覆盤:做這個 AI 測試用例設計助手,我踩過的坑和 8 個關鍵決策
整理版優先睇
工程設計比模型強弱更重要:AI測試用例助手嘅8個關鍵決策與6個坑
呢篇文章係作者做完一套AI測試用例設計助手之後嘅工程覆盤。作者用LangGraph StateGraph嚟做多步驟工作流,目標係解決LLM項目常見問題:格式唔穩定、速度慢、質量不可控、成本失控、難迭代。佢最大感受係模型能力只係上限,工程設計先決定下限。
文章詳細講咗8個關鍵決策,包括揀StateGraph而唔係純Agent、用Send API做動態並行、雙層狀態設計、自定義reducer處理並行追加同清空重試衝突、用硬編碼閾值迴流做質量控制、重試時注入改進建議同降低temperature、按節點分配模型以平衡成本同效果、全鏈路用Pydantic結構化輸出兼做容錯兜底。每個決策都有明確取捨同實戰理由。
另外佢列出6個踩過嘅坑:當生成係終點、當並行係純性能優化、Prompt越長越好、強制每次RAG檢索、只睇單次效果唔睇分佈、導出放到最後先考慮。最後佢建議由0開始嘅路線:先做最小閉環,再補並行、質量、穩定,最後先上增強功能。
- 模型能力只係上限,工程設計決定下限;LLM項目失敗通常唔係生成唔到,而係格式、速度、質量、成本、可迭代性出事。
- 揀LangGraph StateGraph而唔係Agent,因為需要顯式可控嘅節點+狀態+路由,質量閉環嘅閾值迴流必須硬控制。
- 用Send API做動態並行,實測3-5x提速,但要處理狀態合併複雜度,自定義reducer解決並行追加同清空重試衝突。
- 質量控制靠硬編碼閾值迴流(0.85),唔信模型自評;重試時注入改進建議、降低temperature,避免盲目重跑。
- 全鏈路用Pydantic結構化輸出,每個節點似後端接口,可測試可觀測;導出格式越早確定越好,推動數據結構穩定。
工程覆盤:點解模型強弱唔係最關鍵
作者做完呢套AI測試用例設計助手之後,最深刻體會係:模型能力只係上限,工程設計決定下限。LLM工作流項目常見失敗方式唔係「生成唔到」,而係格式唔穩、速度太慢、質量不可控、成本失控、難迭代。
8個關鍵決策:取捨與實戰心得
第一個決策係揀LangGraph StateGraph而唔係純Agent。原因係流程多步驟、強依賴狀態、帶條件分支,仲要支持並行。StateGraph前期代碼量更大,但穩定性同可維護性明顯更強。第二個決策係用Send API做動態並行而唔係固定併發,實測提速3-5倍,但帶嚟狀態合併複雜度。
第三個決策係雙層狀態設計:全局狀態加Worker獨立上下文,避免並行互相污染。第四個決策係自定義reducer(add_or_reset_cases),解決並行追加同清空重試嘅衝突。作者踩過坑:以為設空List就係清空,但reducer合併語義下舊數據仲喺度。
第五個決策係質量控制用硬編碼閾值迴流(0.85),唔靠模型自評。第六個決策係重試時注入改善建議、降低temperature,令輸出更收斂。第七個決策係按節點分配模型</highlight>:強模型做方向性節點,性價比模型做批量生成,輕模型做去重。第八個決策係全鏈路用Pydantic結構化輸出,兼做容錯兜底。
- 1 選LangGraph StateGraph,放棄自由度換取可控性
- 2 Send API動態並行,顯著提速但需處理狀態合併
- 3 雙層狀態隔離Worker上下文,全局狀態共享
- 4 自定義reducer解決並行追加與清空重試衝突
- 5 硬編碼閾值迴流,質量控制工程化
- 6 重試時帶改進建議同温度衰減,避免盲目重跑
- 7 按節點分配模型,平衡效果與成本
- 8 全鏈路Pydantic結構化輸出,方便測試與導出
6個踩過嘅坑:直接收藏慳時間
