多 Agent 協調的五種模式:從最簡單的開始,按需演進
整理版優先睇
多 Agent 協調應該從最簡單模式起步,跟住實際瓶頸逐步演進,唔好一開始就揀最複雜嘅方案。
呢篇文章編譯自 Anthropic 博客,由 Cara Phillips 撰寫,主要探討多 Agent 協調嘅五種模式,同埋點樣按需求演進。作者指出,好多團隊嘅問題係唔知道多 Agent 嘅好處,而係一開頭就揀咗個聽落最型嘅模式,結果被協調開銷拖死。Anthropic 嘅建議係:從最簡單、跑得通嘅模式開始,等佢撐唔住嘅時候再升級。
文章將多 Agent 協調歸納成五種模式:生成-驗證、編排-子 Agent、Agent 團隊、消息總線同共享狀態。每種模式都有適用場景同代價。例如生成-驗證模式最簡單,但驗證標準一定要具體;編排-子 Agent 模式適合任務清晰、子任務之間依賴少嘅情況,但信息瓶頸係主要短板。Agent 團隊模式嘅 worker 係持久嘅,適合需要跨輪積累經驗嘅任務;消息總線模式引入共享通信層,適合事件驅動、不可預測嘅工作流;共享狀態模式冇中央協調者,Agent 自主讀寫共享存儲,適合研究綜合場景。
作者強調,實際生產系統通常會混用多種模式,呢五種模式係積木,唔係互斥選項。最實用嘅做法係從編排-子 Agent 開始,因為佢覆蓋最廣、開銷最低。等遇到瓶頸,再根據具體情況演進到其他模式。文章仲提供咗幾組決策邏輯,例如子任務短小用編排、需要持久上下文用團隊;工作流可預測用編排、事件驅動用消息總線;Agent 之間需要實時溝通用共享狀態等。
