開源「潔癖.skill」 :每次任務完成後自動整理文檔與記憶,讓Agent持續保持聰明
呢篇文章係作者卡茲克分享佢自己開發嘅一個Skill,叫「潔癖.skill 」。佢本身係一個成日用Agent做開發嘅人,特別係用Claude Code 呢類工具。佢發現好多時Agent越用越笨,原因唔係模型蠢,而係項目入面啲文檔、記憶同約束文件已經亂曬籠,冇隨住開發同步更新。佢自己就試過將數據庫由SQLite 轉去PostgreSQL 之後,忘記改CLAUDE.md,搞到Agent仲用緊舊語法,浪費好多時間。
為咗解決呢個問題,佢整咗呢個Skill。每次喺Agent完成一個功能或者修好一個Bug 之後,只要行一次/neat,佢就會自動盤點曬所有.md文件、用變更影響矩陣識別要改嘅位、更新docs/、CLAUDE.md 同記憶,最後出份變更摘要。佢強調「合併優於追加,刪除優於保留 」,因為過期嘅資訊比冇資訊更差。佢建議將呢個Skill當成遊戲存檔機制,每次收尾就行一次,咁下次開新窗口就可以直接繼續,Agent仲會越用越聰明。
定期整理文檔同記憶係防止Agent變笨嘅關鍵,「潔癖.skill 」提供咗自動化解決方案。
Skill行五步 :盤點所有md文件、用變更影響矩陣識別影響範圍、更新docs/同CLAUDE.md 同記憶、自檢清單、輸出變更摘要。
相比AutoDream 只整理記憶,「潔癖.skill 」同時處理記憶、CLAUDE.md 同docs三層知識,確保全面一致。
啟發 :資訊多唔係優勢,資訊準先係;合併同刪除比保留更有價值。
實際行動 :每次任務收尾執行/neat,將知識從依賴對話上下文轉為持久化文檔,新窗口唔使重複提示。
連結
github.com
潔癖.skill 開源倉庫
包含安裝說明同使用方法,四個平台(Claude Code、Codex、OpenCode、OpenClaw)通用。
作者分享佢做AIHOT 項目時,將數據庫由SQLite 轉去PostgreSQL 後,唔記得更新CLAUDE.md,搞到Agent仲用緊SQLite語法,搞咗好耐先發現係文檔問題。佢強調好多時Agent犯嘅錯誤根源都係「文檔同記憶腦腐 」,而唔係模型笨。
一條過期嘅記憶比冇記憶更糟糕
呢個問題特別影響用vibe coding嘅人,例如設計師、產品經理,因為佢哋通常冇工程化習慣去維護文檔。項目一大,文檔就越來越亂,Agent就越用越笨。
Claude Code 之前有功能叫AutoDream ,只係整理記憶文件,唔會掂docs或CLAUDE.md 。但作者指出,一個項目嘅知識分三層:第一層係記憶系統,第二層係CLAUDE.md (畀AI自己睇),第三層係docs/同README(畀其他人睇)。每一層受眾同職責唔同,AutoDream淨管第一層,所以唔夠用。
第一層 :Agent記憶,記錄過去對話同隱性知識。
第二層 :CLAUDE.md ,項目約定、結構、紅線、路由清單等。
第三層 :docs/目錄同README ,畀其他人用嘅接入指南、架構說明等。
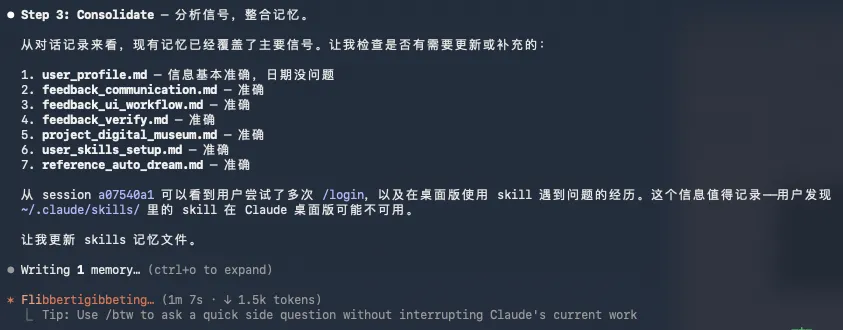
作者開發嘅「潔癖.skill 」會按順序做五件事,確保所有知識層都同步更新。核心原則係「合併優於追加,刪除優於保留 」,因為過期資訊會誤導Agent。
