【實戰篇】用 OpenClaw 搭建你的"數字打工人"
整理版優先睇
用 OpenClaw 搭建自動運維助手「數字打工人」,從監控到自動修復一條龍
呢篇文章係 H先生 OpenClaw 系列嘅實戰篇,承接前面六篇嘅原理、技能、記憶、定時任務同子 Agent 概念,將佢哋串聯成一個真正用得嘅自動運維系統「數字打工人」。作者目標係搭建一個可以主動彙報、監控告警、自動修復、生成日報嘅助手,等用戶只需要睇推送,唔使手動處理。整體結論係:用 OpenClaw 嘅 cron 工具加子 Agent,配合簡單 Shell 腳本,已經可以實現基礎嘅自動化運維,而且可以逐步擴展到更複雜場景。
文章詳細記錄咗從需求分析到落地嘅完整過程:先寫監控腳本檢查服務器存活,再用定時任務每小時執行,然後加入自動修復子 Agent,最後加上晨報同日報。每個步驟都有具體嘅 JSON 配置同 Shell 腳本,仲有踩坑指南同最佳實踐,例如告警分級、靜默時段、失敗重試等。對於想用 OpenClaw 實現自動化工作流程嘅人,呢篇係好實用嘅參考。
- OpenClaw 可以整合 Shell 腳本、定時任務同子 Agent,搭建一個自動運維系統,實現「只睇推送,佢負責做嘢」。
- 核心方法係用 curl 寫健康檢查腳本,配合 cron 每小時定時執行,並利用子 Agent 自動嘗試修復。
- 相比傳統人手運維,呢個方案大幅減少手動操作,將常見問題(如服務器掛咗)自動化處理。
- 啟發係可以將重複性操作封裝成 Skill 或子 Agent,並通過記憶文件記錄常見問題,令系統越來越聰明。
- 可行動點:跟住文中步驟,由創建檢查腳本開始,逐步加入修復、日報,再擴展到更多監控維度。
服務器存活檢查腳本 (check-server.sh)
用 curl 檢查 HTTP 狀態碼,判斷服務器是否正常。返回 200 就正常,否則異常。附超時 10 秒設定。
自動修復腳本 (fix-server.sh)
通過 SSH 遠程重啓指定服務(例如 nginx),需要預先配置免密登錄同 sudo 免密。
服務器監控+自動修復定時任務
OpenClaw cron job JSON 配置:每小時執行檢查腳本,發現異常時先告警、再執行修復腳本、然後二次檢查、最後彙報結果。正常時靜默。
實戰目標:一個完整嘅「數字打工人」
呢篇文章嘅目標係將 OpenClaw 嘅 定時任務、子 Agent 同 Skill 串聯,搭建一個自動運維助手。佢要具備主動彙報、監控告警、自動修復、日報生成同智能分析嘅能力。最終效果係你只負責睇推送,佢負責做嘢。
- 主動彙報:早上 9 點推送服務器狀態,用定時任務加天氣 Skill。
- 監控告警:每小時檢查服務器存活,掛咗就告警,用定時任務加 Shell 腳本。
- 自動修復:檢測到問題後自動嘗試重啓,用子 Agent 加 SSH。
- 日報生成:下班前生成運維日報,用定時任務加文檔 Skill。
- 智能分析:遇到複雜問題時自動查資料分析,用子 Agent 加聯網搜索。
搭建監控基礎同定時任務
第一步係寫監控腳本。作者用 curl -s -o /dev/null -w "%{http_code}" 嚟檢查服務器 /health 端點,超時設為 10 秒。腳本輸出「✅ 服務器正常」或「🚨 服務器異常」,然後用 exit code 區分狀態。記住要加執行權限先。
#!/bin/bash
SERVER="https://your-server.com"
TIMEOUT=10
RESPONSE=$(curl -s -o /dev/null -w "%{http_code}" --max-time $TIMEOUT $SERVER/health)
if [ "$RESPONSE" = "200" ]; then
echo "✅ 服務器正常 (HTTP $RESPONSE)"
exit 0
else
echo "🚨 服務器異常 (HTTP $RESPONSE 或無法連接)"
exit 1
