實測MiniMax M3:多模態跑長程,比 M2.7 強太多
整理版優先睇
MiniMax M3 實測:原生多模態加 1M 上下文,長程任務完成度超出預期
呢篇文章係作者對 MiniMax 最新模型 M3 嘅實測分享。M3 今次主打原生多模態(由訓練開始就一齊學文字、圖像同影片)同埋 1M 嘅超長上下文,仲有強勁嘅 Agent 能力。作者一直等緊呢個模型,因為之前官方預告咗一種新注意力機制——MiniMax Sparse Attention,令佢好期待。M3 上線之後,作者用幾個真實嘅工作任務去測試,由簡單到複雜,逐步驗證 M3 嘅能力。整體結論係:M3 唔單止做得耐,仲可以「帶住眼」做任務,即係同時理解圖片、影片,然後長時間執行複雜指令,呢個係之前 Agent 賽道未見過嘅方向。
作者先用一個簡單需求:畀一堆素材(影片、圖片、文檔),叫 M3 做一個企業官網。佢用一句話講清楚,M3 嘅 Agent(Claude Code 接入 M3)自己讀素材、寫代碼、部署,仲自動修復錯誤,16 分鐘就交貨,完全唔使中間溝通。第二個測試係跟住一個 PPT 影片教程做效果,作者直接將影片畀 M3 叫佢睇完教人,M3 唔單止將影片步驟變成文字 SOP,仲自己跟住步驟做咗一個 PPT 出嚟,最後仲將呢個流程整成一個 Skill 方便重用。
第三個測試係最勁嘅:叫 M3 由零開始復現一篇 ICLR 2025 獲獎論文嘅核心實驗,成個過程長達 12 小時,M3 自己產出 18 次代碼提交、23 張實驗圖,仲成功觀察到論文講嘅「擠壓效應」同驗證緩解方法。呢個任務需要同時理解論文嘅圖表公式、處理超…
- M3 原生多模態加上 1M 上下文,Agent 可以長時間執行需要「睇」嘅任務,係 Agent 賽道新方向。
- 用一句話指令,M3 可以自動從影片、圖片、文檔等多種素材生成完整網站或 PPT,中間唔使反覆溝通。
- M3 能夠自主連續工作 12 小時復現 ICLR 論文,證明多模態長程任務嘅完成度好高。
- 背後嘅 MiniMax Sparse Attention 用「少睇」策略大幅降低計算成本,長上下文先變得實用。
- 官方 Token Plan 中檔套餐性價比凸出,比 Claude 同 GLM 嘅類似計劃更抵用。
PPT 影片教程轉化 Skill
M3 自動將一個 PPT 文字遮罩效果嘅影片教程,理解成圖文 SOP,再根據素材生成 PPT,最後將成個流程封裝成 Skill,方便日後重用。
M3 發佈:原生多模態加長上下文,上手即見真章
