我把 Hermes 裏的模型幾乎測了一遍,得出一個很扎心的結論:越貴的,往往越強
整理版優先睇
模型價格往往與生產力成正比,GLM-5.1 在真實 Agent 任務中的執行力已超越 GPT-4o 級別模型。
這篇文章由資深 AI 實踐者孟健撰寫,分享他在使用 Hermes(終端 Agent 工具)過程中,對多款主流大模型進行深度實測後的真實體感。作者試圖解決在複雜生產鏈路中,如何選擇最合適模型作為「主力底座」的問題,而非單純依賴官方的 Benchmark 數據。
作者指出,模型真正的成本不應只看 API 單價,更要計算返工、吞吐及調度等隱形成本。整體結論是:目前的模型市場價格體系非常誠實,「性價比榜」倒過來讀就是「質量榜」。在 Agent 執行力、中文工程語境及長流程穩定性上,國產模型 GLM-5.1 展現出極強的競爭力,甚至在某些維度優於 GPT 與 Gemini。
- 核心結論:模型質量與價格高度掛鈎,便宜模型帶來的幻覺與返工成本,往往遠超其節省的 API 費用。
- 模型梯隊:GLM-5.1 位居第一梯隊,執行欲強且不廢話;GPT 5.4 與 Gemini 3.1 Pro 緊隨其後,但 GPT 存在過度解釋的問題。
- 性能差異:GLM-5.1 優勢在於中文工程語境穩、長流程不鬆動,但缺點是限頻(Rate Limit)嚴重,影響多 Agent 併發效率。
- 避坑啟發:K2.6 雖有 SOTA 潛力但速度慢且有輕微幻覺;MiniMax 適合輕量助手;Qwen 表現中規中矩,缺乏驚喜。
- 可行動點:不要 all-in 單一模型,應建立「模型編隊」——最強模型做主力,穩定模型做 Fallback,廉價模型處理 OCR 或標題生成等雜活。
Hermes
文章中使用的生產力底座,支持多 Agent 編排、長流程任務及文件系統操作的終端工具。
別被 API 單價騙了:計算模型的三筆隱形賬
在真實的生產環境中,便宜的模型往往是最貴的。當你把模型放入 Terminal、Browser 或多輪追蹤的 Agent 鏈路時,你需要考慮以下三種隱形成本:
實測戰報:GLM-5.1 意外登頂,GPT 太過囉嗦
作者將模型按體感排序,發現 GLM-5.1 在 Agent 任務中的表現極為出色,特別是其「執行欲」——給了任務就動手,沒有多餘的場面話。