fi然後建立定時任務,用 OpenClaw 內置 cron 工具。關鍵設定包括 everyMs: 3600000(每小時)、sessionTarget: "isolated"</highlight-inline>(獨立會話,唔污染主對話),同埋 message 入面嘅條件判斷,要求「正常時唔輸出」,避免嘈雜。
{
"action": "add",
"job": {
"name": "服務器存活監控",
"agentId": "main",
"schedule": {"kind":"every","everyMs":3600000},
"sessionTarget": "isolated",
"payload": {
"kind": "agentTurn",
"message": "執行 ~/scripts/check-server.sh。如果輸出包含「異常」,立即告警:服務器可能掛了,請檢查。如果輸出包含「正常」,不輸出任何內容。要求:(1) 不要回復 HEARTBEAT_OK (2) 不要調用 message 工具 (3) 只在異常時輸出 (4) 告警內容控制在 1 句話"
},
"delivery": {"mode":"announce"}
}
}自動修復同智能分析
監控只係發現問題,作者進一步加入自動修復。佢寫咗 fix-server.sh,用 SSH 遠程重啓服務(例如 nginx),前提係要配置好 SSH 免密同 sudo 免密。然後修改定時任務嘅 message,當檢查異常時:先告警,再執行修復腳本,然後再次檢查,最後彙報結果。整個流程由 子 Agent 自動完成。
- 檢查 → 異常 → 告警 → 執行 fix-server.sh → 再次檢查 → 彙報最終結果。
- 正常時保持靜默,唔會產生任何輸出。
智能分析方面,作者示範點樣用手動或自動觸發子 Agent 嚟排查問題,例如服務器 CPU 持續 100% 時,可以叫 OpenClaw 搜索「Linux CPU 100% 排查方法」,生成排查清單。呢個可以整合到告警流程,當條件符合時自動啟動。
自動修復嘅關鍵係將修復腳本同定時任務結合,等系統可以自我癒合
晨報日報同最佳實踐
作者進一步加入 每日晨報(朝早 9 點)同 每日運維日報(下晝 6 點)。晨報包含服務器狀態、天氣同待辦;日報統計告警次數、自動修復成功次數同需要跟進嘅事項。兩個都用 cron 表達式 設定時間,並要求直接輸出內容,唔調用 message 工具。
- 1 P0 緊急:服務器 down → 立即通知 + 自動修復。
- 2 P1 嚴重:部分功能異常 → 通知 + 記錄日誌。
- 3 P2 一般:性能下降 → 只記錄,下班彙報。
最佳實踐仲包括 靜默時段、失敗重試 設定,同埋將常用操作封裝成 Skill(例如 server-health Skill 包含 check.sh、fix.sh、report.sh),仲可以用 MCP 擴展連接 Prometheus、Grafana 等工具。
踩坑指南同進階方向
實戰一定會遇到問題,作者列出咗幾個常見踩坑位:SSH 免密登錄 未配置會令修復腳本失敗;cron 時區 要留意,最好用 ISO 時間加時區後綴;腳本執行權限 要用 chmod +x;日誌文件</highlight-inline> 唔存在時 grep 會報錯,要先 touch 創建。
- SSH 免密:用 ssh-keygen + ssh-copy-id 配置。
- 時區:檢查 date +%z,用正確 ISO 時間。
- 權限:chmod +x ~/scripts/*.sh。
- 日誌:touch ~/logs/server.log ~/logs/alerts.log。
進階方面,作者建議加入 記憶能力(在 MEMORY.md 記錄常見問題同解決方案)、自定義 Skill(將檢查、修復、報告封裝成獨立模塊),同埋通過 MCP 協議</highlight-inline> 連接更多工具(例如數據庫監控、雲服務 API)。最後仲可以搭建 Grafana 可視化面板。
