大多數公司空有數據,卻毫無記憶 接再多的AI,它也幹不了活
整理版優先睇
公司缺嘅唔係數據,係記憶;Agent接唔到一間唔記得自己點解咁做決定嘅公司
呢篇文章出自 Sentra 聯合創辦人 Ashwin Gopinath,佢係前 MIT 教授,寫過 AI Agent 自我修正嘅論文 Reflexion。Sentra 今年初拎咗 500 萬美元種子輪,由 a16z 旗下 Speedrun 領投。佢想解決嘅問題係:好多公司狂裝 AI Agent,但 Agent 接住嘅係一間唔記得自己點解咁做決定嘅公司——CRM 有曬成交紀錄,但「點解當年咁定價」完全冇人知。佢嘅結論係:公司最大嘅護城河唔再係數據,而係「記得自己點解咁做」嘅判斷鏈;數據可以買、可以爬,但判斷鏈係公司自己嘅歷史,冇得複製。
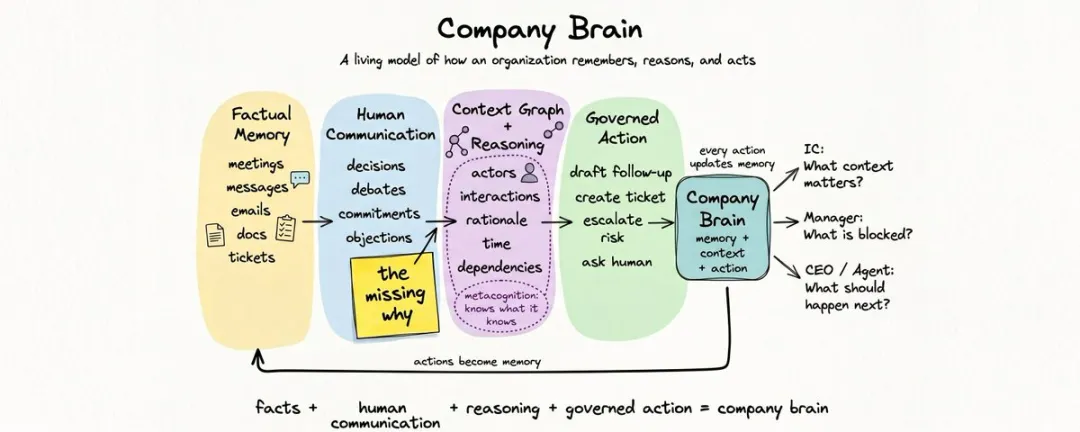
Ashwin 將公司大腦定義為「一個活的模型,模擬組織點樣記憶、推理同行動」,分三層:事實層(記錄發生過嘅事)、上下文層(串起「點解會咁」嘅關係)、行動層(根據上下文協調下一步)。佢批評現有工具——會議記錄、企業搜索、工作流、Agent 工具——都只係覆蓋一個角落,冇辦法做到「由上下文決定做乜」。佢提出公式:事實記憶 + 人類對話 + 上下文圖 + 受控行動 = 公司大腦。
文章指出,老公司只能靠「攢」——將現有工具嘅碎片串埋;而新公司應該由頭就將會議、決策、Agent 動作沉到同一個底子。Ashwin 仲提出一個哲學框架叫 System 3:集體認知層,超越 Kahneman 嘅 System 1(直覺)同 System 2(推理)。佢認為公司大腦就係呢一層嘅載體,而呢個時機成熟係因…
- 公司失敗嘅原因唔係缺數據,係缺記憶——數據只能話畀你「發生過乜」,但唔會話畀你「點解咁決定」。
- Ashwin 提出三層結構:事實層(記錄來源、權限、時間戳)、上下文層(串起關係,仲要識得「知道自己唔靠譜」)、行動層(自動協調下一步)。
- 現有工具(會議記錄、企業搜索、工作流、Agent)都只係做到一部分,公司大腦係四個圓嘅交集點:要同時處理「發生乜」「點解會咁」「下一步點做」「上下文喺邊」。
- 公式:事實記憶 + 人類對話 + 上下文圖 + 受控行動 = 公司大腦;少一樣就會變咗只係檔案、轉錄、猜測或者脆自動化。
- 老公司要「攢」、新公司要「長」——由頭就將記憶、推理、行動當成操作系統一部分;先做嘅公司有先發優勢,因為判斷鏈係唯一買唔到嘅護城河。
公司唔係因為缺數據失敗,係因為缺記憶
Ashwin 用佢個女 Satakshi 嘅成長做比喻:嬰兒唔係讀說明書學嘢,係觀察「跌咗落去會點」嚟記住預期。公司都係咁——每日產生大量碎片:會議、Slack、郵件、工單,但問題係公司「儲碎片嘅速度」快過「將碎片變成記憶嘅速度」。
記憶唔係檔案,記憶係「下次再遇到嘅時候,大概知道點樣搞掂」
組織記憶研究早喺 1991 年就有定義:能用在當下決策上嘅過去信息,先算得上記憶。公司能跑得掂,從來唔係靠 CRM 啲字段,而係靠 Sarah 記得點解呢個客堅持要 SSO、靠 Ravi 記得 onboarding 當時卡咗喺邊。呢種「跨 active memory」——團隊入面互相知道邊個識乜——係公司真正嘅運行機制。
- CRM 記錄咗價格同簽單日期,但當年「點解咁定價」嘅會議冇人寫低;銷售副總、產品同事、創辦人嘅判斷,隨住人走就消失。
- Agent 接住嘅係 Sarah 留低嘅幾百條 Slack message、十幾篇未寫完嘅文檔,但永遠唔會知點解咁決定。
三層結構:事實、上下文、行動
Ashwin 定義公司大腦係「一個活嘅模型,帶權限,模擬組織點樣記憶、推理同行動」,對應三層。第一層係事實層:記錄曬公司發生過嘅事,每條帶來源、權限、時間戳。佢強調呢層唔係 RAG,而係 semantic file system——唔單止存文件,仲要存文件之間嘅關係。
事實層只係骨架,公司唔靠骨架運轉,靠嘅係「被解釋過嘅事實」
第二層係上下文層:將零散事實串成「點解會咁」嘅關係網。客嘅一個電話連到銷售機會,機會連到產品缺口,缺口連到工程取捨,取捨連到路線圖決策,決策連到戰略。佢仲話呢層要識得「metacognition」——知道自己幾時唔靠譜、證據弱唔弱、上下文係咪過時。
第三層係行動層:大腦唔止記同想,仲要協調下一步——決定幾時行動、幾時等、幾時揾人幫手。例如客電話產生咗承諾,自動起跟進電郵;同一個投訴出現三次,自動建工單;三個團隊用矛盾假設做嘢,俾 CEO 發預警。
同普通自動化嘅分別:一個係「按已知流程走」,一個係「根據上下文協調下一步」
點解會議記錄、企業搜索、Agent 工具都搞唔掂
而家所有相關工具都向「公司大腦」呢個中心靠,但每個由一個角落起步:會議工具(Granola、Otter)知道話過乜;企業搜索(Glean)知道有乜嘢;工作流工具(Zapier、ServiceNow)知道點樣做;Agent 工具(Dust)知道點樣試住完成任務。
Ashwin 狠批企業搜索係「塗咗口紅嘅圖書管理員」——被動,你要知道自己唔知乜先識得搜
