多智能體協作指南:五種主流模式怎麼選、怎麼用?【譯】
整理版優先睇
由簡單模式開始,逐步升級:多智能體協作五種模式嘅選擇心得
呢篇文章由Cara Phillips撰寫,翻譯整理咗多智能體協作系統常見嘅五種模式,幫團隊喺揀模式時唔好淨係揀聽落高級嘅,要由最簡單能跑通嘅開始。作者指出好多團隊初期就搞複雜嘅架構,結果浪費資源仲解決唔到問題,所以強調要觀察系統喺邊度遇到瓶頸,再逐步升級。
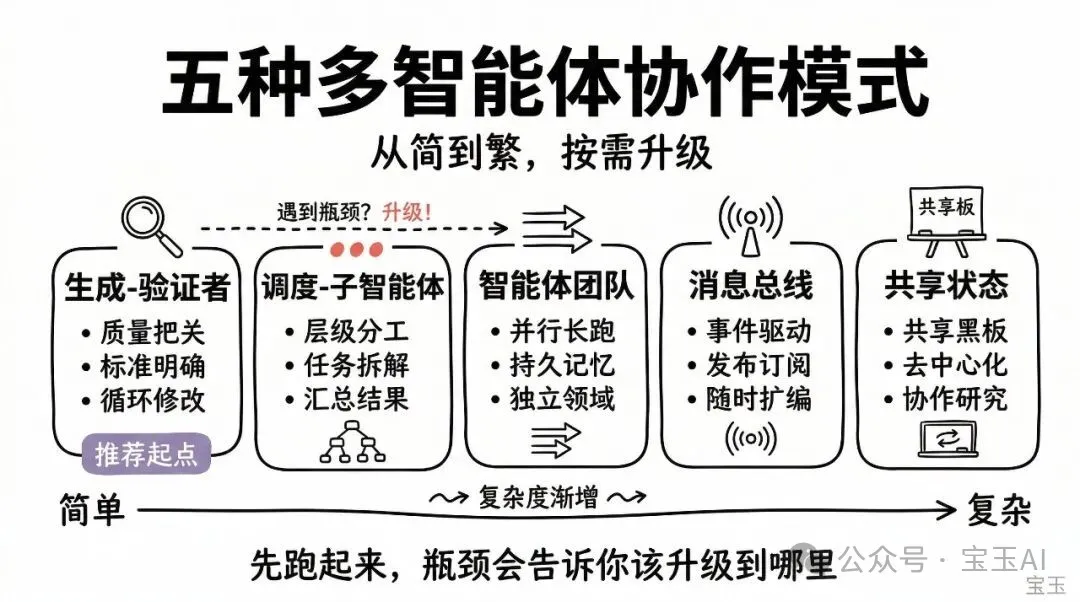
文章詳細介紹咗五種模式:生成-驗證者適合輸出質素高、有明確評估標準嘅場景;調度-子智能體適合任務拆解清晰、子任務邊界分明嘅工作;智能體團隊適合可以並行處理、需要長時間獨立運行嘅子任務;消息總線適合事件驅動嘅流水線同埋需要不斷擴展新智能體嘅系統;共享狀態則適合需要高度協作、智能體之間要互相參考發現嘅場景。呢五種模式最大嘅分別在於點樣劃分上下文邊界同管理信息流。
整體結論係:對於絕大多數初起步嘅需求,強烈建議由調度-子智能體開始,因為佢協調成本低,可以應付最廣泛嘅問題。先用佢跑起來,觀察邊度卡住,再根據具體痛點進化到其他模式。喺真實生產環境,往往會混搭使用呢啲模式,好似大方向用調度,某個需要協作嘅子任務就用共享狀態。
- 揀模式要由最簡單能跑通嘅開始,觀察瓶頸再升級。
- 五種模式各有適用場景:生成-驗證者重質素,調度-子智能體重拆解,智能體團隊重並行,消息總線重事件,共享狀態重協作。
- 模式最大分別在於上下文邊界同信息流管理。
- 新手建議由調度-子智能體開始,因協調成本低。
- 生產環境可以混搭模式,例如大方向用調度,子任務用共享狀態。
Claude Code
Claude Code係一個用調度-子智能體模式嘅工具
構建多智能體系統:何時及如何使用它們
同一作者之前嘅文章
由簡單開始係最穩陣嘅做法
好多團隊揀模式時,淨係揀聽落高級嘅,例如直接上共享狀態或者消息總線,結果搞到系統複雜又難維護。作者建議由最簡單、能跑通嘅模式開始,觀察系統喺邊度遇到瓶頸,再逐步升級。
從最簡單的能跑通的模式開始
逐步升級
呢個原則背後嘅邏輯係:複雜模式嘅成本同風險都好高,如果簡單模式已經夠用,就冇必要增加協調開銷。
- 生成-驗證者:適合輸出質素高、有明確標準嘅場景
- 調度-子智能體:適合任務拆解清晰、子任務邊界分明
- 智能體團隊:適合可以並行、長時間獨立運行嘅子任務
- 消息總線:適合事件驅動、系統持續擴展
- 共享狀態:適合高度協作、需要互相參考發現
生成-驗證者:循環修改直到滿意
生成者接到任務後出一版初步結果,驗證者檢查是否符合標準,唔合格就打返去修改,直至通過或達到最大次數。呢個模式最適合代碼生成、事實核查、合規審查等領域,因為一次錯嘅代價遠大過多次修改。
修改-審核循環
但呢個模式有侷限:佢假設生成同驗證係兩種可拆開嘅技能,但對於評估創意呢類任務,驗證者未必可靠。另外,如果生成者點都解決唔到問題,系統會陷入死衚衕,所以要設定最大循環次數同後備方案。
死衚衕
最大循環次數限制
調度-子智能體 vs 智能體團隊:層級定係平行?
調度-子智能體模式有一個核心智能體做規劃同分配,子智能體各自獨立工作後交結果。佢嘅好處係調度者可以掌控大局,但缺點係容易變成信息瓶頸,而且子智能體順序執行會拖慢速度。
信息瓶頸
順序執行
智能體團隊模式就係協調者創建多個長期存在嘅團隊成員,佢哋從共享任務隊列搶單,自主完成多步操作。成員會積累領域知識,越做越熟練。但獨立係佢嘅生命線都係軟肋,因為彼此好難共享中間進度。
- 調度-子智能體:子任務短平快、輸出明確,適合代碼審查等一次性分析
- 智能體團隊:子任務需要長期獨立處理,適合代碼庫遷移等複雜工作
消息總線 vs 共享狀態:事件驅動定係知識庫?
