怎麼讓 Agent Skills 自進化?Agent 回答質量翻倍
整理版優先睇
通過目標驅動同多路並行測試,令 Agent Skills 實現自進化,穩定產出高質量結果
呢篇文章係作者分享佢用一套新方法訓練 Agent Skills 嘅經驗。佢本身遇到嘅問題係:每次調校一個 Skill 都要花幾個鐘,逐輪同 Agent 對話,效率好低。佢想做到「我想一次,Agent 自己試十次」,所以提出咗一個名為 Skills 自進化嘅流程。
方法嘅核心係:畀 Agent 一個明確嘅目標同一個已被驗證嘅好答案(叫靶子),然後由主 Agent 負責睇結果似唔似靶子,再由 Agent Team 同時試多條唔同嘅路徑(例如改關鍵詞、改表達、對照靶子找出差距)。人唔再逐句問,而係畀 Agent 自己跑多輪,直至接近靶子。最後,唔係將答案塞返入 Skill,而係將跑對嘅方法寫返入去,令下次會更準。
整體結論係:呢套方法可以令 Skills 越用越準,但唔可以完全放手,因為 Skills 有機會膨脹,人要做過程監督,揀選值得保留嘅規則。文章用標題點擊率由 8% 升到 13% 做驗證,證實方法有效。
- 結論:通過目標驅動同多路並行測試,Agent Skills 可以自我進化,提升輸出質量
- 方法:設定靶子(好答案)同 Goal,由主 Agent 判斷差距,Agent Team 多路試錯
