開源「淘金小鎮.Skill」,讓你的Agent挖出每個排行榜裏隱藏的信息差!
整理版優先睇
用Agent自動監控Skill排行榜,挖出每日資訊差
呢篇文章係由Agent Skill重度用戶卡爾分享嘅親身經驗。佢成日安裝大量Skill,但好難揀邊個最好,於是決定自己整一個Skill叫「淘金小鎮」,用Agent自動監控ClawHub嘅排行榜。佢想解決嘅問題係:人眼根本追唔上Skill生態嘅更新速度,好多有潛力嘅工具好易俾人忽略。整體結論係,與其自己日日睇,不如俾Agent每日固定路線去同一個地方攞數據做比較,再將值得睇嘅篩選出嚟,咁樣先可以持續發現資訊差。
技術上,淘金小鎮最初用瀏覽器自動化,但成日因為環境問題失敗。後來改用直接查Convex API,分析ClawHub前端點樣攞數據,發現skills:listPublicPageV4呢個query,加上sort=downloads、dir=desc、nonSuspiciousOnly=true等參數,每次取25條,再用nextCursor分頁,連續4次就拎到Top100。呢種方式比瀏覽器自動化穩定好多,仲可以復刻用戶見到嘅榜單。連續運行後,可以睇到每日排名變動,例如Self-Improving Agent同Proactive Agent融合後衝上前三;又或者agent-browser大更新半個月後先發現,證明每日快照嘅重要性。
為咗更好咁篩選,佢追加咗幾條規則:前100名裏排名升8名以上、下載量增長前20、下載同星標都升10名嘅,全部挖出嚟同現有Skill做對比。咁樣就可以發現新上榜嘅Skill同自己有咩分別,值…
- 結論:Agent可以自動化監控排行榜,人眼追唔上更新速度,Agent能穩定篩選資訊,將榜單變成時間線。
- 方法:透過直接查Convex API嘅skills:listPublicPageV4查詢,配合nextCursor分頁,穩定獲取Top100數據,避免瀏覽器自動化嘅不穩定性。
- 差異:每日快照可以清晰睇到排名變動同趨勢,唔受單次推薦影響,避免錯過重要更新如agent-browser大更新。
- 啟發:Skill生態似早期Chrome插件市場,Agent能幫助發現有潛力嘅基礎設施級工具,例如Polymarket、上下文管理類Skill嘅新神。
- 可行動點:讀者可模仿呢個思路,用Agent監控其他公開數據源(如產品排行榜、新聞榜),自動篩選資訊差。
淘金小鎮GitHub
開源Skill,用於監控ClawHub排行榜,自動對比資訊差。
點解要整淘金小鎮?
作者卡爾成日囤Agent嘅Skills,但好難揀邊個最好。佢發現人類好難拒絕榜單,尤其係帶有倖存者偏差嘅推薦。
囤Agent的Skills有癮
於是決定整一個Skill每日監控ClawHub排行榜,將榜單變成可覆盤嘅情報網。
人類是很難拒絕榜單的
技術實現:由瀏覽器自動化到直接查API
最初用瀏覽器自動化,但成日因為環境問題失敗,就算加大token消耗都解決唔到。
瀏覽器自動化不靠譜
後來改用直接查Convex API,分析ClawHub前端點樣攞數據。
Convex雲端資料庫
關鍵係發現咗skills:listPublicPageV4呢個query,配合sort=downloads、dir=desc、nonSuspiciousOnly=true等參數,每次取25條,再用nextCursor分頁,連續4次就拎到Top100。
skills:listPublicPageV4
nextCursor分頁
sort=downloads
呢種方式比瀏覽器自動化穩定好多,仲可以復刻用戶見到嘅榜單。
運行觀察:榜單變成時間線
連續運行後,可以睇到每日排名變動,例如Self-Improving Agent同Proactive Agent融合後衝上前三;又或者agent-browser大更新半個月後先發現。
排名變動
Self-Improving Agent
agent-browser大更新
為咗更好咁篩選,追加咗幾條規則:
- 前100名裏排名升8名以上嘅Skill
- 下載量增長排進前20嘅Skill
- 下載同星標都升10名嘅Skill
呢啲全部挖出嚟同現有Skill做對比,睇下值唔值得花時間重新適應。
排名升8名以上
下載量增長前20
淘金小鎮嘅真正價值
呢個Skill嘅價值在於將榜單變成時間線,唔受信息流影響。例如最近Polymarket嘅Skill上榜,同Agent上下文管理類Skill嘅新神輪流出現。
Polymarket Skill
上下文管理類Skill
作者認為Agent Skill生態似早期Chrome插件市場,人眼追唔上更新速度,但Agent可以。對讀者嚟講,可以參考呢個思路用Agent監控其他公開數據源,幫自己節省篩選時間。
我發現囤Agent嘅Skills有癮,
今日啱啱裝咗一大堆同類Skill,未用熟就想提早知道呢類裏便最好嘅係邊個。轉頭又發現某個佬推薦咗佢自留嘅20個Skills,回回路過我都忍唔住㩒入去睇。
呢件事就好似以前我睇App Store榜單同Steam新品榜咁。
人類好難拒絕榜單㗎。
尤其係帶少少倖存者偏差,帶少少我替你試過踩過坑嘅榜單。
所以我諗,既然我每日都俾Skill揀都揀唔嚟嘅苦惱折磨,
點解唔俾Agent都體驗嚇呢。
於是有咗一個新Skill,
我幫佢改咗個名,叫淘金小鎮。
佢做嘅第一件事就係,每日去ClawHub睇嚇下載榜Top100,將當日榜單存低,生成一份對比報告,再部署到一個GitHub Pages頁上。
當然,如果淨係用嚟睇ClawHub嘅話,都冇必要整成Skill啦,我掛一個靜態網頁,每日更新,俾大家睇結果就得。呢個Skill仲可以針對好似Claude Code嘅更新日誌,或者AA Index呢啲模型排行榜,監測佢哋嘅更新,等模型用最少嘅環境依賴穩定咁運行多次數據分析。
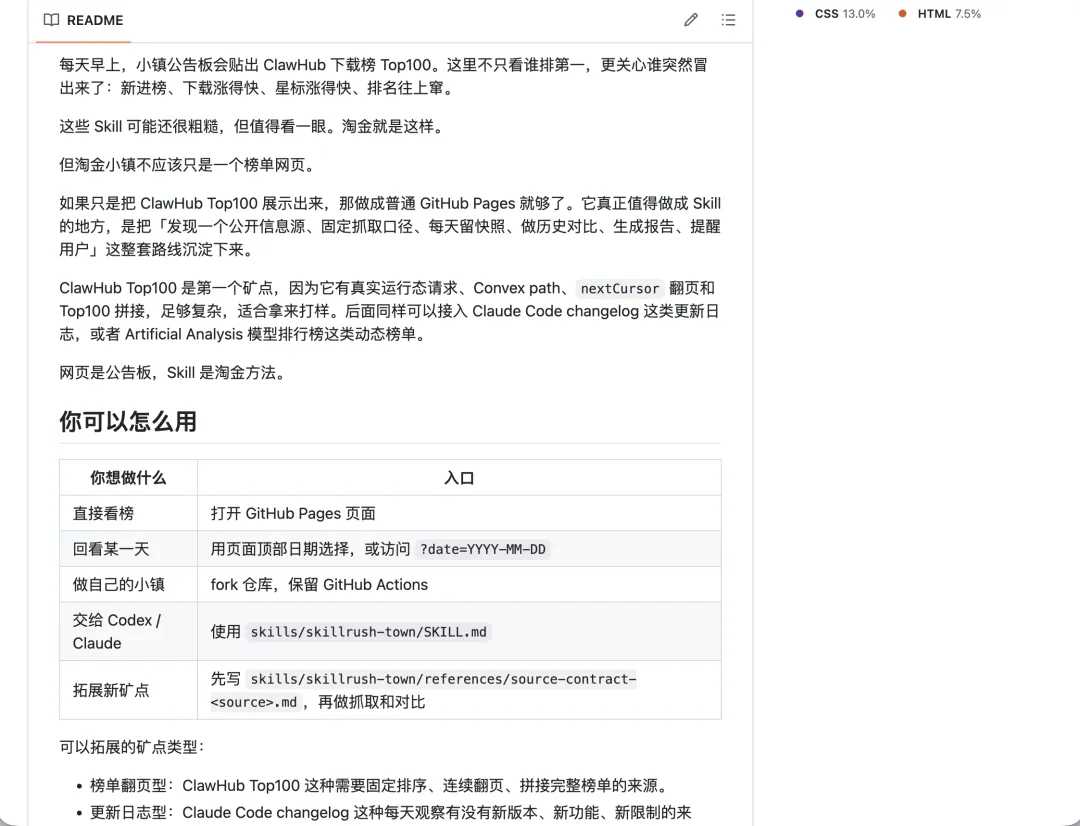
🔗 github.com/LearnPrompt/skillrush-town
做嚇做嚇我發現,網頁其實係最唔重要嘅一層。
真正得意嘅係,佢將一個每日都會變嘅公開資訊源,變成一個可以俾Agent覆盤嘅情報網。
淘金小鎮最初我係用Codex去做嘅。當時ClawHub冇一個現成公開API,所以我一開始用瀏覽器自動化,等Agent好似人咁打開網頁,睇頁面,請求數據,然後將結果存低。
但係講到瀏覽器自動化呢樣嘢,
你話佢唔可靠,佢又可以做到好多API覆蓋唔到嘅嘢。
你話佢可靠,佢又成日喺你最唔想理佢嘅時候出問題。瀏覽器環境冇咗,登錄狀態變咗,頁面加載慢咗,本地依賴抽風一大堆。

就算我寫咗夠複雜夠詳細嘅提示語,一個禮拜仲有三日係失敗嘅。
當時我就覺得,咁唔掂,
唔係就加大token消耗,直接上GPT 5.5 high,但失敗率依然超高。
咁直接推倒重來,等新版Codex行無限循環模式(/goal),目標係揾出依賴最少嘅方案,循環30次都可以將ClawHub嘅Top100拉落嚟。
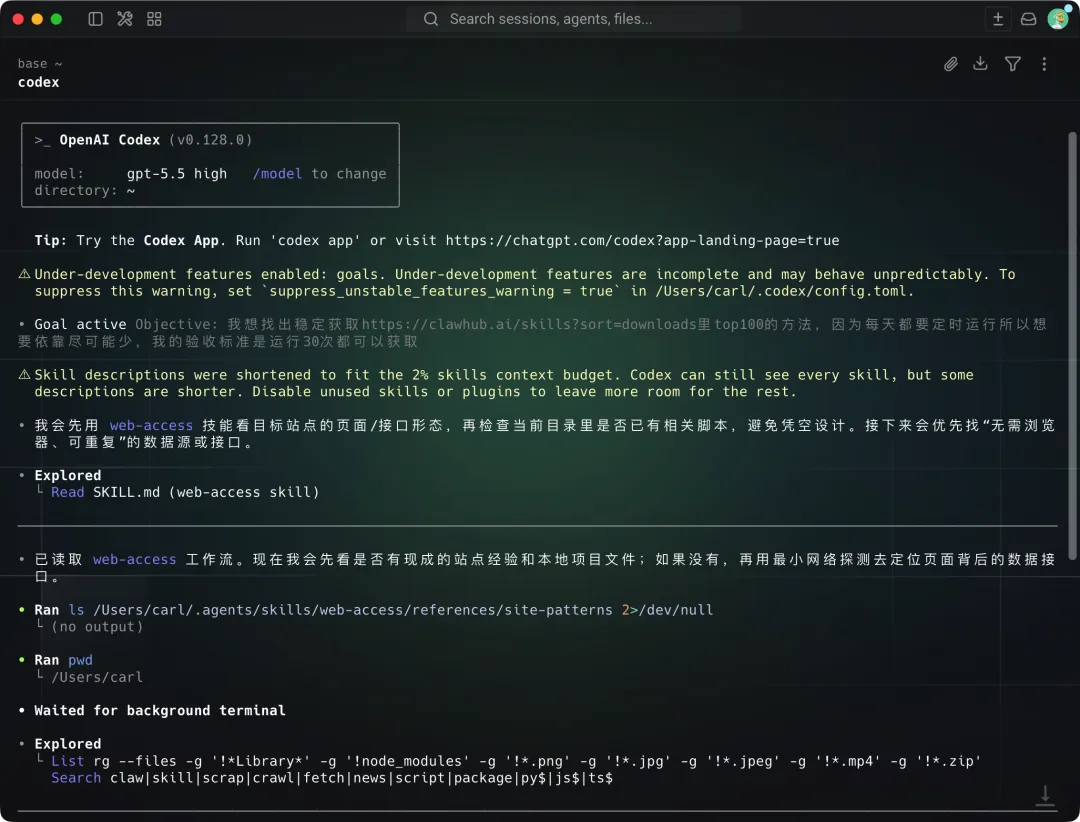
咁樣比起我喺提示語裏便落十幾個限制都好用,斷咗都可以重新連線,模型仲可以發揮自己嘅想像力。
到第五個鐘嘅時候GPT發現咗一條新路,clawhub.ai/skills?sort=downloads呢個地址,㩒開之後點睇都係榜單地址,但本質上只係一個入口,冇數據嘅,背後係一個Convex服務。
Convex你可以先理解為一種雲端數據庫加後端函數。好多網站會將數據存在Convex裏便,前端頁面打開之後,再經由一個query去問佢要數據。
ClawHub呢度對應嘅query path叫skills:listPublicPageV4,大概係公開Skill列表頁嘅第四版查詢。
再繼續睇參數,裏便有幾個關鍵條件。
按下載量排序,sort=downloads。
由高到低,dir=desc。
淨係睇非可疑嘅Skill,nonSuspiciousOnly=true。
每頁25條,numItems=25。
到呢一步,仲唔可以直接話拎到咗Top100。
因為佢一次只係畀25條。
但返回結果裏有一個nextCursor,
呢樣嘢你可以理解成下一頁嘅書籤。你拎住呢個書籤,就可以拎到下一頁。
連續問4次,25條乘4,Top100就出咗嚟。
呢個就係淘金小鎮最早成個諗法。
佢唔係隨便攞咗一個頁面文本,
係盡量復刻ClawHub頁面自己拎數據嘅方式。
網頁點樣問,我就點樣問。
咁樣拎到嘅榜單,先更加接近用戶見到嘅。
連續運行兩日就可以清晰感受到分別喇。
今日第17名係邊個,邊個Skill跌咗排名。邊個Skill今日突然衝上嚟。邊個作者做嘅Skill連續幾日都喺度增長。
呢啲嘢,網頁本身唔會話你知。
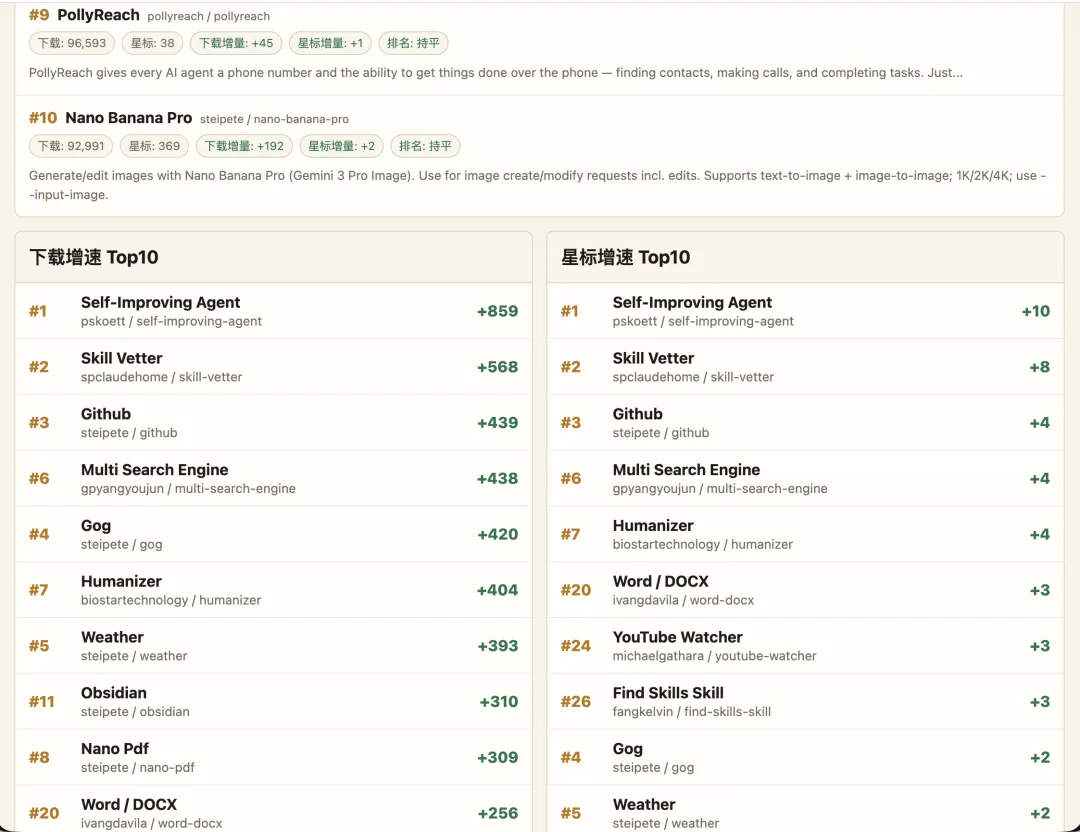
當呢啲數據開始連續存在嘅時候,榜單就變成咗一條時間線。
我印象好深嘅好似Self-Improving Agent呢類自進化嘅Skill,後來佢同另一個Proactive Agent融合,做咗一個新Skill,Self-Improving + Proactive Agent,好快就衝上前三。
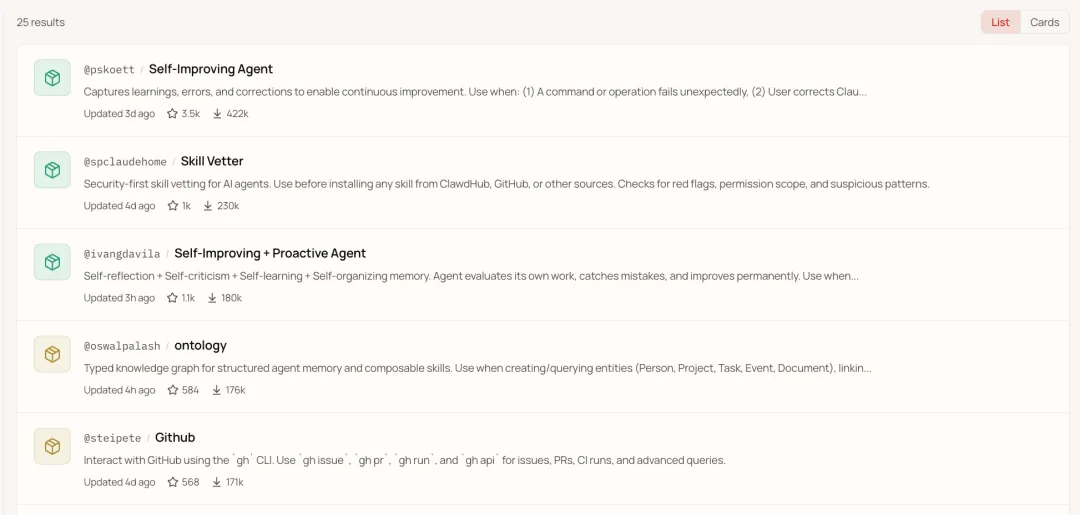
但如果我只係喺X上隨機碌到,甚至會因為呢個名覺得只係一個二創。
如果每日留快照,我哋可以清楚知道新上榜嘅Skill同我哋已經裝咗嘅Skill有咩分別,使用次數唔高嘅情況下,值唔值得花時間重新適應。
淨係睇新進榜嘅話誤導性有啲高,可能只係咁啱俾某個大號推薦咗。有啲Skill可能上榜好耐,但因為版本更新更加好用,排名就一下子飆升,但有時真係會不自覺忽略咗。
我就係咁樣白白錯過咗agent-browser嘅大更新半個月。
所以我幫淘金小鎮加咗幾條新規則。
前100名裏最近排名一下子升咗8名以上嘅,
下載量增長排入前20嘅,
下載同星標都升咗10名嘅,
都挖出嚟同我原有嘅Skill體系做差距對比。
好處就係佢唔太受我哋嘅資訊流影響。
最近我就見到Polymarket嘅Skill上榜咗,平時掛住裝一大堆UI設計同HTML PPT嘅skill,原來都開始將預測市場接入Agent工作流。
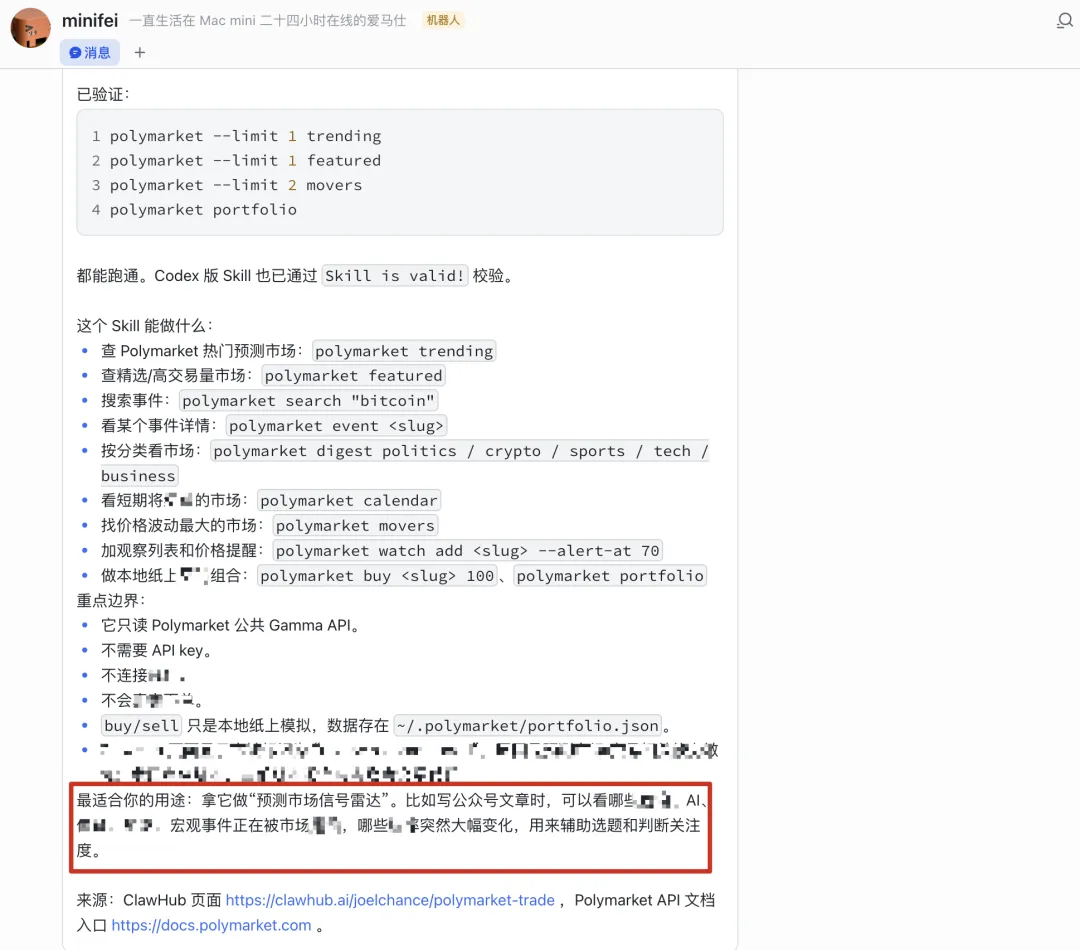
仲有就係好似Agent上下文管理呢類Skill真係每隔一段時間就有個新神出嚟,我啱啱將LLM Wiki整成Skill接入,GBrain就爆紅。啱啱下載咗一個QMD,等本地模型管理上下文,有5個記憶層嘅Elite Longterm Memory又爆紅。
由同一類能力嘅排名變動可以睇出大家最近用同一種能力嘅時候,會有咩偏好。
呢個就係我覺得淘金小鎮得意嘅地方,
佢係幫我將值得判斷嘅金沙先撈出嚟。
你諗嚇,
而家Agent嘅Skill生態真係有啲似早期嘅Chrome插件市場,
所有人都在上載,
名一個比一個勁,說明一個比一個玄。
問題係我冇可能每日將所有新嘅都試一次。
因為資訊流真係太快。
你今日覺得一個工具好Hit,聽日可能冇人提。
你今日錯過一個小Skill,三日後佢可能已經變成好多Agent工作流入面嘅基礎設施。
人眼係追唔上呢個速度㗎。
但Agent可以。
俾佢一條固定路線,等佢每日去同一個地方,拎同一類數據做比較,然後將值得睇嘅撈上嚟。
今日邊個仲喺度,邊個係新嚟嘅,
邊個跌咗落去,邊個突然好多人開始用。
你睇一眼就知曬。
對我嚟講,呢個就係淘金。
唔係揾唯一正確嘅Skill。
而係喺一堆沙裏便,
先將啲會發光嘅嘢撈出嚟。
淨低嘅,再慢慢試。
@ 作者 / 卡爾
最後,多謝你睇到呢度👏如果鍾意呢篇文章,不妨順手俾我哋讚好|在看|轉發|留言 📣
如果想第一時間收到推送,不妨俾我個星標🌟
如果你有更有趣嘅玩法,歡迎喺留言區傾偈🤝
更多嘅內容正在不斷填坑中……

我發現囤Agent的Skills有癮,
今天剛裝了一大堆同類Skill,還沒用熟就想提前知道這類裏最好的到底是哪一個。轉頭又發現某個佬推薦了自留的20個Skills,回回路過我都忍不住點進去看。
這事就很像以前我看App Store榜單和Steam新品榜。
人類是很難拒絕榜單的。
尤其是那種帶一點倖存者偏差,帶一點我替你試過了踩過坑的榜單。
所以我就在想,既然我每天都在被Skill選都選不過來的苦惱折磨,
那為什麼不讓Agent也體驗一下呢。
於是就有了一個新Skill,
我給它起名叫淘金小鎮。
它乾的第一件事就是,每天去ClawHub上看一眼下載榜Top100,把當天榜單存下來,生成一份對比報告,再部署到一個GitHub Pages頁上。
當然,如果只能用來看Clawhub的話,也沒必要做成Skill了,我就掛一個靜態網頁,每天更新一下,給大家看結論就好了。這個Skill還能夠針對一些像Claude Code的更新日誌,或者像AA Index這種模型排行榜,觀測它們的更新,讓模型以最少的環境依賴穩定地運行多次數據分析。
🔗 github.com/LearnPrompt/skillrush-town
做着做着我發現,網頁其實是最不重要的一層。
真正有意思的是,它把一個每天都會變的公開信息源,變成了一個可以被Agent覆盤的情報網。
淘金小鎮最早我是用Codex去做的。當時ClawHub沒有一個現成公開API,所以我一開始走的是瀏覽器自動化,讓Agent像人一樣打開網頁,看頁面,請求數據,然後把結果存下來。
但就是瀏覽器自動化這個東西吧,
你說它不靠譜,它能幹很多API覆蓋不到的活。
你說它靠譜吧,它又經常在你最不想管它的時候出問題。瀏覽器環境沒了,登錄態變了,頁面加載慢了,本地依賴抽風了一大堆。
就算我寫了足夠複雜足夠詳細的提示語,一週還是有三天是失敗的。
當時我就覺得,這不行,
不然就加大token消耗,我直接上GPT 5.5 high,但失敗率還是超高。
那直接推倒重來,讓新版Codex上無限循環模式(/goal),目標就是找出依賴最少的方案,循環30次都可以把ClawHub的Top100拉下來。
這樣比我在提示語裏面上十幾個限制都好用,斷掉也可以重連,模型還可以發揮自己想象力。
到第五個小時的時候GPT發現了一條新路,clawhub.ai/skills?sort=downloads這個地址,點開後怎麼看都是榜單地址,但本質上只是一個入口,沒數據的,背後是一個Convex服務。
Convex你可以先理解成一種雲端數據庫加後端函數。很多網站會把數據存在Convex裏,前端頁面打開以後,再通過一個query去問它要數據。
ClawHub這裏對應的query path叫skills:listPublicPageV4,大概就是公開Skill列表頁的第四版查詢。
再繼續看參數,這裏面有幾個關鍵條件。
按下載量排序,sort=downloads。
從高到低,dir=desc。
只看非可疑Skill,nonSuspiciousOnly=true。
每頁25條,numItems=25。
到這一步,還不能直接說拿到了Top100。
因為它一次只吐25條。
但返回結果裏有一個nextCursor,
這個東西你可以把它理解成下一頁書籤。你拿着這個書籤,就可以拿到下一頁。
連續問4次,25條乘4,Top100就出來了。
這就是淘金小鎮最早成型的思路。
它不是隨便抓了一個頁面文本,
是儘量復刻了ClawHub頁面自己拿數據的方式。
網頁怎麼問,我就怎麼問。
這樣拿到的榜單,才更接近用戶看到的。
連續運行兩天就能清晰感受到差別了。
今天第17名是哪個,哪個Skill掉排名了。哪個Skill今天突然衝上來。哪個作者做的Skill連續幾天都在增長。
這些東西,網頁本身不會告訴你。
當這些數據開始連續存在的時候,榜單就變成了一條時間線。
我印象很深的像Self-Improving Agent這類自進化的Skill,後來它跟另一個Proactive Agent融合,做了一個新Skill,Self-Improving + Proactive Agent,很快就衝上前三了。
但如果我只是在X上隨機刷到,甚至會因為這名字覺得只是個二創。
如果每天留快照,我們能清晰地知道新上榜的Skill跟我們已經安裝Skill有什麼區別,使用頻率不高的情況下,值不值得花時間去重新適應。
光看新進榜的話誤導性有點高,很可能只是剛好被某個大號推薦了。有些Skill可能上榜很久了,但因為版本更新更好用了,排名就一下子往上竄了,但有的時候真的會下意識把它忽略掉。
我就是這樣水靈靈錯過了agent-browser的大更新半個月。
所以我給淘金小鎮追加了幾條新規。
前100名裏最近排名一下子提了8名以上的,
下載量增長排進前20的,
下載和星標都提升了10名的,
都挖出來跟我原有的Skill體系做差距對比。
好處就是它不太受我們的信息流影響。
最近我就看到Polymarket的Skill上榜了,平時光顧着裝一大堆UI設計和HTML PPT的skill了,原來都開始把預測市場也接進Agent工作流了。
還有就是像Agent上下文管理這類Skill真的是每過一段時間就有個新神出來,就我剛把LLM Wiki做成Skill接進來,GBrain就火了。剛剛下了一個QMD,讓本地模型管理上下文,有5個內存層的Elite Longterm Memory又火了。
從同一類能力的排名變動可以看出大家最近在用同一種能力的時候,會有什麼樣的偏好。
這就是我覺得淘金小鎮有意思的地方,
它是在幫我把值得判斷的金子先撈出來。
你想想看,
現在Agent的Skill生態其實有點像早期的Chrome插件市場,
所有人都在上傳,
名字一個比一個猛,說明一個比一個玄。
問題是我不可能每天把所有新的都試一遍。
因為信息流真的太快了。
你今天覺得一個工具火,明天可能沒人提了。
你今天錯過一個小Skill,三天後它可能已經變成很多Agent工作流裏的基礎設施。
人眼是追不上這個速度的。
但Agent可以。
給它一個固定路線,讓它每天去同一個地方,拿同一類數據做比較,然後把值得看的撈上來。
今天誰還在,誰是新來的,
誰掉下去了,誰突然很多人開始用。
你看一眼就都知道了。
對我來說,這就是淘金。
不是找到唯一正確的Skill。
而是在一堆沙子裏,
先把那些會發光的東西撈出來。
剩下的,再慢慢試。
@ 作者 / 卡爾
最後,感謝你看到這裏👏如果喜歡這篇文章,不妨順手給我們點贊|在看|轉發|評論 📣
如果想要第一時間收到推送,不妨給我個星標🌟
如果你有更有趣的玩法,歡迎在評論區聊聊🤝
更多的內容正在不斷填坑中……