MiniMax 尋日發佈咗 M3,支援 原生多模態、1M 上下文,而且 Agent 能力好強。作者之前已經留意到官方預告嘅新注意力機制,一直等緊模型上線,今次終於可以親自實測。
一句話需求,從影片素材直接出官網
第一個測試係幫朋友做一個企業門户網站。素材包入面有 影片、圖片、文檔、代碼等,作者用一句話指令叫 M3 嘅 Agent 參考呢啲素材做一個展示頁。
- 1 M3 嘅 Agent(Claude Code 接入 M3)自己讀素材包,理解圖片、影片同文案,然後寫代碼、本地測試、部署。
- 2 中間因為服務器環境問題出咗 404 錯誤,Agent 自動查錯改路徑再上傳,完全唔使用戶插手。
- 3 由發出需求到收到網址,淨係用咗 16 分鐘,係一條完整嘅交付鏈,唔使反覆溝通。
Agent 影片理解:由教程到 PPT 一氣呵成
作者之前收藏咗一個 PPT 教學影片,想學入面嘅文字遮罩效果。佢直接將 影片傳畀 M3,話「睇下呢個影片,教我」。
- M3 將影片嘅動作步驟逐個抽出,變成文字版 SOP,連合併形狀要先揀矩形再按 Shift 揀文字呢類細節都還原到。
- 作者叫 M3 直接跟住步驟做 PPT,M3 自己安裝依賴、揾素材、一步步點擊,半個鐘後就交咗一個動效好完整嘅 PPT。
- 作者叫 M3 將呢個流程整成 Skill,方便下次重用。呢個係原生多模態嘅自然落點:快速將無文檔、節奏快嘅影片變成可執行嘅生產資料。
連軸 12 小時復現 ICLR 獲獎論文
最令作者驚訝嘅係 M3 嘅長程能力。官方展示咗一個極端測試:將 ICLR 2025 Outstanding Paper Award 論文《Learning Dynamics of LLM Finetuning》畀 M3,叫佢由零復現核心實驗。
- M3 自己跑咗接近 12 小時,中途產出 18 次代碼提交、23 張實驗圖,成功將核心實驗跑通。
- 佢對上咗 SFT 階段嘅概率變化趨勢,觀察到 DPO 入面嘅 擠壓效應(squeezing),仲驗證咗原論文提出嘅緩解方法。
- 呢個任務需要同時理解論文嘅圖表公式、處理十幾個鐘嘅上下文,持續 Coding 同除錯,係 多模態+長上下文+Coding 疊加嘅結果。
背後機制:MiniMax Sparse Attention 與 Token Plan 套餐
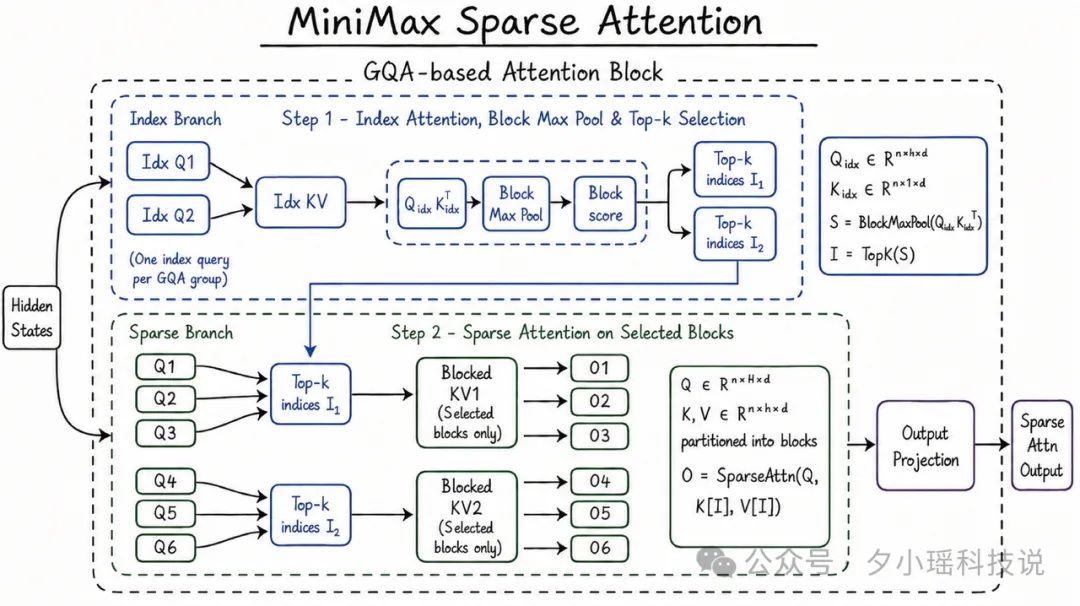