GPT 5.4 的問題在於『服務感』過重,每輪對話多出的 20% 廢話,在幾十個 Session 的 Agent 流程中是致命的負擔。
至於其他模型:K2.6 雖然上限高但速度慢且有幻覺;MiniMax 則定位於 L2 階段的快速助手,無法獨立扛起複雜流程。
最優解:構建你的「模型編隊」策略
真正的 AI 高手不會賭單一模型,而是將 Hermes 作為調度層,根據任務性質分配不同等級的勞動力。
- 主模型 (Main Agent): GLM-5.1 / GPT-4o (追求執行上限)
- 備選 (Fallback): Gemini 1.5 Pro (追求穩定性)
- 輔助 (Sub-tasks): Gemini Flash / Haiku (處理 Web Extract, OCR, 標題生成)
- 專項 (Specialized): Whisper (語音轉文字)這種編隊思維能平衡成本與效率,讓最貴的模型只處理最難的邏輯,雜活交給性價比模型。
大家好,我係孟健。
呢幾條星期我喺 Hermes 入面來回切換咗好多個模型。真係跑落去,我越嚟越肯定一件事:模型嘅水平,好多時一早已經寫咗喺個價錢度。將性價比榜倒轉嚟睇,八九不離十就係質量排行。
呢個唔係 benchmark 嘅結論。
而係我將 Hermes 當成生產底座,攞佢去跑多 Agent、長流程、寫 code 任務、資料整理之後,得出嚟嘅體感排序。


01 先畀個排序:貴,好多時都唔係亂咁貴
先睇下呢張圖。
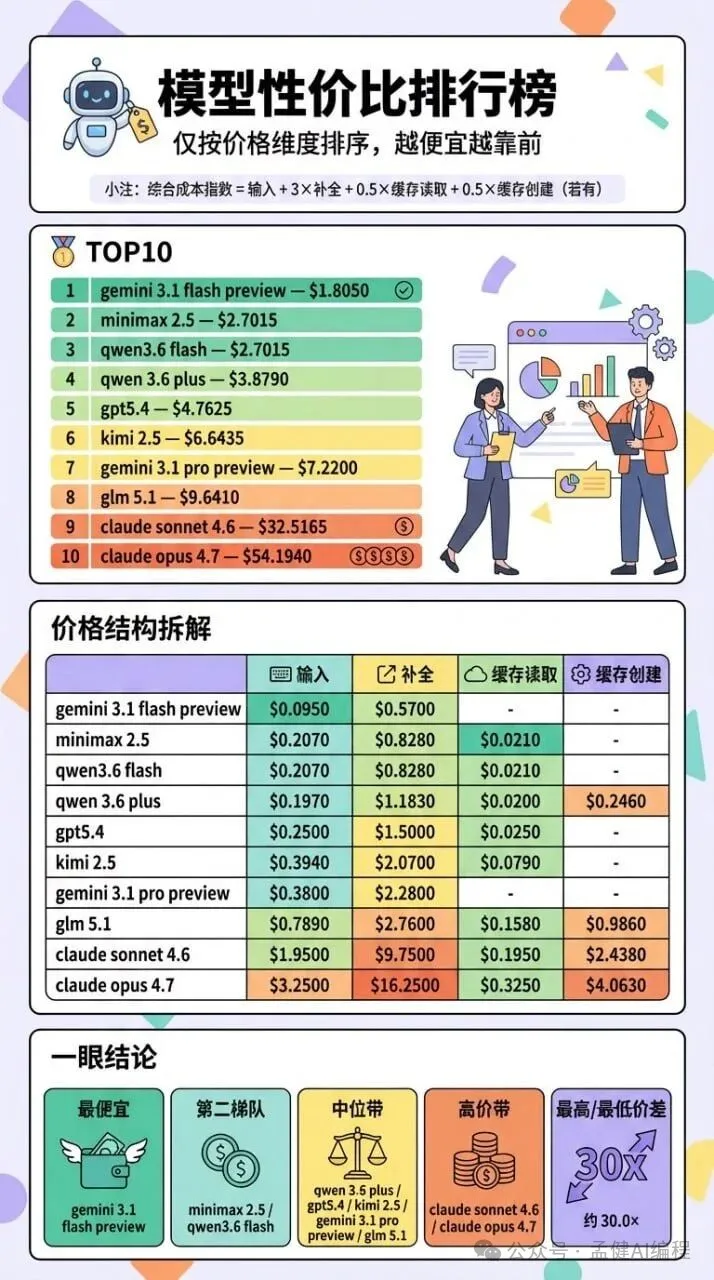
圖入面係按價錢排嘅:平嘅喺前面,貴嘅喺後面。
但我呢輪實際測完之後,如果你將佢倒轉嚟睇,佢反而更似一個質量榜。
我嘅主觀體感大致係咁:
第一梯隊:GLM-5.1 第二梯隊:GPT 5.4、Gemini 3.1 Pro 再往後:K2.6、Qwen 更偏向工具型補位:MiniMax
呢度我講緊嘅係攞嚟做 Hermes 嘅主力生產模型,唔係單輪對話,亦都唔係刷榜題目。
主力生產模型主要睇三件事:能唔能夠搞掂啲嘢、做嘢穩唔穩陣、廢話多唔多。
點解我會話「價錢倒轉嚟睇接近質量榜」?因為模型真正嘅成本,從來都唔係淨係睇 API 單價。
你仲要計埋三筆隱形賬:
重做成本:一次輕微嘅幻覺,可能換嚟成個 round 要重跑過 吞吐成本:一句多餘嘅解釋,擺落幾十個 session 入面就係半日時間 調度成本:限頻、窒機、context 鬆散,都會拖慢晒成條 pipeline
所以好多睇落好平嘅模型,只係喺張單上面平;放落生產流程入面,未必真係平。

只要你真係攞佢嚟跑 terminal、browser、file system、長 context、多輪追蹤,個排名會同好多宣傳網頁寫嘅好唔同。
平,唔代表抵。真正貴嘅係啲平模型拖爛晒你一日嘅節奏。
02 點解我而家會將 GLM-5.1 擺喺最前面
喺呢輪測試入面,我對 GLM-5.1 嘅評價係最高嘅。
唔係因為佢最平。咁啱相反,按圖入面嘅綜合成本嚟睇,佢一啲都唔平。
我將佢排到最前,原因只有一個:佢喺真實嘅 Agent 任務入面,表現比價錢更強。
同 GPT 5.4、Gemini 3.1 Pro 擺埋一齊睇,GLM-5.1 嘅優勢主要有三個:
- 執行慾更強
。畀任務就即刻郁手,唔鍾意鋪墊,亦唔鍾意講埋啲場面話。 - 中文工程語境更順
。path、config、environment variables、中英混合說明,佢都處理得更穩陣。 - 長流程入面唔容易鬆散
。做多步任務嗰陣,推進感更強。
呢個亦都係點解我而家會將佢擺喺 Hermes 嘅主模型位優先考慮。
但佢唔係冇缺點。
GLM-5.1 最大嘅問題,唔係能力,而係限頻(Rate Limit)。
單 Agent 跑嘅話都仲算係咁。
一到多 Agent 併發,429 同埋等待時間就會搞到個節奏碎晒。你明明覺得佢個腦係夠用,但系統吞吐量上唔到去。呢個亦係佢今日唯一一個會令我猶豫嘅位。
03 其他幾個模型,我嘅真實評價
GPT 5.4:強,但太長氣
GPT 5.4 嘅問題唔係唔聰明。
係太鍾意解釋自己。
你叫佢改 config,佢先同你複述一次個 task;你叫佢查問題,佢又寫晒思路出嚟先;做完之後仲想再總結多一次。單次對話入面呢啲叫「服務感」,但放喺 Agent 流程入面,呢啲就叫拖慢吞吐量。
一個模型每輪講多 20% 廢話,放喺成日幾十個 session 入面,就係肉眼可見嘅成本同埋等待。
K2.6:能力喺度,但係慢,而且有輕微幻覺
K2.6 嘅上限唔低。
複雜任務佢做到,寫 code 嘅嘢亦接得起,好多時思路都係啱嘅。
但我而家冇將佢擺得咁前,原因亦好直接:慢。
