怎麼讓AI這個大冤種,幫我們整理像讀書筆記這樣的素材?
整理版優先睇
用AI幫你分類整理大量讀書筆記,解決上下文限制問題,建立索引機制讓檢索更快更準。
呢篇文章係由一個有1000多本讀書筆記嘅作者分享,佢成日要引用筆記去寫文或者整Anki卡,但筆記太多,靠自己記唔曬,AI檢索又會因為上下文限制而漏嘢。佢想解決嘅問題係:點樣令AI可以高效咁幫佢分類同檢索大量讀書筆記。佢嘅結論係:用Obsidian同步筆記、建立獨立素材倉庫、再用預分類同索引目錄,配合一個特製嘅Skill,就可以令AI好似有個導航地圖咁,逐步揾到所需內容,而家唔使一次過塞曬全部筆記畀AI。
成個流程分四步:第一步,用Weread插件將微信讀書筆記同步到Obsidian;第二步,將筆記抄到另一個專用素材文件夾,避免影響原始同步;第三步,用AI Skill幫你自動分類,按主題歸入不同文件夾;第四步,每個分類文件夾入面再整一個索引目錄同config.md,記錄書名、簡介同路徑,等AI可以精準定位。佢強調呢個係「漸進式加載」嘅思路,好似人腦回憶咁,透過線索一步步揾返所需資料。
最後佢提到呢個Skill已經開源,唔止可以用喺微信讀書,其他素材都得。佢仲預告下次會分享點樣將筆記整成Anki卡片。整個方向係將繁瑣嘅分類檢索交畀AI,自己專注創作同學習。
- 結論:用預分類+索引目錄解決AI上下文限制,實現高效率檢索。
- 方法:先用Obsidian同步微信讀書筆記,再抄到獨立素材庫,用Skill分類建立索引。
- 差異:傳統AI檢索一味曬全部筆記,呢個方法係「漸進式披露」,逐層搜尋。
- 啟發:借鑒人腦回憶嘅線索機制,將大問題拆成細步驟,AI都可以處理複雜任務。
