開源 TTS 天花板被捅破!VoxCPM2:20 億參數,30 種語言,48kHz,全功能免費商用
整理版優先睇
VoxCPM2開源TTS天花板再拉高:語音設計、可控克隆、20億參數免費商用
呢篇文章係關於面壁智能聯同OpenBMB開源社區、清華大學人機語音交互實驗室發布嘅VoxCPM2,係VoxCPM系列嘅全新升級版。距離上次VoxCPM-0.5B發佈得半年,今次參數量由5億躍升到20億,訓練數據超過200萬小時,帶來咗語音設計同可控克隆等獨家功能,直接將開源TTS嘅天花板拉高咗一截。作者想解決嘅問題係市面上開源TTS模型喺語音創作靈活性同音質方面嘅限制,特別係語音設計同風格控制嘅缺失。整體結論係VoxCPM2技術路線有優勢,功能全面,性能強勁,而且免費商用,會成為未來語音應用嘅首選方案。
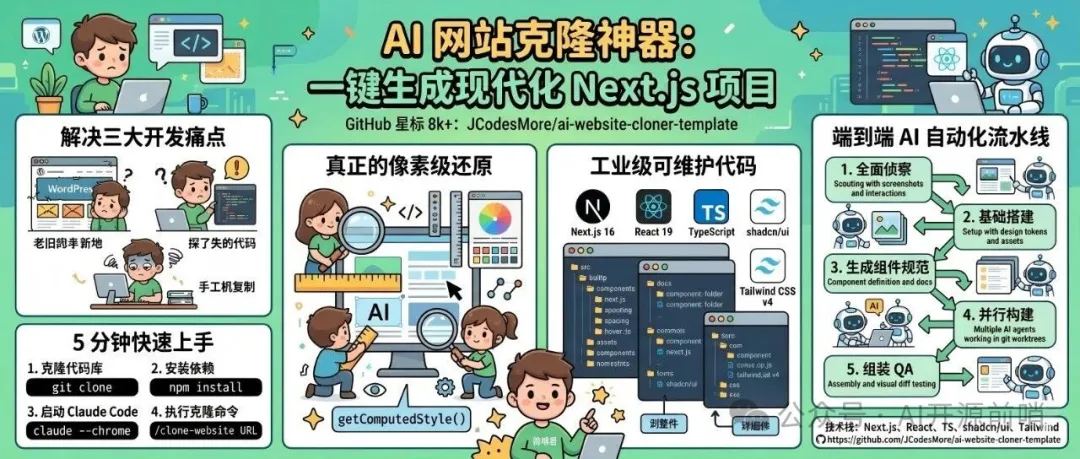
VoxCPM2採用無分詞器嘅端到端擴散自迴歸架構,直接生成連續語音表示,自然度同連貫性天生更強。佢支援30種以上語言同中文九大方言,輸入文本會自動識別語言,唔使手動指定。最突破嘅係語音設計功能,只需要用自然語言描述性別、年齡、音色等特徵,就可以生成全新聲音,完全唔使參考音頻。可控克隆功能就保留原說話人音色,同時可以自由調整情感同節奏。音質方面支援48kHz工作室級輸出,用16kHz低質量參考音頻都可以輸出高清語音。性能方面,RTX 4090上RTF低至0.13,滿足實時交互。所有程式碼同權重都基於Apache-2.0協議開源,可以無限制商用。無論係有聲書、遊戲配音、智能客服定係AI數字人,VoxCPM2都提供強大支持,值得開發者花時間試下。
- 結論:VoxCPM2係目前開源TTS入面功能最全面嘅模型,語音設計同可控克隆獨一無二,免費商用。
- 方法:採用端到端擴散自迴歸架構,直接生成連續語音,避免離散分詞化導致嘅信息損失。
- 差異:支援30+語言自動識別、48kHz工作室級音質,RTF低至0.13,性能強勁。
- 啟發:語音設計功能降低創作門檻,唔需要任何參考音頻就可以生成新聲音,打破傳統限制。
- 可行動點:開發者可以透過pip一鍵安裝,使用Python API或命令行快速整合,仲有Web界面方便測試。
VoxCPM2 GitHub
項目地址
核心升級亮點
距離上次VoxCPM-0.5B發佈得半年,今次VoxCPM2嘅參數量由5億躍升到20億,訓練數據突破200萬小時,帶嚟咗語音設計同可控克隆兩個開源TTS獨有功能,將開源TTS嘅天花板拉高咗一大截。
20億參數
200萬小時訓練數據
語音設計
可控克隆
48kHz工作室級輸出
技術路線與核心功能