M3 做到 1M 上下文嘅關鍵係 MiniMax Sparse Attention。傳統注意力每讀一個字都要同前面所有字比較,字數翻倍計算量翻四倍。業界解決方法有兩條路:少睇或者壓縮。
- 1 Kimi 嘅 MoBA:將上下文切成一塊塊,每讀一句先判斷要睇邊幾塊,按塊揀。
- 2 DeepSeek 嘅 DSA:用輕量索引器直接揀相關 token,更精細但索引器未必準。
- 3 M3 嘅 MSA 都係行少睇路線,但官方話佢嘅 塊分得更精準,對相關內容覆蓋更全面。
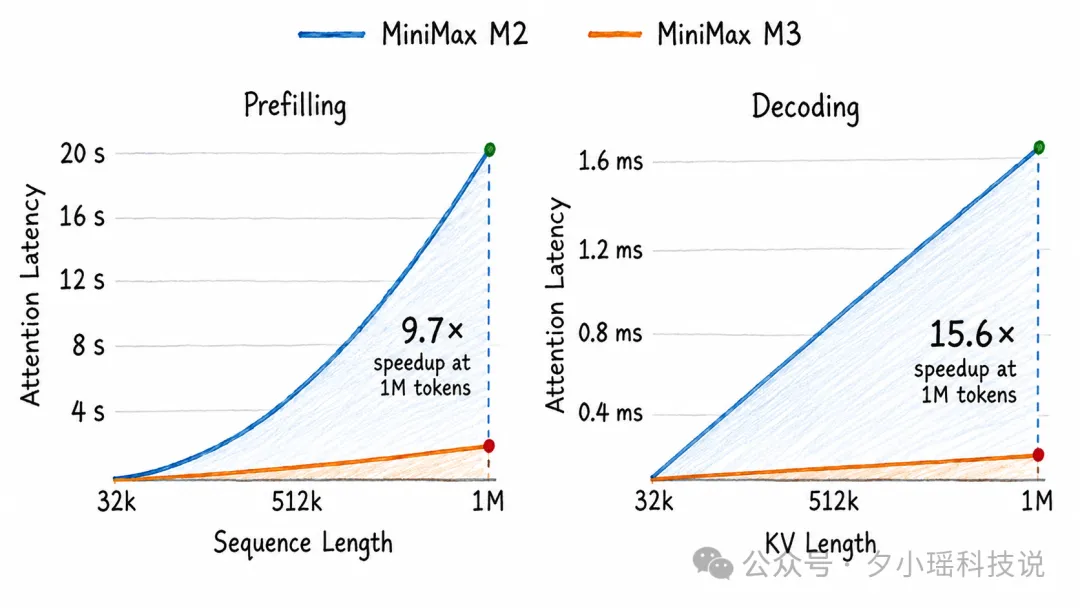
實際效果上,100 萬字上下文入面,M3 每個字嘅計算量只有上一代嘅 1/20,prefilling 快 9 倍,decoding 快 15 倍。只有成本壓低,先敢將 1M 上下文當做默認能力。
琴日,MiniMax M3推出咗,支援原生多模態、1M上下文,仲有Agent能力好強。
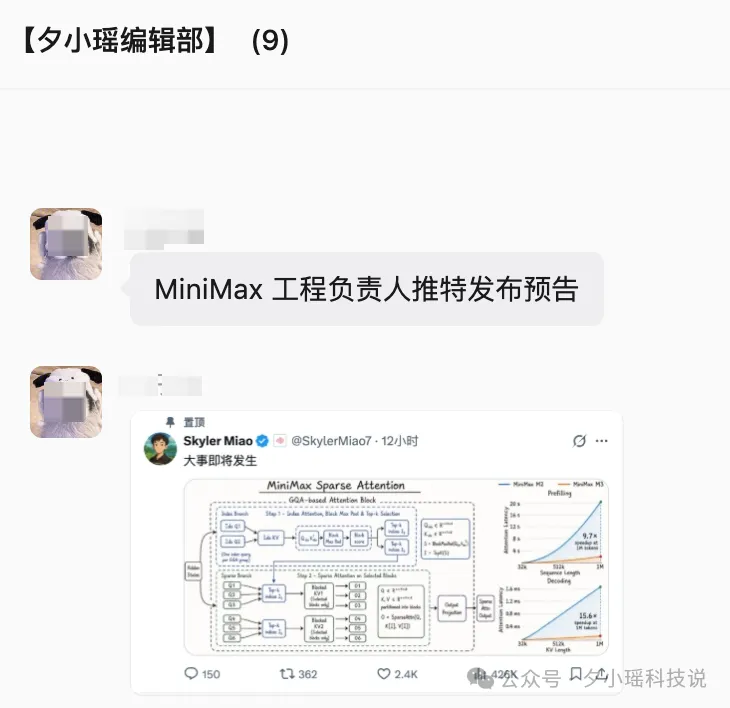
老實講我已經等咗佢幾日,之前MiniMax嘅工程負責人Skyler Miao喺X上面放咗一張預告圖,非常技術核心,提早預告咗一種新嘅注意力機制——MiniMax Sparse Attention,好明顯就係M3嘅預告。
技術係模型嘅基礎,但係體感唔夠直接。
直到琴日模型上線,我哋親手實測咗一輪,我先對今次M3嘅升級有咗真實體感。
今次升級,最直接嘅得兩點:原生多模態,同埋頂得順長程任務嘅能力。
啱啱好,我手頭壓住幾件一直冇時間做嘅嘢,都卡喺呢個位。由簡單到難,我哋一齊睇下M3嘅完成度。
◈一句話需求,由視頻素材直接出一個官網
第一個任務,係有個朋友想幫業務做個入口網站。
聽起嚟唔複雜,但麻煩嘅係素材有好多種格式,視頻、圖片、文件、程式碼等等。

我將幾乎原樣嘅需求send咗畀接咗M3嘅Claude Code,就一句話:
請參考呢啲素材,做一個企業官網嘅展示頁。素材包裏面嘅文字、圖片、視頻都要放喺合適嘅位置,唔好漏咗,整體風格一致要可用,靚啲。你可以喺伺服器上面揾個合適嘅位置部署展示。
佢自己讀素材包,圖片、視頻、文案都睇咗一次,然後寫程式碼、本地測試、部署。中間伺服器環境亂,部署完一直404,佢都自己查到係路徑錯咗,改完重新上傳,冇要我插手。
發完需求16分鐘,佢掉咗個網址畀我:做好咗,你睇下。
將素材準備好,需求講清楚,M3接嘅就係一條交付鏈。中間唔使反覆拗啦。
◈Agent嘅視頻理解都有得救,到PPT生成一氣呵成
之前收藏過一個PPT教學——整成同電影開場一樣嘅文字遮罩效果。
