我發現了一個能把舊內容自動變成新選題的工具(附完整教程)
整理版優先睇
呢個開源內容結構化系統,將舊內容自動變成新選題,解決創作者「寫過用唔返」嘅問題。
dbs-content-system 係由 dontbesilent 開發嘅開源內容結構化系統,佢從自己 12,307 條推文提煉出 21 個 Agent skill,呢個係其中一個基建模塊。佢專幫內容創作者將累積咗嘅文稿、推文、選題等變成可持續增長嘅內容資產,特別適合寫咗一年以上、累積十萬字以上嘅創作者。
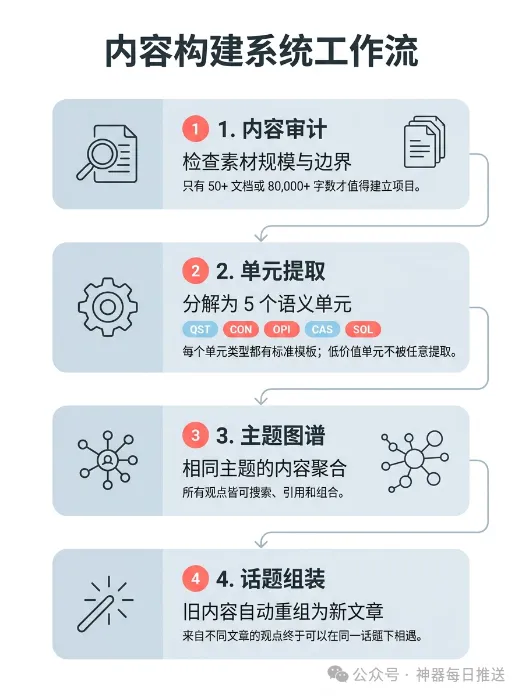
傳統做法有三大問題:按文件夾堆但冇語義、同一概念講法唔一致、舊內容用完就擺。系統嘅解法係將內容拆成 5 種最細語義單元(問題、概念、觀點、案例、方案),每個單元帶來源、版本、關係等字段。然後透過 4 檔遞進模式——審計、樣本、批量、全量——逐步將內容結構化,確保每一步都先驗證再擴大,避免返工。呢套機制同寫代碼先寫測試再實現一樣,強調「寧缺毋濫」:樣本模式唔會硬抽低價值單元。
最終建立主題地圖同選題裝配機制,畀你可以隨時調用舊單元重組新選題。作者話,積累嘅真正含義唔係儲存得多,而係令每一篇舊內容都可以被下一次創作調用。我自己試過將 100 多篇舊文章導進去,抽咗 30 幾個單元,當中好多觀點我自己都差啲唔記得。系統完全開源免費,直接一行命令裝就得。
- 系統將舊內容拆成 5 種語義單元(問題、概念、觀點、案例、方案),解決調用難、概念不一致、再利用問題。
- 4 檔遞進模式(審計→樣本→批量→全量)確保結構穩定先擴大規模,避免返工。
- 主題地圖聚合同主題單元,選題裝配自動組合新文章骨架,實現舊內容自動變新選題。
- 同傳統整理工具唔同,呢套系統先驗證再批量,強調「寧缺毋濫」—樣本模式唔會硬抽低價值單元。
- 實際操作只需 9 步:安裝、審計、初始化工程、複製素材、樣本抽取、校驗、主題地圖、裝配、持續生長;任何支援 skill 機制嘅 AI Agent 都用得。
dbskill 安裝命令
一行命令安裝全部 21 個 Agent skill,包括內容結構化系統。
dbskill GitHub
開源項目地址,包含完整知識庫同安裝說明。
點解你需要內容結構化系統?