佢嘅判斷係:公司大腦喺呢四個圓嘅交點。有用嘅問題唔只係「發生咗乜」,仲有「點解會咁」「下一步點樣做」「上下文喺邊個手上」「公司應該記住乜」。
- 會議工具:知道話過乜,但唔知道點解咁決定。
- 企業搜索:被動等你嚟問,目標應該係 zero-search。
- 工作流工具:執行確定動作,唔識由上下文推動作。
- Agent 工具:接住冇記憶嘅公司,只能做表面嘢。
一個公式、兩條路同埋 System 3
Ashwin 將公司大腦畫成公式:事實記憶 + 人類對話 + 上下文圖 + 受控行動 = 公司大腦。少咗對話,事實只係一份可以搜嘅檔案;少咗結構,對話只係一堆轉錄稿;少咗來源追溯,推理只係似合理嘅猜測;少咗上下文,行動就係脆自動化。
公司大腦要解決嘅問題,就係將呢四件事拼埋一齊
建設有兩條路:老公司靠「攢」——掛喺現有工具上,將碎片逐啲串返埋;新公司靠「長」——由頭就將決策、承諾、Agent 動作沉到同一個底子。Ashwin 唔知邊種贏,但肯定「先開始嘅公司有先發優勢」,因為判斷鏈走得越耐、越難補。
Ashwin 仲提出一個哲學框架叫 System 3:Kahneman 嘅 dual-process 得兩層(System 1 直覺、System 2 推理),佢認為仲有第三層——集體認知。公司大腦就係 System 3 嘅載體。點解係而家先做到?因為大模型理解非結構化溝通、向量檢索跨工具關聯、長上下文維持記憶、工具調用直接動手——呢啲技術棧兩年前唔夠,而家到位咗。
「你能租一個大腦,但租唔到一個神經系統」——通用大模型每次開新視窗都係由零記憶開始
公司大腦服務邊個?由員工到 Agent 都睇得明
Ashwin 反問:「如果公司大腦只係一個高管儀錶板,佢就係個 UI 好啲嘅監控工具;如果只係個人助理,就成唔到組織嘅記憶。」佢話公司大腦要在不同抽象層服務每種角色。
- 普通員工問:我需要咩背景?呢個決定點解咁定?試過乜?下一步邊個負責?
- 經理問:邊啲承諾有風險?邊個決策卡咗?邊啲假設互相衝突?
- CEO 問:公司在邊度飄咗?客講緊乜?邊啲決定當初證據好弱?
- Agent 問:我可以安全做乜?必須用咩上下文?幾時應該問人?
同一個底層,不同抽象層。一份「點解我哋咁做」嘅活地圖,每種角色都可以由自己嗰角度睇入去。
結尾留咗個問題畀讀者:你公司嘅「公司大腦」而家長喺邊幾個老員工嘅腦入面?佢哋走咗嗰日,公司會瞬間忘咗幾多?幾時開始留住呢啲記憶,就幾時開始有真正嘅護城河。
公司最大嘅護城河,由「我哋有最多數據」變咗做「我哋記得自己點解咁做」
小互AI · 深度解讀
點解大多數公司空有數據,但係毫無記憶?
一個舊客半年後返嚟續約,問咗你一句:「上次俾我哋呢個價,係點樣計出嚟㗎?」
你打開 CRM,裡面寫住價格、合同金額、簽單日期,乾乾淨淨。
但是「點解係呢個價」但係就唔知...
當年定價嗰次會議,係銷售副總話要衝業績壓一壓,係產品同事話呢個客戶其實俾到更高,係創始人最後拍板話先攞呢個 logo。呢啲冇任何人寫低。當時知道嘅人,一個走咗,一個調咗崗,淨低嗰個有印象但講唔清楚。
呢個唔係文件唔見咗,文件都仲喺度,係公司唔記得點解要咁決定。
Sentra 嘅聯合創始人 Ashwin Gopinath 上星期寫咗篇長文,標題叫《公司大腦:點解大多數公司有數據但冇記憶》。Sentra 今年 1 月攞咗 500 萬美元種子輪,a16z 旗下種子基金 speedrun 同 Together Fund 聯合領投,已經喺同軟銀跑付費試點。Ashwin 自己係前 MIT 教授,寫過讓 Agent 學會「自己發現錯咗再修正」嘅早期論文 Reflexion。
佢呢篇文章捅穿咗一層窗户紙:所有人都在俾公司裝 AI Agent,但 Agent 接嘅係一個唔記得自己點解咁決定嘅公司。模型再聰明,問到「上次點解咁定價」都只能亂咁估。
YC 幾乎同一時間將「公司大腦」寫咗入 Summer 2026 嘅 Requests for Startups。呢條由 YC group partner、Monzo 銀行創始人 Tom Blomfield 操刀,原話唔繞圈:令 AI 自動化跑通公司嘅最大障礙,已經唔係模型,模型變好得太快喇。而家卡嘅係領域知識,佢散喺郵件、Slack、工單、數據庫、幾個老員工嘅腦裏面。人靠模糊嘅印象嚟調度,Agent 唔得。
YC 呢條仲向前行多一步:公司大腦唔係公司搜索引擎,亦唔係文件問答機械人,係一份 Agent 可以跟住做嘢嘅「可執行技能檔案」(executable skills file)。
兩個獨立嘅人,由兩個唔同位置,見到同一個空位...
01
公司唔係因為冇數據失敗,係因為冇記憶

先講個直覺。
Ashwin 文章裏面講咗佢個女 Satakshi 嘅成長。個女出世喺 Sentra 公司註冊一星期後,佢一邊做呢間公司一邊睇個女學嘢。BB 學嘢唔係由讀手冊開始嘅,係睇嘢跌落地觀察大人反應、聽到聲音轉頭,記住嘅唔係事實而係「下次會點樣」嘅預期。從呢度佢睇出一件事:
記憶唔係檔案。
記憶係「下次再遇到嗰陣,我大概知道應該點麼辦」。
公司都係!
