如何讓你的 Claude Code,像 ADHD 那樣思考
整理版優先睇
ADHD Skill讓Claude Code跳出常規,產出非常規思考方案
呢篇文章嘅作者本身係一個產品定價方案嘅設計者,佢發現Claude Code畀出嘅答案雖然正確但太過平庸,好似教科書咁。佢想揾方法令AI嘅輸出更有創意,結果喺Reddit見到一個叫「I gave Claude Code ADHD.. and it thinks 2x better now」嘅帖。帖主係醫療AI安全研究員,整咗個ADHD Skill,令Claude Code用唔同角度深度思考。作者睇完論文同代碼後,覺得呢個Skill喺開放式問題上好有價值。
ADHD Skill嘅核心係三個設計:五個完全獨立嘅LLM調用(冇共享上下文)、每個Agent配唔同認知框架(例如監管者、十歲細路)、同埋將生成同批評階段分離。呢個做法模擬ADHD式多線程思考,避免大模型被前文錨定。作者試咗兩個真實問題——SaaS定價同產品命名——都得到意想不到嘅好結果,例如「反熵定價」同「Quorum」呢類跨框架碰撞嘅創意。
作者認為,ADHD比起CoT(思維鏈)同ToT(思維樹)嘅最大分別係:佢從物理上隔離上下文同換角度,而唔係沿一條線想得更深。佢係推理時工程嘅具體例子,適合做架構決策、產品定位嘅人。安裝只需一行命令:npm install -g adhd-agent。
- 大模型最大問題唔係幻覺,而係回答得太「正確」,缺乏獨特見解。
- ADHD Skill用五個完全獨立嘅Agent,每個有唔同認知框架,從物理上隔離上下文。
- 生成同批評階段分離:發散階段禁止評價,收斂階段先整合批判。
- 真實案例:反熵定價(知識庫越完善,賬單越低)同Quorum命名,展示跨框架碰撞嘅威力。
- 相比CoT同ToT,ADHD改變咗思考角度嘅多樣性,係推理時工程嘅具體實例。
ADHD Agent
安裝命令:npm install -g adhd-agent
大模型輸出太「正確」嘅困擾
作者早排做緊產品定價方案,問Claude Code有咩思路。佢畀咗四個方向,但都係按用量分層、計費呢類標準答案,同豆包畀嘅冇分別。作者覺得呢啲答案太「正確」,唔係佢想要嗰種「仲可以咁樣?」嘅驚喜。
大模型最大問題唔係幻覺,而係回答得太「正確」
呢個問題源於LLM嘅自迴歸生成機制:每個token都係基於前文概率分佈,寫到第三句時前兩句已經錨定咗方向。所以輸出永遠係符合訓練分佈嘅常規思考,而唔係真正有價值嘅獨特想法。
ADHD Skill嘅三個核心設計
呢個Skill嘅核心係三個設計,令Claude Code跳出常規。
五個完全獨立嘅Agent,每個調用之間冇共享上下文
第一,五個獨立嘅LLM調用,物理隔離上下文,唔係靠prompt話「請忽略之前想法」。第二,每個Agent被分配唔同認知框架,例如「監管者審計合規性」或者「十歲細路重新思考問題」,強制從單一視角出發。
認知框架驅動,令每個Agent各自「唔同」而唔係各自「正確」
第三,生成同批評流程分離:發散階段禁止評價、排序;收斂階段換另一個LLM調用進行對抗性批判。呢個設計避免咗創造力同判斷力互相干擾。
真實案例:反熵定價同Quorum命名
作者用ADHD Skill跑咗兩個真實問題。第一個係SaaS定價,畀一個有5000用戶嘅團隊協作工具設計定價模型。ADHD選擇咗市場機制、遊戲設計師、反向思考、十歲細路、競爭對手視角五個框架,最終提出「反熵定價」:團隊知識庫越完善,月賬單越低。呢個設計將付費變成產品價值一部分,用戶為咗省錢會主動完善知識庫,提高留存率。
反熵定價:知識庫越完善,賬單越低
第二個係為一個面向一人公司嘅Agent工具命名。ADHD用反向思維、市場定位、競爭者視角、天真直覺、生物隱喻框架,最終推薦「Quorum」——將一人公司重新定義為「一組達到協調共識閾值嘅智能體集合」。呢個名從生物學框架冒出,收斂階段被高分評價。
跨框架碰撞好難靠單一視角想出來
ADHD vs CoT/ToT:推理時工程嘅差異化
你可能會諗:CoT(思維鏈)令AI諗得更深,ToT(思維樹)令佢搜得更廣。但CoT係一條路諗到底,ToT嘅分支共享上下文,所以無論點樣,個角度本身就冇換過。ADHD就唔同,佢物理隔離上下文同換框架,從根本上改變思考多樣性。
角度本身就冇換過,呢個先係問題
作者認為,當模型能力趨同之後,下一個差異化維度係推理時工程:點樣組織調用、隔離上下文、分配角色、安排生成同評估時序。Claude Code最近推出嘅蜂羣模式(Agent Teams)都係類似方向。ADHD Skill正係呢個方向嘅具體實現——唔改模型權重,純粹用調用編排改變輸出質素。
npm install -g adhd-agent
內容編輯丨特工小花 特工小餅
內容審核丨特工少女
前兩日我做緊一個產品定價方案,問 Claude Code 有咩思路。
佢俾咗四個方向我。但我睇完之後覺得,呢啲唔係我直接問豆包都得嘅答案咩:
按用量分層(Free、Pro)、按用量計費、Token Plan、免費加廣告。
呢啲回答好似教科書咁正確,但唔係我想要嗰種「嚇?仲可以咁?然後恍然大悟」有啲新意嘅答案。
有冇可能令 Claude Code 嘅輸出冇咁悶?
我試咗幾次,例如改 Agent 嘅 md 檔案,發現效果一般。
呢個問題直到前幾日,我突然揾到一個參考答案:
我喺 Reddit 見到一個帖,標題係「I gave Claude Code ADHD.. and it thinks 2x better now」。
個帖嘅作者主要做醫療 AI 安全研究,佢透過 Skill 嘅方法將 ADHD 嘅思維塞入 Claude Code,仲為呢個 Skill 寫咗篇論文。
前段時間,我同事寫過一篇 ADHD 嘅文章我好鍾意:《ADHD,反而成為 AI 時代嘅版本答案?! 》
我雖然唔係 ADHD,但我即刻諗到一點:呢個 Skill 可以幫我將 Claude Code 變成 ADHD?咁就真係好型。
於是我用咗兩個鐘,將論文同啲 code 都睇曬。
睇完之後我覺得,呢個 Skill 喺一啲特定場景真係好有價值。

