如何訓練 Skill 讓它自進化:從"能用"到"精準"的完整方法論
整理版優先睇
訓練 Skill 需用數據驅動,透過寫初版 → 跑 Eval → 看數據 → 改進循環,將觸發率同輸出質量從約65%提升到95%,實現自進化。
呢篇文章係作者分享點樣訓練 AI Skill,而唔係寫完就算。佢指出好多人寫完 Skill 試兩次就收工,結果觸發率低、輸出質量唔穩定。作者使用 Claude Code 嘅 skill-creator 工具,提出完整訓練循環:寫初版 → 跑 Eval 睇數據 → 改進 → 再跑 Eval。佢強調 Skill 要睇兩個核心指標:觸發率同輸出質量。最終結論係 Skill 唔係靜態文檔,而係需要持續迭代嘅「模型行為規範」,透過用戶反饋、定期回歸測試同 description 自動優化,可以做到自進化。
文章仲提供咗實戰案例,展示一個 code-review Skill 點樣由 v1 嘅 65% 觸發率同 C 級質量,經過三次迭代升到 v3 嘅 95% 同 A 級。作者亦講解咗管理多個 Skill 嘅常見問題,例如衝突、過時、邊界劃分,同埋 CLAUDE.md 同獨立 Skill 嘅分工。最後佢畀出收斂標準:觸發率 ≥ 90% 就停,輸出質量連續兩次冇提升就停,迭代通常 3-4 輪。
總括嚟講,呢篇文嘅核心係用數據驅動方式訓練 Skill,將 AI 嘅行為從「撞彩」變成「穩定可靠」,適合所有用緊 AI 輔助開發嘅人參考。
- Skill 訓練係一個閉環:寫/改 → 跑 Eval → 睇數據 → 改進,直至觸發率 ≥ 90% 且輸出質量連續兩次冇提升先收手。
- description 決定觸發率,要加正面觸發詞同負面排除詞;正文決定輸出質量,要畀具體規則、反面案例同邊界情況。
- 用戶每次糾正 AI 嘅反饋都係訓練機會,應寫返入 Skill 令佢永久生效,實現自進化。
- Skill 數量多咗之後要留意衝突同過時,用 description 劃清邊界,定期做「Skill 年檢」。
- CLAUDE.md 放靜態事實(技術棧、目錄),獨立 Skill 放動態行為(流程、格式、檢查清單),兩者配合唔好溝埋。
skill-creator
Anthropic 開發嘅 skill-creator 工具,可以自動評估 Skill 觸發準確率同輸出質量,並支援 description 自動優化。需要從 GitHub 倉庫下載放到 ~/.claude/skills/ 目錄。
寫咗 Skill 但 AI 唔跟?問題在於冇訓練
好多人寫 Skill 嘅方式係:寫一份 SKILL.md,試兩次「好像能用」,就收工。一個月後發現 AI 該觸發時唔觸發,唔該觸發時亂觸發,輸出質量時好時壞。
問題在於你冇用數據驅動去訓練佢
Skill 唔係寫完就結束嘅靜態文檔,而係一個需要持續訓練、度量、迭代嘅「模型行為規範」。好消息係 Claude Code 嘅 skill-creator 工具已經將成個訓練循環自動化咗——你只需要理解原理,然後讓工具幫你跑。
兩個核心指標:觸發率同輸出質量
訓練 Skill 要優化嘅只有兩件事:
- 1 觸發率:取決於 description 寫得好唔好。AI 根據 description 判斷「呢個 Skill 同當前任務相關嗎」。description 太模糊就會漏觸發或誤觸發。
- 2 輸出質量:取決於 SKILL.md 正文嘅規則寫得好唔好。規則太模糊 AI 會自由發揮,規則冇覆蓋嘅位 AI 會跟默認行為——未必係你想要嘅。
訓練循環:4 步閉環
- 1 寫初版 Skill:description 以「Use when」開頭,正文寫 3-5 條核心規則加 1 個完整示例。
- 2 跑 Eval:用 skill-creator 自動生成測試查詢,評估觸發率同輸出質量。
- 3 睇數據定位問題:觸發率低就改 description;輸出質量差就改正文規則。
- 4 改進並重跑:根據診斷做針對性修改,再跑 Eval 睇數字有冇漲。
成個過程係一個反覆循環,直至滿意為止。
觸發率低常見原因:description 太寬泛、太窄、有歧義
輸出質量差常見原因:規則太模糊、缺少反面示例、缺少邊界情況
# 改前
description: Use when 用戶完成代碼修改準備提交時,生成中文 commit message
# 改後
description: Use when 用戶說"提交"、"commit"、"寫 commit message"或完成一輪代碼修改後要求生成提交信息時。不適用於 PR 描述、changelog、release note。讓 Skill 自進化:3 個機制
- 用戶反饋驅動迭代:每次糾正 AI 時,將反饋寫返入 Skill 正文,實現「反饋 → 記憶 → 寫回 Skill → 永久生效」。
- 定期跑 Eval 回歸測試:每兩週跑一次,因為項目可能演變、新 Skill 可能衝突、AI 模型更新可能改變行為。
- description 自動優化:skill-creator 可以自動生成多個 description 版本,測試邊個分數最高,觸發率可從 ~70% 提升到 ~90%。
用戶反饋係最好嘅訓練數據——每次糾正 AI 都係一次訓練機會
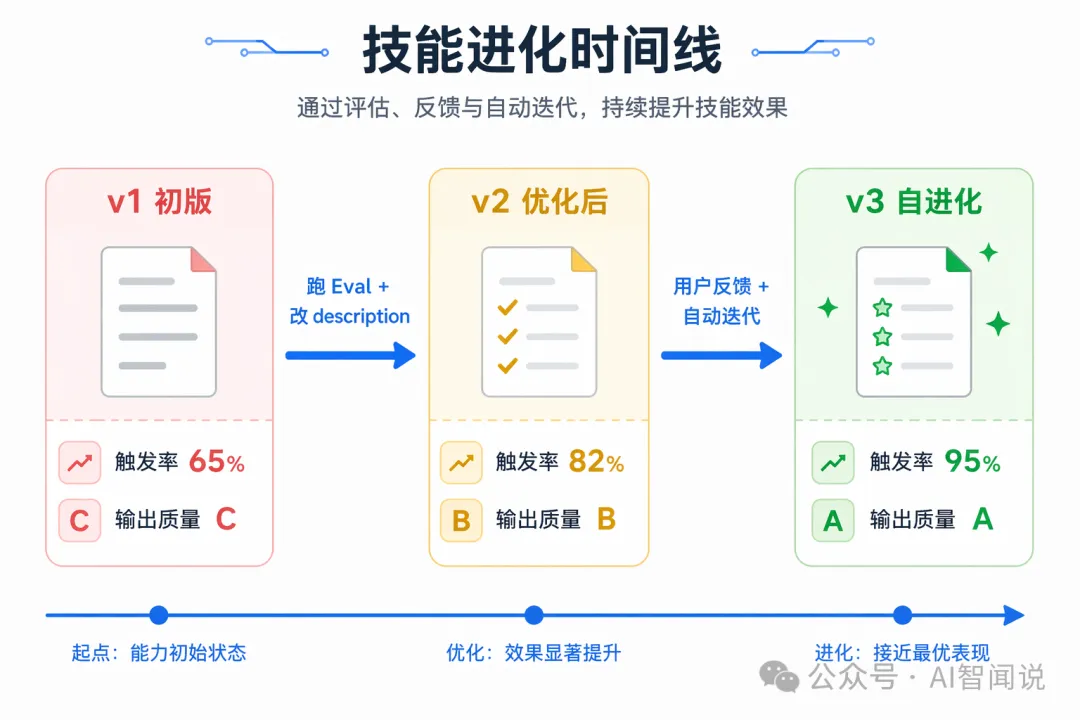
實戰案例:code-review Skill 嘅 3 次進化
以作者自己嘅 code-review Skill 為例,從 v1 到 v3 觸發率由 65% 升到 95%,輸出質量由 C 升到 A。
v1 問題:description 太模糊,規則太抽象
v2 改善:加咗具體觸發詞同排除場景,規則從抽象變具體
v3 最終版:加咗鐵律(防止偷懶)、反面案例(防止廢話輸出)、description 經過自動優化
description: Use when 用戶在代碼修改完成後要求審查質量(觸發詞:review、檢查、看看有沒有問題、幫我過一遍),或在 /commit 之前自動觸發。不適用於:功能需求討論、架構設計、寫新代碼。
## 鐵律
- 每次 review 必須至少指出一個改進點。如果真的沒問題,說明為什麼沒問題。
- 不要只說"看起來沒問題"——這等於沒 review。
## 檢查項(按優先級)
1. 安全:硬編碼密鑰?SQL 注入?XSS?未驗證的用戶輸入?