Agent 場景唔係淨係睇答得啱唔啱,仲要睇系統有冇嗰種「推進感」。K2.6 喺呢點上面會令人等得有啲煩。
第二個問題係佢會有輕微幻覺。唔係嗰種離譜到九唔搭八嘅大話,而係細節上間唔中會行多咗半步、補多半句、幫你做咗個未經授權嘅假設。呢個問題喺有人望住嗰陣就唔算致命,但放喺自動化流程入面,就會變成要返工重做。
MiniMax:仲喺 L2 階段,優勢係夠快
MiniMax 畀我嘅感覺更似係「幫到手嘅輕量助手」,而唔係「可以獨立頂到複雜流程嘅主模型」。
我會將佢放喺速度優先、對成本敏感、就算失敗都接受到嘅環節。
如果要頂住複雜嘅生產任務,佢同前面嗰幾個唔係同一個層次。
Qwen:中規中矩,冇明顯短板,亦都冇乜驚喜
Qwen 嘅問題唔係差。
係太過普通。
你好難話佢邊度明顯翻車,但亦好難話佢喺邊個關鍵維度可以令人眼前一亮。擺喺 Hermes 呢種要長期行、多模型編排嘅系統入面,佢更似係一個「可用選項」,而唔係「必須選項」。
04 Hermes 入面真正值得做嘅,唔係賭死一個模型
我而家更認同嘅思路,唔係 all in 某一家。
係將 Hermes 當成一個模型調度層。
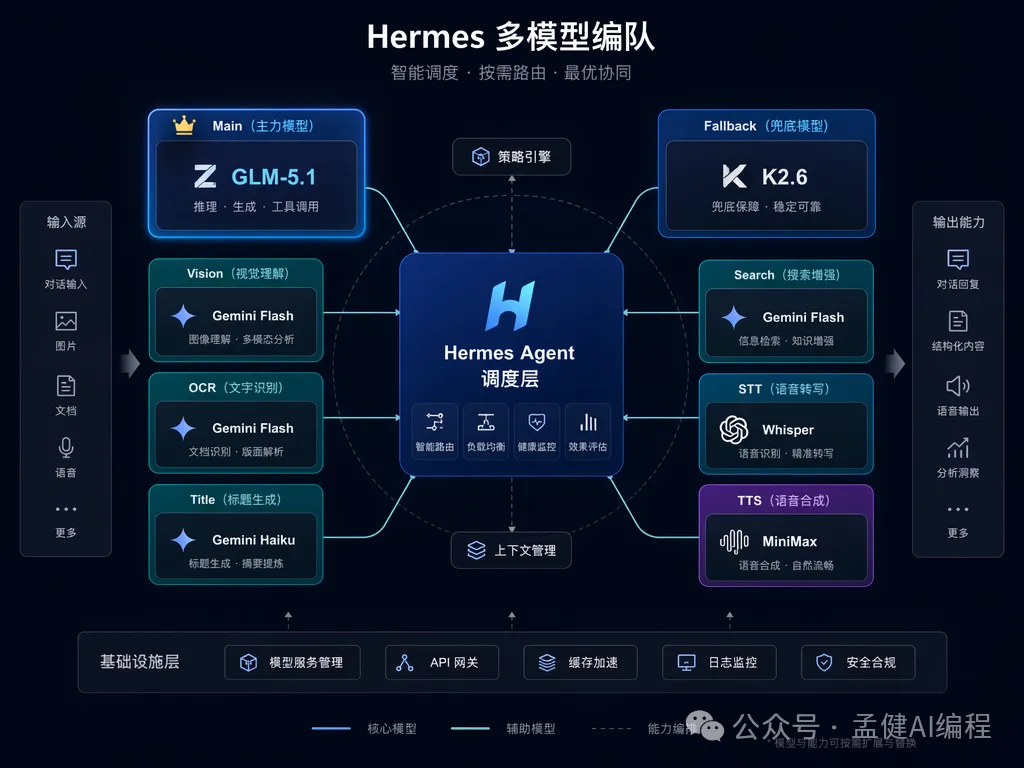
主模型可以追求上限。
Fallback 可以追求穩定。
Vision、OCR、標題生成、Session Search 呢啲輔助位,反而應該優先用性價比高嘅模型。
圖 1 入面嗰套思路,我更加認同:
主模型:邊個最幫到手,就用邊個 Fallback:邊個更穩陣,就用邊個兜底 輔助模型:邊個平得嚟又夠用,就用邊個填坑
好似圖 1 入面,Web Extract、標題生成、OCR 呢啲位,就冇必要用最貴嘅模型;可以用 Gemini Flash、Haiku、Whisper 呢類輔助模型搞掂嘅,就唔好叫主模型去燒錢。
呢個先係 Hermes 真正有趣嘅地方。
你唔係揀緊一個模型,你係砌緊一支模型編隊。
如果你問我呢輪測完有咩結論,我會講一句好唔「政治正確」嘅話:
今日嘅模型市場,價格體系已經比好多榜單更加誠實。
你將性價比榜倒轉嚟睇,基本上就知邊個應該做主力,邊個應該做備胎,邊個只係啱做雜務。
工具就擺喺度,模型亦都擺喺度。
真正拉開差距嘅,唔係你用咗邊個名氣最大嘅平台,而係你有冇將佢哋擺喺啱嘅位。
🚀 想同更多 AI 愛好者交流,一齊成長?