前面六篇文章,我哋學識咗 OpenClaw 嘅原理、技能、記憶、定時任務、子 Agent。而家係時候將呢啲能力串埋一齊,砌一個真正做到嘢嘅「數位打工人」。呢篇文章唔講概念,只講實戰——由需求到落地嘅完整過程。
一、實戰目標:一個完整嘅「數位打工人」
我哋要砌一個自動運維助手,佢有以下能力:
最終效果:你淨係負責睇推送,佢負責做嘢。
二、第一步:起監控基礎
2.1 建立監控腳本
需求:檢查伺服器係咪生還
方案:用 Shell 腳本 + curl
#!/bin/bash
# 保存為 ~/scripts/check-server.sh
SERVER="https://your-server.com"
TIMEOUT=10
# 健康檢查
RESPONSE=$(curl -s -o /dev/null -w "%{http_code}" --max-time $TIMEOUT $SERVER/health)
if [ "$RESPONSE" = "200" ]; then
echo "✅ 服務器正常 (HTTP $RESPONSE)"
exit 0
else
echo "🚨 服務器異常 (HTTP $RESPONSE 或無法連接)"
exit 1
fi說明:
curl -s靜默模式,唔輸出進度-o /dev/null掉咗響應體,淨係留狀態碼-w "%{http_code}"淨係輸出 HTTP 狀態碼--max-time $TIMEOUT超時 10 秒
2.2 測試腳本
# 添加執行權限
chmod +x ~/scripts/check-server.sh
# 測試
~/scripts/check-server.sh
# 輸出:✅ 服務器正常 (HTTP 200) 或 🚨 服務器異常三、第二步:建立定時監控任務
3.1 需求分析
頻率:每個鐘檢查一次 通知:有事先通知,正常嘅時候靜音 渠道:微信
3.2 建立定時任務
用內置 cron 工具:
{
"action": "add",
"job": {
"name": "服務器存活監控",
"agentId": "main",
"schedule": {"kind":"every","everyMs":3600000},
"sessionTarget": "isolated",
"payload": {
"kind": "agentTurn",
"message": "執行 ~/scripts/check-server.sh。如果輸出包含「異常」,立即告警:服務器可能掛了,請檢查。如果輸出包含「正常」,不輸出任何內容。要求:(1) 不要回復 HEARTBEAT_OK (2) 不要調用 message 工具 (3) 只在異常時輸出 (4) 告警內容控制在 1 句話"
},
"delivery": {"mode":"announce"}
}
}關鍵設計:
everyMs: 3600000= 每個鐘(1個鐘 = 3600秒 = 3600000毫秒)sessionTarget: "isolated"= 獨立會話,唔會污染主對話message 入面嘅條件判斷 = 「正常嘅時候唔輸出」
3.3 驗證任務建立
openclaw cron list輸出例子:
job_xxx 服務器存活監控 every 1h enabled next: 10:00四、第三步:加自動修復能力
4.1 需求分析
監控只係發現問題,真正有用嘅係自動修復。
場景:伺服器程序死咗,自動重啟
4.2 建立修復腳本
#!/bin/bash
# 保存為 ~/scripts/fix-server.sh
SERVER="user@your-server.com"
SERVICE="nginx"
echo "嘗試重啓 $SERVER 上的 $SERVICE..."
# SSH 遠程執行(需要提前配置免密登錄)
ssh $SERVER "sudo systemctl restart $SERVICE && echo '重啓成功' || echo '重啓失敗'"前提條件:
本地已經 set 好 SSH 免密登入 伺服器上面 sudo 免密碼(或者喺 sudoers 度 set)
4.3 建立自動修復子 Agent
方案:當監控發現異常,就開動子 Agent 執行修復
喺定時任務度改 message:
{
"action": "add",
"job": {
"name": "服務器存活監控+自動修復",
"agentId": "main",
"schedule": {"kind":"every","everyMs":3600000},
"sessionTarget": "isolated",
"payload": {
"kind": "agentTurn",
"message": "執行 ~/scripts/check-server.sh。如果輸出包含「異常」:(1) 先告警:服務器異常,正在嘗試自動修復 (2) 執行 ~/scripts/fix-server.sh (3) 再次檢查 (4) 彙報最終結果。如果輸出包含「正常」,不輸出任何內容。要求:(1) 不要回復 HEARTBEAT_OK (2) 不要調用 message 工具 (3) 每步操作簡短彙報"
},
"delivery": {"mode":"announce"}
}
}工作流程:
檢查 → 異常 → 告警 → 修復 → 再檢查 → 彙報五、第四步:每日朝早報告
5.1 需求分析
每日朝早 9 點,自動推送:
尋日伺服器運行情況 今日天氣 今日待辦
5.2 建立朝早報告任務
{
"action": "add",
"job": {
"name": "每日晨報",
"agentId": "main",
"schedule": {"kind":"cron","expr":"0 9 * * *"},
"sessionTarget": "isolated",
"payload": {
"kind": "agentTurn",
"message": "生成今日晨報,包含:(1) 昨日服務器監控結果(查 ~/logs/server.log 最後 20 行)(2) 今日天氣(查北京天氣)(3) 今日待辦(查 ~/notes/todo.md)。格式:簡潔清晰,每項 2-3 句話。要求:(1) 不要回復 HEARTBEAT_OK (2) 不要調用 message 工具 (3) 直接輸出晨報內容"
},
"delivery": {"mode":"announce"}
}
}cron 表達式說明:
0 9 * * *= 每日 9:00格式: 分 時 日 月 星期
5.3 效果例子
📊 今日晨報 (2026-05-08)
🖥️ 服務器狀態:昨日運行正常,無異常記錄
🌤️ 天氣:北京晴,15-25℃,適合户外活動
📝 待辦:
- 完成項目文檔整理
- 下午 3 點代碼評審
- 晚上健身房六、第五步:每日日報
6.1 需求分析
每日下晝 6 點,自動生成運維日報:
今日告警次數 處理結果統計 需要人工跟進嘅事項
6.2 建立日報任務
{
"action": "add",
"job": {
"name": "每日運維日報",
"agentId": "main",
"schedule": {"kind":"cron","expr":"0 18 * * 1-5"},
"sessionTarget": "isolated",
"payload": {
"kind": "agentTurn",
"message": "生成今日運維日報,包含:(1) 今日告警次數(grep 統計 ~/logs/alerts.log)(2) 自動修復成功次數 (3) 需要人工跟進的事項。格式:表格 + 簡要說明。要求:(1) 不要回復 HEARTBEAT_OK (2) 不要調用 message 工具 (3) 直接輸出日報內容"
},
"delivery": {"mode":"announce"}
}
}cron 表達式說明:
0 18 * * 1-5= 星期一至五 18:001-5= 星期一至五
七、第六步:智能分析能力
7.1 需求分析
遇到複雜問題嘅時候,自動查資料分析。
場景:伺服器 CPU 持續 100%,要分析原因
7.2 建立分析子 Agent
方案:人手觸發,但可以整合到告警流程度
你:分析服務器 CPU 高的原因
OpenClaw:啓動分析子 Agent...實際操作:
{
"task": "服務器 CPU 持續 100%,請:(1) 搜索「Linux CPU 100% 排查方法」(2) 列出常見原因和排查步驟 (3) 生成排查清單。要求:簡潔清晰,控制在 300 字以內",
"runtime": "subagent",
"mode": "run",
"timeoutSeconds": 300
}自動觸發版本(喺告警 message 度加):
{
"message": "如果 CPU 持續 100% 超過 10 分鐘:(1) 告警 (2) 啓動子 Agent 分析原因 (3) 推送分析結果"
}八、完整架構圖
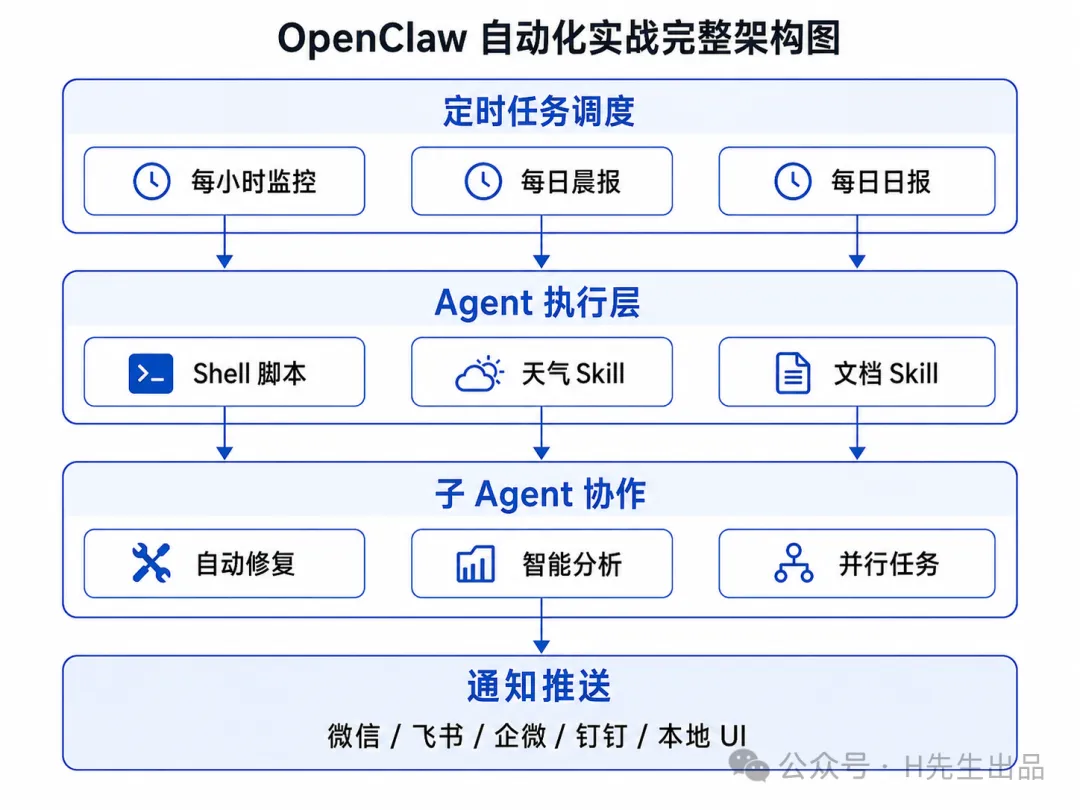
九、設定檔清單
9.1 腳本檔案
9.2 日誌檔案
9.3 數據檔案
十、進階:令「數位打工人」更聰明
10.1 加入記憶能力
喺 OpenClaw 嘅記憶檔案度記錄:
常見問題同解決方案 伺服器歷史數據 個人偏好
示例:在 MEMORY.md 度加:
## 服務器運維記錄
### 常見問題
- CPU 100%:通常是 Node.js 死循環,重啓 pm2
- 內存泄漏:檢查日誌中的 "out of memory",重啓服務
- 磁盤滿:清理 /var/log 和 /tmp
### 個人偏好
- 告警時間:工作日 9:00-18:00
- 告警頻率:同類型問題 1 小時內不重複告警10.2 加入自訂 Skill
將常用操作封裝成 Skill:
示例:創建 server-health Skill
skills/server-health/
├── SKILL.md # 技能說明
├── scripts/
│ ├── check.sh # 檢查腳本
│ ├── fix.sh # 修復腳本
│ └── report.sh # 報告腳本
└── references/
└── common-issues.md # 常見問題庫10.3 加入 MCP 擴展
通過 MCP 協議連接更多工具:
數據庫監控 雲服務 API 監控平台(Prometheus、Grafana)
十一、踩坑指南
11.1 SSH 免密登入設定
問題:執行遠端腳本嘅時候彈出要入密碼
解決:set 好 SSH 免密登入
# 生成密鑰對
ssh-keygen -t rsa -b 4096
# 複製公鑰到服務器
ssh-copy-id user@your-server.com
# 測試
ssh user@your-server.com "echo 'SSH OK'"11.2 cron 時區問題
問題:任務比預期早/遲 8 個鐘
解決:檢查時區
# 查看系統時區
date +%z
# 輸出:+0800
# 使用正確的 ISO 時間
# 錯誤:2026-05-08T09:00:00
# 正確:2026-05-08T09:00:00+08:0011.3 腳本執行權限
問題:彈出「Permission denied」
解決:加執行權限
chmod +x ~/scripts/*.sh11.4 日誌檔案唔存在
問題:grep 報錯「No such file」
解決:先建立檔案
touch ~/logs/server.log
touch ~/logs/alerts.log十二、最佳做法
12.1 告警分級
12.2 靜音時段
避免深夜告警騷擾:
{
"message": "如果是 23:00-08:00,只記錄日誌不告警。其他時間正常告警。"
}12.3 失敗重試
set 任務失敗嘅重試策略:
{
"job": {
...