真理往往掌握喺少數人手上
先講一個我嘅判斷:而家大模型最大嘅問題,唔係幻覺同回答錯誤,而係答得太「正確」喇。
呢種太過正確嘅原因係 LLM 嘅自迴歸生成機制:
佢令每個 token 都係基於前文嘅條件概率分佈採樣出嚟,雖然有 temperature 呢啲隨機性調節,但整體仍然被訓練分佈強烈約束。
即係話:大模型寫到第三句嘅時候,前兩句已經將後面嘅方向錨死咗。
《這就是 ChatGPT》
所以大模型最終輸出嘅,永遠係符合訓練分佈嘅常規「思考」,而唔係真正有價值嘅「獨特」想法(除非你嘅提示詞非常獨特,但呢個唔符合大部分嘅對話方式)。
呢個喺有標準答案嘅問題上完全冇問題:你問佢快排點寫,佢會寫得又快又啱。
但大部分問題係開放式問題,大模型喺呢度就容易變得好「平庸」。
例如當你做架構決策、思考方案呢啲問題時,標準答案往往就係嗰個「平庸」嘅答案。
但真正有價值嘅方案,往往係「掌握喺少數人手上」嘅「非常規化思考」。
而呢樣嘢,恰恰就係 ADHD 思維嘅舒適區:
跳過頭三個顯而易見嘅答案,喺人哋停低嘅地方繼續轉彎,呢個就係 ADHD 思維最擅長嘅事。