- 可行動點:跟住步驟建立自己嘅素材庫,再用開源Skill自動分類,慳返大量手動時間。
素材整理Skill(mowan-sucai-sort)
開源嘅AI Skill,用於自動分類整理讀書筆記或其它素材,支援索引目錄同config配置。
點解要搞咁大陣仗?
作者有超過1000本讀書筆記,寫文想引用或者整Anki卡嘅時候,靠人腦記憶根本搞唔掂。如果用ima知識庫直接檢索,AI唔知你嘅上下文,會漏咗好多重要資訊。
所以佢要用素材搜索Skill嚟做,但搜之前要先整理好啲筆記。呢篇文章就係講點樣用AI幫手做分類整理,等後續檢索更順。
同步筆記同搬去素材庫
- 1 第一步:用Obsidian嘅Weread插件,可以自動將微信讀書嘅劃線、想法同書本資訊同步到本地,仲可以按年份顯示。
- 2 第二步:將筆記抄到一個獨立文件夾,唔好直接喺原始倉庫鬱手,否則會影響後續同步。建立一個專用素材倉庫,方便AI讀取同整理。
用Trae呢類程式編輯器打開素材文件夾,就可以調用Skill幫手做分類。
預分類+索引機制:AI嘅導航地圖
面對1000本書,AI冇可能一次過load曬所有內容,所以佢借鑑咗漸進式加載嘅概念。即係人腦回憶都要靠線索,例如「邊度睇、幾時睇、用咩睇」,逐步聯想返啲內容。
佢做法係先將所有筆記分門別類,例如個人成長、電腦、心理學等,呢步交畀AI做。每個分類文件夾入面,再建立一個索引文檔,記錄每本書嘅一句話簡介同主要內容。
## 計算機分類
### 索引
- 《兩漢風雲》:歷史類,探討西漢東漢政權更迭
- 《深入理解計算機系統》:系統底層原理
### config
根目錄:C:\xxx\微信讀書筆記和摘錄(截止 26-1-22)呢個機制好似畀AI裝咗高德地圖導航,唔使盲舂舂咁搜,而係跟住索引同config逐步落去,解決曬上下文限制嘅問題。
