當Karpathy的LLM Wiki遇上本體論:一場知識表示的終極融合
整理版優先睇
將 Karpathy 的 LLM Wiki 理念與傳統本體論結合,構建一套「既不幻覺、又不僵化」的企業級知識架構。
這篇文章探討了知識管理領域的兩大流派:傳統的「本體論」(Ontology)與 Andrej Karpathy 提出的「LLM Wiki」理念。作者指出,傳統本體論雖然精確但維護成本極高且過於僵化;而 LLM Wiki 則將知識視為代碼庫,利用大模型進行自動化編譯,雖然靈活但存在幻覺風險。作者希望解決如何在企業環境中,既能發揮 AI 的自動化抽取能力,又能保持業務邏輯的嚴謹性。
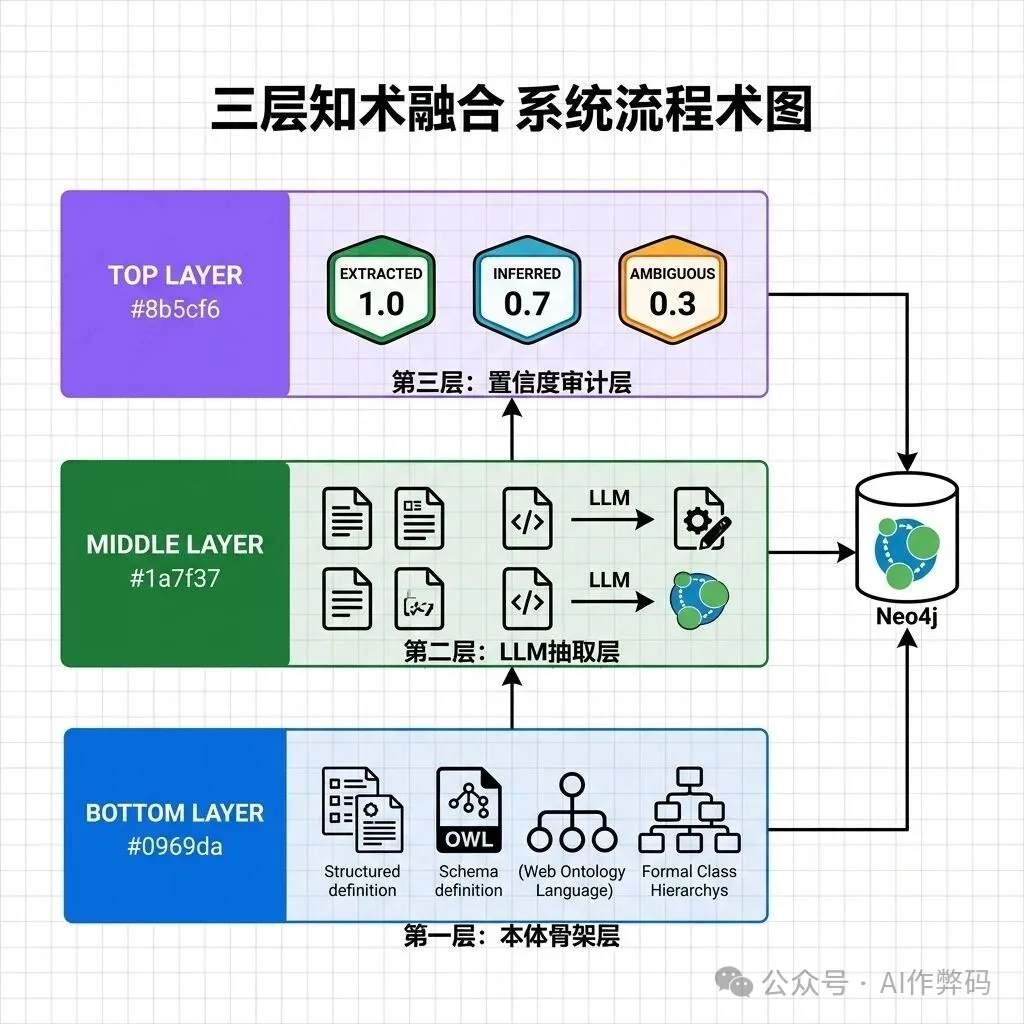
文章最終提出了一套「三層融合架構」作為結論。這套架構以 Neo4j 圖數據庫為基礎,結合了本體論的約束力與 LLM 的發現能力。作者認為,純大模型太過飄忽,純本體論則太過累人,只有將兩者有機結合,通過置信度標籤進行分層管理,才是智能體(AI Agent)時代知識庫的終極形態。
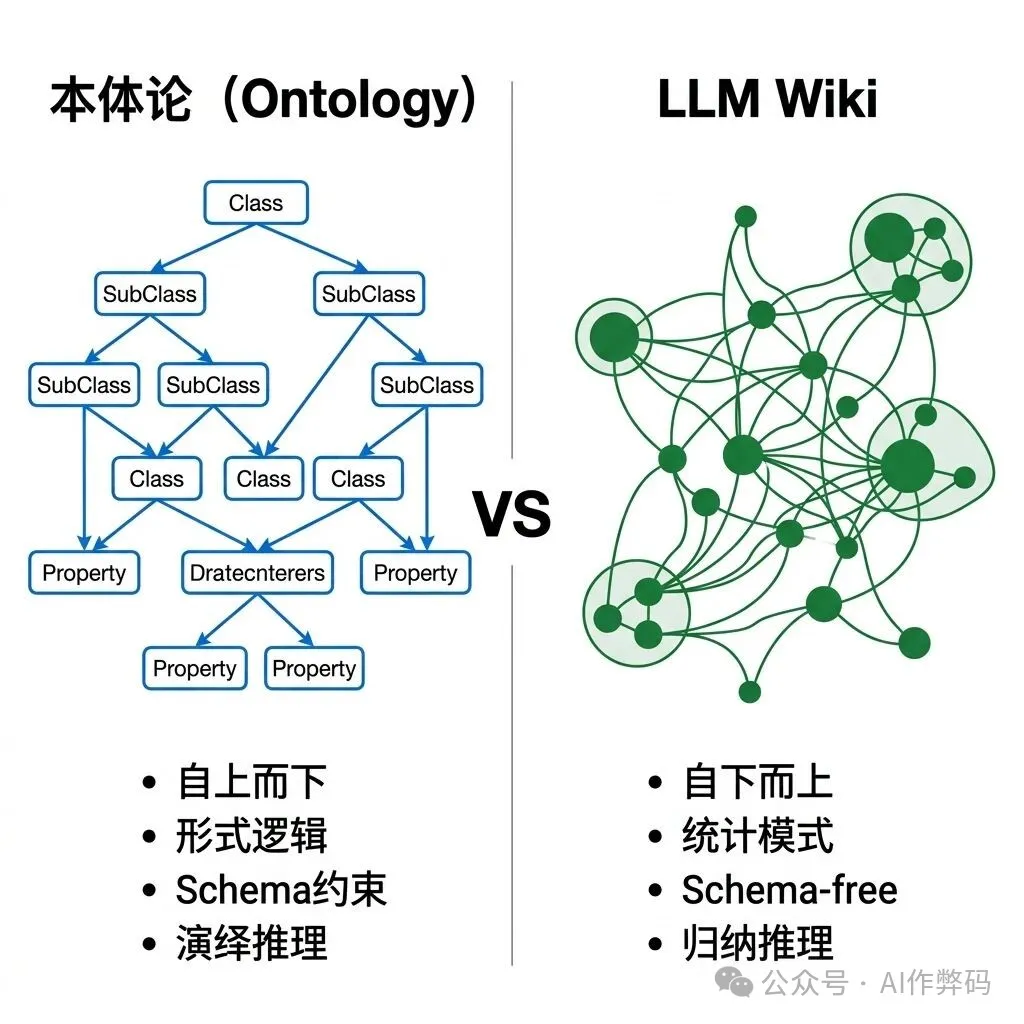
- 核心矛盾:本體論是自上而下的理性主義(精確但昂貴),LLM Wiki 是自下而上的經驗主義(靈活但有幻覺)。
- 技術路徑:利用 Graphify 流水線,結合 tree-sitter 進行本地確定性解析(AST)與 LLM 語義抽取,實現知識的自動化編譯。
- 分層架構:建立「本體骨架層」定義規則、「LLM 抽取層」發現事實、「置信度審計層」量化不確定性。
- 置信度模型:引入 EXTRACTED(1.0)、INFERRED(0.6-0.9)及 AMBIGUOUS(0.1-0.3)三級標籤,解決開放世界假設下的認知問題。
- 行動建議:企業應將本體作為寫入約束(Schema Validator),將 LLM 作為讀取發現引擎,構建可審計、可追溯的智能體知識底座。
Graphify 7階段知識處理流水線
包含 Detect (掃描), Extract (AST+LLM混合抽取), Build (注入圖), Cluster (Leiden算法社區發現), Analyze, Report 及 Export。
Graphify
將 Karpathy 的 LLM Wiki 理念工程化實現的開源項目,支持將原始文檔編譯為結構化知識圖譜。
兩種知識觀的哲學博弈:規劃圖與自然村落
本體論(Ontology)就像是城市規劃圖,在動工前就精確定義了所有概念與關係。它基於描述邏輯,雖然極其嚴謹且可推理,但面臨「知識獲取瓶頸」,一旦現實變化,預定義的 Schema 往往追趕不及。
Graphify 工程實踐:確定性骨架與語義血肉
在 Graphify 的實現中,最精妙的是其混合抽取策略。它不依賴昂貴的向量數據庫,而是回歸圖拓撲結構。