- 差異:以前係人逐句改,Agent 停滯;而家一次由 Agent 試多條路,效率大增
- 啟發:訓練 Skills 唔係俾答案,而係訓練佢靠近好結果嘅方法,方法要寫返入 Skill
- 可行動點:喺 Codex 或 Claude Code 用 /goal 開頭,配合靶子同循環規則,人最後審核方法
由人逐句改變為 Agent 自試多路
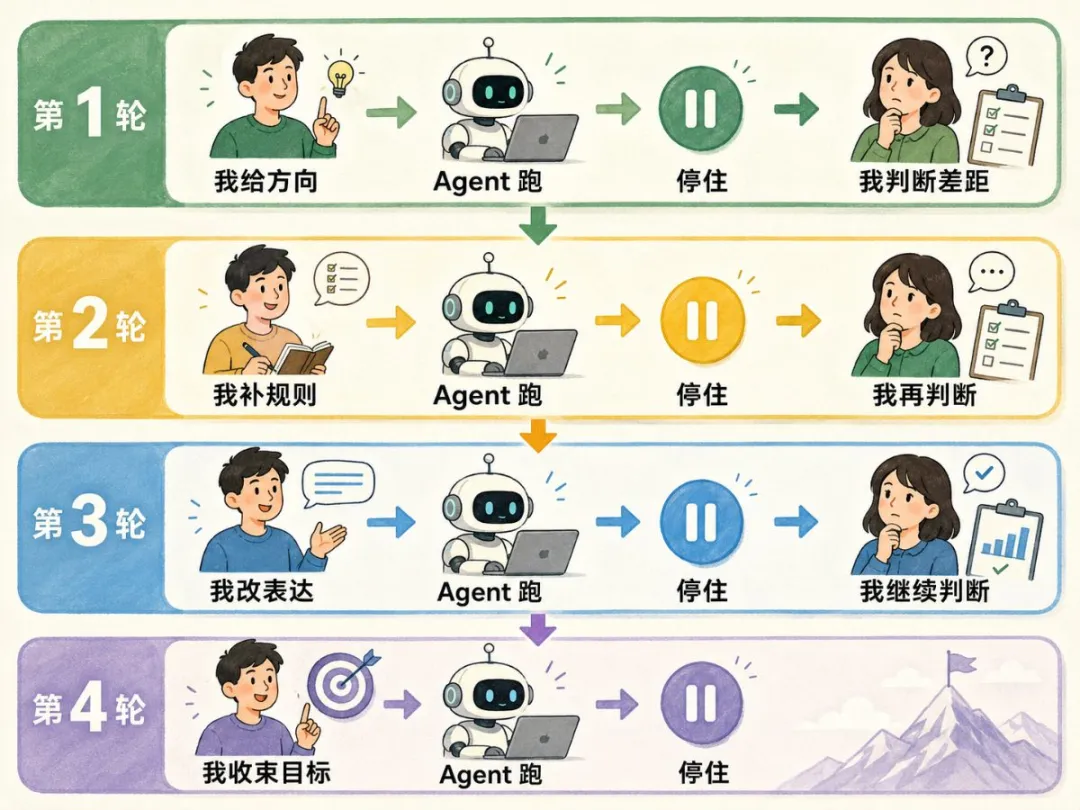
以前調一個 Skill,要逐輪同 Agent 對話:畀素材,佢跑結果;唔滿意,再補一句,佢再跑。呢個循環好慢,因為係 單線,一輪只試一條路,仲要成日停低等人接手。
作者換咗問題:由「點樣改好呢個 Skill」變成「點樣想一次,叫 Agent 自己試十次」
呢個問題一換,方法就唔同咗。唔再一輪一輪推 Agent,而係畀佢一個目標,叫佢圍住呢個目標自己跑。
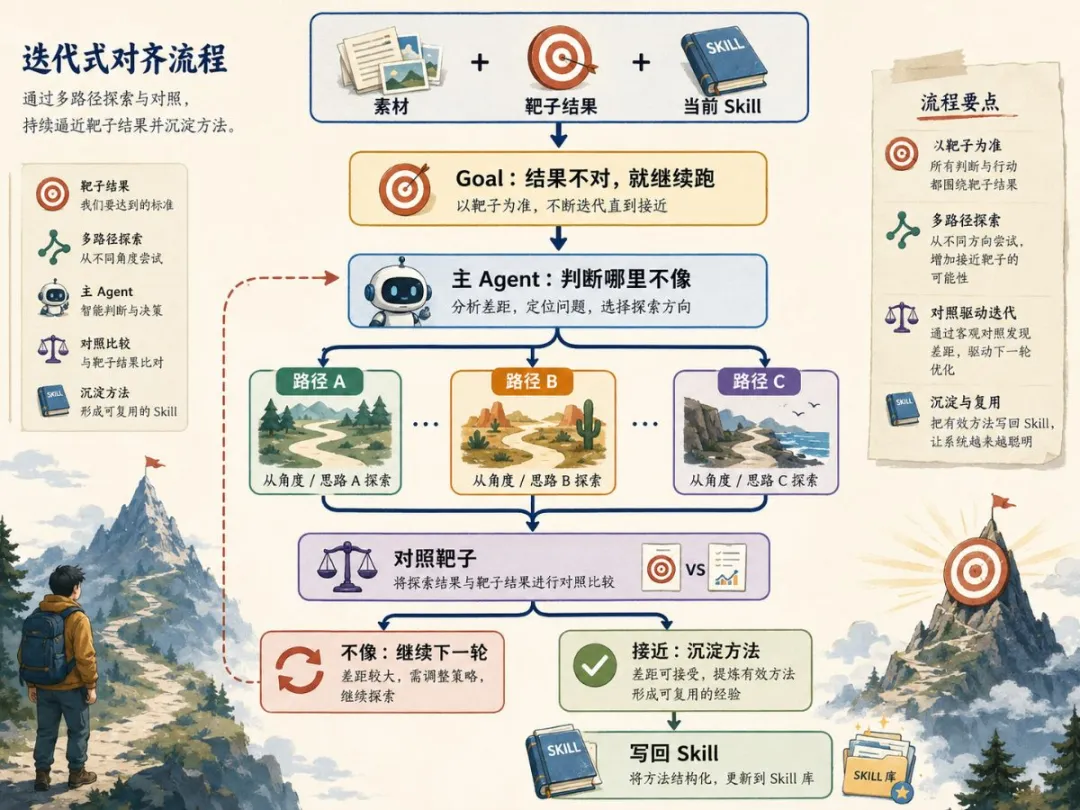
三層結構:靶子、主 Agent 同 Agent Team
整個方法分三層:靶子係已經被驗證過嘅好答案,例如一個高點擊標題;主 Agent負責睇結果似唔似靶子,同決定下一輪要試邊度;Agent Team就同時由唔同方向去試,例如改關鍵詞、改表達、對照靶子找差距。
- 靶子:一個具體、可對照嘅好結果,畀 Agent 一個接近標準
- 主 Agent:每輪判斷兩件事——有冇接近靶子?差距喺邊度?