消息總線透過發佈同訂閲機制協調智能體,路由器將消息推畀相關訂閲者。呢種模式適合事件驅動嘅流水線,而且擴展新智能體好方便,只需訂閲相應話題就得。但排查問題好睏難,而且路由器分錯類會導致靜默崩潰。
發佈訂閲
靜默崩潰
共享狀態模式就徹底唔用中間商,所有智能體直接對住一個公共存儲區讀寫,好似喺黑板前工作。佢消除咗單點故障,但容易出現反應式死循環,即係智能體無限互相回應。
- 消息總線:事件驅動、系統不斷擴展,適合安全營運等流水線
- 共享狀態:高度協作、需要實時共享發現,適合綜合研究系統
- 如果消息總線入面主要係共享情報而唔係觸發動作,應該改用共享狀態
點樣揀同進化:先跑起再優化
揀模式時要問自己幾個核心問題:幹活嘅智能體需要長時間保留記憶嗎?工作流程可以預測嗎?智能體之間需要互相對答案嗎?文章提倡圍繞「上下文」嚟拆解工作,即係按每個智能體需要知道嘅背景嚟分工。
上下文拆解
從調度-子智能體開始
對於絕大多數初起步嘅需求,強烈建議由調度-子智能體開始,因為佢協調成本低,可以應付最廣泛嘅問題。先用佢跑起來,觀察邊度卡住,再根據具體痛點進化。喺生產環境可以混搭模式,例如大方向用調度,子任務用共享狀態。
- 如果系統出現信息瓶頸,考慮轉用消息總線或共享狀態
- 如果子任務需要長期記憶,由調度轉團隊
- 如果工作流由事件觸發,用消息總線取代調度
- 如果智能體需要頻繁互通有無,用共享狀態取代團隊
我哋成日見到,有啲團隊揀模式嘅時候,淨係顧住揀聽落「高大上」嘅,但就忽略咗到底啱唔啱手頭嘅問題。我哋嘅建議係:由最簡單、行得通嘅模式開始,觀察嚇佢喺邊度會遇到瓶頸,然後再逐步升級。 今日呢篇文章,我哋就嚟拆解五種常見模式嘅運作原理同侷限性:
• 生成 - 驗證者 (Generator-verifier):適用於着重輸出質素、而且有明確評估標準嘅場景。 • 調度 - 子智能體 (Orchestrator-subagent):適用於任務拆解清晰、子任務邊界分明嘅場景。 • 智能體團隊 (Agent teams):適用於可以並行處理、互不幹擾而且需要長時間運行嘅子任務。 • 消息總線 (Message bus):適用於事件驅動嘅流水線作業,以及系統仲喺度不斷擴展新智能體嘅場景。 • 共享狀態 (Shared-state):適用於需要高度協作、智能體之間需要互相參考人哋發現嘅場景。
呢個係最簡單嘅多智能體模式,亦係目前落地應用最廣泛嘅模式之一。喺我哋之前嘅文章入面,曾經叫佢做「驗證子智能體模式」,呢度我哋用更闊嘅「生成 - 驗證者」嚟稱呼佢,因為呢度嘅「生成者」唔一定係個指揮全局嘅調度者。
佢係點運作嘅
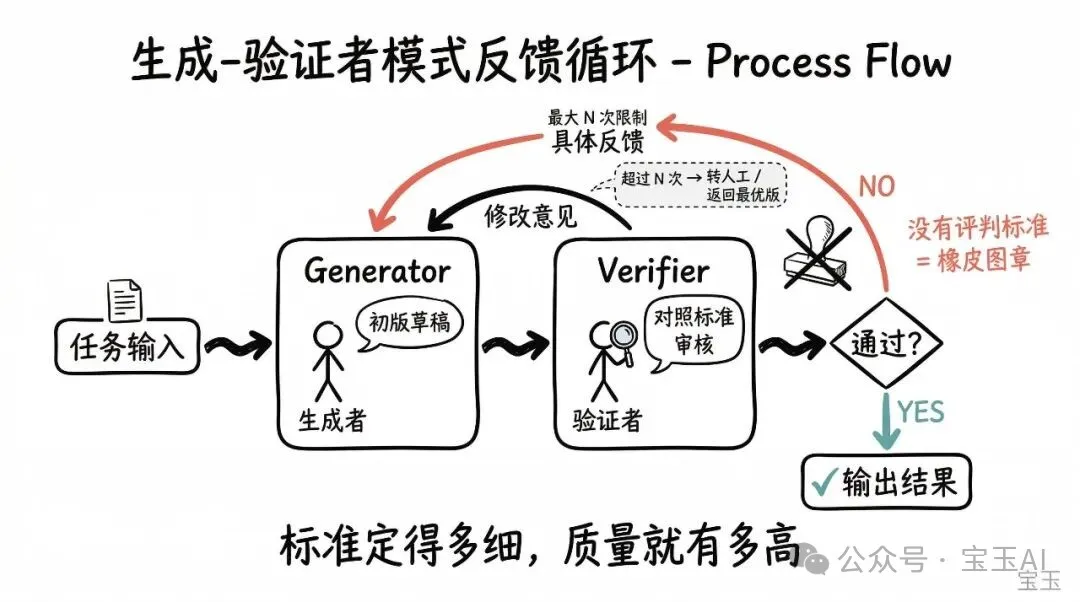
生成者 (Generator) 接到一個任務之後,會先畀出一版初步結果,然後傳俾驗證者 (Verifier) 去評估。驗證者會檢查呢個結果係咪符合規定嘅標準。如果符合,就蓋章通過;如果唔符合,驗證者會將具體嘅修改意見(反饋)打返去。生成者拎住呢啲反饋再重新修改一版。呢個「修改 - 審核」嘅循環會一直進行,直到驗證者滿意,或者達到系統設定嘅最大修改次數限制。
佢喺幾時最好用
想象一個用嚟回覆客戶工單嘅自動電郵系統。生成者利用產品文檔同工單詳情寫出一封初稿。驗證者就充當「質檢員」:核對知識庫睇事實準唔準、檢查語氣符唔符合品牌要求、確認客戶提到嘅每個問題係咪都答咗。如果檢查唔通過,驗證者會將具體問題掟返畀生成者,例如指出「將某個功能錯誤噉歸咗落低配版度」或者「漏答咗某個問題」。
當輸出質素至關重要,而且你能夠將「咩叫好結果」用明確嘅標準寫出嚟嘅時候,用呢個模式實冇錯。佢非常適合代碼生成(一個智能體寫代碼,另一個寫測試同執行)、事實核查、按固定評分表評分、合規性審查,以及任何「一次錯誤嘅代價遠大過多行一圈修改流程」嘅領域。
佢嘅侷限性喺邊
呢個系統嘅下限,完全取決於驗證者嘅審核標準有幾細。(註:如果你淨係叫驗證者「幫我睇嚇呢樣嘢好唔好」,但係唔畀佢具體嘅條條框框,佢往往就會變成一個冚埋眼蓋「合格」章嘅橡皮圖章。) 團隊應用呢個模式嘅時候最常犯嘅錯誤,就係整好咗循環機制,但冇定義清楚「驗證」到底係乜意思,只係營造出一種「我哋做緊品質控制」嘅虛假繁榮。
