實現 Karpathy 的神級腳本:讓Agent自我進化
整理版優先睇
用 PI-autoresearch 實現 Karpathy 嘅自動實驗循環,等 Agent 自主優化代碼,你只需定義指標同等結果
呢篇文章由 Karpathy 嘅 autoresearch 項目出發,講點樣用 PI 呢個極簡終端工具,整出一個可以通宵幫你做性能優化嘅 AI Agent。
作者先介紹 Karpathy 嘅核心哲學:「Try an idea, measure it, keep what works, discard what doesn't, repeat forever。」佢開源咗 autoresearch,將 Claude 或 Codex 放入代碼倉庫,等 agent 自主改模型架構、優化器、超參數,跑 5 分鐘訓練睇 val_loss 有冇降低。但呢個方案冇內置實驗管理,上下文窗口一滿就會失憶。
跟住作者引入 PI 呢個工具——佢唔係重框架而係極簡殼,只提供終端交互接口,所有複雜邏輯靠擴展同技能實現。開發者 davebcn87 將 Karpathy 嘅思想移植到 PI 上,整咗 PI-autoresearch 插件,加入儀表盤、實驗管理、自動分支清理等功能。
- 結論:實驗驗證比一次性長程規劃更可靠,環境嘅真實反饋係最好嘅糾偏器
- 方法:用 PI 呢個極簡框架搭建 harness,等 Agent 自主執行 Edit → Commit → Run → Log → Evaluate 循環
- 差異:PI-autoresearch 唔似 AutoGen 等重框架,佢只係一個殼,所有上層邏輯靠擴展實現,保持 prompt 極簡
- 啟發:用算力(LLM API 消耗)換取絕對可靠性,特別適合有明確衡量指標嘅優化任務
- 可行動點:定義好優化目標同 metric,執行 /skill:autoresearch-create,然後等結果;最後用 /skill:autoresearch-finalize 將有效修改拆成獨立分支方便 code review
PI-autoresearch GitHub repo
插件源碼同使用說明
PI 官方網站
極簡 terminal-based coding agent
Karpathy 嘅 autoresearch 項目
靈感來源,原始嘅自主研究腳本
靈感起源:Karpathy 嘅 autoresearch
2026 年 3 月,Andrej Karpathy 開源咗 autoresearch,基於佢嘅 nanochat 框架。核心思路係:將 AI agent(Claude 或 Codex)放進代碼倉庫,等佢自主修改訓練代碼,跑 5 分鐘訓練,睇 val_loss 有冇降低。
但 autoresearch 原始架構好粗糙:只係一份 program.md 加一個 train.py,你需要手動打開 Claude 或 Codex,指向倉庫。佢冇內置嘅 實驗管理、狀態持久化、分支清理 或 進度監控。一旦 agent 嘅上下文窗口溢出,之前嘅實驗記憶就全丟失。
PI:唔造輪子,只造「馬具」
要令 AI 接管實驗循環,需要一個能喺終端執行命令、管理代碼嘅工具。呢個就係 PI (pi.dev) 出場嘅原因。相對於 AutoGen、CrewAI 等重框架,PI 嘅作者 Mario Zechner 走咗極簡路線。
PI 擁有極其乾淨嘅 System Prompt,畀開發者留低巨大嘅「上下文工程 (Context Engineering)」空間。正因為咁輕量化同高擴展性,開發者 davebcn87 成功將 Karpathy 嘅思想移植到 PI 上,開發出 PI-autoresearch 插件。
拆解 PI-autoresearch 嘅架構與工作流
安裝 PI-autoresearch 後,佢會喺終端上方注入一個 Dashboard,並喺後台掛載三個核心工具:init_experiment、run_experiment 同 log_experiment。成個工作流分三個階段。
- 1 任務初始化與基準確立:執行 /skill:autoresearch-create</highlight>,話畀 Agent 優化目標(例如「優化單元測試運行時間,確保正確性」)。Agent 會即刻創建一條新 Git 分支、寫入 autoresearch.md</highlight>,並運行一次基準命令確立 Baseline。
- 2 Agent 自主狂奔 (The Loop):Agent 開始無限嘅 Ralph Wiggum Loop</highlight>:清空上下文 → 讀狀態 → 執行一步 → 保存狀態 → 清空上下文。具體包括 Edit、Commit、Run、Log、Evaluate。如果指標變差就 git revert</highlight>,並吸取教訓。每次實驗結果以單行 JSONL 追加到 autoresearch.jsonl</highlight>,防止上下文溢出。
- 3 收割果實 (Finalize):執行 /skill:autoresearch-finalize</highlight>,Agent 會分析 JSONL,將所有保留嘅優化點拆成多個互不衝突嘅獨立分支(從 merge-base 重新派生),方便逐個 Code Review 後合併入主幹。
點解呢個係 Coding Agent 嘅正解?
