我做了一個"動畫 + 口播"的知識演繹技能,扔個主題就能出片
整理版優先睇
用 AI 自動生成技術動畫口播視頻,一個主題幾分鐘出片
呢篇文章係關於 AgentBuff 開發嘅一個叫 animation-explainer 嘅 Claude Code skill,可以將技術概念自動變成帶口播嘅動畫短片。作者本身係一個程式設計師,佢發現文字同靜態圖好難講清「瀏覽器請求底層」呢類概念,於是諗住用 AI 直接生成 HTML 動畫。結果佢用 Claude 做到第一個 demo,發現呢個結構可以重用,就沉澱成一個 skill。
成個開發過程佢踩咗唔少坑:由最初嘅瀏覽器原生 TTS 太生硬,轉用免費嘅 edge-tts 雲希男聲;由固定 setTimeout 切換口播導致話未講完就跳,改為事件驅動;仲有 CSS 嘅 white-space bug 搞到 code block 迫埋一行。每個坑佢都 fix 咗並寫入 SKILL.md 做規則,令到之後嘅主題生成快咗五倍以上。
最後佢用 Playwright 無頭瀏覽器錄製畫面再加 ffmpeg 拼入音軌,幾分鐘就輸出 5MB 嘅 MP4,可以直接發佈。呢套方案嘅核心係單文件 HTML 加零構建,純 SVG 動畫,口播按自然結束切換,並且完全開源。作者相信呢種「動畫 + 解說」係教技術最好嘅方式,而 AI 令到呢種高質內容人人負擔得起。
- AI 可以自動生成帶口播嘅技術動畫視頻,成本接近零,幾分鐘出片。
- 方法:用 Claude Code 加 SKILL.md 沉澱視覺模式,edge-tts 生成口播,Playwright 同 ffmpeg 導出 MP4。
- 相比傳統 motion designer 一日上千,呢個方案免費、快速、可無限重用。
- 啟發:技術可視化教學嘅未來係動畫加解說,而 AI 令呢個變得大眾化。
- 可行動點:安裝 animation-explainer skill 之後,一句話「用 animation-explainer skill 做一個 X 嘅動畫演示」就得。
animation-explainer skill
一個 Claude Code skill,可自動生成技術動畫口播視頻。安裝:npx skills add AgentBuff/animation-explainer
內容結構
輸入: "用 animation-explainer skill 給我做一個 X 的動畫演示" ↓1. Claude 按
SKILL.md 拆 3–8 節,每節配視覺模式 ↓2. 複製 examples/browser-request/index.html 改 SVG / 旁白 / CHAPTERS ↓ 單文件 HTML(含 SVG 動畫 + 旁白文本 + narration 字段)3. node scripts/generate-audio.mjs examples/<topic> ↓ + audio/scene-1~N.mp3 (edge-tts 雲希男聲)4. 瀏覽器打開預覽
- 按口播 onended 驅動切換
- 控件:上/下/播放/暫停/重播/🔊 靜音 + 鍵盤 ←→/Space/R/M ↓ ✅ 人工審核通過5. node scripts/export-video.mjs examples/<topic>
- Playwright headless 錄 WebM
- ffmpeg 拼 mp3 + apad(1.2s) + 1s pre-roll
- mux WebM + 音軌 → MP4 ↓輸出: video.mp4 (~5MB / 2 分鐘),可發任意平台核心成果:一句話出片
AgentBuff 花咗一個晚上,用 Claude 整咗個 8 節帶雲希男聲講解、按口播節奏自動切換嘅技術動畫,最後一行命令就導出咗 5MB 嘅 MP4。佢用兩個主題做咗示範:瀏覽器請求底層之旅同 Vue 3 原理之旅,每個都係真實 SVG 動畫、真實代碼同日誌、雲希男聲口播,效果似足博物館科普影片。
呢條路打通之後,下一個主題——無論係 Vue 原理、Kafka 消息流轉定 Postgres MVCC——只要一句話,幾分鐘就出到完整科普視頻。
最終輸出係 npm run video:vue 就出到 video.mp4,可以直接發微信、抖音、B 站、知乎。
關鍵迭代:踩過的坑同點解
起初只係想做個 demo 講清楚瀏覽器請求底層,但發現文字太抽象,畫圖太靜態。Claude 第一版 HTML 動畫已經令佢驚訝——唔係 PPT 截圖,而係真係播到嘅劇場式演示。佢即刻將呢個模式抽成 SKILL.md,包含骨架、設計 token、5 種視覺模式(實物 mockup / 節點+飛包 / 時序圖 / 流水線 / 結構樹)同「反 AI slop」清單。