另外,呢種模式假設「生成」同「驗證」係兩種可以拆開嘅技能。但如果你要評估嘅係一個絕妙嘅創意,評估佢嘅難度可能同諗出佢一樣高,咁樣驗證者通常就唔係咁可靠。
最後,呢種循環好容易陷入「死衚衕」。如果生成者點都解決唔到驗證者提出嘅問題,系統就會喺兩者之間來回踢波,永遠無法收斂。因此,必須設定一個最大循環次數限制,並準備好後備方案(例如轉交人工,或者帶埋提示說明返回當前最好嗰版),防止佢變成死循環。
模式二:調度 - 子智能體 (Orchestrator-subagent)
呢個模式嘅核心在於「層級制」。有一個好似「團隊主管」噉嘅核心智能體負責規劃工作、分發任務,同最終滙總結果;而各個子智能體 (Subagents) 就負責處理具體嘅分攤工作,做完之後向上級滙報。
佢係點運作嘅
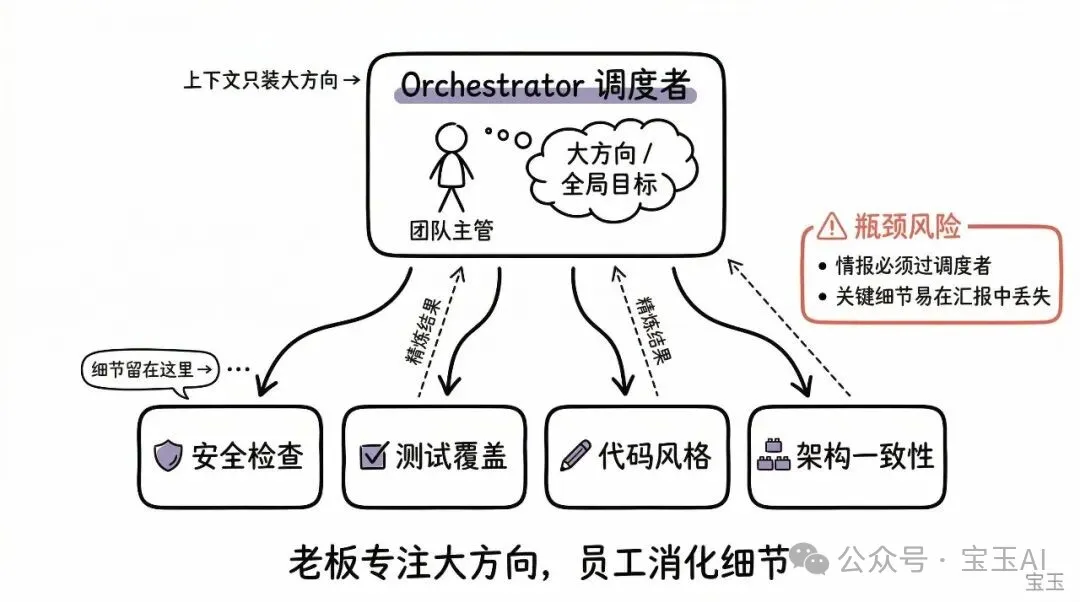
主導嘅調度者 (Orchestrator) 收到任務之後,會先思考應該點樣動手。佢可以自己解決一部分,將剩低嘅指派畀唔同嘅子智能體。等小弟哋做完嘢、交上結果之後,調度者再將呢啲碎片拼成一份完整嘅最終答案。
Claude Code[1] 就係用呢種模式。主智能體自己負責寫代碼、改文件、執行指令,但當佢需要喺龐大嘅代碼庫裏面大範圍搜尋,或者需要調查一啲獨立問題嘅時候,佢就會喺後台派發俾子智能體。咁樣主線工作唔會停,搜尋結果亦會源源不絕噉送返嚟。每個子智能體都喺自己獨立嘅上下文窗口 (Context window) 入面工作,只係返回精煉咗嘅調查結果。(註:呢個就好似老細嘅腦(上下文)只需要專注於大方向,而查資料等繁雜資訊喺員工嘅大腦入面消化,從而保證老細嘅思路唔會被瑣事塞滿。)
佢喺幾時最好用
諗嚇一個自動化嘅代碼審查 (Code review) 系統。當有人提交咗新代碼,系統需要檢查安全漏洞、驗證測試覆蓋率、評估代碼風格、並檢查架構一致性。呢幾個檢查方向互不干涉,需要嘅背景知識唔同,而且都可以產出清晰嘅報告。嗰陣時,調度者就可以將任務分發俾幾個專門嘅子智能體,等佢哋查完,再將報告融合成一份全面嘅審查意見。
當任務拆解非常明確,而且子任務之間互相冇乜依賴嘅時候,呢個模式非常得心應手。調度者能夠時刻保持對大目標嘅掌控,而子智能體就心無旁騖噉做好自己嘅細分工作。
佢嘅侷限性喺邊
調度者好容易變成資訊嘅「瓶頸」。一旦某個子智能體發現咗可能會影響另一個子智能體工作嘅資訊,呢個情報必須先上報俾調度者,再由調度者下發。例如,查安全嘅智能體發現咗一個認證漏洞,呢個漏洞啱好會影響查架構嘅智能體嘅分析。如果資訊喺上下級之間倒手太多次,關鍵細節好容易就會喺被一次次「總結滙報」嘅過程入面丟失。
另外,如果唔做專門嘅並行處理,子智能體會按順序一個一個噉做嘢。呢個意味住你要畀住多智能體處理數據(Token)嘅錢,但享受唔到「人多做得快」嘅速度優勢。
模式三:智能體團隊 (Agent teams)
當一份大工作可以拆成多個並行嘅子任務,而且呢啲任務需要好耐時間獨立完成嗰陣,「組長派工」嘅層級制就會顯得太死板喇。
佢係點運作嘅
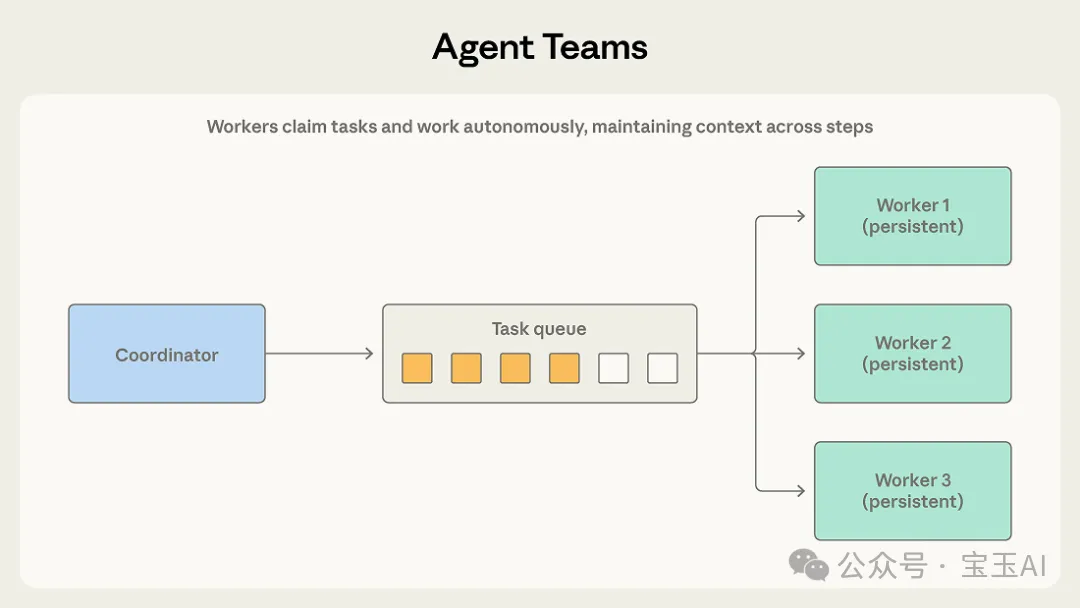
一個協調者 (Coordinator) 會創建出多個作為獨立進程運行嘅團隊成員 (Teammates)。呢啲成員會由一個共享嘅任務隊列度自己「搶單」,接單之後自主完成多步操作,做完就舉手示意。
佢同「調度 - 子智能體」最大嘅分別在於成員嘅持久性。調度者通常係為咗一件小事臨時叫出一個子智能體,做完就解散。但係喺團隊模式入面,成員係長期存在嘅,佢哋喺接手一個個任務嘅過程入面,會不斷累積領域知識同上下文,越做越熟練。協調者只係負責派工同收功課,並唔會喺每次任務結束之後將佢哋嘅記憶清空。
佢喺幾時最好用
假設你要將一個龐大嘅代碼庫由一個框架遷移到另一個框架。每個團隊成員都可以獨立負責遷移其中一個服務模組,自己處理依賴項、改代碼、修測試 bug、做驗證。協調者將一個個模組分俾成員,成員自主完成呢一整套遷移流程。最後協調者將所有遷移好嘅模組集埋一齊,執行一次系統級嘅整合測試。
