如何用Skill做競品調研?
整理版優先睇
用Skill做競品調研,關鍵係自己準備高質材料(用戶手冊、PRD),再畀AI做逐條對比,而唔係叫AI自己去網上揾料。
呢篇文章係一位B端SaaS產品經理分享佢用AI Skill做競品調研嘅經驗。佢一開始好天真,諗住輸入競品名稱,AI就會自動去網上抓取資訊,分析出產品路線圖同戰略變化。結果出嚟嘅報告係基於公開營銷軟文、發版通稿拼湊,資訊不可靠、滯後,分析仲係正確嘅廢話。佢先至明白—AI冇腿,跑唔到市場;佢需要嘅唔係「調研員」,而係一個消化已整理材料嘅工具。
於是佢轉變思路:自己收集競品官網嘅更新日誌、用戶手冊、財務報表,再加上自己負責模塊嘅PRD,然後定義分析粒度—每次只聚焦一個模塊或專項能力,避免資訊過載。佢仲喺Skill入面加入「材料可信度分級」指令,話畀AI用戶手冊係最可靠證據,更新日誌要注意過濾營銷話術。最後佢鎖死輸出結構,要求全部用Markdown表格,按固定順序輸出六個板塊:競品演進路線圖、重點功能與資源投入分佈、背後企業戰略洞察、對自身產品規劃嘅啓示、核心功能說明、差異化對比。
透過呢個方法,佢成功用AI快速對比兩家競品嘅智能排班能力,發現幾個關鍵差異:競品A走數據驅動路線,競品B深耕本土化規則;競品A覆蓋複雜用工場景更廣,競品B喺「大小周」呢類高頻場景做得更細。呢啲發現直接影響咗佢嘅產品優先級判斷。整體結論係:AI增強對比能力,但唔替代調研工作;你要畀AI高質材料同判斷標準,先至可以得到真正有價值嘅洞察。
- AI做競品調研唔可以靠AI自己上網揾料,資訊淺層且誤導;正確方法係自己準備用戶手冊、PRD等真材實料。
- 定義分析粒度:每次只聚焦一個模塊或專項能力,資訊更集中,分析更深,結論更直接。
- 設定判斷標準:話畀AI每份材料嘅可信度(用戶手冊最可靠,更新日誌要過濾營銷話術),將自身調研經驗傳授畀AI。
- 鎖死輸出結構:要求全部用Markdown表格,按固定順序輸出六個板塊,降低二次加工成本,強制執行分析框架。
- 競品調研結果可以餵畀其他Skill(如需求優先級判斷),融入產品決策工作流,令分析唔再係「做完就放一邊」嘅報告。
競品分析Skill核心指令
你要話畀Skill:每份材料嘅身份(我哋嘅PRD、競品A手冊、競品B手冊、更新日誌)同可信度分級,同埋分析要求—以我方PRD為錨點,逐條對比,要具體到功能點差異,重點關注「你有我冇」或「實現方式根本不同」嘅位。輸出必須全部用Markdown表格,按固定順序輸出六個板塊。
競品調研分析框架輸出結構
六個板塊順序:1. 競品演進路線圖(時間線精細到季度,用財報數據印證);2. 重點功能與產研資源投入分佈(按核心重倉/創新新增分類);3. 背後企業戰略洞察(從客羣、國際化、AI三個維度,要求產品功能迭代同財報數據雙重支撐);4. 對自身產品規劃嘅啓示(分防禦性基建P0/P1同差異化突破進攻兩類);5. 核心功能說明(逐條盤點所有提取功能);6. 差異化對比(多競品時輸出,突出核心差異點)。
第一次嘗試:叫AI自己去「調研」,結果中伏
作者一開始好天真,建咗個Skill,輸入競品名稱就等AI自動分析。AI好快俾咗份報告,格式漂亮,有表格有分類,但逐條驗證就發現問題:資訊來源係營銷推文,滯後半年,而且分析全部係正確嘅廢話。
AI唔係調研員,佢冇腿,跑唔到市場。
佢先至明白—如果俾AI嘅資訊本身就係淺層、片面、誤導性嘅,咩分析都係「喺沙子上建城堡」。