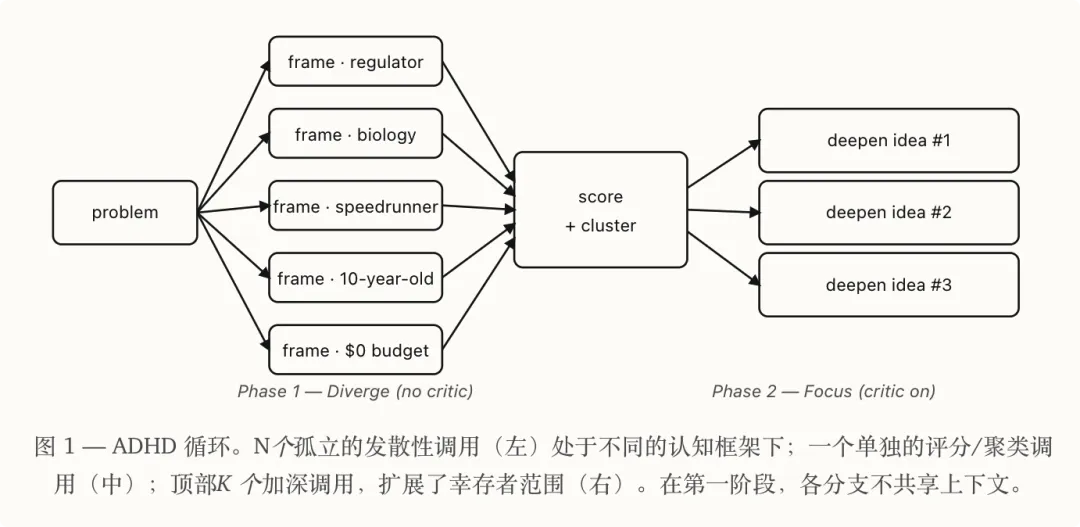
ADHD Skill 嘅三個設計
ADHD 呢個 Skill 嘅核心設計,我將佢概括成三點。
第一,五個獨立嘅 Agent。
佢唔係叫一個 AI 諗五次,而係開五個完全獨立嘅 LLM 調用,每個調用之間冇任何共享上下文。
Agent A 裏面嘅想法,喺 Agent B 裏面根本睇唔到。上下文直接被物理隔離咗,所以呢個唔係靠 Prompt 話「請忽略之前嘅想法」或者透過上下文壓縮嚟「減少上下文」,而係根本冇「之前嘅想法」呢樣嘢存在。
呢個同 Anthropic 喺 Harness 工程裏面推薦嘅做法類似:佢哋認為長任務應該將上下文直接重置,避免上下文壓縮影響任務效果。

《harness-design-long-running-apps》
第二,認知框架驅動。
每個 Agent 被分配一個完全唔同嘅「思考角色」。
例如「你係一個監管者,審計呢個系統嘅合規性同失敗模式」、「你係一個十歲細路,從未見過軟件,用最天真嘅方式重新諗呢個問題」。

論文裏面有 15 個咁嘅框架,ADHD 喺跑嘅時候每次會揀五個:目的唔係要佢哋各自「正確」,而係要佢哋各自「唔同」。
咁樣就強制令每個 Agent 只能夠從一個特定視角出發思考,模擬出 ADHD 式嘅多線程認知。
第三,生成同批評嘅流程分離。
呢個係我覺得最巧妙嘅設計:
- 發散階段,系統提示清楚寫住「你係生成器唔係批評者,禁止評價、禁止排序、禁止對衝」。
- 收斂階段,換一個完全唔同嘅 LLM 調用,系統提示變成「你而家係批評者,對抗性閲讀,評分,揾陷阱」。
呢兩個角色,用嘅係唔同嘅調用、唔同嘅 system prompt、唔同嘅輸出格式。
點解呢個咁重要?因為創造力同判斷力同時運作嘅時候,創造力就發揮唔到能力。
就好似一個人物寫文章初稿嘅同時改稿,結果就係乜都寫唔出,LLM 都係一樣。
所以,透過呢個分階段設計,ADHD Skill 就可以實現:
發散階段,根據問題從五個獨立視角「多線程思考」
收斂階段,用一個線程負責「整合思考」,最後,俾出一個「非常規」嘅答案。

我拎佢跑咗兩個真實問題
我用 ADHD 嘅 Skill 跑咗兩個真實嘅問題。
第一個係 SaaS 定價。
呢個背景係,我一個朋友做咗一個面向中小企嘅團隊協作工具,大概 5000 用戶,需要設計定價模型。
然後佢哋團隊內部討論咗好耐,唔知點定。
於是,佢揾我幫手設計定價方案,我就用咗呢個 Skill 喺 Claude Code 度跑咗一下:
結果 ADHD 揀咗五個框架:市場機制、遊戲設計師、反向思考、十歲細路、競爭對手視角。