內容創作者最大嘅浪費,唔係唔識寫,而係寫過嘅嘢再也用唔返。
「寫過嘅嘢再也用唔返」
- 1 問題一:文件夾堆砌但冇語義,你要靠記憶猜個觀點喺邊篇文章。
- 2 問題二:同一概念講法唔一致,讀者睇到你前後矛盾。
- 3 問題三:舊內容只用一次就擺喺度,入面嘅好觀點、案例、方法論框架全部鎖死。
核心機制:4 檔遞進模式
系統唔係一次過整理,而係分 4 個檔位逐步推進,先驗證結構,再擴大規模。
- 檔位 1 審計模式:檢查內容量夠唔夠,門檻係 50 個文件或 8 萬字,唔夠就直接勸退。
- 檔位 2 樣本模式:抽 3-5 篇代表性文稿抽取第一批內容單元,驗證抽取口徑穩定。
- 檔位 3 批量模式:口徑穩定後按批次推進,每批覆盤,連續 2 批冇問題先進入全量。
- 檔位 4 全量模式:規則凍結,對剩餘庫存全面覆蓋。
「先驗證結構,再擴大規模」
完整實操步驟(9 步)
首先用 npx 命令安裝:npx -y skills add dontbesilent2025/dbskill -g --all。然後觸發內容結構化系統。
npx -y skills add dontbesilent2025/dbskill -g --all
- 1 審計素材:系統問你目錄、排除項、優先類型,然後統計文件數同字數,判斷可否建工程。
- 2 初始化工程骨架:系統創建標準目錄,包括規則、原始素材、內容單元庫等 8 個文件夾同 4 個說明文件。
- 3 複製原始素材:系統唔碰原文件,只複製一份到工程內部,原文完全保留。
- 4 首批樣本抽取:揀 3-5 篇代表性文稿,抽取 QST、CON、OPI、CAS、SOL 單元,寧缺毋濫。
- 5 校驗鏈路:生成關係索引、去重候選、處理狀態總覽,全部通過先算樣本模式完成。
- 6 建立主題地圖:將同主題嘅單元聚合,寫清楚覆蓋問題、核心概念、可用觀點同方案。
- 7 自動裝配新選題:指定選題標題,系統自動從單元庫匹配組合,生成文章骨架。
- 8 持續生長:規則穩定後開全量模式覆蓋全庫,新單元同舊單元產生新關係,指數級增值。
「寧缺毋濫」
我寫嘢成日有個問題:明明寫過類似嘅觀點,但諗唔起喺邊篇度。揾關鍵字都揾唔到——因為個觀點可能散落喺唔同文章嘅唔同段落度。每次寫新嘢,都係從零開始諗選題、揾材料。
內容創作者最大嘅浪費,唔係唔識寫,而係寫過嘅嘢再用唔番。
你寫咗一年甚至更耐,積累咗幾十萬字,但調用佢哋嘅效率幾乎係零。「擁有」同「用得着」係兩回事。

尋日見到 dontbesilent 新開源嘅內容結構化系統——dbs-content-system。第一個反應就係——呢個咪係我缺嗰樣嘢囉?
佢支援將本地大量文稿、推文、選題、案例同課程稿搭成一個可持續增長嘅內容結構化工程:先審計內容規模同邊界,再建立新工程、複製素材、抽取內容單元、生成主題地圖同選題裝配稿。
dbskill 係咩嘢
dbskill 係一個開源嘅 Agent 工具箱,作者係 dontbesilent(X 上面揾到佢)。佢從自己 12,307 條推文入面提煉出一套方法論,打包成 21 個 Agent skill。每個 skill 對應一個具體問題嘅診斷或處理流程。

整個項目係開源兼免費嘅,知識庫亦完全公開——4,000 幾個知識原子、方法論文檔、高頻概念詞典,你唔使裝任何嘢就可以訪問。
佢可以在 Claude Code、Codex、Cursor、Trae Solo 等支援 system prompt 或 skill 機制嘅 AI Agent 上執行。安裝命令就一行:
npx -y skills add dontbesilent2025/dbskill -g --all
21 個 skill,從商業模式診斷到內容創作方法到執行力分析,基本覆蓋咗一個內容創業者日常經營會遇到嘅大部分問題。
但呢篇文章我只係想重點講其中一個——dbs-content-system,內容結構化系統。因為呢個係我近期見到最有工程思維嘅內容工具,冇之一。
點解你需要內容結構化系統
先講嚇傳統做法嘅幾個問題。
問題一:內容按文件夾堆,但文件夾冇語義。