當子任務相互獨立,而且需要跨越多步、長時間處理嘅時候,用呢個模式最爽。因為每個成員都喺不斷累積自己嗰個細領域嘅經驗,而唔係每次接工都好似個失憶嘅新手。
佢嘅侷限性喺邊
「獨立」係呢個模式嘅生命線,亦係死穴。唔似調度模式入面有個組長幫手傳話,團隊成員都係靜靜雞做自己嘢嘅,彼此之間好難共享中間進度。如果 A 嘅工作會影響到 B,但佢哋兩個毫不知情,最後交上嚟嘅結果就可能會打交。
進度管理都係一個令人頭痛嘅問題。因為大家做嘢嘅時間長短唔同,有啲兩分鐘搞掂,有啲要搞二十分鐘,協調者必須要有耐性處理呢種「參差不齊」嘅部分完成狀態。
如果大家仲要爭奪公共資源,問題就更大。當多個成員同時喺改同一個代碼庫、資料庫或檔案嗰陣,好容易發生兩個人改同一個檔案或者做出互相衝突嘅修改。呢個要求我哋喺任務分配嗰陣劃好「楚河漢界」,並準備好衝突解決機制。
模式四:消息總線 (Message bus)
隨住智能體數量增加,大家互動嘅方式越來越複雜,直接叫佢哋面對面交流會變成一場災難。嗰陣時,消息總線 (Message bus) 就登場喇:佢提供咗一個共享嘅通訊大廳,畀智能體透過「發佈」同「訂閲」嚟協調工作。
佢係點運作嘅
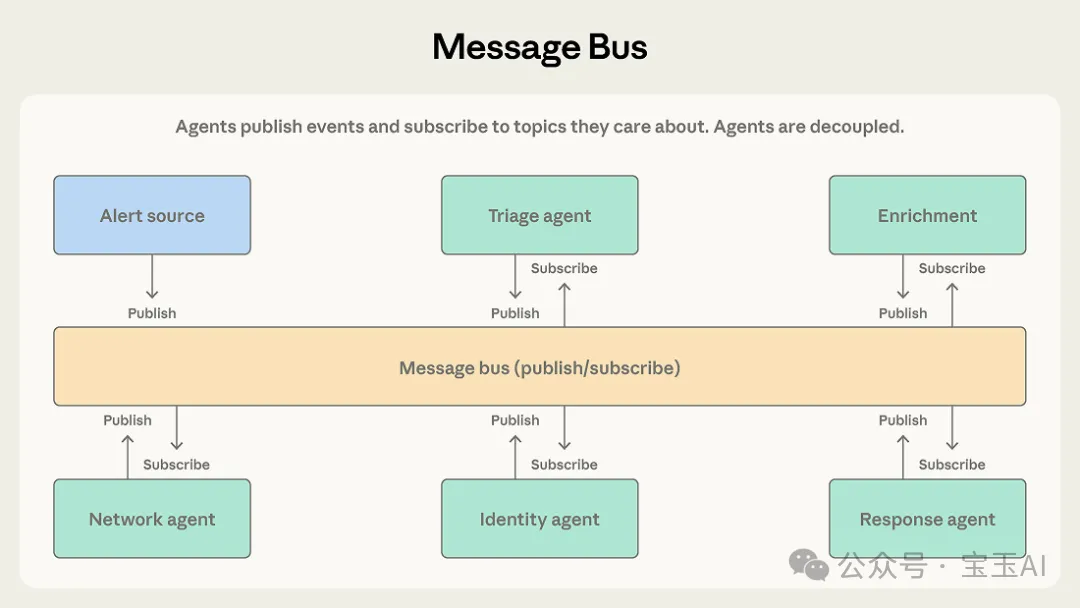
智能體只靠兩個基本動作交流:發佈 (Publish) 同訂閲 (Subscribe)。智能體會訂閲自己關心嘅「話題」,一個路由器 (Router) 會將相關嘅消息精準推俾佢哋。(註:呢個就好似喺一個大型公司 Group 入面,有人喺 Group 度發需求,相關部門嘅人見到就會自動領走,你根本唔需要知具體係邊個接咗單。) 如果第時有新功能嘅智能體加入,佢哋只要訂閲相應嘅話題就可以直接上崗,完全唔需要改動現有嘅網絡線路。
佢喺幾時最好用
自動化安全營運系統係呢個模式嘅完美舞台。各種渠道嘅警報好似雪片噉飛嚟,一個「分診智能體」負責評估嚴重程度同類型,將高危嘅網絡警報推俾「網絡調查智能體」,將帳號相關警報推俾「身份分析智能體」。調查智能體喺做嘢嘅時候,可能會發佈一條「需要更多背景」嘅需求,專門負責收集情報嘅智能體見到之後就會去幫手。最後,所有嘅發現都會流向「響應協調智能體」,由佢嚟決定點樣處理。
呢種流水線簡直就係為消息總線度身訂造:事件由上一個環節順暢噉流向下個環節;隨住新型威脅出現,團隊可以隨時塞新嘅安保智能體入去;各個智能體嘅開發同部署亦可以互不幹擾。
當系統係一個由事件驅動嘅流水線(工作流程係由突發事件決定嘅,唔係定死嘅順序),而且你嘅智能體團隊未來好可能會繼續擴編嗰陣時,揀佢。
佢嘅侷限性喺邊
呢種事件驅動嘅通訊過於靈活,導致排查問題非常困難。當一個警報好似骨牌效應噉觸發咗五個智能體嘅連鎖反應嗰陣,想搞清楚中間到底發生咗乜,你一定要查閲非常詳細嘅日誌記錄並進行關聯比對。呢個比起跟住「調度者」一步步按順序查 bug 痛苦得多。
路由器嘅分發準確性都至關重要。如果路由器將消息分錯咗類,或者直情漏發咗,系統就會陷入「靜默崩潰」——佢唔報錯,冇死機,但就係乜都唔做。基於大語言模型 (LLM) 嘅路由器雖然能夠喺理解語義上更靈活,但同時帶嚟咗 LLM 特有嘅失靈風險(例如理解偏差或幻覺)。
模式五:共享狀態 (Shared state)
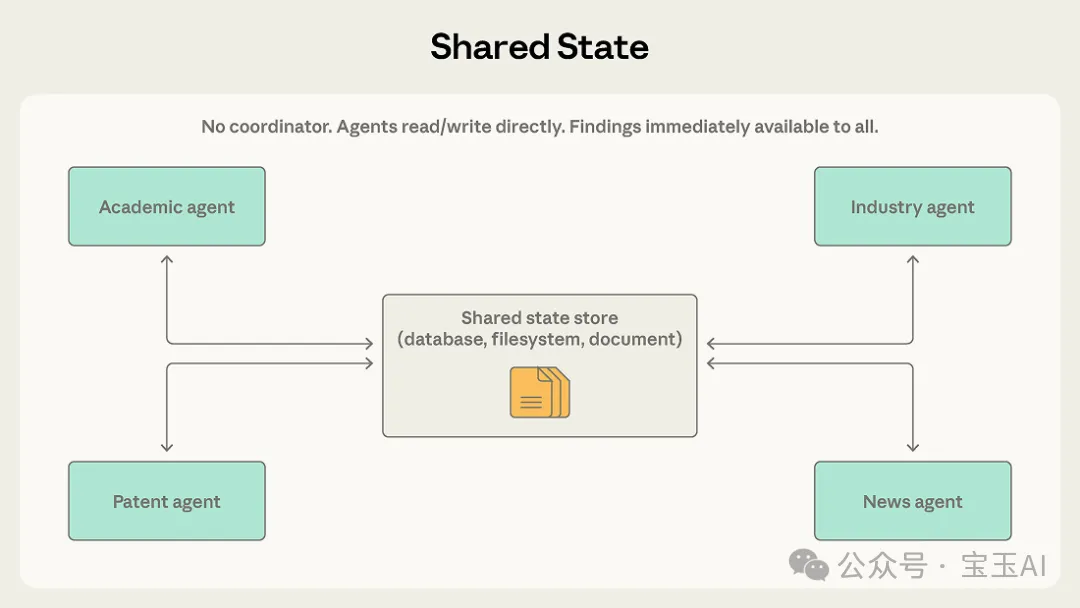
喺前幾種模式入面,無論係調度者、協調者定係路由器,本質上都係充當資訊流嘅「中間商」。而共享狀態 (Shared state) 模式就徹底斬咗中間商,佢畀所有智能體共同面對一個持久化嘅儲存區(例如資料庫、檔案系統或文件),大家可以直接從中讀取資訊、寫入結果。
佢係點運作嘅
喺呢個模式下,冇所謂嘅「中心指揮官」。智能體好似喺一個公共嘅大黑板前做嘢:佢哋睇住黑板上有咩線索,攞走自己能處理嘅去做,有新發現就寫返上黑板。通常,啟動流程就係喺黑板上寫低一個大問題或放低一堆初始數據;當滿足某個結束條件嘅時候,工作就停止——例如時間到咗、大家好耐冇新發現(收斂閾值),或者某個被專門指派嘅智能體出嚟話「黑板上嘅答案已經夠好」。
佢喺幾時最好用
