又會係咩呢。
🚥
附上 Hyperframes 使用體驗總結:
Pros:
•確定性。改一處就係一處,唔會似生成式工具咁每次重新嚟過都係賭博
•純 HTML 底座對 AI 友好,成品率高,幾乎唔出結構性錯誤
•迭代好快,五分鐘一輪,三四輪就可以由粗糙到發得
•適合批量生產,同模板換內容,系列化內容嘅效率碾壓手工
Cons:
•最後 20% 嘅視覺微調仍然要人嚟做,空間位置、動畫程度呢啲嘢講唔清楚
•自然語言描述精確嘅空間關係效率太低,遠不如 GUI 直接拖
•模型睇唔到自己渲染出嚟嘅嘢,總是傾向保守,需要反覆 push
•HTML+CSS 動畫嘅表現力有天花板,寫實同電影級畫面做唔到

確定、可控、批量生產
👦🏻 作者: Daniel
🥷 編輯: Koji
🧑🎨 排版: Zeooo
4 月,HeyGen 發佈了 Hyperframes,一個基於 HTML 的視頻渲染框架。它不生成畫面,而是讓代碼變成幀率穩定、動畫流暢、可以直接上傳播放的視頻文件。關鍵詞三個:確定、可控、批量生產。
不是通過 Diffusion 去生成,而是通過代碼來逐幀精確控制畫面。
在 Hyperframes 之前,這個領域最重要的項目是 Remotion。2021 年發佈,思路很優雅:用最經典的前端框架 React 寫視頻,每一幀是一個組件,時間軸上的每一秒都是代碼可控的。
Remotion 做得不錯,也有了不少付費用戶。但 HeyGen 自己大量使用 Remotion 之後,覺得不夠用了,於是從頭寫了 Hyperframes,然後開源。
為什麼不夠用?為什麼要重新造一個輪子?這是理解 Hyperframes 最重要的問題。先看看它用起來到底怎樣。
啓動方法很簡單。運行一行命令把 Hyperframes 的 skill 裝進你的 AI agent(Claude Code、Codex、OpenClaw 都行),初始化一個項目目錄,之後就完全用自然語言交互了。
我用 Claude Code 配 Opus 4.6 做測試。第一條指令:
做一個 9:16 的 TikTok 風格短視頻,給外行人介紹 DeepSeek V4 和 V3 的區別,大概 30 秒,畫面要有 DeepSeek 的視覺特徵,動畫有彈性,加上語調專業的 TTS。
這模擬的是一個很真實的場景:我想快速做一個科普視頻給大眾看,沒怎麼動腦寫 prompt,也沒有規定視頻裏的每個部分講什麼、怎麼講,全讓 AI 自己來做,成本能低到什麼程度?
Claude Code 自己去搜索了 DeepSeek V4 的資料,用 Kokoro 生成了語音,做了視覺設計,輸出了一個 HTML 文件。
這裏有一個值得注意的細節:Hyperframes 內置了強制校驗機制。HTML 生成後會自動檢查格式規範,內容溢出、對比度不夠導致文字看不清,這些問題會在渲染前就被攔住。出品至少是「可看」的,不會出現排版亂掉的情況。
效果比較簡單,基本是幾頁帶文字和過渡動畫的畫面,像一個會動的 PPT。配色也偏醜,而且默認用了英文。不過只給了一句指令,沒做任何調優,這個起點算合格。
接下來我開始調。給了一段修改指令:
主配色換成白底藍黑字、更簡約高級的視覺風格;語言換成中文;解決字幕和語音的節奏錯位問題;轉場動畫換成更豐富的效果;關鍵詞出現時藍底高亮白字。
Claude Code 不只是改了樣式。它重新核實了 V4 的技術參數,修正了第一版裏的幾個事實錯誤,比如把模糊的「計算量減少 73%」改成了更準確的「注意力計算省 73%」,內容和形式一起迭代了。
再微調一輪:頂部加一個標題、把條狀圖換成環形圖、換掉一句太中二的口號、轉場動畫多樣化一些。每輪微調大概五分鐘。
調完的效果已經比較像樣了。從「醜 PPT」到「能發出去」,一共三四輪迭代,累計半小時。 這個成本已經比自己在剪映裏拖拽元素低了,而且完全沒有軟件的上手門檻。
科普視頻是「從零開始」,多少有點粗糙。接下來測一個更接近實際生產的場景:提供一些基礎素材和指令,同一套模板、同一個風格,批量生成一組系列視頻。
