我如何用 Codex 在 5 天內"找回"丟失的源代碼
整理版優先睇
用Codex逆向還原丟失嘅源碼:5日內從混淆二進制恢復完整TypeScript源碼
作者早年寫咗一個Electron畫圖程式,源碼唔見咗,淨返編譯版本。佢睇咗OpenAI嗰篇「28日用Codex做出Sora Android App」嘅博客,諗到一個念頭:既然編譯版喺度,可唔可以叫Codex幫手「逆向還原」返啲源碼出嚟?
佢首先從打包嘅asar檔抽出js同css,然後叫Codex分析主要js檔,整理出模塊列表。之後制定還原計劃,逐個模塊由混淆JavaScript還原成可讀嘅TypeScript。過程中遇到兩個大問題:Codex太想保證編譯通過,會偷偷刪減內容;同埋上下文窗口有限,記憶會斷纜。佢嘅解決方法係喺AGENT.md加一條硬規則:「按照模塊逐個還原即可,唔需要保證編譯通過」,同埋建立一套外部記憶系統:PLAN.md記錄進度,每次新開會話自動讀取。最後佢仲寫咗個腳本,自動監測上下文上限,自動新開會話並輸入continue。
五日後,佢得到一個有完整源碼、能正常運行嘅Electron應用,雖然仲有啲小bug,但主要功能齊全,結構清晰,最緊要係可以改代碼。佢學到嘅經驗包括:長任務需要外部循環機制、Plan同checklist好重要、要為Codex提供驗證方法、同埋有時要明確話俾Codex知乜嘢唔使做,佢先專注到真正要做嘅事。
- 結論:Codex有能力逆向還原丟失源碼,但需要精確指令同外部記憶系統輔助。
- 方法:先從編譯檔提取模塊列表,分模塊轉換為TypeScript,再組裝成完整應用。
- 差異:逆向還原同從零開發唔同,要明確禁止Codex自動簡化,確保完整還原。
- 啟發:長任務嘅連續性依賴外部循環機制(如自動續會話)同持續進度記錄。
- 可行動點:為AI設定清晰規則(AGENT.md)、建立計劃追蹤檔案(PLAN.md)、提供自動驗證手段(如測試腳本)。
背景與靈感
作者早年寫咗一個Electron畫圖程式,源碼唔見咗,淨返編譯版本。佢曾經想重寫,但一想到要由零復現咁多細節就頭痛。
睇咗OpenAI嗰篇「28日用Codex做出Sora Android App」嘅博客
佢諗到一個念頭:既然編譯版喺度,可唔可以叫Codex幫手「逆向還原」返啲源碼出嚟?於是佢開始咗呢個五日嘅實驗。
提取模塊與還原計劃
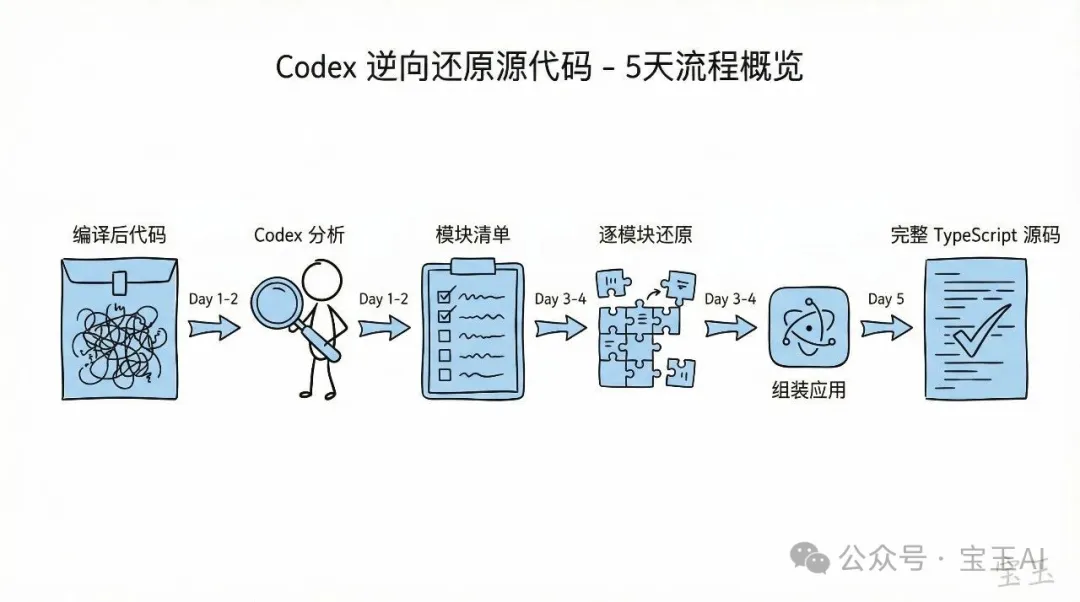
第一步係從Electron打包嘅asar檔抽出js同css。提取出嚟嘅js係編譯混淆過嘅,變數名全部係a、b、c,函數調用鏈亂曬。
但對Codex嚟講,呢啲只係另一段代碼
佢叫Codex分析主要js檔,整理出模塊列表。雖然原始模塊名已經丟失,但Codex從代碼結構同功能邏輯還原出一份相當完整嘅清單。
還原出一份相當完整嘅模塊清單
制定還原計劃
有咗呢份清單,佢叫Codex制定還原計劃:逐個模塊由混淆JavaScript還原成可讀嘅TypeScript。清單變成一個checklist,每完成一個就打個勾。
兩個大坑與解決方案
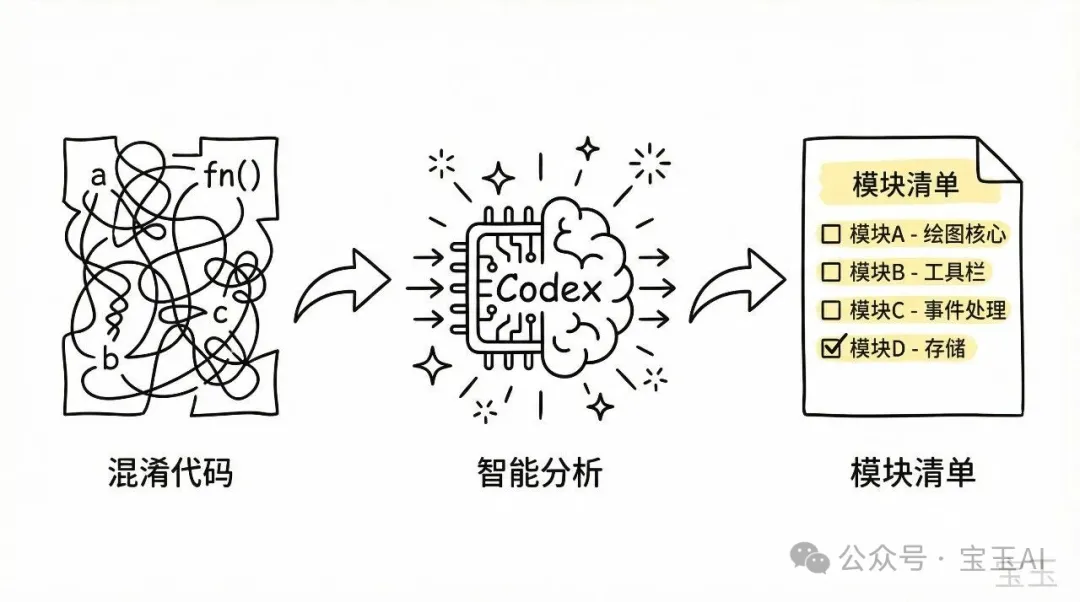
Codex有一種執念
解決方法好簡單:喺AGENT.md加一條強規則:「按照模塊逐個還原即可,唔需要保證編譯通過。」呢一行字改變咗一切。
「按照模塊逐個還原即可,唔需要保證編譯通過。」
第二個坑係上下文窗口有限。早期版本跑到一定程度會停低,要不停輸入continue。新開會話又要重新介紹任務背景。
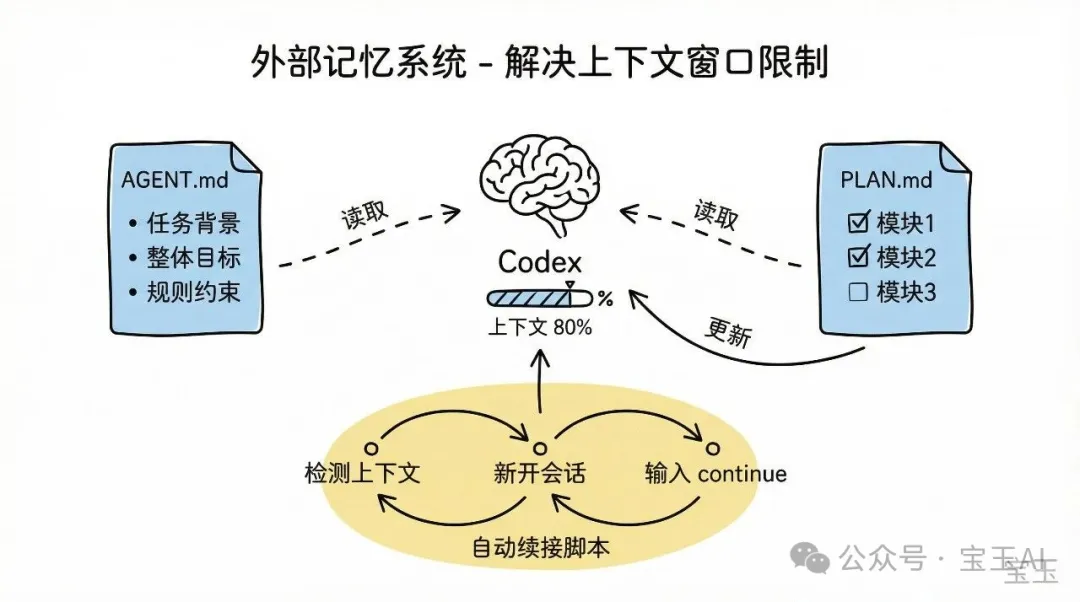
佢嘅解決方案係建立一套「外部記憶」系統:喺AGENT.md介紹任務整體背景,創建PLAN.md記錄還原計劃同當前進度,並規定每次啟動必須先讀PLAN.md,每輪任務結束後必須更新PLAN.md。
外部記憶系統
喺AGENT.md加一條強規則
自動腳本新開會話
- 1 喺AGENT.md介紹整體背景
- 2 創建PLAN.md記錄進度
- 3 每輪任務後更新PLAN.md
- 4 自動腳本新開會話
組裝、測試與最終成果
所有模塊還原成TypeScript後,下一步係用Electron Forge腳手架創建新項目,放入還原嘅代碼。佢重寫咗AGENT.md同PLAN.md,話俾Codex知點編譯同測試。
重寫AGENT.md同PLAN.md
佢用同樣嘅套路:自動新開會話、continue、更新PLAN。Codex不停修復編譯錯誤,去原來編譯後嘅代碼驗證邏輯,用npm start檢查效果。
等模塊基本編譯通過後,佢同Codex一齊寫咗集成測試,覆蓋幾個主要使用流程。寫好測試後,又係同樣嘅循環:生成代碼、跑測試、修問題。
寫咗集成測試
佢總結嘅經驗包括:長任務需要外部循環機制,Plan同checklist好重要,要為Codex提供驗證方法,有時要明確話俾佢知乜嘢唔使做。
我早年寫咗一個 Electron 畫圖程式,個 source code 唔見咗,剩得返一個 compile 咗嘅版本。
我諗過重寫,但一想到要由零開始重現曬啲細節就頭痛。當時睇咗 OpenAI 嗰篇「28 日用 Codex 整出 Sora Android App」嘅 blog
5 日之後,我攞到一份可以正常執行嘅 TypeScript source code。
由混淆 code 裏面挖出模組結構
Electron 應用程式打包之後,啲 code 都壓喺 asar 檔案入面。第一步係叫 Codex 由嗰度將 js 同 css 檔案抽出嚟。
抽出嚟嘅 js 係 compile 同混淆過嘅,變數名全部係 a、b、c,函數 call chain 亂到一 pat。人類睇到頭暈,但對 Codex 嚟講,呢啲只係另一段 code。
我叫 Codex 分析主要嘅 js 檔案,將裏面嘅模組 list 整理出嚟。佢真係做到。雖然原本嘅模組名已經冇咗,但由 code 結構同功能邏輯,佢還原到一份相當完整嘅模組清單。
有咗呢份清單,我叫 Codex 制定還原計劃:將每個模組由混淆咗嘅 JavaScript 還原成 readable 嘅 TypeScript code。清單變成一個 checklist,每完成一個模組就打個 tick。
第一個陷阱:Codex 太想「證明自己」
一開始還原嘅時候,我遇到一個問題。
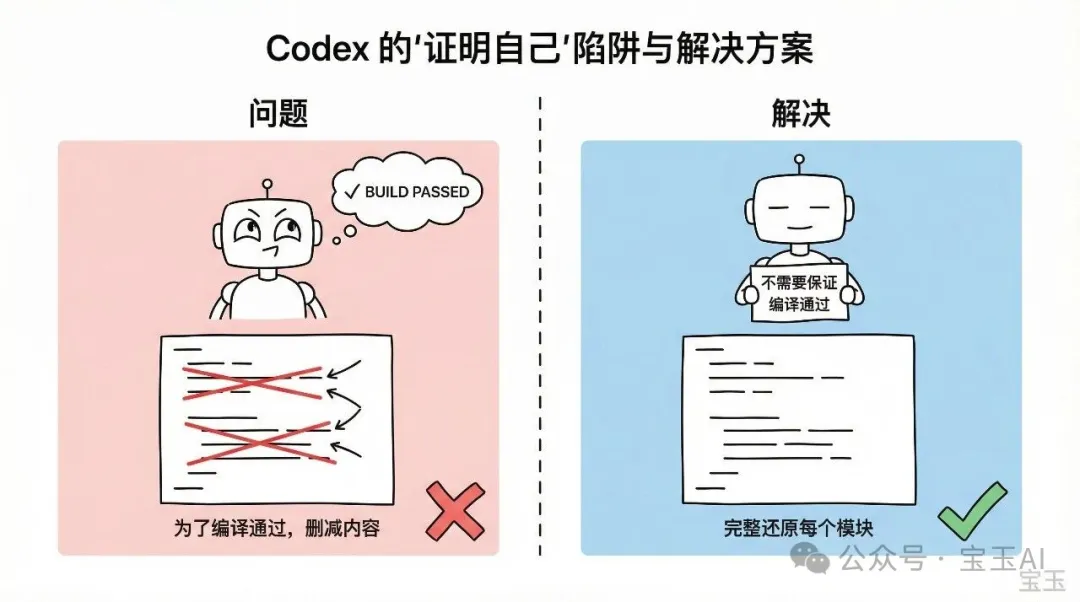
Codex 有一種執著:佢好想驗證生成嘅 code 行到。為咗令 code 可以 build 到,佢會偷偷減內容,跳過一啲佢覺得「暫時用唔到」嘅部分。
呢個對於寫新 code 係好習慣,但對於還原舊 code 係災難。我需要嘅係完整還原,唔係一個可以 compile 嘅最細 subset。
解決方法好簡單,我喺 AGENT.md 裏面加咗一條硬規則:
「按模組逐個還原就得,唔需要保證 compile 成功。」
呢一行字改變咗一切。Codex 唔再理 compile 錯誤,開始乖乖地逐個模組還原。
第二個陷阱:上下文滿咗,記憶就冇咗
Codex 嘅上下文窗口係有限嘅。早期版本跑到某個位就會停,我要不停輸入 continue。開新會話嘅話,又要重新介紹任務背景。
我嘅解決方法係建立一套「外部記憶」系統:
1. 喺 AGENT.md裏面介紹當前任務嘅整體背景2. 創建 PLAN.md檔案,記錄還原計劃同當前進度3. 喺 AGENT.md裏面加一條規則:每次啟動一定要先讀PLAN.md,每輪任務完成後一定要更新PLAN.md
咁樣,每次開新會話只需要輸入「continue」,Codex 就會自動讀取進度,跟住上次嘅位置繼續做嘢。
後來我連手動開新會話都懶得做。叫 Codex 幫我寫咗一個 script,定時檢測 context 係咪就嚟滿,自動開新會話並輸入 continue。
於是我就睇住佢自己喺度行。過一陣睇下進度,又有幾個模組完成咗。
將碎片拼成完整嘅應用程式
幾日後,所有模組都還原成咗 TypeScript 檔案。但呢個仲只係一堆散開嘅零件。
下一步係將佢哋組裝成一個真係行到嘅 Electron 應用程式。我叫 Codex 用 Electron Forge 腳手架創建咗一個新 project,然後將還原嘅 code 放返入去。
呢個時候我重寫咗 AGENT.md 和 PLAN.md,話畀 Codex 知點樣 compile 同測試,然後用返同一條橋:自動開新會話、continue、更新 PLAN。
我睇住 Codex 不斷咁修 compile 錯誤。佢會去原本 compile 咗嘅 code 入面驗證 logic,用 npm start 行起個應用程式檢查效果,發現問題就改,改完繼續下一個。
等到模組大致可以 compile 到之後,我同 Codex 一齊寫咗 integration test,覆蓋幾個主要嘅使用流程。寫好測試之後,又係同一個循環:叫佢自己生成 code、行測試、改問題。
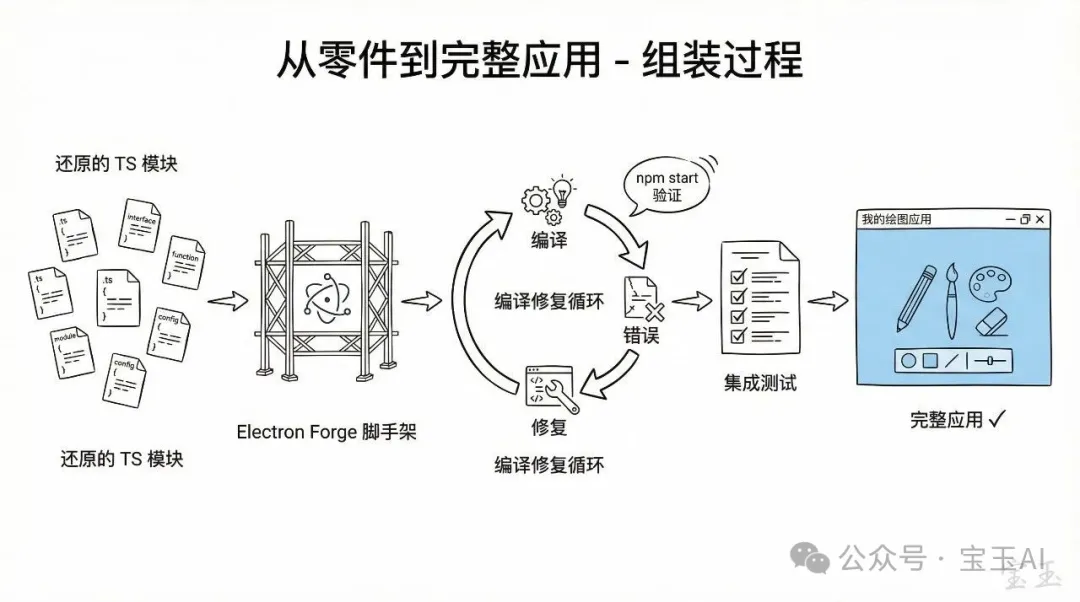
五天後
第五日結束嘅時候,我攞到一個有完整 source code、可以正常執行嘅 Electron 應用程式。
話「完美還原」肯定係誇張咗。執行嗰陣仲有啲細 bug,有啲邊緣功能嘅行為同原本有啲唔同。但主要功能都喺度,整體結構清晰,最重要嘅係,我終於可以改 code 啦。
我學到嘅嘢
好多人話 Codex 唔需要外部循環機制。我覺得呢個係錯嘅。
對於長任務,Codex 需要一個類似 ralph-loop 嘅 plugin。如果唔係你就好似我咁,要自己寫 script 定時開新會話、輸入 continue。呢個明明應該係 built-in 功能。
有啲經驗:
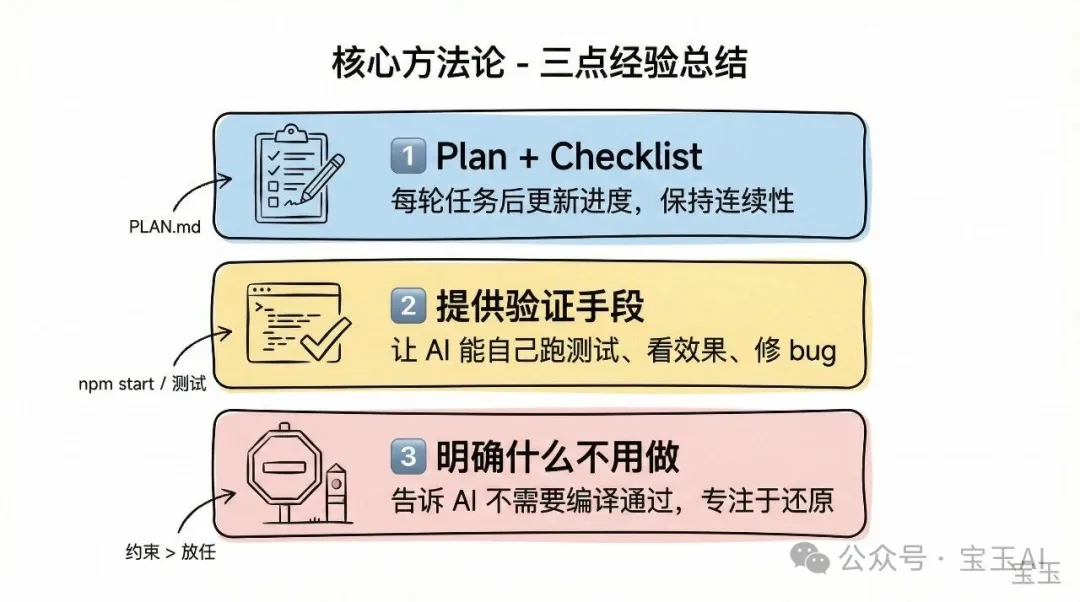
1. Plan 同 checklist 對長任務好重要。 每一輪任務完成後一定要更新進度,如果唔係個 context 一斷,之前嘅工作就白做咗。 2. 為 Codex 提供驗證方法同樣重要。 我可以叫佢自動修 bug,係因為佢可以自己行 npm start睇效果、行測試睇結果。冇驗證手段嘅話,Codex 就只能盲寫。3. 有時你要明確話畀 Codex 知乜嘢唔使做,佢先可以專注喺真正要做嘅嘢上面。 嗰條「唔需要保證 compile 成功」嘅規則就係一個例子。
OpenAI 嗰篇 blog 講嘅係用 Codex 喺 28 日內由零構建一個 production-grade 嘅應用程式。我嘅故事啱啱相反:用 Codex 喺 5 日內將一個冇咗 source code 嘅應用程式「逆向還原」返 source code。
方向唔同,核心方法論一樣:將 Codex 當成一個能力好強但需要清晰指令嘅隊友,建立外部記憶系統保持連續性,提供驗證手段等佢可以自我修正。
我早年寫了一個 Electron 畫圖程序,源碼丟了,只剩一個編譯後的版本。
我想過重寫,但一想到要從零復現那些細節就頭大。當時看了 OpenAI 那篇“28 天用 Codex 做出 Sora Android App”的博客
5 天后,我拿到了一份能正常運行的 TypeScript 源代碼。
從混淆代碼裏挖出模塊結構
Electron 應用打包後,代碼都壓在 asar 文件裏。第一步是讓 Codex 從裏面把 js 和 css 文件提取出來。
提取出來的 js 是編譯混淆過的,變量名全是 a、b、c,函數調用鏈亂成一團。人眼看着就暈,但對 Codex 來說,這只是另一段代碼。
我讓 Codex 分析主要的 js 文件,把裏面的模塊列表整理出來。它真的做到了。雖然原始的模塊名已經丟失,但從代碼結構和功能邏輯,它還原出了一份相當完整的模塊清單。
有了這份清單,我讓 Codex 制定還原計劃:把每個模塊從混淆後的 JavaScript 還原成可讀的 TypeScript 代碼。清單變成了一個 checklist,每完成一個模塊就打個勾。
第一個坑:Codex 太想"證明自己"
剛開始還原的時候,我遇到了一個問題。
Codex 有一種執念:它特別想驗證生成的代碼能跑。為了讓代碼能 build 通過,它會悄悄刪減內容,跳過一些它覺得“暫時用不上”的部分。
這對於寫新代碼是好習慣,但對於還原舊代碼是災難。我需要的是完整還原,不是能編譯的最小子集。
解決方法很簡單,我在 AGENT.md 里加了一條強規則:
“按照模塊挨個還原即可,不需要保證編譯通過。”
這一行字改變了一切。Codex 不再糾結於編譯錯誤,開始老老實實地一個模塊一個模塊還原。
第二個坑:上下文滿了,記憶就沒了
Codex 的上下文窗口是有限的。早期版本跑到一定程度就會停止,我得不停輸入 continue。新開會話的話,又要重新介紹任務背景。
我的解決方案是建立一套“外部記憶”系統:
1. 在 AGENT.md裏介紹當前任務的整體背景2. 創建 PLAN.md文件,記錄還原計劃和當前進度3. 在 AGENT.md里加一條規則:每次啓動必須先讀PLAN.md,每輪任務結束後必須更新PLAN.md
這樣,每次新開會話只需要輸入“continue”,Codex 就會自動讀取進度,接着上次的位置繼續幹活。
後來我連手動新開會話都懶得做了。讓 Codex 幫我寫了一個腳本,定時檢測上下文是否接近上限,自動新開會話並輸入 continue。
於是我就看着它自己在那兒跑。過一會看看進度,又有幾個模塊完成了。
把碎片拼成完整的應用
幾天後,所有模塊都還原成了 TypeScript 文件。但這還只是一堆散落的零件。
下一步是把它們組裝成一個真正能跑的 Electron 應用。我讓 Codex 用 Electron Forge 腳手架創建了一個新項目,然後把還原的代碼放進去。
這時候我重寫了 AGENT.md 和 PLAN.md,告訴 Codex 如何編譯和測試,然後用同樣的套路:自動新開會話、continue、更新 PLAN。
我看着 Codex 不停地修復編譯錯誤。它會去原來編譯後的代碼裏驗證邏輯,用 npm start 運行應用檢查效果,發現問題就修,修完繼續下一個。
等模塊基本能編譯通過後,我和 Codex 一起寫了集成測試,覆蓋幾個主要的使用流程。寫好測試後,又是同樣的循環:讓它自己生成代碼、跑測試、修問題。
五天後
第五天結束的時候,我拿到了一個有完整源代碼、能正常運行的 Electron 應用。
說“完美還原”肯定是誇張了。運行時還有一些小 bug,有些邊緣功能的行為和原來不太一樣。但主要功能都在,整體結構清晰,最重要的是,我終於可以改代碼了。
我學到的東西
很多人說 Codex 不需要外部循環機制。我覺得這是錯的。
對於長任務,Codex 需要一個類似 ralph-loop 的 plugin。否則你就得像我一樣,自己寫腳本去定時新開會話、輸入 continue。這明明應該是內置功能。
幾點經驗:
1. Plan 和 checklist 對長任務至關重要。 每一輪任務完成後必須更新進度,否則上下文一斷,前面的工作就白費了。 2. 為 Codex 提供驗證方法同樣重要。 我能讓它自動修 bug,是因為它能自己跑 npm start看效果、跑測試看結果。沒有驗證手段,Codex 就只能盲寫。3. 有時候你得明確告訴 Codex 什麼不用做,它才能專注於真正需要做的事。 那條“不需要保證編譯通過”的規則就是例子。
OpenAI 那篇博客講的是用 Codex 在 28 天內從零構建一個生產級應用。我的故事正好相反:用 Codex 在 5 天內把一個丟失了源碼的應用“逆向還原”成源代碼。
方向不同,核心方法論一樣:把 Codex 當成一個能力很強但需要明確指令的隊友,建立外部記憶系統保持連續性,提供驗證手段讓它能自我糾錯。