作者分享咗6個實戰坑,值得做類似項目嘅朋友注意。第一個坑係將「生成」當成終點,無評審同迴流,輸出一定唔穩定。第二個坑係將「並行」當成純性能優化,唔處理reducer遲早出事。
- 生成唔係終點,要加評審同迴流先穩定
- 並行會改變狀態合併語義,一定要處理reducer
- Prompt越長越易漂,能結構化就結構化
- RAG唔好強制每次檢索,按需檢索兼摘要注入
- 唔好只睇單次效果,要睇質量分數分佈、重試率、平均耗時
- 導出格式越早做越好,會推動數據結構穩定
由0開始嘅建議路線:先可用,再好用,最後更強
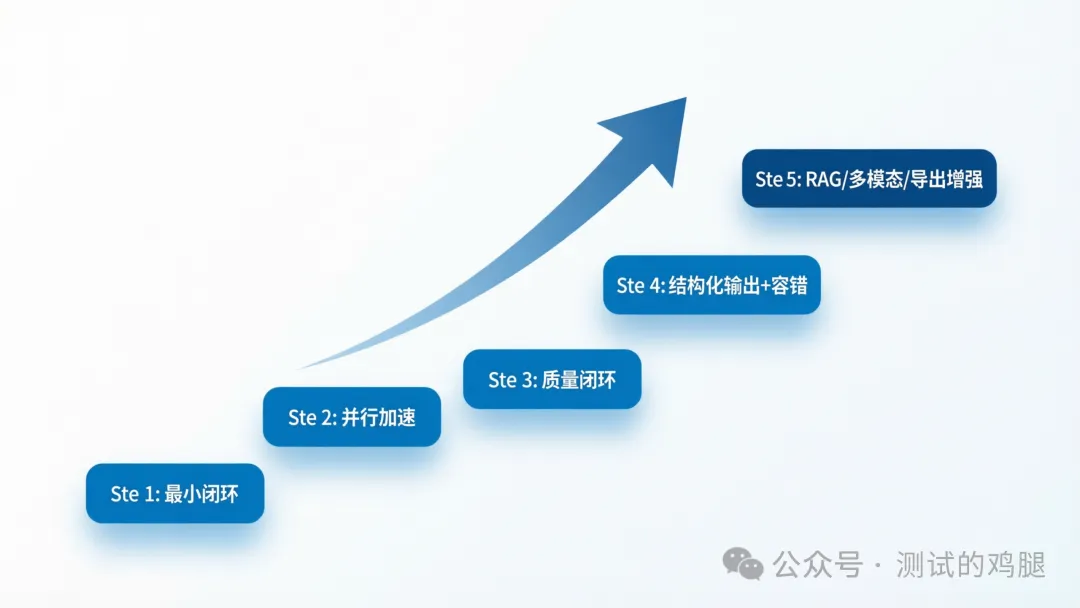
作者建議如果由0開始,應該先做最小閉環:parse_requirement → generate_cases → export_json。然後補並行:split_features + Send API。再補質量:quality_review + 迴流。再補穩定:Pydantic結構化加容錯。最後先上增強:RAG、多模態、XMind、Excel。順序好重要:先可用,再好用,最後先係更強。
- 1 先做最小閉環:解析需求→生成用例→導出JSON
- 2 再補並行:拆分功能點加Send API
- 3 再補質量:質量評審加迴流機制
- 4 再補穩定:Pydantic結構化與容錯
- 5 最後上增強:RAG、多模態、多種導出格式

呢篇比較偏經驗總結,適合你喺團隊入面重複用,亦適合準備做 LLM 工作流項目嘅同學參考。
一、先講結論:LLM 項目能唔能夠落地,決定因素通常唔係「模型勁唔勁」
我做完成套系統最大嘅感受係:
模型能力只係上限,工程設計決定下限。
LLM 工作流項目常見嘅失敗方式唔係「生成唔到」,而係:
- 格式唔穩定:匯出/儲存全部係補丁
- 速度太慢:用戶等唔切
- 品質唔受控:一係全靠運氣,一係無止境重試
- 成本失控:用量一多就爆
- 無法迭代:每次改一個位就要改一大堆 prompt/代碼
下面呢 8 個決策就係我為咗解決呢啲問題而做出嘅取捨。
二、關鍵決策 1:揀 LangGraph StateGraph,唔係純 Agent

我選擇:LangGraph StateGraph
原因:
- 流程係多步驟、強依賴狀態、有條件分支、仲要支援並行
- 我需要顯式可控嘅「節點 + 狀態 + 路由」,而唔係畀 Agent 自由發揮
- 品質閉環入面嘅「閾值迴流」必須硬控制,唔可以畀模型繞過
Trade-off:
- StateGraph 前期碼量較大(你要將每個節點工程化)
- 但係一旦搞掂,穩定性同可維護性會明顯更強
三、關鍵決策 2:用 Send API 做動態並行,而唔係固定併發
我選擇:Send API 動態 Worker
原因:
- 功能點數量係執行時先確定,無得預先寫死 N 個節點
- 並行係提速最有效嘅方法之一:功能點越多,提速越明顯
Trade-off:
- 並行帶嚟狀態合併複雜度(下面嘅 reducer 坑就係咁嚟)
- 但收益巨大:實測 3-5x 提速,用戶體驗明顯提升
四、關鍵決策 3:雙層狀態設計(Global State + Worker State)
我選擇:全局狀態 + Worker 獨立上下文
原因:
- Worker 並行時必須隔離上下文,否則容易互相污染
- 全局狀態用嚟承載「跨節點共享嘅數據」,Worker 狀態只關心「單功能點任務」
Trade-off:
- 狀態模型定義更加複雜,要諗清楚每個欄位屬於邊一層
- 但換嚟嘅係並行可控、邏輯清晰、容易除錯同擴展
五、關鍵決策 4:自定義 reducer,解決「並行追加 + 清空重試」嘅衝突
我選擇:自定義 reducer(add_or_reset_cases)
原因:
- 默認列表合併(operator.add)只會追加,無法表達「清空」
- 品質迴流重試時需要先清空 raw_cases,再接收新一輪輸出