VoxCPM從誕生起就避開傳統TTS嘅離散分詞化陷阱,採用無分詞器嘅端到端擴散自迴歸架構,直接生成連續語音表示,自然度同連貫性天生更強。多語言方面支援30種以上語言同中文九大方言,輸入文本會自動識別語言,唔使手動指定。語音設計係最具突破性嘅功能,唔需要任何參考音頻,只用自然語言描述性別、年齡、音色、情緒、語速等特徵,就能直接生成符合要求嘅全新語音。可控克隆功能就保留原說話人核心音色,同時允許自由調整情感、節奏同表達方式,適配更多場景。
無分詞器端到端擴散自迴歸
30種語言自動識別
語音設計:一句話生成全新聲音
可控克隆:保留音色,自由調風格
音質、性能與許可
VoxCPM2支援48kHz工作室級音頻輸出,係目前開源TTS最高水準之一。佢用AudioVAE V2非對稱編解碼設計,即使輸入16kHz低質量參考音頻,都可以輸出48kHz高清語音。性能方面,模型保留上下文感知合成能力,響RTX 4090上RTF低至0.13,完全滿足實時交互需求。全量代碼同權重基於Apache-2.0協議開源,可以無限制用於商業項目。
48kHz工作室級輸出
AudioVAE V2非對稱編解碼
RTF 0.13
Apache-2.0開源商用
快速上手體驗
VoxCPM2嘅安裝好簡單,只需要一行命令:
pip install voxcpm安裝之後就可以用Python API進行文本轉語音、語音設計同可控克隆。以下係基本用法:
from voxcpm import VoxCPM
import soundfile as sf
model = VoxCPM.from_pretrained(
"openbmb/VoxCPM2",
load_denoiser=False,
)
wav = model.generate(
text="VoxCPM2 is the current recommended release for realistic multilingual speech synthesis.",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("demo.wav", wav, model.tts_model.sample_rate)語音設計示例:
wav = model.generate(
text="(A young woman, gentle and sweet voice)Hello, welcome to VoxCPM2!",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("voice_design.wav", wav, model.tts_model.sample_rate)可控克隆示例:
wav = model.generate(