- 多 Agent 協調有五種模式:生成-驗證、編排-子 Agent、Agent 團隊、消息總線、共享狀態,由簡到繁。
- 最常見嘅錯誤係一開始就用複雜模式,應該從最簡單嘅開始,等佢撐唔住先演進。
- 生成-驗證模式嘅關鍵係驗證標準一定要具體,否則驗證方會放行所有輸出。
- 編排-子 Agent 模式適合任務清晰但信息瓶頸明顯,子 Agent 之間需要共享發現時要考慮團隊模式。
- 消息總線適合事件驅動工作流,共享狀態適合需要實時共享發現嘅研究場景,兩者都要處理可追溯性同終止條件。
原文:Multi-agent coordination patterns
Anthropic 博客原文,詳細介紹五種協調模式同演進路徑。
由最簡單開始:生成-驗證模式
呢篇文章係編譯自 Anthropic 博客,作者係 Cara Phillips。佢提出一個好重要嘅觀點:大部分團隊嘅問題係唔知道多 Agent 嘅好處,而係一開頭就揀咗個聽落最型嘅模式,結果被協調開銷拖死。Anthropic 嘅建議係從最簡單嘅模式開始,等佢撐唔住嘅時候再演進。
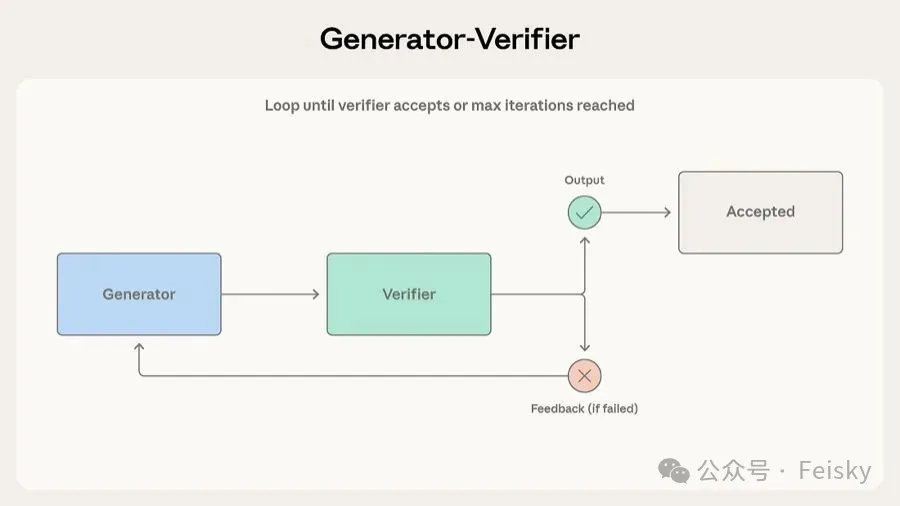
第一個模式係 生成-驗證,亦係部署最廣嘅。一個 Agent 負責生成輸出,另一個負責評估。如果評估通過就結束,唔通過就循環返生成方。最常見嘅應用係 代碼生成:一個寫代碼,另一個寫測試、跑測試。客服場景都啱用,生成方起草回覆,驗證方檢查有冇引用產品文檔。