想象一個負責跨領域綜合研究嘅系統。為咗調查一個複雜問題,有啲智能體負責睇學術論文,有啲睇行業報告,有啲摷專利文件,仲有啲睇住新聞動態。每個人查到嘅嘢都可能成為其他人嘅關鍵線索。例如,睇論文嘅智能體偶然發現咗一位核心研究員,睇行業報告嘅智能體即刻就可以去深挖呢位研究員背後嘅公司。
喺共享狀態下,所有嘅發現都直接上黑板。睇行業嘅智能體即刻就可以見到睇論文智能體嘅新發現,完全唔使等協調者嚟回傳話。大家互相踩住對方嘅膊頭向上爬,呢塊共享黑板就會慢慢變成一個不斷進化演進嘅知識庫。
呢種模式仲有一個好處:消除咗單點故障。就算某個智能體死咗機,其他人依然可以對住黑板繼續讀寫。但喺調度模式或消息總線模式入面,一旦指揮官或路由器罷工,整個系統就全癱瘓曬。
佢嘅侷限性喺邊
冇咗統一指揮,智能體好容易會重複做同一樣嘢,或者南轅北轍。例如兩個智能體可能唔約而同噉去調查咗同一條線索。系統嘅最終行為係大家碰撞出嚟嘅,唔係由上而下設計好嘅,呢個令結果變得難以預測。
最致命嘅故障模式係陷入 「反應式死循環」 (Reactive loops)。例如,智能體 A 寫低咗一個發現,智能體 B 見到之後寫咗一句補充,A 見到補充之後又回咗一句…… 成個系統就好似兩個機械人喺度無限套娃傾偈,瘋狂燃燒昂貴嘅算力 (Token) 但無法得出結論。針對重複工作同並發寫入,工程師有成熟嘅解決辦法(例如加鎖、版本控制、分區);但呢種「無限套娃」係一個行為模式問題,你一定要喺系統設計之初就設定好「一票否決」嘅終止條件:例如只係畀固定嘅時間預算,或者一旦連續幾輪都冇新發現就強制停止,或者指派一個「裁判」智能體隨時判定答案係咪已經圓滿。(註:如果忽略咗停止機制嘅設計,系統要唔係會無限循環到破產,要唔係會因為某個智能體嘅大腦(上下文窗口)被塞滿而死機。)
點樣喺唔同模式之間選擇同進化
揀邊種模式,取決於你對系統嘅幾個核心結構問題嘅判斷。喺我哋之前嘅文章入面,我哋提倡圍繞「上下文」嚟拆解工作(Context-centric decomposition),即係按照每個智能體「需要知道邊啲背景資訊」嚟分工,而唔係按「佢做邊類型嘅工作」嚟分工。呢個原則喺呢度一樣適用。呢五種模式最大嘅分別,就係在於佢哋點樣劃分上下文嘅邊界,同埋點樣管理資訊嘅流動。
調度 - 子智能體 vs. 智能體團隊
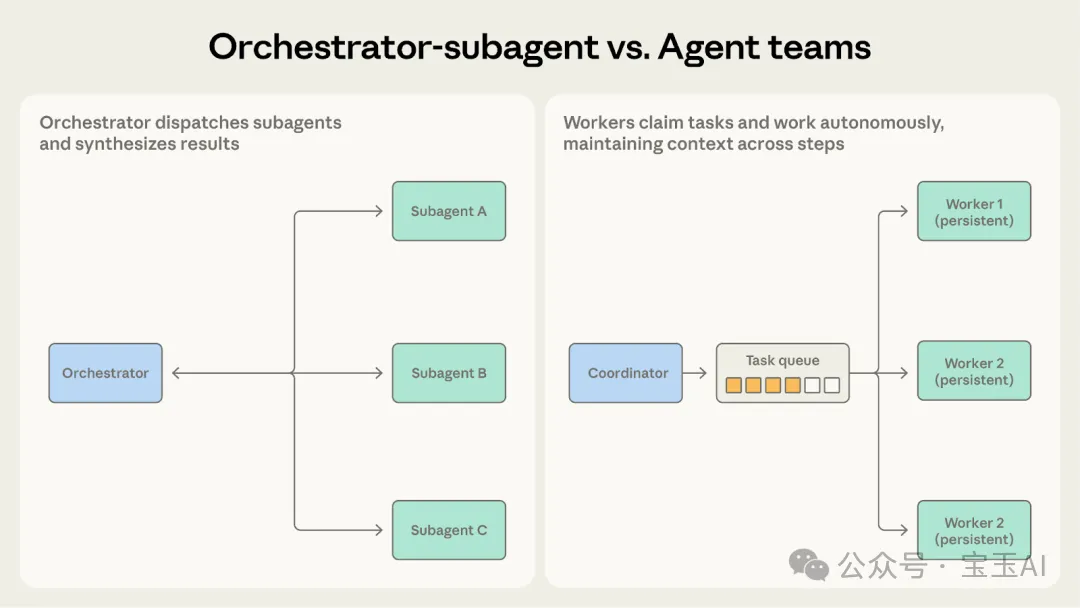
兩者都有一個「分配工作」嘅協調者。點樣揀?問自己:做嘢嘅智能體需要長時間保留記憶(上下文)嗎?
• 揀調度 - 子智能體:如果子任務短平快,目標集中,而且輸出明確。代碼審查系統就適用,因為每次檢查都係一次性嘅:行分析、出報告,直接交差。子智能體唔需要喺多次任務之間保留記憶。 • 揀智能體團隊:如果子任務需要跨越多步、長時間處理先至有成效。代碼庫遷移適用呢個,因為成員需要長期對付同一個服務模組,慢慢摸熟佢嘅依賴關係、測試規律同部署配置。呢啲累積落嚟嘅背景知識,係「用完即走」嘅調度模式畀唔到嘅。
當子智能體需要喺多次被喚醒之間記住以前嘅狀態嗰陣,智能體團隊係更好嘅選擇。
調度 - 子智能體 vs. 消息總線
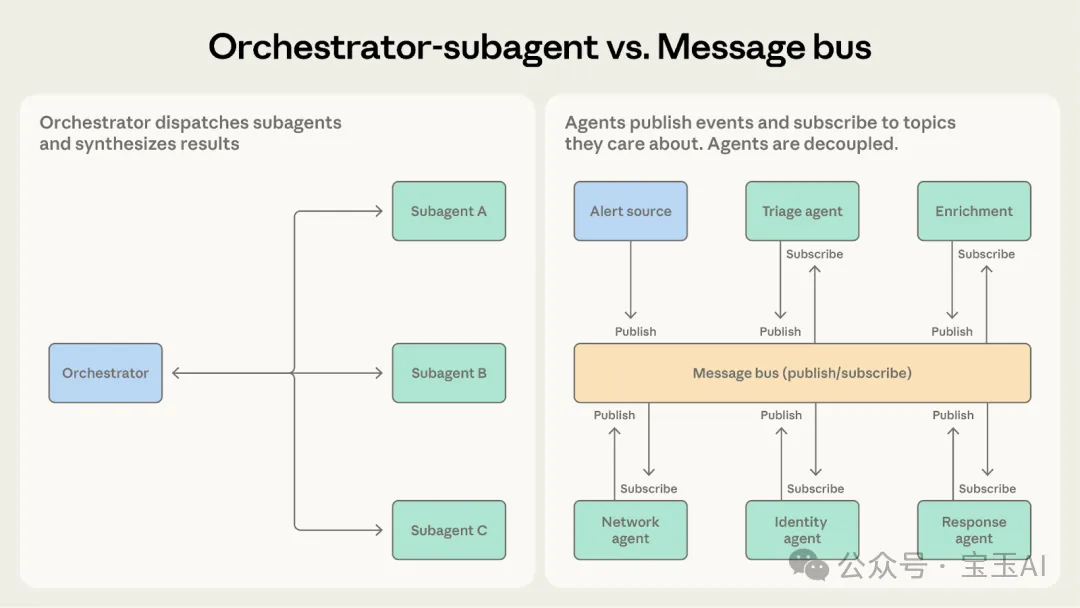
兩者都能夠處理多步工作流程。點樣揀?問自己:你嘅工作流程係咪可以提前預測?
• 揀調度 - 子智能體:如果步驟早就定好咗。就好似代碼審查系統,永遠係嗰三板斧:接收提交請求、行檢查、滙總結果。 • 揀消息總線:如果工作流程係由突發事件觸發,而且隨時有可能改變方向。安全營運系統永遠估唔到下一秒會嚟咩警報,或者需要開展咩調查。佢甚至要隨時容納新類型嘅警報。消息總線透過將事件推畀能做嘢嘅智能體嚟適應呢種變數,而唔係死守預設嘅劇本。
如果為咗應付越來越多嘅特殊情況,你嘅「調度者」腦入面嘅「If-Else」判斷語句越堆越多,咁就係時候換成消息總線,等分發機制變得更加清晰同容易擴展。
智能體團隊 vs. 共享狀態
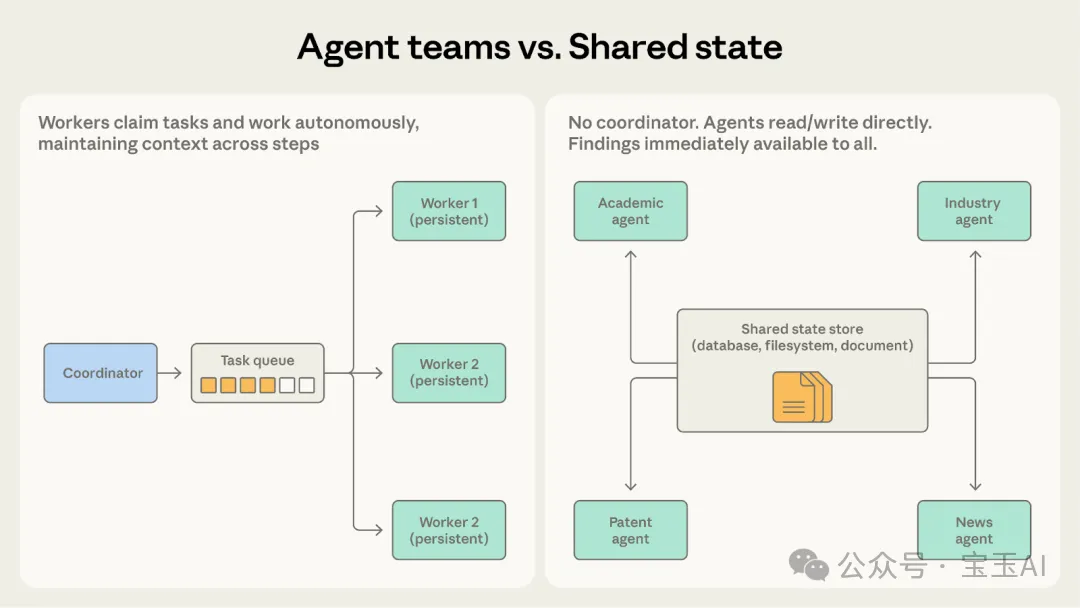
兩者入面嘅智能體都係自主做嘢。點樣揀?問自己:智能體之間需要互相對答案、抄功課嗎?