第二個主題 Vue 原理,從拆解到出片快咗 5 倍——因為 Claude 唔會每次重新發明輪子。
口播方面,佢試過瀏覽器原生 TTS(太僵硬),之後改用 edge-tts,免費嘅 Neural voice 質量接近商業級。同步問題係最大嘅坑:最初用固定 setTimeout 切換,但口播長度唔固定,經常有口播打斷嘅情況。佢改為 事件驅動,用 speak() 嘅 onEnd 回調,口播自然結束先推進,並加 1.2 秒緩衝。
仲有一個弱智 bug:右側 code block 迫埋一行,原因係 CSS 缺咗 white-space: pre</highlight>。佢修復後將呢條加落 SKILL.md 嘅強制規則,避免下次再踩。技能能夠「自我完善」嘅關鍵就係每踩一個坑就固化做規則,SKILL.md 從 235 行寫到 425 行。
最終架構:單文件 HTML + 零構建
輸入一句「用 animation-explainer skill 做一個 X 嘅動畫演示」,Claude 按 SKILL.md 拆 3–8 節,每節配視覺模式,複製模板改 SVG、旁白同 CHAPTERS,生成單文件 HTML。之後用 scripts/generate-audio.mjs 生成每節嘅 mp3(edge-tts 雲希男聲)。
瀏覽器打開預覽時,畫面按口播 onended 驅動切換,有上下暫停播放等控件,鍵盤快捷鍵都支援。
確認冇問題後,用 scripts/export-video.mjs 做:Playwright headless Chromium 錄 WebM,ffmpeg 拼 mp3 加 1.2 秒靜音同 1 秒 pre-roll,最後 mux 成 MP4(H.264 + AAC,pix_fmt yuv420p,faststart)。成個過程 3 分鐘,輸出約 5MB。
關鍵取捨:單文件 HTML 零構建步驟,任何機器都跑得,冇 webpack/vite 負擔;純 SVG 動畫,唔依靠任何動畫庫;TTS 雙軌(mp3 優先,Web Speech 兜底);視頻導出走 Playwright + ffmpeg,穩定成熟。
點樣用:安裝一句話,全新主題即出
一次性安裝:npx skills add AgentBuff/animation-explainer。之後可以直接睇現有 demo(open examples/browser-request/index.html 等),或者用 Claude Code 講「用 animation-explainer skill 做一個 [主題] 嘅動畫演示」。
- 1 Claude 會自動拆場景、複製模板改、用真實代碼填旁白、寫口播稿、跑生成腳本,最後輸出到 examples/<topic>/。
- 2 適合:網絡協議、底層原理、加密算法、編譯器、虛擬機、數據庫內部、操作系統——所有「睇唔見但需要睇見」嘅技術主題。
- 3 唔適合:靜態信息圖、交互式教程、超過 8 節嘅長課程、需要真人出鏡嘅內容。
價值同展望:技術可視化嘅未來
作者相信呢件事有價值,因為教技術最好嘅方式唔係寫博客,亦唔係錄屏,而係動畫加解說,似博物館嘅科普紀錄片。以前一個好嘅 motion designer 一日上千,專業配音另計,所以高質量技術科普極少。
而家 AI 將成本降到「幾句話加幾分鐘」,一個能講清 Vue 響應式嘅視頻,過去要一個團隊幾周,而家一個人一個晚上。
可以預見嘅延展:雙語字幕、多種視覺風格、更長複合主題、直接發佈到 B 站/抖音嘅自動化。作者連呢篇文章嘅開發過程都係用 Claude Code 完成,全程對話推進,證實技術唔再係壁壘,而係對要做嘅嘢有清晰判斷先係壁壘。
如果你想試,直接同 Claude 講「用 animation-explainer skill 做一個 git rebase 內部發生咗咩嘅動畫演示」就得。
花了一個晚上,我讓 Claude 給我做出了 8 節帶雲希男聲講解、按口播節奏自動切換的技術動畫,最後一行命令導出成 5MB 的 MP4。這條路打通後,下一個主題——不管是 Vue 原理、Kafka 消息流轉還是 Postgres 的 MVCC——只要一句話,幾分鐘出一個完整的科普視頻。
先看效果
我給了 Claude 兩個主題,分別得到了兩份完整的動畫演示。
主題 1:瀏覽器請求底層之旅
你在瀏覽器輸入 https://example.com 按下回車,背後到底發生了什麼?