2. 錯誤處理:Promise 有 catch?外部 API 調用有超時?錯誤信息對用戶友好?
3. 類型安全:有 any?類型斷言有根據?泛型用對了?
4. 邏輯:邊界值測試了?空值處理了?併發安全?
5. 可讀性:命名錶達意圖?嵌套 ≤ 3 層?函數 ≤ 30 行?
## 反面案例
- ❌ "代碼看起來還行" → 沒有價值
- ❌ "建議加註釋" → 太模糊
- ❌ 列出 20 個低優先級問題 → 信息過載多 Skill 管理同收斂標準
- 多個 Skill 同時觸發:喺 description 明確劃分邊界,加「不適用於」排除詞。
- Skill 過時:每月做一次「Skill 年檢」,檢查是否同當前項目匹配。
- 唔確定應唔應該新建 Skill:如果你在不同會話重複同一條糾正指令,就值得寫成 Skill;一次性嘅唔需要。
- CLAUDE.md vs 獨立 Skill:CLAUDE.md 放靜態事實(技術棧、目錄),Skill 放動態行為(流程、輸出格式、檢查清單)。
寫咗個 Skill,AI 有時用、有時唔用,用咗效果都係一般?問題唔係喺 Skill 本身,而係你冇訓練佢。呢篇會講一套完整嘅 Skill 訓練循環:寫初版 → 跑 Eval → 睇數據 → 改進 → 再跑 Eval,令到 Skill 由「用得」進化到「精準」。
寫喺前面
大多數人寫 Skill 嘅方式係咁樣:
一個月之後發現:有時 AI 應該觸發嘅時候冇觸發,唔應該觸發嘅時候亂觸發。輸出質量時好時壞,全靠運氣。
問題喺邊?你冇用數據驅動咁訓練佢。
Skill 唔係寫完就完事嘅靜態文件。佢係一個需要持續訓練、度量、迭代嘅「模型行為規範」。好消息係,Claude Code 嘅 skill-creator 工具已經將成個訓練循環自動化咗——你只需要理解原理,然後叫工具幫你搞掂。
一、Skill 嘅兩個核心指標
訓練 Skill 要優化嘅只有兩件事:
1. 觸發率(Triggering Accuracy)
「應該觸發嘅時候有冇觸發?唔應該觸發嘅時候冇亂觸發?」
呢個取決於 description 字段寫得好唔好。AI 根據 description 判斷「呢個 Skill 同當前任務相關嗎?」。description 寫得模糊,就會漏觸發或者誤觸發。
2. 輸出質量(Output Quality)
「觸發之後,AI 跟住 Skill 做嘢嘅效果好唔好?」
呢個取決於 SKILL.md 正文嘅規則寫得好唔好。規則太模糊 AI 會自由發揮,規則冇覆蓋到嘅地方 AI 會跟住自己嘅默認行為嚟——未必係你想要嘅。
訓練嘅目標:將觸發率由 ~65% 拉到 95%,將輸出質量由「勉強用得」拉到「穩定可靠」。
二、訓練循環:4 步閉環
成個訓練過程係一個循環,重複跑直到滿意:
第 1 步:寫初版 Skill
初版唔使追求完美,能夠表達核心意圖就得。重點關注:
description 寫清楚「幾時用」(以「Use when」開頭)第 2 步:跑 Eval——叫 skill-creator 幫你測
呢一步係關鍵。用 skill-creator 跑評估(需要先安裝:從 github.com/anthropics/skills 倉庫把 skill-creator 目錄放到 ~/.claude/skills/ 下):