• 揀智能體團隊:如果大家各家自掃門前雪,互不干涉。代碼庫遷移中,每個人負責自己嘅服務,最後統一合併就得。 • 揀共享狀態:如果呢個係一個需要高度協作嘅任務,而且線索需要即時流轉。綜合研究系統就好啱,睇論文嘅智能體只要有新發現,睇行業嘅智能體即刻就可以用得上。
一旦團隊成員唔再淨係交差嗰陣滙總結果,而係需要喺做緊嘢途中頻繁互通消息,噉就快啲換成共享狀態模式啦,佢會令交流順暢好多。
消息總線 vs. 共享狀態
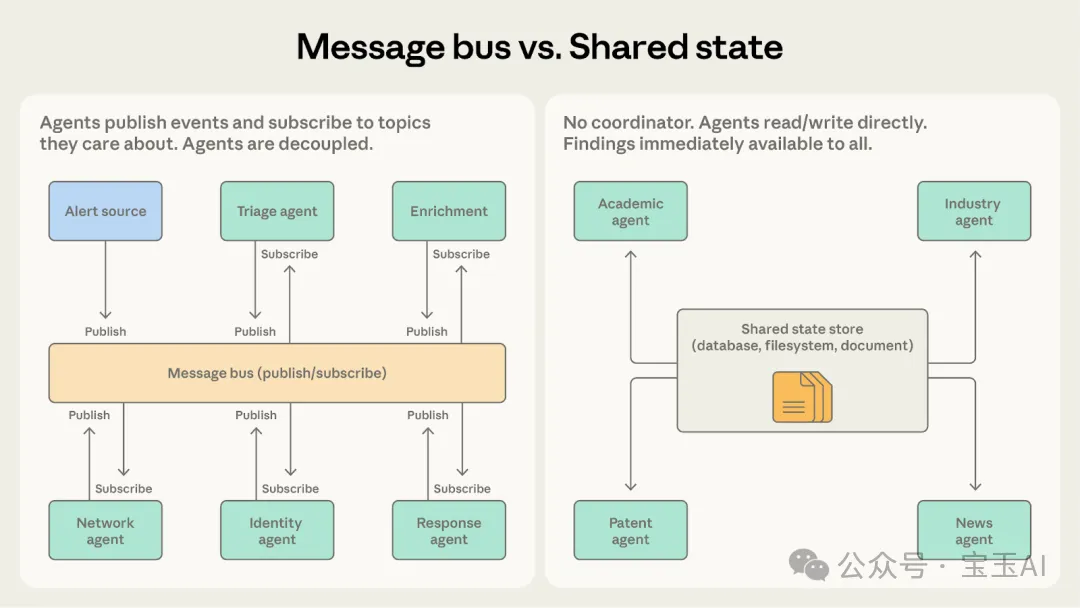
兩者都擅長處理複雜嘅多智能體協作。點樣揀?問自己:任務係好似流水線噉一個一個解決事件,定係為咗慢慢儲出一個知識庫?
• 揀消息總線:如果智能體係對流水線上嘅事件做出反應。安全系統就係一環扣一環,處理完上一步先觸發下一步。呢個模式對「精準派工」非常在行。 • 揀共享狀態:如果智能體係要基於日積月累嘅線索持續深入。綜合研究系統係喺不斷匯聚知識。智能體會反覆返去黑板前面,睇嚇人哋發現咗乜,然後調整自己嘅調查方向。
記住,消息總線入面依然有個「路由器」喺中心掌控全局決定邊個接工。而共享狀態係徹頭徹尾嘅去中心化。如果你非常在意消除「單點故障」,共享狀態能夠畀到你最大嘅安全感。
另外,如果你嘅消息總線系統入面,大家發佈消息主要只係為咗「共享情報」而唔係為咗「觸發別人嘅動作」,咁就說明你揀錯咗,呢個情況更啱用共享狀態模式。

新手指南
喺真實嘅商業環境(生產環境)入面,我哋通常會混搭使用呢啲模式。一種常見嘅組合係:大方向嘅工作流程用調度 - 子智能體,而喺某個需要大量協作嘅子任務入面就用共享狀態。仲有啲系統會用消息總線嚟分發事件,而喺處理每類事件嘅末端掛上一個一個智能體團隊。呢啲模式本質上係積木,並唔係水火不容。
下表總結咗各種模式嘅適用場景:
對於絕大多數啱啱起步嘅需求,我哋強烈建議由「調度 - 子智能體 (Orchestrator-subagent)」開始。 佢能夠以極低嘅協調成本搞掂最廣泛嘅問題。先用佢行起嚟,觀察系統喺邊度卡住,然後再根據具體痛點進化到其他模式。
喺跟住落嚟嘅文章入面,我哋會結合生產級別嘅實際案例,深入探討每種模式嘅具體落地做法。如果你想回顧「我哋到底幾時先值得投入多智能體系統」,請參考:《構建多智能體系統:何時及如何使用它們》[2]。
致謝
本文由 Cara Phillips 撰寫,Eugene Yang, Jiri De Jonghe, Samuel Weller 以及 Erik Schluntz 亦有貢獻。
引用連結
[1] Claude Code: https://code.claude.com/docs/en/overview[2] 《構建多智能體系統:何時及如何使用它們》: https://claude.com/blog/building-multi-agent-systems-when-and-how-to-use-them
我們常常看到,有些團隊在挑選模式時,只顧着選聽起來“高大上”的,卻忽略了到底適不適合手頭的問題。我們的建議是:從最簡單的、能跑通的模式開始,觀察它在哪裏會遇到瓶頸,然後再逐步升級。 今天這篇文章,我們就來拆解五種常見模式的運作原理和侷限性:
• 生成 - 驗證者 (Generator-verifier):適用於看重輸出質量、且有明確評估標準的場景。 • 調度 - 子智能體 (Orchestrator-subagent):適用於任務拆解清晰、子任務邊界分明的場景。 • 智能體團隊 (Agent teams):適用於可以並行處理、互不干擾且需要長時間運行的子任務。 • 消息總線 (Message bus):適用於事件驅動的流水線作業,以及系統還在不斷擴展新智能體的場景。 • 共享狀態 (Shared-state):適用於需要高度協作、智能體之間需要互相參考別人發現的場景。
這是最簡單的多智能體模式,也是目前落地應用最廣泛的模式之一。在我們之前的文章中,曾將其稱為“驗證子智能體模式”,這裏我們使用更寬泛的“生成 - 驗證者”來稱呼它,因為這裏的“生成者”不一定非得是個指揮全局的調度者。
它是如何運作的
生成者 (Generator) 接到一個任務後,會先給出一版初步結果,然後把它傳給驗證者 (Verifier) 去評估。驗證者會檢查這個結果是否符合規定的標準。如果符合,就蓋章通過;如果不符合,驗證者會把具體的修改意見(反饋)打回去。生成者拿着這些反饋再重新修改一版。這個“修改 - 審核”的循環會一直進行,直到驗證者滿意,或者達到了系統設定的最大修改次數限制。
它在何時最好用
想象一個用來回復客戶工單的自動郵件系統。生成者利用產品文檔和工單詳情寫出一封初稿。驗證者則充當“質檢員”:核對知識庫看事實準不準、檢查語氣符不符合品牌要求、確認客戶提到的每個問題是不是都回答了。如果檢查沒通過,驗證者會把具體問題甩回給生成者,比如指出“把某個功能錯誤地歸到了低配版裏”或者“漏答了某個問題”。
當輸出質量至關重要,而且你能把“什麼是好結果”用明確的標準寫出來時,用這個模式準沒錯。它非常適合代碼生成(一個智能體寫代碼,另一個寫測試並運行)、事實核查、按固定評分表打分、合規性審查,以及任何“一次錯誤的代價遠大於多跑一圈修改流程”的領域。
它的侷限性在哪
這個系統的下限,完全取決於驗證者的審核標準有多細。(注:如果你只告訴驗證者“幫我看看這東西好不好”,卻不給它具體的條條框框,它往往就會變成一個閉着眼睛蓋“合格”章的橡皮圖章。) 團隊在應用這個模式時最常犯的錯誤,就是建好了循環機制,卻沒定義清楚“驗證”到底意味着什麼,這隻會營造出一種“我們在做質量控制”的虛假繁榮。
另外,這種模式假設“生成”和“驗證”是兩種可以拆開的技能。但如果你要評估的是一個絕妙的創意,評估它的難度可能和想出它一樣高,這時候驗證者往往就不太靠譜了。
最後,這種循環很容易陷入“死衚衕”。如果生成者就是無法解決驗證者提出的問題,系統就會在兩者之間來回踢皮球,永遠無法收斂。因此,必須設置一個最大循環次數限制,並準備好後備方案(比如轉交人工,或者帶着提示說明返回當前最好的一版),防止它變成死循環。
模式二:調度 - 子智能體 (Orchestrator-subagent)
這個模式的核心在於“層級制”。有一個像“團隊主管”一樣的核心智能體負責規劃工作、分發任務,並最終彙總結果;而各個子智能體 (Subagents) 則負責處理具體的分攤工作,做完後向上級彙報。
它是如何運作的
主導的調度者 (Orchestrator) 收到任務後,會先思考該怎麼動手。它可以自己解決一部分,把剩下的指派給不同的子智能體。等小弟們把活幹完、交上結果後,調度者再把這些碎片拼成一份完整的最終答案。
