我在新華社的分享:上下文即一切
整理版優先睇
上下文決定AI一切:原理、問題同用法都係由上下文話事
呢篇文章係作者喺新華社內部分享嘅內容整理,主要圍繞「上下文」呢個核心概念,解釋大模型嘅運作原理、點解有時唔靠譜、同埋點樣先用得好。作者認為,無論係ChatBot、Agent定係週報生成器,底層都係同一套流程:系統預設上文,加上用戶輸入,再由模型按概率生成下一個token。AI嘅能力同限制,都取決於點樣構建上下文。
上下文來源有三種:參數記憶(訓練數據)、手動構建(喂文檔)、自動構建(AI自己揾資料)。幻覺嘅產生就係因為上下文唔夠,模型焗著猜。作者指出,AI做得好嘅工作,都係可以準確表達成一段上下文嘅任務;做唔到嘅,例如到現場、判斷真偽、承擔責任,就冇咁易取代。
最後作者俾咗三條落地建議:跟進AI進展(每週30分鐘睇官方同社區)、自己上手(畀夠上下文,唔好糾結提示詞)、守住紅線(事實數據要人工核對,敏感信息唔好亂喂)。對媒體嚟講,未來嘅角色係提供最稀缺嘅上下文——去現場、做採訪、篩選材料。
- 大模型嘅本質係根據上文預測下一個token,所有產品嘅底層流程都係「預設上文 + 用戶輸入 + 模型生成」。
- Agent同ChatBot嘅分別在於邊個負責構建上下文:ChatBot靠人喂,Agent自己揾。
- 上下文愈好,幻覺愈少,但唔會係零;幻覺係模型喺冇足夠上文下焗著估答案。
- 判斷一件事適唔適合交俾AI,睇嚇佢能唔能夠被準確表達成一段好嘅上下文。
- 三條實用建議:每週跟進AI進展、自己上手實戰、永遠守住事實同數據嘅人工核對紅線。
大模型嘅核心原理:token預測循環
作者解釋,大模型生成內容嘅原理好簡單:佢會根據上文信息,不斷推測下一組文字最大概率係乜嘢,呢組文字就叫 token,可以係一個字、一個詞或者一啲信息。
舉例:「今日北京嘅天氣很」後面接咩?模型會俾出四個候選詞:「好」42%,「熱」25%,「冷」18%,「亂」6%。然後揀中概率最高嘅「好」,放返上下文,繼續猜下一個——呢個循環不斷重複:給定上下文,預測概率,選中結果,放回上下文,重複生成。
上下文決定AI能做咩、做唔到咩
ChatBot同週報生成器睇落係兩種產品,但底層流程完全一樣:系統預設一段上文(提示詞、歷史對話、頁面模板),加上用戶輸入,交給模型接龍,最後填返結果。記住:無論UI係聊天框定係報表,內核都係同一套。
Agent同ChatBot嘅分別在於邊個負責構建上下文:ChatBot靠人喂,你俾咩材料佢就用咩;Agent會自己搜網頁、讀文檔、調工具,將有用嘅內容寫入上下文,發現唔夠仲會自動回頭繼續揾。
- 1 第一種:參數記憶——模型訓練時讀過嘅海量內容,壓縮咗入模型權重,係廣義嘅上下文。
- 2 第二種:手動構建——人將Word、Excel、提示詞等材料喂入去。
- 3 第三種:自動構建——AI透過工具調用,自己聯網搜索、查知識庫、調接口。
判斷一個AI工具好唔好用,睇佢構建上下文嘅能力就夠。如果上下文唔夠,模型焗著猜,就會產生幻覺:例如要求俾某政策文件第18條原文,但模型冇訓練過,上下文又冇,佢就會從幾個合理候選中估一個,輸出看似真但可能錯嘅內容。
AI做得到同做唔到嘅工作
而家AI可以做好多工作,例如翻譯、校對、改寫、摘要、首稿、資料整理。呢啲工作嘅共通點係:背後嘅素材可以準確表達成一段上下文。
但係有啲嘢AI做唔到:到現場、觀察細節、判斷真偽、決定選題、承擔責任。點樣判斷一件事交唔交得俾AI?好簡單:睇嚇佢能唔能夠被準確表達成一段好嘅上下文。
三條落地建議,尤其係俾媒體工作者
- 1 跟蹤AI進展:盯模型官方、開發者社區同可信媒體,每週固定30分鐘就夠。
- 2 自己上手:畀夠上下文(任務、材料、輸出格式),唔好糾結提示詞話術。
- 3 恪守紅線:事實、引語、數據、法條必須人工核驗,敏感信息唔好喂外部模型,重要稿件一定要人審。
喺AI加持下,內容生產方法要跟進時代,都要有所恪守:唔好拒絕用AI,但亦唔好盲目用,更唔好製造賽博垃圾。
媒體嘅未來角色:提供最稀缺嘅上下文
過去媒體主要靠自己寫內容,但未來愈來愈多係為AI提供準確嘅上下文。媒體要承擔嘅係去現場——拎最稀缺嘅上下文;做採訪——拎別人拎唔到嘅上下文;睇材料——篩選上下文;做判斷——組織上下文。
TALK
前幾日,我去咗新華社做咗個兩粒鐘嘅內部分享,講咗好多嘢
完咗之後同新華社啲朋友傾偈,覺得「大模型嘅原理同用法」呢部份內容對好多人都有用,今日就將呢啲嘢貼出嚟,每頁配一段說明
成個分享入面,我都係圍繞一個詞嚟講:上下文
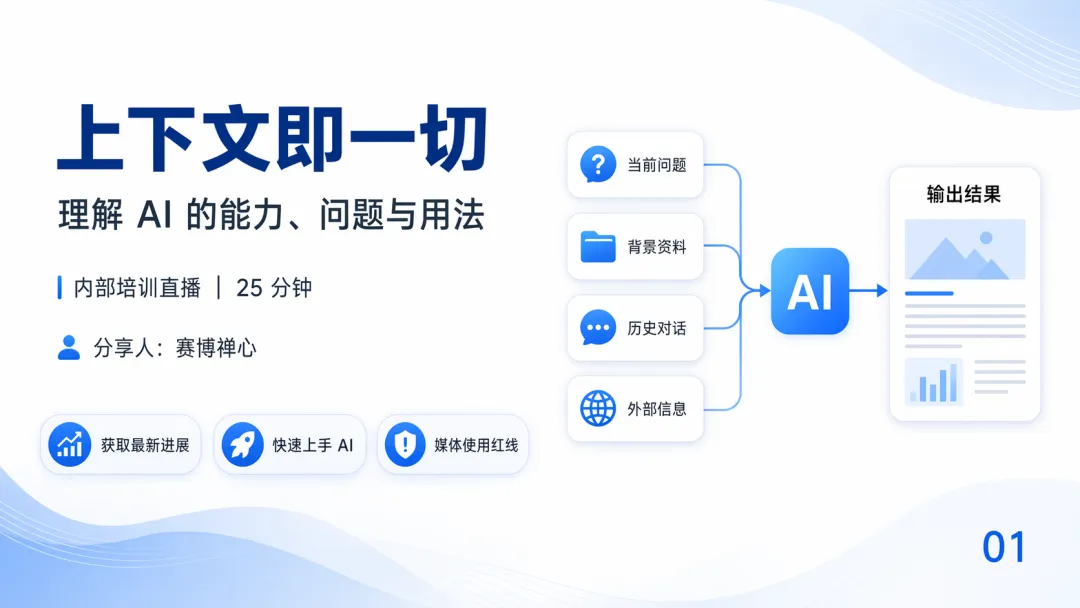
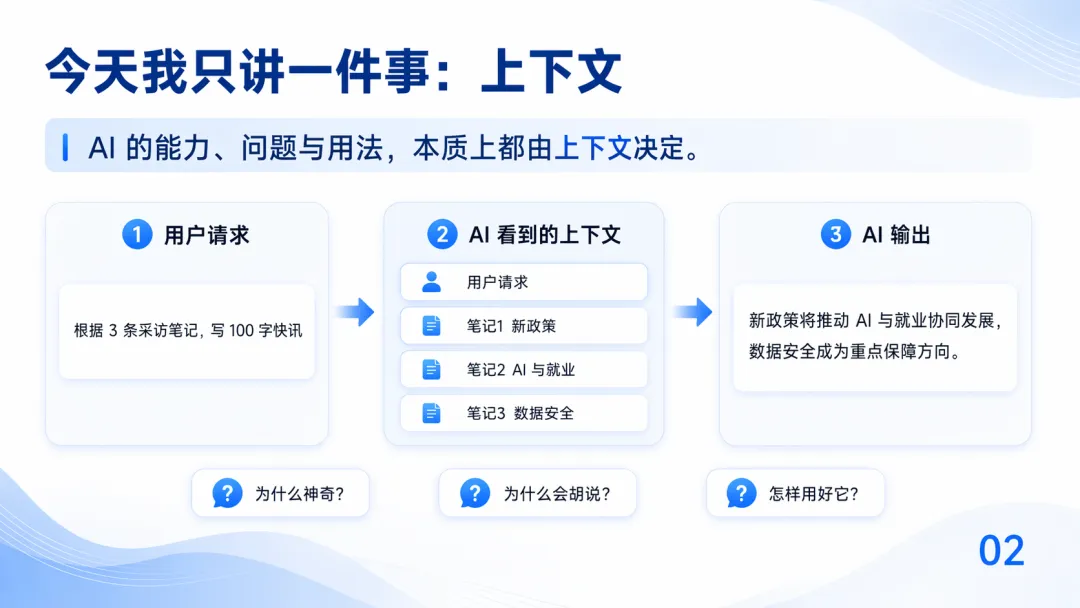
AI 嘅能力、問題同用法,本質上都係由上下文決定。用戶發一個請求,AI 將個請求同佢拎到嘅所有材料拼埋一齊,組成一整段完整嘅上下文,再繼續生成結果...循環往復
大模型點解咁神奇、點解有時唔多靠譜、同埋點樣先用得好,全部都依賴於點樣構建上下文
大模型喺進行內容生成嘅原理,其實好簡單:大模型會根據上文信息,不斷推測下一組文字最大機會係乜,而呢組文字就叫做 token,可以係一個字、一個詞或者一啲信息
呢度我舉個例子:「今日北京嘅天氣好」之後接乜嘢?
首先,模型俾出四個候選詞,「好」42%,「熱」25%,「冷」18%,「亂」6%;接着模型會揀中概率最高嘅「好」,放返入上下文,繼續估下一個...循環往復
呢個循環喺大模型生成嘅過程中不斷重複:俾定上下文,預測概率,揀中結果,放返上下文,重複生成...唔理參數有幾大,模型都係做緊呢一樣嘢

ChatBot 同週報生成器睇落係兩種產品,底層流程完全一樣
系統預設一段上文(提示詞、歷史對話、頁面模板),加上用戶輸入,交俾模型接龍,最後將結果填返去界面
記住:無論 UI 係聊天框定係報表,內核都係行緊同一套「預設上文 + 用戶輸入 + 模型生成」
Agent 同 ChatBot 嘅分別在於一件事:邊個嚟構建上下文
ChatBot 靠人餵,你俾佢乜嘢材料佢就用乜嘢材料
Agent 會自己搜網頁、讀文檔、調用工具,將有用嘅內容寫入上下文,發現唔夠仲會自動返轉頭繼續揾
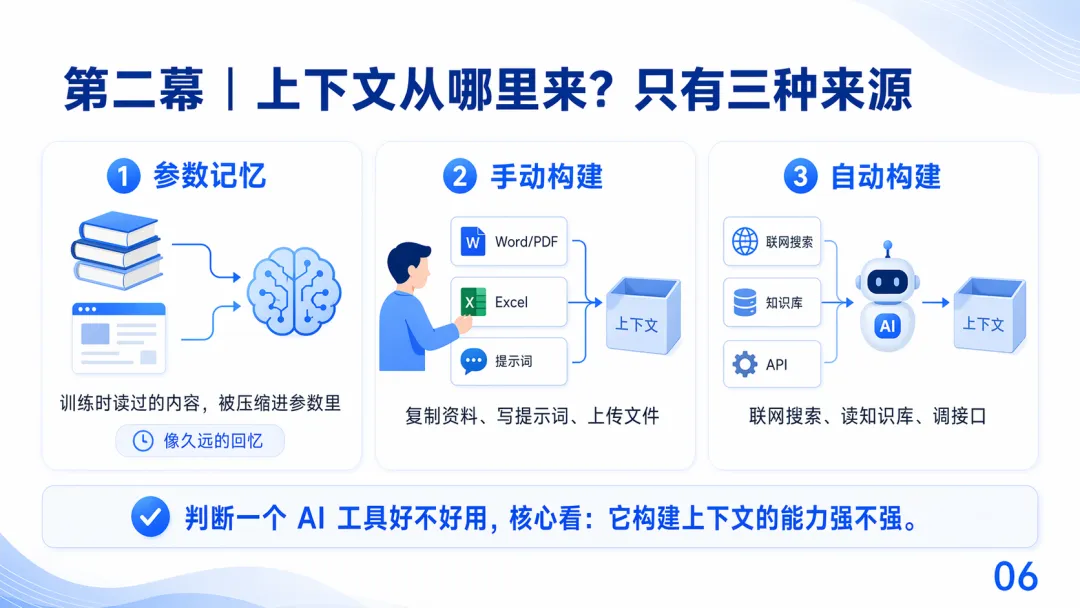
上下文嘅來源包括以下
第一種係參數記憶,即係模型訓練時讀過嘅海量內容,被壓縮咗入模型權重入面,呢個係廣義上嘅上下文
第二種係手動構建,人將 Word、Excel、提示詞呢啲材料餵入去
第三種係自動構建,AI 通過各種工具調用,自己聯網搜索、查知識庫、調用接口
判斷一個 AI 工具好唔好用,睇佢構建上下文嘅能力就夠
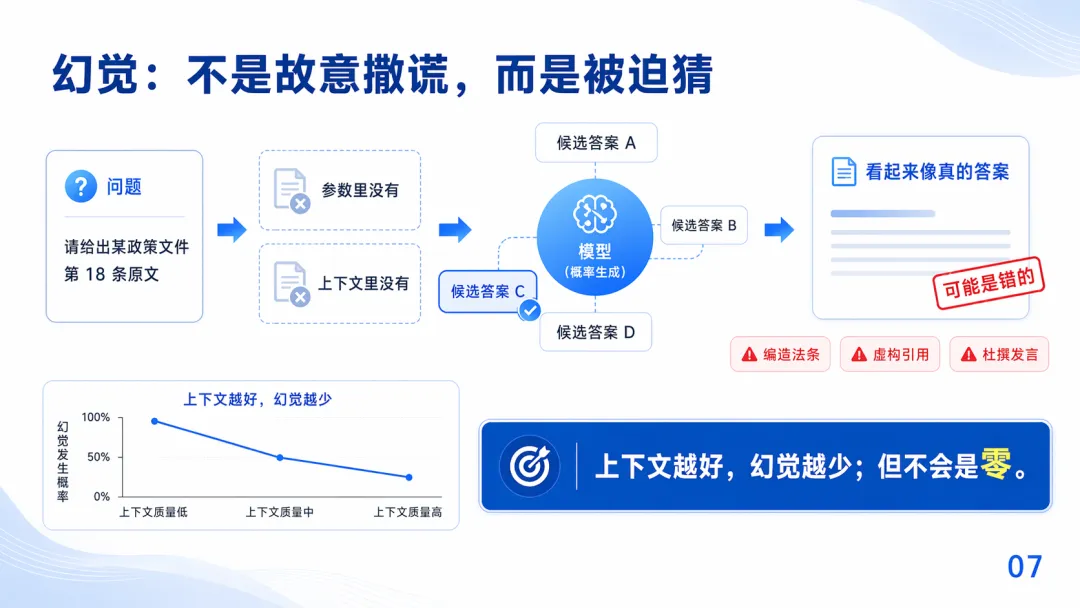
我哋設想嚇,如果叫 AI 俾某政策文件第 18 條原文,但模型訓練嘅時候又冇訓練到,咁會發生咩事?
參數入面冇呢條原文,上下文入面都冇,但佢被要求一定要俾答案。於是模型從幾個睇落合理嘅候選入面估咗一個,輸出嘅嘢形式上好似真,但可能係錯。呢個就係幻覺嘅產生過程
上下文越好,幻覺越少,但唔會係零
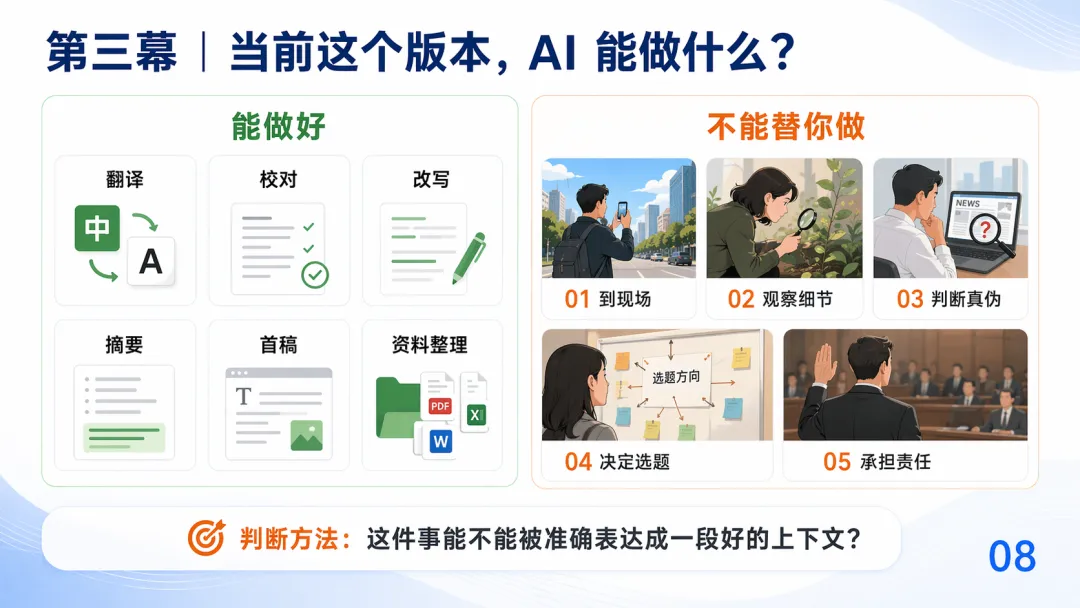
現時嘅 AI 做到好多嘢,包括翻譯、校對、改寫、摘要、初稿、資料整理在內嘅好多工作,都能夠好好咁解決。嗰陣你會發現一個共通點:AI 做得好好嘅工作,背後嘅素材都能夠準確表達成一段上下文
但係有啲嘢係 AI 做唔到嘅呢?去到現場、觀察細節、判斷真偽、決定選題、承擔責任...,呢啲做唔到。
點樣判斷一件事交俾 AI 合唔合適?睇嚇佢能唔能夠準確表達成一段好嘅上下文

對於大家嚟講,尤其係媒體工作者,喺用 AI 嘅過程中,我有三條落地建議:
跟蹤 AI 進展:盯實模型官方、開發者社區同可信媒體,每週固定 30 分鐘就夠。
自己上手:俾夠上下文(任務、材料、輸出格式),唔好糾結提示詞嘅話術
恪守紅線:事實、引述、數據、法例一定要人手核對,敏感資訊唔好餵外部模型,重要稿件一定要人審

喺 AI 嘅加持下,內容生產嘅方法都要跟貼時代,都要有所堅守:唔好拒絕用 AI,但亦唔好盲目用,更加唔好製造賽博垃圾
以往,媒體主力係自己寫內容,而將來越來越多係為 AI 提供準確嘅上下文
媒體要承擔嘅,係去現場係拎最稀缺嘅上下文,做採訪係拎人哋拎唔到嘅上下文,睇材料係篩選上下文,做判斷係組織上下文
AI 係一個需要被餵養嘅系統,喂乜嘢,就決定佢吐出乜嘢
TALK
前幾天,我在新華社做了場兩小時的內部分享,聊了許多東西
結束後跟新華社的朋友聊,覺得「大模型的原理和用法」的這部分內容對很多人都有用,今天就把這些東西貼出來,每頁配一段說明
整場分享中,我都在圍繞一個詞展開論述:上下文
AI 的能力、問題和用法,本質都由上下文決定。用戶發一條請求,AI 把請求和它能拿到的所有材料拼在一起,組成一段完整的上下文,再往下生成結果...循環往復
大模型之所以神奇、為什麼有時候不靠譜、以及怎麼能用好,都依賴於對上下文的構建
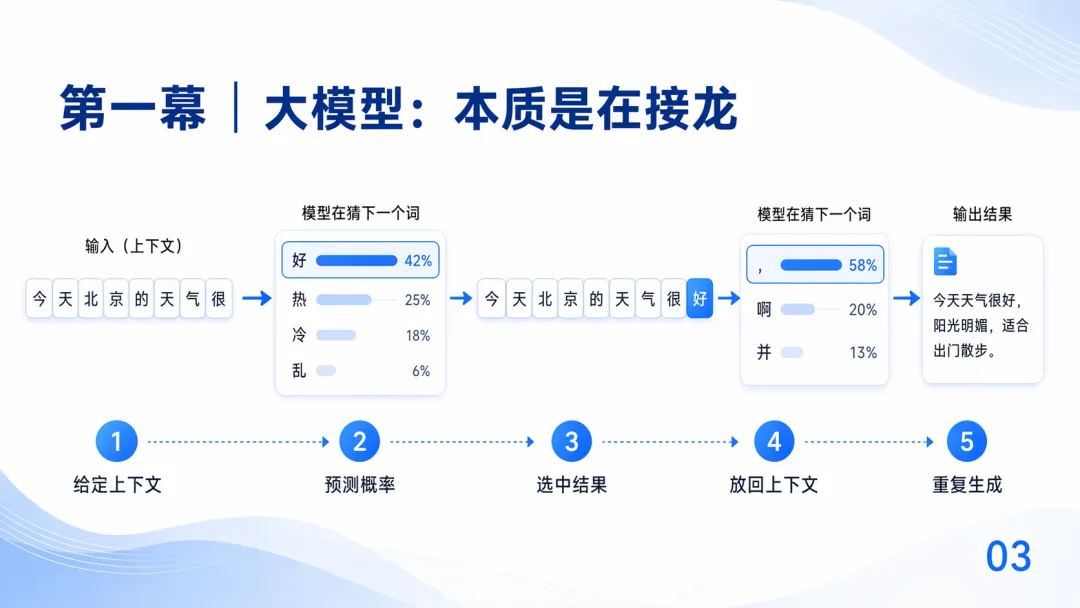
大模型在進行內容生成的原理,其實很簡單:大模型會根據上文信息,不斷推測下一組文字最大概率是什麼,而這組文字,就叫做 token,他可以是一個字、一個詞或者一些信息
這裏我來舉一個例子:「今天北京的天氣很」後面接什麼?
首先,模型給出四個候選詞,「好」42%,「熱」25%,「冷」18%,「亂」6%;接着模型會選中概率最高的「好」,放回上下文,繼續猜下一個...循環往復
這個循環在大模型生成的過程中不斷重複:給定上下文,預測概率,選中結果,放回上下文,重複生成...不管參數多大,模型都在做這一件事
ChatBot 和週報生成器看起來是兩種產品,底層流程完全一樣
系統預設一段上文(提示詞、歷史對話、頁面模板),加上用戶輸入,交給模型接龍,最後把結果填回界面
記住:無論 UI 是聊天框還是報表,內核跑的都是同一套「預設上文 + 用戶輸入 + 模型生成」
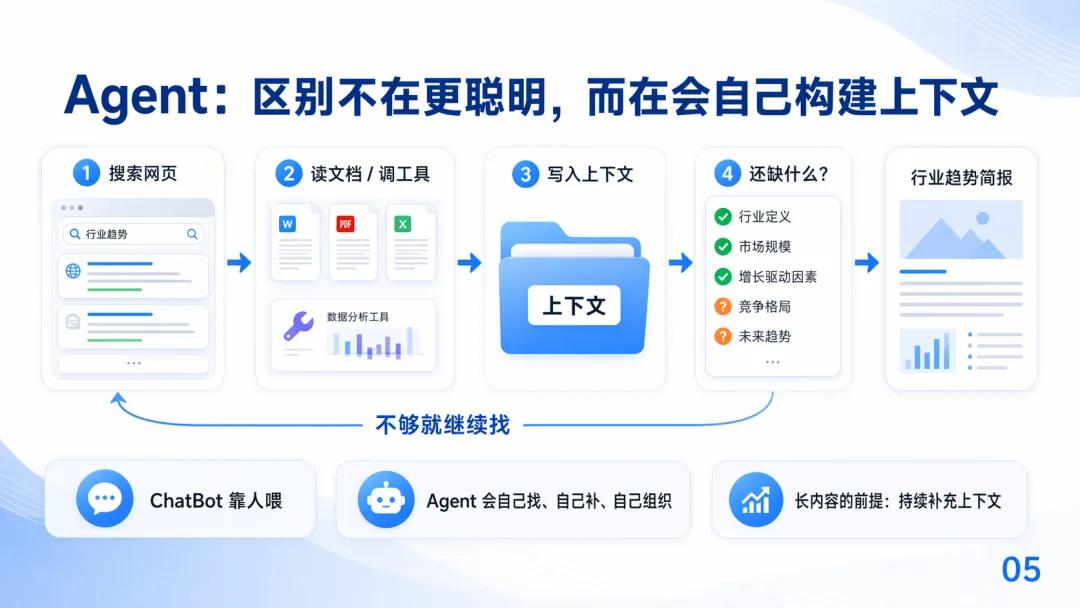
Agent 和 ChatBot 的區別在一件事上:誰來構建上下文
ChatBot 靠人喂,你給它什麼材料它就用什麼材料
Agent 會自己搜網頁、讀文檔、調工具,把有用的內容寫進上下文,發現不夠還會自動回頭繼續找
上下文的來源,包括以下
第一種是參數記憶,也就是模型訓練時讀過的海量內容,被壓縮進了模型權重裏,這是廣義上的上下文
第二種是手動構建,人把 Word、Excel、提示詞這些材料喂進去
第三種是自動構建,AI 通過各種工具調用,自己聯網搜索、查知識庫、調接口
判斷一個 AI 工具好不好用,看它構建上下文的能力就夠了
我們設想一下,如果讓 AI 給出某政策文件第 18 條原文,但模型訓練的時候又沒有訓練到,那麼會發生什麼?
參數裏沒有這條原文,上下文裏也沒有,但它被要求必須給答案。於是模型從幾個看起來合理的候選裏猜了一個,輸出的東西形式上很像真的,但可能是錯的。這就是幻覺的產生過程
上下文越好,幻覺越少,但不會是零
現在的 AI,能夠做很多的事情,包括翻譯、校對、改寫、摘要、首稿、資料整理在內的很多工作,都能夠很好的被解決。這時候你能發現一個共通點:AI 能做好的工作,其背後的素材都能被準確表達成一段上下文
但是哪些事情是 AI 做不到的呢?到現場、觀察細節、判斷真偽、決定選題、承擔責任...,這些做不到。
怎麼判斷一件事交給 AI 合不合適?看它能不能被準確表達成一段好的上下文
對於大家來說,尤其是媒體工作者來說,在使用 AI 的過程中,我有三條落地建議:
跟蹤 AI 進展:盯模型官方、開發者社區和可信媒體,每週固定 30 分鐘夠了。
自己上手:給夠上下文(任務、材料、輸出格式),別糾結提示詞話術
恪守紅線:事實、引語、數據、法條必須人工核驗,敏感信息不喂外部模型,重要稿件必須人審
在 AI 的加持下,內容生產的方法也要跟進時代,也要有所恪守:不要拒絕使用 AI,但也不要盲目使用,更不要去製作賽博垃圾
過去,媒體是主要自己寫內容,而未來越來越多是在為 AI 提供準確的上下文
媒體要承擔的,是去現場是在拿最稀缺的上下文,做採訪是在拿別人拿不到的上下文,看材料是在篩選上下文,做判斷是在組織上下文
AI 是需要被餵養的系統,喂什麼,決定它吐什麼