"failureAlert": {
"mode": "announce",
"after": 2
}
}
}含義:失敗 2 次先告警,避免誤報。
十三、效果驗證
13.1 模擬伺服器故障
# 臨時停止服務
sudo systemctl stop nginx
# 等待下一次檢查(最多 1 小時)
# 或手動觸發:openclaw cron run <jobId>預期效果:
收到告警:伺服器異常,正在嘗試自動修復 收到修復結果:重啟成功/失敗 收到最終狀態:伺服器已恢復/需要人工介入
13.2 檢查日誌
# 查看監控日誌
tail -f ~/logs/server.log
# 查看告警日誌
tail -f ~/logs/alerts.log十四、總結
由零到一嘅完整路徑:
需求分析 → 腳本編寫 → 定時任務配置 → 子 Agent 集成 → 測試驗證 → 持續優化下一步方向:
加更多監控維度(記憶體、磁碟、網絡) 接入雲服務 API(阿里雲、騰訊雲) 起可視化監控面板(Grafana)
系列文章完結
到呢度,OpenClaw 系列文章全部完成:
由認識 OpenClaw,到用佢解決實際問題,希望呢個系列對你有幫助。
撳個讚同關注唔怕迷路,之後仲會分享更多 AI 效率工具。
👨💻 H先生出品 | 專注 AI 工具與效率提升
前面六篇文章,我們學會了 OpenClaw 的原理、技能、記憶、定時任務、子 Agent。現在,是時候把這些能力串聯起來,搭建一個真正能幹活的"數字打工人"了。這篇文章不講概念,只講實戰——從需求到落地的完整過程。
一、實戰目標:一個完整的"數字打工人"
我們要搭建一個自動運維助手,它具備以下能力:
最終效果:你只負責看推送,它負責幹活。
二、第一步:搭建監控基礎
2.1 創建監控腳本
需求:檢查服務器是否存活
方案:用 Shell 腳本 + curl
#!/bin/bash
# 保存為 ~/scripts/check-server.sh
SERVER="https://your-server.com"
TIMEOUT=10
# 健康檢查
RESPONSE=$(curl -s -o /dev/null -w "%{http_code}" --max-time $TIMEOUT $SERVER/health)
if [ "$RESPONSE" = "200" ]; then
echo "✅ 服務器正常 (HTTP $RESPONSE)"
exit 0
else
echo "🚨 服務器異常 (HTTP $RESPONSE 或無法連接)"
exit 1
fi說明:
curl -s靜默模式,不輸出進度-o /dev/null丟棄響應體,只保留狀態碼-w "%{http_code}"只輸出 HTTP 狀態碼--max-time $TIMEOUT超時 10 秒
2.2 測試腳本
# 添加執行權限
chmod +x ~/scripts/check-server.sh
# 測試
~/scripts/check-server.sh
# 輸出:✅ 服務器正常 (HTTP 200) 或 🚨 服務器異常三、第二步:創建定時監控任務
3.1 需求分析
頻率:每小時檢查一次 通知:有問題才通知,正常時靜默 渠道:微信
3.2 創建定時任務
使用內置 cron 工具:
{
"action": "add",
"job": {
"name": "服務器存活監控",
"agentId": "main",
"schedule": {"kind":"every","everyMs":3600000},
"sessionTarget": "isolated",
"payload": {
"kind": "agentTurn",
"message": "執行 ~/scripts/check-server.sh。如果輸出包含「異常」,立即告警:服務器可能掛了,請檢查。如果輸出包含「正常」,不輸出任何內容。要求:(1) 不要回復 HEARTBEAT_OK (2) 不要調用 message 工具 (3) 只在異常時輸出 (4) 告警內容控制在 1 句話"
},
"delivery": {"mode":"announce"}
}
}關鍵設計:
everyMs: 3600000= 每小時(1小時 = 3600秒 = 3600000毫秒)sessionTarget: "isolated"= 獨立會話,不污染主對話message 中的條件判斷 = "正常時不輸出"
3.3 驗證任務創建
openclaw cron list輸出示例:
job_xxx 服務器存活監控 every 1h enabled next: 10:00四、第三步:添加自動修復能力
4.1 需求分析
監控只是發現問題,真正有用的是自動修復。
場景:服務器進程掛了,自動重啓
4.2 創建修復腳本
#!/bin/bash
# 保存為 ~/scripts/fix-server.sh
SERVER="user@your-server.com"
SERVICE="nginx"
echo "嘗試重啓 $SERVER 上的 $SERVICE..."