Claude Code[1] 用的就是這種模式。主智能體自己負責寫代碼、改文件、跑命令,但當它需要在龐大的代碼庫裏大範圍搜索,或者需要調查一些獨立問題時,它就會在後台派發給子智能體。這樣主線工作不會停,搜索結果也會源源不斷地送回來。每個子智能體都在自己獨立的上下文窗口 (Context window) 裏工作,只返回精煉後的調查結果。(注:這就好比老闆的腦子(上下文)只需專注於大方向,而查資料等繁雜信息都在員工的大腦裏消化,從而保證老闆的思路不被瑣事塞滿。)
它在何時最好用
想想一個自動化的代碼審查 (Code review) 系統。當有人提交了新代碼,系統需要檢查安全漏洞、驗證測試覆蓋率、評估代碼風格、並檢查架構一致性。這幾個檢查方向互不干涉,需要的背景知識也不同,並且都能產出清晰的報告。此時,調度者就可以把任務分發給幾個專門的子智能體,等它們查完,再把報告融合成一份全面的審查意見。
當任務拆解非常明確,且子任務之間互相沒啥依賴時,這個模式非常得心應手。調度者能時刻保持對大目標的掌控,而子智能體則心無旁騖地幹好自己的細分工作。
它的侷限性在哪
調度者很容易變成信息的“瓶頸”。一旦某個子智能體發現了可能影響另一個子智能體工作的信息,這個情報必須先上報給調度者,再由調度者下發。比如,查安全的智能體發現了一個認證漏洞,這個漏洞恰好會影響查架構的智能體的分析。如果信息在上下級之間倒手太多次,關鍵細節很容易就在被一次次“總結匯報”的過程中弄丟了。
另外,如果不做專門的並行處理,子智能體會按順序一個個幹活。這意味着你要花着多智能體處理數據(Token)的錢,卻享受不到“人多幹活快”的速度優勢。
模式三:智能體團隊 (Agent teams)
當一份大工作可以被拆成多個並行的子任務,而且這些任務需要花很長時間獨立完成時,“組長派活”的層級制就會顯得太死板了。
它是如何運作的
一個協調者 (Coordinator) 會創建出多個作為獨立進程運行的團隊成員 (Teammates)。這些成員會從一個共享的任務隊列裏自己“搶單”,接單後自主完成多步操作,幹完再舉手示意。
它和“調度 - 子智能體”最大的區別在於成員的持久性。調度者通常是為了一件小事臨時叫出一個子智能體,幹完就解散。但在團隊模式裏,成員們是長期存在的,它們在接手一個個任務的過程中,會不斷積累領域知識和上下文,越幹越熟練。協調者只管派活和收作業,並不會在每次任務結束後把它們的記憶清空。
它在何時最好用
假設你要把一個龐大的代碼庫從一個框架遷移到另一個框架。每個團隊成員都可以獨立負責遷移其中一個服務模塊,自己處理依賴項、改代碼、修測試 bug、做驗證。協調者把一個個模塊分給成員,成員們自主完成這一整套遷移流程。最後協調者把所有遷移好的模塊攢在一起,跑一遍系統級的集成測試。
當子任務相互獨立,且需要跨越多步、長時間處理時,用這個模式最爽。因為每個成員都在不斷積累自己那個小領域的經驗,而不是每次接活都像個失憶的新手。
它的侷限性在哪
“獨立”是這個模式的生命線,也是軟肋。不像調度模式裏有個組長幫忙傳話,團隊成員們都是悶頭幹活的,彼此之間很難共享中間進度。如果 A 的工作會影響到 B,他們倆卻毫不知情,最後交上來的結果可能就打架了。
進度管理也是個讓人頭疼的問題。因為大家幹活的時間長短不一,有的兩分鐘搞定,有的要弄二十分鐘,協調者必須得有耐心處理這種“參差不齊”的部分完成狀態。
如果大家還要搶奪公共資源,問題就更大了。當多個成員同時在改同一個代碼庫、數據庫或文件時,很容易發生兩個人改同一個文件或者做出互相沖突的修改。這就要求我們在任務分配時劃好“楚河漢界”,並準備好衝突解決機制。
模式四:消息總線 (Message bus)
隨着智能體數量增加,大家互動的方式越來越複雜,直接讓他們面對面交流會變成一場災難。這時候,消息總線 (Message bus) 就登場了:它提供了一個共享的通訊大廳,讓智能體們通過“發佈”和“訂閲”來協調工作。
它是如何運作的
智能體只靠兩個基本動作交流:發佈 (Publish) 和訂閲 (Subscribe)。智能體會訂閲自己關心的“話題”,一個路由器 (Router) 會把相關的消息精準推給它們。(注:這就好比在一個大型公司羣裏,有人在羣裏發需求,相關部門的人看到了自動領走,你根本不需要知道具體是誰接了單。) 如果未來有了新功能的智能體加入,它們只要訂閲相應的話題就能直接上崗,完全不需要改動現有的網絡線路。
它在何時最好用
自動化安全運營系統是這個模式的完美舞台。各種渠道的警報像雪片一樣飛來,一個“分診智能體”負責評估嚴重程度和類型,把高危的網絡警報推給“網絡調查智能體”,把賬號相關警報推給“身份分析智能體”。調查智能體在幹活時,可能還會發布一條“需要更多背景”的需求,專門負責收集情報的智能體看到後就會去幫忙。最後,所有的發現都會流向“響應協調智能體”,由它來拍板怎麼處理。
這種流水線簡直就是為消息總線量身定製的:事件從上一個環節順暢地流向下個環節;隨着新型威脅出現,團隊可以隨時往裏塞新的安保智能體;各個智能體的開發和部署也可以互不干擾。
當系統是一個由事件驅動的流水線(工作流是由突發事件決定的,而不是定死的順序),而且你的智能體團隊未來很可能會繼續擴編時,選它。
它的侷限性在哪
這種事件驅動的通訊過於靈活,導致排查問題非常困難。當一個警報像多米諾骨牌一樣觸發了五個智能體的連鎖反應時,想搞清楚中間到底發生了什麼,你必須查閲非常仔細的日誌記錄並進行關聯對比。這可比跟着“調度者”一步步按順序查 bug 痛苦多了。
路由器的分發準確性也至關重要。如果路由器把消息分錯了類,或者乾脆漏發了,系統就會陷入“靜默崩潰”——它不報錯,沒死機,但就是什麼也不幹。基於大語言模型 (LLM) 的路由器雖然能在理解語義上更靈活,但也帶來了 LLM 特有的失靈風險(比如理解偏差或幻覺)。
模式五:共享狀態 (Shared state)
在前幾種模式裏,無論是調度者、協調者還是路由器,本質上都在充當信息流的“中間商”。而共享狀態 (Shared state) 模式則徹底幹掉了中間商,它讓所有智能體共同面對一個持久化的存儲區(比如數據庫、文件系統或文檔),大家可以直接從中讀取信息、寫入結果。
它是如何運作的
在這個模式下,沒有所謂的“中心指揮官”。智能體們像在一個公共的大黑板前工作:他們看着黑板上有什麼線索,拿走自己能處理的去幹活,有了新發現再寫回黑板上。通常,啓動流程就是在黑板上寫下一個大問題或放下一堆初始數據;當滿足某個結束條件時,工作就停止——比如時間到了、大家很久沒新發現了(收斂閾值),或者某個被專門指派的智能體站出來說“黑板上的答案已經足夠好了”。