公司每日都在產生「碎片」:會議、Slack 對話、郵件、客戶電話、客服工單、路線圖爭論、銷售反對意見、投資人更新、代碼評審、走廊裏隨口傾嘅幾句。呢啲嘢嘅量大到冇人搞得掂。
問題唔係公司冇將佢哋存起嚟,問題係公司整碎片嘅速度比將佢哋變成記憶嘅速度快太多。組織記憶研究領域喺 1991 年就已經有過一篇基礎論文,James Walsh 同 Gerardo Ungson 嘅《Organizational Memory》。佢哋幫記憶落嘅定義就係一句:能夠用喺當下決策嘅過去信息。淨係存起嚟唔算,要喺你做決定嘅時候幫到手先算。
公司可以繼續運作,靠嘅從來唔係 CRM 裏面嗰啲字段。靠嘅係 Sarah 仲記得點解呢個客戶當時堅持要 SSO,靠嘅係 Ravi 仲記得 onboarding 當時點解卡住咗,靠嘅係創始人仲記得點解呢單生意比儀錶板上面睇起嚟更加重要。
呢種嘢喺組織行為學裏面叫 transactive memory,翻譯過嚟就係「團隊裏面互相知道邊個識啲乜」嘅嗰種默契。佢唔喺文件度,佢喺人腦度。
人走咗,佢就會消失。
呢件事 AI 唔嚟,問題冇咁明顯。Sarah 同 Ravi 一邊做嘢一邊寫返啲上文下理出嚟,公司勉強頂得住。AI 嚟咗,問題被放大十倍。Agent 接嘅唔係 Sarah 個腦,係 Sarah 剩低嘅幾百條 Slack 訊息、十幾篇未寫完嘅文件、一堆 CRM 字段。佢睇曬所有數據,仍然唔知點解咁決定。
Ashwin 呢篇裏面最值得拎出嚟嘅一句,譯返做大白話:「Agent 失敗唔單止係因為公司冇數據,係因為公司唔記得呢啲數據點解係呢個意思。」
根據 McKinsey 報告(2026 年 4 月《Building the Foundations for Agentic AI at Scale》),有 8 成嘅企業將數據問題列為擴展 agentic AI 嘅頭號障礙。呢個數字大家都見過。但麥肯錫嘅診斷停喺「數據基礎唔夠」呢一層。Ashwin 將呢層再挖深一刀:你嘅數據基礎就算整好,Agent 都係做唔到嘢。因為缺嘅根本唔係結構化數據,係俾人解讀過嘅判斷鏈。
02
Ashwin 嘅三層結構:事實、上文下理、行動

Ashwin 畀嘅定義好短,但每個詞都係有用嘅:公司大腦係一個活嘅模型,帶權限,模擬組織點樣記憶、推理、行動。
留意呢三個動詞:記憶、推理、行動。
對應佢文章裏面嘅三層結構。
第一層係事實層: 將公司裏面發生過嘅事都記低:會議、訊息、郵件、文件、工單、CRM 備註、代碼提交、客戶通話、客服對話。每條記錄要帶來源、權限、時間戳。
聽起嚟同企業搜索好似,係咪?大多數想做「公司大腦」嘅產品,最後都係靜靜雞變咗「換咗個皮嘅搜索」。Ashwin 自己好坦白咁講,事實層可以話俾你知客戶提過 SSO 呢個需求,可以話俾你知時間同會議記錄喺邊。但佢冇辦法話俾你知,當時點解呢件事咁重要,冇辦法話俾你知考慮過邊啲替代方案,冇辦法話俾你知邊個反對過、最後做咗啲乜嘢取捨。
事實係骨架,但公司唔係靠骨架運作。公司靠嘅係「被解釋過嘅事實」。
Ashwin 上星期仲寫咗 Part 2 專門講呢一層。裏面有句說話適合所有想做企業知識庫嘅人貼上牆:呢個唔係 RAG(令 AI 一邊查文件一邊回答嘅技術)。RAG 可以攞到片段,演示效果好好。但公司要嘅唔係睇落啱嘅片段,要嘅係帶來源、帶權限、帶所有權、帶時效、知道邊條資訊係真、知道各文件之間咩關係嘅耐用結構。佢幫呢層改咗個名叫 semantic file system,語義級文件系統。淨係將文件存起嚟唔夠,要將文件之間嘅關係存下來。
第二層係上文下理層: 呢一層將零碎事實串成「點解會咁樣」嘅關係網。客戶嘅一通電話連到一個銷售機會,機會連到一個產品缺口,缺口連到一個工程取捨,取捨連到一次路線圖決策,決策連到策略。
大多數系統將呢啲當成各自獨立嘅嘢嚟存。Slack 係 Slack,CRM 係 CRM,PRD 係 PRD。Ashwin 嘅判斷係公司大腦必須保留佢哋之間嘅關係。
再進一步,呢一層仲要做一件事:知道自己幾時係唔可靠嘅。證據強唔強、上文下理係咪過時、唔同團隊係咪用緊互相矛盾嘅假設、有啲承諾有冇人認領。Ashwin 俾呢個能力改咗個名叫 metacognition,講人話就係「諗嚇自己有冇諗清楚」
公司唔記得嘢嘅方式好奇怪。佢唔止係唔記得事實,佢會唔記得點解呢件事當初重要:嗰個爭論、嗰個反對意見、嗰啲試過又放棄嘅方案,同埋當時嗰個少數派嘅聲音(事後證明係啱嘅)。
第三層係行動層: 大腦唔止係記同諗,仲要協調下一步。決定幾時鬱、幾時等、幾時要揾人幫手、幾時直接停。
舉幾個具體例子:上一個客戶電話產生咗一個承諾,自動起一份跟進電郵草稿;客服裏面同一個投訴已經出現咗三次,自動開一個工單;三個團隊用緊互相矛盾嘅假設嚟開工,俾 CEO 發個預警;呢筆退款符合規則,Agent 直接處理,但呢個定價例外要揾人審批。
呢個同普通嘅自動化唔一樣。普通自動化係「按已知流程行」,公司大腦係「根據上文下理協調下一步」。一個係 Zapier 做嘅嘢,一個係得裝咗「組織記憶」嘅系統先做到嘅嘢。
03
點解會議記錄、企業搜索、Agent 工具都唔夠
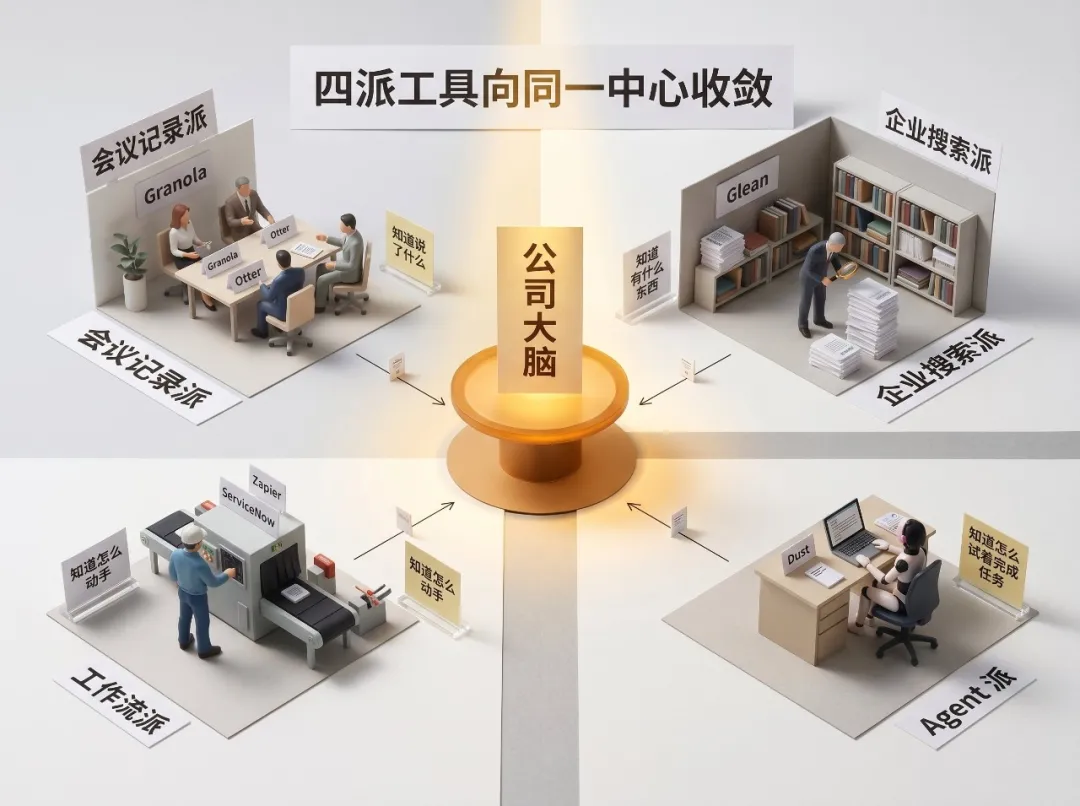
而家所有相關嘅工具,都朝着公司大腦呢個中心靠攏,但每個都係由一個角落起步,覆蓋嘅只係一片。
會議記錄呢類,例如 Granola、Otter,價值好大但係有個隱憂。Granola 自己喺博客度講過一個畫面:連續開會嘅人最缺嘅唔係「會議記完未」,係「上一場會嘅關鍵決策仲未沉澱,下一場會就開始咗,上文下理蒸發咗」。Otter 最近做咗跨企業工具搜索,TechCrunch 報道過呢個動作,意思就係 Otter 都喺度由「記錄」走向「搜索成間公司」。
但 Ashwin 嘅判斷好狠:轉錄好快就唔會係產品壁壘了。下一個 macOS 版本可能直接內置 Granola 嗰種功能。等到呢一日,做會議記錄嘅公司就要回答一個更難嘅問題:轉錄免費咗,我個產品到底護城河喺邊?