- Agent Team:由模型決定點樣拆路徑,多路並行測試
關鍵係 訓練線索 要準。人畀線索可能更準,但太慢;而家主 Agent 會先拆出一組線索,例如關鍵詞偏咗喺邊、表達結構差喺邊、靶子入面邊啲嘢必須保留,然後 Agent Team 攞住呢啲線索去試,咁樣發散先唔會散掉。
實測驗證同寫回方法
作者用標題 Skill 做測試。畀咗文章素材同一個已知高點擊標題做靶子,但冇俾答案。主 Agent 自己規劃點測:先拆線索,再叫 Agent Team 由唔同路徑試,試完對照靶子。關鍵詞唔夠就拆細啲,表達唔夠似就繼續從結構、語氣、點擊動機去試。最後跑出嚟嘅標題,關鍵詞接近、表達結構接近、點擊結果都接近。
最易搞錯嘅位:唔係將個高點擊標題塞返入 Skill,而係將跑對嘅方法寫返入去
寫返入 Skill 嘅係方法,例如「關鍵詞要點樣靠近」「表達結構要保留邊啲元素」「跑偏嘅規則要刪除或降級」。下次再跑,佢就唔係由零開始,而係由上一次判斷過嘅地方繼續,呢個就係 Skills 自進化。
實際操作同風險管理
喺 Codex 或 Claude Code 入面,可以用 /goal 開頭。作者常用嘅輸入格式如下:
/goal
目標:用當前素材,把某個 Skill 調到能穩定產出接近靶子的結果。
主 Agent 評判:每輪只判斷兩件事:是否達標,差距在哪裡。
Agent Team 批量測試:由模型自己決定怎麼拆分路徑、調用多個 Agent 測試,並把結果交給主 Agent 對照。
循環規則:沒達標就繼續測試,達標後停止。
最終輸出:可寫回 Skill 的方法論 + 應該刪除或降級的規則。呢套方法啱用喺有靶子嘅 Skills,例如標題、開頭、大綱、正文。如果任務本身冇明確對照,就好難訓練。
- 風險一:冇靶子嘅任務難以訓練
- 風險二:Skills 膨脹,寫入太多無用規則
- 風險三:人唔可以完全退出,要 oversee 過程
作者最後總結:以前寫 Skills 似寫說明書,而家訓練 Skills 似畀 Agent 一個訓練場。有效嘅方法留低,Skills 就越用越準。
呢個方法,我叫佢 Skills 自進化。
佢有啲似大模型嘅強化學習。分別係,我冇訓練模型參數,我訓練嘅係 Skill 嘅執行方式。
以前我調一個 Skill,成日要搞幾個鐘。而家俾個目標佢,十幾分鍾就可以跑出一版接近可用嘅結果。
嗰次高點擊標題只係第一次驗證。更大嘅變化係:Skill 開始記住點樣靠近好結果。
Skill 寫完,唔等於跑得準
Skill 寫完,唔代表佢每次都可以跑出我想要嘅結果。尤其係標題、開頭、大綱、正文呢類任務,我俾一份素材佢,佢會俾一個結果我。
但呢個結果好多時爭少少。關鍵詞可能偏咗,表達可能太平,方向都可能俾佢偷偷改咗。
所以 Skill 需要調校。
以前嘅調法好似手動改稿。我俾素材,佢跑結果;結果唔滿意,我再補一句,佢再跑一版。

呢個循環睇落都係訓練,但佢有兩個地方好慢。
第一,佢係單線。我問一句,佢答一句。一輪只試一條路,呢條路唔啱,就要等我重新判斷。
第二,佢會停。結果唔啱,佢會停;方向唔清,佢都會停。中間任何一步斷咗,都要我接手。
模型生成本身唔慢,慢嘅係呢種除錯方式。佢一路卡喺「我問一句,佢答一句」裏面。
我想一次,Agent 試十次
一開始我想嘅係:
我怎麼把這個 Skill 改好?