第二次嘗試:自己準備「真材實料」,定義分析粒度
作者換咗個思路:與其叫AI自己揾料,不如自己收集好資訊,再叫AI幫手消化。佢列出三個最實在嘅資訊源:競品官網嘅更新日誌、用戶手冊、財務報表。
用戶手冊係被嚴重低估嘅競品資訊源
手冊直接話畀你競品實際交付咗咩功能、操作流程、配置項,資訊密度極高。佢仲定義分析粒度:每次只聚焦一個模塊或專項能力,唔好貪多求全。
- 1 明確需要咩資訊:更新日誌睇迭代信號,用戶手冊睇功能細節,財報睇戰略重心。
- 2 定義分析粒度:每次只睇一個模塊,例如「智能排班」,資訊集中,分析更深。
- 3 將材料「喂」俾Skill,同時話畀佢材料嘅可信度—用戶手冊最可靠,更新日誌要過濾營銷話術。
你俾AI嘅唔應該只係任務說明,更應該係判斷標準
鎖死輸出結構,並用真實案例驗證
作者仲喺Skill入面鎖死咗一套輸出結構,要求全部用Markdown表格,按固定順序輸出六個板塊。咁樣做降低咗二次加工成本,仲強制AI執行一個分析框架。
佢用一個真實案例展示效果:分析兩個競品嘅智能排班能力,AI快速對比後提出四個發現,每一個都直接影響產品決策。
- 發現一:競品A走數據驅動路線(業務預測模塊),競品B走規則引擎路線(循環模板、智能對班),背後反映目標客羣唔同。
- 發現二:競品A嘅多維度排班同劃線排班覆蓋咗大量複雜用工場景,我哋目前唔支持,未來向連鎖門店拓展會有硬傷。
- 發現三:競品B喺本土化規則(如大小周)做得更細,呢個係中腰部客戶揀排班工具嘅關鍵決策因素。
- 發現四:從更新日誌睇到兩家競品資源投入節奏唔同,競品A進入打磨期,競品B仲喺能力補齊階段。
呢四個發現,每一個都可以直接轉化為產品決策輸入
經驗總結:AI係增強工具,唔係替代品
作者總結五個重要經驗,核心係:AI做競品調研,本質係增強你嘅對比能力,而唔係替代你嘅調研工作。你依然要負責收集、判斷,AI只係幫你快速消化。
聚焦比全面更重要—每次只分析一個模塊,AI嘅分析深度明顯提升
另外,要俾AI判斷標準(材料可信度分級),而唔係淨係任務要求。仲可以將競品調研Skill同其他Skill組合使用,例如將分析結果餵俾需求優先級判斷Skill,融入工作流。
- 1 AI增強對比能力,唔替代調研—你要準備高質材料。
- 2 聚焦比全面更重要—每次只分析一個模塊或專項能力。
- 3 用戶手冊係被低估嘅競品資訊源—資訊密度高,直接反映產品實際交付。
- 4 俾AI判斷標準,而唔係淨係任務—將自身調研經驗傳授畀AI。
- 5 競品調研Skill可以同其他Skill組合使用—融入產品決策工作流。
你而家俾AI嘅,係隨手搜嚟嘅營銷通稿,定係自己花時間整理過嘅用戶手冊同需求文檔?
在上一篇《用Skill做產品規劃?聊聊我踩過的三個坑》裏,我提到過的第二個坑:過度迷信AI對"私有化數據"的抓取能力。
當時做競品分析,我一開始的想法很豐滿——輸入競品名稱,AI就能自動去網上抓取他們最近1-2年的升級日誌和財務報表,自動給我分析出一份產品路線圖和戰略變化。
結果呢?它確實給我輸出了一篇洋洋灑灑的內容。但仔細一看,基本全是基於網上公開的營銷軟文、發版通稿、甚至發佈會公關稿拼湊出來的。對於產品底層究竟是怎麼迭代的,幾乎沒有任何參考價值。
那篇文章裏,我只簡單說了結論——"迴歸外腦定位,把人工整理的競品日誌作為原材料投餵給AI"。
但有夥伴看完之後私信我:具體怎麼喂?喂什麼?Skill怎麼寫?能不能展開講講?