答案明顯唔係更準嘅轉錄。係將人同人之間嘅對話變成組織嘅記憶。而且唔可以扮一份轉錄稿就裝得曬當時所有嘅判斷、猶豫、唔同意、反事實。
企業搜搜索呢一類,例如 Glean,路徑係由「揾嘢」走向「合成答案 + Agent」。Glean 自己講佢哋嘅知識圖譜將公司嘅內容、人、活動連成一張網,覆蓋 100 幾個數據源。Ashwin 喺自己續篇度對企業搜索呢一派嘅評價比較狠,佢直接話企業搜索係「塗咗唇膏嘅圖書管理員」,骨子裏係被動嘅:你要知你唔知啲乜,要諗措辭成查詢,再睇結果。真正嘅目標應該係 zero-search,令上文下理喺你寫提案、開會之前自動浮現,唔係等你打開搜索框。
工作流工具這一類,例如 Zapier、ServiceNow,路徑係由「按流程行」走向「Agent 編排」。Zapier Agents 已經可以喺幾千個 app 之間設觸發器、動作、審批。ServiceNow 將 AI、數據、工作流、治理捏成一個大平台。但工作流派擅長嘅係執行確定嘅動作。公司大腦要嘅係「從上文下理度決定應該執行啲乜動作」。一個執行已知流程,一個從碎片化上文下理度推論應該做啲乜,爭一層。
Agent 工具呢一類,例如 Dust,路徑係直接做「識你公司、做到嘢嘅 Agent」。但同一樣嘅問題:Agent 接嘅係冇記憶嘅公司,佢就只可以做表面嘢。
四類工具,四個角落向同一個中心行:
知識工具知道有咩嘢。 會議工具知道講咗啲乜。 工作流工具知道點樣動手。 Agent 工具知道點樣試嚇完成任務。
Ashwin 嘅判斷係:公司大腦就喺呢四個圓嘅交點上。因為有用嘅問題唔止係「發生咗啲乜」,仲有:點解會咁樣,下一步應該點樣鬱,上文下理喺邊個人手度,公司應該記住什麼。
YC 同期 RFS 裏面 Diana Hu 仲寫咗另一篇相關條目叫《公司的 AI 操作系統》。佢嘅觀察同 Ashwin 係同一個:最 AI 原生嘅嗰批公司發現咗一件大多數人冇發現嘅事,佢哋將成間公司做咗成個可以查詢嘅。每場會議錄、每張工單、每次客戶互動留痕,都對一個可以學習嘅智能層透明。佢話見過咁樣做嘅團隊衝刺週期減半,發佈翻倍。
公司大腦呢個詞,係由唔同切入點向同一個中心收斂嘅現象嘅命名。
04
一個公式:四樣嘢少一樣都唔得

Ashwin 將呢件事畫成一個公式:
事實記憶 + 人類對話 + 上文下理圖 + 受控行動 = 公司大腦
四樣少一樣會點樣?
少咗對話,事實就只係一份可以搜嘅檔案,搜出嚟全部係結論冇過程。
少咗結構,對話就只係一堆轉錄稿同摘要,聽完同冇聽一樣。
少咗來源追溯,推理就只係睇落合理嘅猜測,冇人敢信。
少咗上文下理,行動就係脆弱嘅自動化,一掂就散。
公司大腦要解決嘅問題,就係將呢四件事併埋一起。
05
老公司補唔返,新公司一開始就應該有

淨低嘅問題係:呢樣嘢點樣建立?
Ashwin 俾咗兩條路。
第一條路係「攢」:公司大腦掛喺公司已經用緊嘅工具上面:郵箱、日曆、Slack、文件、CRM、項目管理、客服、代碼、工作流。大公司基本上只能夠咁樣起步,因為佢哋嘅上文下理已經散到周圍都係。麥肯錫都寫過類似嘅判斷:增量集成係一條路,全面 agentic 轉型係另一條。
第二條路係「生」:一間年輕公司由第一日就將「記憶、推理、行動」當成自己操作系統嘅一部分。會議、決策、承諾、Agent 動作,由一開始就沉到同一個底子度,知識仲未碎裂之前就已經被串起咗。
Ashwin 自己嘅判斷係:佢唔知邊種架構最後會贏。但先開始嘅公司,會有先發優勢。
意思好直接:公司大腦呢種基礎設施,唔係「等業務做大了再裝」嘅嘢。裝得越遲,要補嘅「點解」越多,老員工已經走咗一半,嗰啲當年嘅判斷永遠揾唔返。
老公司裏面有一個反直覺嘅事實:文件之間係互相矛盾嘅,儀錶板睇起嚟好乾淨,但記憶已經沒了。
06
公司大腦俾邊個用?
最後一個問題:呢樣嘢到底服務邊個?