你嘅文稿可能按「公眾號」「小紅書」「課程」分目錄。咁樣確實方便歸檔,但當你需要揾一個觀點時,你要靠記憶估嚇喺邊個文件夾邊篇文章度。兩個月前嘅文章寫咗啲咩,你自己都記唔清,更唔好講入面有價值嘅觀點同金句。
問題二:同一個概念反覆講,但每次講法都唔一致。
「反脆弱」呢個概念你可能寫過 3 次。第一次寫嘅時候定義係 A,第二次加咗啲新理解變成 A',第三次又轉咗個角度。3 篇文章各講各嘅,你自己都唔知邊個版本係而家最成熟嘅表述。更差嘅係——讀者如果咁啱睇咗你兩篇唔同時間出嘅文章,可能覺得你嘅觀點前後矛盾。
問題三:舊內容只用一次,然後就打入冷宮。
呢個就係我開頭講嘅問題。一篇 3000 字嘅文章,裏面可能藏住 3 個好觀點、2 個案例、1 個方法論框架。但因為佢被鎖喺一篇完整嘅文章裏面,你冇辦法單獨調用入面某個節點。下次寫新選題時,呢啲價值就被浪費咗。
dbs-content-system 嘅解法好簡單:唔將內容當文件管,而係拆成最細嘅語義單元。
佢哋定義咗 5 種內容單元:
- QST(問題單元):
呢篇文章喺回答咩問題 - CON(概念單元):
文中定義咗邊啲關鍵概念 - OPI(觀點單元):
本文嘅核心觀點同立場 - CAS(案例單元):
引用嘅真實案例同數據 - SOL(方案單元):
俾出嘅具體方法或動作路徑
每類單元有標準模板,自帶字段:來源、版本、關係、關鍵詞、主題標籤。
舊文件依然擺喺度唔鬱。但系統多咗一層索引——你嘅觀點唔再被「鎖」喺文章入面,而係變成咗一個獨立、可檢索、可引用嘅節點。
進一步,系統透過 主題地圖 聚合同主題節點,透過 選題裝配 將一組節點重新組合成一篇新嘅文章骨架。
寫到呢度你可能已經感覺到——呢個同我上面講嘅三個問題係一一對應嘅。拆成單元解決調用難,統一概念定義解決一致性,主題地圖加裝配解決舊內容再利用。
核心機制:4 檔遞進模式
但真正令我覺得呢個項目靠譜嘅,係佢嘅工程思維——一套 4 檔遞進模式。
大多數內容整理工具嘅邏輯係:你將素材導入去,我幫你一次性整理好。結果係整理完你再冇打開過,因為整理過程唔符合你底層嘅工作習慣。
dbs-content-system 唔係咁。佢分咗 4 個檔位:
檔位 1:審計模式。
先檢查你嘅內容量夠唔夠。門檻係至少 50 個文件或 8 萬字。如果唔夠,系統直接話你知——你而家嘅素材積累仲未到做工程化嘅時候,繼續去寫先。呢層過濾避免咗「素材冇幾多就先搭架」嘅浪費。

檔位 2:樣本模式。
通過審計後,唔好急住做全量處理。先從 3-5 篇代表性文稿抽第一批內容單元,驗證抽口徑是否穩定——你呢 5 篇文稿嘅「觀點」邊界係咪清晰?「方案」真係可以同「概念」區分開?口徑未穩定之前,唔做下一步。
檔位 3:批量模式。
口徑穩定後,按批次推進。每批處理完覆盤:有冇改字段規範?有冇改關係規則?去重有冇失控?連續 2 批冇出問題,先準許進入全量。
檔位 4:全量模式。
規則凍結,對剩餘庫存全面覆蓋。
呢 4 檔設計嘅核心思想係:先驗證結構,再擴大規模。 呢個同寫程式先寫測試再寫實現係同一個邏輯。大多數內容整理工具翻車,就係因為冇諗清楚呢一點——一開頭就想將全量處理曬,結果口徑唔啱、關係混亂、大量返工。
完整實操教程
以下係我嘅實際操作流程,你用任何支援 skill 機制嘅 AI Agent 都能重現。
第一步:安裝
有兩種方法。
方法一(推薦)—— 用 npx 命令直接安裝:
npx -y skills add dontbesilent2025/dbskill -g --all
裝完之後,你可以在 Agent 中輸入 /dbs-content-system 或「內容結構化系統」嚟觸發。
方法二 —— 手動下載安裝:
去 GitHub 下載項目壓縮包:
https://github.com/dontbesilent2025/dbskill
將本地文件路徑交俾 opencode、openclaw 呢類工具安裝。
第二步:審計素材
呢個同 4 檔遞進中嘅審計模式對應。系統會問你三個問題:
要處理嘅內容目錄係邊度? 邊啲目錄納入、邊啲排除? 優先處理咩類型嘅內容?