所以今天這篇文章,就專門把這個話題掰開揉碎了聊。
先說一個殘酷的現實
做競品調研這件事,產品經理應該都不陌生。
傳統的做法,大致是這樣一條鏈路:確定競品範圍 → 收集競品信息(官網、行業報告、用戶評價、用戶手冊)→ 整理競品功能清單 → 分析產品路線圖 → 輸出競品調研報告
這裏面,最耗時的不是"分析",而是"收集"和"整理"。
你可能要花兩三天時間,把北森、薪人薪事、飛書這些競品的官網翻個遍,把他們的更新日誌一條條扒下來,把用戶手冊裏跟自己負責的模塊相關的章節截圖保存,最後才能開始真正有價值的分析工作。
所以當我第一次嘗試用AI做競品調研的時候,我的期待很簡單:能不能把"收集和整理"這件事交給AI,讓我直接進入"分析"環節?
事實證明,這個期待本身就沒問題。問題出在我對AI能力的誤判上。
第一次嘗試:讓AI自己去"調研"
我當時的做法,現在回想起來,確實有點天真。
我建了一個Skill,輸入的內容大概是這樣的:
"請分析以下競品(北森、薪人薪事、飛書人事)最近兩年的產品迭代情況,包括:1. 主要功能更新;2. 產品戰略方向變化;3. 對我們產品的啓示。"
然後我就等着它給我一份"競品分析報告"。
它確實給了。而且給得很快,格式也很漂亮,有表格、有分類、甚至還有"戰略建議"。
但當我逐條去驗證的時候,問題就暴露了。
第一,信息來源不可靠。它引用的"北森2025年Q3更新",實際上是北森公眾號的一篇營銷推文,標題寫着"全新升級",但內容只是換了個UI皮膚。它卻把這個解讀成了"北森在重新設計核心交互架構"。
第二,信息嚴重滯後。它引用的一些"最新動態",實際上已經是半年前的舊聞了。對於SaaS產品來說,半年的迭代可能已經翻天覆地。
第三,分析全是正確的廢話。"建議關注競品的用戶體驗優化方向"、"建議加強移動端能力"——這種話,不說我也知道。
說白了,它給我的不是"競品調研報告",而是一份"基於公開營銷信息的拼湊稿"。
那一刻我才真正理解了一件事:AI不是調研員,它沒有腿,跑不了你的市場。
它能做的,是基於你給它的信息或公開信息,進行結構化的分析和推理。但如果你給它的信息本身就是淺層的、片面的、甚至誤導性的,那它的分析再漂亮,也不過是"在沙子上建城堡"。
第二次嘗試:給它"真材實料"
踩完這個坑之後,我換了一個思路。
與其讓AI自己去網上"找"信息,不如我自己把信息找好,整理好,然後讓AI來幫我"消化"。
這個思路的轉變,看似退了一步,實際上是進了一大步。
具體怎麼做呢?
第一步,明確我需要什麼信息,以及從哪獲取。
說實話,做B端SaaS的競品調研,你真正需要的信息來源其實很有限,但每一個都很實在:
競品官網的更新日誌
——這是最直接的迭代信號。哪個模塊在持續更新、更新頻率如何、最近加了什麼新功能,一目瞭然。需要登錄才能看到的部分,我手動截圖保存
競品的用戶手冊
——這是最被低估的競品信息源。手冊裏寫了什麼功能、操作流程是什麼、支持哪些配置項——這等於競品把自己的"產品說明書"直接遞到了你手上。手冊裏沒提到的功能,至少說明不是他們的重點
競品的財務報表
——這個不是每次分析都需要,但當你想判斷競品的戰略重心時,財報數據(營收增速、研發投入佔比)是一個很好的輔助參考
你可能會問:行業報告呢?競品的招聘信息呢?公眾號推送呢?