AI做苦力,你專心創作
分類同檢索呢啲重複性工作,最啱交畀AI呢個大冤種去做。作者已經將呢個素材整理Skill開源,放咗喺GitHub,唔止適用於微信讀書,其他素材都得。
佢仲預告下次會分享點樣用Skill將讀書筆記整成Anki卡片,方便間歇性複習。成個流程嘅目標係將AI融入工作流,解放生產力。
分類和檢索這種活,要是讓我們自己來幹,那可累死人了

Part 01
問題背景
筆記管理 · AI檢索 · 上下文限制
Part 02
同步與遷移
Obsidian插件 · 素材倉庫 · 路徑管理
Part 03
預分類策略
漸進式加載 · 線索檢索 · 自動分類
Part 04
索引機制
目錄文檔 · config配置 · 路徑組合
最後
開源與延伸
Skill倉庫 · Anki卡片 · 工作流融合
我平時冇嘢做就鍾意亂咁睇書,積咗好多讀書筆記。呢啲筆記有兩個幾重要嘅用途:
用途 ① 寫文章嘅時候,可以去引用自己嘅讀書筆記內容 | 用途 ② 將有啟發嘅內容整理成Anki卡片,進行間歇性複習 |
但係如果讀書筆記嘅量好大點算?好似我自己就有 1000 幾本書嘅讀書筆記,寫文章想引用嘅時候,光靠自己個腦嘅記憶肯定唔夠,就需要用 AI 幫手檢索。
但如果用 ima 知識庫呢種方式去檢索,佢會流失好多資訊,唔知我嘅上下文係咩,唔知文章需要揾邊啲資料,所以就要用另一個方法——之前我提過嘅素材搜索Skill嚟做呢件事,但係搜索之前,要先整理好啲素材。
所以,呢篇文章再介紹下:我係點樣叫 AI 幫我將讀書筆記分類整理。
跟住落嚟以微信讀書嘅筆記做例子,簡單介紹下成個流程。
1、將微信讀書筆記同步到 Obsidian