回答完,系統開始審計——統計文件數、估算總字數、識別來源維度。審計會輸出一段明確嘅結論:素材夠唔夠、邊界清唔清楚、可唔可以建工程。
我當時嘅素材大約 80 幾個文件,15 萬字嘅規模,審計直接通過。如果你嘅唔夠 50 個文件或 8 萬字,系統會話你知繼續寫先,唔好做工程。呢個唔係打擊你,係真係冇必要。
第三步:初始化工程骨架
審計通過後,系統會喺你指定嘅位置創建標準工程目錄。結構係咁樣:
內容結構化系統/
├── 00-規則與索引/
├── 01-原始素材區/
├── 02-內容單元庫/
├── 03-處理狀態/
├── 04-模板/
├── 05-主題地圖/
├── 06-選題裝配/
└── 07-腳本與工具/
根目錄仲有 4 個文件:
AGENTS.md、CLAUDE.md、SOURCE_OF_TRUTH.md、README.md。
佢哋分別規定咗跨宿主規則、AI 側嘅說明、權威定位與衝突規則、以及系統說明。
第四步:複製原始素材
呢一步好重要:系統唔會碰你原本嘅文件。
原始目錄嘅原內容唔鬱,系統將佢哋複製一份到 01-原始素材區/完整副本/。所有後續處理都喺工程內部進行,原文完全保留。呢個意味着你隨時可以返去原始版本核對。
複製完成後,系統會生成來源註冊表同原始素材索引。所有進入工程嘅文件都有咗獨立嘅來源記錄——幾時入嚟、從邊度嚟、原始路徑係咩。
第五步:首批樣本抽取
呢個係最關鍵嘅一步。系統從你嘅素材中揀 3-5 篇代表性文稿,對每篇抽取:
1 個主問題單元(QST):呢篇係解決咩問題 1 個主觀點單元(OPI):核心觀點係咩 如果文中有穩定概念定義:抽概念單元(CON) 如果有具體案例或數據:抽案例單元(CAS) 如果有明確嘅動作路徑:抽方案單元(SOL)
每個新單元生成時,系統自動補齊來源、關鍵詞、主題標籤同關聯關係。
呢度有一條鐵律:唔好為咗追求數量大量製造低價值單元。 第一批樣本嘅目標唔係覆蓋全部語義,而係驗證呢套結構能否跑通。所以如果某篇文章就係冇明確嘅「方案」,咁就唔好硬抽 SOL。寧缺毋濫。
第六步:校驗鏈路
抽取完成後,行校驗鏈路。系統會生成 3 個核心索引:
- 關係索引:
單元之間嘅關聯關係(回應、解釋、證明、衝突) - 去重候選:
邊啲內容可能重複咗(完全重複、同義重複、近似重複、重複講述) - 處理狀態總覽:
而家邊啲處理咗、邊啲等緊處理、整體進度
呢三項指標全部通過後,先算樣本模式行通。
第七步:建立主題地圖
主題地圖嘅作用係將同主題嘅內容單元聚合埋一齊。
例如你之前喺唔同文章中寫過「N 個關於商業嘅思考」,咁系統會將所有涉及該主題嘅 QST、CON、OPI、CAS、SOL 單元歸攏到一張主題地圖上面。
主題地圖唔只係「將文件列出來」。佢需要寫清楚:呢個主題覆蓋咗邊啲問題?核心概念係咩?有啲咩可用嘅觀點同案例?邊啲方案已經驗證過?咁樣後續寫新選題時,你直接入主題地圖,就能睇到所有可調動嘅內容資產。
第八步:自動裝配新選題
呢個係成個系統最亮眼嘅能力。
你可以行一個裝配腳本,指定選題標題,系統會自動從已有嘅內容單元庫入面匹配最合適嘅組合。例如你寫咗一個標題「普通人點樣揾到自己嘅賺錢方向」,系統會:
從某個 QST 單元揾到呢個問題嘅原始定義 從某個 CON 單元提取相關概念解釋 從某個 OPI 單元引用核心觀點 從某個 CAS 單元插入真實案例 從某個 SOL 單元提供具體執行路徑