Ashwin 反問咗一句好狠嘅說話:「如果公司大腦只係一個高層儀錶板,咁佢就係一個 UI 好啲嘅監控工具。如果佢只係一個個人助理,咁佢就成唔到組織嘅記憶。」
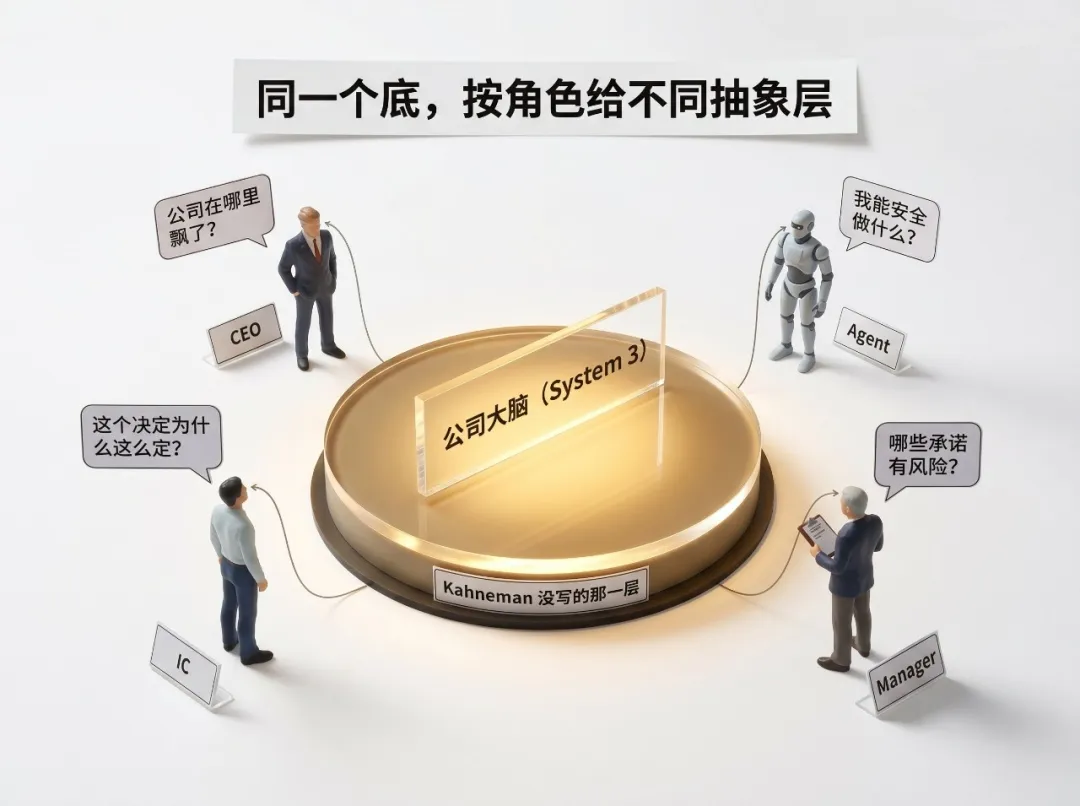
佢俾嘅答案係:公司大腦要喺唔同抽象層服務每種角色。
普通員工問:我做呢件事需要咩背景?呢個決策當初點解咁定?試過啲乜?下一步邊個負責?我即刻會影響邊個客戶承諾?
經理問:邊啲承諾有風險?邊啲決策卡住咗?邊啲假設互相衝突?邊啲跟進跌咗落地?
CEO 問:公司喺邊度飄咗?客戶講緊啲乜?邊啲決策當初證據其實好弱?公司裏面有啲乜高層仲未知?
Agent 問:我可以安全做啲乜?一定要用咩上文下理?幾時要問人?
同一個底,唔同抽象層。一份「點解我哋咁做」嘅活地圖,每種角色都可以由自己嘅角度望入去。
07
System 3:Kahneman 冇寫嘅嗰一層

Ashwin 自己有個更哲學嘅框架,佢喺 1 月嘅一篇文章度第一次提出,叫 System 3 thinking。
諾貝爾經濟學獎得主 Kahneman 將人嘅思考分成兩層,叫 dual-process model:System 1 係直覺、快、自動(見到老虎就跑);System 2 係推理、慢、刻意(解一條數學題)。Ashwin 認為仲有一層,係個體推理之上嘅集體認知,佢叫佢做 System 3。
公司大腦就係 System 3 嘅載體。
呢個唔係捉字蝨,係喺度講:過去幾十年所有俾企業造嘅工具,由 ERP 到 CRM 到 BI 到企業搜索,都係喺度幫 System 1 或 System 2 加 buff。令員工反應快啲,令分析師推理強啲。Company Brain 第一次係直接製造 System 3 呢一層本身。
點解係而家?因為底層組件第一次到位咗:大模型可以理解非結構化溝通,向量檢索可以跨工具關聯上文下理,長上文下理窗口可以跨時間維持記憶,工具調用令 Agent 可以直接動手。呢套技術棧兩年前唔夠。而家夠喇。
Ashwin 喺另一篇續文度寫咗句說話適合貼喺辦公室門口:「你可以租一個大腦。你租唔到一個神經系統。」
意思係:通用大模型再強,佢都係租返嚟嘅。佢點樣思考你話唔到事,佢每次開新視窗都由零記憶開始(OpenAI、Anthropic 一定要咁樣設計,如果唔係算力賬單頂唔住)。佢唔會真係成為你公司嘅一部分。
公司大腦要做嘅事,係搭一個「持續感知 + 持續記憶 + 持續調整」嘅層,同「無狀態 prompt 出入」嘅模型結構正好相反。所以 Ashwin 俾 Sentra 嘅定位唔係「賣一個模型 API 俾你接」,係「賣一整套會持續學習你公司嘅系統」,佢自己俾呢種模式改咗個名叫 System-as-a-Service。
無論最後係 Sentra 定係第個做出嚟,AI 時代真正嘅護城河,可能唔係模型本身,係裝喺模型外面嘅「組織級神經系統」。模型大家都用到,神經系統每間公司唔一樣,而且只能由公司自己嘅信號度慢慢生出來。
08
Agent 接嘅係一個唔記得自己嘅公司
返到開頭嗰個續約場景。
如果你公司有咁樣一個底,嗰個客戶問「點解當年咁定價」嘅時候,Agent 攞到嘅唔係一堆 CRM 字段,係當年嗰場會議裏面銷售副總嘅判斷、產品同事講嘅「呢個客戶扛得起」嘅依據、創始人最後拍板嘅理由,同埋呢啲判斷之間嘅關係。
Agent 唔需要亂估,因為公司本身記得。
呢一年大家都喺度卷 Agent。但 Agent 失敗嘅真問題唔係模型唔夠強。模型已經強到可以寫 code、可以讀財報、可以開會、可以寫電郵。
真問題係:佢接嗰間公司,從來冇認真記住過自己。
佢唔知點解呢條規則要咁樣寫。
佢唔知呢個客戶兩年前提過啲乜。
佢唔知嗰次故障之後到底改咗啲乜。
佢唔知點解呢個 deal 要緊、嗰個 deal 唔緊要。
佢唔知邊啲假設已經過期、邊啲團隊對同一件事各有版本、邊個老員工個腦度仲壓住未講出嚟嘅關鍵資訊。
Ashwin 呢篇真正嘅貢獻,唔係三層結構本身,係佢將「公司冇記憶」同「Agent 落唔到地」呢兩件事連埋一齊。
連埋一齊之後你會突然睇清楚一件事:今日組織最大嘅護城河,由「我哋有最多數據」,變成咗「我哋記得自己點解要咁做」。
數據可以買,可以爬,可以洗。
判斷鏈唔得。
嗰啲消化過嘅點解、嗰啲被推翻嘅反方案、嗰啲轉過彎嘅權衡、嗰啲走廊上邊個說服咗邊個,係公司真正嘅「我」。
Sentra 另一位聯合創始人、CEO Jae Park 俾 PR Newswire 嘅引述都係呢個意思:「現代公司產生嘅知識比佢哋可以保留或使用嘅多好多。每一次對話、決策、文件都加進一片越來越大嘅上下文之海,幾分鐘之後就消失咗,或者沉到孤島裏面去。」
Ashwin 嘅原話更直接啲:真正變成「AI 原生」嘅公司,唔會係嗰種將 Agent 扭到散落數據上面嘅公司,而係嗰種記得自己嘅工作點解有意義嘅公司。
呢個先係真正嘅護城河。
唔係有冇 AI。
唔係模型夠唔夠好。
是公司記唔記得自己。
09
留個問題俾你
寫到呢度,留一個問題。
你公司嘅「公司大腦」而家教喺邊幾個老員工嘅腦裏面?