點解唔叫 LLM 一次性改好曬,而要等佢好似笨蛋咁一次次試錯?因為大模型喺軟件工程上有個核心痛點:誤差的指數級放大。如果 Agent 試圖做 10 步複雜推理,只要第 3 步出咗微細邏輯錯誤,後面 7 步就會建立喺錯嘅地基上。呢個就係點解「一鍵生成複雜項目」demo 好靚,但真實落地成日炒車。
呢種「微步快跑、遇錯即回」嘅模式,本質上係用 算力(LLM API 消耗)</highlight> 換取絕對嘅可靠性。對於 Lighthouse 跑分優化</highlight>、模型超參數搜尋</highlight>、Rust 編譯耗時優化</highlight> 呢類有明確衡量指標嘅任務,呢種暴力美學展現出驚人嘅戰鬥力。
Agent 嘅終局唔一定要係將你隔離在外嘅巨型系統。PI 同 PI-autoresearch 展示咗另一種可能:基於 Unix 哲學</highlight>,將 LLM 降格為一個喺終端幫你幹髒活累活嘅模塊。環境依然係你嘅終端,代碼庫依然用 Git 管理,大模型只係一個幫你沒日沒夜執行 Try → Measure → Revert</highlight> 嘅打工人。別再手動調優喇,下次遇到玄學性能優化,定義好 Metric,敲下 /skill:autoresearch-create</highlight>,然後去飲杯咖啡啦。
喺日常開發入面,優化性能(無論係單元測試速度、Webpack 包大小,定係大模型嘅訓練 Loss)通常都係一個好折磨人嘅「玄學」過程:改一行 code、等 5 分鐘基準測試、將結果記喺筆記簿度,有效就 keep,退步就 git revert。呢種機械式嘅循環,而家俾一套全新嘅 AI Agent 工作流程完全改變咗。
01 靈感來源:Karpathy 嘅 autoresearch
故事要從 Andrej Karpathy 講起。2026 年 3 月,Karpathy 開源咗 autoresearch 項目,係基於佢嘅 nanochat(一個單 GPU 嘅輕量 LLM 訓練框架)。核心思路係:將 AI agent(Claude 或 Codex)放入代碼倉庫,等佢自己修改訓練代碼(模型架構、優化器、超參數),跑 5 分鐘訓練,睇嚇 val_loss 有冇降低,有效就 keep,退步就回滾。你瞓一覺,朝早起身睇實驗日誌就得。
Karpathy 總結嘅核心哲學:
“Try an idea, measure it, keep what works, discard what doesn't, repeat forever.”
(試一個諗法,量度佢,保留有效嘅部分,棄掉冇效嘅部分,永遠重複。)
autoresearch 嘅獨特之處在於:agent 唔係做傳統嘅超參數搜索(grid search),而係真正理解 code 邏輯之後提出創造性修改——例如調整注意力窗口模式、替換優化器、改變模型深度。每次改動之後經過固定 5 分鐘嘅訓練預算,用 val_bpb(驗證 bits per byte)作為統一量度,決定 commit 定係 revert。
但 autoresearch 嘅架構好原始:佢只係一份 Markdown 指令(program.md)加一個訓練腳本(train.py),你需要手動打開 Claude 或 Codex,將 agent 指向呢個倉庫。佢冇內置嘅實驗管理、狀態持久化、分支清理或者進度監控。如果 agent 嘅上下文窗口爆咗,之前嘅實驗記憶就會全部冇曬。呢個就係 PI-autoresearch 要解決嘅問題。
02 PI:唔造輪子,只造「馬具」(Harness)
要俾 AI 接管呢個實驗循環,我哋需要一個可以喺終端運行、可以執行命令、可以管理 code 嘅工具。呢個就係 PI (pi.dev) 出場嘅原因。
市面上有好多重量級嘅 Agent 框架(例如 AutoGen、CrewAI),佢哋內置咗複雜嘅子代理(Sub-agents)、規劃模式(Plan Mode)同任務分解邏輯。但係 PI 嘅作者 Mario Zechner 行咗一條完全相反嘅極簡路線。PI 嘅核心設計理念係:Change the harness, not your workflow.(改變馬具,而唔係改變你嘅工作流程)。
💡 咩係 Harness Engineering?