# SSH 遠程執行(需要提前配置免密登錄)
ssh $SERVER "sudo systemctl restart $SERVICE && echo '重啓成功' || echo '重啓失敗'"前提條件:
本地已配置 SSH 免密登錄 服務器上 sudo 免密碼(或在 sudoers 中配置)
4.3 創建自動修復子 Agent
方案:當監控發現異常時,啓動子 Agent 執行修復
在定時任務中修改 message:
{
"action": "add",
"job": {
"name": "服務器存活監控+自動修復",
"agentId": "main",
"schedule": {"kind":"every","everyMs":3600000},
"sessionTarget": "isolated",
"payload": {
"kind": "agentTurn",
"message": "執行 ~/scripts/check-server.sh。如果輸出包含「異常」:(1) 先告警:服務器異常,正在嘗試自動修復 (2) 執行 ~/scripts/fix-server.sh (3) 再次檢查 (4) 彙報最終結果。如果輸出包含「正常」,不輸出任何內容。要求:(1) 不要回復 HEARTBEAT_OK (2) 不要調用 message 工具 (3) 每步操作簡短彙報"
},
"delivery": {"mode":"announce"}
}
}工作流程:
檢查 → 異常 → 告警 → 修復 → 再檢查 → 彙報五、第四步:每日晨報
5.1 需求分析
每天早上 9 點,自動推送:
昨日服務器運行情況 今日天氣 今日待辦
5.2 創建晨報任務
{
"action": "add",
"job": {
"name": "每日晨報",
"agentId": "main",
"schedule": {"kind":"cron","expr":"0 9 * * *"},
"sessionTarget": "isolated",
"payload": {
"kind": "agentTurn",
"message": "生成今日晨報,包含:(1) 昨日服務器監控結果(查 ~/logs/server.log 最後 20 行)(2) 今日天氣(查北京天氣)(3) 今日待辦(查 ~/notes/todo.md)。格式:簡潔清晰,每項 2-3 句話。要求:(1) 不要回復 HEARTBEAT_OK (2) 不要調用 message 工具 (3) 直接輸出晨報內容"
},
"delivery": {"mode":"announce"}
}
}cron 表達式說明:
0 9 * * *= 每天 9:00格式: 分 時 日 月 星期
5.3 效果示例
📊 今日晨報 (2026-05-08)
🖥️ 服務器狀態:昨日運行正常,無異常記錄
🌤️ 天氣:北京晴,15-25℃,適合户外活動
📝 待辦:
- 完成項目文檔整理
- 下午 3 點代碼評審
- 晚上健身房六、第五步:每日日報
6.1 需求分析
每天下午 6 點,自動生成運維日報:
今日告警次數 處理結果統計 需要人工跟進的事項
6.2 創建日報任務
{
"action": "add",
"job": {
"name": "每日運維日報",
"agentId": "main",
"schedule": {"kind":"cron","expr":"0 18 * * 1-5"},
"sessionTarget": "isolated",
"payload": {
"kind": "agentTurn",
"message": "生成今日運維日報,包含:(1) 今日告警次數(grep 統計 ~/logs/alerts.log)(2) 自動修復成功次數 (3) 需要人工跟進的事項。格式:表格 + 簡要說明。要求:(1) 不要回復 HEARTBEAT_OK (2) 不要調用 message 工具 (3) 直接輸出日報內容"
},
"delivery": {"mode":"announce"}
}
}cron 表達式說明:
0 18 * * 1-5= 週一到週五 18:001-5= 週一到週五
七、第六步:智能分析能力
7.1 需求分析
遇到複雜問題時,自動查資料分析。
場景:服務器 CPU 持續 100%,需要分析原因
7.2 創建分析子 Agent
方案:手動觸發,但可以集成到告警流程中
你:分析服務器 CPU 高的原因
OpenClaw:啓動分析子 Agent...實際操作:
{
"task": "服務器 CPU 持續 100%,請:(1) 搜索「Linux CPU 100% 排查方法」(2) 列出常見原因和排查步驟 (3) 生成排查清單。要求:簡潔清晰,控制在 300 字以內",