呢啲嘢嚟自你唔同時期、唔同文章入面嘅唔同段落。 你兩年前寫嘅一篇文章入面有個好案例,三個月前寫嘅文章入面有個好觀點——佢哋喺你嘅舊文件入面永遠碰唔到面,但喺內容單元庫入面可以被重組到同一個選題之下。
呢個就係我標題講嘅——將舊內容自動變成新選題。
第九步:持續增長
系統做到呢一步已經處於「可用態」。後續你可以繼續批量推進更多素材,規則穩定後開全量模式覆蓋全庫。
隨住時間推移,你嘅內容單元庫愈來愈大,主題地圖愈來愈密集,選題裝配嘅選擇愈來愈豐富。系統嘅價值唔係線性,而係指數級增長——因為新單元會同舊單元之間產生新嘅關係,新嘅關係會觸發新嘅重組可能。
唔只係呢一個工具
最後講嚇 dbskill 全家桶。
dbs-content-system 係呢套工具箱入面嘅「基建模塊」,佢嘅定位係搭建內容資產底層。喺佢之上,仲有一堆診斷同優化工具:
對單篇內容冇把握 → /dbs-content內容創作診斷開頭寫得唔好 → /dbs-hook開頭優化標題起唔到 → /dbs-xhs-title標題公式匹配擔心有 AI 味 → /dbs-ai-checkAI 寫作特徵檢測知道應該寫但一直拖延 → /dbs-action執行力診斷商業模式唔清晰 → /dbs-diagnosis商業模式診斷想揾對標模仿 → /dbs-benchmark對標分析概念諗唔清楚 → /dbs-deconstruct概念拆解目標模糊 → /dbs-goal目標審計
成條鏈路係通嘅:先搭內容基礎結構(content-system)→ 單篇診斷優化(content/hook/title/ai-check)→ 方向層面嘅問題(diagnosis/benchmark/goal)。
最後
我將 100 幾篇舊文章導入工程後,第一批樣本抽出咗 30 幾個內容單元——包括我以前寫過嘅幾個核心判斷、幾個案例、幾個方法論框架。講真,有啲觀點我自己都快唔記得了。
但重要嘅係,佢哋唔再只係「瞓喺一個文件夾入面嘅庫存」了。
佢哋變成咗我可以隨手調用嘅資產。每次啟動一個新選題時,我唔使再從零開始諗——先睇主題地圖我寫過咩,再睇有冇適合重組嘅單元。有時一個舊嘅方案配上新嘅案例,就係一篇全新嘅文章。
幾年前有人同我講,內容創作最大嘅護城河唔係寫得快,而係積累。我當時理解錯咗,以為「積累」就係將文章越存越多。而家我明白咗——積累嘅真正含義,係令每一篇舊內容都可以俾下一次創作調用。
dbskill 嘅開源地址喺 GitHub 上(dontbesilent2025/dbskill),整個知識庫亦完全公開。你可以只攞其中一部分嚟用。
但建議你至少試一下內容結構化系統。就算你只行一次審計、只抽一批樣本,都會對你現有嘅內容資產有一個完全唔同嘅認知——原來你寫過嘅嘢比你以為嘅值錢得多。
我的寫作一直有個問題:明明寫過類似的觀點,但想不起在哪篇裏。搜關鍵詞也搜不到——因為那個觀點可能散落在不同文章的不同段落裏。每次寫新東西,還是從零開始想選題、找素材。
內容創作者最大的浪費,不是不會寫,而是寫過的東西再也用不上。
你寫了一年甚至更久,積累了幾十萬字,但調用它們的效率幾乎是零。"擁有"和"能用"是兩回事。
昨天看到 dontbesilent 新開源的內容結構化系統——dbs-content-system。第一反應是——這不就是我缺的那個東西嗎?