踩坑位:驗證標準太模糊會令驗證方放行所有輸出,一定要拆成具體、可檢查嘅標準。
另一個問題係迭代可能卡死,生成方解決唔到驗證方提出嘅問題。所以一定要設 最大迭代次數</highlight>,同埋加兜底策略,例如升級畀人處理。
編排-子 Agent 與 Agent 團隊:層級分工同持久 worker
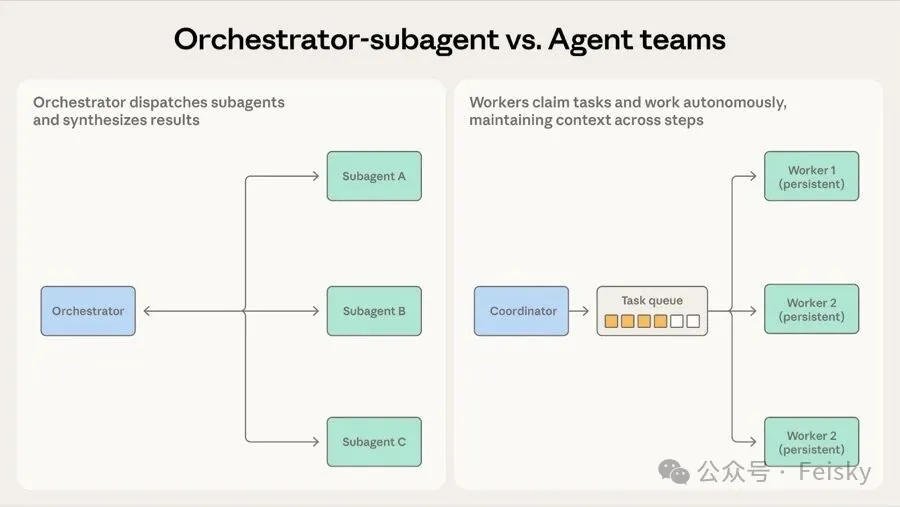
第二個模式係 編排-子 Agent</highlight>,就好似一個 Team Lead 規劃任務、分配工作、彙總結果。Claude Code 就係用呢個模式:主 Agent 自己寫代碼,需要搜索大型代碼庫時就派 subagent 去做。每個 subagent 喺自己嘅上下文窗口工作,完成後將精煉結果返回。
呢個模式嘅主要問題係 信息瓶頸</highlight>:子 Agent 之間嘅信息一定要經編排 Agent 中轉,經過幾輪之後關鍵細節可能會丟失。我哋自己用 Claude Code 嘅 subagent 時都體會到呢點。
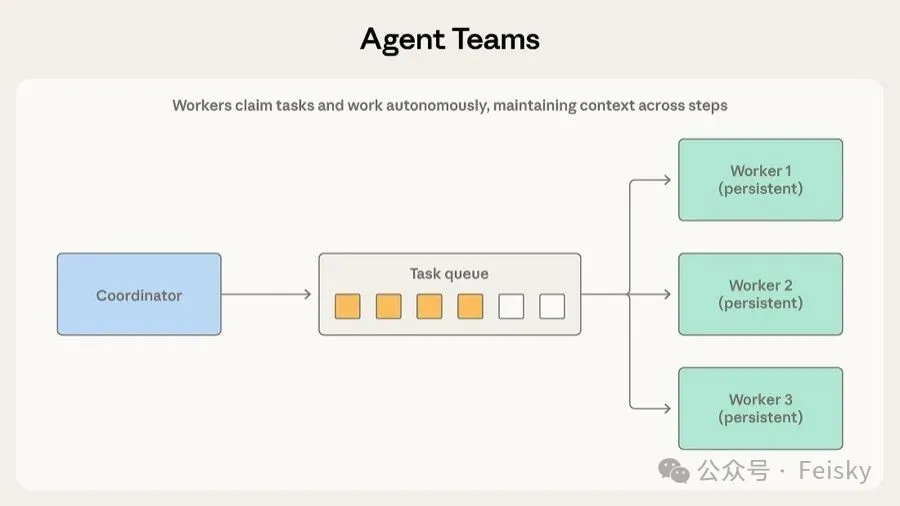
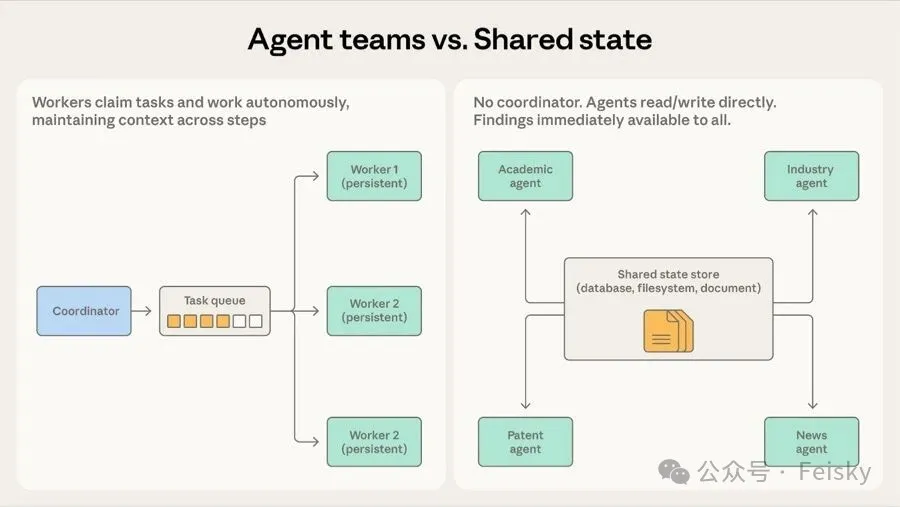
第三個模式係 Agent 團隊</highlight>,同編排模式嘅分別係 worker 係持久嘅,唔會用一次就丟。適合需要多輪迭代積累經驗嘅任務,例如大規模代碼遷移,每個 worker 分管一個服務,反覆處理同一服務時可以重複使用上下文。