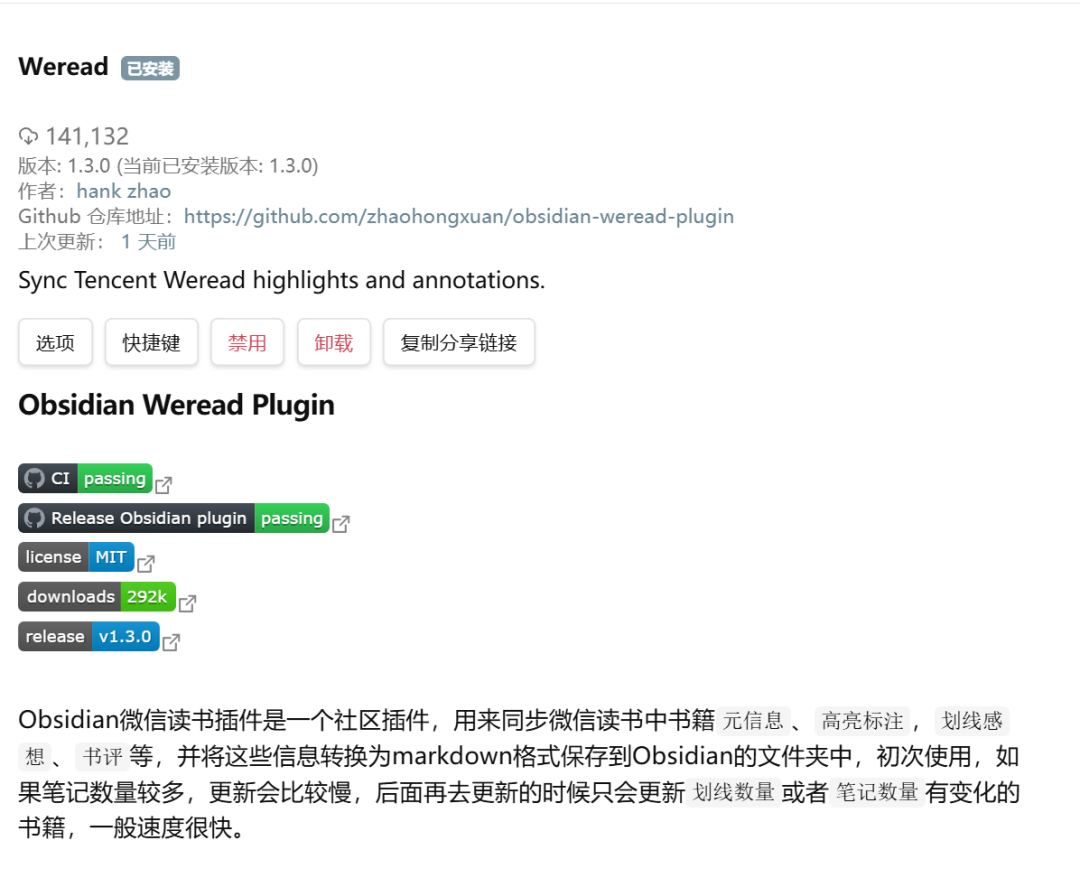
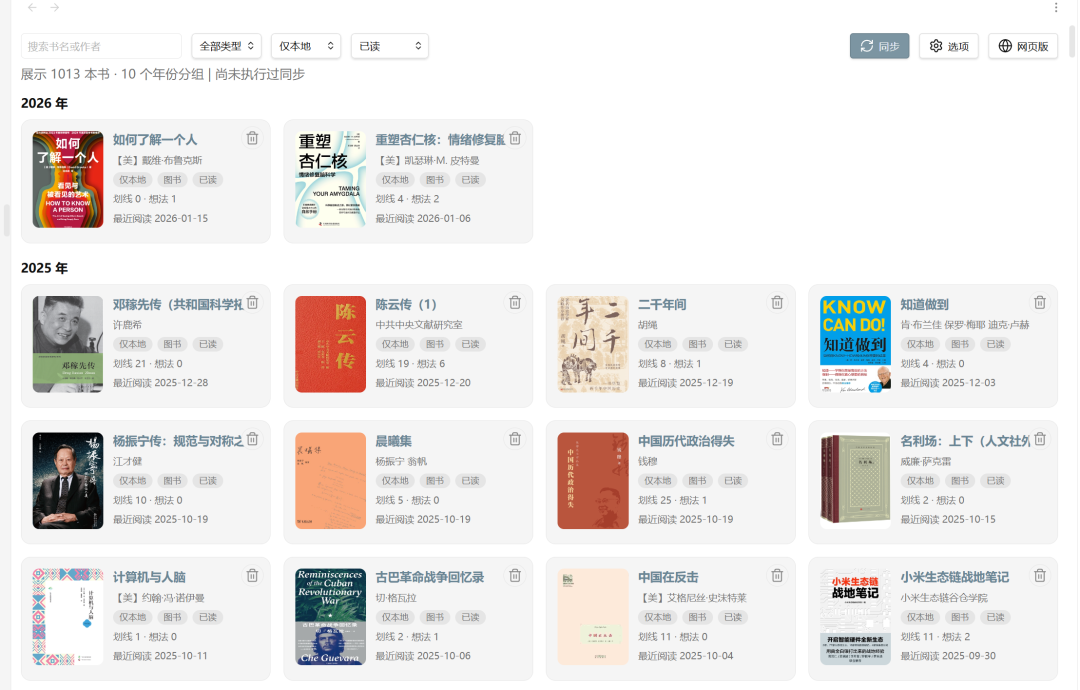
首先,我哋要知道點樣將微信讀書筆記下載到本地,喺 Obsidian 上面有一個好好用嘅插件,可以自動同步微信讀書嘅筆記去 Obsidian 倉庫度,同步完之後,佢可以按年份格式顯示,仲可以自定義設置樣式,每一本書嘅劃線筆記、諗法,佢都同步到,包括本書嘅封面同基本資訊,用起上嚟好方便。
所以做呢件事嘅第一步,就係打開Obsidian嘅社羣插件市場,搜Weread呢個下載微信讀書筆記嘅第三方插件。
 |  |  |
2、將筆記搬去專門嘅素材倉庫
筆記下載到 Obsidian 倉庫之後,我哋可以揾到倉庫所在嘅檔案路徑,作為工作目錄,用Trae呢類編程工具打開,然後叫 Skill 幫我哋分類整理。
注意:原本嘅筆記倉庫係唔鬱得㗎,如果唔係會影響後續微信讀書筆記嘅同步。
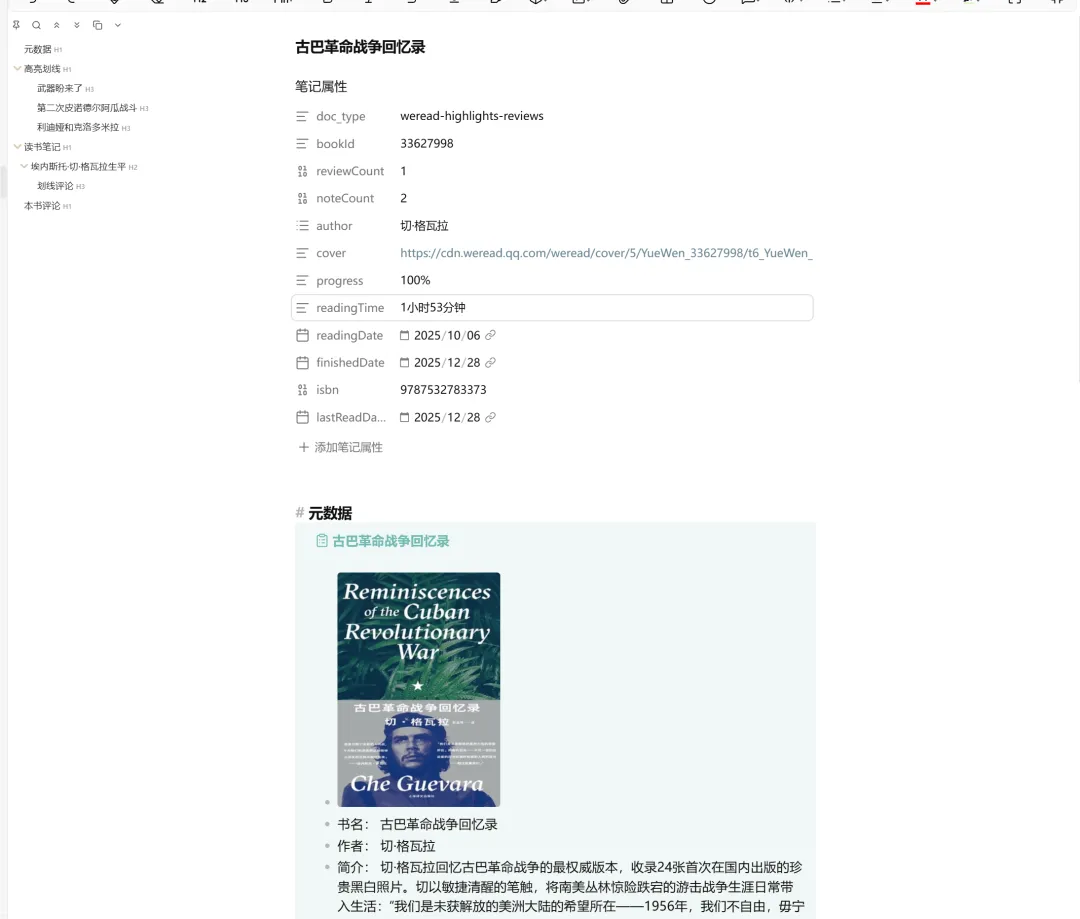
所以要開一個資料夾,專門用嚟放素材,咁樣方便之後叫素材,又可以同原始倉庫分開,好似下面呢張圖,就係我專登開嘅一個資料夾,專門放微信讀書筆記。
3、用 Skill 幫我預分類
但係,而家遇到一個問題:1000 幾本書嘅讀書筆記,將來搜索嗰陣,AI 嘅上下文一定頂唔順。
咁點樣解決?
呢度參考咗漸進式加載嘅思路。
有本經典嘅書叫《追尋記憶的痕跡》,裏面提到,人腦提取記憶係需要線索嘅,例如我突然諗唔起尋晚睇書嘅內容,咁點樣回憶呢?
我就需要用場景聯想,我尋晚係咩時間睇書,喺邊度睇呢?
"哦,大概夜晚十點幾,喺屋企嘅書枱旁邊",咁我又係用咩嘢睇?