合併優於追加,刪除優於保留
1
強制機械式盤點 :列出所有.md文件,逐個讀,唔可以漏。
2
用變更影響矩陣識別要改嘅範圍 :新事實會波及邊啲文檔層級,仲要檢查係咪跨項目影響。
3
直接改 :先改docs/,再改CLAUDE.md ,最後整理記憶。
4
自檢清單 :檢查新增環境變量係咪喺runbook同CLAUDE.md 都出現咗,有冇相對時間遺留等。
5
輸出變更摘要 :畀你知道改咗啲乜。
自檢清單
呢五步過程全部自動化,你只需要輸入/neat就得。作者自己每次任務收尾都會行一次,當成遊戲存檔機制。
作者建議喺每次任務完成之後,就行一次/neat,將知識體系從依賴對話上下文轉為持久化文檔。佢自己會喺對話大約400K tokens左右整理一次,然後開新窗口。因為文檔同記憶管理得夠好,新窗口可以直接繼續,Agent好精準。
/neat
斷舍離
佢話呢個skill比學寫Prompt更重要,因為過期嘅就刪,重複嘅就合,模糊嘅就改,令知識庫永遠保持最準確嘅真相。
今日冇題材揀喇,所以想開源一個我自己整嘅,已經用咗差唔多成個月,迭代咗好多版嘅一個我覺得好有用嘅Skill。 個名聽落可能好戇居,但我覺得佢做到嘅嘢,雖然睇落好簡單,但其實好實用,公司同事同啲合作伙伴用過之後,都話唔錯。 佢做嘅嘢大概係咁:每次你喺Agent入面做完一個功能或者搞掂咗一個BUG,就call呢個潔癖Skill,然後講聲「幫我全面審查一下」或者直接打/Neat一下,佢就會自動審查你成個項目嘅文檔體系同記憶文件,然後根據呢次對話,將要改嘅文檔、記憶、CLAUDE.md進行迭代,確保好乾淨之後,最後俾返一份變更摘要你,等你知道改咗啲乜。 四個平台通用,Claude Code、Codex、OpenCode、OpenClaw都裝到。 信我,呢個嘢會令你嘅Agent越嚟越聰明,仲好符合潔癖嘅定義。 每次做完一個任務,想quit呢個視窗嘅時候,如果唔run一次/neat,我就周身唔舒服,坐立不安、背脊刺痛、喉嚨頂住咁。 大家而家都知道,好多時你個Agent越用越蠢,其實係因為你嘅上下文太亂。 上下文唔止係你同Agent喺單次對話嘅聊天記錄,仲包括你個項目入面嘅各種文檔、約束同記憶。 但其實好多朋友用Agent嗰陣,例如用CC同Codex做一個項目,初期嘅文檔規範規劃得幾好,但每次迭代、每次更新,你會發現呢啲文檔同記憶都冇維護,可能代碼都迭代咗七、八輪,新功能上咗無數,但文檔仲係最開始1.0.0版本嘅初始文檔。 其實唔止Agent,好多公司內部項目嘅文檔都係咁,初期雄心壯志,文檔規範好清晰,過咗兩個月之後,規範?文檔?你講緊乜,我聽唔明。 我自己個項目其實就出過呢種事,例如我做嘅AIHOT AI熱點監控系統(PS:呢個我最近會再打磨嚇降低成本,然後會免費開放俾所有人,到時都會出文章介紹,希望對大家有用。) 淨係精選策略相關嘅功能就有亂七八糟嘅五、六個,一條資訊捉到系統入面,會需要十幾個步驟做數據清洗、加工、好幾層評估等等,然後先會落庫。 而家每日處理嘅量級,喺我嚴格挑選同管控信源嘅前提下,都仲有500幾條信源產出嘅數據。 