text="This is a cloned voice generated by VoxCPM2.",
reference_wav_path="path/to/voice.wav",
)
sf.write("clone.wav", wav, model.tts_model.sample_rate)除咗Python API,仲有命令行同Web界面。命令行語音設計:
voxcpm design \
--text "VoxCPM2 brings studio-quality multilingual speech synthesis." \
--output out.wav命令行克隆:
voxcpm clone \
--text "This is a voice cloning demo." \
--reference-audio path/to/voice.wav \
--output out.wavWeb界面只需運行 python app.py 然後訪問 http://localhost:7860。
pip install voxcpm
Python API
命令行工具
Web界面
總結與應用
- 有聲書:高質量語音生成,支援多語言同方言
- 遊戲配音:語音設計功能快速生成角色聲音
- 智能客服:可控克隆保留真人音色,調整情感表達
- AI數字人:實時語音合成滿足交互需求
VoxCPM2嘅出現,將語音合成從「能聽」提升到「好聽」,再進一步到「好用」。多語言支援解決國際化痛點,語音設計降低創作門檻,可控克隆拓展應用邊界。加上完全開源同商業友好許可,VoxCPM2好可能成為未來語音應用嘅首選技術方案。
從「能聽」到「好聽」到「好用」
多語言支援
語音設計降低門檻
可控克隆拓展邊界
今天語音合成領域又迎來了一個重磅炸彈。
面壁智能聯合OpenBMB開源社區、清華大學人機語音交互實驗室,正式發佈了VoxCPM的全新升級版本——VoxCPM2。

距離去年9月VoxCPM-0.5B的發佈還不到半年時間,這次的升級可以說是全方位的。
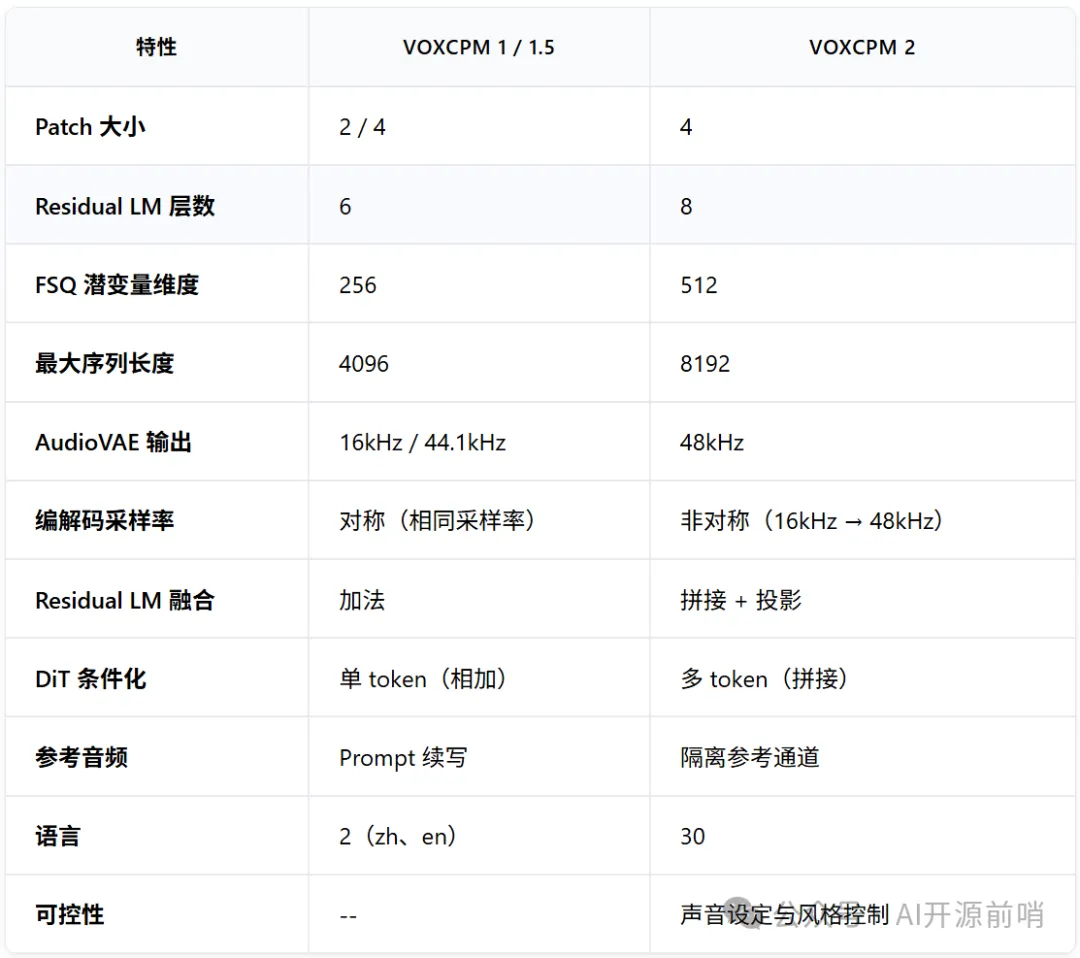
不僅參數量從5億躍升到20億,訓練數據量也突破了200萬小時,更重要的是,它帶來了一系列行業領先的新功能,直接把開源TTS的天花板又拉高了一大截。
特別是語音設計和可控克隆這兩個功能,目前在開源TTS模型中幾乎是獨一份的存在。
為什麼VoxCPM2值得關注
技術路線:天生的自然度優勢
VoxCPM從誕生起就避開了傳統TTS的離散分詞化陷阱。
它採用無分詞器的端到端擴散自迴歸架構,直接生成連續語音表示,從根源上避免了信息損失,生成語音的自然度和連貫性天生更強。
多語言:30+語言自動識別
VoxCPM2支持30種以上語言及中文九大方言。