它支持把本地大量文稿、推文、選題、案例和課程稿搭成一個可持續生長的內容結構化工程:先審計內容規模與邊界,再建立新工程、複製素材、抽取內容單元、生成主題地圖與選題裝配稿。
dbskill 是什麼
dbskill 是一個開源的 Agent 工具箱,作者是 dontbesilent(X 上能找到他)。他從自己 12,307 條推文裏提煉出一套方法論,打包成 21 個 Agent skill。每個 skill 對應一個具體問題的診斷或處理流程。
整個項目是開源且免費的,知識庫也完全公開——4,000 多個知識原子、方法論文檔、高頻概念詞典,你不需要裝任何東西就能訪問。
它能在 Claude Code、Codex、Cursor、Trae Solo 等支持 system prompt 或 skill 機制的 AI Agent 上跑。安裝命令就一行:
npx -y skills add dontbesilent2025/dbskill -g --all
21 個 skill,從商業模式診斷到內容創作方法到執行力分析,基本覆蓋了一個內容創業者在日常經營中會遇到的大部分問題。
但這篇文章我只想重點聊其中一個——dbs-content-system,內容結構化系統。因為這是我近期見到的最有工程思維的內容工具,沒有之一。
為什麼你需要內容結構化系統
先說說傳統做法的幾個問題。
問題一:內容按文件夾堆,但文件夾沒有語義。
你的文稿可能按「公眾號」「小紅書」「課程」分目錄。這確實方便歸檔,但當你需要找一個觀點時,你得靠記憶猜它在哪個文件夾哪篇文章裏。兩個月前的文章寫了什麼,你自己都記不清了,更別說裏面有價值的觀點和金句。
問題二:同一個概念反覆講,但每次講法都不一致。
「反脆弱」這個概念你可能寫過 3 次。第一次寫的時候定義是 A,第二次加了點新理解變成 A',第三次又切了個角度。3 篇文章各講各的,你自己都不知道哪個版本是當前最成熟的表述。更糟糕的是——讀者如果湊巧看了你兩篇不同時間發的文章,可能覺得你的觀點前後矛盾。
問題三:舊內容只用一次,然後就進了冷宮。
這就是我開頭說的問題。一篇 3000 字的文章,裏面可能藏着 3 個好觀點、2 個案例、1 個方法論框架。但因為它被鎖在一篇完整的文章裏,你沒法單獨調取其中的某個節點。下次寫新選題時,這些價值就被浪費了。
dbs-content-system 的解法很簡單:不把內容當文件管,而是拆成最小語義單元。
他們定義了 5 種內容單元:
- QST(問題單元):
這篇文章在回答什麼問題 - CON(概念單元):
文中定義了哪些關鍵概念 - OPI(觀點單元):
本文的核心觀點和立場 - CAS(案例單元):
引用的真實案例和數據 - SOL(方案單元):
給出的具體方法或動作路徑
每類單元有標準模板,自帶字段:來源、版本、關係、關鍵詞、主題標籤。
舊文件還是放在那裏不動。但系統裏多了一層索引——你的觀點不再被"鎖"在文章裏,而是變成了一個獨立的、可檢索、可引用的節點。
進一步,系統通過 主題地圖 聚合同主題節點,通過 選題裝配 把一組節點重新組合成一篇新的文章骨架。
寫到這裏你可能已經感受到——這和我上面說的三個問題是一一對應的。拆成單元解決調用難,統一概念定義解決一致性,主題地圖 + 裝配解決舊內容再利用。
核心機制:4 檔遞進模式
但真正讓我覺得這個項目靠譜的,是它的工程思維——一套 4 檔遞進模式。
大多數內容整理工具的邏輯是:你把素材導進去,我給你一次性整理好。結果是整理完你再也沒打開過,因為整理過程不符合你到底層工作習慣。
dbs-content-system 不是這樣。它分了 4 個檔位:
檔位 1:審計模式。
先檢查你的內容量夠不夠。門檻是至少 50 個文件或 8 萬字。如果不夠,系統直接告訴你——你現在的素材積累還不到做工程化的時候,先去繼續寫。這層過濾避免了"素材沒多少就先搭架子"的浪費。