跑完之後佢俾咗 30 個想法,聚類成五個大方向。
令我真正呆咗一下嘅係,佢最終提出一個叫「反熵定價」嘅嘢:團隊嘅知識庫越完善,月賬單越低。
具體嚟講就係,知識庫裏面嘅文檔覆蓋率高咗、重複問題少咗,折扣就自動出嚟。
呢個想法好喺邊?佢將「付費」變成咗產品價值嘅一部分。用戶為咗慳錢會主動完善知識庫,而知識庫越完善轉換成本越高。留存率同產品質量形成正循環。
老實講,我喺見到佢之前,最多隻係諗到按照文檔 API 付費呢一層。
而按佢呢個方向,千人千面,每個人嘅付費邏輯唔一樣,呢種定價邏輯,我想都未諗過。

第二個問題係幫一個 Agent 產品改個名。
我最近想幫面向一人公司,做個 Agent 工具,但係諗名唔知點諗。
然後我就用咗呢個 Skill 跑咗一下:
於是五個框架,揀咗反向思維、市場定位、競爭者視角、天真直覺、生物隱喻。

最終推薦排第一嘅叫 Quorum:
佢將一人公司重新定義成「一組達到協調共識閾值嘅智能體集合」,都幾有敍事張力。

呢個名從「生物學」框架走出嚟,然後收斂階段俾人打咗高分。
呢種跨框架嘅碰撞,好難靠單一視角諗出嚟。

ADHD 論文,講咗啲咩?
當然,呢兩個案例仲未夠嚴謹,ADHD 真係夠有效咩?
作者自己都做咗更系統嘅驗證,甚至寫咗篇論文:《ADHD: Parallel Divergent Ideation for Coding Agents》

論文裏面用 6 個開放式工程問題做咗測評:ADHD 對比同模型嘅單次回答,5 勝 1 負。
佢嘅測評結果係,ADHD 令整個方案嘅新穎性提升 5.17,廣度提升 4.17。
如果從傳統提示詞工程嘅角度,可以咁樣理解呢個思想:
ADHD 改變嘅係 AI 嘅思考邏輯,令我哋喺調用模型時,直接改變模型輸出嘅結構。
你可能會話,CoT(思維鏈)唔係令 AI 諗得更深咩?ToT(思維樹)唔係令佢搜得更廣咩?
沒錯。
但 CoT 係令一個腦仔沿住一條路諗得更慢更仔細,佢依然係一條線。ToT 係令同一個腦仔喺分叉點嘗試唔同嘅下一步,但分支之間共享上下文,寫到第四步嘅時候前三步嘅上下文依然喺度。
所以無論大模型諗得再深、搜得再廣,都解決唔到「角度本身就冇換過」呢個問題。