然後我當初一開始做嗰陣,其實想將成個項目後續封裝成CLI,俾所有人嘅Agent都可以嚟瀏覽上面嘅數據,用起上嚟方便啲,所以我就將數據庫由SQLite轉咗做PostgreSQL。 但呢個切換其實工作量都幾大,當時用緊Opus 4.6,時間一長,真係顧頭唔顧尾,搞完之後,文檔之類嘅我忘記咗改。 結果後嚟我繼續開發新功能嘅時候,Claude仲係call緊SQLite嘅語法,我當時以為係模型嘅問題,搞咗一輪,發現係文檔冇改,包括我個CLAUDE.md入面,仲赫然寫住「項目使用SQLite數據庫」呢個意思。 呢種只係一個小摩擦,如果你經歷多咗,你會發現Agent好多時犯嘅大多數莫名其妙嘅錯誤,根源其實唔係模型蠢,而係文檔同記憶已經腦腐咗,出現咗明顯嘅混亂。 好多朋友可能會話,呢啲唔係專業開發者先要關心嘅嘢咩? 但我想話,啱啱相反,好多我嘅專業開發者朋友都有自己一套工程化習慣,git commit message寫得規規矩矩,README隨手就更新。 真正俾呢個問題折磨得最慘嘅,反而係我哋呢啲靠Agent嚟vibe coding嘅人,例如設計師、產品經理、內容創作者,當然仲包括我自己。 vibe coding前期好爽,同AI吹兩句code就出咗,功能就跑得起。但項目一做大,文檔就無可避免咁開始混亂,而且好多人完全冇維護嘅概念,到最後就越嚟越混亂,你就會覺得,屌我個Agent點解越嚟越蠢。 而呢個維護,就係今日呢個潔癖.skill要做嘅嘢。 之前Claude Code有一個功能叫AutoDream,亦即係做夢,我都寫過文章: Claude Code悄悄學識咗做夢 ,我當時好興奮,因為呢個嘢睇落就係我想要嘅嘢?
但實際用咗之後我發現一個好大嘅問題。
AutoDream只鬱記憶,唔鬱項目文檔,咁就尷尬到仆街。
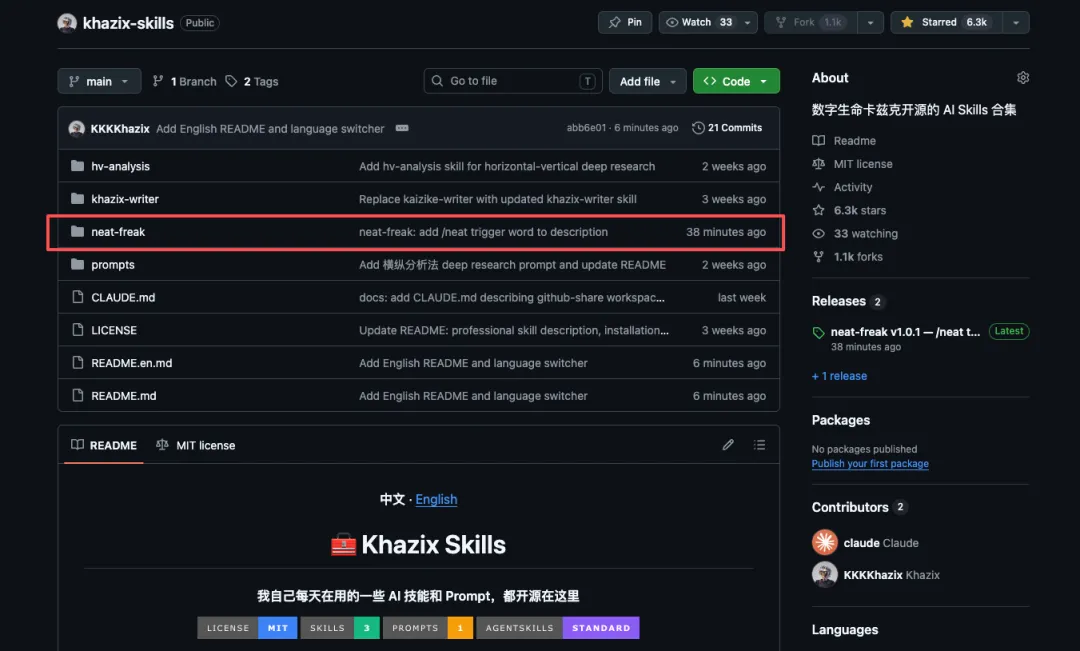
如果你用Agent開發過任何嘢,你就知一個項目入面嘅知識其實分三層,每一層服務嘅人唔同。 第一層係Agent自己嘅記憶系統,以前嘅聊天記錄、項目嘅隱性知識。 第二層係項目根目錄嘅CLAUDE.md,俾AI自己睇嘅,項目約定、結構、紅線、路由清單等等。 第三層係docs/目錄同README,俾其他人睇嘅,例如Agent、同事、下游開發者等等,例如接入指南、架構說明、運維手冊等等。 例如CLAUDE.md入面寫新增咗五個路由,唔等於docs/integration-guide.md入面寫下游點樣接呢五個路由。 前者係提醒自己,後者係教人,兩份作用完全唔同,都要寫。 AutoDream嘅問題就係,佢淨係理第一層,記憶文件確實乾淨咗,但另外兩個佢唔理,所以用落,作用真係唔大。 而今次照舊,已經喺我自己嘅Skills倉庫入面開源,任何人都可以隨意使用: https://github.com/KKKKhazix/khazix-skills