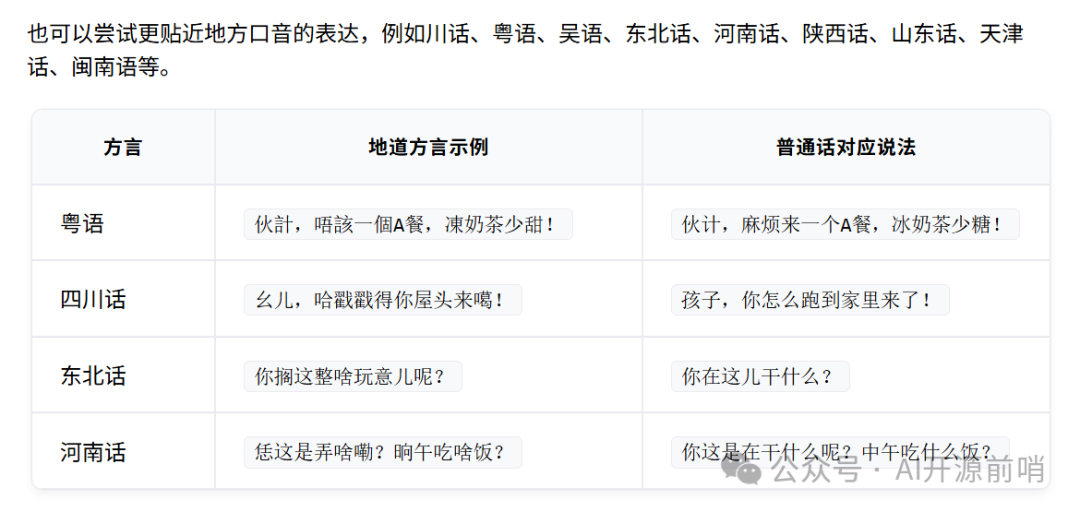
無需手動指定語言標籤,輸入任意支持語言的文本,模型會自動識別並完成合成,徹底解決多語言應用的適配痛點。
語音設計:一句話生成全新聲音
這是VoxCPM2最具突破性的功能。
不需要任何參考音頻,只用自然語言描述性別、年齡、音色、情緒、語速等特徵,就能直接生成符合要求的全新語音,打破了語音創作的固有門檻。

可控克隆:保留音色,自由調風格
傳統克隆只能原樣複製聲音,VoxCPM2實現了可控克隆。
它能完整保留原說話人的核心音色,同時允許你自由調整語音的情感、節奏和表達方式,適配更多場景需求。
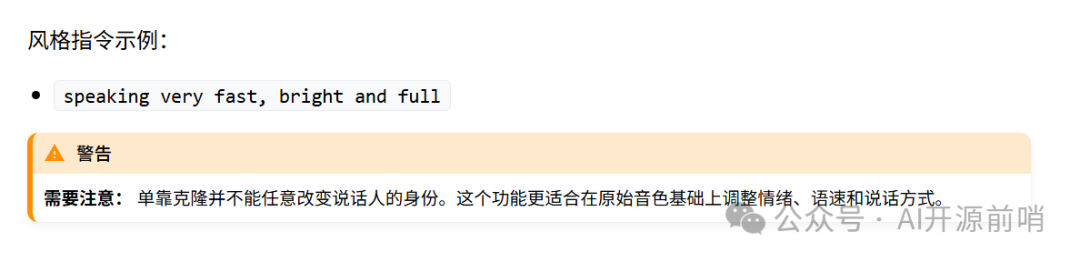
音質:48kHz工作室級輸出
VoxCPM2支持48kHz工作室級音頻輸出,是目前開源TTS的最高水準之一。
依託AudioVAE V2的非對稱編解碼設計,即使用16kHz的低質量參考音頻,也能輸出48kHz的高清語音。
性能與許可:實時可用,免費商用
模型保留了上下文感知合成能力,能根據文本自動匹配韻律。
在RTX 4090上RTF低至0.13,完全滿足實時交互需求。全量代碼和權重基於Apache-2.0協議開源,可無限制用於商業項目。
快速上手VoxCPM2
VoxCPM2的使用非常簡單,即使是沒有太多AI經驗的開發者,也能在幾分鐘內跑起來。
首先是安裝,只需要一行命令:
pip install voxcpm需要注意的是,VoxCPM2要求Python版本≥3.10,PyTorch版本≥2.5.0,CUDA版本≥12.0。
安裝完成後,你就可以通過Python API來使用它了。
最基礎的文本轉語音:
from voxcpm import VoxCPM
import soundfile as sf
model = VoxCPM.from_pretrained(
"openbmb/VoxCPM2",
load_denoiser=False,
)
wav = model.generate(
text="VoxCPM2 is the current recommended release for realistic multilingual speech synthesis.",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("demo.wav", wav, model.tts_model.sample_rate)體驗最酷的語音設計功能:
wav = model.generate(
