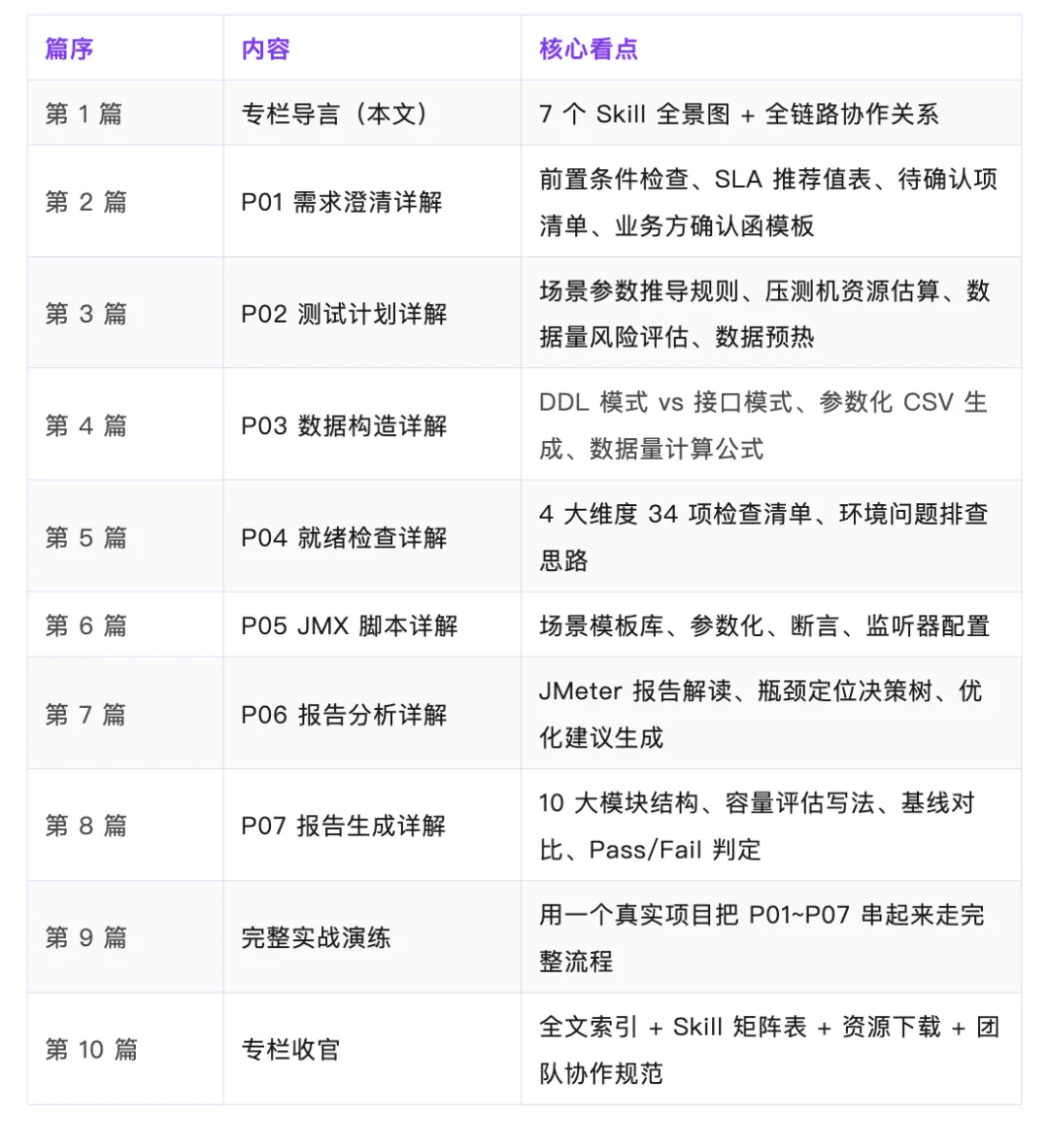
基於AI的全鏈路性能測試提效:7個 Skill技能,親測好用,實現全鏈路壓測落地
整理版優先睇
7個AI Skill將性能測試準備時間壓縮92%,全鏈路標準化流程
呢篇文章係一個資深測試工程師分享佢用7個AI Skill嚟將性能測試全流程標準化嘅經驗。作者發現,壓測執行本身只佔8%時間,其餘92%都係準備、溝通、文檔呢類重複性工作,而且一個唔小心就會返工。佢整理咗一份「返工清單」,列出需求、計劃、執行、報告階段常見嘅坑,例如SLA未書面確認、併發數拍腦袋、環境差異冇評估、數據耗盡導致TPS虛高等等。
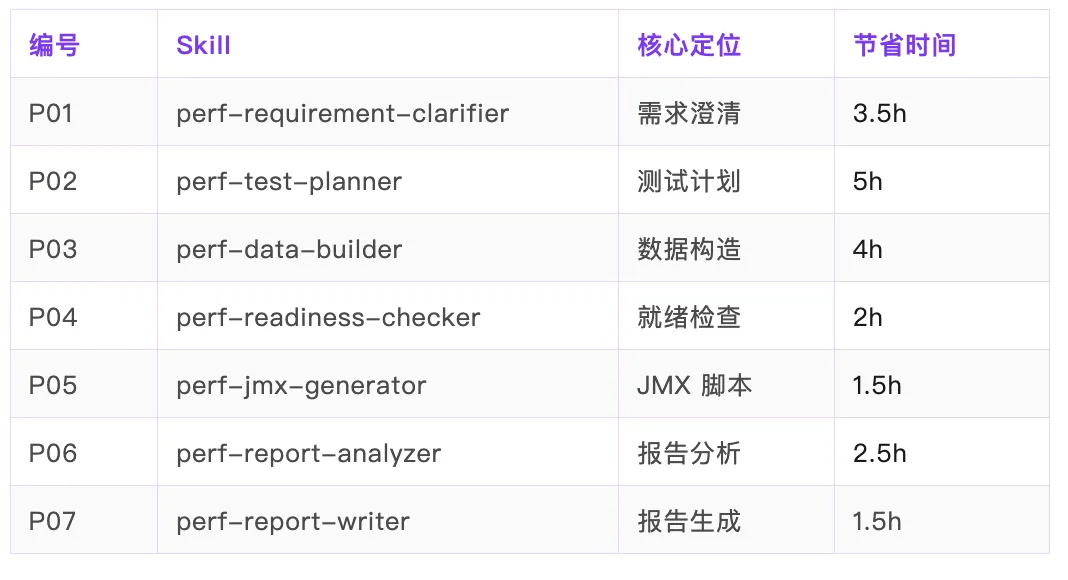
為咗解決呢啲問題,作者設計咗7個Skill,覆蓋從需求澄清到報告生成嘅完整鏈路。每個Skill都有明確嘅輸入輸出,可以喺WorkBuddy、Cursor、Trae、Claude等平台使用。核心設計係一個文件跨平台用,確保輸出質量一致。
成個專欄共10篇,呢篇係第一篇,介紹7個Skill嘅全景同每個Skill嘅具體功能。作者強調,AI係輔助決策,唔係取代,真正嘅判斷仲係要靠測試工程師。總結嚟講,呢套Skill可以將92%嘅準備時間壓縮到30%以下,等測試人員可以集中時間喺瓶頸定位同優化建議呢類高價值工作上。
- 結論:7個Skill將性能測試非執行時間從92%壓縮到30%以下,專注高價值判斷。
- 方法:每個Skill有標準輸入輸出,涵蓋需求澄清、測試計劃、數據構造、就緒檢查、腳本生成、報告分析、報告生成。
- 差異:AI只負責標準化產出,壓測執行由人操控,避免自動化風險,保留專業決策權。
- 啟發:性能測試嘅痛點唔係工具,而係流程決策——書面確認SLA、環境差異折算、數據預熱等先係關鍵。
- 可行動點:直接複製跨平台Prompt模板到各AI工具使用,或導入WorkBuddy作為Skill調用,立即提升效率。
返工清單:你踩過呢啲坑未?