"runtime": "subagent",
"mode": "run",
"timeoutSeconds": 300
}自動觸發版本(在告警 message 中加入):
{
"message": "如果 CPU 持續 100% 超過 10 分鐘:(1) 告警 (2) 啓動子 Agent 分析原因 (3) 推送分析結果"
}八、完整架構圖
九、配置文件清單
9.1 腳本文件
9.2 日誌文件
9.3 數據文件
十、進階:讓"數字打工人"更智能
10.1 加入記憶能力
在 OpenClaw 的記憶文件中記錄:
常見問題和解決方案 服務器歷史數據 個人偏好
示例:在 MEMORY.md 中加入:
## 服務器運維記錄
### 常見問題
- CPU 100%:通常是 Node.js 死循環,重啓 pm2
- 內存泄漏:檢查日誌中的 "out of memory",重啓服務
- 磁盤滿:清理 /var/log 和 /tmp
### 個人偏好
- 告警時間:工作日 9:00-18:00
- 告警頻率:同類型問題 1 小時內不重複告警10.2 加入自定義 Skill
把常用操作封裝成 Skill:
示例:創建 server-health Skill
skills/server-health/
├── SKILL.md # 技能說明
├── scripts/
│ ├── check.sh # 檢查腳本
│ ├── fix.sh # 修復腳本
│ └── report.sh # 報告腳本
└── references/
└── common-issues.md # 常見問題庫10.3 加入 MCP 擴展
通過 MCP 協議連接更多工具:
數據庫監控 雲服務 API 監控平台(Prometheus、Grafana)
十一、踩坑指南
11.1 SSH 免密登錄配置
問題:執行遠程腳本時提示輸入密碼
解決:配置 SSH 免密登錄
# 生成密鑰對
ssh-keygen -t rsa -b 4096
# 複製公鑰到服務器
ssh-copy-id user@your-server.com
# 測試
ssh user@your-server.com "echo 'SSH OK'"11.2 cron 時區問題
問題:任務比預期早/晚 8 小時
解決:檢查時區
# 查看系統時區
date +%z
# 輸出:+0800
# 使用正確的 ISO 時間
# 錯誤:2026-05-08T09:00:00
# 正確:2026-05-08T09:00:00+08:0011.3 腳本執行權限
問題:提示 "Permission denied"
解決:添加執行權限
chmod +x ~/scripts/*.sh11.4 日誌文件不存在
問題:grep 報錯 "No such file"
解決:先創建文件
touch ~/logs/server.log
touch ~/logs/alerts.log十二、最佳實踐
12.1 告警分級
12.2 靜默時段
避免深夜告警打擾:
{
"message": "如果是 23:00-08:00,只記錄日誌不告警。其他時間正常告警。"
}12.3 失敗重試
配置任務失敗時的重試策略:
{
"job": {
...
"failureAlert": {
"mode": "announce",
"after": 2
}
}
}含義:失敗 2 次後才告警,避免誤報。
十三、效果驗證
13.1 模擬服務器故障
# 臨時停止服務
sudo systemctl stop nginx
# 等待下一次檢查(最多 1 小時)
# 或手動觸發:openclaw cron run <jobId>預期效果:
收到告警:服務器異常,正在嘗試自動修復 收到修復結果:重啓成功/失敗 收到最終狀態:服務器已恢復/需要人工介入
13.2 檢查日誌
# 查看監控日誌
tail -f ~/logs/server.log
# 查看告警日誌
tail -f ~/logs/alerts.log十四、總結
從零到一的完整路徑:
需求分析 → 腳本編寫 → 定時任務配置 → 子 Agent 集成 → 測試驗證 → 持續優化下一步方向:
加入更多監控維度(內存、磁盤、網絡) 接入雲服務 API(阿里雲、騰訊雲) 搭建可視化監控面板(Grafana)
系列文章完結
至此,OpenClaw 系列文章全部完成:
從認識 OpenClaw,到用它解決實際問題,希望這個系列對你有幫助。
點點贊和關注不迷路,後續還會分享更多 AI 效率工具。
👨💻 H先生出品 | 專注 AI 工具與效率提升