text="(A young woman, gentle and sweet voice)Hello, welcome to VoxCPM2!",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("voice_design.wav", wav, model.tts_model.sample_rate)進行可控語音克隆:
wav = model.generate(
text="This is a cloned voice generated by VoxCPM2.",
reference_wav_path="path/to/voice.wav",
)
sf.write("clone.wav", wav, model.tts_model.sample_rate)除了Python API,VoxCPM2還提供了方便的命令行工具和Web演示界面。
使用命令行進行語音設計:
voxcpm design \
--text "VoxCPM2 brings studio-quality multilingual speech synthesis." \
--output out.wav進行語音克隆:
voxcpm clone \
--text "This is a voice cloning demo." \
--reference-audio path/to/voice.wav \
--output out.wav如果你想體驗更直觀的圖形界面,只需要運行:
python app.py然後打開瀏覽器訪問http://localhost:7860就可以了。
最後說幾句
語音合成技術發展到今天,已經從"能聽"變成了"好聽",而VoxCPM2的出現,又把這個標準提升到了"好用"的層面。
它的多語言支持解決了國際化應用的痛點,語音設計功能降低了語音創作的門檻,可控克隆則拓展了語音合成的應用邊界。再加上完全開源的商業友好許可,VoxCPM2很可能會成為未來很多語音應用的首選技術方案。
無論是做有聲書、遊戲配音、智能客服,還是開發語音助手、AI數字人,VoxCPM2都能提供強大的技術支持。
如果你正在尋找一款高質量的開源TTS模型,那麼VoxCPM2絕對值得你花時間去嘗試。
項目地址:
https://github.com/OpenBMB/VoxCPM

隨着前哨君分享的開源項目日漸增多,為了方便小夥伴們查詢過往分享的開源項目,前哨君做了一個“Ai-projectsHub”的網站,會在上面同步我過往分享的項目,後續也會在專欄上架一些好用的Ai產品。
國內地址:https://www.yaowendeep.cn
國際地址:https://ai-projects-hub-six.vercel.app/
歡迎 置頂(標星)關注本公眾號「AI開源前哨」獲取有趣AI技術/工具分享,這樣就第一時間獲取推送啦~