我選了三麗鷗家族做試驗,提前搜好了美樂蒂、庫洛米、布丁狗、玉桂狗四個角色的圖片素材(PNG、GIF),然後給了一條比較詳細的指令:
四個視頻共用一套模板結構(出場→介紹→角色關係→系列結尾),但每個角色有自己的配色(粉、紫、黃、藍)和動態背景(格子、流星、圓點、條紋);圖片要保持無底 PNG 的透明狀態;標題用可愛卡通的字體加描邊;角色圖片要有輕微浮動的呼吸感動畫。
(我從網上扒的參考圖)
從準備素材到四個視頻全部出完,大約20分鐘。效果如下:
在整個體驗過程中,我覺得最值得說的不是最終效果有多好看,而是工作方式的變化。
用 Sora 或者 Runway 生視頻,你面對的是一個黑盒:輸入 prompt,等輸出,不滿意就換個 prompt 重來,有時候之前改過的東西,重新輸出一次之後又改回去了。你沒有辦法說「就這個畫面,把左邊那個元素往右移一點」。每次重新生成都是一次完整的賭博。
Hyperframes 完全不同。因為底層是 HTML 代碼,每一幀的每一個元素都是確定的。你可以直接讓 AI 改某一行 CSS,把標題顏色從藍色換成紅色,或者把某個動畫的時長從 2 秒改成 1.5 秒,然後重新渲染。
同樣的代碼,每次渲染出來的視頻是一模一樣的。 這意味着你可以大膽修改細節,不用擔心改一個地方、另一個地方莫名其妙變了。
Hyperframes 和純 prompt 驅動的視頻生成工具,類似於用代碼寫定的 workflow 和模型通過自然語言理解的 skill,前者更穩定可控,後者靈活性和上限更高。在當前階段兩種路徑並存。
如果你的需求是同模板批量生產內容,Hyperframes 這種路徑會更適合。
另外,以上我手搓的兩個視頻仍然粗糙。Hyperframes 官方提供了一些成品模板,如果之後使用社羣壯大起來,也一定會有開發者貢獻更多模板,和 PPT 模板生態一樣。
不過落到實際的生產環境裏,Hyperframes 的侷限性依然存在。
前面提到,Hyperframes 的代碼成品率很高,HTML 層面幾乎不出結構性錯誤。但「代碼跑得通」和「畫面好看」之間仍然有距離。
對於複雜的畫面構成和精緻的動效,哪怕已經用自然語言進行了詳細描繪,效果和預期之間仍然會出現落差。這種落差來自兩個不同層面的侷限。
第一類侷限是自然語言描述空間關係的帶寬有限。 比如我讓它生成十字路口播客的嘉賓金句剪輯(金句 clip 是我手工剪的):
使用Hyperframes做一個播客金句&開場的視頻,橫版16:9
素材:(視頻地址及文字)
佈局:類似聚光燈,深綠色背景上,一個圓形框住視頻裏的嘉賓,圓形下方是嘉賓的名字和title,旁邊用大字展示金句。三個素材的人像和文字位置要各不相同,以保證畫面的多樣性。
動畫:圓和文字從側方偏移滑入,文字隨着視頻節奏逐句出現。
轉場:clip 之間用簡潔的轉場。
這個動畫本身不難,但畫面的位置、縮放怎麼設置,才能剛好框住我想要的範圍,這個我是無法用語言跟 Claude 說清的——「往左一點」「再大一點」是一個無底洞。我只能手動一點點調 HTML 裏的數值,調完之後重新渲染看結果,這是最費時間的一步。
這不是模型的能力問題,而是自然語言本身在描述精確空間關係時帶寬不夠,效率比不上 GUI 界面,手動直接拖拽移動。
第二類侷限是模型沒有視覺反饋迴路,無法自判效果是否達標。 比如我讓它生成一個十字路口播客的動畫,prompt 如下:
使用Hyperframes做一個十字路口播客的動畫視頻,橫版16:9
播客名稱:十字路口,意為“站在科技與人文的十字路口”
播客logo:(圖片)
畫面佈局:背景,使用播客主題深綠色,佈滿複雜密集的線路,類似交通道路,又類似電路板和生長的樹枝,有曲有直。線路之間有豐富的幾何圖形不規則地排列做點綴,顯示出生命力。前景,畫面上半部分是logo,下半部分是播客名和slogan。前景的圖像都使用淺綠色
