我把GPT-image-2生成PSD的能力打包成了Skill,免費開源
整理版優先睇
用 Codex 將 GPT-image-2 生成嘅圖變成可編輯 PSD,開源 Skill 拆到 12 層無殘影
AI 生成圖片雖然越來越靚,但改圖依然係一個大難題。作者發現 ChatGPT 可以透過連接 Photoshop 應用,將生成嘅合併圖拆成多個圖層再拼成 PSD,但網頁版體驗有限。
具體流程係先用提示詞叫 GPT 將圖片拆成獨立圖像(底色白色),再用 Python 嘅 psd-tools 包拼成 PSD。不過網頁版最多得 7 層圖層,而且文字同背景有時會黏埋一齊,出現殘影。
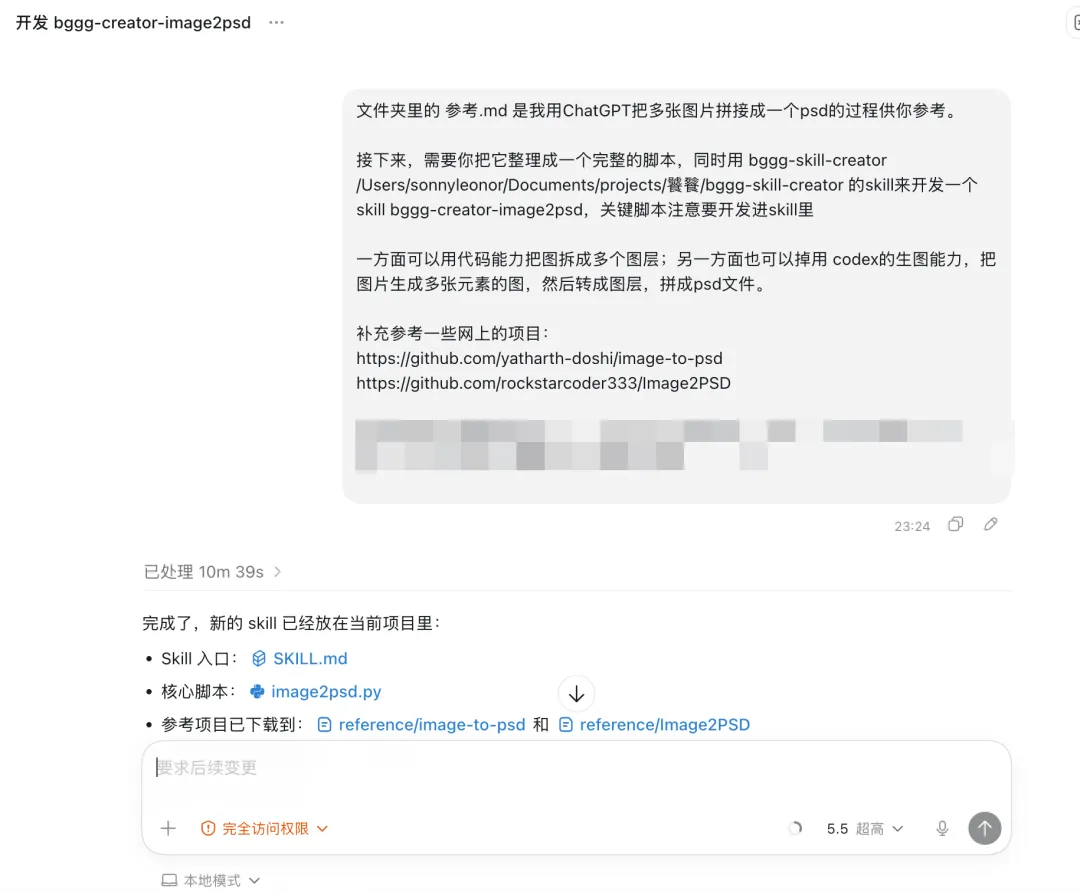
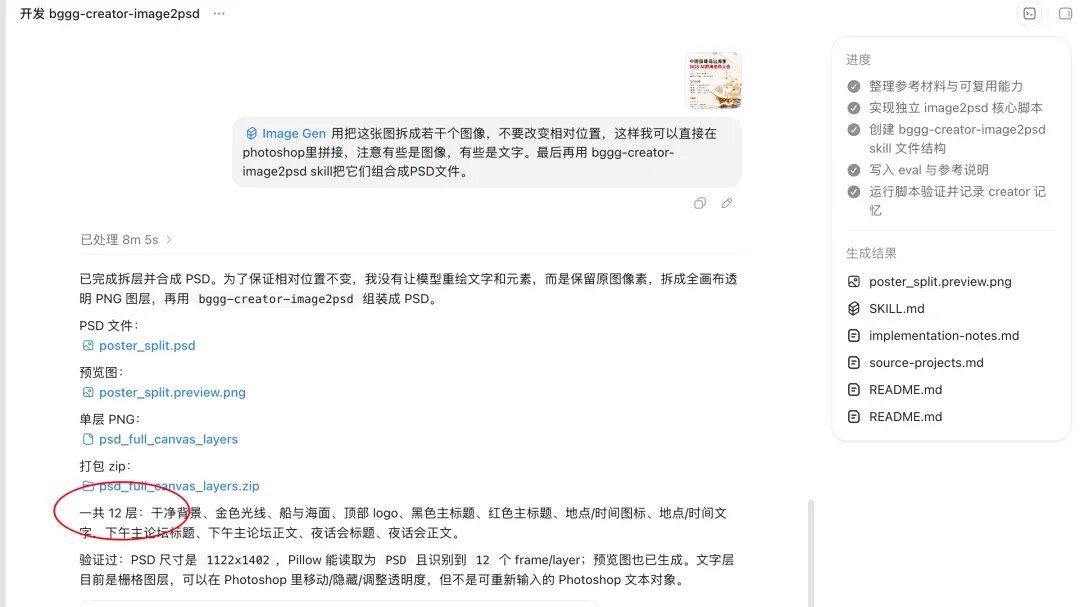
為咗提升品質,作者利用 Codex 嘅 reasoning loop 開發咗 bggg-creator-image2psd Skill。Codex 會喺執行過程中自我檢查,發現圖層有問題就自動修正參數,最後成功拆到 12 層,所有元素分離乾淨。成個 Skill 已經開源,畀大家直接用或者改進。
- AI 改圖係痛點,但 ChatGPT 可以將 Image2 生成嘅圖轉成 PSD,不過網頁端最多 7 層且易有殘影。
- 背後用 Python 嘅 psd-tools 包處理,圖層質素取決於腳本點寫,網頁版一次性生成唔會回頭檢查。