- 1 編排模式適合子任務短小、輸出明確嘅情況。
- 2 團隊模式適合子任務需要多步驟持續工作、會從積累上下文受益嘅情況。
- 3 團隊模式嘅代價係 worker 之間冇中間人傳話,改動可能衝突,完成時間參差。
消息總線與共享狀態:事件驅動同去中心化
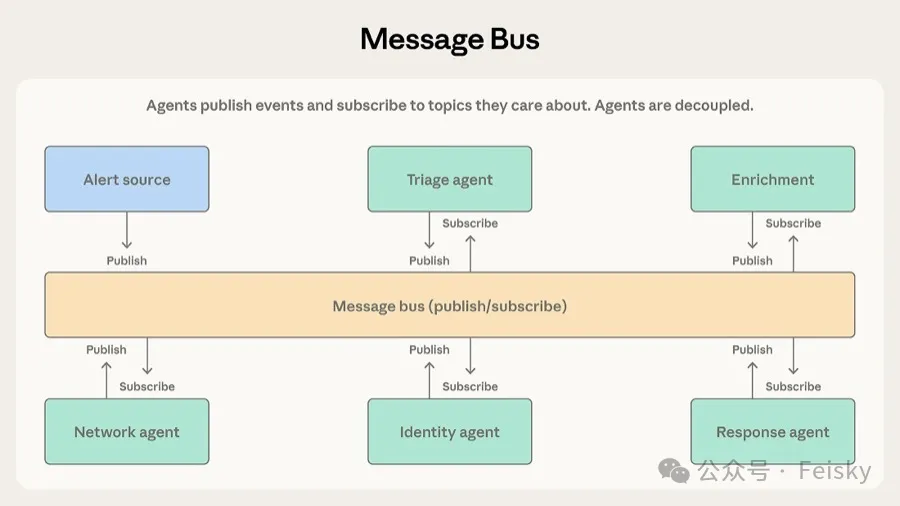
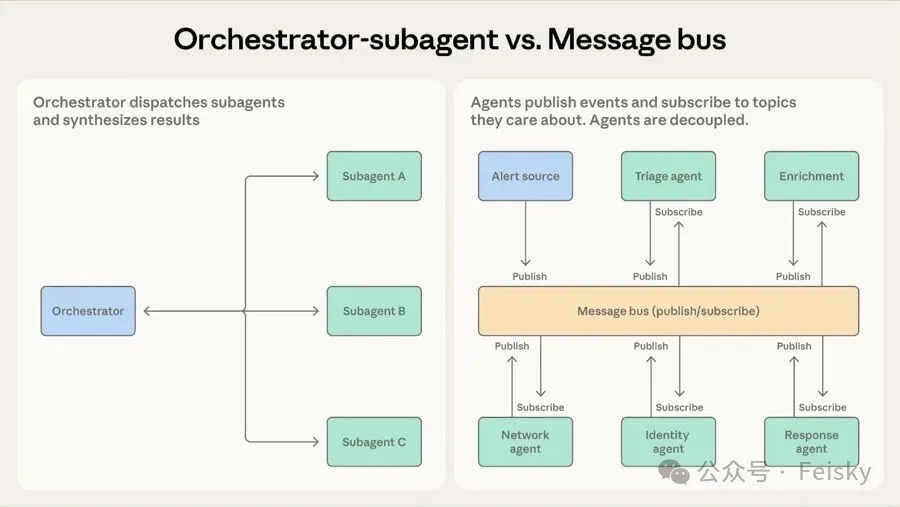
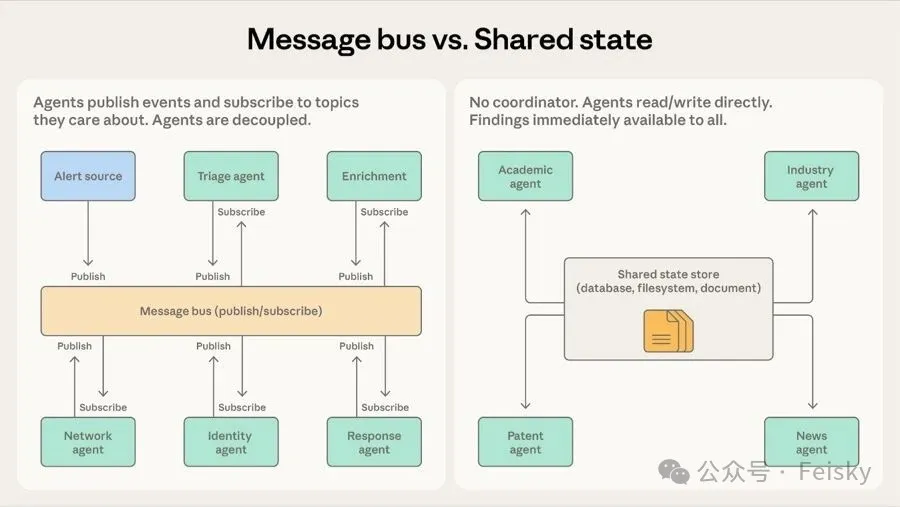
第四個模式係 消息總線</highlight>,引入一個共享通信層,核心操作係發佈同訂閲。Agent 訂閲自己關心嘅 topic,路由器負責分發,新 Agent 上線唔使改已有連接。呢個模式同微服務事件驅動架構好相似,不過參與者從服務變成 Agent。
Anthropic 舉嘅例子係安全運維自動化:告警從多個來源入,分診 Agent 分類後路由畀調查 Agent,調查結果再流向響應協調 Agent。好處係可以獨立開發部署新 Agent,但代價係 可追溯性差</highlight>,調試難度高,而且路由器錯配或丟失事件會靜默失敗。
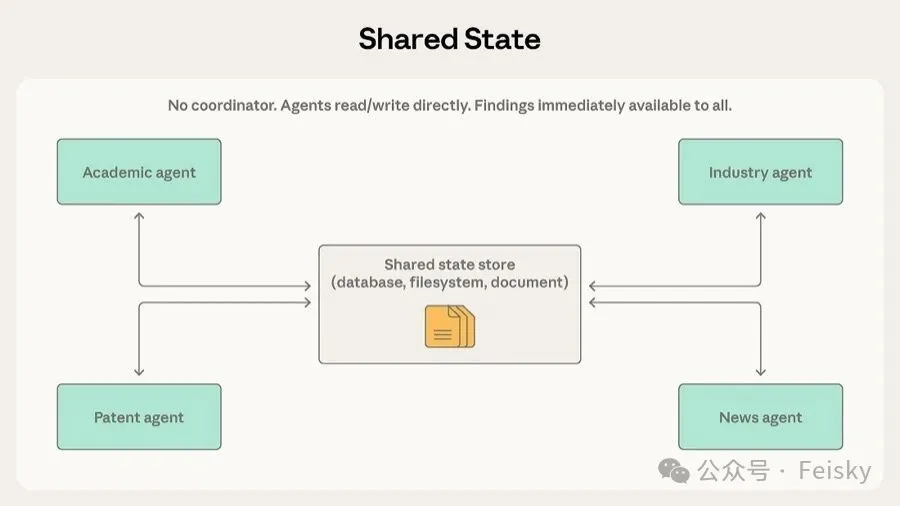