嗰幾個人離職嗰日,公司會瞬間唔記得幾多?
如果 張三 聽日走,如果 小李 後日走,公司需要幾耐先可以從「憑記憶運作」重新建立返判斷鏈?
你而家公司裏面嗰啲走廊傾出嚟嘅判斷、嗰啲會議室裏面臨時拍板嘅取捨、嗰啲得少數老員工先講得清楚嘅「點解」,每日都喺度蒸發。
幾時開始將佢哋留低,就幾時開始有真正嘅護城河。
— END —
原文:https://x.com/ashwingop/status/2049641901410955694
小互AI · 深度解讀
為什麼大多數公司空有數據,卻毫無記憶?
一個老客戶半年後回來續約,問了你一句:「上次給我們這個價,是怎麼算出來的?」
你打開 CRM,裏面寫着價格、合同金額、簽單日期,乾乾淨淨。
但是「為什麼是這個價」卻不知道...
當年定價那次會議,是銷售副總說要衝業績壓一壓,是產品同事說這家客戶其實能給到更高,是創始人最後拍板說先拿下這個 logo。這些沒有任何人寫下來。當時知道的人,一個走了,一個調崗了,剩下那個有印象但說不清楚。
這不是文檔丟了,文檔都還在,是公司忘了為什麼要這麼決定。
Sentra 的聯合創始人 Ashwin Gopinath 上週寫了一篇長文,標題叫《公司大腦:為什麼大多數公司有數據但沒有記憶》。Sentra 今年 1 月拿了 500 萬美元種子輪,a16z 旗下種子基金 speedrun 和 Together Fund 聯合領投,已經在跟軟銀跑付費試點。Ashwin 自己是前 MIT 教授,寫過讓 Agent 學會「自己發現錯了再修正」的早期論文 Reflexion。
他這篇文章捅破了一層窗户紙:所有人都在給公司裝 AI Agent,但 Agent 接的是一個不記得自己為什麼這麼決定的公司。模型再聰明,問到「上次為什麼這麼定價」也只能瞎猜。
YC 幾乎同一時間把「公司大腦」寫進了 Summer 2026 的 Requests for Startups。這條由 YC group partner、Monzo 銀行創始人 Tom Blomfield 操刀,原話不繞:讓 AI 自動化跑通公司的最大障礙,已經不是模型,模型變好得太快了。現在卡的是領域知識,它散在郵件、Slack、工單、數據庫、幾個老員工腦子裏。人靠模糊的印象在調度,Agent 不行。
YC 這條還往前再走一步:公司大腦不是公司搜索引擎,也不是文檔問答機器人,是一份 Agent 能照着幹活的「可執行技能檔案」(executable skills file)。
兩個獨立的人,從兩個不同位置,看到了同一個空缺...
01
公司不是因為缺數據失敗的,是因為缺記憶
先講個直覺。
Ashwin 文章裏講了他女兒 Satakshi 的成長。孩子出生在 Sentra 公司註冊一週後,他一邊做這家公司一邊看孩子學東西。嬰兒學東西不是從讀手冊開始的,是看東西掉下去觀察大人反應、聽到聲音轉頭,記住的不是事實而是「下一次會怎樣」的預期。從這他看出來一件事:
記憶不是檔案。
記憶是「下次再遇到的時候,我大概知道該怎麼辦」。
公司也是!
公司每天都在生成「碎片」:會議、Slack 對話、郵件、客戶電話、客服工單、路線圖爭論、銷售反對意見、投資人更新、代碼評審、走廊裏隨口聊的幾句。這些東西的量大到沒人能管。
問題不是公司沒把它們存起來,問題是公司攢碎片的速度比把它們變成記憶的速度快太多。組織記憶研究領域在 1991 年就有過一篇基礎論文,James Walsh 和 Gerardo Ungson 的《Organizational Memory》。他們給記憶下的定義就一句:能用在當下決策上的過去信息。光存下來不算,能在你做決定的時候幫上忙才算。
公司能跑下去,靠的從來不是 CRM 裏那些字段。靠的是 Sarah 還記得為什麼這家客戶當時堅持要 SSO,靠的是 Ravi 還記得 onboarding 當時為什麼卡住了,靠的是創始人還記得為什麼這一單比儀表盤上看起來更重要。
這種東西在組織行為學裏叫 transactive memory,翻譯過來就是「團隊裏互相知道誰懂什麼」的那種默契。它不在文檔裏,它在人腦裏。
人走了,它就消失了。
這事 AI 不來,問題沒那麼明顯。Sarah 和 Ravi 一邊幹活一邊把上下文寫一點出來,公司勉強湊合。AI 來了,問題被放大十倍。Agent 接的不是 Sarah 腦子,是 Sarah 留下的幾百條 Slack 消息、十幾篇沒寫完的文檔、一堆 CRM 字段。它讀完所有數據,仍然不知道為什麼這麼決定。
Ashwin 這篇裏最值得拎出來的一句,翻成大白話:「Agent 失敗不只是因為公司缺數據,是因為公司不記得這些數據為什麼是這個意思。」
據 McKinsey 報告(2026 年 4 月《Building the Foundations for Agentic AI at Scale》),有 8 成的企業把數據問題列為擴展 agentic AI 的頭號障礙。這個數字大家都看到過。但麥肯錫的診斷停在「數據基礎不夠」這層。Ashwin 把這層往下又挖了一刀:你的數據基礎就算建好,Agent 還是幹不了活。因為缺的根本不是結構化數據,是被解讀過的判斷鏈。
02
Ashwin 的三層結構:事實、上下文、行動
Ashwin 給的定義很短,但每個詞都在幹活:公司大腦是一個活的模型,帶權限,模擬組織怎麼記憶、推理、行動。
注意這三個動詞:記憶、推理、行動。
對應他文章裏的三層結構。
第一層是事實層: 把公司裏發生過的事都記下來:會議、消息、郵件、文檔、工單、CRM 備註、代碼提交、客戶通話、客服對話。每條記錄要帶來源、權限、時間戳。
聽起來跟企業搜索很像,對吧?大多數想做「公司大腦」的產品,最後都默默變成了「換了個皮的搜索」。Ashwin 自己很坦白地說,事實層能告訴你客戶提過 SSO 這個需求,能告訴你時間和會議記錄在哪。但它沒法告訴你,當時為什麼這事重要,沒法告訴你考慮過哪些替代方案,沒法告訴你誰反對過、最後做了什麼取捨。