skill-creator 會自動做呢啲嘢(以下係簡化示意,實際輸出包含更多細節):
觸發率測試:
輸出質量測試:
第 3 步:睇數據,定位問題
根據 Eval 結果,問題通常分為兩類:
觸發率低?→ 改 description
常見原因:
輸出質量差?→ 改正文規則
常見原因:
第 4 步:改進同重跑
根據第 3 步嘅診斷,做針對性修改。然後再跑一次 Eval,睇數字有冇升。
例如觸發率由 85% 要拉到 95%,description 改成:
關鍵改動:加咗正面觸發詞 + 加咗負面排除詞。咁樣 AI 就唔會將「寫 PR 描述」誤判為需要呢個 Skill。
三、令 Skill 自進化:3 個機制
訓練一次只係起點。真正厲害嘅係令 Skill 持續自動進化:
機制 1:用戶反饋驅動迭代
每次 Skill 嘅輸出唔符合你嘅預期時,直接話畀 AI 知:
「呢個 commit message 唔啱,多文件修改時應該寫最主要嘅改動,唔好列曬所有文件」
AI 會自動將呢條反饋存入記憶。下次再遇到同樣情況,行為就會改變。
但更進一步——將呢條反饋寫返入 Skill 本身:
反饋 → 記憶 → 寫返入 Skill → 永久生效。呢個就係自進化。
機制 2:定期跑 Eval 回歸測試
每兩星期跑一次 Eval。原因:
當佢係「單元測試」——代碼改咗要跑測試,Skill 改咗都要跑 Eval。
機制 3:description 自動優化
skill-creator 有一個殺手級功能:自動優化 description 嘅觸發準確率。
它會:
根據社區實測分享(Reddit、Medium 上多位開發者嘅反饋),觸發率由 ~70% 提升到 ~90% 係可以預期嘅。
四、實戰案例:一個 Skill 嘅 3 次進化
以我自己嘅 code-review Skill 為例:
v1:初版(第一次跑 Eval 結果:觸發率 65%,輸出質量 C)
問題:description 太模糊(「reviewing code」太寬泛),規則太抽象(「檢查安全性」具體查啲乜?)。
v2:跑 Eval 後優化(觸發率 82%,輸出質量 B)
改進:description 加咗具體觸發詞同排除場景,規則由抽象變具體。
v3:用戶反饋 + 自動優化後(觸發率 95%,輸出質量 A)
改進:加咗鐵律(防止偷懶)、加咗反面案例(防止廢話輸出)、description 經過自動優化觸發率到 95%。
五、Skill 數量多咗之後嘅管理
當你有 10+ 個 Skill 時,新問題出現:Skill 之間互相衝突或搶觸發。
問題 1:多個 Skill 同時觸發
例如你有 code-review 和 security-review 兩個 Skill,用戶話「幫我檢查下呢段代碼」——兩個都想觸發。
解決方案: 喺 description 裏面明確劃分邊界:
問題 2:Skill 過時咗
項目由 REST 搬咗去 tRPC,但你嘅 api-design Skill 裏面仲寫緊 REST 嘅規範。
解決方案: 每月做一次「Skill 年檢」:
問題 3:唔確定應唔應該新建 Skill
判斷標準:你係咪喺唔同會話中重複畀 AI 同一條糾正指令?