後來我轉咗另一個問題:
能不能我想一次,讓 Agent 自己試十次?
呢個問題一轉,方法就變咗。我唔再一輪一輪推佢,而係俾個目標佢,等佢圍住呢個目標自己跑。
我先俾個靶佢。靶就係已經俾結果驗證過嘅好答案,例如一個點擊率更高嘅標題,佢俾 Agent 一個接近嘅標準。
然後用 Goal 將任務掛住。結果冇接近,就繼續跑,唔好跑一版就停喺度等我。
呢度先講清楚 Agent Team。佢唔係一羣 Agent 各自寫各自嘅,你可以理解成:主 Agent 一次叫幾個小 Agent 去試唔同嘅改法。
主 Agent 就係當前負責 Goal 嗰個 Agent。佢負責睇結果似唔似靶,亦負責決定下一輪要試邊度,呢啲「下一輪要試邊度」,就係我講嘅訓練線索。
再等 Agent Team 喺同一輪裏面試多條路。有啲路改關鍵詞,有啲路改表達,有啲路對照高點擊標題,有啲路專門揾差距。
多跑唔夠,線索要準
準確率唔係來自多跑幾版。Agent Team 如果只係多跑幾版,結果只會更熱鬧,唔一定更準。
以前都可以由人嚟俾線索,例如我判斷關鍵詞偏咗,表達結構唔啱,或者靶裏面某個嘢一定要保留。
人俾線索可能好準,但問題係太慢,我每次只可以諗到幾條,再一條條交俾 Agent 試。
而家呢一層交俾主 Agent。佢會先俾出一組訓練線索:關鍵詞可能偏喺邊度,表達結構差喺邊度,靶裏面邊啲嘢一定要保留,邊啲規則可能會帶偏結果。
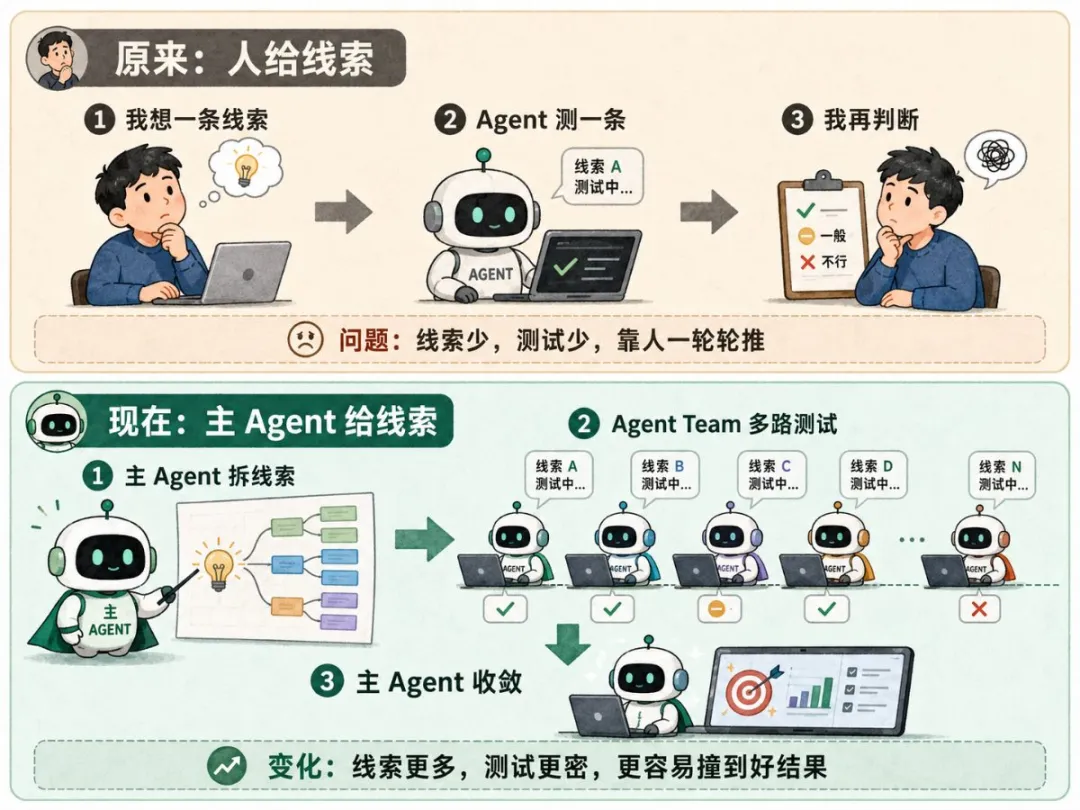
Agent Team 攞住呢啲線索去試,發散先唔會散開。呢度嘅變化唔係「人唔俾線索」,而係「線索生產都交俾 Agent 跑起嚟」。
人俾線索,可能更準。Agent 俾線索,效率更高,可以試得更多。測試路徑一多,命中好結果嘅概率亦會變高。
主 Agent 只做兩件事:
有沒有接近靶子?
差距到底在哪裏?
唔似,就繼續試。接近咗,就停低總結方法。
8% 到 13%,先用標題驗證
我第一次攞嚟試嘅,係標題 Skill。我俾文章素材佢,亦俾一個已經驗證過嘅高點擊標題做靶,但我冇將答案話俾佢知。