作者發現一個驚人數字:壓測執行只佔8%時間,92%都花喺準備、溝通、整理文檔呢類環節,而且一步錯就會連環返工。佢整理咗一份「返工清單」,提醒自己避開常見陷阱。
- 1 SLA冇書面確認:壓測完改要求,500ms變200ms,重跑
- 2 併發數拍腦袋定1000,結果係日活10倍,結論失真
- 3 測試環境數據庫1C2G,生產8C32G,冇折算環境差異
- 4 場景參數全憑感覺,Ramp-up、持續時間亂填
- 5 目標併發800,單機JMeter壓到600時壓測機CPU 95%,結果失真
- 6 100個測試賬號跑500併發15分鐘,數據耗盡後緩存命中率100%,TPS虛高3倍
- 7 冇做數據預熱,冷緩存下RT係Warmed-up嘅3~5倍
- 8 壓測寫到測試庫,污染其他團隊數據
7個Skill全景:從需求到報告一條龍
作者將性能測試全流程拆成7個環節,每個環節整一個Skill,用AI輔助完成標準化輸出。唔係取代你決策,而係壓縮重複工作,留時間畀專業判斷。
呢套Skill最初喺WorkBuddy開發,但每個附帶跨平台Prompt模板,可喺Cursor、Trae、Claude、ChatGPT使用。一個文件,多平台用,輸出質量一致。
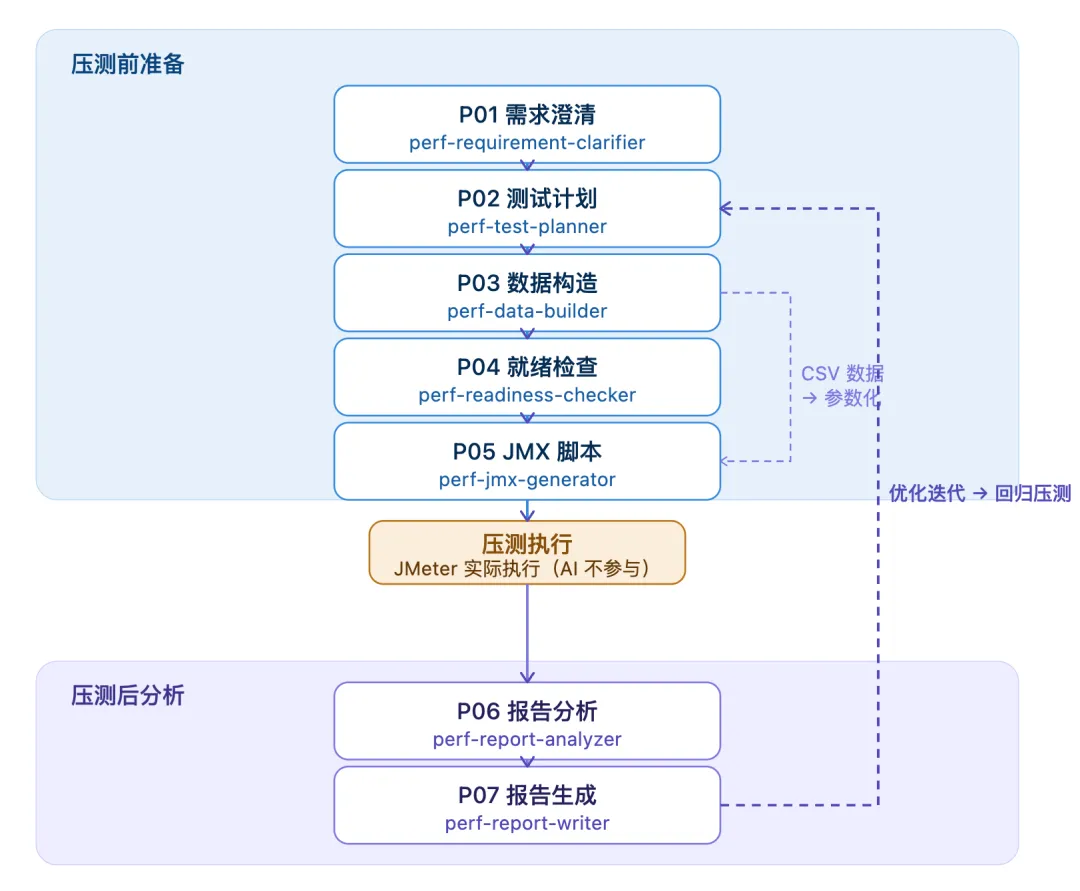
- P01 需求澄清:解決SLA未確認、併發數拍腦袋、環境差異未評估
- P02 測試計劃:自動推導場景參數、壓測機資源、數據量風險
- P03 數據構造:生成INSERT SQL或CSV參數化文件
- P04 就緒檢查:34項檢查清單,確保環境、腳本、監控、數據準備好
- P05 JMX腳本:生成場景模板庫同完整JMX文件
- P06 報告分析:解讀JMeter報告,定位瓶頸並畀優化建議
- P07 報告生成:輸出標準報告,含容量評估同基線對比
P01需求澄清:終極「防甩鍋」神器
作者用一個真實場景說明:週四下午4點收到「明早壓測」,文檔得一句「對訂單接口壓測,併發1000」。挨個問開發、業務、運維,到晚上9點都未搞清SLA、環境差異、鏈路範圍。P01就係將呢種混亂變成一份所有人事前簽字確認嘅標準化文檔。
- 1 直接扔畀佢接口文檔、PRD或一句話,例如「AIO平台用例查詢接口,200併發,P95≤500ms」
- 2 回答佢追問嘅關鍵問題:前置條件檢查(7項基本條件)
- 3 輸出2~4個文件:需求澄清文檔(10大章節)、待確認項清單(P0/P1分級)、業務方確認函、需求摘要
P01仲有負載默認值規則:基線測試持續5分鐘,容量規劃每階梯5~10分鐘,穩定性測試12小時。版本管控:plan_id命名規範,變更自動遞增版本號。
P02~P07:計劃、數據、檢查、腳本、分析、報告一條龍
其餘6個Skill針對計劃、執行、報告階段嘅痛點,每個都有明確輸入輸出。例如P02測試計劃自動推導線程數、Ramp-up、數據量風險;P03數據構造按DDL或接口模式生成數據;P04就緒檢查提供34項檢查清單+排查思路。
P05 JMX腳本內置查詢類、下單類等場景模板,生成完整JMX文件;P06報告分析用四象限決策樹定位瓶頸,畀出具體根因同優化建議;P07報告生成輸出10大模塊標準報告,包含容量評估、基線對比同HTML可視化。
總結:性能測試唔係跑個數字咁簡單
好多團隊做法係「壓一下」,出個TPS數字就交差。但好嘅性能測試應該輸出三個嘢:1. 撐唔撐得住?2. 瓶頸喺邊?3. 點樣優化?呢7個Skill就係圍繞呢三點設計,確保客觀依據、定位組件、正式報告。
Skill唔會取代你嘅業務理解同技術判斷,但可以將92%嘅準備時間壓縮到30%以下,等你集中精力喺真正有價值嘅事上。下一篇會講點樣用Skill做測試計劃。
我上個月幫一個業務團隊做咗一次完整嘅性能迴歸驗證。完整記錄時間之後,發現咗一個幾得意嘅數字分佈:
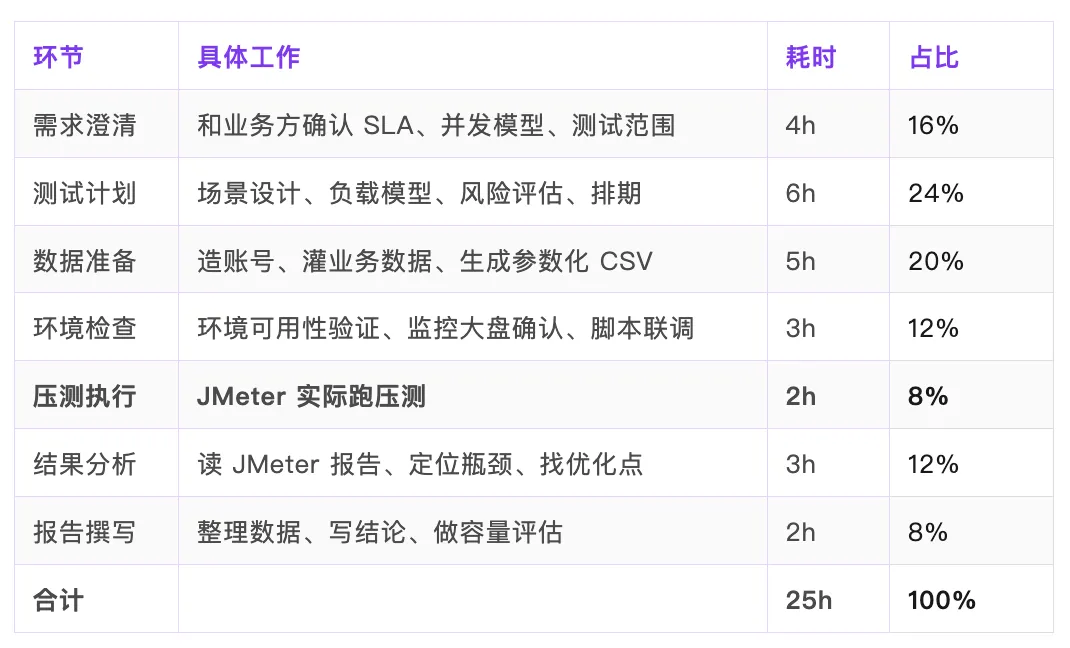
壓測執行本身只佔 8%。剩低嘅 92% 時間,全部用咗喺準備、溝通、整理同寫文檔上面。
呢個仲未係最攞命嘅。真正攞命嘅係呢啲環節環環相扣,前面一步未踩實,後面全部要返工。
踩過嘅坑