視頻得一分鐘,節奏都幾快。如果跟住做嘅話,要重複睇,一步步跟住操作步驟做,先學得識。
(視頻來源:抖音:阿欣說個P(PPT定製)2022年10月視頻)
今次我將視頻直接send咗畀MiniMax Code(M3嘅專屬Agent),只講咗一句:睇下呢個視頻,教我。
M3直接將視頻裏面嘅動作扒咗做文字版SOP,細節佢都摳咗出嚟,例如合併形狀,要揀咗矩形先、再按住Shift揀文字,順序相反效果就唔啱。
我基本上都用緊Claude Code,做到,但細節唔及呢個。
再進一步,既然教學可以直接睇得明。我心諗,如果繼續叫佢做落去呢?M3自己有寫程式碼、叫工具、操作檔案嘅能力㗎!
於是,我繼續落指令:用呢個素材包直接幫我整好PPT。
接着就係一連串猛虎操作——安裝依賴、揾素材、跟住視頻教學一步步㩒....
半個鐘之後,M3交貨啦——
睇得出,對最初嘅動態效果復刻得好完美,只係我嘅素材拖累咗佢。。
為咗累積呢種整優質PPT嘅能力,我索性就畀M3將佢整成skill,下次繼續用。
我想,呢個都係佢原生多模態比較自然嘅落點,快速將一個冇文件、節奏又快嘅視頻,變成可以繼續執行嘅生產資料。
到呢一步,我基本上有咗實感,M3可以直接理解圖片、視頻,吞落好長嘅資料同程式碼去跑任務。
◈連續12個鐘重現一篇ICLR獲獎論文
前面兩件事其實都係小嘢,真正厲害嘅係連續做十幾個鐘、中途冇人接手嘅長任務。
呢件事最近國產模型其實都在鬥。通義嘅Qwen3.7-Max、智譜GLM、Kimi,成日一口氣叫兩三百次工具唔使人管。
但係呢啲長任務幾乎大同小異,就係死磕程式碼+工具,係文字處理。
M3今次令我出乎意料嘅係,多模態+長程,即係帶住對眼跑長任務。
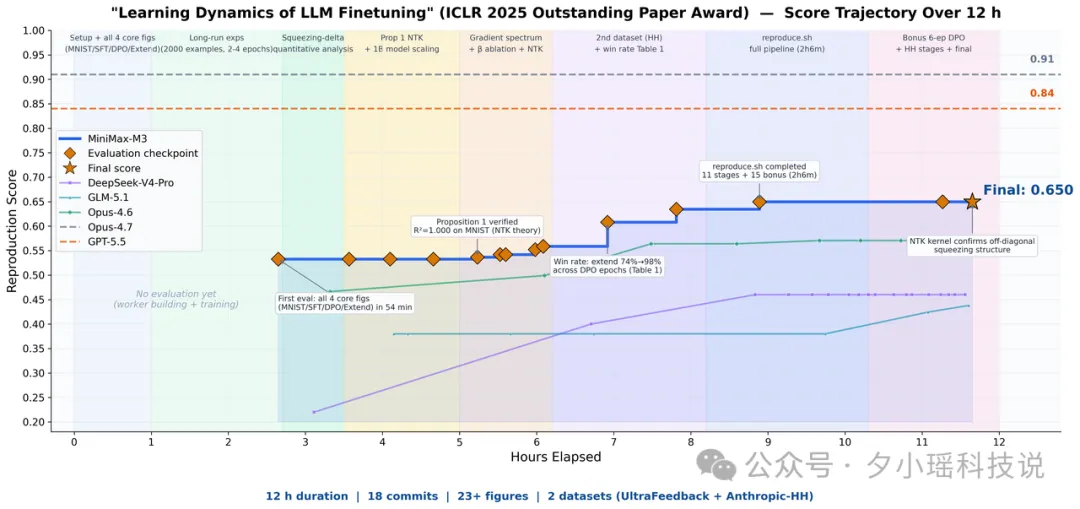
官方自己做咗個更狠嘅測試:將一篇ICLR 2025 Outstanding Paper Award論文 _Learning Dynamics of LLM Finetuning_掉畀M3,叫佢從頭重現。
M3自己跑咗接近12個鐘,中途產出18次提交、23張實驗圖,將核心實驗跑通咗。佢對應到SFT階段嘅概率變化趨勢,觀察到DPO裏面嘅擠壓效應(squeezing),仲驗證咗原論文畀嘅緩解方法。
呢個任務淨係識寫程式碼唔夠。論文裏面嘅曲線、公式要睇得明,十幾個鐘嘅論文、程式碼、日誌要一直裝喺上下文記憶入面。
呢啱啱就係M3嘅多模態、長上下文、coding能力疊加嘅地方。
多模態負責睇得明圖表、公式同視頻;百萬上下文負責將論文、程式碼、日誌同中間判斷一齊裝入腦;Coding/Agentic 負責持續推進任務,不斷改錯、提交、驗證。