"用嘅微信讀書",咁樣一通場景聯想,我就諗起尋晚睇書嘅內容了。
所以,千祈唔好以為漸進式加載呢個詞好難明,其實都係類似嘅思路,跟住線索一步步揾到最終需要嘅嘢,例如我要揾魯迅全集嘅讀書筆記,AI 面對 1000 幾本書,冇可能一次過將所有筆記全部塞入上下文裏面,效率太低而且都做唔到。
佢只能一步步嚟——先帶住"魯迅全集"呢個關鍵詞去資料夾度搜,搜到之後,再睇筆記內容,將結果帶返嚟。
這就是漸進式披露嘅過程。
想叫 AI 跟住線索,一步步揾讀書筆記嘅內容,我哋一定要先將書分類,分成個人成長類、電腦類、心理學類等等。
之後我哋要寫個人成長類嘅文章,AI 就直接去個人成長嘅資料夾度搜就得,分類都係苦差事,呢啲嘢我哋都唔使自己做,交俾我哋嘅 AI 牛馬就得。
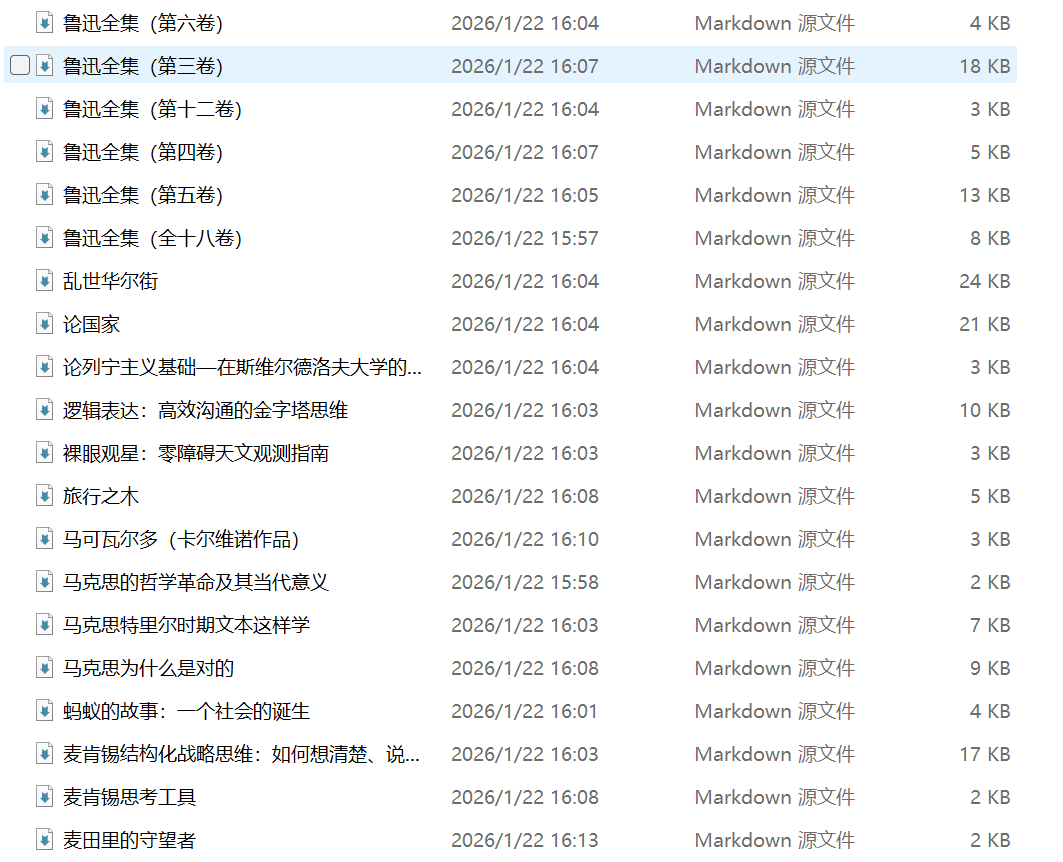
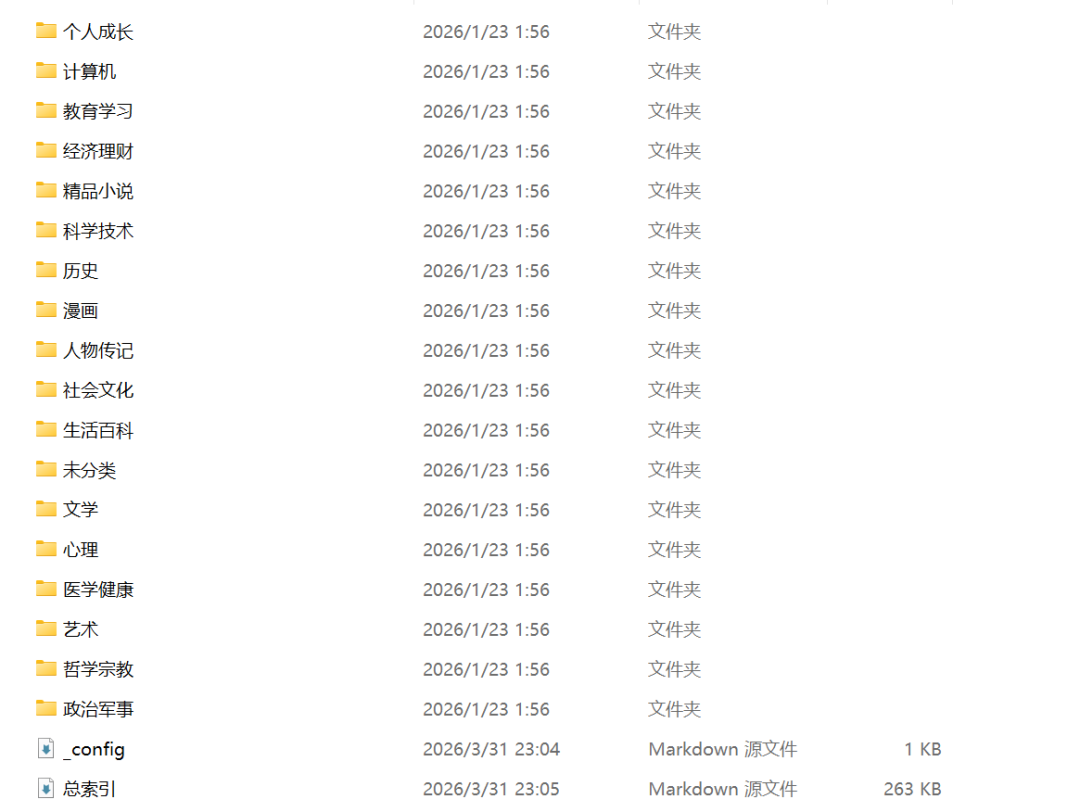
下面呢張圖,就係我叫 AI 幫我將微信讀書筆記做嘅分類。
4、建立索引目錄
有咗分類之後,每個分類資料夾裏面可能仲有幾十本書嘅筆記,AI 揾起上嚟都唔方便。所以要建立一個索引目錄。
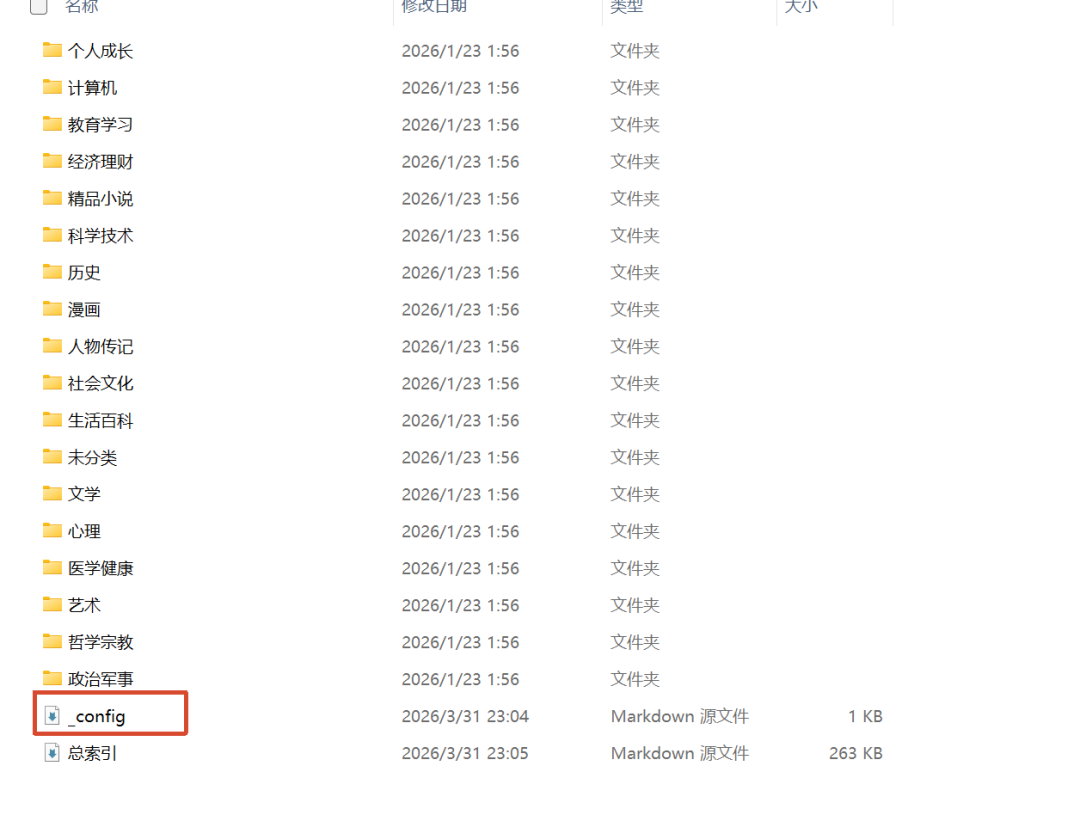
例如,我有個電腦分類資料夾,裏面有一份索引文件,記錄咗資料夾大概有邊啲書,每本書一句話簡介、主要內容係咩。咁樣之後想揾資料嘅時候,AI 就可以先睇索引入面嘅簡介,判斷需要邊啲讀書筆記。
 |  |  |
例如我要查《兩漢風雲》呢本書,Skill 就會根據config.md存嘅根目錄C:\xxx\微信讀書筆記和摘錄(截止 26-1-22),帶住書名一齊組合成完整嘅路徑,去C:\xxx\微信讀書筆記和摘錄(截止 26-1-22)\《兩漢風雲》裏面,精準咁揾到呢本書嘅筆記。