Harness 直譯係「馬具」。喺 AI 領域,係指為大模型搭建一個同真實系統互動嘅外部環境(包含 code 庫、命令行、測試框架等)。PI 只係一個極簡嘅殼,佢唔規定 AI 應該點樣思考,只係提供最基礎嘅終端互動接口,所有嘅上層邏輯(MCP、複雜任務流)全靠擴展(Extensions)同技能(Skills)實現。
PI 有好乾淨嘅 System Prompt,呢個俾開發者留低咗巨大嘅「上下文工程 (Context Engineering)」空間。正正係因為 PI 嘅呢種輕量化同高擴展性,開發者 davebcn87 成功將 Karpathy 嘅思想移植咗上 PI,開發出咗 PI-autoresearch 插件。
03 拆解 PI-autoresearch 嘅架構同工作流程
安裝 PI-autoresearch 之後,佢會喺終端上方注入一個儀錶板(Dashboard),同埋喺後台掛載三個核心工具:init_experiment、run_experiment 和 log_experiment。
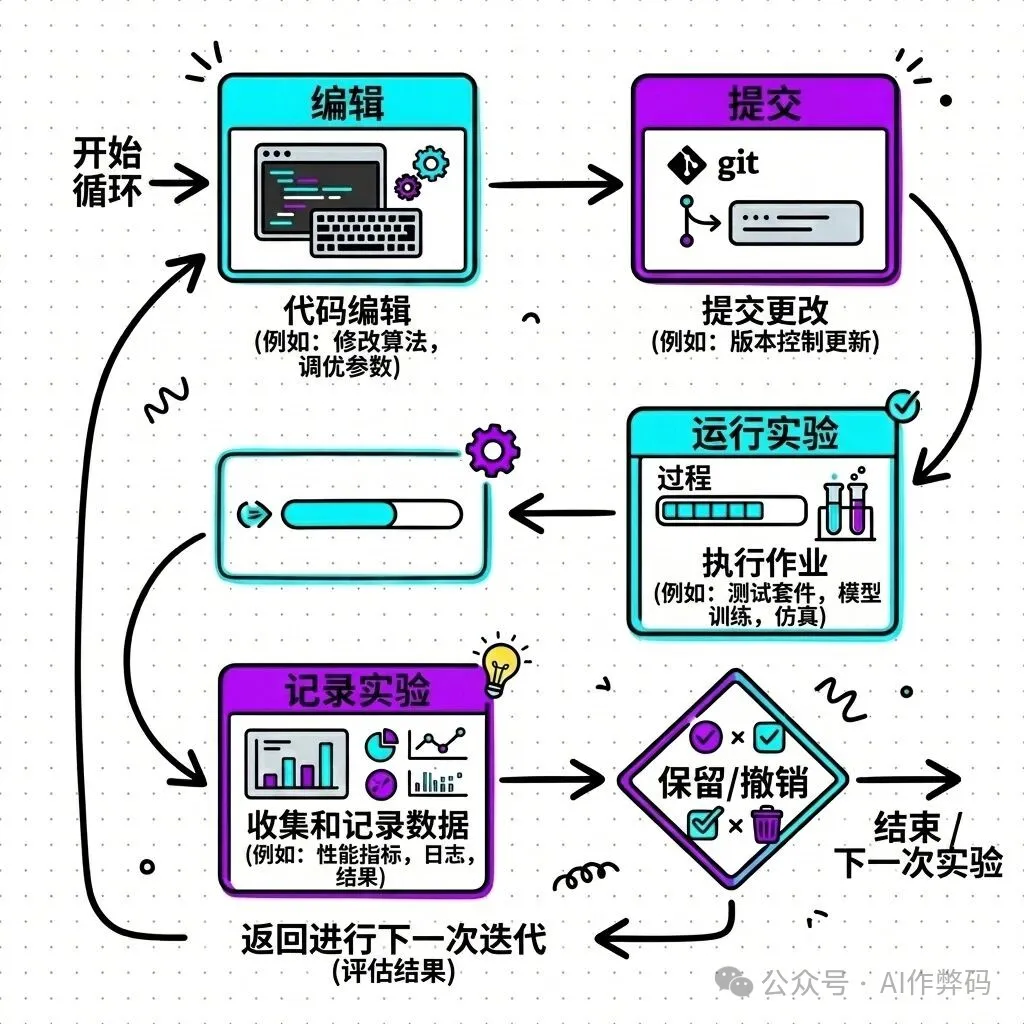
成個工作流程可以分為三個階段:
階段一:任務初始化同基準確立
透過執行 /skill:autoresearch-create,你需要話俾 Agent 你嘅優化目標。例如:「優化單元測試運行時間,確保正確性」。
Agent 會即刻做三件事:創建一條新嘅 Git 分支;寫入 autoresearch.md(用嚟向 AI 說明目標同上下文);運行一次基準命令,確立當前嘅「零點(Baseline)」。
階段二:Agent 自己狂奔 (The Loop)