我的經驗是:這些信息看起來很"豐富",但對產品經理的實際決策幫助有限。行業報告通常是宏觀視角,落到具體模塊的對比上粒度不夠;招聘信息能看出方向但驗證成本太高;公眾號推送裏營銷噪音太多,過濾的精力不如直接去看更新日誌。
與其貪多求全,不如把有限的精力集中在三個最實在的信息源上。
第二步,定義分析粒度——不要試圖"全面分析",要"精準打擊"。
這是我踩的第二個坑。
一開始,我每次做競品調研都想"全面瞭解"一個競品——從考勤到排班到薪酬到績效,恨不得把對方的產品翻個底朝天。
我給Skill餵了競品A四個模塊的用戶手冊,加起來快100頁,然後讓它"全面分析"。
結果就是:信息量太大,AI的分析變得又淺又泛,什麼都提到了,但什麼都沒說透。
後來我換了一個策略:每次只聚焦一個模塊或一個專項能力。
比如這次只分析"智能排班"這個專項能力,下次只看"國際化"做得怎麼樣。
這樣做的好處是:信息更聚焦,AI的分析深度明顯提升,而且產出的結論可以直接對接到我負責的具體模塊上,不用再二次加工。
第三步,把信息"喂"給Skill——但不是簡單丟進去就完事。
這一步很關鍵。你要告訴Skill的不只是"這些是什麼材料",更要告訴它"這些材料分別有多可信,以及我希望你怎麼用它們"。
我的競品分析Skill裏,有一段很核心的指令:
"分析要求:以我方PRD為錨點,逐條對比兩家競品用戶手冊中的對應功能。不要給我'競品在持續創新'這種正確的廢話,我要的是'競品A支持了XX種規則,競品B只支持XX種,我們目前支持XX種'這種具體到功能點的差異。重點關注'你有我沒有'或'實現方式根本不同'的核心差異點。"
你看,這段指令的本質,不是在告訴AI"做什麼",而是在告訴它"怎麼判斷"。
這又回到了我之前反覆強調的那個觀點:你給AI的不應該只是任務說明,更應該是你的判斷標準。
第四步,定義輸出結構——而且要"鎖死"格式。
光有信息和分析方向還不夠,你還得告訴它,你希望最終看到什麼樣的輸出。
這一點我踩過坑。一開始我沒定義輸出格式,Skill每次給我的報告結構都不一樣——有時候先講功能,有時候先講戰略,有時候表格和文字混着來。我每次看完都得自己重新整理一遍,反而增加了工作量。
後來我在Skill裏"鎖死"了一套輸出結構,要求它必須全部用Markdown表格呈現,而且必須按固定順序輸出六個板塊:
競品演進路線圖:時間線精細到季度,按階段梳理每個競品的產品路線和核心功能,並且要求用財報數據做印證說明
重點功能與產研資源投入分佈:把功能按"核心重倉"和"創新/新增"分類,標註迭代頻次和資源投入預估
背後企業戰略洞察:從客羣、國際化、AI三個維度分析競品戰略,要求每個洞察都有產品功能迭代和財報數據雙重支撐
對自身產品規劃的啓示:分"防禦性基建(P0/P1)"和"差異化突破(進攻)"兩類,給出具體的行動建議