我踩過嘅坑:
- 以為將 raw_cases 設為 [] 就係清空
- 實際上喺 reducer 合併語義下,「空列表」可能只係「乜都唔加」,舊數據仲喺度
Trade-off:
- 自定義 reducer 需要一啲實現成本
- 但呢個係並行系統嘅地基,冇佢重試一定會出問題
六、關鍵決策 5:品質控制用「閾值 + 迴流」,而唔係畀模型自我判斷
我選擇:硬編碼閾值迴流(QUALITY_THRESHOLD=0.85)
原因:
- 「畀模型自評合唔合格」好唔可靠,亦好易畀 prompt 繞過
- 品質閉環必須工程化成明確規則:score 唔夠就回流,而且最多重試 3 次
Trade-off:
- 閾值要調校參數,唔同業務可能唔一樣
- 但佢將品質控制由「玄學」變成「可調嘅工程參數」
七、關鍵決策 6:重試唔係重跑——改進建議注入 + 温度衰減
我選擇:帶回饋嘅迭代最佳化
- 把
improvement_suggestions注入重試上下文 - 將上一輪用例
existing_cases作為參考(強調唔好照抄) - 降低 temperature(0.5 → 0.3),令輸出更加收斂
原因:
- 盲目重試只會增加成本,並唔保證會變好
- 品質閉環嘅本質係「修訂」,而唔係「再創作」
Trade-off:
- Prompt 設計更加複雜
- 但重試次數更少、收斂更快、輸出更穩定
八、關鍵決策 7:多模型協同——將算力用喺最值錢嘅節點上
我選擇:按節點分配模型
- 需求解析/拆分/評審:用強模型
- 批量生成:用性價比模型
- 去重:用輕模型
原因:
- 成本主要來自「高頻調用節點」(generate_cases)
- 效果上限主要來自「方向性節點」(parse/評審)
Trade-off:
- 模型調度邏輯更加複雜
- 但可以做到「效果同成本同時可控」,適合生產化長期運行
九、關鍵決策 8:全鏈路結構化輸出(Pydantic)+ 容錯兜底
我選擇:Pydantic + with_structured_output()
原因:
- 只要產物要匯出 Excel/XMind、要做追溯矩陣,你就必須要有穩定結構
- 結構化輸出令每個節點都好似一個「後端接口」,可測試、可觀測、可重用
我做嘅兜底:
- 模型直接返回陣列時,自動包裝成
{cases: [...]}(model_validator) - 欄位類型漂移(str ↔ list)時,模型層允許、匯出層統一規範化
Trade-off:
- 前期要花時間定義數據模型同校驗邏輯
- 但後期你會省翻大量「解析補丁」嘅時間
十、我踩過嘅 6 個坑(如果你要做類似項目,建議直接收藏)

坑 1:將「生成」當成終點
冇評審同迴流,輸出就係唔穩定嘅。
坑 2:將「並行」當成純效能最佳化
並行會直接改變狀態合併語義,唔處理 reducer 遲早出事。
坑 3:Prompt 越長越好
上下文越長越容易漂。能夠結構化就結構化,能夠摘要就摘要。
坑 4:RAG 強制每次檢索
成本爆炸 + 噪音增多。正確做法係按需檢索、結果摘要後注入。
坑 5:淨係睇單次效果,唔睇分佈
你需要關注嘅係:品質 score 嘅分佈、重試率、平均需時、去重率。
坑 6:匯出放到最後先諗
匯出格式一旦確定,反過來會推動你將數據結構整穩定。越早做越好。
十一、如果叫我由 0 再做一次,我會點樣規劃(建議路線)
- 先做最小閉環:parse_requirement → generate_cases → export_json
- 再補並行:split_features + Send API
- 再補品質:quality_review + 迴流
- 再補穩定:Pydantic 結構化 + 容錯
- 最後先上加強:RAG / 多模態 / XMind / Excel
十二、系列收尾:呢套架構嘅核心價值係咩?