- Codex 嘅 reasoning loop 可以自動檢查中間結果並修正,用嚟拆圖層可以拆得更細更準。
- 作者開發嘅 bggg-creator-image2psd Skill 用同一張海報測試,成功拆出 12 層,冇殘影,文字、背景分開曬。
- 開源咗喺 GitHub,仲包含之前嘅饕餮 Skill,未來會繼續更新,求 stars 支持。
bggg-creator-image2psd Skill 開源地址
GitHub 倉庫,包含 Skill 原始碼同使用說明
bggg-skills 總倉庫
包含饕餮 Skill 同其他未來 Skill
網頁端嘅嘗試:7 層圖層,有殘影
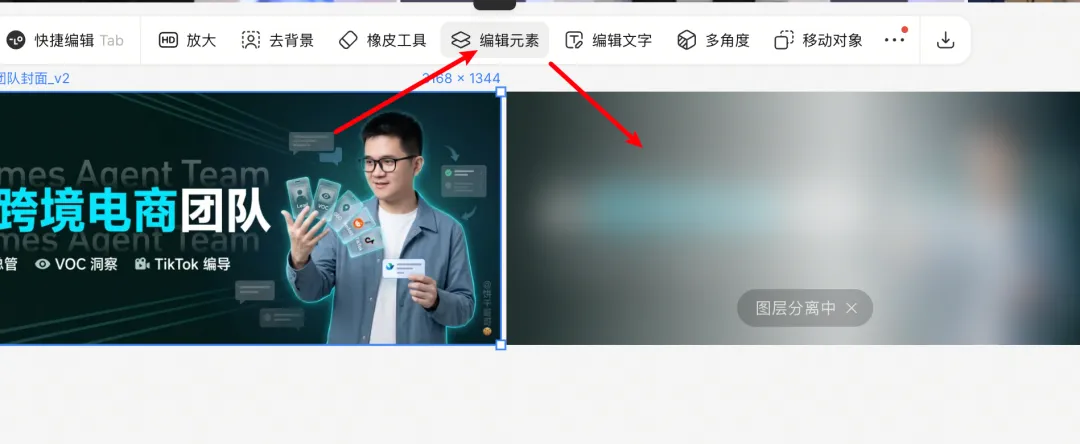
作者需要一張 AI 跨境電商大會嘅海報,用 GPT-image-2 生完之後發現係合併圖,冇得直接改文字或底色。佢諗到一個方法:先叫 ChatGPT 將海報拆成若干張獨立圖像(底色白色),再用 Photoshop 應用拼成 PSD。
接下來,我要把這張圖改成 PSD 導入 Photoshop 做編輯,所以需要你先把生成的這張海報拆成若干個圖像,不要改變相對位置,底色為白色。
根據以上拆分的圖像拼成 PSD 文件,每個圖像對應一個圖層,注意有些是圖像,有些是文字。去除白色底。給我 PSD 文件。結果拿到一個 7 層嘅 PSD,但標題下面有殘影,文字同背景圖合埋一齊。呢個係網頁端嘅極限,一次性生成唔會回頭修正。
網頁端最多 7 層圖層,而且有殘影