核心功能說明:逐條盤點所有提取到的核心功能,不遺漏,包含功能簡要、解決場景、迭代時間線
差異化對比(多競品時輸出):重點突出"你有我沒有"或"實現方式根本不同"的核心差異點
為什麼要"鎖死"格式?兩個原因。
第一,降低你的二次加工成本。你拿到報告之後,不需要再重新排版、重新歸類,直接就能用。尤其是全表格輸出,複製到PPT或者飛書文檔裏,幾乎不用調整。
第二,讓Skill的分析更結構化。當你要求它必須按"路線圖→資源投入→戰略洞察→自身啓示→功能盤點→差異化對比"這個順序輸出時,它實際上是在被強制執行一個分析框架——先看時間線,再看資源分配,再推斷戰略,最後落到自己的行動上。這個框架本身就是一種分析質量的保障。
一個真實的案例
拿我最近做的一次競品調研來說。
當時我要分析兩個競品在"智能排班"這個專項能力上的情況。我準備的材料其實很簡單:
我們排班模塊的PRD(包含已上線功能和規劃中的需求)
競品A排班模塊的產品文檔(從對方官網下載的用戶手冊,包含循環排班、智能對班等功能的詳細說明)
競品B排班模塊的產品文檔(同樣來自官網)
兩家競品近兩年的更新日誌(從官網"版本記錄"頁面整理)
就這些。沒有行業報告,沒有招聘信息,沒有公眾號推送。
把這些材料餵給Skill之後,大概幾分鐘,它給了我一份結構化的對比分析報告。
它給我輸出的結果:

有幾個發現,確實是我之前沒有意識到的:
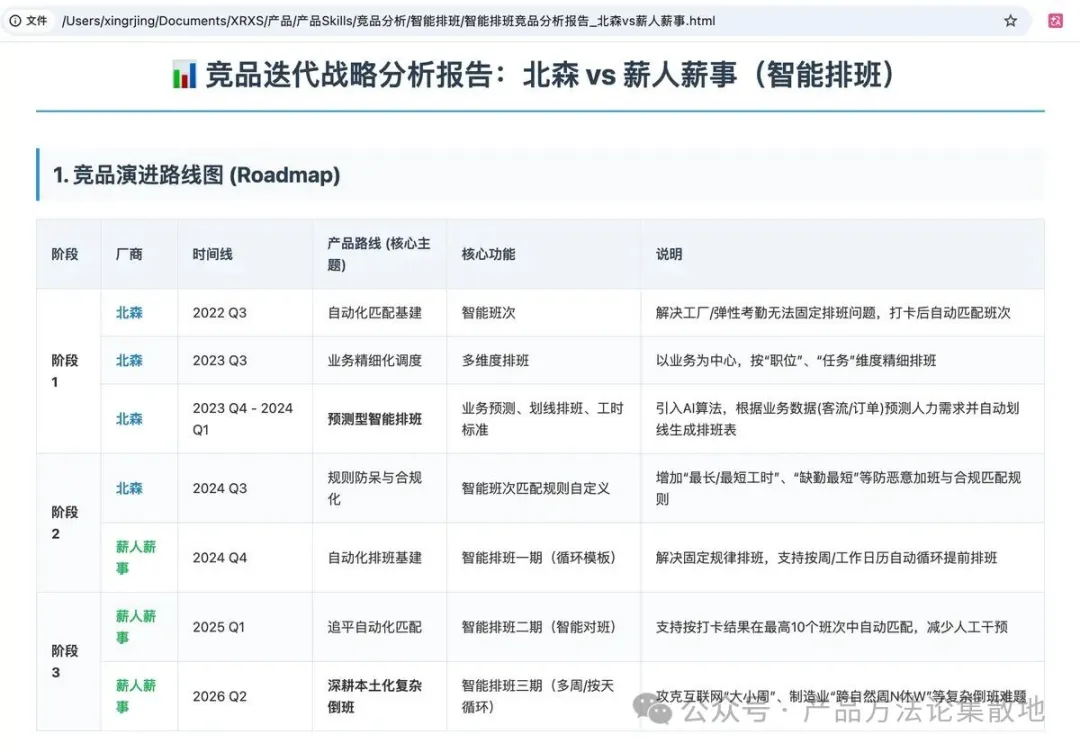
發現一:兩家競品走的是完全不同的技術路線。
競品A已經從"規則驅動"進化到了"數據驅動"——他們引入了業務預測模塊,能根據歷史客流、訂單數據預測未來的人力需求,然後自動生成排班表。說白了,他們的排班已經不只是"排班"了,而是WFM(勞動力管理)的一部分。
競品B則一直在深耕"規則引擎"——循環模板、智能對班、打卡自動匹配,全都是基於規則邏輯的自動化。他們最新一期甚至專門攻克了"大小周""跨自然周N休W"這類本土化極強的倒班場景。
這個差異背後,其實是兩家公司目標客羣的不同:競品A主攻大型連鎖和製造業大客,這些客戶對人力成本極度敏感,需要預測型排班;競品B深耕中腰部製造和互聯網企業,這些客戶的核心痛點是"排班規則太複雜,手工排太慢"。
發現二:競品A在"複雜用工場景"上的覆蓋度遠超我們。
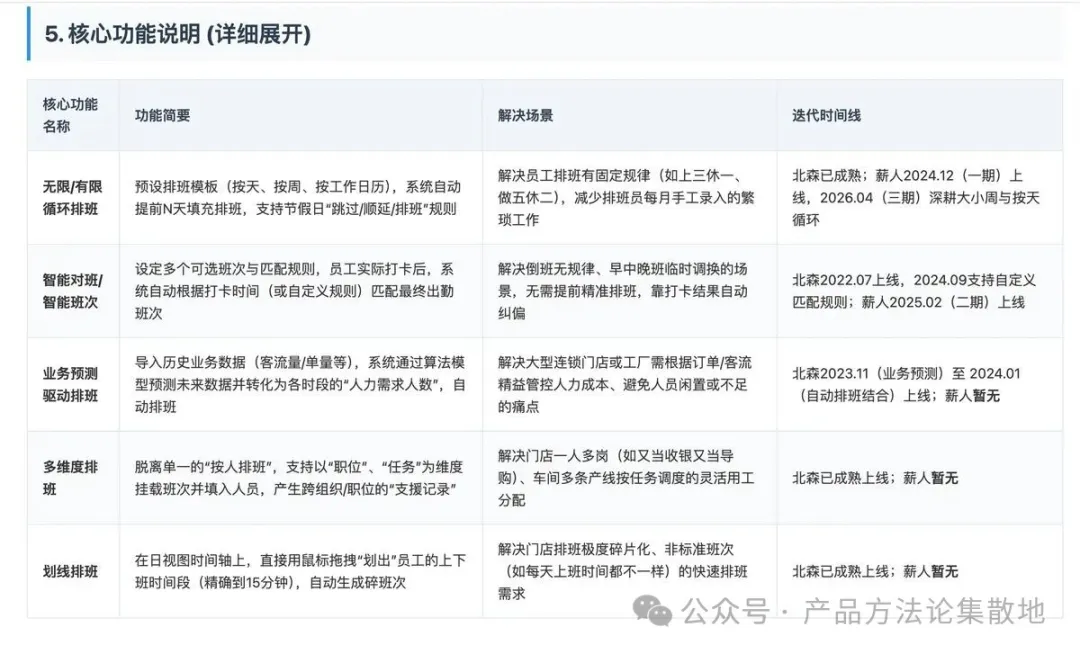
他們的用戶手冊裏詳細描述了"多維度排班"——脱離單一的"按人排班",支持按職位、按任務維度掛載班次並填入人員,能處理門店一人多崗、車間多條產線按任務調度的場景。還有"劃線排班"——在時間軸上直接拖拽生成碎班次,精確到15分鐘。