📚 精選文章推薦
hermes101.dev 上線喇!5 分鐘裝完、7 日入門、OpenClaw 老用家無痛遷移 由 OpenClaw、Harness 工程到世界模型全覆蓋——AI 下半場頂級大會終極議程公佈! Hermes 接入 Kimi K2.6 實測:SOTA 級代碼能力,但有兩個真實痛點 我將 Hermes 入面 23 個 Agent 全部轉晒做 GLM-5.1:執行力強過 GPT,但有個硬傷 對唔住,OpenClaw,我揀 Hermes! 我用 OpenClaw 做 Backend 開發:由 Stripe 支付到 AI 生成,全程唔使寫一行 code 突發:Anthropic 今日起封殺 OpenClaw 用訂閱額度,我嘅應對方案 一行 code 都冇手寫,OpenClaw 前端 Agent 用 100 分鐘就整完一個站 GLM-5.1 嚟喇:開源模型第一次喺長程任務上面斷層式領先 Claude Code Source Code 流出後,我反而更加肯定:終端 Agent 只係應該接 3 類 Job
大家好,我是孟健。
這幾周我在 Hermes 裏來回切了很多模型。真跑下來,我越來越確認一件事:模型的水平,很多時候早就寫在價格裏了。把性價比榜倒過來看,八九不離十就是質量排行。
這不是 benchmark 結論。
是我把 Hermes 當生產底座,拿它去跑多 Agent、長流程、代碼任務、資料整理之後,交出來的體感排序。
01 先給排序:貴,很多時候不是亂貴
先看這張圖。
圖裏是按價格排的:便宜的在前,貴的在後。
但我這輪實際測下來,如果你把它倒過來看,它反而更像質量榜。
我的主觀體感大致是這樣:
第一梯隊:GLM-5.1 第二梯隊:GPT 5.4、Gemini 3.1 Pro 再往後:K2.6、Qwen 更偏工具型補位:MiniMax
這裏我說的是拿來當 Hermes 的主力生產模型,不是單輪聊天,也不是刷榜題。
主力生產模型看三件事:能不能把活幹完,幹得穩不穩,廢話多不多。
為什麼我會說“價格倒過來接近質量榜”?因為模型真正的成本,從來不只在 API 單價裏。
你還要算三筆隱形賬:
返工成本:一次輕微幻覺,可能換來一整輪重跑 吞吐成本:一句多餘解釋,放到幾十個 session 裏就是半天 調度成本:限頻、卡頓、上下文鬆動,都會把整條鏈路拖慢
所以很多看起來便宜的模型,只是在賬單上便宜;放進生產鏈路裏,未必便宜。
只要你真的拿它跑 terminal、browser、文件系統、長上下文、多輪追蹤,排序會和很多宣傳頁很不一樣。
便宜,不代表划算。真正貴的是便宜模型把你一天節奏拖爛。
02 為什麼我現在把 GLM-5.1 放在最前面
這輪測試裏,GLM-5.1 給我的評價是最高的。
不是因為它最便宜。恰恰相反,按圖裏的綜合成本,它並不便宜。
我把它排到最前,原因只有一個:它在真實 Agent 任務裏,表現比價格更強。
和 GPT 5.4、Gemini 3.1 Pro 放一起看,GLM-5.1 的優勢主要有三個:
- 執行欲更強
。給任務就動手,不愛鋪墊,不愛講場面話。 - 中文工程語境更順
。路徑、配置、環境變量、中英混合說明,它吃得更穩。 - 長流程裏不容易鬆掉
。做多步任務時,推進感更強。
這也是為什麼我現在會把它放在 Hermes 的主模型位優先考慮。
但它不是沒缺點。
GLM-5.1 最大的問題,不是能力,是限頻。
單 Agent 跑還好。
一旦多 Agent 併發,429 和等待就會把節奏切碎。你明明感覺它腦子夠用,但系統吞吐上不去。這也是它今天唯一一個會讓我猶豫的點。
03 其他幾個模型,我的真實評價