我對呢個項目嘅定位一直好明確:
佢唔係為咗「取代測試」,而係為咗:
- 將經驗固化做流程
- 將品質控制變成規則
- 將交付效率變成可量度指標
如果你喺團隊入面推進 AI 測試落地,我建議你優先做兩件事:
- 將品質閉環做出嚟
- 將結構化輸出做紮實
剩低嘅(RAG、多模態、匯出格式)都係可以迭代加強嘅。

完結彩蛋:你可以點樣繼續擴展?
- 加「測試策略庫」:按業務類型自動選擇覆蓋維度
- 加「接口文檔解析」:自動生成接口測試用例 + 參數邊界
- 加「自動化生成」:將可自動化用例直接輸出到 pytest/playwright 模板
- 加「需求追溯矩陣」更細粒度:Feature → Rule → Case → Automation
如果你希望我將呢套架構代碼化成一套可運行嘅開源模板(包括 Graph、節點、模型、匯出器),都歡迎留言交流。
這篇更偏經驗總結,適合你在團隊內部複用、也適合準備做 LLM 工作流項目的同學參考。
一、先給結論:LLM 項目能不能落地,決定因素通常不是“模型強不強”
我做完這套系統最大的感受是:
模型能力只是上限,工程設計決定下限。
LLM 工作流項目常見的失敗方式不是“生成不出來”,而是:
- 格式不穩:導出/落庫全是補丁
- 速度太慢:用戶等不下去
- 質量不可控:要麼全靠運氣,要麼無休止重試
- 成本失控:調用量一上來就炸
- 無法迭代:每改一個點要改一堆 prompt/代碼
下面 8 個決策就是我為了解決這些問題做出來的取捨。
二、關鍵決策 1:選 LangGraph StateGraph,而不是純 Agent
我選擇:LangGraph StateGraph
原因:
- 流程是多步驟、強依賴狀態、帶條件分支、還要支持並行
- 我需要顯式可控的“節點 + 狀態 + 路由”,而不是讓 Agent 自由發散
- 質量閉環裏的“閾值迴流”必須硬控制,不能被模型繞過
Trade-off:
- StateGraph 前期代碼量更大(你要把每個節點工程化)
- 但一旦搭好,穩定性與可維護性會明顯更強
三、關鍵決策 2:用 Send API 做動態並行,而不是固定併發
我選擇:Send API 動態 Worker
原因:
- 功能點數量是運行時才確定的,無法預先寫死 N 個節點
- 並行是提速最有效的方式之一:功能點越多,提速越明顯
Trade-off:
- 並行帶來狀態合併複雜度(下面的 reducer 坑就是這麼來的)
- 但收益巨大:實測 3-5x 提速,用戶體驗提升明顯
四、關鍵決策 3:雙層狀態設計(Global State + Worker State)
我選擇:全局狀態 + Worker 獨立上下文
原因:
- Worker 並行時必須隔離上下文,否則容易互相污染
- 全局狀態用來承載“跨節點共享的數據”,Worker 狀態只關心“單功能點任務”
Trade-off:
- 狀態模型定義更復雜,要想清楚每個字段屬於哪一層
- 但換來的是並行可控、邏輯清晰、便於調試與擴展
五、關鍵決策 4:自定義 reducer,解決“並行追加 + 清空重試”的衝突
我選擇:自定義 reducer(add_or_reset_cases)
原因:
- 默認列表合併(operator.add)只會追加,無法表達“清空”
- 質量回流重試時需要先清空 raw_cases,再接收新一輪輸出
我踩過的坑:
- 以為把 raw_cases 設為 [] 就是清空
- 實際上在 reducer 合併語義下,“空列表”可能只是“什麼都不加”,舊數據還在
Trade-off:
- 自定義 reducer 需要一些實現成本
- 但這是並行系統的地基,沒它重試必出問題
六、關鍵決策 5:質量控制用“閾值 + 迴流”,而不是讓模型自我判斷
我選擇:硬編碼閾值迴流(QUALITY_THRESHOLD=0.85)
原因:
- “讓模型自評是否合格”非常不可靠,也很容易被 prompt 繞過
- 質量閉環必須工程化成明確規則:score 不夠就回流,且最多重試 3 次