如果你發現自己重複話「唔啱,我哋項目應該咁樣做」——就值得寫成 Skill。一次性嘅、只係喺特定調試場景出現嘅指令就唔需要。
問題 4:乜嘢內容應該寫喺 CLAUDE.md,乜嘢應該寫成獨立 Skill
分層策略:
舉例:
CLAUDE.md 畀 AI 背景知識,Skill 畀 AI 執行手冊。兩者配合,唔好撈亂。
六、幾時停止迭代
唔係無限跑 Eval 就係好嘅。收斂標準:
觸發率 ≥ 90% 就可以停。 100% 唔現實——有些邊界查詢本來就有歧義(「幫我睇下呢段代碼」到底係 review 定係解釋?),追求 100% 反而會令 description 變得過度具體、喪失泛化能力。
輸出質量連續 2 次 Eval 冇提升就停。 說明當前規則已經到達咗呢個 Skill 能覆蓋嘅上限。再想提升一係拆成多個 Skill,一係接受現狀。
一個 Skill 嘅迭代輪數通常唔超過 3-4 輪。 如果 4 輪仲未收斂,好大機會係 Skill 嘅定義範圍太大——拆成 2 個更窄嘅 Skill 比硬優化一個闊 Skill 效果更好。
七、總結:Skill 訓練嘅核心心法
最小行動:揀你用得多嘅一個 Skill,跑一次 幫我評估 xx skill 的觸發率和輸出質量。睇下數據,你會驚訝咁發現改進空間有幾大。
掃碼關注「AI智聞說」,每日3分鐘掌握AI新知識
寫了個 Skill,AI 有時候用、有時候不用、用了效果也一般?問題不在 Skill 本身,在於你沒有訓練它。這篇講一套完整的 Skill 訓練循環:寫初版 → 跑 Eval → 看數據 → 改進 → 再跑 Eval,讓 Skill 從"能用"進化到"精準"。
寫在前面
大多數人寫 Skill 的方式是這樣的:
一個月後發現:有時候 AI 該觸發的時候沒觸發,不該觸發的時候亂觸發。輸出質量時好時壞,全看運氣。
問題在哪?你沒有用數據驅動地訓練它。
Skill 不是寫完就結束的靜態文檔。它是一個需要持續訓練、度量、迭代的"模型行為規範"。好消息是,Claude Code 的 skill-creator 工具已經把整個訓練循環自動化了——你只需要理解原理,然後讓工具幫你跑。
一、Skill 的兩個核心指標
訓練 Skill 要優化的只有兩件事:
1. 觸發率(Triggering Accuracy)
"該觸發的時候觸發了嗎?不該觸發的時候沒亂觸發嗎?"
這取決於 description 字段寫得好不好。AI 根據 description 判斷"這個 Skill 跟當前任務相關嗎"。description 寫得模糊,就會漏觸發或誤觸發。
2. 輸出質量(Output Quality)
"觸發之後,AI 按 Skill 幹活的效果好不好?"
這取決於 SKILL.md 正文的規則寫得好不好。規則太模糊 AI 會自由發揮,規則沒覆蓋到的地方 AI 會按自己的默認行為來——未必是你想要的。
訓練的目標:把觸發率從 ~65% 拉到 95%,把輸出質量從"勉強能用"拉到"穩定可靠"。
二、訓練循環:4 步閉環
整個訓練過程是一個循環,反覆跑直到滿意:
第 1 步:寫初版 Skill
初版不用追求完美,能表達核心意圖就行。重點關注:
description 寫清楚"什麼時候用"(以 "Use when" 開頭)第 2 步:跑 Eval——讓 skill-creator 幫你測
這一步是關鍵。用 skill-creator 跑評估(需要先安裝:從 github.com/anthropics/skills 倉庫把 skill-creator 目錄放到 ~/.claude/skills/ 下):
skill-creator 會自動做這些事(以下為簡化示意,實際輸出包含更多細節):
觸發率測試:
輸出質量測試:
第 3 步:看數據,定位問題
根據 Eval 結果,問題通常歸為兩類:
觸發率低?→ 改 description
常見原因:
輸出質量差?→ 改正文規則
常見原因:
第 4 步:改進並重跑
根據第 3 步的診斷,做針對性修改。然後再跑一次 Eval,看數字有沒有漲。