它在何時最好用
想象一個負責跨領域綜合研究的系統。為了調查一個複雜問題,有的智能體負責翻學術論文,有的看行業報告,有的扒專利文件,還有的盯着新聞動態。每個人查到的東西都可能成為別人的關鍵線索。比如,看論文的智能體偶然發現了一位核心研究員,看行業報告的智能體立馬就可以去深挖這家研究員背後的公司。
在共享狀態下,所有的發現都直接上黑板。看行業的智能體立馬就能看到看論文智能體的新發現,根本不用等協調者來回傳話。大家互相踩着對方的肩膀往上爬,這塊共享黑板也就漸漸變成了一個不斷進化演進的知識庫。
這種模式還有一個好處:消除了單點故障。即便某個智能體宕機了,其他人依然能對着黑板繼續讀寫。但在調度模式或消息總線模式裏,一旦指揮官或路由器罷工,整個系統就全癱瘓了。
它的侷限性在哪
失去了統一指揮,智能體很容易會重複造輪子,或者南轅北轍。比如兩個智能體可能不約而同地去調查了同一條線索。系統的最終行為是大家碰撞出來的,而不是從上往下設計好的,這也讓結果變得難以預測。
最致命的故障模式是陷入 “反應式死循環” (Reactive loops)。比如,智能體 A 寫下了一個發現,智能體 B 看到後寫了一句補充,A 看到補充後又回了一句…… 整個系統就像兩個機器人在無限套娃聊天,瘋狂燃燒昂貴的算力 (Token) 卻無法得出結論。針對重複工作和併發寫入,工程師們有成熟的解決辦法(比如加鎖、版本控制、分區);但這這種“無限套娃”是一個行為模式問題,你必須在系統設計之初就設定好“一票否決”的終止條件:比如只給固定的時間預算,或者一旦連續幾輪都沒有新發現就強制停止,或者指派一個“裁判”智能體隨時判定答案是否已經圓滿。(注:如果忽略了停止機制的設計,系統要麼會無限循環到破產,要麼會因為某個智能體的大腦(上下文窗口)被塞滿而死機。)
如何在不同模式間選擇與進化
選哪種模式,取決於你對系統的幾個核心結構問題的判斷。在我們之前的文章中,我們提倡圍繞“上下文”來拆解工作(Context-centric decomposition),即按照每個智能體“需要知道哪些背景信息”來分工,而不是按“它幹什麼類型的活”來分工。這個原則在這裏同樣適用。這五種模式最大的區別,就在於它們如何劃分上下文的邊界,以及如何管理信息的流動。
調度 - 子智能體 vs. 智能體團隊
兩者都有一個“分配工作”的協調者。怎麼選?問自己:幹活的智能體需要長時間保留記憶(上下文)嗎?
• 選調度 - 子智能體:如果子任務短平快,目標集中,且輸出明確。代碼審查系統就適用,因為每次檢查都是單次的:跑分析、出報告,直接交差。子智能體不需要在多次任務間保留記憶。 • 選智能體團隊:如果子任務需要跨越多步、長時間處理才能出成效。代碼庫遷移適用這個,因為成員們需要長期對付同一個服務模塊,慢慢摸透它的依賴關係、測試規律和部署配置。這種積累下來的背景知識,是“用完即走”的調度模式給不了的。
當子智能體需要在多次被喚醒之間記住以前的狀態時,智能體團隊是更好的選擇。
調度 - 子智能體 vs. 消息總線
兩者都能處理多步工作流。怎麼選?問自己:你的工作流程是可以提前預測的嗎?
• 選調度 - 子智能體:如果步驟早就定好了。就像代碼審查系統,永遠是那三板斧:接收提交請求、跑檢查、彙總結果。 • 選消息總線:如果工作流是由突發事件觸發的,而且隨時可能改變方向。安全運營系統永遠猜不到下一秒會來什麼警報,或者需要開展什麼調查。它甚至需要隨時容納新類型的警報。消息總線通過把事件推給能幹活的智能體來適應這種變數,而不是死守着預設的劇本。
如果為了應付越來越多的特殊情況,你的“調度者”腦子裏的“If-Else”判斷語句越堆越多,那麼是時候換成消息總線,讓分發機制變得更加清晰和容易擴展了。
智能體團隊 vs. 共享狀態
兩者裏的智能體都是自主幹活的。怎麼選?問自己:智能體之間需要互相對答案、抄作業嗎?
• 選智能體團隊:如果大家各人自掃門前雪,互不干涉。代碼庫遷移中,每個人負責自己的服務,最後統一合併就行。 • 選共享狀態:如果這是一場需要高度協作的任務,且線索需要實時流轉。綜合研究系統就很合適,看論文的智能體只要有新發現,看行業的智能體立馬就能用上。
一旦團隊成員們不再僅僅是交差時彙總結果,而是需要在幹活途中頻繁互通有無,那趕緊換成共享狀態模式吧,它會讓交流順暢得多。
消息總線 vs. 共享狀態
兩者都擅長處理複雜的多智能體協作。怎麼選?問自己:任務是像流水線一樣一個個解決事件,還是為了慢慢攢出一個知識庫?
• 選消息總線:如果智能體是對流水線上的事件做出反應。安全系統就是一環扣一環,處理完上一步才觸發下一步。這個模式對“精準派活”非常在行。 • 選共享狀態:如果智能體是要基於日積月累的線索持續深入。綜合研究系統是在不斷匯聚知識。智能體們會反覆回到黑板前,看看別人發現了什麼,然後調整自己的調查方向。
記住,消息總線裏依然有個“路由器”在中心掌控全局決定誰接活。而共享狀態是徹頭徹尾的去中心化。如果你非常在意消除“單點故障”,共享狀態能給你最大的安全感。
另外,如果你的消息總線系統裏,大家發佈消息主要只是為了“共享情報”而不是為了“觸發別人的動作”,那說明你選錯了,這活兒更適合共享狀態模式。
新手指南
在真實的商業環境(生產環境)中,我們往往會混搭使用這些模式。一種常見的組合是:大方向的工作流用調度 - 子智能體,而在某個需要大量協作的子任務裏套用共享狀態。還有的系統會用消息總線來分發事件,而在處理每類事件的末端掛上一個個智能體團隊。這些模式本質上是積木,並非水火不容。
下表總結了各種模式的適用場景:
對於絕大多數剛剛起步的需求,我們強烈建議從“調度 - 子智能體 (Orchestrator-subagent)”開始。 它能以極低的協調成本搞定最廣泛的問題。先用它跑起來,觀察系統在哪裏卡了脖子,然後再根據具體痛點進化到其他模式。
在接下來的文章中,我們將結合生產級別的實際案例,深入探討每種模式的具體落地做法。如果你想回顧“我們到底什麼時候值得投入多智能體系統”,請參閲:《構建多智能體系統:何時及如何使用它們》[2]。
致謝
本文由 Cara Phillips 撰寫,Eugene Yang, Jiri De Jonghe, Samuel Weller 以及 Erik Schluntz 亦有貢獻。
引用連結
[1] Claude Code: https://code.claude.com/docs/en/overview[2] 《構建多智能體系統:何時及如何使用它們》: https://claude.com/blog/building-multi-agent-systems-when-and-how-to-use-them