Trade-off:
- 閾值需要調參,不同業務可能不一樣
- 但它把質量控制從“玄學”變成“可調的工程參數”
七、關鍵決策 6:重試不是重跑——改進建議注入 + 温度衰減
我選擇:帶反饋的迭代優化
- 把
improvement_suggestions注入重試上下文 - 把上一輪用例
existing_cases作為參考(強調不要照抄) - 降低 temperature(0.5 → 0.3),讓輸出更收斂
原因:
- 盲目重試只會增加成本,並不能保證變好
- 質量閉環的本質是“修訂”,而不是“再創作”
Trade-off:
- Prompt 設計更復雜
- 但重試次數更少、收斂更快、輸出更穩定
八、關鍵決策 7:多模型協同——把算力用在最值錢的節點上
我選擇:按節點分配模型
- 需求解析/拆分/評審:用強模型
- 批量生成:用性價比模型
- 去重:用輕模型
原因:
- 成本主要來自“高頻調用節點”(generate_cases)
- 效果上限主要來自“方向性節點”(parse/評審)
Trade-off:
- 模型調度邏輯更復雜
- 但可以做到“效果與成本同時可控”,適合生產化長期運行
九、關鍵決策 8:全鏈路結構化輸出(Pydantic)+ 容錯兜底
我選擇:Pydantic + with_structured_output()
原因:
- 只要產物要導出 Excel/XMind、要做追溯矩陣,你就必須要穩定結構
- 結構化輸出讓每個節點都像一個“後端接口”,可測試、可觀測、可複用
我做的兜底:
- 模型直接返回數組時,自動包裝成
{cases: [...]}(model_validator) - 字段類型漂移(str ↔ list)時,模型層允許、導出層統一規範化
Trade-off:
- 前期要花時間定義數據模型與校驗邏輯
- 但後期你會省下大量“解析補丁”的時間
十、我踩過的 6 個坑(如果你要做類似項目,建議直接收藏)
坑 1:把“生成”當成終點
沒有評審與迴流,輸出就是不穩定的。
坑 2:把“並行”當成純性能優化
並行會直接改變狀態合併語義,不處理 reducer 遲早出事。
坑 3:Prompt 越長越好
上下文越長越容易漂。能結構化就結構化,能摘要就摘要。
坑 4:RAG 強制每次檢索
成本爆炸 + 噪聲增多。正確姿勢是按需檢索、結果摘要後注入。
坑 5:只看單次效果,不看分佈
你需要關注的是:質量 score 的分佈、重試率、平均耗時、去重率。
坑 6:導出放到最後才考慮
導出格式一旦確定,反過來會推動你把數據結構做穩定。越早做越好。
十一、如果讓我從 0 再做一次,我會怎麼規劃(建議路線)
- 先做最小閉環:parse_requirement → generate_cases → export_json
- 再補並行:split_features + Send API
- 再補質量:quality_review + 迴流
- 再補穩定:Pydantic 結構化 + 容錯
- 最後再上增強:RAG / 多模態 / XMind / Excel
十二、系列收尾:這套架構的核心價值是什麼?
我對這個項目的定位一直很明確:
它不是為了“替代測試”,而是為了:
- 把經驗固化成流程
- 把質量控制變成規則
- 把交付效率變成可度量指標
如果你在團隊裏推進 AI 測試落地,我建議你優先做兩件事:
- 把質量閉環做出來
- 把結構化輸出做紮實
剩下的(RAG、多模態、導出格式)都是可迭代增強。
完結綵蛋:你可以怎麼繼續擴展?
- 加“測試策略庫”:按業務類型自動選擇覆蓋維度
- 加“接口文檔解析”:自動生成接口測試用例 + 參數邊界
- 加“自動化生成”:把可自動化用例直接輸出到 pytest/playwright 模板
- 加“需求追溯矩陣”更細粒度:Feature → Rule → Case → Automation
如果你希望我把這套架構代碼化成一套可運行的開源模板(含 Graph、節點、模型、導出器),也歡迎留言交流。