做性能測試呢啲年,我整理咗一個「返工清單」,每次壓測前都會拎出嚟睇一次,提醒自己唔好喺同一個地方衰兩次:
需求階段
SLA 冇同業務方書面確認,壓測完先話「反應時間要求唔係 500ms 係 200ms」,要重跑
併發數直接諗都唔諗就定 1000,結果係日活用戶嘅 10 倍,測試結論完全失真
測試環境數據庫係 1C2G,生產係 8C32G,環境差異冇評估,結果冇得折算
計劃階段
場景參數全部寫 X,實際填嗰時併發數、Ramp-up、持續時間全部靠估
目標併發 800,單機 JMeter 壓到 600 時壓測機 CPU 已經 95%,結果失真都唔知
100 個測試賬號撐 500 併發跑咗 15 分鐘,數據耗盡之後緩存命中率 100%,TPS 虛高 3 倍
執行階段
冇做數據預熱,冷緩存底下第一次壓測 RT 係 warmed-up 狀態嘅 3~5 倍
壓測寫咗入測試庫,污染咗其他測試團隊嘅數據
第三方接口冇做 Mock,對方服務波動導致 RT 跳嚟跳去,判斷唔到係自己問題定係外部問題
報告階段
報告結構每次唔一樣,老細問「同上次份報告點比」,發現口徑唔統一
容量評估唔識寫,老細問「而家撐到幾多用戶」,答唔出
基線對比漏咗,今次優化之後到底提升幾多、有冇退化,冇數據支撐
呢啲坑嘅共通點係:同壓測工具本身無關,全部係流程同決策層面嘅問題。
JMeter 你肯定識用。但需求點樣澄清、場景點樣設計、數據量點樣評估、瓶頸點樣定位、容量點樣寫,呢啲先係決定一次壓測有冇價值嘅關鍵。
呢套 Skill 可以解決咩問題
我將性能測試全流程拆成 7 個環節,每個環節整咗一個 Skill,用 AI 輔助完成標準化輸出。
唔係代替你做決策,而係將重複性、模板化嘅工作壓縮到最細,等你將時間花喺真正需要專業判斷嘅地方。
7 個 Skill 全景圖
呢啲 Skill 支援的平台
呢套 Skill 最初喺 WorkBuddy 入面開發,但每個 Skill 都提供咗跨平台通用 Prompt 模板,你可以直接喺以下平台用:
| 平台 | 使用方式 |
|---|---|
| WorkBuddy | @skill:perf-requirement-clarifier |
| Cursor | .cursorrules 文件 |
| Trae | |
| Claude / ChatGPT / DeepSeek |
核心設計:一個文件,多平台使用。
每個 Skill 文件同時包含兩部分內容:
WorkBuddy 專用格式:YAML frontmatter + 完整執行規則,等 WorkBuddy 識別同自動化叫用
跨平台 Prompt 模板:抽出核心流程、SLA 建議值、負載默認值、驗收標準呢啲關鍵規則,壓縮成各平台通用嘅 Prompt,複製貼上就用得
呢個意思係你唔需要為咗轉平台而重新寫一套 Prompt。無論喺邊個工具裏面,攞到嘅輸出質量都係一致嘅。
每個 Skill 都有明確嘅輸入、輸出同邊界,串埋就係完整嘅性能測試工作流。下面逐個展開每個 Skill 具體解決咩問題、輸入輸出係咩。
P01 需求澄清 — perf-requirement-clarifier
第二節需求階段嘅坑,SLA 冇書面確認、併發數靠估、環境差異冇評估,就係 P01 要解決嘅。
先講一個真實場景。
星期四下晝 4 點,你收到消息:聽朝 10 點壓測。
你打開需求文檔,發現得一句話:「對訂單接口進行壓測,併發 1000。」
你逐個問:
• 開發:「1000 併發係邊度嚟㗎?」開發:「業務方講嘅。」
• 業務方:「1000 係我哋嘅峯值,得唔得?」你:「峯值持續幾耐?」業務方:「就…峯值囉。」
• 運維:「測試環境數據庫係生產嘅一半規格,結果要唔要折算?」你:「……」
• 開發:「呢個接口仲調用咗庫存服務同支付網關,你哋壓唔壓?」你:「……」
夜晚 9 點,你仲喺微信追住三個人要資料。聽朝嘅壓測,SLA 未定、環境差異未評估、鏈路範圍未對齊、數據未準備好。
P01 做嘅嘢,就係將呢種混亂局面,變成一張所有人事前簽名確認嘅標準化需求文檔。
點樣用
性能需求澄清
壓測需求確認
perf requirement clarifier
確認壓測目標三步完成需求澄清:
第一步:將你手頭嘅材料直接掉俾佢