8 節,從 URL 解析、DNS 遞歸查詢,到 TCP 三次握手、TLS 握手、HTTP 請求報文飛向服務器,再到 Nginx → Router → Handler → DB 的處理流水線,最後是瀏覽器把字節變成像素的整個渲染流程。
主題 2:Vue 3 原理之旅
同樣 8 節,從一個 .vue 文件出發,到編譯器把 template 轉成 render 函數(含靜態提升和 patchFlag),再到響應式系統三件套(reactive 的 Proxy 包裝 / track 依賴收集 / trigger 觸發更新),最後到 VNode → Diff → Patch 真實 DOM。
每節都有:
- 真實在動的 SVG 動畫:不是靜態截圖,是數據包飛過去、握手箭頭依次出現、流水線節點逐段亮起、DOM 樹一層層展開
- 真實的代碼和日誌:
dig輸出、tcpdump抓包、HTTP/1.1 報文、Rails server log、Vue 源碼裏真實的 Proxy handler 實現——不是 AI 瞎編的 - 雲希男聲的中文口播:每節 10–20 秒,專業術語保留英文("Proxy 攔截器"而不是"代理攔截器"),不會讀成"乃是一個 Proxy 實例"那種書面腔
- 按口播節奏自動切換:當前章節的口播說完,停 1.2 秒,再切下一節——而不是固定 setTimeout 把口播打斷
最終 npm run video:vue,輸出 video.mp4,5MB,2 分 17 秒,1280×800 30fps。可以直接發微信、抖音、B 站、知乎。
起點:本來只想做一個 demo
最初我只是想給朋友講清楚一件事:瀏覽器請求的底層。
試過幾次發現,文字講太抽象,畫圖講太靜態。最好是個"會動的"——數據包從客戶端飛到 DNS 服務器,再飛到根服務器,逐級返回。但這種動畫一般要找 motion designer 做,一天上千,不是日常能用的工具。
我想試試讓 AI 直接出 HTML 動畫。問 Claude:"給我做一份'用戶輸入 URL 後底層發生什麼'的演示,要能播放的 HTML 動畫,分章節,配真實的代碼和日誌。"
得到的第一版就讓我驚訝——不是 PPT 截圖,是真的能播的劇場式演示。
那一刻我意識到:這個結構本身是可複用的。多場景、自動播放、章節導航、配真實代碼的旁白——任何"看不見但需要看見"的技術主題都可以套這個模子。
於是停下來,把模式抽成一個 Claude Code skill,再用 skill 做第二個、第三個。
關鍵迭代(也是踩過的坑)
整個過程沒有從頭規劃好,是邊做邊發現的幾個關鍵節點。
#沉澱成 skill
第一個 demo 跑通後,我把骨架、設計 token、5 種視覺模式(實物 mockup / 節點+飛包 / 時序圖 / 流水線 / 結構樹)和"反 AI slop"清單都寫進 SKILL.md。
效果立竿見影:第二個主題 Vue 原理,從拆解到出片,比第一次快了 5 倍以上。Claude 不會每次重新發明輪子,它就照着 5 種已有模式選一個。
#加口播:先嚐試瀏覽器原生 TTS
光看動畫太冷場。最先想到瀏覽器自帶的 speechSynthesis API——零依賴,一行 JS 就能說話。
跑起來,發現聲音僵硬得像導航:"您已駛入主路。"那種感覺。Mac 系統裏的 Ting-Ting 中文 voice 實在撐不起教學場景。
#切換到 edge-tts:免費的 Neural voice
換方案:用 msedge-tts 這個 npm 包,調用微軟 Edge 瀏覽器後端的 TTS 服務。免費、不要 API key,中文有"曉曉"、"雲希"、"雲揚"等 Neural voice,質量接近商業級。
寫一個腳本:從 HTML 裏用正則摳出 CHAPTERS 數組的 narration 字段,逐節生成 audio/scene-N.mp3。
HTML 端做雙軌設計:探測 audio/scene-1.mp3 能不能加載,能就用 mp3,不能就回退到 Web Speech API。這樣:
- 項目克隆下來就能用(哪怕沒裝 Node 依賴,HTML 也能放話)
- 改完 narration 文案,重跑生成腳本即可
- 文件 file:// 雙擊打開也能工作
#同步問題:必須按口播驅動切換
第一版用固定 setTimeout(CHAPTERS[i].duration) 切下一節。結果發現:口播長度不固定,常常話還沒說完就跳到下一節,觸發新的口播打斷舊的。
改成事件驅動:
speak(text, idx, () => {
// 口播自然結束 → 1.2s 緩衝 → 切下一節
if (state.playing) scheduleAdvance(1200);
});
speak() 接受 onEnd 回調,掛在 audio.onended 上。口播說完才推進,加 1.2 秒緩衝讓觀眾回看一眼代碼。再加一個 60 秒兜底定時器防止 onEnd 因為某些原因沒觸發。
這次改完整個節奏就對了。
#一個弱智 bug:代碼擠成一行
寫完口播改完同步,發現右側旁白裏的代碼塊全擠在一行:<template> <div class="counter"> <h1>Count...