1. tree-sitter (本地確定性): 解析代碼 AST,產出 100% 確定的函數調用與類繼承關係。
2. LLM 子代理 (語義推理): 處理文檔與圖片,產出帶有置信度標籤的語義關係。
3. Leiden 算法: 基於圖拓撲密度進行社區發現,而非單純的語義相似度匹配。三層融合架構:智能體時代的知識終解
真正的工程突破在於設計二者的接口協議。我們建議在 Neo4j 中實施分層管理,讓本體做風控,讓 LLM 做苦力。
本體提供寫入約束 (Write Constraint),LLM 提供讀取發現 (Read Discovery)。
MATCH (a:Module {name:"ChassisControl"})-[r:DEPENDS_ON]->(b:Module)
WHERE r.confidence >= 0.7
AND r.source IN ["tree-sitter", "claude-inferred"]
RETURN a.name, r.confidence, r.source, b.name
ORDER BY r.confidence DESC這種架構確保了智能體在執行審批流時不會產生幻覺,同時在回答複雜關聯問題時擁有足夠的上下文支撐。
📖 前置閲讀 Graphify:將 Karpathy 嘅 LLM Wiki 由理念變成產品介紹咗 Graphify 係點樣將 Karpathy 嘅知識編譯理念工程化。呢篇會由「本體論」嘅視角去睇 LLM Wiki,並提供一個分層融合嘅架構方案。 ··· 一、本體論:知識世界嘅憲法喺哲學入面,「本體論」(Ontology) 研究嘅係「存在」本身——到底乜嘢嘢先係真實嘅?事物嘅本質係咩?佢哋之間有咩關係? 喺電腦科學入面,呢個概念喺 1993 年被 Tom Gruber 精煉成一句經典定義: 「本體論係對一個共享概念體系嘅 — Tom Gruber, 1993 講返人話,即係:喺寫任何 code 之前,先好似制訂憲法咁,清清楚楚定義呢個領域入面有啲咩「概念」(Class),佢哋有咩「屬性」(Property),概念之間准許有咩「關係」(Relation),同埋咩推理規則先至係合法嘅。 呢套理論落地之後就係 OWL (Web Ontology Language),佢嘅底層係 Description Logic (描述邏輯)——一種專門為知識表示而設計嘅形式邏輯。 💻 OWL 描述邏輯示例 關鍵優勢在於:OWL 配合埋推理器(例如 Pellet、HermiT)可以自動發現隱含嘅知識。你只需要定義好規則,推理器就可以幫你檢查一致性、推導出新嘅事實。呢點喺合規場景入面係至關重要。 但佢嘅致命弱點亦都好明顯: ❌ 知識獲取樽頸 (Knowledge Acquisition Bottleneck) 要構建同維護一個精確嘅 OWL 本體,需要領域專家加埋本體工程師付出大量手工勞動。現實中好多團隊都等唔切。 ❌ 脆弱性 (Brittleness) 任何唔喺預先定義 Schema 入面嘅新概念,系統都會「睇唔到」。當 codebase 快速變化嗰陣,本體永遠都只係喺後面追趕緊現實。 簡單嚟講:本體論精確但係好貴,完美但係好僵化。 ··· 二、LLM Wiki:知識世界嘅進化論Karpathy 提出嘅 LLM Wiki 完全行咗去另一個極端。核心理念可以用一句話概括: 「Obsidian 係 IDE,LLM 係 Programmer, — Andrej Karpathy, 2026 將知識當成一個「代碼庫」咁去管理。原始文檔(論文、code、會議記錄)係「源文件」,大模型係「編譯器」,輸出嘅結構化 Wiki 就係「編譯產物」。呢個過程 Karpathy 稱之為Knowledge Compilation (知識編譯)。 開源項目 Graphify 將呢套理念做成咗工程化實現,佢嘅 7 階段流水線如下: 💻 Graphify 處理流水線 呢套流水線入面最精妙嘅係 Stage 2 嘅混合抽取策略: 🌳 tree-sitter:確定性嘅骨架 對 code 文件使用 tree-sitter 進行 AST 解析。呢一步唔會 call 任何 LLM,唔會消耗任何 token,直接喺本地行,產出嘅 function call 關係、class 繼承層級、module import 等等都係 100% 確定性 嘅。 🧠 LLM 子代理:語義嘅血肉 對文檔同圖片使用 Claude 子代理做並行語義抽取。產出會帶有 置信度標籤:EXTRACTED (1.0)、INFERRED (0.6-0.9)、AMBIGUOUS (0.1-0.3)。每一條邊都標記咗來源,可以審計、可以追溯。 特別值得留意嘅係 Leiden 社區發現算法 嘅應用。Graphify 特登冇用向量數據庫同餘弦相似度呢類「泛語義匹配」,而係揀咗基於圖拓撲嘅社區檢測——佢根據節點之間嘅 邊密度 嚟發現自然聚類。圖結構本身就係相似性信號——唔需要另外做 embedding 步驟。 ··· 三、深層對比:兩種知識觀嘅哲學根源呢兩套體系嘅分歧,本質上係電腦科學入面符號主義 (Symbolic AI)同埋連接主義 (Connectionist AI)爭論咗幾十年嘅延續。 一個直覺啲嘅比喻:本體論係城市規劃圖——喺起之前就精確定義好晒每條路、每個區域嘅功能。LLM Wiki 係自然生長嘅村落——居民 (實體) 自發聚居,慢慢形成集市、廣場同埋小徑。 前者精確但係僵化,後者靈活但係混亂。一個成熟嘅城市,通常兩樣都有齊。 ··· 四、融合方案:等 LLM 做苦力,等本體做風控真正嘅工程突破唔係喺兩者揀其一,而係喺設計兩者之間嘅接口協議。喺我哋最近構建 Neo4j 本體管理系統嘅實踐入面,已經驗證咗一種分層融合架構。 第一層:本體骨架層 喺 Neo4j 入面預先定義核心業務嘅元數據字典。例如: 第二層:LLM 抽取層 行 Graphify 風格嘅流水線,自動掃描 Confluence、JIRA Comment、PR Review、Error Log 等等。LLM 抽取返嚟嘅關係全部都一定要映射返去本體骨架層預設嘅關係類型入面。如果 LLM 發現咗一種本體入面冇嘅新關係類型,佢唔可以直接寫入圖數據庫,而係要放喺一個Staging Area (暫存區),等人類去審核。 第三層:置信度審計層 所有由 LLM 生成嘅邊 (Edge) 都會帶住 Graphify 式嘅三級置信度標籤:EXTRACTED (1.0) 嚟自 AST 確定性解析,INFERRED (0.6-0.9) 嚟自 LLM 語義推理,AMBIGUOUS (0.1-0.3) 嚟自 LLM 嘅低確信度估計。業務查詢嗰陣可以按置信度過濾——合規場景只睇 EXTRACTED + INFERRED 閾值以上嘅邊,探索性分析就可以放寬到睇晒全部。 呢三層架構嘅關鍵設計在於:本體提供寫入約束 (Write Constraint),LLM 提供讀取發現 (Read Discovery)。 💻 Cypher 查詢示例:帶置信度過濾嘅架構探索 ··· 五、開放世界假設同埋封閉世界假設呢度有一個好容易俾人忽略、但係極之關鍵嘅理論層面問題:本體論同 LLM Wiki 對世界嘅基本假設係唔同嘅。 🔒 封閉世界假設 (CWA) 傳統數據庫 (包括大部分 Neo4j 嘅用法) 都係跟 CWA:如果一個事實唔喺數據庫入面,就當佢係假嘅。如果圖入面冇「模組 A 依賴模組 B」呢條邊,就預設佢哋係冇依賴關係。喺業務系統入面咁樣係好合理嘅——冇記錄到嘅權限就即係冇權限。 🌍 開放世界假設 (OWA) OWL 本體論同 LLM Wiki 都係跟 OWA:如果一個事實唔喺知識庫入面,只可以話係「唔知」,唔可以話「唔係」。LLM 抽取返嚟嘅關係可能唔完整,但唔代表現實中呢啲關係唔存在。呢點正正就係 Graphify 嘅置信度模型同埋「暫存區」設計哲學嘅根基。 融合架構嘅設計秘訣在於:業務規則層用 CWA (未授權即係禁止),知識發現層用 OWA (未發現唔代表唔存在)。兩個假設共存喺同一個圖數據庫入面,通過置信度閾值同埋關係類型嚟區分。 2 ≠ 1 兩種世界觀喺同一個圖入面共存,通過置信度閾值嚟分割邊界 ··· 六、面向智能體時代嘅知識架構當視角拉高到 AI Agent 嘅層面,呢套融合架構嘅戰略價值就更加清晰喇: 🤖 智能體需要啲咩樣嘅知識庫? ① 精確嘅業務規則——智能體執行審批流嗰陣,絕對唔可以幻覺出一個唔存在嘅審批節點。呢樣嘢需要本體論嘅形式化約束。 ② 豐富嘅上下文關聯——智能體回答「點解今次測試失敗咗」嗰陣,需要知道「測試模組 X 依賴嘅底盤通信庫喺尋日被重構咗」。呢種隱性關聯只有靠 LLM 抽取先可以高效捕獲。 ③ 可審計嘅推理鏈——每一條推薦或者決策都可以追溯返去原始證據。Graphify 嘅置信度標籤 + 本體公理嘅推理軌跡,共同構成咗一條完整嘅可解釋性鏈路。 呢三個需求,單獨靠本體論或者單獨靠 LLM Wiki 都無辦法同時滿足。只有分層融合,先可以做到既唔會幻覺、又唔會僵化。 最終嘅架構畫面係:Neo4j 圖數據庫作為統一存儲層,OWL 約束作為寫入時嘅 Schema Validator,Graphify 流水線作為持續運行嘅知識注入引擎,Leiden 社區檢測定期重新發現模塊邊界,智能體通過 Cypher 查詢結合自然語言理解嚟服務上層業務。 純大模型太飄,純本體論太攰。三層融合先至係智能體時代嘅最終解法。 架構層一 本體骨架層 → 定義「允許啲咩」 架構層二 LLM 抽取層 → 發現「存在啲咩」 架構層三 置信度審計層 → 量化「確信幾分」 統一運行時 Neo4j 圖數據庫 + 智能體查詢接口 📝 總結 ① Karpathy 嘅 LLM Wiki 唔係要取代本體論,而係佢最好嘅互補。 ② 置信度標籤係雙方對接嘅接口協議。 ③ 下一代企業知識庫 = 本體骨架 + LLM 抽取 + 置信度審計。 📚 延伸閱讀 Karpathy 嘅 LLM Wiki——當 AI 成為你嘅知識管家 — 完 — |
📖 前置閲讀 Graphify:把 Karpathy 的 LLM Wiki 從理念變成了產品介紹了Graphify如何將Karpathy的知識編譯理念工程化。本篇將從“本體論”的視角審視LLM Wiki,並給出分層融合的架構方案。 ··· 一、本體論:知識世界的憲法在哲學中,“本體論”(Ontology)研究的是“存在”本身——什麼東西是真實的?事物的本質是什麼?它們之間有何種關係? 在計算機科學中,這個概念被Tom Gruber在1993年精煉為一句經典定義: “本體論是對一個共享概念體系的 — Tom Gruber, 1993 翻譯成人話就是:在寫任何代碼之前,先像制定憲法一樣,明確定義這個領域裏有哪些“概念”(Class),它們有什麼“屬性”(Property),概念之間允許什麼“關係”(Relation),以及什麼推理規則是合法的。 這套理論落地後就是OWL(Web Ontology Language),它的底層是Description Logic(描述邏輯)——一種專門為知識表示設計的形式邏輯。 💻 OWL描述邏輯示例 關鍵優勢在於:OWL配合推理器(如Pellet、HermiT)可以自動發現隱含知識。只需要定義規則,推理器就能幫你檢查一致性、推導新的事實。這在合規場景中至關重要。 但它的致命弱點也很明顯: ❌ 知識獲取瓶頸(Knowledge Acquisition Bottleneck) 構建和維護一個精確的OWL本體需要領域專家+本體工程師的大量手工勞動。現實中團隊往往等不起。 ❌ 脆弱性(Brittleness) 任何不在預定義Schema中的新概念都是“看不見”的。當代碼庫快速變化時,本體永遠在追趕現實。 簡單來說:本體論精確但昂貴,完美但僵化。 ··· 二、LLM Wiki:知識世界的進化論Karpathy提出的LLM Wiki完全走向了另一個極端。核心理念用一句話概括: “Obsidian是IDE,LLM是Programmer, — Andrej Karpathy, 2026 把知識當作一個“代碼庫”來管理。原始文檔(論文、代碼、會議記錄)是“源文件”,大模型是“編譯器”,輸出的結構化Wiki是“編譯產物”。這個過程Karpathy稱之為Knowledge Compilation(知識編譯)。 開源項目Graphify把這套理念做成了工程化實現,其7階段流水線如下: 💻 Graphify處理流水線 這套流水線中最精妙的是Stage 2的混合抽取策略: 🌳 tree-sitter:確定性的骨架 對代碼文件使用tree-sitter進行AST解析。這一步不調用任何LLM,不消耗任何token,運行在本地,產出的函數調用關係、類繼承層級、模塊導入等都是100%確定性的。 🧠 LLM子代理:語義的血肉 對文檔和圖片使用Claude子代理做並行語義抽取。產出帶有置信度標籤:EXTRACTED(1.0)、INFERRED(0.6-0.9)、AMBIGUOUS(0.1-0.3)。每條邊都標記了來源,可審計、可追溯。 特別值得注意的是Leiden社區發現算法的使用。Graphify刻意沒有使用向量數據庫和餘弦相似度這種“泛語義匹配”,而是選擇了基於圖拓撲的社區檢測——它根據節點間的邊密度來發現自然聚類。圖結構本身就是相似性信號——不需要單獨的embedding步驟。 ··· 三、深層對比:兩種知識觀的哲學根源這兩套體系的分歧,本質上是計算機科學中符號主義(Symbolic AI)和連接主義(Connectionist AI)數十年爭論的延續。 一個直覺性的比喻:本體論是城市規劃圖——在建造之前就精確定義了每條道路、每個區域的功能。LLM Wiki是自然生長的村落——居民(實體)自發聚居,逐漸形成集市、廣場和小徑。 前者精確但僵化,後者靈活但混亂。一個成熟的城市,往往兩者兼具。 ··· 四、融合方案:讓LLM做苦力,讓本體做風控真正的工程突破不在於選擇其中一種,而在於設計二者的接口協議。在我們最近構建的Neo4j本體管理系統的實踐中,已經驗證了一種分層融合架構。 第一層:本體骨架層 在Neo4j中預定義核心業務元數據字典。例如: 第二層:LLM抽取層 運行Graphify風格的流水線,自動掃描Confluence、JIRA Comment、PR Review、錯誤日誌等。LLM抽取出的關係都必須映射到本體骨架層預定義的關係類型中。如果LLM發現了一種本體中不存在的新關係類型,它不能直接寫入圖數據庫,而是將其放入一個Staging Area(暫存區),等待人類審核。 第三層:置信度審計層 所有LLM生成的邊都攜帶Graphify式的三級置信度標籤:EXTRACTED(1.0)來自AST確定性解析,INFERRED(0.6-0.9)來自LLM語義推理,AMBIGUOUS(0.1-0.3)來自LLM的低確信度猜測。業務查詢時可以按置信度過濾——合規場景只看EXTRACTED+INFERRED閾值以上的邊,探索性分析可以放寬到全部。 這三層架構的關鍵設計在於:本體提供寫入約束(Write Constraint),LLM提供讀取發現(Read Discovery)。 💻 Cypher查詢示例:帶置信度過濾的架構探索 ··· 五、開放世界假設與封閉世界假設這裏有一個容易被忽略但極其關鍵的理論層面的問題:本體論和LLM Wiki對世界的基本假設不同。 🔒 封閉世界假設(CWA) 傳統數據庫(包括大多數Neo4j用法)遵循CWA:如果一個事實不在數據庫中,則認為它是假的。如果圖中沒有“模塊A依賴模塊B”這條邊,就默認它們不依賴。在業務系統中這很合理——未記錄的權限就是沒有權限。 🌍 開放世界假設(OWA) OWL本體論和LLM Wiki都遵循OWA:如果一個事實不在知識庫中,只能說“不知道”,不能說“不是”。LLM抽取出的關係可能不完整,但不代表現實中這些關係不存在。這正是Graphify的置信度模型和“暫存區”設計哲學的根基。 融合架構的設計訣竅在於:業務規則層用CWA(未授權即禁止),知識發現層用OWA(未發現不代表不存在)。兩個假設共存於同一個圖數據庫中,通過置信度閾值和關係類型來區分。 2 ≠ 1 兩種世界觀在同一個圖裏共存,通過置信度閾值分割邊界 ··· 六、面向智能體時代的知識架構當視角拉高到AI Agent的層面,這套融合架構的戰略價值就更清晰了: 🤖 智能體需要什麼樣的知識庫? ① 精確的業務規則——智能體執行審批流時,絕不能幻覺出一個不存在的審批節點。這需要本體論的形式化約束。 ② 豐富的上下文關聯——智能體回答“為什麼這次測試失敗了”時,需要知道“測試模塊X依賴的底盤通信庫在昨天被重構了”。這種隱性關聯只有LLM抽取才能高效捕獲。 ③ 可審計的推理鏈——每條推薦或決策都能追溯到原始證據。Graphify的置信度標籤+本體公理的推理軌跡,共同構成了一條完整的可解釋性鏈路。 這三個需求,單獨靠本體論或單獨靠LLM Wiki都無法同時滿足。只有分層融合,才能做到既不幻覺、又不僵化。 最終的架構畫面是:Neo4j圖數據庫作為統一存儲層,OWL約束作為寫入時的Schema Validator,Graphify流水線作為持續運行的知識注入引擎,Leiden社區檢測定期重新發現模塊邊界,智能體通過Cypher查詢結合自然語言理解來服務上層業務。 純大模型太飄,純本體論太累。三層融合才是智能體時代的最終解法。 架構層一 本體骨架層 → 定義“允許什麼” 架構層二 LLM抽取層 → 發現“存在什麼” 架構層三 置信度審計層 → 量化“確信幾分” 統一運行時 Neo4j圖數據庫 + 智能體查詢接口 📝 總結 ① Karpathy的LLM Wiki不是對本體論的替代,而是它最好的互補。 ② 置信度標籤是雙方對接的接口協議。 ③ 下一代企業知識庫 = 本體骨架 + LLM抽取 + 置信度審計。 📚 延伸閲讀 Karpathy 的 LLM Wiki——當 AI 成為你的知識管家 — END — |