唔使提前整理格式,直接將接口文檔、PRD,或者業務方講嘅說話複製入去:
「我想對 AIO 平台嘅用例查詢接口做壓測,大概有 200 個併發用戶,要求 P95 喺 500ms 以內」
咁就夠㗎喇。P01 會自動解析接口資訊,提取業務場景,識別鏈路關係,發現缺失字段。
第二步:回答 P01 嘅補充問題
Skill 會先做前置條件檢查,確認 7 項基本條件係咪準備好:
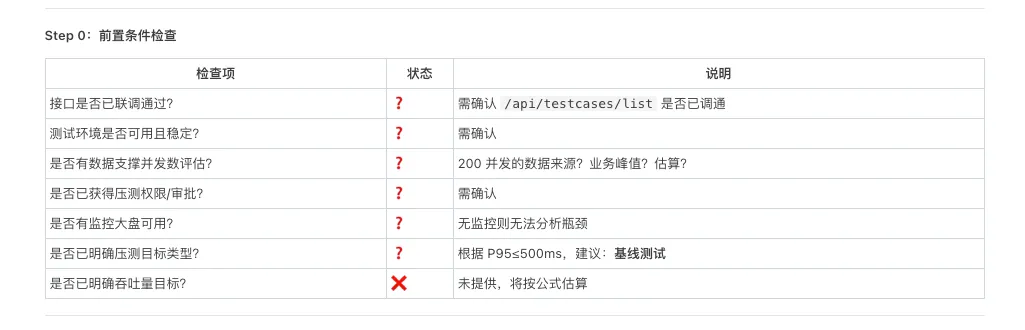
任何一項唔符合,P01 直接建議暫停,唔俾你喺一個有問題嘅基礎上繼續做落去。
檢查通過之後,P01 會追問幾個關鍵問題:

第三步:攞到輸出文件,直接用
P01 唔再強制輸出 4 個文件,而係根據場景自動判斷輸出數量:

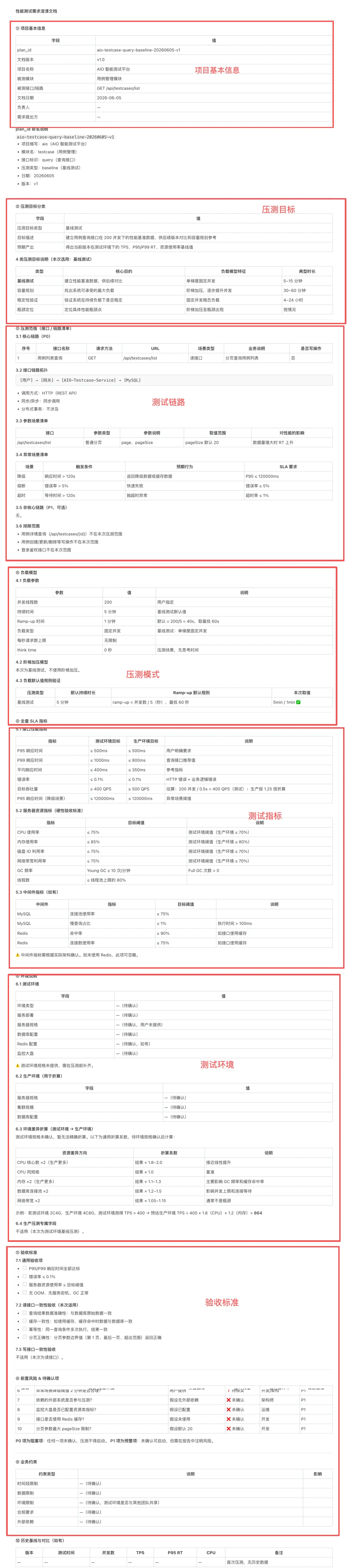
① 需求澄清文檔(主文檔)
模塊固化為 10 大固定章節,編號 ①~⑩,唔可以漏、唔可以調轉次序:
① 項目基本資訊(含 plan_id 命名規範)→ ② 壓測目標分類(4 類目標說明)→ ③ 壓測範圍(接口清單 + 鏈路拓撲 + 參數場景 + 異常場景)→ ④ 負載模型(按目標類型自動選擇)→ ⑤ 全量 SLA 指標 → ⑥ 環境說明(含差異折算)→ ⑦ 驗收標準 → ⑧ 前置風險 & 待確認項 → ⑨ 業務約束 → ⑩ 歷史基線
文檔裏面最有價值嘅三個地方:
SLA 建議值表,業務方講唔出 SLA 嗰時,將呢個表掉過去。
| 場景類型 | 測試環境 P95 | 生產環境 P95 | 錯誤率 |
|---|---|---|---|
環境差異折算公式:
→ CPU ×1.8,內存 ×1.2
→ 測試環境 TPS=500 → 預計生產 TPS ≈ 500 × 1.8 × 1.2 ≈ 1080
| 壓測類型 | 默認持續時長 | Ramp-up 默認規則 |
|---|---|---|
P01 自動掃描文檔入面所有「假設/默認值/未驗證」嘅字段,按風險等級分級:
| 序號 | 待確認問題 | 風險等級 | 建議確認人 |
|---|---|---|---|
| P0 | |||
| P0 | |||
| P0 | |||
| P0 | |||
| P0 | |||
| P0 | |||
③ 業務方確認函(可以直接轉發)
確認函有回覆記錄,壓測完唔會有人跳出嚟話「我當初冇同意呢個方案」。我哋計劃對 [訂單接口] 進行壓測,預計 [下星期五] 執行,核心接口包括:POST /api/order/create 等 3 個。
需要你確認:
1. 併發數 1000 同吞吐量目標 [X QPS] 係咪合理?係咪等於業務峯值流量?
2. 反應時間要求 P95 ≤ 500ms / P99 ≤ 1000ms 係咪可以接受?
3. 壓測範圍係咪完整?參數場景(分頁/批量/文件)係咪對齊咗?
4. 寫接口嘅驗收標準係咪可以接受?(庫存最終一致性、冪等性、事務回滾正確性)
5. 係咪接受測試環境結果作為參考?(測試環境性能約為生產嘅 60-70%,結果需要折算)
請回覆:✅ 確認以上內容,可按計劃執行 / ❓ 有以下修改意見:[請填寫]
④ 需求摘要(一頁紙版本)
淨係保留核心指標,俾老細或者跨團隊同事睇,一頁 A4 就打得曬。
版本管控:需求變更點樣處理?
plan_id 命名規範:{項目}-{模塊}-{接口}-{壓測類型}-{日期}-{版本}
示例:aio-testcase-query-baseline-20260605-v1
| 變更類型 | 版本規則 |
|---|---|
每次變更保留歷史版本,plan_id 同步更新。如果下游 perf-readiness-checker 就緒檢查失敗,發現係需求理解偏差,可以迴流 P01 重新澄清,版本號會自動遞增。
完整示例:AIO 平台用例查詢接口
你嘅輸入:


需求澄清文檔:
業務方確認函:


典型節省:3.5 個鐘(主要係來回溝通嘅時間)
P02 測試計劃 — perf-test-planner
第二節計劃階段嘅坑——場景參數靠估、壓測機資源冇估算、數據量冇評估,P02 逐一解決。
• 場景參數推導規則:根據目標併發同 QPS 自動推導線程數、Ramp-up、持續時間