到呢度就完成咗呢個 Skill 最核心嘅部分——建立起微信讀書筆記嘅更新儲存同索引機制。
有咗呢套機制,每次有新筆記,只要將新嘅讀書筆記放入素材庫資料夾,叫素材整理嘅Skill,AI 就會自動識別邊啲更新咗、加咗咩新嘢,自動幫我哋分門別類咁整理。同時有咗索引機制,之後進行素材搜索嘅時候,AI 都可以好好咁識別出對應嘅讀書筆記,等於俾 AI 裝咗個高德地圖導航,知道去邊度揾,唔係亂咁周圍搜,亦都解決咗上下文限制嘅問題。
分類同檢索呢啲嘢,如果叫我哋自己嚟做,真係會累死人,AI 呢啲任勞任怨嘅大冤種,好適合做呢啲嘢,咁樣,我哋就將 AI 融入咗自己嘅工作流程入面。
之後,我再抽時間同大家分享,點樣用 Skill 將讀書筆記整成 Anki 卡片,方便不斷複習同記憶。
哦啱喇,呢個整理微信讀書筆記嘅 Skill 我都開源咗出嚟,放喺我嘅 Skill 倉庫度,俾大家參考,佢唔單止可以整理微信讀書筆記,仲可以整理其他內容。
skill地址
github.com/limowan/mowan-skill/tree/main/mowan-sucai-sort

同你一齊探索 AI 喺生活中嘅有趣用法 🌱
👍 點贊 | 👀 在看 | ➤ 轉發 |
Part 01
問題背景
筆記管理 · AI檢索 · 上下文限制
Part 02
同步與遷移
Obsidian插件 · 素材倉庫 · 路徑管理
Part 03
預分類策略
漸進式加載 · 線索檢索 · 自動分類
Part 04
索引機制
目錄文檔 · config配置 · 路徑組合
Last
開源與延伸
Skill倉庫 · Anki卡片 · 工作流融合
我平時沒事就喜歡瞎看書,積累了非常多的讀書筆記。這些筆記有兩個比較重要的用處:
用處 ① 寫文章的時候,可以去引用自己的讀書筆記內容 | 用處 ② 把有啓發的內容整理成Anki卡片,進行間歇性複習 |