這意味着他們能處理"一人多崗""門店碎班"這類我們目前還不太支持的場景。如果我們的客戶羣體未來向連鎖門店拓展,這個差距會變成一個硬傷。
發現三:競品B在"本土化規則"上做得比競品A更細。
比如"大小周"這個場景——第一週上5天,第二週上6天,循環往復。競品A的循環排班只支持按周或按天的基礎循環,但競品B專門做了"多周循環"模板,能精確處理"第一週小周、第二週大周"這種國內互聯網企業極度高頻的排法。
這個發現讓我重新思考了我們的優先級——我們之前把"業務預測"作為排班模塊的下一個重點方向,但看完這個分析之後,我覺得可能應該先把本土化規則引擎夯實。畢竟我們的客羣裏,互聯網和製造業客戶佔大頭,"大小周"是實打實的高頻剛需。
發現四:從更新日誌能看出兩家競品的資源投入節奏完全不同。
競品A在2023年下半年到2024年初密集上線了業務預測、劃線排班、工時標準等功能,之後迭代節奏明顯放緩,進入了"打磨期"。競品B則是從2024年底開始,跨越三個版本穩步推進智能排班,每個版本解決一類具體問題(循環模板→智能對班→複雜倒班)。
這說明競品A已經在排班模塊上完成了"從0到1"的能力建設,正在向"從1到N"的精細化演進;而競品B還處於能力補齊階段,但節奏很穩,每個版本都有明確的交付目標。
這四個發現,每一個都是可以直接轉化為產品決策的輸入。尤其是第三個發現——競品B在本土化規則上的深耕,如果我不做這次系統性的對比,很可能不會意識到"大小周"這個看似不起眼的功能,實際上是中腰部客戶選擇排班工具時的一個關鍵決策因素。
幾個我覺得很重要的經驗
第一,AI做競品調研,本質是"增強你的對比能力",而不是"替代你的調研工作"
調研這件事,核心價值從來不在"整理信息",而在"判斷信息"。哪些差異重要,哪些只是實現方式不同,哪些變化意味着戰略轉向,哪些只是常規迭代——這些判斷,AI無法替你做。
但它可以幫你做一件事:把你可能要花兩天才能逐條對比完的PRD和用戶手冊,在幾分鐘內消化完,然後告訴你"這裏有3個值得你關注的差異"。
你只需要去驗證這3個差異,而不是從頭到尾重新看一遍。
第二,聚焦比全面更重要
不要試圖一次分析一個競品的所有模塊。信息量太大,AI的分析會變得又淺又泛。
我的做法是:每次只聚焦一個模塊(如考勤)或一個專項能力(如智能排班、國際化)。信息更聚焦,分析更深,結論更直接。
這就像看病——你不會讓醫生一次性給你做全身檢查然後給你一個"總體健康評估",你會告訴他"我最近胃不舒服",讓他針對性地檢查。
競品調研也一樣。你這次關心的是智能排班,那就只喂排班相關的材料,只分析排班相關的差異。下次關心考勤,再單獨做一輪。
第三,用戶手冊是被嚴重低估的競品信息源
很多人做競品分析,第一反應是去看更新日誌、看行業報告、看新聞動態。但說實話,競品的用戶手冊才是最實在的信息源。