檔位 2:樣本模式。
通過審計後,不急着全量處理。先從 3-5 篇代表性文稿抽取第一批內容單元,驗證抽取口徑是否穩定——你這 5 篇文稿的"觀點"邊界是清晰的嗎?"方案"真的能跟"概念"區分開嗎?口徑沒穩住之前,不做下一步。
檔位 3:批量模式。
口徑穩定後,按批次推進。每批處理完覆盤:有沒有改字段規範?有沒有改關係規則?去重是否失控?連續 2 批沒出問題,才允許進入全量。
檔位 4:全量模式。
規則凍結,對剩餘庫存全面覆蓋。
這 4 檔設計的核心思想是:先驗證結構,再擴大規模。 這和寫代碼先寫測試再寫實現是一個邏輯。大多數內容整理工具翻車,就是因為沒想清楚這一點——一上來就想把全量處理完,結果口徑不對、關係混亂、大量返工。
完整實操教程
下面是我的實際操作流程,你用任何支持 skill 機制的 AI Agent 都能復現。
第一步:安裝
有兩種方式。
方式一(推薦)—— 用 npx 命令直接安裝:
npx -y skills add dontbesilent2025/dbskill -g --all
裝完之後,你可以在 Agent 中輸入 /dbs-content-system 或「內容結構化系統」來觸發。
方式二 —— 手動下載安裝:
去 GitHub 下載項目壓縮包:
https://github.com/dontbesilent2025/dbskill
把本地文件路徑發給 opencode、openclaw 這類工具安裝。
第二步:審計素材
這和 4 檔遞進中的審計模式對應。系統會問你三個問題:
要處理的內容目錄是哪裏? 哪些目錄納入、哪些排除? 優先處理什麼類型的內容?
回答完,系統開始審計——統計文件數、估算總字數、識別來源維度。審計會輸出一段明確的結論:素材夠不夠、邊界清不清楚、是否可以建工程。
我當時的素材大約 80 多個文件,15 萬字的規模,審計直接通過。如果你的不夠 50 個文件或 8 萬字,系統會告訴你去繼續寫,先不做工程。這不是打擊你,是真的沒必要。
第三步:初始化工程骨架
審計通過後,系統會在你指定的位置創建標準工程目錄。結構是這樣的:
內容結構化系統/
├── 00-規則與索引/
├── 01-原始素材區/
├── 02-內容單元庫/
├── 03-處理狀態/
├── 04-模板/
├── 05-主題地圖/
├── 06-選題裝配/
└── 07-腳本與工具/
根目錄還有 4 個文件:
AGENTS.md、CLAUDE.md、SOURCE_OF_TRUTH.md、README.md。
它們分別規定了跨宿主規則、AI 側的說明、權威定位與衝突規則、以及系統說明。
第四步:複製原始素材
這一步很重要:系統不碰你原來的文件。
原始目錄的原內容原地不動,系統把它們複製一份到 01-原始素材區/完整副本/。所有後續處理都在工程內部進行,原文完全保留。這意味着你隨時可以回到原始版本去核對。
複製完成後,系統會生成來源註冊表和原始素材索引。所有進入工程的文件都有了獨立的來源記錄——什麼時候進來的、從哪裏來的、原始路徑是什麼。
第五步:首批樣本抽取
這是最關鍵的一步。系統從你的素材中挑選 3-5 篇代表性文稿,對每篇抽取:
1 個主問題單元(QST):這篇在解決什麼問題 1 個主觀點單元(OPI):核心觀點是什麼 如果文中有穩定概念定義:抽概念單元(CON) 如果有具體案例或數據:抽案例單元(CAS) 如果有明確的動作路徑:抽方案單元(SOL)
每個新單元生成時,系統自動補齊來源、關鍵詞、主題標籤和關聯關係。
這裏有一條鐵律:不要為了追求數量大量製造低價值單元。 第一批樣本的目標不是覆蓋全部語義,而是驗證這套結構能不能跑通。所以如果某篇文章就是沒有明確的"方案",那就不要硬抽 SOL。寧缺毋濫。
第六步:校驗鏈路
抽取完成後,跑校驗鏈路。系統會生成 3 個核心索引:
- 關係索引:
單元之間的關聯關係(回應、解釋、證明、衝突) - 去重候選:
哪些內容可能重複了(完全重複、同義重複、近似重複、重複講述) - 處理狀態總覽:
當前哪些處理了、哪些待處理、整體進度
這三項指標全部通過後,才算樣本模式走通。
第七步:建立主題地圖
主題地圖的作用是把同主題的內容單元聚合到一起。
比如你之前在不同文章中寫過"N 個關於商業的思考",那麼系統會把所有涉及該主題的 QST、CON、OPI、CAS、SOL 單元歸攏到一張主題地圖上。
主題地圖不只是"把文件列出來"。它需要寫清楚:這個主題覆蓋了哪些問題?核心概念是什麼?有哪些可用的觀點和案例?哪些方案已經驗證過?這樣後續寫新選題時,你直接進入主題地圖,就能看到所有可調動的內容資產。
第八步:自動裝配新選題
這是整個系統最亮眼的能力。
你可以跑一個裝配腳本,指定選題標題,系統會自動從已有的內容單元庫裏匹配最合適的組合。比如你寫了一個標題「普通人怎麼找到自己的賺錢方向」,系統會:
從某個 QST 單元找到這個問題的原始定義 從某個 CON 單元提取相關概念解釋 從某個 OPI 單元引用核心觀點 從某個 CAS 單元插入真實案例 從某個 SOL 單元提供具體執行路徑
這些東西來自你不同時期、不同文章裏的不同段落。 你兩年前寫的一篇文章裏有個好案例,三個月前寫的文章裏有個好觀點——它們在你的舊文件裏永遠碰不到面,但在內容單元庫裏可以被重組到同一個選題下。
這就是我標題說的——把舊內容自動變成新選題。
第九步:持續生長
系統做到這一步已經處於"可用態"。後面你可以繼續批量推進更多素材,規則穩定後開全量模式覆蓋全庫。
隨着時間推移,你的內容單元庫越來越大,主題地圖越來越密集,選題裝配的選擇越來越豐富。系統的價值不是線性的,而是指數級增長——因為新單元會跟舊單元之間產生新的關係,新的關係會觸發新的重組可能。
不只是這一個工具
最後說一下 dbskill 全家桶。
dbs-content-system 是這套工具箱裏的"基建模塊",它的定位是搭建內容資產底層。在它之上,還有一堆診斷和優化工具:
對單篇內容沒把握 → /dbs-content內容創作診斷開頭寫不好 → /dbs-hook開頭優化標題起不來 → /dbs-xhs-title標題公式匹配擔心有 AI 味 → /dbs-ai-checkAI 寫作特徵檢測知道該寫但一直拖延 → /dbs-action執行力診斷商業模式不清晰 → /dbs-diagnosis商業模式診斷想找對標模仿 → /dbs-benchmark對標分析概念想不清楚 → /dbs-deconstruct概念拆解目標模糊 → /dbs-goal目標審計
整條鏈路是通的:先搭內容基礎結構(content-system)→ 單篇診斷優化(content/hook/title/ai-check)→ 方向層面的問題(diagnosis/benchmark/goal)。
最後
我把 100 多篇舊文章導進工程後,第一批樣本抽出了 30 多個內容單元——包括我以前寫過的幾個核心判斷、幾個案例、幾個方法論框架。說實話,有些觀點我自己都快忘了。
但重要的是,它們不再只是"躺在一個文件夾裏的庫存"了。
它們變成了我可以隨手調用的資產。每次啓動一個新選題時,我不用再從零想——先看看主題地圖裏我寫過什麼,再看看有沒有適合重組的單元。有時候一箇舊的方案配上新的案例,就是一篇全新的文章。
幾年前有人跟我說,內容創作最大的護城河不是寫得快,而是積累。我當時理解錯了,以為"積累"就是把文章越存越多。現在我明白了——積累的真正含義,是讓每一篇舊內容都可以被下一次創作調用。
dbskill 的開源地址在 GitHub 上(dontbesilent2025/dbskill),整個知識庫也完全公開。你可以只取其中一部分來用。
但建議你至少試一下內容結構化系統。就算你只跑一次審計、只抽一批樣本,也會對你現有的內容資產有一個完全不同的認知——原來你寫過的東西比你以為的值錢得多。