我只俾一個目標佢:
把這個標題 Skill 調到能穩定跑出接近靶子的標題。
接下來就唔係我一句一句推喇。主 Agent 會自己規劃點樣測:佢會先拆出一組訓練線索,再叫 Agent Team 由唔同路徑去試,試完一輪,主 Agent 再將結果攞返嚟對照靶。
關鍵詞冇捉到,就將關鍵詞線索拆得更細;表達唔夠似,就叫 Agent Team 繼續由結構、語氣、點擊動機呢啲方向去試;結果接近咗,就停低總結。
呢個過程最似訓練。佢一輪一輪試,一輪一輪睇,一輪一輪靠近,答案只係最後浮出嚟嘅嘢。
最後跑出嚟嘅標題,唔一定每個詞都一樣,但關鍵詞接近,表達結構接近,點擊結果都接近。
咁就夠喇。
我要訓練嘅係 Skill 靠近好標題嘅方式,某個標題只係驗證結果。
寫返入 Skill 嘅唔係答案,係方法
呢度最易搞錯。嗰個高點擊標題唔會塞返入 Skill,下一篇文章點可能仲用同一個標題。
要寫返去嘅係方法。
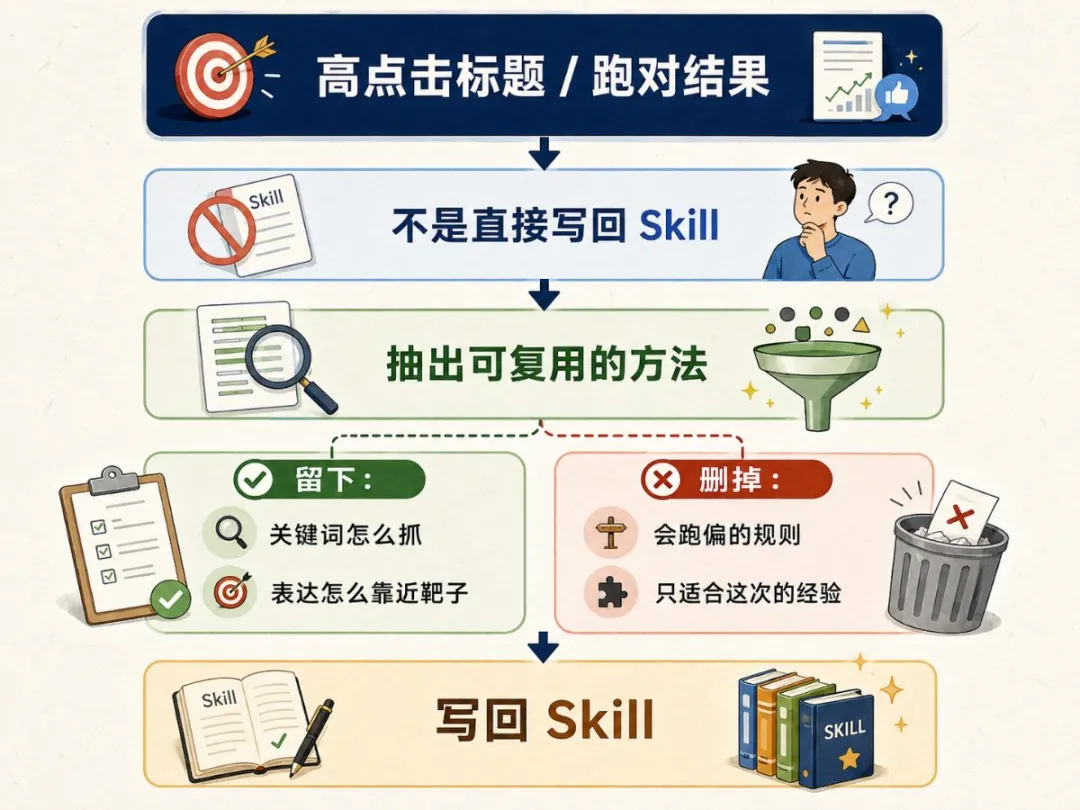
寫返入 Skill 嘅,係跑出呢類答案嘅方法。跑啱嘅路徑留低,跑偏嘅規則刪除或者降級。
下一次再跑,佢就唔係由零開始,而係由上一次判斷過嘅地方繼續跑。
呢個就係 Skills 自進化。
Goal 令任務唔好半路停
如果喺 Codex 裏面,可以直接用 /goal 開頭。Codex 嘅問題係入口唔明顯:你輸入 /goal,唔會彈出表單,亦唔會提你下一步要填咩。
Claude Code 裏面更自然。Goal 默認開咗,你俾個明確目標佢,佢就會圍住目標持續推進。
我而家常見嘅輸入格式係:
/goal
目標:用當前素材,把某個 Skill 調到能穩定產出接近靶子的結果。
主 Agent 評判:每輪只判斷兩件事:是否達標,差距在哪裏。
Agent Team 批量測試:由模型自己決定怎麼拆分路徑、調用多個 Agent 測試,並把結果交給主 Agent 對照。
循環規則:沒達標就繼續測試,達標後停止。
最終輸出:可寫回 Skill 的方法論 + 應該刪除或降級的規則。