第五個模式係 共享狀態</highlight>,冇中央協調者,Agent 自主運行,讀寫一個共享嘅數據庫或文件系統。研究綜合場景係主場,例如多個 Agent 分頭調查複雜問題嘅唔同方面,發現直接寫入共享存儲,其他 Agent 即刻睇到。好處係冇單點故障,但代價係可能出現 反應式循環</highlight>,Agent 互相回應唔收斂。
- 1 工作流由事件驅動、可能隨發現變化,用消息總線。
- 2 Agent 需要喺持續積累嘅知識基礎上反覆迭代,用共享狀態。
- 3 如果消息總線裏嘅 Agent 發佈事件係為咗分享發現而唔係觸發動作,可能更需要共享狀態。
點樣揀同演進?由編排-子 Agent 開始
Anthropic 畀咗幾組對比決策邏輯,最實用嘅係前兩組。首先,如果子任務短小、輸出明確,用編排模式;如果子任務需要多步驟持續工作、會從積累上下文受益,就用團隊模式。其次,如果步驟順序事先已知,用編排模式;如果工作流由事件驅動、可能隨發現變化,就用消息總線。
經驗法則:當編排 Agent 裏嘅條件分支越來越多、需要處理越來越多特殊情況時,就應該考慮換消息總線。
實際生產系統通常會混用多種模式,例如外層用編排-子 Agent 管整體工作流,內層某個協作密集嘅子任務用共享狀態。Anthropic 建議由編排-子 Agent 開始,因為佢覆蓋最廣、協調開銷最低,等撐唔住時再按瓶頸演進。Claude Code 就係呢個模式嘅典型實現,對大多數日常任務完全夠用。
文章仲提到唔同框架嘅抽象思路:Anthropic 呢套分類偏描述性,LangGraph 用狀態圖定義流轉,CrewAI 角色分工優先。底層要解決嘅問題其實一樣:誰同誰通信、信息點樣流、幾時要停。