• 場景組合推薦:單接口基線 → 混合場景 → 極限容量 → 穩定性,四段式遞進
• 壓測機資源估算:根據目標併發同協議類型估算需要嘅 JMeter 節點數
• 數據量風險評估:計算併發 × 持續時間需要消耗幾多數據,提早預警數據耗盡
• 數據預熱環節:明確係咪需要數據預熱,避免冷緩存導致 RT 虛高
• 基線對比計劃:今次壓測同邊個版本對比,口徑提前對齊
P03 數據構造 — perf-data-builder
P03 解決嘅係第二節入面冇展開嘅問題:造數據慢、參數化 CSV 手動併、數據量唔夠導致壓測中途數據耗盡。
• DDL 模式:直接生成 INSERT SQL,按表依賴順序批量造數據
• 接口模式:生成 CSV 參數化文件 + 配套請求體模板,直接餵俾 JMeter
• 數據量計算公式:按併發 × 持續時間 × 去重係數自動計算需要造幾多條數據
P04 就緒檢查 — perf-readiness-checker
P04 解決嘅係第二節執行階段嘅前置問題:環境唔穩定、監控冇配、腳本跑唔通,導致壓測中途中斷或結果失真。
• 4 大維度 34 項檢查清單:環境維度(服務狀態、數據庫連接、網絡連通)/ 腳本維度(參數化、斷言、關聯提取)/ 監控維度(JMeter 監聽器、服務器監控大盤、日誌採集)/ 數據維度(數據量、數據分佈、髒數據)
• 環境問題排查思路:檢查項唔通過嗰時,俾出具體嘅排查步驟同常見根因
P05 JMX 腳本 — perf-jmx-generator
P05 解決嘅係工具層面最嘥時間嘅事:喺 JMeter GUI 入面手動配置場景、斷言、參數化,一個場景搞半個鐘,仲好易整錯。
• 場景模板庫:查詢類、下單類、登錄類、搜索類——每類附帶推薦嘅線程組配置
• 完整 JMX 文件:包含線程組、HTTP 請求、斷言(響應碼 + 業務碼 + 響應時間)、參數化、監聽器
• 參數化配置:CSV Data Set Config + 變量引用,直接用得
• 跨平台 Prompt 模板:複製去 Cursor / Trae 都出到同樣質素嘅腳本
P06 報告分析 — perf-report-analyzer
P06 解決嘅係壓測完成之後最頭痕嘅事:JMeter 報告 20 幾行指標唔知睇邊個先,瓶頸定位靠估,優化建議寫唔具體。
• JMeter 報告解讀:邊啲指標異常、異常程度、優先級排序
• 瓶頸定位決策樹:按 TPS/RT/錯誤率/資源佔用四象限定位,縮細到具體組件
• 根因分析:數據庫慢查詢、GC 停頓、線程阻塞、連接池耗盡——俾出具體判斷依據
• 優化建議:每個瓶頸俾 2~3 個優化方向,附帶預計收益估算
P07 報告生成 — perf-report-writer
第二節報告階段嘅三個坑——報告結構唔統一、容量評估唔識寫、基線對比漏咗——P07 逐一解決。
• 10 大模塊標準結構:基本資訊 → 測試概述 → 環境 → 場景 → 結果 → 瓶頸 → 容量 → 基線對比 → 結論 → 附件
• 三種報告類型:標準性能測試報告 / 性能迴歸報告 / 性能驗收報告,按需要揀
• Pass/Fail/Pass with risk 判定:基於 SLA 自動判定,冇模稜兩可
• 容量評估:當前配置下最大撐到嘅併發數、建議擴容方案
• 基線對比表格:今次 vs 歷史版本,TPS/RT/錯誤率變化一目瞭然
• HTML 可視化報告:暗色主題、指標卡片、趨勢圖表,直接 Send email 或者貼 Wiki
Skill 協作鏈路
呢 7 個 Skill 唔係獨立嘅工具,佢哋構成一條完整嘅協作鏈路:
專欄內容
呢個專欄共 10 篇,結構如下:
專欄特色
- 工具導向,摒棄空談原理:唔講空泛嘅性能理論,集中落地提速、避坑實戰;
- 量化數據,落地可算 ROI:每篇附帶工時、產出數據,方便測試團隊核算投入收益;
- 輕量化 AI 落地:冇浮誇 AI 推銷話術,全部靠真實項目沉澱方案同模板。
總結
性能測試係測試工程師進階必經嘅路,亦都係最容易被低估嘅環節。
好多團隊嘅做法係:開發話「壓嚇」,測試就是但寫個 JMX 跑一跑,出咗個 TPS 數字就交差。但係呢種做法嘅產出得一個數字,對系統撐唔撐到、瓶頸喺邊、點樣優化——冇回答。