呢段輸入嘅作用,係將目標、判斷、測試、循環同寫返去一次過講清楚,等主 Agent 唔好跑散。
人唔需要預先規定每個 Agent 嘅職位,人只要俾目標、俾靶、睇結果。Agent 負責多路試錯,主 Agent 負責收斂判斷,人負責最後審核:邊啲方法值得寫返去,邊啲規則應該刪走。
自進化唔係放手唔理
呢套方法適合有靶嘅 Skills,好似標題、開頭、大綱、正文。呢啲任務可以對照結果,似唔似,準唔準,仲可唔可以改,都可以判斷。
如果任務本身冇靶,就好難訓練。
仲有一個風險係 Skills 會膨脹。Agent 好容易將所有經驗都寫曬入去,寫得越多,唔一定越準。
有啲經驗只適合今次,有啲規則會重複,有啲規則仲會帶偏下一次,所以人唔可以完全退出,人要做過程監督。
應該保留嘅方法保留,應該刪嘅規則刪走,應該降級嘅經驗降級。
我而家對 Skills 嘅理解都變咗。以前寫 Skills,似寫一份說明書;而家訓練 Skills,似俾 Agent 一個訓練場。
佢不斷試,我不斷睇。有效嘅方法留低,Skills 就會越用越準。
這個方法,我叫它 Skills 自進化。
它有點像大模型的強化學習。區別是,我沒有訓練模型參數,我訓練的是 Skill 的執行方式。
以前我調一個 Skill,經常要花幾個小時。現在給它一個目標,十幾分鍾就能跑出一版接近可用的結果。
那次高點擊標題只是第一次驗證。更大的變化是:Skill 開始記住怎麼靠近好結果。
Skill 寫完,不等於跑準
Skill 寫完,不代表它每次都能跑出我想要的結果。尤其是標題、開頭、大綱、正文這種任務,我給它一份素材,它會給我一個結果。
但這個結果經常差一點。關鍵詞可能偏了,表達可能太平,方向也可能被它偷偷換掉。
所以 Skill 需要被調。
以前的調法很像手動改稿。我給素材,它跑結果;結果不滿意,我再補一句,它再跑一版。
這個循環看起來也在訓練,但它有兩個地方很慢。
第一,它是單線的。我問一句,它答一句。一輪只試一條路,這條路不對,就要等我重新判斷。