但如果讀書筆記的量非常大怎麼辦呢?比如我自己就有 1000 多本書的讀書筆記,寫文章想引用的時候,光靠自己大腦的記憶肯定不夠,這時候就需要用 AI 來幫忙檢索。
但如果用 ima 知識庫這種方式去檢索,它會丟失非常多的信息,它不知道我的上下文是什麼,不知道文章需要查哪些資料,所以就要用到另一個辦法——之前我提到的素材搜索Skill來做這件事,但搜索之前,得先把素材整理好。
所以,這篇文章再介紹下:我是怎麼讓 AI 幫我把讀書筆記進行分類整理的。
接下來以微信讀書的筆記為例,給大家簡單介紹下整個流程。
1、把微信讀書筆記同步到 Obsidian
首先,我們得知道怎麼把微信讀書筆記下載到本地,在 Obsidian 上有一個非常好用的插件,可以自動同步微信讀書的筆記到 Obsidian 倉庫裏,同步過來後,它可以按照年份格式展示,也可以自定義設置樣式,每本書的劃線筆記、想法,它都能同步過來,包括書的封面和基礎信息,用起來非常方便。
所以做這件事的第一步,就是打開Obsidian的社區插件市場,搜索Weread這個下載微信讀書筆記的第三方插件。
| | |
2、把筆記遷移到專門的素材倉庫
筆記下載到 Obsidian 倉庫之後,我們可以找到倉庫所在的文件路徑,作為工作目錄,用Trae之類的編程工具打開,然後調用 Skill 幫我們分類整理。
注意:原來的筆記倉庫是不能動的,不然會影響後續微信讀書筆記的同步。
所以需要建立個文件夾,作為專門存放素材的地方,既方便後面調用素材,也能和原始倉庫區分開來,比如下面這張圖,就是我專門建的一個文件夾,專門存放微信讀書筆記。
3、用 Skill 幫我預分類
但是,現在面臨一個問題:1000 多本書的讀書筆記,未來搜索的時候,AI 的上下文肯定吃不消。
那怎麼解決?