入面最核心嘅原則,其實係合併優於追加,刪除優於保留。 呢個同大多數人嘅直覺相反,因為好多時大家會覺得,資訊多總好過資訊少掛?萬一將來用得着呢? 但其實喺AI協作嘅場景下,資訊多唔係優勢,資訊準先係,坦白講,一條過期嘅記憶,比起冇記憶更差,因為冇記憶嘅時候,AI至少知道自己唔知,佢會問你。 但如果佢讀到一條過期嘅資訊,佢會以為係啱嘅,然後基於錯誤嘅前提做嘢。 OpenClaw越用越蠢,就係因為佢嘅記憶系統實在太臃腫。 而當你安裝咗潔癖.skill,每次run潔癖.skill嘅時候,佢會按順序做五件事。 第一步,就係先強制機械式盤點。將項目入面所有md文件全部列曬出嚟,每個都讀一次,唔好漏,因為之前試過好幾次,你以為佢改咗,點知漏咗一個文檔,仲要係好關鍵嗰啲。 第二步,用我嘅變更影響矩陣文檔去識別嚇要改啲乜。唔單止睇對話入面有新事實,仲要睇新事實會波及邊啲文檔層級。 然後呢步仲有一個關鍵檢查:呢次對話係咪跨項目?如果改咗項目A而項目B依賴佢,咁項目B嘅docs都要跟住改,呢個係歷次同步最常炒車嘅地方。 第三步,直接改,呢度有一個順序步驟:先改docs/,再改CLAUDE.md,最後整理記憶。 第四步,自檢清單,基本上係我嘅skill入面嘅老演員,實會有自檢清單,例如新增嘅環境變量,喺runbook同CLAUDE.md都出現咗未?有冇相對時間遺留等等之類嘅嘢,確認一次。
第五步,輸出一份變更摘要,就係呢啲嘢。
呢五步睇落麻煩,其實係skill自己嘅過程,你根本唔使理,你要做嘅,就係run呢個skill。 或者你用中文講「審查一下」、「整理一下」之類都得。 我自己通常喺所有任務嘅收尾,都一定會run一次/neat。 我將潔癖.skill當做類似遊戲嘅存檔機制用,今次要完結,要存檔,就run一次/neat,然後下次開新會話,可以繼續做。 講真,潔癖呢個嘢表面係整理文檔,但佢真正解決嘅問題我覺得比整理文檔有用得多。 佢會令你嘅知識體系由依賴對話上下文變成依賴持久化文檔,即係對話可以隨時關,但文檔永遠喺度。 因為上下文腐敗問題,其實大家都明,一個對話入面資訊越多模型能力越差,然後喺Claude入面,雖然Opus 4.7話有1M上下文,但我測試嗰陣,成日到大約500K左右就有啲唔妥,所以我而家幾乎係選擇喺400K左右整理一次兼存檔,然後開新視窗。 開新視窗之後,因為文檔同記憶管理得夠好,所以你幾乎唔使俾任何提示,有咩問題直接講就得,Agent都能好精準咁幫你搞掂,搞掂咗你繼續/neat存檔,你會發現真係越用越聰明。 呢個skill最近俾公司同事同幾個合作企業嘅朋友試咗,大家居然意外咁話幾好用。 過期嘅就刪,重複嘅就合,模糊嘅就改。
令你嘅知識庫,永遠只保留呢一刻最準確嘅真相。
以上,既然睇到呢度,如果覺得唔錯,隨手點個讚、在看、轉發三連啦,如果想第一時間收到推送,都可以俾我個星標⭐~多謝你睇我嘅文章,我哋,下次再見。
> / 作者:卡茲克
> / 投稿或爆料,請聯絡郵箱: wzglyay@virxact.com
今天沒選題了,所以想開源一個我自己做的,已經用了快1個多月,迭代了好多版的一個我覺得很有用的Skill。 名字可能聽着還挺呆逼的,但是我覺得它能幹的事,雖然看着非常的簡單,但是卻又很實用,在公司內部同事和一些我們的合作伙伴使用後,還都反饋挺不錯的。 做的事大概就是,每次你在Agent裏,做完一個功能或者又解決了一個BUG,就調用這個潔癖Skill,然後說一聲幫我全面審查一下或者直接就/Neat一下,它就會自動審查你整個項目的文檔體系和記憶文件,然後根據這次對話,把該改的文檔、記憶、CLAUMD.md進行迭代,確保非常乾淨之後,最後,再給你一份變更摘要,讓你知道改了啥東西。 