事實是骨架,但公司不靠骨架運轉。公司靠的是「被解釋過的事實」。
Ashwin 上週還寫了 Part 2 專門講這一層。裏面有句話適合所有想做企業知識庫的人貼牆上:這不是 RAG(讓 AI 一邊查文檔一邊回答的技術)。RAG 能拿到片段,演示效果很神奇。但公司要的不是看起來對的片段,要的是帶來源、帶權限、帶所有權、帶時效、知道哪條信息是真的、知道各文檔之間什麼關係的耐用結構。他給這層取了個名字叫 semantic file system,語義級文件系統。光把文件存下來不夠,要把文件之間的關係存下來。
第二層是上下文層: 這一層把零散事實串成「為什麼會這樣」的關係網。客戶的一通電話連到一個銷售機會,機會連到一個產品缺口,缺口連到一個工程取捨,取捨連到一次路線圖決策,決策連到戰略。
大多數系統把這些當成各自獨立的東西存。Slack 是 Slack,CRM 是 CRM,PRD 是 PRD。Ashwin 的判斷是公司大腦必須保留它們之間的關係。
更進一步,這一層還要會一件事:知道自己什麼時候是不靠譜的。證據弱不弱、上下文是不是過時了、不同團隊是不是在用相互矛盾的假設、有些承諾有沒有人認領。Ashwin 給這個能力起了個名字叫 metacognition,說人話就是「想自己有沒有想清楚」。
公司忘事的方式很奇怪。它不只是忘掉事實,它會忘掉為什麼這件事當初重要:那個爭論、那個反對意見、那些被試過又放棄的方案,還有當時那個少數派的聲音(事後證明是對的)。
第三層是行動層: 大腦不只是記和想,還要協調下一步。決定什麼時候動、什麼時候等、什麼時候要找人幫忙、什麼時候直接停。
舉幾個具體例子:上一通客戶電話產生了一個承諾,自動起一份跟進郵件草稿;客服裏同一個抱怨已經出現三次了,自動建一個工單;三個團隊在用相互矛盾的假設幹活了,給 CEO 發個預警;這一筆退款符合規則,Agent 直接處理掉,但這個定價例外要找人審批。
這跟普通的自動化不一樣。普通自動化是「按已知流程走」,公司大腦是「根據上下文協調下一步」。一個是 Zapier 乾的事,一個是隻有裝了「組織記憶」的系統才能乾的事。
03
為什麼會議記錄、企業搜索、Agent 工具都不夠
現在所有相關的工具,都在朝公司大腦這個中心靠攏,但每家都是從一個角落起步,覆蓋的只是一片。
會議記錄這一類,比如 Granola、Otter,價值很大但有個隱憂。Granola 自己在博客裏講過一個畫面:連續開會的人最缺的不是「會議記完沒有」,是「上一場會的關鍵決策還沒沉澱,下一場會就開始了,上下文蒸發了」。Otter 最近做了跨企業工具搜索,TechCrunch 報道過這個動作,意思就是 Otter 也在從「記錄」往「搜索整個公司」走。
但 Ashwin 的判斷很扎心:轉錄馬上就不是產品壁壘了。下一個 macOS 版本可能直接內置 Granola 那種功能。等到這一天,做會議記錄的公司就要回答一個更難的問題:轉錄免費了,我的產品到底護城河在哪裏?
答案顯然不是更準的轉錄。是把人和人之間的對話變成組織的記憶。而且不能假裝一份轉錄稿就裝下了當時所有的判斷、猶豫、不同意、反事實。
企業搜索這一類,比如 Glean,路徑是從「找東西」走向「合成答案 + Agent」。Glean 自己講他們的知識圖譜把公司的內容、人、活動連成一張網,覆蓋 100 多個數據源。Ashwin 在自己續篇裏對企業搜索這一派的評價比較狠,他直接說企業搜索是「塗了口紅的圖書管理員」,骨子裏是被動的:你得知道你不知道什麼,會措辭成查詢,再翻結果。真正的目標應該是 zero-search,讓上下文在你寫提案、開會前自動浮現,不是等你打開搜索框。
工作流工具這一類,比如 Zapier、ServiceNow,路徑是從「按流程跑」走向「Agent 編排」。Zapier Agents 已經能在幾千個 app 之間設觸發器、動作、審批。ServiceNow 把 AI、數據、工作流、治理捏成一個大平台。但工作流派擅長的是執行確定的動作。公司大腦要的是「從上下文裏決定該執行什麼動作」。一個執行已知流程,一個從碎片化上下文裏推出該做什麼,差一層。
Agent 工具這一類,比如 Dust,路徑是直接做「懂你公司、能幹活的 Agent」。但同樣的問題:Agent 接的是沒有記憶的公司,它就只能做表面活。
四類工具,四個角落往同一個中心走:
知識工具知道有什麼東西。 會議工具知道說了什麼。 工作流工具知道怎麼動手。 Agent 工具知道怎麼試着完成任務。
Ashwin 的判斷是:公司大腦就在這四個圓的交點上。因為有用的問題不只是「發生了什麼」,還有:為什麼會這樣,下一步該怎麼動,上下文在誰手裏,公司應該記住什麼。
YC 同期 RFS 裏 Diana Hu 還寫了另一篇相關條目叫《公司的 AI 操作系統》。她的觀察跟 Ashwin 是同一個:最 AI 原生的那批公司發現了一件大多數人沒發現的事,他們把整家公司做成了可查詢的。每場會議錄、每張工單跟、每次客戶互動留痕,都對一個能學習的智能層透明。她說見過這麼幹的團隊衝刺週期減半,發佈翻倍。
公司大腦這個詞,是從不同切入點向同一個中心收斂的現象的命名。
04
一個公式:四樣東西少一樣都不行
Ashwin 把這事畫成一個公式:
事實記憶 + 人類對話 + 上下文圖 + 受控行動 = 公司大腦
四樣少一樣會怎樣?
少了對話,事實就只是一份能搜的檔案,搜出來全是結論沒有過程。
少了結構,對話就只是一堆轉錄稿和摘要,聽完跟沒聽一樣。
少了來源追溯,推理就只是看起來合理的猜測,沒人敢信。
少了上下文,行動就是脆的自動化,碰一下就崩。
公司大腦要解決的問題,就是把這四件事拼到一起。
05
老公司補不上,新公司一開始就該有
剩下的問題是:這東西怎麼建?