好嘅性能測試應該輸出三樣嘢:
1. 撐唔撐得住:喺當前配置下,目標併發能否穩定跑完,SLA 係咪達標
2. 瓶頸喺邊:CPU、內存、IO、網絡、數據庫、代碼,到底邊個係短板
3. 點樣優化:針對瓶頸俾出具體嘅優化方向同預計收益
呢 7 個 Skill 就係圍住呢三個輸出設計嘅:P01~P02 確保「撐唔撐得住」有客觀依據;P03~P06 確保「瓶頸喺邊」能定位到具體組件;P07 確保「點樣優化」能寫入正式報告交付畀業務方。
Skill 唔可以代替你對業務嘅理解同技術判斷,但可以將 92% 嘅準備工作時間壓縮到 30% 以下,等你將時間集中喺真正有價值嘅事情上。
下一篇我哋講下點樣用 skill 做性能測試嘅測試計劃。
往期精彩:
測試人嘅免費寶藏學習網站,TestHub 官網上線:使用手冊 + 視頻教程 + 學習中心 + 開源專區,強烈建議收藏
親測實踐!呢款 Skill 提升 90% 嘅複雜測試報告編寫效率
90% 測試團隊都喺度踩坑,Hermes Tester Skills 技能系統,1:1 復刻團隊測試能力
如需 skill 轉發呢篇文之後,加微信:

我上個月幫一個業務團隊做了一次完整的性能迴歸驗證。完整記錄時間後,發現了一個有意思的數字分佈:
壓測執行本身只佔 8%。剩下 92% 的時間,全部花在準備、溝通、整理和寫文檔上。
這還不是最要命的。真正要命的是這些環節環環相扣,前面一步沒踩實,後面全得返工。
踩過的坑
做性能測試這些年,我整理了一個「返工清單」, 每次壓測前都會拿出來看一遍,提醒自己別在同一個地方栽兩次:
需求階段
SLA 沒和業務方書面確認,壓測完說"響應時間要求不是 500ms 是 200ms",重跑
併發數直接拍腦袋定了 1000,結果是日活用戶的 10 倍,測試結論完全失真
測試環境數據庫是 1C2G,生產是 8C32G,環境差異沒評估,結果無法折算
計劃階段
場景參數全寫的 X,實際填的時候併發數、Ramp-up、持續時間全是憑感覺
目標併發 800,單機 JMeter 壓到 600 時壓測機 CPU 已經 95%,結果失真還不知道
100 個測試賬號支撐 500 併發跑了 15 分鐘,數據耗盡後緩存命中率 100%,TPS 虛高 3 倍
執行階段
沒做數據預熱,冷緩存下第一次壓測 RT 是 warmed-up 狀態的 3~5 倍
壓測寫到測試庫,污染了其他測試團隊的數據
第三方接口沒做 Mock,對方服務波動導致 RT 抖動,判斷不出是自己的問題還是外部問題
報告階段
報告結構每次都不一樣,領導問"和上次的報告對比呢",發現口徑不統一
容量評估不會寫,領導問"現在能支撐多少用戶",答不上來
基線對比漏掉,本次優化後到底提升多少、有沒有退化,沒數據支撐
這些坑的共同點是:和壓測工具本身無關,全部是流程和決策層面的問題。
JMeter 你肯定會用。但需求怎麼澄清、場景怎麼設計、數據量怎麼評估、瓶頸怎麼定位、容量怎麼寫,這些才是決定一次壓測有沒有價值的關鍵。
這套 Skill 能解決什麼
我把性能測試全流程拆成 7 個環節,每個環節做了一個 Skill,用 AI 輔助完成標準化輸出。
不是替代你做決策,而是把重複性、模板化的工作壓縮到最小,讓你把時間花在真正需要專業判斷的地方。
7 個 Skill 全景圖
這些 Skill 支持的平台
這套 Skill 最初在 WorkBuddy 中開發,但每個 Skill 都提供了跨平台通用 Prompt 模板,你可以直接在以下平台使用:
| 平台 | 使用方式 |
|---|---|
| WorkBuddy | @skill:perf-requirement-clarifier |
| Cursor | .cursorrules 文件 |
| Trae | |
| Claude / ChatGPT / DeepSeek |
核心設計:一個文件,多平台使用。
每個 Skill 文件同時包含兩部分內容:
WorkBuddy 專用格式:YAML frontmatter + 完整執行規則,供 WorkBuddy 識別和自動化調用