比如觸發率從 85% 要拉到 95%,description 改成:
關鍵改動:加了正面觸發詞 + 加了負面排除詞。這樣 AI 就不會把"寫 PR 描述"誤判為需要這個 Skill。
三、讓 Skill 自進化:3 個機制
訓練一次只是起點。真正厲害的是讓 Skill 持續自動進化:
機制 1:用戶反饋驅動迭代
每次 Skill 的輸出不符合你的預期時,直接告訴 AI:
"這個 commit message 不對,多文件修改時應該寫最主要的改動,不要列所有文件"
AI 會自動把這條反饋存入記憶。下次再遇到同樣情況,行為就會改變。
但更進一步——把這條反饋寫回 Skill 本身:
反饋 → 記憶 → 寫回 Skill → 永久生效。這就是自進化。
機制 2:定期跑 Eval 迴歸測試
每兩週跑一次 Eval。原因:
把它當成"單元測試"——代碼改了要跑測試,Skill 改了也要跑 Eval。
機制 3:description 自動優化
skill-creator 有一個殺手級功能:自動優化 description 的觸發準確率。
它會:
根據社區實測分享(Reddit、Medium 上多位開發者的反饋),觸發率從 ~70% 提升到 ~90% 是可預期的。
四、實戰案例:一個 Skill 的 3 次進化
以我自己的 code-review Skill 為例:
v1:初版(第一次跑 Eval 結果:觸發率 65%,輸出質量 C)
問題:description 太模糊("reviewing code"太寬泛),規則太抽象("檢查安全性"具體查什麼?)。
v2:跑 Eval 後優化(觸發率 82%,輸出質量 B)
改進:description 加了具體觸發詞和排除場景,規則從抽象變具體。
v3:用戶反饋 + 自動優化後(觸發率 95%,輸出質量 A)
改進:加了鐵律(防止偷懶)、加了反面案例(防止廢話輸出)、description 經過自動優化觸發率到 95%。
五、Skill 數量多了之後的管理
當你有 10+ 個 Skill 時,新問題出現:Skill 之間互相沖突或搶觸發。
問題 1:多個 Skill 同時觸發
比如你有 code-review 和 security-review 兩個 Skill,用戶說"幫我檢查下這段代碼"——兩個都想觸發。
解決方案: 在 description 裏明確劃分邊界:
問題 2:Skill 過時了
項目從 REST 遷到 tRPC 了,但你的 api-design Skill 裏還寫着 REST 的規範。
解決方案: 每月做一次"Skill 年檢":
問題 3:不確定該不該新建 Skill
判斷標準:你是否在不同會話中重複給 AI 同一條糾正指令了?
如果你發現自己反覆說"不對,我們項目應該這樣做"——就值得寫成 Skill。一次性的、只在特定調試場景出現的指令不需要。
問題 4:什麼內容該寫在 CLAUDE.md,什麼該寫成獨立 Skill
分層策略:
舉例:
CLAUDE.md 給 AI 背景知識,Skill 給 AI 執行手冊。兩者配合,不要混在一起。
六、什麼時候停止迭代
不是無限跑 Eval 就是好的。收斂標準:
觸發率 ≥ 90% 就可以停。 100% 不現實——有些邊界查詢本來就有歧義("幫我看看這段代碼"到底是 review 還是解釋?),追求 100% 反而會讓 description 變得過度具體、喪失泛化能力。
輸出質量連續 2 次 Eval 沒有提升就停。 說明當前規則已經到達了這個 Skill 能覆蓋的上限。再想提升要麼拆成多個 Skill,要麼接受現狀。
一個 Skill 的迭代輪數通常不超過 3-4 輪。 如果 4 輪還不收斂,大概率是 Skill 的定義範圍太大了——拆成 2 個更窄的 Skill 比硬優化一個寬 Skill 效果更好。
七、總結:Skill 訓練的核心心法
最小行動:挑你用得最多的一個 Skill,跑一次 幫我評估 xx skill 的觸發率和輸出質量。看看數據,你會驚訝地發現改進空間有多大。
掃碼關注「AI智聞說」,每天3分鐘掌握AI新知識