◈M3背後係一種新嘅注意力機制
M3做到1M嘅上下文,開頭嗰張預告圖,就係核心。
一種新嘅注意力機制——MiniMax Sparse Attention。
先講清楚,長點解貴?
傳統注意力入面,模型每讀一個字,都要回頭同前面所有字逐個比較一次。讀到第100萬個字,就要比較100萬次。字數翻倍,計算量翻四倍。
如果處理到超長上下文,業界其實得兩條路:少睇,或者壓縮。
少看:唔同所有字硬比,先篩一次,只揀相關嘅計。點睇點揀,各家唔同。例如
Kimi嘅MoBA:將上下文切成一塊塊,每讀一句先判斷應該揭邊幾塊,只揭嗰幾塊,按塊揀。 DeepSeek嘅DSA:更細,唔按塊。用一個輕量級索引器喺全文直接揀相關嘅token,按token揀,但索引器估嘅未必準。
壓縮係另一條:唔揀,先將內容壓成摘要再讀。DeepSeek嘅MLA行呢條路。
M3嘅MSA都係行少睇呢條路徑。但官方話佢嘅塊分得更精準,對真正相關嘅內容覆蓋得更全面。
落到實際差別,100萬字嘅上下文入面,M3每個字嘅計算量得上一代嘅1/20,prefilling(預填充)階段加速超過9倍,decoding(解碼)階段超過15倍。
只有將「長」嘅成本壓低,先敢用100萬上下文做默認能力。
另一半係原生多模態,關鍵在於原生。
M3唔係先訓練好一個文字模型再外加睇圖模組,而係由訓練第一步開始,文字、圖文、視頻就溝埋一齊餵。
佢嘅預訓練規模做到100T量級。
當然,但原生多模態係有代價嘅。從頭就用圖文、視頻一齊訓練,成本一定比只餵文字嘅純文字模型高一截,跑起嚟食嘅記憶體同運算力都更多。
用咗可以直接睇圖睇視頻,1M上下文嘅模型,照道理推理成本係要翻幾倍。但係今次一齊更新嘅仲有Token Plan——MiniMax直接賣畀個人用戶嘅套餐。
官方畀出三款套餐,我大概計咗計,裏面第二檔MAX套餐競爭力好強,唔使120蚊嘅價錢,用量大概相當於Claude MAX 100美金套餐嘅兩倍。同GLM Coding Plan呢類國產訂閲相比,雖然計費角度唔同,M3畀出嘅中檔價格依然係最抵嘅。。
同GLM Coding Plan呢類國產訂閲相比,雖然計費角度唔同,但社區反饋喺中高強度Agent使用場景裏面,M3畀出嘅中檔價格更低、額度更闊。
綜合計落,最推薦嘅就係中檔套餐,好抵。
當然,講到尾平只係前提,M3今次真正令我意外嘅地方,係多模態長程任務嘅完成度。
Agent賽道喺長程鬥咗大半年,一直以嚟嘅指標係睇邊個唔間斷做得耐。