四個平台通用,Claude Code、Codex、OpenCode、OpenClaw都能裝。 相信我,這玩意會讓你的Agent越來越聰明,也非常符合潔癖的定義。 每次一個任務做完,要退出這個窗口的時候,如果不跑一遍/neat,我就渾身難受,如坐針氈如芒刺背如鯁在喉。 大家現在也都知道,在很多時候,你的Agent之所以越用越笨,其實是因為,你的上下文過於混亂。 上下文不止是你跟你的Agent在單次對話中的聊天記錄,也包括你這個項目裏面的,各種文檔,還有約束,還有記憶。 但是其實很多的小夥伴,在用Agent的時候,比如CC和Codex去做一個項目,初期的文檔規範倒是規劃的挺好,但是每次迭代,每次更新,其實你會發現,這些文檔和記憶,都是疏於維護,你可能代碼都迭代了7、8輪了,新功能都上了無數了,但是你的文檔,還是最開始的1.0.0版本的初始文檔。 其實不止Agent,很多公司內部項目的文檔也都這樣,前期雄心壯志,文檔規範賊清晰,過兩個月之後,規範?文檔?你在說什麼,我聽不懂。 我自己的項目裏其實就出過這種事,就比如我做的AIHOT AI熱點監控系統(PS:這個我最近會再打磨打磨降降成本,然後會免費向所有人開放,到時候也會發文章介紹,希望對大家有用。) 光精選策略相關的功能就有亂七八糟的5、6個,一個信息抓到系統裏,會需要十幾個步驟進行數據清洗、加工、好幾層評估等等,然後才會落庫。 現在每天處理的量級,在我嚴格挑選和管控信源的前提下,還是會有500多條信源產出的數據。 然後我當時剛開始做的時候,其實想把整個項目後續封裝成CLI,允許所有人的Agent都可以來瀏覽這上面的數據,能讓大家用起來更方便,所以呢,我就把數據庫從SQLite換成了PostgreSQL。 但是這個切換其實工作量還是有點大的,當時用的還是Opus 4.6,時間一長的,真的就是顧頭不顧尾,然後,搞完以後,文檔啥的我忘記改了。 結果後來我繼續開發新功能的時候,Claude還在調用SQLite的語法,我當時還以為是模型啥的原因,搞了半天,發現是文檔沒改,包括我的CLAUDE.md裏面,還赫然寫着大概項目使用SQLite數據庫這個意思。 這種只是一個小摩擦,當你如果經歷多了之後,你會發現,Agent很多時候犯的大多數莫名其妙的錯誤,根源其實都不是模型笨,是文檔和記憶已經都腦腐了,都出現明顯的混亂了。 很多朋友可能會說,這不是專業開發者才需要關心的事嗎? 但是我想說,恰恰相反,很多我的專業開發者朋友都有自己的一套工程化習慣,git commit message寫得規規矩矩,README隨手就更新。 真正被這個問題折磨最深的,反而是我們這些藉助Agent來vibe coding的人,比如設計師、產品經理、內容創作者,當然也包括我自己。 vibe coding前期特別爽,跟AI聊兩句代碼就出來了,功能也就跑起來了。但項目一旦做大,文檔就不可避免地開始混亂,而且很多人也完全沒有維護的概念,到最後就越來越混亂,你就會感覺到,我靠我的Agent怎麼越來越笨。 而這個維護,就是今天這個潔癖.skill,它要做的事情。 之前Claude Code有一個功能叫AutoDream,也就是做夢,我也寫過文章: Claude Code悄悄學會了做夢 ,我當時挺興奮的,因為這玩意感覺就是我想要的東西?