動畫:背景,從純深綠色開始,道路快速從中心向四周延伸,同時裝飾的幾何元素隨着道路生長而出現。前景,從一串大小不一的圓形組成的漩渦/波紋開始,波紋旋轉消失後,logo和文字快速彈出。前景和背景的動畫同時結束,結束後畫面靜止不變,總時長2s.整體動畫儘可能地跳躍、誇張、活潑、有生命力。
初版生成的畫面十分粗糙且簡單,在多次反覆追加「更復雜」之後,模型才終於把初始 prompt 裏已經寫明的「複雜」「繁多」「誇張」落實到位。換句話說,要求從一開始就寫在那裏了,但模型自動降級了。
成品如下:
這是因為語言模型無法真正「看」到渲染結果。它不知道自己寫出來的代碼在視覺上是什麼效果,也就無法判斷「夠不夠複雜」「夠不夠誇張」。
它傾向於生成保守、安全的版本,因為它沒有反饋信號來校準自己對「程度」的理解。
兩類侷限疊加在一起,意味着目前 Hyperframes 的工作流裏仍然存在一個必須人工介入的環節:視覺微調。
AI 能快速生成 80% 的效果,但最後那 20%,位置對不對、動畫夠不夠複雜、整體感覺到沒到位,仍然需要人看着畫面手動調參數。 這個環節的效率,決定了它能不能真正替代傳統視頻製作流程。
理解了體驗,再來看背後的商業邏輯。
HeyGen 是做 AI 數字人的公司,核心產品是你上傳一段文字,它幫你生成一個數字人說話的視頻。
背後的流程大概是:先用 AI 生成數字人的臉部動畫和口型,然後把這些素材組裝成一個完整的視頻,加上背景、字幕、轉場、logo。
這個組裝環節,HeyGen 之前一直在用 Remotion。但 Remotion 有一個現實問題:它是商業授權的。
但省錢只是表面原因。更深層的原因是,Remotion 是為人設計的。
Remotion 選 React 作為技術底座,因為 React 是前端工程師最熟悉的框架。如果你的用戶是程序員,讓他們用最熟的工具就是最低摩擦的方案。
但 HeyGen 的場景變了。在他們的生產管線裏,越來越多的視頻不是人在寫代碼生成的,而是 AI agent 在調 API 自動生成的。
所以 Hyperframes 砍掉了 React,回到最基礎的 HTML + CSS + JavaScript。對 AI 來說,生成一段純 HTML 比生成一個 React 組件樹準確率高得多。
從商業模式上看,Hyperframes 的組件目錄裏有一個叫 HeyGen Avatar 的組件,用來嵌入 HeyGen 的數字人。框架免費,數字人收費。用了這個框架,自然就接入了 HeyGen 的核心付費產品。
HeyGen 賭的是:在 AI 視頻的世界裏,雖然會大量用到 AIGC 生成的內容,但仍然需要一個結構化的、可控的代碼層來控制視頻的基本信息、剪輯和畫面轉換。誰定義了這層基礎設施的接口,誰就擁有了平台地位。
(hyperframes的動畫和數字人結合在一起的效果)
Hyperframes 本質上是把視頻拉進了 vibe coding 的領域:版本控制、批量生成、確定性復現。
我在體驗 Hyperframes 的全程都在用 Claude Code,它不是一個視頻製作 agent,它就是一個通用的 coding agent,只不過這次寫的代碼會被渲染成視頻。
agent 能力的邊界不在 agent 本身,而在它能調用的工具,代碼正在成為 AI 理解和操控世界的 lingua franca,換句話說,coding agent 就是通用 agent。
下一個被拉進代碼世界的創作媒介,又會是什麼呢。
🚥
附上 Hyperframes 使用體驗總結:
Pros:
•確定性。改一處就是一處,不會像生成式工具那樣每次重來都是賭博
•純 HTML 底座對 AI 友好,成品率高,幾乎不出結構性錯誤
•迭代很快,五分鐘一輪,三四輪就能從粗糙到能發
•適合批量生產,同模板換內容,系列化內容的效率碾壓手工
Cons:
•最後 20% 的視覺微調仍然得人來做,空間位置、動畫程度這些東西說不清楚
•自然語言描述精確的空間關係效率太低,遠不如 GUI 直接拖
•模型看不到自己渲染出來的東西,總是傾向保守,需要反覆 push
•HTML+CSS 動畫的表現力有天花板,寫實和電影級畫面做不了