M3反而開咗另一個方向,唔止做得耐,係可以邊睇邊做。

昨天,MiniMax M3發佈了,支持原生多模態、1M上下文,而且Agent能力很強。
說實話我已經等它好幾天了,之前MiniMax 的工程負責人 Skyler Miao 在 X 上放了一張預告圖,非常技術內核,提前預告了一種新的注意力機制——MiniMax Sparse Attention,很明顯就是M3的預告。
技術是模型的底子,但是體感不夠直接。
直到昨天模型上線,我們上手實測了一輪,我才對這次M3的升級有了真實體感。
這次升級,最直接的就兩點:原生多模態,和扛長程任務的能力。
正好,我手頭壓着幾件一直沒空乾的活,都卡在這個點上。由簡到難,我們一起看下M3的完成度。
◈一句話需求,從視頻素材直接出一個官網
第一個活兒,是個朋友想給業務做個門户網站。
聽起來不復雜,但麻煩就在於素材有多種格式,視頻、圖片、文檔、代碼等等。
我把幾乎原樣的需求發給接了 M3 的 Claude Code,就一句話:
請參考這些素材,做一個企業官網的展示頁。素材包裏的文字、圖片、視頻都要放在合適的位置,不要遺漏,整體風格一致可用,好看點。你可以在服務器上找個合適的位置部署展示。
它自己讀素材包,圖片、視頻、文案都過了一遍,然後寫代碼、本地測試、部署。中間服務器環境髒,部署完一直404,它也自己查到是路徑錯了,改完重新傳上去,沒用我插手。
發完需求 16 分鐘,它丟給我一個網址:做好了,你看看。
把素材準備好,需求講清楚,M3接的就是一條交付鏈。中間不用反覆掰扯了。
◈Agent的視頻理解也有救了,到PPT生成一氣呵成
之前收藏過一個 PPT 教程——做成和電影開場一樣的文字遮罩效果。
視頻就一分鐘,節奏挺快。如果照着做的話,得反覆觀看,一步步照着操作步驟走,才能學會。
(視頻源:抖音:阿欣說個P(PPT定製)2022年10月視頻)
這次我把視頻直接發給 MiniMax Code(M3 的專屬 Agent),只說了一句:看下這個視頻,教我。
M3直接把視頻裏的動作扒成了文字版SOP,細節它也摳出來了,比如合併形狀,得先選矩形、再按住 Shift選文字,順序反了效果就不對。
我基本都在用Claude Code,能做,但是細節不如這個。
更進一步,既然教程都能直接看懂了。我心想,如果繼續讓它往下做呢?M3自己有寫代碼、調工具、操作文件的能力誒!
於是,我接着下達指令:用這個素材包直接幫我做好ppt。
接着就是一連串猛虎操作——安裝依賴、尋找素材、按照視頻教程一步步點擊....