呢個先至係最硬核嘅部分。Agent 開始咗無休止嘅 Ralph Wiggum Loop(即係:清空上下文,讀取狀態,執行一步,保存狀態,再清空上下文):
1. Edit: AI 分析當前 code 並提出一個優化猜想,修改檔案。
2. Commit: 即刻將修改 git commit。
3. Run: 調用 run_experiment 執行測試命令(例如 pnpm test)。
4. Log: 將測試結果(用時、分數等)提取出來。
5. Evaluate: 如果指標變好,進入下一 round。如果指標變差,執行 git revert 回退到上一版本,吸取教訓,再入下一 round。
為咗防止長文本溢出(Context Window Explosion),每次實驗嘅結果都會以單行 JSONL 嘅形式追加入 autoresearch.jsonl 檔案度。就算你熄咗終端聽日再開,Agent 都可以透過讀取呢個檔案,瞬間恢復所有嘅實驗記憶。
階段三:收割成果 (Finalize)
如果 Agent 跑咗一晚,做咗 50 次實驗,其中有 8 次有效,其餘全部係 Revert 同失敗。人手 Review 呢種 Git 歷史會令人崩潰。
PI-autoresearch 提供咗一個殺手級功能:/skill:autoresearch-finalize。Agent 會分析 autoresearch.jsonl,揾出所有被保留(Keep)嘅優化點,然後將佢哋拆解成多個互不衝突嘅獨立分支(從 merge-base 重新派生)。呢個意味住,你可以針對每一個優化點進行獨立嘅代碼審查(Code Review),乾淨利落地合併入主幹。
04 點解佢係 Coding Agent 嘅正解?
點解我哋唔俾 LLM 一次性將 code 全部改好,而係要等佢好似蠢材咁一次又一次試錯?
呢個觸及到當前大模型喺軟件工程上嘅核心痛點:誤差嘅指數級放大。如果 Agent 試圖進行 10 步嘅複雜推理同重構,只要其中第 3 步出現咗微小嘅邏輯錯誤,之後嘅 7 步都會建立在錯誤嘅根基上。呢個就係點解好多「一鍵生成複雜項目」嘅示範睇落好型,但真實落地時就不斷出問題。
⚠️ 「實驗驗證」好過「長程規劃」
PI-autoresearch 嘅思路係:唔相信模型嘅一次性長程規劃,只相信「環境嘅真實反饋」。每一次修改,都必須通過真實測試(編譯器、測試框架、性能探針)嘅檢驗。環境嘅反饋充當咗強行嘅糾偏器,將長鏈條嘅推理誤差,強制截斷喺每一個 Commit 入面。
呢種「微步快跑、遇錯即回」嘅模式,本質上係用算力(LLM API 嘅消耗)換取絕對嘅可靠性。對於 Lighthouse 跑分優化、模型超參數搜尋、Rust 編譯用時優化等「有明確衡量指標」嘅任務,呢種暴力美學展現出驚人嘅戰鬥力。
最後
Agent 嘅終局唔一定係嗰種將你隔離在外、黑盒化操作嘅巨型系統。PI 同 PI-autoresearch 展示咗另一種可能:基於 Unix 哲學,將 LLM 降格為一個喺終端入面幫你做苦力嘅模塊。環境依然係你嘅終端,code 庫依然用 Git 管理,大模型只係一個幫你冇日冇夜執行 Try -> Measure -> Revert 嘅打工人。
唔好再手動調優啦。下次遇到玄學嘅性能優化,不妨定義好 Metric,敲低 /skill:autoresearch-create,然後去飲杯咖啡啦。
參考
1. GitHub: davebcn87/pi-autoresearch
https://github.com/davebcn87/pi-autoresearch
2. PI: A terminal-based coding agent
https://pi.dev/
3. GitHub: karpathy/autoresearch
https://github.com/karpathy/autoresearch
在日常開發中,優化性能(無論是單元測試速度、Webpack 包大小,還是大模型的訓練 Loss)往往是一個極其折磨人的“玄學”過程:改一行代碼、等 5 分鐘基準測試、把結果記在小本本上,有效就保留,退化就 git revert。這種機械的循環,正在被一套全新的 AI Agent 工作流顛覆。
01 靈感起源:Karpathy 的 autoresearch
故事要從 Andrej Karpathy 說起。2026 年 3 月,Karpathy 開源了 autoresearch 項目,基於他的 nanochat(一個單 GPU 的輕量 LLM 訓練框架)。核心思路是:把 AI agent(Claude 或 Codex)放進代碼倉庫,讓它自主修改訓練代碼(模型架構、優化器、超參數),跑 5 分鐘訓練,看 val_loss 有沒有降低,有效就保留,退化就回滾。你睡一覺,早上起來看實驗日誌就行。
Karpathy 總結的核心哲學:
“Try an idea, measure it, keep what works, discard what doesn't, repeat forever.”
(嘗試一個想法,測量它,保留有效的部分,丟棄無效的部分,永遠重複。)
autoresearch 的獨到之處在於:agent 不是在做傳統的超參數搜索(grid search),而是在真正理解代碼邏輯後提出創造性修改——比如調整注意力窗口模式、替換優化器、改變模型深度。每次改動後經過固定 5 分鐘的訓練預算,用 val_bpb(驗證 bits per byte)作為統一度量,決定 commit 還是 revert。
但 autoresearch 的架構非常原始:它只是一份 Markdown 指令(program.md)加一個訓練腳本(train.py),你需要手動打開 Claude 或 Codex,把 agent 指向這個倉庫。它沒有內置的實驗管理、狀態持久化、分支清理或進度監控。如果 agent 的上下文窗口溢出了,之前的實驗記憶就全丟了。這就是 PI-autoresearch 要解決的問題。
02 PI:不造輪子,只造“馬具” (Harness)
要讓 AI 接管這個實驗循環,我們需要一個能運行在終端、能執行命令、能管理代碼的工具。這就是 PI (pi.dev) 出場的原因。
市面上有很多重量級的 Agent 框架(如 AutoGen、CrewAI),它們內置了複雜的子代理(Sub-agents)、規劃模式(Plan Mode)和任務分解邏輯。但 PI 的作者 Mario Zechner 走了一條完全相反的極簡路線。PI 的核心設計理念是:Change the harness, not your workflow.(改變馬具,而不是改變你的工作流)。
💡 什麼是 Harness Engineering?
Harness 直譯是“馬具”。在 AI 領域,指的是為大模型搭建一個與真實系統交互的外部環境(包含代碼庫、命令行、測試框架等)。PI 只是一個極簡的殼,它不規定 AI 應該怎麼思考,只提供最基礎的終端交互接口,所有的上層邏輯(MCP、複雜任務流)全靠擴展(Extensions)和技能(Skills)實現。
PI 擁有極其乾淨的 System Prompt,這給開發者留下了巨大的“上下文工程 (Context Engineering)”空間。正是因為 PI 的這種輕量化和高擴展性,開發者 davebcn87 成功將 Karpathy 的思想移植到了 PI 上,開發出了 PI-autoresearch 插件。
03 拆解 PI-autoresearch 的架構與工作流
安裝 PI-autoresearch 後,它會在終端上方注入一個儀表盤(Dashboard),並在後台掛載三個核心工具:init_experiment、run_experiment 和 log_experiment。
整個工作流可以分為三個階段:
階段一:任務初始化與基準確立
通過執行 /skill:autoresearch-create,你需要告訴 Agent 你的優化目標。例如:“優化單元測試運行時間,確保正確性”。
Agent 會立刻做三件事:創建一條新的 Git 分支;寫入 autoresearch.md(用於向 AI 說明目標和上下文);運行一次基準命令,確立當前的“零點(Baseline)”。
階段二:Agent 自主狂奔 (The Loop)
這才是最硬核的部分。Agent 開始了無休止的 Ralph Wiggum Loop(即:清空上下文,讀取狀態,執行一步,保存狀態,再清空上下文):
1. Edit: AI 分析當前代碼並提出一個優化猜想,修改文件。
2. Commit: 立即將修改 git commit。
3. Run: 調用 run_experiment 執行測試命令(如 pnpm test)。
4. Log: 將測試結果(耗時、分數等)提取出來。
5. Evaluate: 如果指標變好,進入下一輪。如果指標變差,執行 git revert 退回上一版本,吸取教訓,再進下一輪。
為了防止長文本溢出(Context Window Explosion),每次實驗的結果都會被單行 JSONL 的形式追加到 autoresearch.jsonl 文件中。即使你關掉終端明天再開,Agent 也能通過讀取這個文件,瞬間恢復所有的實驗記憶。
階段三:收割果實 (Finalize)
如果 Agent 跑了一晚上,做了 50 次實驗,其中 8 次有效,剩下的全是 Revert 和失敗。人工 Review 這種 Git 歷史會讓人崩潰。
PI-autoresearch 提供了一個殺手級功能:/skill:autoresearch-finalize。Agent 會分析 autoresearch.jsonl,找出所有被保留(Keep)的優化點,然後把它們拆解成多個互不衝突的獨立分支(從 merge-base 重新派生)。這意味着,你可以針對每一個優化點進行單獨的代碼審查(Code Review),乾淨利落地合併進主幹。
04 為什麼它是 Coding Agent 的正解?
為什麼我們不讓 LLM 一次性把代碼全改好,而是要讓它像個笨蛋一樣一次次試錯?
這觸及了當前大模型在軟件工程上的核心痛點:誤差的指數級放大。如果 Agent 試圖進行 10 步的複雜推理和重構,只要其中第 3 步出了微小的邏輯錯誤,後續的 7 步都會建立在錯誤的地基上。這就是為什麼很多“一鍵生成複雜項目”的演示看起來很酷,但真實落地時卻頻頻翻車。
⚠️ “實驗驗證”優於“長程規劃”
PI-autoresearch 的思路是:不相信模型的一次性長程規劃,只相信“環境的真實反饋”。每一次修改,都必須通過真實測試(編譯器、測試框架、性能探針)的檢驗。環境的反饋充當了強行的糾偏器,把長鏈條的推理誤差,強制截斷在了每一個 Commit 裏。
這種“微步快跑、遇錯即回”的模式,本質上是在用算力(LLM API 的消耗)換取絕對的可靠性。對於 Lighthouse 跑分優化、模型超參數搜尋、Rust 編譯耗時優化等“有明確衡量指標”的任務,這種暴力美學展現出了驚人的戰鬥力。
最後
Agent 的終局不一定是那種把你隔離在外、黑盒化操作的巨型系統。PI 與 PI-autoresearch 展示了另一種可能:基於 Unix 哲學,把 LLM 降格為一個在終端裏幫你幹髒活累活的模塊。環境依然是你的終端,代碼庫依然用 Git 管理,大模型只是一個幫你沒日沒夜執行 Try -> Measure -> Revert 的打工人。
別再手動調優了。下次遇到玄學的性能優化,不妨定義好 Metric,敲下 /skill:autoresearch-create,然後去喝杯咖啡吧。
參考
1. GitHub: davebcn87/pi-autoresearch
https://github.com/davebcn87/pi-autoresearch
2. PI: A terminal-based coding agent
https://pi.dev/
3. GitHub: karpathy/autoresearch
https://github.com/karpathy/autoresearch