理解咗呢個分別之後,我哋可以諗一個更大嘅問題:
當模型能力同框架趨同之後,下一個差異化嘅維度係咩?
我認為係推理時工程:喺調用模型嘅嗰一刻,你點樣組織調用、點樣隔離上下文、點樣分配角色、點樣安排生成同評估嘅時序。
一個例子就係最近 Claude Code 推出嘅蜂羣模式(Agent Teams):令多個 AI 並行協作成為可能,最多支援 20 個子 Agents 同時跑。
ADHD Skill 都係呢個方向嘅一個具體實現:
佢唔改模型權重,唔做微調,純粹喺推理時用調用編排嘅方式,改變 Agent 輸出嘅多樣性同質量。
如果你想試下,安裝只需要一行指令:npm install -g adhd-agent
對於嗰啲每日都做架構決策、產品定位、技術選型嘅人嚟講,呢個可能係性價比最高嘅「第二大腦擴展」:
令佢學好似一個版本最強嘅 ADHD 咁,用唔同嘅角度深度思考一個問題。
內容編輯丨特工小花 特工小餅
內容審核丨特工少女
前兩天我在做一個產品定價方案,問 Claude Code 有什麼思路。
它給了我四個方向。但我看完之後覺得,這不就是我直接問豆包也能得出的答案嘛:
按用量分層(Free、Pro)、按用量計費、Token Plan、免費加廣告。
這些回答如同教科書一般正確,但不是我想要的那種「還能這樣?然後恍然大悟」的有些心意的答案。
有沒有可能讓 Claude Code 的輸出不這麼枯燥?
我做了幾次嘗試,比如改 Agent 的 md 文件,發現效果一般。
這個問題直到前幾天,我突然找到了一個參考答案:
我在 Reddit 上看到一個帖子,標題是「I gave Claude Code ADHD.. and it thinks 2x better now」.
帖子的作者主要是做醫療 AI 安全研究,他通過 Skill 的方法把 ADHD 的思維塞進了 Claude Code,還為這個 Skill 寫了篇論文。
前段時間,我同事寫過一篇 ADHD 的文章我很喜歡:《ADHD,反而成了 AI 時代的版本答案?! 》
我雖然不是 ADHD,但我立刻想到一點:這個 Skill 能幫我把 Claude Code 變成 ADHD?那可太帥了。
於是我花了兩個小時,把論文和代碼都看了一遍。
看完之後我覺得,這個 Skill 在一些特定的場景真的很有價值。
真理往往掌握在少數人手裏
先說一個我的判斷:現在大模型最大的問題,不是幻覺和回答錯誤,而是回答得太「正確」了。
這種過於正確的原因是 LLM 的自迴歸生成機制:
它讓每個 token 都是基於前文的條件概率分佈採樣出來的,雖然有 temperature 等隨機性調節,但整體仍然被訓練分佈強烈約束。
這意味着:大模型寫到第三句話的時候,前兩句話已經把後面的方向錨定了。
《這就是 ChatGPT》
所以大模型最終輸出的,永遠是符合訓練分佈的常規「思考」,而不是真正有價值的「獨特」想法(除非你的提示詞非常獨特,但這不符合大部分的對話方式)。
這在有標準答案的問題上完全沒毛病:你問它快排怎麼寫,它給你寫得又快又對。
但大部分問題是開放式的問題,大模型在這裏就容易變得「平庸」。
比如當你做架構決策、思考方案這種問題時,這時候標準答案往往就是那個「平庸」的答案。
但真正有價值的方案,往往是「掌握在少數人手裏」的「非常規化思考」。
而這,恰恰就是 ADHD 思維的舒適區:
跳過前三個顯而易見的答案,在別人停下來的地方繼續拐彎,這就是 ADHD 思維最擅長的事。
ADHD Skill 的三個設計
ADHD 這個 Skill 的核心設計,我把它概括成三點。
第一,五個獨立的 Agent。
它不是讓一個 AI 想五次,而是開五個完全獨立的 LLM 調用,每個調用之間沒有任何共享上下文。
Agent A 裏的想法,在 Agent B 里根本看不到。上下文直接被物理隔離掉了,所以這就不是靠 Prompt 說「請忽略之前的想法」或者通過上下文的壓縮來「減少上下文」,而是根本沒有「之前的想法」這個東西存在。
這和 Anthropic 在 Harness 工程裏推薦的做法類似:他們認為長任務應該把上下文直接重置,避免上下文壓縮影響任務效果。
《harness-design-long-running-apps》
第二,認知框架驅動。
每個 Agent 被分配一個完全不同的「思考角色」。
比如「你是一個監管者,審計這個系統的合規性和失敗模式」、「你是一個十歲小孩,從沒見過軟件,用最天真的方式重新想這個問題」。
論文裏有 15 個這樣的框架,ADHD 在跑的時候每次會選五個:目的不是讓它們各自「正確」,而是讓它們各自「不同」。
這樣就強制讓每個 Agent 只能從一個特定視角出發思考,模擬出 ADHD 式的多線程認知。
第三,生成和批評的流程分離。
這是我覺得最精妙的設計:
- 發散階段,系統提示明確寫着「你是生成器不是批評者,禁止評價、禁止排序、禁止對沖」。
- 收斂階段,換一個完全不同的 LLM 調用,系統提示變成「你現在是批評者,對抗性閲讀,打分,找陷阱」。
這兩個角色,用的是不同的調用、不同的 system prompt、不同的輸出格式。
為什麼這很重要?因為創造力和判斷力同時運作的時候,創造力就發揮不出來能力。
就像一個人在寫文章初稿的時候同時在改稿,結果就是什麼都寫不出來,LLM 也一樣。
所以,通過這樣的分階段設計,ADHD Skill 就可以實現:
發散階段,根據問題從五個獨立視角「多線程思考」
收斂階段,用一個線程負責「整合思考」,最後,給出一個「非常規」的答案。
我拿它跑了兩個真實問題
我用 ADHD 的 Skill 跑了兩個真實的問題。
第一個是 SaaS 定價。
這個背景是,我一個朋友做了一個面向中小企業的團隊協作工具,大概 5000 用戶,需要設計定價模型。
然後他們團隊內部討論了很久,不知道怎麼定。
於是,他找我做設計定價方案,我就用了這個 Skill 在 Claude Code 跑了一下:
結果 ADHD 選了五個框架:市場機制、遊戲設計師、反向思考、十歲小孩、競爭對手視角。
跑完之後它給出了 30 個想法,聚類成了五個大方向。
讓我真正愣了一下的是,它最終提出一個叫「反熵定價」的東西:團隊的知識庫越完善,月賬單越低。
具體來說就是,知識庫裏的文檔覆蓋率高了、重複問題減少了,折扣就自動出來。
這個想法好在哪?它把「付費」變成了產品價值的一部分。用戶為了省錢會主動完善知識庫,而知識庫越完善切換成本越高。留存率和產品質量形成正循環。
說實話,我在看到它之前,最多隻能想到按照文檔 API 付費這一層。
而按他這個方向,千人千面,每個人的付費邏輯不一樣,這種定價邏輯,我想到沒想過。
第二個問題是給一個 Agent 產品想一個名字。
我最近想給面向一人公司,做個 Agent 工具,但是起名字不知道怎麼起。
然後我就用了這個 Skill 跑了一下:
於是五個框架,選了反向思維、市場定位、競爭者視角、天真直覺、生物隱喻。
最終推薦排第一的叫 Quorum:
它把一人公司重新定義成「一組達到協調共識閾值的智能體集合」,還是蠻有敍事張力的。
這個名字從「生物學」框架冒出來的,然後收斂階段被打了高分。
這種跨框架的碰撞,很難靠單一視角想出來。
ADHD 論文,講了什麼?
當然,這兩個案例還不夠嚴謹,ADHD 真的足夠有效嗎?
作者自己也做了更系統的驗證,甚至寫了篇論文:《ADHD: Parallel Divergent Ideation for Coding Agents》
論文裏用 6 個開放式工程問題做了測評:ADHD 對比同模型的單次回答,5 勝 1 負。
他的測評結果是,ADHD 讓整個方案的新穎性提升 5.17,廣度提升 4.17。
如果從傳統提示詞工程的角度,可以這樣理解這個思想:
ADHD 改變的是 AI 的思考邏輯,讓我們在調用模型時,直接改變模型輸出的結構。
你可能會說,CoT(思維鏈)不是讓 AI 想得更深了嗎?ToT(思維樹)不是讓它搜得更廣了嗎?
沒錯。
但 CoT 是讓一個腦子沿着一條路想得更慢更仔細,它依然是一條線。ToT 是讓同一個腦子在分叉點嘗試不同的下一步,但分支之間共享上下文,寫到第四步的時候前三步的上下文依然在。
所以無論大模型想得再深、搜得再廣,都不能解決「角度本身就沒換過」這個問題。
理解了這個區別之後,我們可以思考一個更大的問題:
當模型能力和框架趨同之後,下一個差異化的維度是什麼?
我認為是推理時工程:在調用模型的那一刻,你怎麼組織調用、怎麼隔離上下文、怎麼分配角色、怎麼安排生成和評估的時序。
一個例子就是最近 Claude Code 推出的蜂羣模式(Agent Teams):讓多個 AI 並行協作成為可能,最多支持 20 個子 Agents 同時跑。
ADHD Skill 也是這個方向的一個具體實現:
它不改模型權重,不做微調,純粹在推理時用調用編排的方式,改變 Agent 輸出的多樣性和質量。
如果你想試試,安裝只需要一行命令:npm install -g adhd-agent
對於那些每天都在做架構決策、產品定位、技術選型的人來說,這可能是目前性價比最高的「第二大腦擴展」:
讓它學會像一個版本最強的 ADHD 一樣,用不同的角度深度思考一個問題。