這裏借鑑了漸進式加載的思路。
有本經典的書叫《追尋記憶的痕跡》,裏面就提到,人腦提取記憶是需要線索的,比如我突然想不起來昨天晚上看書的內容,那怎麼去回憶呢?
我就需要用場景聯想,我昨天晚上是什麼時間看的書,在哪看的呢?
"哦,大概晚上十點多,在家裏的書桌旁",那我又是用什麼看的?
"用的微信讀書",這樣一通場景的聯想,我就想起來昨晚看書的內容了。
所以,別看漸進式加載這個詞很難懂,其實也是類似的思路,按照線索一步步找到最終需要的東西,比如說我要找魯迅全集的讀書筆記,AI 面對 1000 多本書,不可能一次性把所有筆記全部吞進上下文裏,效率太低而且也做不到。
它只能一步一步來——先帶着"魯迅全集"這個關鍵詞去文件夾裏搜,搜到了之後,再查看筆記內容,把結果帶回來。
這就是漸進式披露的過程。
想讓 AI 按照線索,一步步尋找讀書筆記的內容,我們必須先把書分門別類,分成個人成長類、計算機類、心理學類等。
後面我們要寫個人成長類的文章,AI 就直接去個人成長的文件夾裏搜索就好了,分類也是個苦差事,這活我們也不用自己幹,交給我們的AI牛馬就行了。
下面這張圖,就是我讓 AI 幫我把微信讀書筆記做的分類。
4、建立索引目錄
有了分類之後,每個分類文件夾裏可能還有幾十本書的筆記,AI 找起來還是不方便。所以要建立一個索引目錄。
比如,我有個計算機分類文件夾,裏面有份索引文檔,記錄了文件夾裏大概有哪些書,每本書一句話簡介、主要內容是什麼。這樣後面想查資料的時候,AI 就可以先看索引裏的簡介,判斷需要什麼讀書筆記。
| | |
比如說我要查《兩漢風雲》這本書,Skill 就會根據config.md存的根目錄C:\xxx\微信讀書筆記和摘錄(截止 26-1-22),帶着書名一起組合成完整的路徑,到C:\xxx\微信讀書筆記和摘錄(截止 26-1-22)\《兩漢風雲》裏面我,精準的找到這本書的筆記。
到這裏就完成了這個 Skill 最核心的部分——建立起微信讀書筆記的更新存儲和索引機制。
有了這套機制,每次有新筆記,只要把新的讀書筆記放到素材庫文件夾裏,調用素材整理的Skill,AI就會自動識別哪些更新了、新增了什麼,自動幫我們分門別類地整理。同時有了索引機制,後面進行素材搜索的時候,AI也能很好的識別出對應的讀書筆記,相當於給AI裝了個高德地圖導航,知道去哪找,不是漫無目的地瞎搜索,也解決了上下文限制的問題。
分類和檢索這種活,要是讓我們自己來幹,那可累死人了,AI這種任勞任怨的大冤種,很適合來幹這種活,這樣,我們就把AI融入到了自己的工作流中。
在後面,我再抽空給大家分享,怎麼用 Skill 把讀書筆記做成 Anki 卡片,方便不斷複習和記憶。
哦對了,這個整理微信讀書筆記的 Skill 我也開源出來了,放在我的 Skill 倉庫裏,供大家參考,它不光可以整理微信讀書筆記,還可以整理其它的內容。
skill地址
github.com/limowan/mowan-skill/tree/main/mowan-sucai-sort
和你一起探索 AI 在生活中的有趣用法 🌱
👍 點贊 | 👀 在看 | ➤ 轉發 |