第二,它會停。結果不對,它會停;方向不清,它也會停。中間任何一步斷了,都要我接手。
模型生成本身不慢,慢的是這種調試方式。它一直被卡在“我問一句,它答一句”裏面。
我想一次,Agent 試十次
一開始我想的是:
我怎麼把這個 Skill 改好?
後來我換成了另一個問題:
能不能我想一次,讓 Agent 自己試十次?
這個問題一換,方法就變了。我不再一輪一輪推它,而是給它一個目標,讓它圍着這個目標自己跑。
我先給它一個靶子。靶子就是已經被結果驗證過的好答案,比如一個點擊率更高的標題,它給 Agent 一個接近標準。
然後用 Goal 把任務掛住。結果沒接近,就繼續跑,不要跑一版就停下來等我。
這裏先把 Agent Team 說清楚。它不是一羣 Agent 各寫各的,你可以先理解成:主 Agent 一次叫多個小 Agent 去試不同改法。
主 Agent 就是當前負責 Goal 的那個 Agent。它負責看結果像不像靶子,也負責決定下一輪要試哪裏,這些“下一輪要試哪裏”,就是我說的訓練線索。
再讓 Agent Team 在同一輪裏試多條路。有的路改關鍵詞,有的路改表達,有的路對照高點擊標題,有的路專門找差距。
多跑不夠,線索要準
準確率不是來自多跑幾版。Agent Team 如果只是多跑幾版,結果只會更熱鬧,不一定更準。
以前也可以由人來給線索,比如我判斷關鍵詞偏了,表達結構不對,或者靶子裏某個東西必須保留。
人給線索可能很準,但問題是太慢,我每次只能想出幾條,再一條條交給 Agent 測。
現在這一層交給主 Agent。它會先給出一組訓練線索:關鍵詞可能偏在哪裏,表達結構差在哪裏,靶子裏哪些東西必須被保留,哪些規則可能把結果帶偏。
Agent Team 拿着這些線索去試,發散才不會散掉。這裏的變化不是“人不給線索了”,而是“線索生產也交給 Agent 跑起來”。
人給線索,可能更準。Agent 給線索,效率更高,能試得更多。測試路徑一多,命中好結果的概率也會變高。
主 Agent 只做兩件事:
有沒有接近靶子?