跨平台 Prompt 模板:提取核心流程、SLA 推薦值、負載默認值、驗收標準等關鍵規則,壓縮成各平台通用的 Prompt,複製粘貼即可使用
這意味着你不需要為了換平台而重寫一套 Prompt。無論在哪個工具裏,拿到的輸出質量是一致的。
每個 Skill 都有明確的輸入、輸出和邊界,串起來就是完整的性能測試工作流。下面逐個展開每個 Skill 具體能解決什麼、輸入輸出是什麼。
P01 需求澄清 — perf-requirement-clarifier
第二節需求階段的坑,SLA 沒書面確認、併發數拍腦袋、環境差異沒評估,就是 P01 要解決的。
先說一個真實場景。
週四下午 4 點,你收到消息:明早 10 點壓測。
你打開需求文檔,發現只有一句話:「對訂單接口進行壓測,併發 1000。」
你挨個問:
• 開發:「1000 併發是哪裏來的?」開發:「業務方說的。」
• 業務方:「1000 是我們峯值,行嗎?」你:「峯值持續多久?」業務方:「就…峯值啊。」
• 運維:「測試環境數據庫是生產的一半規格,結果要折算嗎?」你:「……」
• 開發:「這個接口還調了庫存服務和支付網關,你們壓嗎?」你:「……」
晚上 9 點,你還在微信上追着三個人要信息。明早的壓測,SLA 沒定、環境差異沒評估、鏈路範圍沒對齊、數據沒準備好。
P01 做的事,就是把這種混亂局面,變成一份所有人事前簽字確認的標準化需求文檔。
怎麼使用
性能需求澄清
壓測需求確認
perf requirement clarifier
確認壓測目標三步完成需求澄清:
第一步:把你手裏的材料直接扔給它
不用提前整理格式,直接把接口文檔、PRD、或者業務方的話複製進去:
「我想對 AIO 平台的用例查詢接口做壓測,大概有 200 個併發用戶,要求 P95 在 500ms 以內」
這就夠了。P01 會自動解析接口信息,提取業務場景,識別鏈路關係,發現缺失字段。
第二步:回答 P01 的補充問題
Skill 會先做前置條件檢查,確認 7 項基本條件是否就緒:
任何一項不滿足,P01 直接建議暫停,不讓你在一個有問題的基礎上繼續往下走。
檢查通過後,P01 會追問幾個關鍵問題:
第三步:拿到輸出文件,直接用
P01 不再強制輸出 4 個文件,而是根據場景自動判斷輸出數量:
① 需求澄清文檔(主文檔)
模塊固化成 10 大固定章節,編號 ①~⑩,不得遺漏、不得調換順序:
① 項目基本信息(含 plan_id 命名規範)→ ② 壓測目標分類(4 類目標說明)→ ③ 壓測範圍(接口清單 + 鏈路拓撲 + 參數場景 + 異常場景)→ ④ 負載模型(按目標類型自動選擇)→ ⑤ 全量 SLA 指標 → ⑥ 環境說明(含差異折算)→ ⑦ 驗收標準 → ⑧ 前置風險 & 待確認項 → ⑨ 業務約束 → ⑩ 歷史基線
文檔裏最有價值的三個地方:
SLA 推薦值表,業務方說不出 SLA 時,把這個表甩過去。
| 場景類型 | 測試環境 P95 | 生產環境 P95 | 錯誤率 |
|---|---|---|---|
環境差異折算公式:
→ CPU ×1.8,內存 ×1.2
→ 測試環境 TPS=500 → 預估生產 TPS ≈ 500 × 1.8 × 1.2 ≈ 1080
| 壓測類型 | 默認持續時長 | Ramp-up 默認規則 |
|---|---|---|
P01 自動掃描文檔裏所有「假設/默認值/未驗證」的字段,按風險等級分級:
| 序號 | 待確認問題 | 風險等級 | 建議確認人 |
|---|---|---|---|
| P0 | |||
| P0 | |||
| P0 | |||
| P0 | |||
| P0 | |||
| P0 | |||
③ 業務方確認函(可直接轉發)
確認函有回覆記錄,壓測完不會有人跳出來說「我當初沒同意這個方案」。我們計劃對 [訂單接口] 進行壓測,預計 [下週五] 執行,核心接口包括:POST /api/order/create 等 3 個。
需要你確認:
1. 併發數 1000 及吞吐量目標 [X QPS] 是否合理?是否等於業務峯值流量?
2. 響應時間要求 P95 ≤ 500ms / P99 ≤ 1000ms 是否可接受?
3. 壓測範圍是否完整?參數場景(分頁/批量/文件)是否已對齊?