為什麼?因為更新日誌只告訴你"他們最近做了什麼",行業報告只告訴你"市場大概是什麼樣",但用戶手冊告訴你的是——"他們實際交付了一個什麼樣的產品"。
手冊裏寫了什麼功能、操作流程是什麼、支持哪些配置項、邊界場景怎麼處理——這些信息,是你做功能對比最需要的"原材料"。
而且用戶手冊有一個天然優勢:它的信息密度極高。一份排班模塊的用戶手冊,可能涵蓋了循環排班、智能對班、業務預測、多維度排班等十幾個功能點的詳細說明。你讓AI去對比這份手冊和你自己的PRD,比讓它去網上搜10篇競品相關的文章,產出質量高出一個量級。
第四,要給Skill"判斷標準",而不只是"任務要求"
我在前面提到過,我的Skill裏有一段關於"材料可信度分級"的指令。這個指令的價值,遠比"請分析競品"這五個字大得多。
因為當你告訴它"用戶手冊是最可靠的證據,更新日誌要注意過濾營銷話術,財務報表只是輔助參考"的時候,你實際上是在把自己的調研經驗傳授給它。
這又回到了那個核心觀點:Skill的價值,不在於它多會寫提示詞,而在於你願不願意把自己的經驗和方法論裝進去。
第五,競品調研Skill可以和其它Skill組合使用
這是我最近在嘗試的一件事。
做完競品分析之後,我會把分析結果直接餵給"需求優先級判斷Skill",讓它結合競品的動態,重新評估我那1000多條需求的優先級。
比如,如果競品A在智能排班上已經從規則驅動進化到了數據驅動,而且他們的多維度排班和劃線排班覆蓋了大量我們還不支持的複雜用工場景,那我們排班模塊裏相關的需求,優先級就應該往上提。
這樣一來,競品調研就不再是一個"做完就放一邊"的報告,而是真正融入了產品決策的工作流裏。
寫在最後
回頭看,競品調研這件事,AI能幫的其實很有限。
它不能替你去下載競品的用戶手冊,不能替你去整理更新日誌,也不能替你判斷競品下一步會怎麼走。
但它能做一件事:把你準備好的PRD和競品手冊,在幾分鐘內完成逐條對比,然後告訴你"這裏有4個你需要注意的差異,其中第3個可能會改變你的優先級判斷"。
前提是,你得先把材料準備好——去官網下載用戶手冊,整理更新日誌,準備好自己模塊的PRD。然後告訴Skill:這些材料分別是什麼、可信度如何、你希望它怎麼用。
說到底,AI終究只是那個幫你消化信息的大腦。而你,才是那個決定要消化什麼信息、以及怎麼消化的人。
如果你最近也在嘗試用AI做競品調研,不妨問自己一個問題:
你現在給AI的,是隨手搜來的營銷通稿,還是你自己花時間整理過的用戶手冊和需求文檔?
這兩者的差別,往往決定了你拿到的是一份"看起來很專業的報告",還是一份"真正能影響產品決策的洞察"——比如讓你意識到,"大小周"這個看似不起眼的排班規則,可能是中腰部客戶選擇排班工具時的一個關鍵決策因素。