差距到底在哪裏?
不像,就繼續試。接近了,就停下來總結方法。
8% 到 13%,先拿標題驗證
我第一次拿來測的,是標題 Skill。我給它文章素材,也給它一個已經驗證過的高點擊標題當靶子,但我沒有把答案告訴它。
我只給它一個目標:
把這個標題 Skill 調到能穩定跑出接近靶子的標題。
接下來就不是我一句一句推了。主 Agent 會自己規劃怎麼測:它會先拆出一組訓練線索,再讓 Agent Team 從不同路徑去試,試完一輪,主 Agent 再把結果拿回來對照靶子。
關鍵詞沒抓住,就把關鍵詞線索拆得更細;表達不夠像,就讓 Agent Team 繼續從結構、語氣、點擊動機這些方向去試;結果接近了,就停下來總結。
這個過程最像訓練。它一輪一輪試,一輪一輪看,一輪一輪靠近,答案只是最後浮出來的東西。
最後跑出來的標題,不一定每個詞都一樣,但關鍵詞接近,表達結構接近,點擊結果也接近。
這就夠了。
我要訓練的是 Skill 靠近好標題的方式,某個標題只是驗證結果。
寫回 Skill 的不是答案,是方法
這裏最容易搞錯。那個高點擊標題不會被塞回 Skill,下一篇文章不可能還用同一個標題。
要寫回去的是方法。
寫回 Skill 的,是跑出這類答案的方法。跑對的路徑留下,跑偏的規則刪除或降級。
下一次再跑,它就不是從零開始,它從上一次判斷過的地方接着跑。
這就是 Skills 自進化。
Goal 讓任務不要半路停
如果在 Codex 裏,可以直接用 /goal 開頭。Codex 的問題是入口不明顯:你輸入 /goal,不會彈出表單,也不會提醒你下一步該填什麼。
Claude Code 裏更自然。Goal 默認開啓,你給它一個明確目標,它就會圍繞目標持續推進。
我現在常用的輸入格式是:
/goal
目標:用當前素材,把某個 Skill 調到能穩定產出接近靶子的結果。
主 Agent 評判:每輪只判斷兩件事:是否達標,差距在哪裏。
Agent Team 批量測試:由模型自己決定怎麼拆分路徑、調用多個 Agent 測試,並把結果交給主 Agent 對照。
循環規則:沒達標就繼續測試,達標後停止。
最終輸出:可寫回 Skill 的方法論 + 應該刪除或降級的規則。
這段輸入的作用,是把目標、判斷、測試、循環和寫回一次說清楚,讓主 Agent 不要跑散。
人不需要提前規定每個 Agent 的職位,人只要給目標、給靶子、看結果。Agent 負責多路試錯,主 Agent 負責收斂判斷,人負責最後審核:哪些方法值得寫回,哪些規則應該刪掉。
自進化不是放手不管
這套方法適合有靶子的 Skills,比如標題、開頭、大綱、正文。這些任務能對照結果,像不像,準不準,能不能繼續改,都能判斷。
如果任務本身沒有靶子,就很難訓練。
還有一個風險是 Skills 會膨脹。Agent 很容易把所有經驗都寫進去,寫得越多,不一定越準。
有些經驗只適合這一次,有些規則會重複,有些規則還會把下一次帶偏,所以人不能完全退出,人要做過程監督。
該留下的方法留下,該刪的規則刪掉,該降級的經驗降級。
我現在對 Skills 的理解也變了。以前寫 Skills,更像寫一份說明書;現在訓練 Skills,更像給 Agent 一個訓練場。
它不斷試,我不斷看。有效的方法留下來,Skills 就會越用越準。