半小時後,M3交付了——
看得出來,對最初的動效復刻得非常完美,只是我的素材耽誤了孩子。。
為了積累這種做優質PPT的能力,我索性就讓M3把它做成skill,下次接着用。
我想,這也是它原生多模態比較自然的落點,快速把一個沒有文檔、節奏又快的視頻,變成可以繼續執行的生產資料。
到這一步,我基本有了實感,M3可以直接理解圖片、視頻,吃下很長的資料和代碼去跑任務。
◈連軸 12 小時復現一篇 ICLR 獲獎論文
前面兩件事其實都是小活兒,真正的厲害的是連軸幹十幾個小時、中途沒人接手的長活。
這事最近國產模型其實都在拼。通義的 Qwen3.7-Max 、智譜 GLM、Kimi,動輒一口氣調兩三百次工具不用人管。
但是這些長活幾乎大同小異,就是死磕代碼+工具,是文本的處理。
M3這次讓我出乎意料的是,多模態+長程,也就是帶着眼睛跑長任務。
官方自己做了個更狠的測試:把一篇ICLR 2025 Outstanding Paper Award 論文 _Learning Dynamics of LLM Finetuning_丟給M3,讓它從零復現。
M3 自己跑了接近 12 小時,中途產出 18 次提交、23 張實驗圖,把核心實驗跑通了。它對上了 SFT階段的概率變化趨勢,觀測到了 DPO 裏的擠壓效應(squeezing),還驗證了原論文給的緩解辦法。
這活兒光會寫代碼不夠。論文裏的曲線、公式得看懂,十幾個小時的論文、代碼、日誌得一直裝在上下文記憶裏。
這恰好就是M3的多模態、長上下文、coding能力疊起來的地方。
多模態負責看懂圖表、公式和視頻;百萬上下文負責把論文、代碼、日誌和中間判斷一起裝進腦子;Coding/Agentic 負責持續推進任務,不斷修錯、提交、驗證。
◈M3背後是一種新的注意力機制
M3能做到1M的上下文,開頭那張預告圖,就是核心。
一種新的注意力機制——MiniMax Sparse Attention。
先說清楚,長為什麼貴?
傳統注意力裏,模型每讀一個字,都要回頭跟前面所有字挨個比一遍。讀到第 100萬個字,就要比 100 萬次。字數翻倍,計算量翻四倍。
如果能處理地起超長上下文,業界其實就兩條路:少看,或者壓縮。
少看:不跟所有字硬比,先篩一遍,只挑相關的算。怎麼看怎麼挑,各家不同。比如
Kimi 的 MoBA:把上下文切成一塊塊,每讀一句先判斷該翻哪幾塊,只翻那幾塊,按塊挑。 DeepSeek 的 DSA:更細,不按塊。用一個輕量索引器在全文裏直接挑相關的 token,按token挑,但是索引器估的不一定準。
壓縮是另一條:不挑,先把內容壓成摘要再讀。DeepSeek 的 MLA 走這條路。
M3 的 MSA也是走少看這個路徑。但官方說它的塊分得更精準,對真正相關的內容覆蓋得更全。
落到實際差別上,100萬字的上下文裏,M3每個字的計算量只有上一代的 1/20,prefilling(預填充)階段加速超過9倍,decoding(解碼)階段超過15倍。
只有把“長”的成本壓下來,才敢拿100萬上下文當默認能力用。
另一半是原生多模態,關鍵在原生。
M3不是先訓好一個文字模型再外掛看圖模塊,而是從訓練第一步起,文字、圖文、視頻就混在一起喂。
它的預訓練規模做到了100T量級。
當然,但原生多模態是有代價的。從頭就拿圖文、視頻一起訓,成本必然比只喂文字的純文本模型高一截,跑起來吃的內存和算力也更多。
用上能直接看圖看視頻,1M上下文的模型,按道理推理成本是要翻好幾倍。但是這次一同更新的還有Token Plan——MiniMax直接賣給個人用戶的套餐。
官方給出了三檔套餐,我大概算了算,裏面第二檔MAX套餐競爭力非常強,不到120元的價格,用量大致相當於Claude MAX 100刀套餐的兩倍。和GLM Coding Plan這類國產訂閲相比,雖然計費口徑不同,M3給出的中檔價格依舊是最划算的。
和GLM Coding Plan這類國產訂閲相比,雖然計費口徑不同,但社區反饋在中高強度 Agent 使用場景裏,M3給出的中檔價格更低、額度更寬。
綜合算下來,最推薦的就是中檔套餐,非常划算。
當然,說到底便宜只是前提,M3這次真正讓我意外的地方,是多模態長程任務的完成度。
Agent賽道卷長程捲了大半年,一直以來的指標是看誰不間斷乾的久。
M3反倒開啓了另一個方向,不只是幹得久,是能邊看邊幹。