但實際用了以後我發現一個很致命的問題。
AutoDream只動記憶,不動項目文檔,這就尷尬的一比了。
如果你用Agent開發過任何東西,你就知道,一個項目裏的知識其實分三層,每一層服務的人不太一樣。 第一層是Agent自己的記憶系統,過去的聊天記錄、項目的隱性知識。 第二層是項目根目錄的CLAUDE.md,給AI自己看的,項目約定、結構、紅線、路由清單等等。 第三層是docs/目錄和README,給其他人看的,比如Agent、同事、下游開發者等等,比如接入指南、架構說明、運維手冊等等。 比如CLAUDE.md裏寫新增了五個路由不等於docs/integration-guide.md裏寫下游怎麼接這五個路由。 前者是提醒自己,後者是教別人,兩份作用是完全不同的,都得寫。 AutoDream的問題就在於,它只管了第一層,記憶文件確實變乾淨了,但是另外兩個,它確實是不管,所以也就導致,我用下來,確實作用不大。 目前老規矩,已經在我自己的Skills倉庫裏面開源,所有人都可以隨意使用: https://github.com/KKKKhazix/khazix-skills
裏面最核心的原則,其實就是合併優於追加,刪除優於保留。 這個跟大多數人的直覺是反的,因為很多時候,大家會覺得,信息多總比信息少好吧?萬一以後用得上呢? 但其實在AI協作的場景裏,信息多不是優勢,信息準才是,坦率的講,一條過期的記憶,比沒有記憶更糟糕,因為沒有記憶的時候,AI至少知道自己不知道,它會問你。 但如果它讀到了一條過期的信息,它會以為那是對的,然後基於錯誤的前提做事。 OpenClaw越用越笨,就是它的記憶系統實在是過於臃腫了。 而當你安裝了潔癖.skill,每次跑潔癖.skill的時候,它會按順序做五件事。 第一步,就是先強制機械式盤點。把項目裏所有的md文件全列出來,每一個都讀一遍,都不要漏掉,因為之前遇到過好幾次,你看着是給你改了,結果哎就給你漏了那麼一個文檔,關鍵還是賊關鍵的。 第二步,用我的變更影響矩陣文檔去識別一下需要改什麼。不只看對話裏有什麼新事實,也要去看新事實會波及哪些文檔層級。 然後這一步還有一個關鍵檢查,這次對話是不是跨項目的?如果改了項目A而項目B依賴它,那項目B的docs也得跟着改,這個其實是歷次同步最常翻的車。 第三步,直接改,這裏有一個順序步驟,先改docs/,再改CLAUDE.md,最後整理記憶。 第四步,自檢清單,基本是我的skill裏面的老演員了,必然都會有自檢清單,就比如新增的環境變量,在runbook和CLAUDE.md都出現了嗎?有沒有相對時間遺留等等之類的東西,確認一遍。
第五步,輸出一份變更摘要,就是這樣的東西。
這五步看着麻煩,其實就是skill自己的過程,你根本不用管,你要做的,就是運行一下這個skill。 我自己一般在所有任務的收尾,都必定會運行一下/neat。 我把潔癖.skill一般當類似於遊戲的存檔機制用,這次要結束了,要存檔了,就運行一下/neat,然後,下次打開一個新的會話,還可以接着來。 說實話,潔癖這個東西看起來只是在整理文檔,但它真正解決的問題我覺得比整理文檔有用的多。 它會讓你的知識體系從依賴對話上下文變成了依賴持久化文檔,也就是說,對話可以隨時關,但文檔,永遠在。 因為上下文腐敗問題,所以其實大家都懂,一個對話裏,信息越多模型能力越差,然後再Claude裏,雖然Opus 4.7說有1M上下文,但是我測試的時候,經常到了500K左右就有點不對勁了,所以我現在幾乎是選擇在400K左右進行一次整理並存檔,然後新開窗口了。 新開窗口以後,因為文檔和記憶管理的足夠好,所以你幾乎不需要給任何提示,有任何問題直接說就行,Agent都能非常精準的給你解決,解決完了你繼續/neat進行存檔,你會發現,真的就是,越用越聰明。 這個skill最近讓公司同事和幾個合作企業的朋友試了一下,大家居然意外的說挺好用的。 過期的就刪,重複的就合,模糊的就改。
讓你的知識庫,永遠只保留此刻最準確的真相。
以上,既然看到這裏了,如果覺得不錯,隨手點個贊、在看、轉發三連吧,如果想第一時間收到推送,也可以給我個星標⭐~謝謝你看我的文章,我們,下次再見。
>/ 作者:卡茲克
>/ 投稿或爆料,請聯繫郵箱: wzglyay@virxact.com