4. 寫接口驗收標準是否可接受?(庫存最終一致性、冪等性、事務回滾正確性)
5. 是否接受測試環境結果作為參考?(測試環境性能約為生產的 60-70%,結果需折算)
請回復:✅ 確認以上內容,可按計劃執行 / ❓ 有以下修改意見:[請填寫]
④ 需求摘要(一頁紙版本)
只保留核心指標,給領導或跨團隊同事看,一頁 A4 能打完。
版本管控:需求變更怎麼辦?
plan_id 命名規範:{項目}-{模塊}-{接口}-{壓測類型}-{日期}-{版本}
示例:aio-testcase-query-baseline-20260605-v1
| 變更類型 | 版本規則 |
|---|---|
每次變更保留歷史版本,plan_id 同步更新。如果下游 perf-readiness-checker 就緒檢查失敗,發現是需求理解偏差,可以迴流 P01 重新澄清,版本號自動遞增。
完整示例:AIO 平台用例查詢接口
你的輸入:
需求澄清文檔:
業務方確認函:
典型節省:3.5h(主要是來回溝通的時間)
P02 測試計劃 — perf-test-planner
第二節計劃階段的坑——場景參數憑感覺、壓測機資源沒估算、數據量沒評估,P02 逐一解決。
• 場景參數推導規則:根據目標併發和 QPS 自動推導線程數、Ramp-up、持續時間
• 場景組合推薦:單接口基線 → 混合場景 → 極限容量 → 穩定性,四段式遞進
• 壓測機資源估算:根據目標併發和協議類型估算需要的 JMeter 節點數
• 數據量風險評估:計算併發 × 持續時間需要消耗多少數據,提前預警數據耗盡
• 數據預熱環節:明確是否需要數據預熱,避免冷緩存導致 RT 虛高
• 基線對比計劃:本次壓測和哪個版本對比,口徑提前對齊
P03 數據構造 — perf-data-builder
P03 解決的是第二節裏沒展開的問題:造數據慢、參數化 CSV 手工拼、數據量不足導致壓測中途數據耗盡。
• DDL 模式:直接生成 INSERT SQL,按表依賴順序批量造數據
• 接口模式:生成 CSV 參數化文件 + 配套請求體模板,直接餵給 JMeter
• 數據量計算公式:按併發 × 持續時間 × 去重係數自動計算需要造多少條數據
P04 就緒檢查 — perf-readiness-checker
P04 解決的是第二節執行階段的前置問題:環境不穩定、監控沒配、腳本跑不通,導致壓測中途中斷或結果失真。
• 4 大維度 34 項檢查清單:環境維度(服務狀態、數據庫連接、網絡連通)/ 腳本維度(參數化、斷言、關聯提取)/ 監控維度(JMeter 監聽器、服務器監控大盤、日誌採集)/ 數據維度(數據量、數據分佈、髒數據)
• 環境問題排查思路:檢查項不通過時,給出具體的排查步驟和常見根因
P05 JMX 腳本 — perf-jmx-generator
P05 解決的是工具層面最耗時的事:在 JMeter GUI 裏手動配置場景、斷言、參數化,一個場景配半小時,還容易配錯。
• 場景模板庫:查詢類、下單類、登錄類、搜索類——每類帶推薦的線程組配置
• 完整 JMX 文件:包含線程組、HTTP 請求、斷言(響應碼 + 業務碼 + 響應時間)、參數化、監聽器
• 參數化配置:CSV Data Set Config + 變量引用,直接可用
• 跨平台 Prompt 模板:複製到 Cursor / Trae 也能生成同樣質量的腳本
P06 報告分析 — perf-report-analyzer
P06 解決的是壓測完成後最頭疼的事:JMeter 報告 20 多列指標不知道先看哪個,瓶頸定位靠猜,優化建議寫不具體。
• JMeter 報告解讀:哪些指標異常、異常程度、優先級排序
• 瓶頸定位決策樹:按 TPS/RT/錯誤率/資源佔用四象限定位,縮小到具體組件
• 根因分析:數據庫慢查詢、GC 停頓、線程阻塞、連接池耗盡——給出具體判斷依據
• 優化建議:每個瓶頸給出 2~3 個優化方向,帶預期收益估算
P07 報告生成 — perf-report-writer
第二節報告階段的三個坑——報告結構不統一、容量評估不會寫、基線對比漏掉——P07 逐一解決。
• 10 大模塊標準結構:基本信息 → 測試概述 → 環境 → 場景 → 結果 → 瓶頸 → 容量 → 基線對比 → 結論 → 附件
• 三種報告類型:標準性能測試報告 / 性能迴歸報告 / 性能驗收報告,按需選擇
• Pass/Fail/Pass with risk 判定:基於 SLA 自動判定,不模稜兩可
• 容量評估:當前配置下最大支撐併發數、建議擴容方案
• 基線對比表格:本次 vs 歷史版本,TPS/RT/錯誤率變化一目瞭然
• HTML 可視化報告:暗色主題、指標卡片、趨勢圖表,直接發郵件或貼 Wiki
Skill協作鏈路
這 7 個 Skill 不是孤立的工具,它們構成一條完整的協作鏈路:
專欄內容
這個專欄共 10 篇,結構如下:
專欄特色
- 工具導向,摒棄空談原理:不講空洞性能理論,聚焦落地提速、避坑實操;
- 量化數據,落地可算 ROI:每篇附帶工時、產出數據,方便測試團隊核算投入收益;
- 輕量化 AI 落地:無浮誇 AI 營銷話術,全部依託真實項目沉澱方案與模板。
總結
性能測試是測試工程師進階的必經之路,也是最容易被低估的環節。
很多團隊的做法是:開發說"壓一下",測試就隨便寫個 JMX 跑一跑,出了個 TPS 數字就交差。但這種做法的產出只有一個數字,對系統能撐多少、瓶頸在哪、怎麼優化——沒有回答。
好的性能測試應該輸出三個東西:
1. 能不能撐住:在當前配置下,目標併發能不能穩定跑完,SLA 是否達標
2. 瓶頸在哪:CPU、內存、IO、網絡、數據庫、代碼,到底哪個是短板
3. 怎麼優化:針對瓶頸給出具體的優化方向和預期收益
這 7 個 Skill 就是圍繞這三個輸出設計的:P01~P02 確保「能不能撐住」有客觀依據;P03~P06 確保「瓶頸在哪」能定位到具體組件;P07 確保「怎麼優化」能寫進正式報告交付給業務方。
Skill 不能替代你對業務的理解和技術判斷,但能把 92% 的準備工作時間壓縮到 30% 以下,讓你把時間集中在真正有價值的事情上。
下一篇我們講講如何用skill做性能測試的測試計劃。
往期精彩:
測試人的免費寶藏學習網站,TestHub官網上線:使用手冊 + 視頻教程 + 學習中心 + 開源專區,強烈建議收藏
90%測試團隊都在踩坑,Hermes Tester Skills 技能系統,1:1復刻團隊測試能力
如需skill轉發此文後,添加微信: