如何把Obsidian Web Clipper價值最大化?
整理版優先睇
玩轉 Obsidian Web Clipper:原版進階技巧同中文增強版實戰
呢篇文章係蔡蔡分享點樣最大化利用 Obsidian Web Clipper 嘅心得。佢之前分享過 Karpathy 嘅 AI 知識庫方法,入面提到呢個插件,發現真係好好用,但對中文內容(尤其係 B站同飛書)支援唔夠,所以就自己開發咗中文增強版 obsidian-clipper-cn。
文章分兩部分:第一部分教大家點樣「榨乾」原版插件,包括四個實用技巧(解釋器、模板觸發器、高亮文字、配合沉浸式翻譯);第二部分介紹中文增強版點樣完整支援 B站字幕同飛書文檔,仲有飛書 API 嘅配置方法。整體結論:只要用啱技巧,原版已經可以發揮七八成功力;如果成日要用 B站或飛書,就一定要用增強版。
- 原版插件可以一鍵剪存網頁同 YouTube 字幕,但中文內容(B站、飛書)需要增強版先搞得掂。
- 解釋器變量引入 AI 能力,可以用自然語言做總結、翻譯、提取特定內容,係最值得用嘅功能。
- 模板觸發器按 URL 自動切換對應模板,省卻手動揀選嘅麻煩。
- 高亮功能可以直接喺網頁劃重點,同步到 Obsidian,唔使二次整理。
- 作者開發嘅中文增強版 obsidian-clipper-cn 完整支援 B站字幕嵌入播放器同飛書文檔 API 提取,補足原版短板。
解釋器變量模板(AI 總結)
{{ "用簡體中文總結和提煉呢篇文章嘅核心內容。請用 Why How What 結構話畀讀者知呢篇文章點解值得睇,風格類似作家 Paul Graham" }}
obsidian-clipper-cn(中文增強版)
支援 B站視頻字幕同飛書文檔嘅 Obsidian Web Clipper 分支,開源免費。
原版 Obsidian Web Clipper
官方瀏覽器插件 GitHub 倉庫。
飛書開放平台
創建自建應用以獲取 App ID 同 App Secret。
原版插件基本用法同四大進階技巧
Obsidian Web Clipper 係官方推出嘅瀏覽器插件,可以一鍵將網頁內容(包括 YouTube 字幕)以 Markdown 格式保存到 Obsidian。Markdown 喺 AI 時代係硬通貨,因為 AI 可以無損理解,仲跨平台、保存得耐。不過,要將佢嘅價值最大化,一定要用以下幾個技巧。
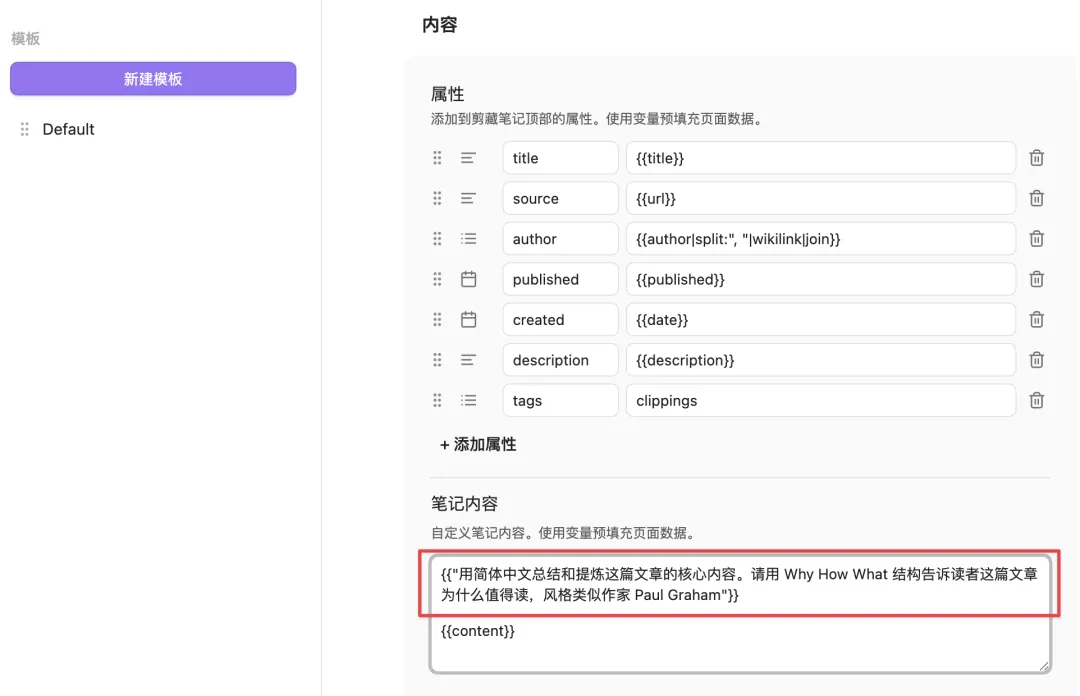
- 1 技巧一:配置解釋器。喺模板中加入類似 {{ "用繁體中文總結呢篇文章" }} 嘅變量,插件就會先 call AI 再填返結果,咁就可以睇完總結先決定係咪要剪存。
- 2 技巧二:設置模板觸發條件。喺編輯模板時設定 URL 觸發器,例如 YouTube 同 B站用視頻模板,公眾號用文章模板,打開插件就會自動揀啱嘅模板,唔使手動切換。
- 3 技巧三:高亮文字。閲讀時直接點插件嘅高亮功能,劃重點後會同步到 Obsidian 文檔,慳返二次整理時間。
- 4 技巧四:沉浸式翻譯配合使用。直接用沉浸式翻譯譯完個頁面,再開 Obsidian Web Clipper,佢可以同時拎到原文同翻譯內容,唔使另外搞翻譯解釋器。
解釋器嘅運作原理同配置方法
解釋器變量同普通變量最大分別係:普通變量好似 {{title}},直接從網頁代碼攞值;解釋器變量就會將網頁內容 send 畀 AI,AI 理解後再填返結果。呢個設計令插件可以做到翻譯、提取重點、格式轉換等任務,只要用自然語言講清楚就得。
例如你可以用 {{ "用廣東話總結呢篇文" }} 或者 {{ "提取文中提到嘅三項風險" }},AI 會按指示處理。
選大模型會令處理時間拉長好多,所以權衡速度同準確度好重要。
中文增強版:完整支援 B站同飛書
原版插件唔支援 B站視頻字幕同飛書文檔,所以作者開發咗 obsidian-clipper-cn。呢個增強版保留原版所有能力,仲額外支援兩個平台。
B站支援同官方 YouTube 整合幾乎一致:可以提取簡介、章節同字幕。
- 嵌入 Bilibili 播放器,支援置頂固定時間戳。
- 點擊任何字幕或章節時間戳,視頻會跳轉到對應時間。
- 播放時自動滾動字幕,跟隨進度高亮當前字幕行。
- 可以配合解釋器技巧一齊用,效果更出眾。
飛書文檔方面,原版因動態渲染機制令內容提取唔完整。
增強版透過接入飛書開放平台 API,用結構化接口完整獲取文檔內容,不過目前暫時未支援圖片,作者話後續會研究點解決。
飛書文檔配置步驟同開發背後
- 1 去飛書開放平台創建自建應用,攞到 App ID 同 App Secret。
- 2 開通權限:docx:document:readonly 同 wiki:node:read,記住要啟用應用先得。
- 3 打開 obsidian-clipper-cn 插件設定,喺「飛書 / Lark」模塊填入 App ID 同 App Secret。注意呢啲資料只保存在本地瀏覽器儲存,唔會上傳任何伺服器。
如果遇到 Bugs 或者功能不足,可以去 GitHub 開 Issues 或者直接留言。
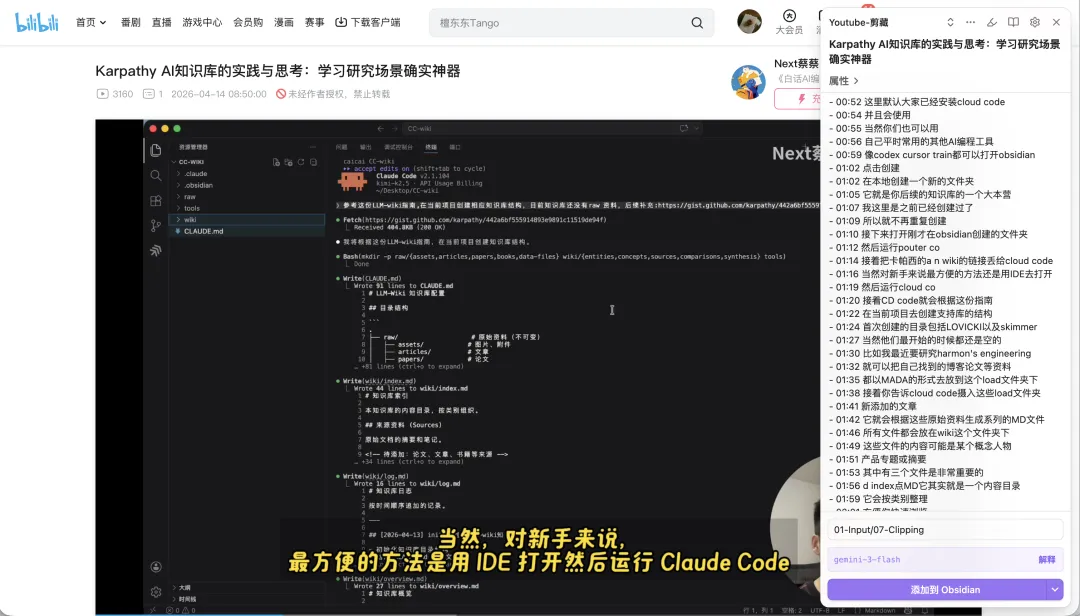
之前分享過 Karpathy 搭建 AI 知識庫嘅方法,當中簡單講過 Obsidian Web Clipper 呢個剪存插件。
🔗:https://github.com/obsidianmd/obsidian-clipper
佢本身好好用,好多網頁內容甚至 YouTube 影片字幕都可以一鍵剪存到 Obsidian 裏面,我喺知識星球入面都分享過好多次。不過佢對一啲中文內容仲未支援,所以我就幫佢做咗個中文增強,而家支援B站影片字幕+飛書文檔。
🔗:https://github.com/nextcaicai/obsidian-clipper-cn
呢篇文章就係分享我點樣玩轉 Obsidian Web Clipper,分成兩部分:
點樣「榨乾」原版 Obsidian Web Clipper?
點樣用中文增強版 Obsidian Web Clipper?
一、點樣「榨乾」原版 Obsidian Web Clipper?
Obsidian Web Clipper 係 Obsidian 官方推出嘅瀏覽器插件,可以俾你一鍵將網頁內容保存到 Obsidian 裏面。
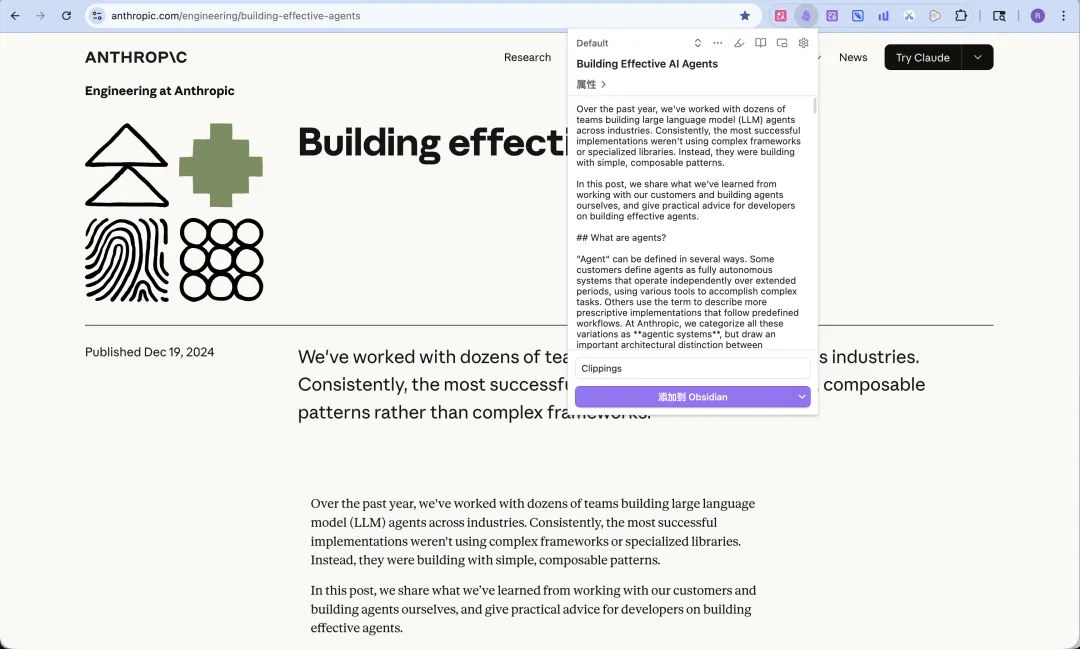
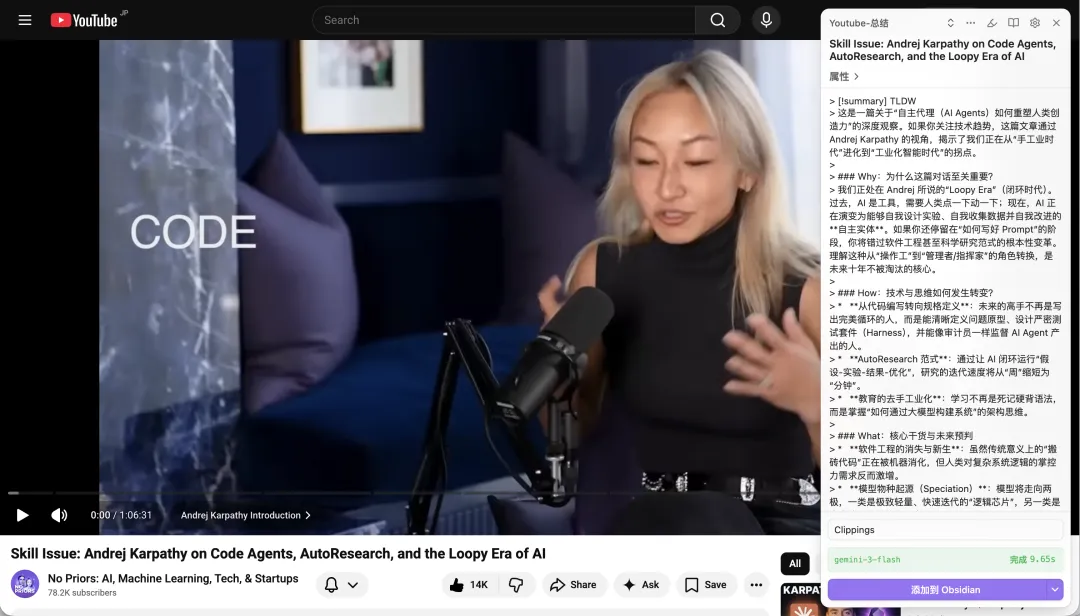
例如我想保存 Anthropic 呢篇乾貨網誌,直接叫出 Obsidian Web Clipper 插件,就會見到網誌嘅全部內容已經喺插件面板度,㩒「添加到 Obsidian」,就可以一鍵加到 Obsidian 知識庫度。
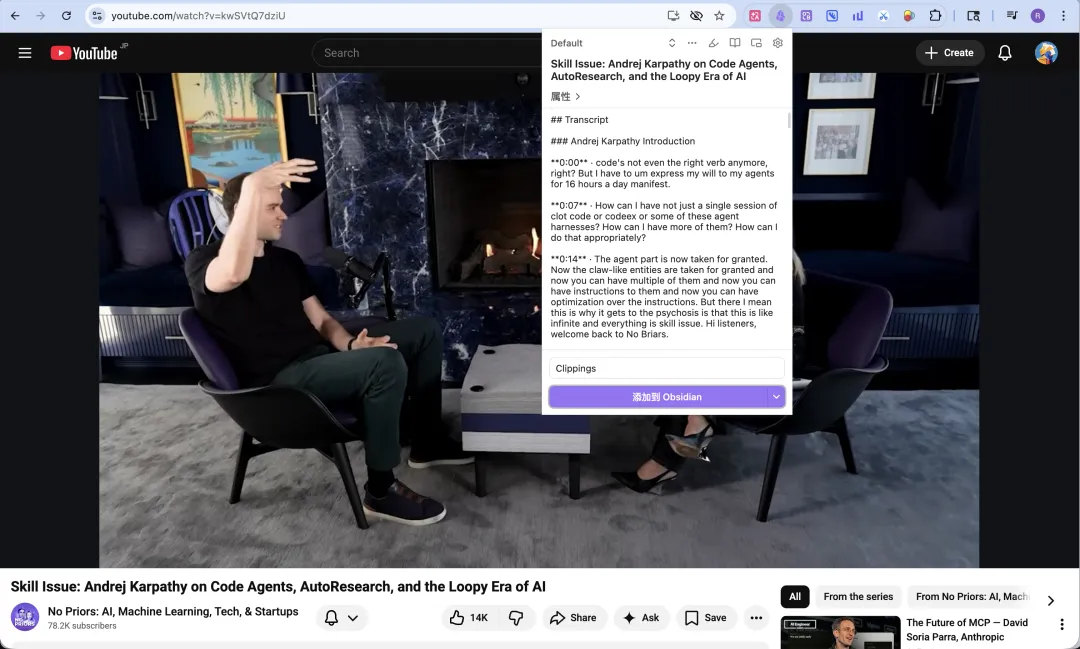
唔止文字形態嘅網頁內容,佢仲可以一鍵拎到 YouTube 影片嘅文字稿。
所有內容,最終都會以 Markdown 格式保存落嚟。
Markdown 格式嘅文字內容,喺 AI 時代幾乎係硬通貨咁滯,因為 AI 可以無損理解,仲可以跨平台、保存得耐。
而呢啲,都仲只係呢個插件嘅基本操作。
想將 Obsidian Web Clipper 插件嘅價值最大化,咁下面呢幾個小技巧你一定試下。
技巧一:設定「解釋器」
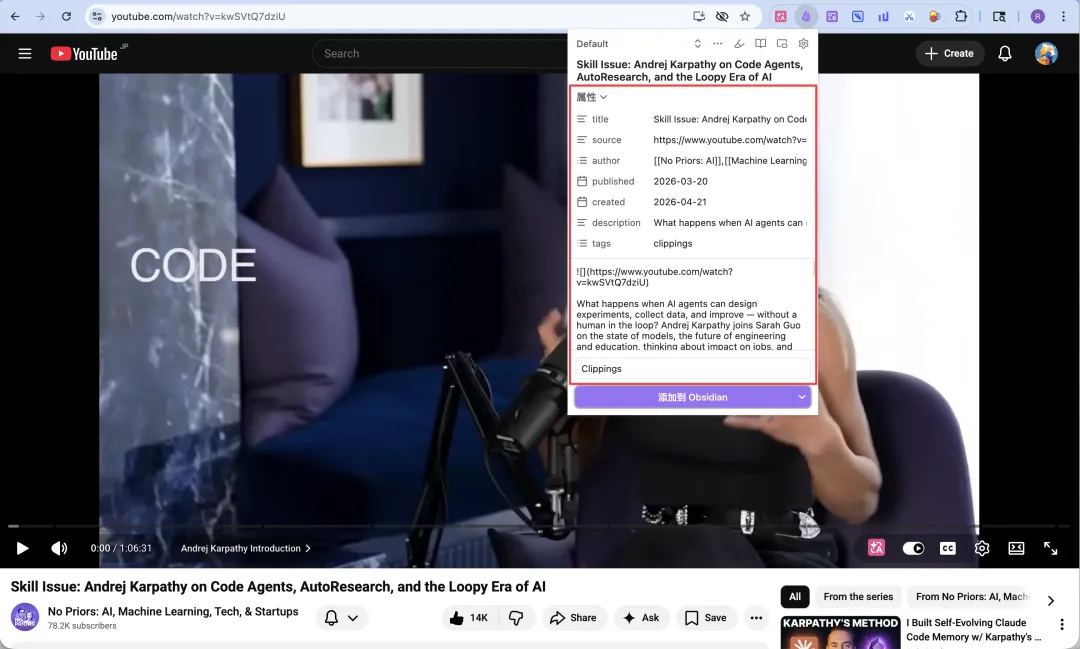
而家大多數人都係用 Obsidian Web Clipper 嘅預設模板,即係下圖,預設嘅屬性、筆記內容、筆記位置等,但係佢哋其實都可以根據自己嘅剪藏同閲讀需求做自訂;
喺呢啲自訂選項入面,「解釋器」最值得用。簡單嚟講,佢可以俾 Obsidian Web Clipper 引入 AI 能力,然後透過自然語言同網頁互動。
咁講可能仲有啲抽象,舉個例,我哋可以直接喺筆記內容入面加咁嘅一個變量:
{{"用繁體中文總結同提煉呢篇文章嘅核心內容。請用 Why How What 結構話俾讀者知呢篇文章點解值得睇,風格類似作家 Paul Graham"}}
咁樣我哋就可以先拎到文章或影片嘅 AI 總結,再根據 AI 總結嘅內容決定係咪要剪存到 Obsidian 度。
呢度簡單介紹下「變量」呢個編程概念。
大家平時應該都會填啲申請表,例如表上面寫住:
姓名:
__________電話:
__________
呢度嘅「姓名」同「電話」就係變量。
我填嘅時候,「姓名」變量嘅值就係「Next蔡蔡」。
馬斯克填嘅時候,「姓名」變量嘅值就係「馬斯克」。
變量定義咗數據嘅類型(呢度應該填名),而具體填啲乜取決於使用者。
返去 Obsidian Web Clipper 嘅語境,當你寫低 {{ "用簡體中文總結和提煉這篇文章的核心內容" }} 嗰陣,你就創建咗一個解釋器變量。佢同普通變量嘅分別係咁:
普通變量: 比如
{{title}},插件直接從網頁代碼度「摳」個標題俾你,唔經大腦。解釋器變量: 插件將網頁內容發俾 AI,AI 讀明之後,將計算/思考完嘅結果填返呢個位。
有了解釋器之後,Obsidian Web Clipper 就唔止剪存網頁內容,仲可以用喺翻譯、提取特定文字片段、格式轉換等場景,只要我哋可以用自然語言描述清楚就得。
咁佢具體要點樣設定呢?都唔複雜
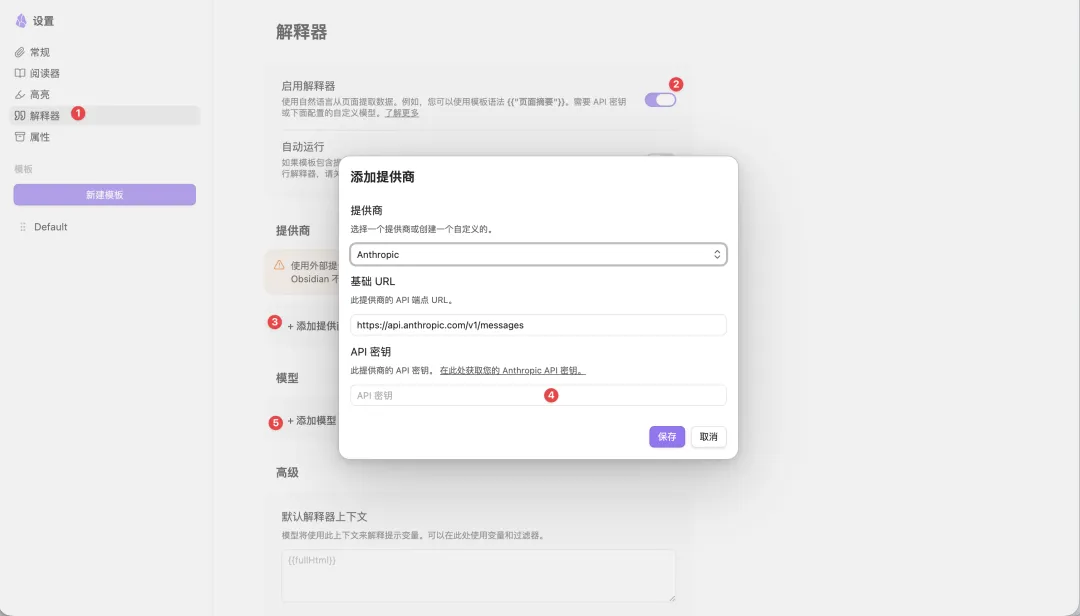
㩒 Obsidian Web Clipper 插件面板右上角嘅「設定」icon,喺開咗嘅「設定」頁面揀「解釋器」;
㩒「啟用解釋器」;
㩒「+添加提供商」,可以喺內置嘅模型提供商入面揀,亦支援自訂;
確定模型提供商之後,就可以揀模型。我實測對比過國內外多個模型之後,最後揀咗 Gemini-3-Flash,因為又快又準。如果揀大模型嘅話,處理時間會長好多
技巧二:設定模板觸發條件
如果你設定咗唔同嘅自訂模板,咁呢個技巧一定要用。
喺「編輯模板」設定頁面最頂,有個「模板觸發器」俾你設定 URL。點用呢?
舉個例,你有影片、公眾號文章兩個模板。
就可以俾影片模板設定呢兩條 URL:
https://www.youtube.com/watch
https://www.bilibili.com/video
俾公眾號文章設定呢條 URL:
https://mp.weixin.qq.com/s咁當你喺 YouTube 影片或 B 站影片頁面打開插件時,插件面板默認打開嘅就係影片模板,公眾號頁面都係咁。慳返來回切換嘅麻煩。
技巧三:高亮文字
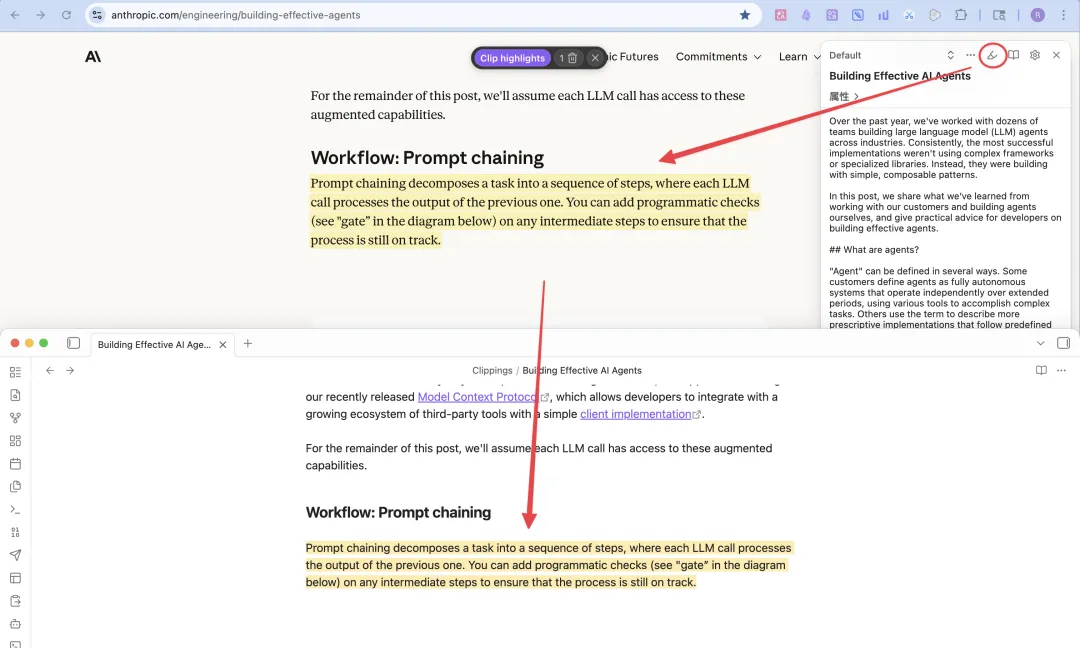
當你喺度睇網誌或者影片文字稿嘅時候,見到啲令自己好驚喜或者有啟發嘅內容,可以㩒插件嘅「高亮」功能,咁你就可以直接劃重點,唔使跳出當前網頁。
所有高亮嘅文字,最後都會同步到 Obsidian 文檔入面,你唔使二次整理。
技巧四:沉浸式翻譯 + Obsidian Web Clipper
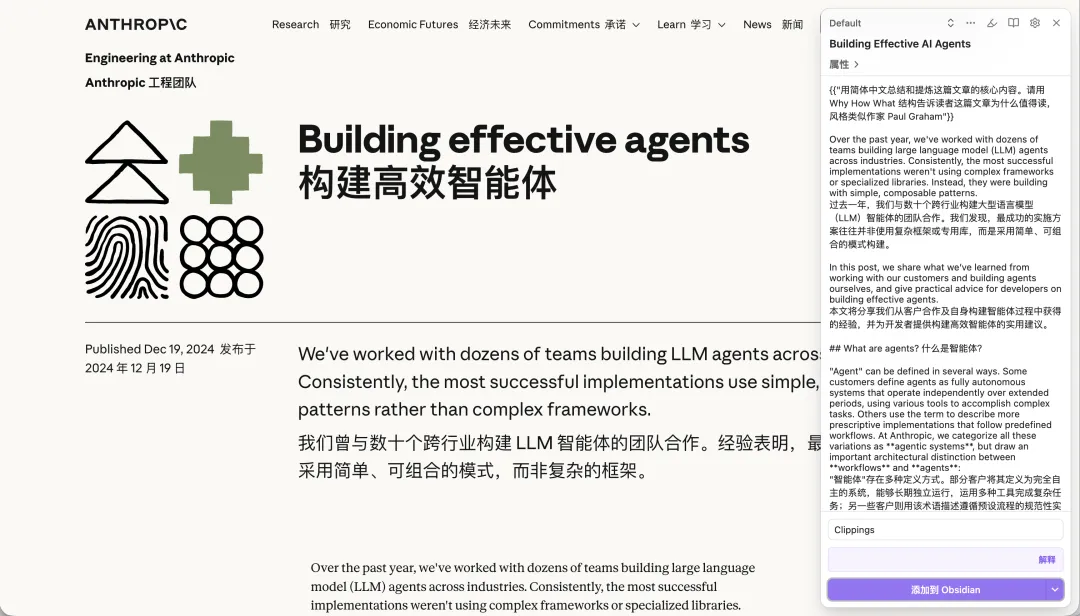
如果你平時好習慣用沉浸式翻譯做頁面翻譯,咁你可以唔使喺 Obsidian Web Clipper 入面另外設定一個翻譯解釋器,而係喺沉浸式翻譯嘅頁面直接打開 Obsidian Web Clipper。
然後你就會發現,Obsidian Web Clipper 可以同時拎到原文同翻譯。
二、點樣用中文增強版 Obsidian Web Clipper?
用好前面幾個技巧,基本上將原版 Obsidian Web Clipper 嘅價值挖掘到 70-80%。
但如果你平時仲要成日同 B 站影片、飛書文檔打交道,咁原版就唔夠用,因為佢唔支援 B 站影片文字稿同飛書文檔嘅處理。
咁大家可以用呢個中文內容增強嘅插件:obsidian-clipper-cn,佢有齊原版插件嘅所有能力,仲額外支援 B 站影片同飛書文檔:
🔗:https://github.com/nextcaicai/obsidian-clipper-cn
B 站影片支援
obsidian-clipper-cn 對 B 站影片嘅支援體驗,同官方嘅 YouTube 集成基本一致,包括:
內容提取 — 從影片頁面提取影片簡介、章節同字幕
影片嵌入 — 喺 Reader Mode 入面嵌入 Bilibili 播放器,支援置頂固定
時間戳㩒跳轉 — 㩒任何字幕或章節嘅時間戳,影片跳轉到對應時間
自動滾動 — 播放過程中自動滾動字幕,跟住播放進度
高亮當前行 — 播放時高亮顯示當前字幕行
可以搭配前面提到嘅解釋器技巧一齊用,效果更佳。
飛書文檔支援
原版 Obsidian Web Clipper 插件係透過通用 DOM 解析提取飛書文檔內容,但會因為飛書嘅動態渲染機制令內容唔完整。
obsidian-clipper-cn 透過接入飛書開放平台 API,用結構化接口完整拎到文檔內容。
不過而家有啲不足,就係拎唔到文檔圖片,遲啲我再睇下呢個問題可唔可以解決。
用 obsidian-clipper-cn 插件拎飛書文檔嘅方法都唔難:
前往飛書開放平台(https://open.feishu.cn/app)開一個自建應用,如果你哋之前有將龍蝦接入過飛書,咁應該會好熟成個流程;
跟住俾應用開通以下權限:
docx:document:readonly、wiki:node:read,開通完記得要啟用應用先可以繼續下一步;
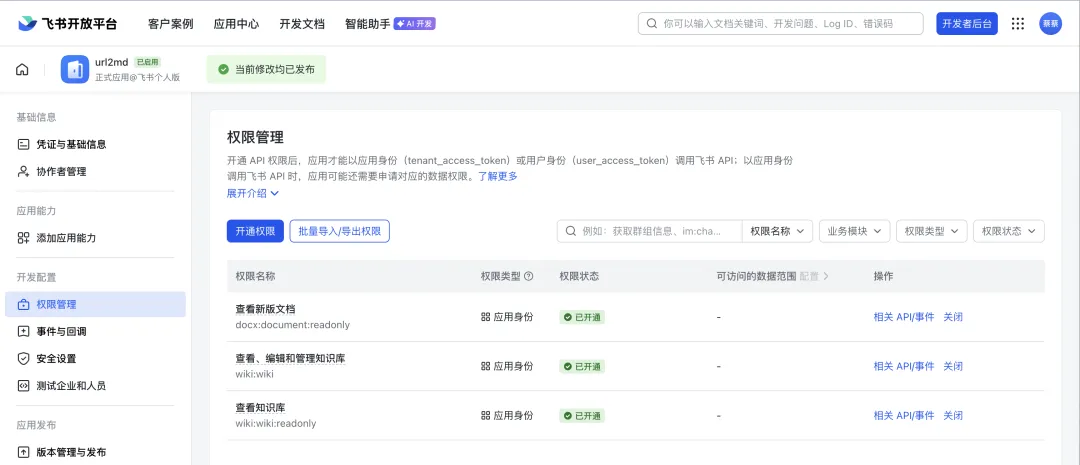
跟住你就可以喺「憑證與基礎信息」度拎到應用嘅 App ID 同 App Secret(官方文檔有非常詳細嘅介紹>>>https://open.feishu.cn/document/server-docs/api-call-guide/calling-process/get-access-token#63c75bdc,呢度唔重複)
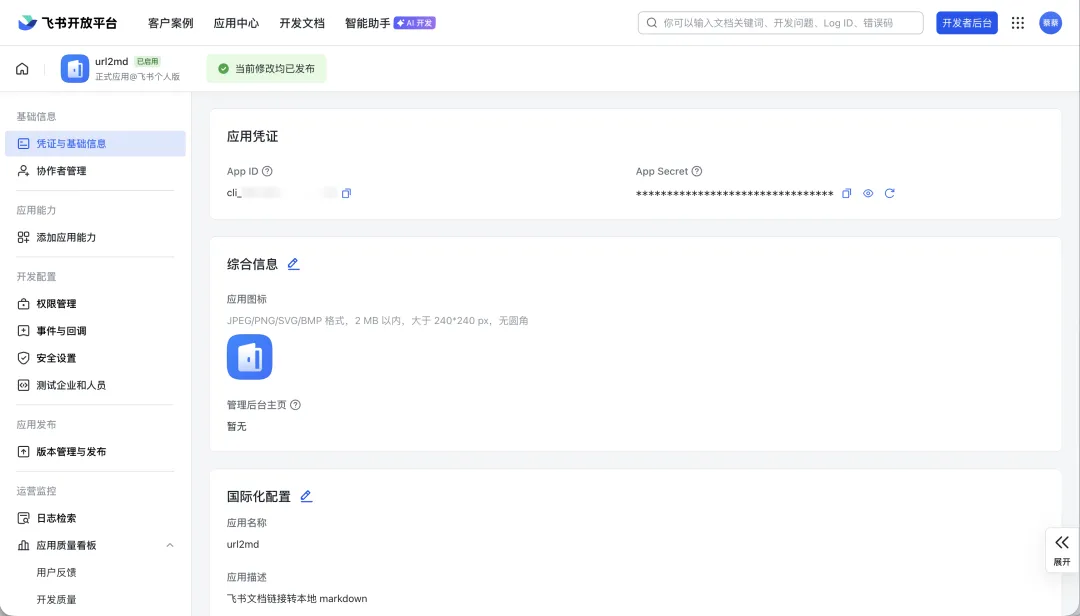
最後,打開 obsidian-clipper-cn 插件,㩒右上角「設定」,喺開咗嘅「設定-常規」頁面最底揾到「飛書 / Lark」模塊,填入前面拎到嘅 App ID 同 App Secret
私隱說明:App ID 同 App Secret 只會保存喺你本地瀏覽器嘅儲存入面(
browser.storage.local),唔會上傳到任何服務器。
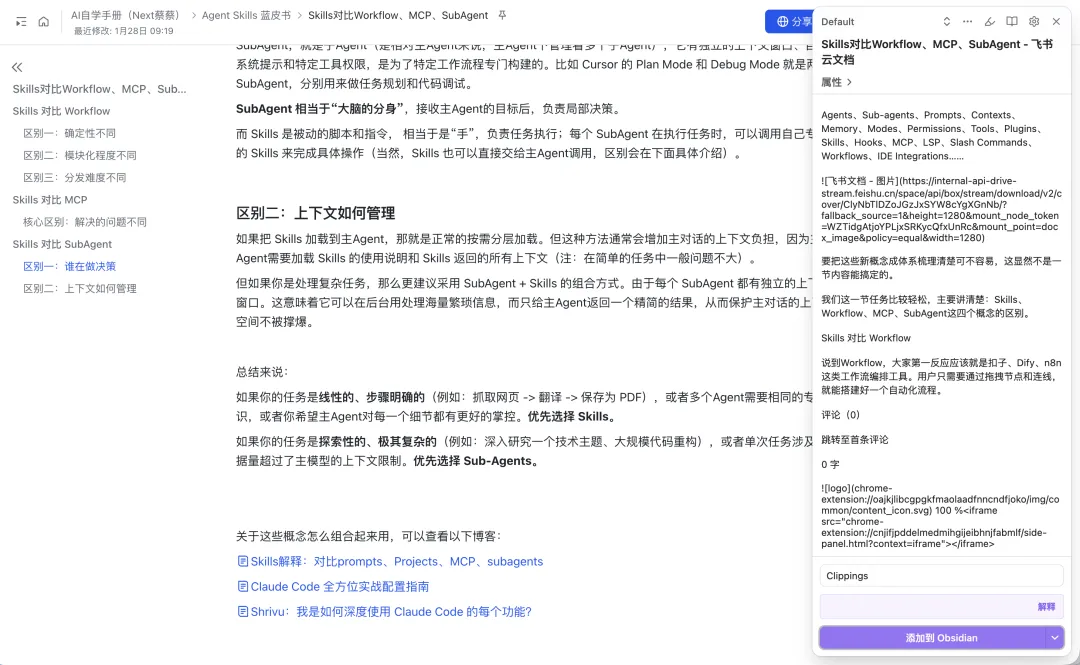
大家可能會問,點解我唔將呢兩個渠道嘅支援合併到原項目度。
其實我一開始有試過喺官方項目度提交 PR 合併,但係冇通過。Obsidian CEO 駁回嘅理由係:Obsidian Web Clipper 只處理從 Defuddle 處理完嘅內容。
後來我就諗住喺 Defuddle 項目度提交 PR,但因為冇辦法喺本地驗證自己嘅 PR 喺 Defuddle 嘅真實服務器度係咪成功,所以最後冇提交,而係基於 Obsidian Web Clipper 做咗個中文內容增強嘅插件,即係大家而家見到嘅 obsidian-clipper-cn。
🔗:https://github.com/nextcaicai/obsidian-clipper-cn
歡迎大家試用,中間如果遇到啲體驗上或功能上嘅不足,可以提 Issues,或者直接喺度留言反饋。
**聲明:呢個插件已經開源,淨係用嚟學習,唔好攞嚟做其他用途。
之前分享了 Karpathy 搭建 AI 知識庫的方法,其中簡單帶過了 Obsidian Web Clipper 這個剪存插件。
🔗:https://github.com/obsidianmd/obsidian-clipper
它本身非常好用,很多網頁內容甚至 YouTube 視頻字幕都能一鍵剪存到 Obsidian 中,我在知識星球裏就多次分享過。不過它對一些中文內容還不支持,於是我就給它做箇中文增強,現在支持B站視頻字幕+飛書文檔。
🔗:https://github.com/nextcaicai/obsidian-clipper-cn
這篇文章就是分享我是怎麼玩轉 Obsidian Web Clipper 的,分為兩部分:
如何“榨乾”原版 Obsidian Web Clipper ?
如何使用中文增強版 Obsidian Web Clipper ?
一、如何“榨乾”原版 Obsidian Web Clipper ?
Obsidian Web Clipper 是 Obsidian 官方推出的瀏覽器插件,可以讓你一鍵將網頁內容保存到 Obsidian 中。
比如我想保存 Anthropic 這篇乾貨博客,直接喚起 Obsidian Web Clipper 插件,就會看到博客的全部內容都已經在插件面板裏了,點擊“添加到 Obdsidian”,就可以一鍵添加到 Obsidian 知識庫中。
不只文本形態的網頁內容,它還可以一鍵獲取 YouTube 視頻裏的文字稿。
所有的內容,最終都會以 Markdown 格式保存下來。
Markdown 格式的文本內容,在 AI 時代幾乎就是硬通貨的存在,因為 AI 能無損理解,而且還能跨平台、保存還久。
而這些,還都只是這個插件的基操。
想要把 Obsidian Web Clipper 插件的價值最大化,那麼下面這幾個小技巧你們一定要試試。
技巧一:配置“解釋器”
目前大多數人都是用 Obsidian Web Clipper 的默認模板,也就是下圖,默認的屬性、筆記內容、筆記位置等,但它們其實都可以根據自己的剪藏和閲讀需求做自定義;
在這些自定義選項中,“解釋器”最值得用起來。簡單來說,它可以給 Obsidian Web Clipper 引入 AI 能力,然後通過自然語言和網頁交互。
這麼說可能還是有點抽象,舉個例子,我們可以直接在筆記內容中添加這麼一個變量:
{{"用簡體中文總結和提煉這篇文章的核心內容。請用 Why How What 結構告訴讀者這篇文章為什麼值得讀,風格類似作家 Paul Graham"}}
這樣我們就可以先獲取文章或視頻的 AI 總結,再根據 AI 總結的內容決定是否要剪存到 Obsidian 中。
這裏簡單介紹下“變量”這個編程概念。
大家平時應該都會填一些申請表時,比如表上面寫着:
姓名:
__________電話:
__________
這裏的“姓名”和“電話”就是變量。
我填的時候,“姓名”變量的值就是“Next蔡蔡”。
馬斯克填的時候,“姓名”變量的值就是“馬斯克”。
變量定義了數據的類型(這裏該填名字),而具體填什麼取決於使用者。
回到 Obsidian Web Clipper 的語境,當你寫下 {{ "用簡體中文總結和提煉這篇文章的核心內容" }} 時,你就創建了一個解釋器變量。它和普通變量的區別是這樣的:
普通變量: 比如
{{title}},插件直接從網頁代碼裏“摳”出標題給你,不帶腦子。解釋器變量: 插件把網頁內容發給 AI,AI 讀懂後,把計算/思考後的結果填回這個位置。
有了解釋器後, Obsidian Web Clipper 就不只是剪存網頁內容,還可以用在翻譯、提取特定文本片段、格式轉換等場景,只要我們能用自然語言描述清楚就可以實現。
那它具體該怎麼配置呢?也不復雜
點擊 Obsidian Web Clipper 插件面板右上角的“設置”icon,在打開的“設置”頁面中選擇“解釋器”;
點擊“啓用解釋器”;
點擊“+添加提供商”,可以在內置的模型提供商中選擇,也支持自定義;
確定模型提供商後,就可以選擇模型了。我在實測對比國內外多個模型後,最終選擇了Gemini-3-Flash,因為快且準。要是選大模型的話,處理時間會拉長不少
技巧二:設置模板觸發條件
如果你設置了不同的自定模板,那這個技巧一定要用上。
在“編輯模板”配置頁面頂部,有個“模板觸發器”讓你配置 URL。怎麼用呢?
舉個例子,你有視頻、公眾號文章兩個模板。
就可以給視頻模板配置上這兩條 URL:
https://www.youtube.com/watch
https://www.bilibili.com/video
給公眾號文章配置上這條 URL:
https://mp.weixin.qq.com/s這樣當你在 YouTube 視頻或 B 站視頻頁面打開插件時,插件面板默認打開的就是視頻模板,公眾號頁面同理。省去來回切換的麻煩。
技巧三:高亮文本
當你在閲讀博客或者視頻文字稿的過程中,看到一些讓自己很驚喜或受啓發的內容,可以點擊插件的“高亮”功能,這樣你就可以直接劃重點,而不用跳出當前網頁。
所有高亮的文本,最後都會同步到 Obsidian 文檔中,你就不用二次整理了。
技巧四:沉浸式翻譯 + Obsidian Web Clipper
如果你平常很習慣用沉浸式翻譯做頁面翻譯,那麼月可以不用在 Obsidian Web Clipper 中單獨配置一個翻譯解釋器,而是在沉浸式翻譯的頁面直接打開 Obsidian Web Clipper。
然後你就會發現,Obsidian Web Clipper 是可以將同時獲取原文和翻譯的。
二、如何使用中文增強版 Obsidian Web Clipper ?
用好前面幾個技巧,基本能把原版 Obsidian Web Clipper 的價值挖掘到 70-80%。
但如果你平常還需要經常和 B 站視頻、飛書文檔打交道,那麼原版就不夠用了,因為它不支持 B 站視頻文字稿和飛書文檔的處理。
那麼大家可以使用這個中文內容增強的插件:obsidian-clipper-cn,它既有原版插件的所有能力,還額外支持 B 站視頻和飛書文檔:
🔗:https://github.com/nextcaicai/obsidian-clipper-cn
B 站視頻支持
obsidian-clipper-cn 對 B 站視頻的支持體驗,和官方的 YouTube 集成基本保持一致,包括:
內容提取 — 從視頻頁面提取視頻簡介、章節和字幕
視頻嵌入 — 在 Reader Mode 中嵌入 Bilibili 播放器,支持置頂固定
時間戳點擊跳轉 — 點擊任意字幕或章節的時間戳,視頻跳轉到對應時間
自動滾動 — 播放過程中自動滾動字幕,跟隨播放進度
高亮當前行 — 播放時高亮顯示當前字幕行
可以搭配前面提到的解釋器技巧一起用,效果更佳。
飛書文檔支持
原版 Obsidian Web Clipper 插件是通過通用 DOM 解析提取飛書文檔內容,但會因為飛書的動態渲染機制導致內容不完整。
obsidian-clipper-cn 通過接入飛書開放平台 API,通過結構化接口完整獲取文檔內容。
不過目前有個不足,無法獲取文檔圖片,後續我再看看這個問題能否解決。
使用 obsidian-clipper-cn 插件獲取飛書文檔的方法也不難:
前往飛書開放平台(https://open.feishu.cn/app)創建一個自建應用,如果你們之前有把龍蝦接入過飛書,那應該會很熟悉下面整個流程;
接着給應用開通以下權限:
docx:document:readonly、wiki:node:read,開通完記得要啓用應用才能推進後續步驟;
接着你就可以在“憑證與基礎信息”這裏獲取應用的 App ID 和 App Secret(官方文檔有非常詳細的介紹>>>https://open.feishu.cn/document/server-docs/api-call-guide/calling-process/get-access-token#63c75bdc,這裏就不贅述了)
最後,打開 obsidian-clipper-cn 插件,點擊右上角“設置” ,在打開的“設置-常規”頁面底部找到“飛書 / Lark”模塊,填入前面獲取到的 App ID 和 App Secret
隱私說明:App ID 和 App Secret 僅保存在你本地瀏覽器的存儲中(
browser.storage.local),不會上傳到任何服務器。
大家可能會有疑問,我為什麼不把這兩個渠道支持合併到原項目中。
其實我一開始有試過在官方項目中提了 PR 合併,不過沒通過。Obsidian CEO 駁回的理由是:Obisidian Web Clipper 只處理從 Defuddle 處理後的內容。
後來我就想着在 Defuddle 項目上提 PR,但由於沒法在本地驗證自己的 PR 在 Defuddle 的真實服務器中是否成功,所以最後沒提交,而是基於 Obisidian Web Clipper 做了箇中文內容增強的插件,也就是大家現在看到的 obsidian-clipper-cn。
🔗:https://github.com/nextcaicai/obsidian-clipper-cn
歡迎大家體驗,中間如果遇到一些體驗上或功能上的不足,可以提 Issues,或者直接在這裏留言反饋。
**聲明:該插件已開源,僅用於學習,勿作他用。