Ashwin 給了兩條路。
第一條路是「攢」:公司大腦掛在公司已經在用的工具上:郵箱、日曆、Slack、文檔、CRM、項目管理、客服、代碼、工作流。大公司基本只能這樣起步,因為它們的上下文已經散得到處都是。麥肯錫也寫過類似的判斷:增量集成是一條路,全面 agentic 轉型是另一條。
第二條路是「長」:一家年輕公司從第一天就把「記憶、推理、行動」當成自己操作系統的一部分。會議、決策、承諾、Agent 動作,從一開始就沉到同一個底子裏,知識還沒碎裂之前就已經被串起來了。
Ashwin 自己的判斷是:他不知道哪種架構最後會贏。但先開始的公司,會有先發優勢。
意思直白:公司大腦這種基礎設施,不是「等業務做大了再裝」的東西。裝得越晚,要補的「為什麼」越多,老員工已經走了一半,那些當年的判斷永遠找不回來了。
老公司裏有一個反直覺的事實:文檔之間是互相矛盾的,儀表盤看起來很乾淨,但記憶已經沒了。
06
公司大腦給誰用?
最後一個問題:這東西到底服務誰?
Ashwin 反問了一句很狠的話:「如果公司大腦只是一個高管儀表盤,那它就是個 UI 更好的監控工具。如果它只是個個人助理,那它就成不了組織的記憶。」
他給的答案是:公司大腦要在不同抽象層服務每種角色。
普通員工問:我做這件事需要什麼背景?這個決策當初為什麼這麼定?試過什麼了?下一步誰負責?我馬上要影響哪個客戶承諾?
經理問:哪些承諾有風險?哪些決策卡住了?哪些假設互相沖突?哪些跟進掉地上了?
CEO 問:公司在哪裏飄了?客戶在說什麼?哪些決策當初證據其實很弱?公司裏有什麼是高層還不知道的?
Agent 問:我能安全做什麼?必須用什麼上下文?什麼時候該問人?
同一個底,不同抽象層。一份「為什麼我們這麼幹」的活地圖,每種角色都能從自己的角度看進去。
07
System 3:Kahneman 沒寫的那一層
Ashwin 自己有個更哲學的框架,他在 1 月的一篇文章裏第一次提,叫 System 3 thinking。
諾貝爾經濟學獎得主 Kahneman 把人的思考拆成兩層,叫 dual-process model:System 1 是直覺、快、自動(看到老虎就跑);System 2 是推理、慢、刻意(解一道數學題)。Ashwin 認為還有一層,是個體推理之上的集體認知,他叫它 System 3。
公司大腦就是 System 3 的載體。
這不是摳字眼,這是在說:過去幾十年所有給企業造的工具,從 ERP 到 CRM 到 BI 到企業搜索,都是在給 System 1 或 System 2 加 buff。讓員工反應快一點,讓分析師推理強一點。Company Brain 第一次是在直接造 System 3 這一層本身。
為什麼是現在?因為底層組件第一次到位了:大模型能理解非結構化溝通,向量檢索能跨工具關聯上下文,長上下文窗口能跨時間維持記憶,工具調用讓 Agent 能直接動手。這套技術棧兩年前不夠。現在夠了。
Ashwin 在另一篇續文裏寫了句話適合貼辦公室門上:「你能租一個大腦。你租不到一個神經系統。」
意思是:通用大模型再強,它也是租來的。它怎麼思考你說了不算,它每次打開新窗口都從零記憶開始(OpenAI、Anthropic 必須這樣設計,否則算力賬單頂不住)。它不會真的成為你公司的一部分。
公司大腦要做的事,是搭一個「持續感知 + 持續記憶 + 持續調整」的層,跟「無狀態 prompt 進出」的模型架構正好相反。所以 Ashwin 給 Sentra 的定位不是「賣一個模型 API 讓你接」,而是「賣一整套會持續學習你公司的系統」,他自己給這種模式起了個名字叫 System-as-a-Service。
不管最後是 Sentra 還是別的誰做出來,AI 時代真正的護城河,可能不是模型本身,是裝在模型外面的「組織級神經系統」。模型大家都能用,神經系統每家公司不一樣,而且只能從公司自己的信號裏慢慢長出來。
08
Agent 接的是一個不記得自己的公司
回到開頭那個續約場景。
如果你公司有這樣一個底,那個客戶問「為什麼當年這麼定價」的時候,Agent 拿到的不是一堆 CRM 字段,是當年那場會議裏銷售副總的判斷、產品同事說的「這家客戶能扛」的依據、創始人最後拍板的理由,以及這些判斷之間的關係。
Agent 不需要瞎猜,因為公司本身記得。
這一年大家都在卷 Agent。但 Agent 失敗的真問題不是模型不夠強。模型已經強到能寫代碼、能讀財報、能開會、能寫郵件了。
真問題是:它接的那家公司,從來沒認真記住過自己。
它不知道為什麼這條規則要這麼寫。
它不知道這個客戶兩年前提過什麼。
它不知道那次故障之後到底改了什麼。
它不知道為什麼這個 deal 要緊、那個 deal 不要緊。
它不知道哪些假設已經過期、哪些團隊對同一件事各有版本、哪個老員工腦子裏還壓着沒說出來的關鍵信息。
Ashwin 這篇真正的貢獻,不是三層架構本身,而是他把「公司沒記憶」和「Agent 落不了地」這兩件事接在了一起。
接在一起後你會突然看清一件事:今天組織最大的護城河,從「我們有最多數據」,變成了「我們記得自己為什麼這麼做」。
數據可以買,可以爬,可以洗。
判斷鏈不能。
那些消化過的為什麼、那些被推翻的反方案、那些轉過彎的權衡、那些走廊上誰說服了誰,是公司真正的「我」。
Sentra 另一位聯合創始人、CEO Jae Park 給 PR Newswire 的引述也是這個意思:「現代公司產生的知識比它們能保留或使用的多得多。每一次對話、決策、文檔都加進一片越來越大的上下文之海,幾分鐘後就消失了,或者沉到孤島裏去了。」
Ashwin 的原話更直白一點:真正變成「AI 原生」的公司,不會是那種把 Agent 擰到散落數據上的公司,而是那種記得自己的工作為什麼有意義的公司。
這才是真正的護城河。
不是有沒有 AI。
不是模型夠不夠好。
是公司記不記得自己。
09
留個問題給你
寫到這兒,留一個問題。
你公司的「公司大腦」現在長在哪幾個老員工的腦子裏?
那幾個人離職那天,公司會瞬間忘掉多少?
要是 張三 明天走,要是 小李 後天走,公司需要多久才能從「憑記憶運轉」重新建立起判斷鏈?
你現在公司裏那些走廊裏聊出來的判斷、那些會議室裏臨時拍板的取捨、那些只有少數老員工才說得清楚的「為什麼」,每天都在蒸發。
什麼時候開始把它們留下來,就什麼時候開始有真正的護城河。
— END —
原文:https://x.com/ashwingop/status/2049641901410955694