GPT 5.4:強,但太囉嗦
GPT 5.4 的問題不是不聰明。
是太愛解釋自己。
你讓它改配置,它先給你複述任務;你讓它查問題,它先寫思路;做完之後還想再總結一遍。單次對話裏這叫“服務感”,放到 Agent 流程裏,這叫拖慢吞吐。
一個模型每輪多說 20%,放到一整天幾十個 session 裏,就是肉眼可見的成本和等待。
K2.6:能力在線,但慢,而且有輕微幻覺
K2.6 的上限不低。
複雜任務它能做,代碼活也能接,很多時候思路是對的。
但我現在沒把它放到更前面,原因也很直接:慢。
Agent 場景不是隻看答得對不對,還看系統有沒有“推進感”。K2.6 在這點上會讓人等得有點煩。
第二個問題是它會有輕微幻覺。不是那種離譜胡說,而是細節上偶爾會多走半步、補半句、替你做一個沒被授權的假設。這個問題在人盯着看的時候不致命,但放到自動鏈路裏,就會變成返工。
MiniMax:還在 L2 階段,優勢是快
MiniMax 給我的感覺更像“能幹活的輕量助手”,不是“能獨立扛複雜流程的主模型”。
我會把它放在速度優先、成本敏感、失敗可接受的環節。
如果要扛複雜生產任務,它和前面幾個不是一個檔位。
Qwen:中規中矩,沒有明顯短板,也沒有明顯驚喜
Qwen 的問題不是差。
是太普通。
你很難說它哪裏明顯翻車,但也很難說它在哪個關鍵維度把人打穿。放在 Hermes 這種要長期跑、多模型編排的系統裏,它更像一個“可用選項”,不是“必須選項”。
04 Hermes 裏真正值得做的,不是賭一個模型
我現在更認同的思路,不是 all in 某一家。
是把 Hermes 當成一個模型調度層。
主模型可以追求上限。
Fallback 可以追求穩定。
Vision、OCR、標題生成、Session Search 這些輔助位,反而應該優先用性價比高的模型。
圖1裏那套思路,我更認同:
主模型:誰最能幹活,用誰 Fallback:誰更穩,用誰兜底 輔助模型:誰便宜且夠用,用誰填坑
比如圖1裏,Web Extract、標題生成、OCR 這些位子,就沒必要上最貴模型;能用 Gemini Flash、Haiku、Whisper 這類輔助模型解決的,就別讓主模型去燒錢。
這才是 Hermes 真正有意思的地方。
你不是在選一個模型。你是在搭一支模型編隊。
如果你問我這輪測完的結論,我會給一句很不政治正確的話:
今天的模型市場,價格體系已經比很多榜單更誠實了。
你把性價比榜倒過來看,基本就知道誰該做主力,誰該當備胎,誰只適合幹雜活。
工具就擺在那裏。模型也擺在那裏。
真正拉開差距的,不是你用了哪個名字最大的平台,而是你有沒有把它們放到對的位置上。
🚀 想要與更多AI愛好者交流,共同成長嗎?
📚 精選文章推薦
hermes101.dev 上線了!5 分鐘裝完、7 天入門、OpenClaw 老用戶無痛遷移 從OpenClaw、Harness工程到世界模型全覆蓋——AI下半場頂級大會終極議程公佈! Hermes 接入 Kimi K2.6 實測:SOTA 代碼能力,但有兩個真實痛點 我把Hermes裏23個Agent全切到GLM-5.1:執行力比GPT強,但有個硬傷 對不起,OpenClaw,我選擇 Hermes! 我用 OpenClaw 做後端開發:從 Stripe 支付到 AI 生成,全程不寫一行代碼 突發:Anthropic 今天起封殺 OpenClaw 用訂閲額度,我的應對方案 一行代碼沒手寫,OpenClaw 前端 Agent 100 分鐘做完一個站 GLM-5.1 來了:開源模型第一次在長程任務上斷檔領先 Claude Code 源碼泄露後,我反而更確定:終端 Agent 只該接 3 類活