原因找了 30 秒就發現了——.codeblk 的 CSS 缺了 white-space: pre。HTML 默認把所有空白(含換行)摺疊成單個空格。
修復一行,加 white-space: pre; tab-size: 2;。然後把這條加進 SKILL.md 的強制規則——避免下次新 demo 再踩。
技能能"自我完善"的關鍵:每踩一個坑就把它固化成規則。skill 文件從 235 行寫到 425 行,主要就是這種"為防止下次再錯"的內容。
#最後一步:導出 MP4
光在瀏覽器裏看不夠,得能發出去。
最初想用 ffmpeg + MediaRecorder API 在瀏覽器裏錄屏,複雜、需要用戶交互。
換方案:
- Playwright headless Chromium:加載 HTML,自動播放
- recordVideo 錄 WebM:但這有個硬限制——Playwright 不錄音軌
- ffmpeg 單獨拼音軌:把 8 個 mp3 文件中間補 1.2 秒靜音(對齊 HTML 的
ADVANCE_BUFFER_MS),開頭加 1 秒 pre-roll(對齊瀏覽器 autoplay 啓動延遲) - ffmpeg mux:WebM(視頻)+ 拼好的音軌 → MP4,H.264 + AAC,pix_fmt yuv420p(QuickTime/微信/抖音兼容),faststart(網頁流播友好)
npm run video:vue,3 分鐘跑完,5MB 的 MP4 出現在目錄裏。
四、最終的實現架構
輸入: "用 animation-explainer skill 給我做一個 X 的動畫演示"
↓
1. Claude 按 SKILL.md 拆 3–8 節,每節配視覺模式
↓
2. 複製 examples/browser-request/index.html 改 SVG / 旁白 / CHAPTERS
↓ 單文件 HTML(含 SVG 動畫 + 旁白文本 + narration 字段)
3. node scripts/generate-audio.mjs examples/<topic>
↓ + audio/scene-1~N.mp3 (edge-tts 雲希男聲)
4. 瀏覽器打開預覽
- 按口播 onended 驅動切換
- 控件:上/下/播放/暫停/重播/🔊 靜音 + 鍵盤 ←→/Space/R/M
↓ ✅ 人工審核通過
5. node scripts/export-video.mjs examples/<topic>
- Playwright headless 錄 WebM
- ffmpeg 拼 mp3 + apad(1.2s) + 1s pre-roll
- mux WebM + 音軌 → MP4
↓
輸出: video.mp4 (~5MB / 2 分鐘),可發任意平台
關鍵的技術取捨:
- 單文件 HTML + 零構建步驟:複製到任何機器都能跑,沒有 webpack/vite 的負擔
- 純 SVG 動畫:不依賴任何動畫庫(不用 GSAP/Lottie/Three.js),原生 setAttribute + requestAnimationFrame 完全夠
- TTS 雙軌:mp3 優先質量好、Web Speech 兜底保證最低可用
- 畫面切換按口播驅動:而不是固定 setTimeout,避免口播被打斷
- 視頻導出走 Playwright + ffmpeg:成熟工具組合,比 puppeteer-stream 那種 hack 穩定
五、如何使用
整套技能已經開源(連結在文末)。
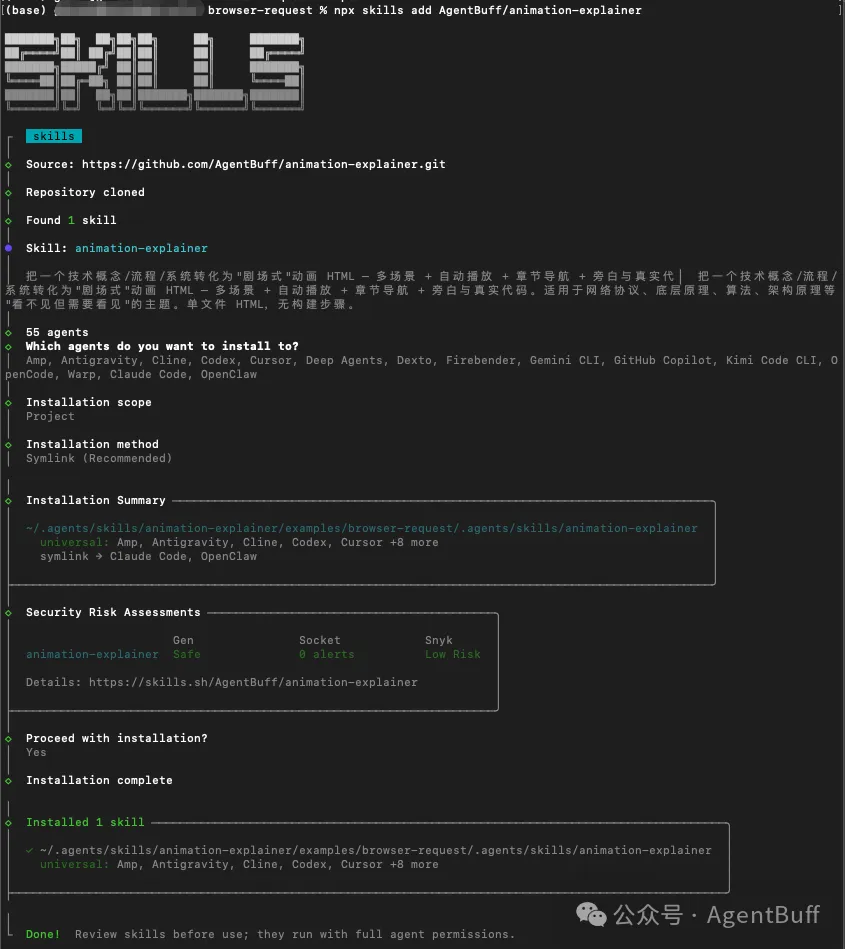
一次性安裝:
npx skills add AgentBuff/animation-explainer 看現有 demo:
open examples/vue-internals/index.html # Vue 3 原理
導出視頻,直接跟ai說或者執行以下命令
npm run video:vue
npm run video:browser
做新主題(如果你在用 Claude Code):
跟 Claude 說:
用 animation-explainer skill 給我做一個 [主題] 的動畫演示
例如:
- "用 animation-explainer skill 做一個 git rebase 內部發生了什麼的動畫演示"
- "用 animation-explainer 把 V8 怎麼編譯 JavaScript 講清楚"
- "用 animation-explainer 解釋 Postgres 的 MVCC 怎麼工作"
它會:拆場景 → 複製模板改 → 用真實代碼填旁白 → 寫口播稿 → 跑生成腳本 → 輸出到 examples/<topic>/。完整工作流在 SKILL.md 裏有詳細描述。
適合做什麼 / 不適合做什麼
適合:
- 網絡協議、底層原理、加密算法、編譯器、虛擬機、數據庫內部、操作系統——所有"看不見但需要看見"的技術主題
- 公司內部技術分享、培訓課程片段、工具講解
- 自己想搞清楚一個概念,反向用動畫"逼自己講明白"
不適合:
- 靜態信息圖(Markdown 寫就夠)
- 交互式教程(這是"播放型",不是"操作型")
- 大於 8 節的長課程(拆成多個 demo 更好)
- 需要真人出鏡的內容(這套是純動畫+合成語音)
為什麼我相信這事有價值
教技術最好的方式不是寫博客,也不是錄屏。是動畫 + 解說,跟博物館裏的科普影片一樣——一邊看東西在動,一邊聽人在講。
但這種內容貴:好的 motion designer 一天上千,專業配音另算。所以高質量技術科普極少。絕大多數程序員習慣了一行行讀文檔、一段段讀源碼,從來沒在博物館裏看過"程序員視角的科普紀錄片"。
現在 AI 把這件事的成本降到了"幾句話 + 幾分鐘"。一個能講清楚 Vue 響應式的視頻,過去要一個團隊幾周,現在一個人一個晚上。
這條路才剛剛開始。可以預見的延展:
- 雙語字幕(用 ffmpeg 的 subtitle filter)
- 多種視覺風格(暗色/亮色主題切換)
- 更長的複合主題(多個 demo 串成一個系列)
- 直接發佈到 B 站/抖音的自動化
如果你看到這裏,那這篇文章對你還是有點幫助的,希望得到你的關注,獲取更多有見解的內容,你的點贊,收藏,轉發是我堅持的動力。
項目地址:https://github.com/AgentBuff/animation-explainer
寫在最後:這篇文章本身的整個開發過程也是用 Claude Code 完成的。從最初一句"我想做一個動畫視頻學習技能",到最終拿到完整的 MP4 視頻,全程用對話推進。技術不再是壁壘,對要做什麼有清晰的判斷才是壁壘。