偷睇背後技術:Python 嘅 psd-tools 包
作者翻查 ChatGPT 嘅思考過程,發現佢背後用咗 Python 嘅 psd-tools 包嚟處理圖像拆分同拼裝。換句話講,圖層拆得細唔細,取決於 Python 腳本點寫,而網頁端係一次性生成,唔會自我檢查。
於是作者決定將呢套流程開發成一個 Codex Skill,利用 reasoning loop 嘅自檢能力。
用 Codex 開發 Skill:12 層,冇殘影
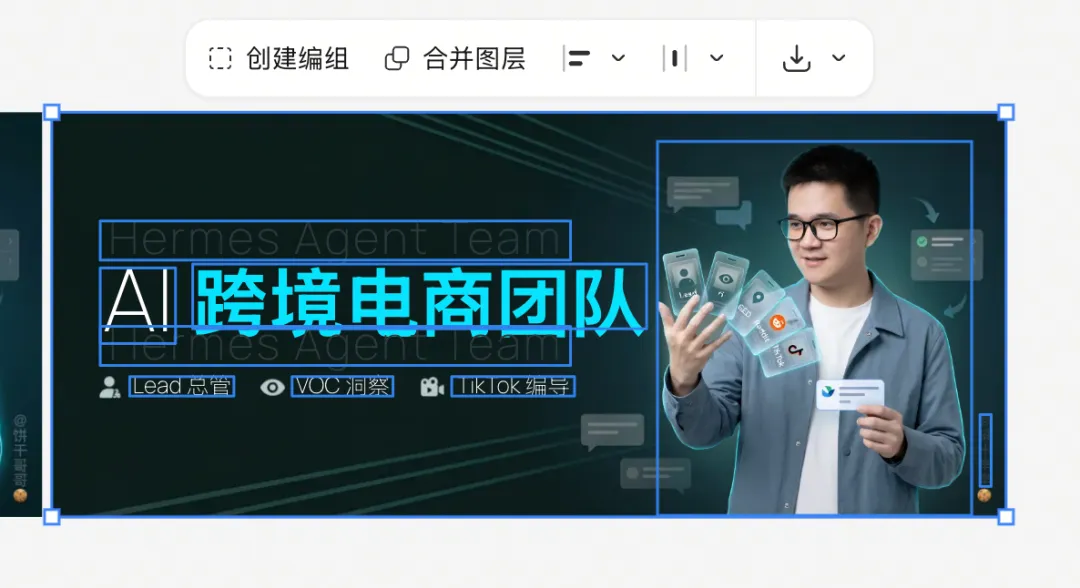
打開 Codex,畀咗一段需求描述同網上揾到嘅兩個開源項目做參考,一輪操作就開發好咗 bggg-creator-image2psd Skill。用返同一張廈門大會海報測試,結果出到 12 個圖層,標題下面嘅殘影消失咗,文字、背景、圖形元素各自分開。
Codex 拆出 12 層,冇殘影
因為 Codex 喺執行過程中發現邊緣污點,會自動調整 Python 腳本參數,重新處理到乾淨為止。呢個就係 reasoning loop 嘅實際效果。
- 同一套 Skill 用跨境電商素材圖測試,同樣成功拆層。
- 開源地址已經放喺 GitHub,可以免費使用。
開源同後續
作者將呢個 Skill 同之前嘅饕餮 Skill 一併放喺 GitHub 倉庫,方便大家下載同改進。佢承認效果仲未算完美,歡迎大家提議。
開源地址喺 GitHub:bggg-skills
如果有更好嘅想法,可以直接去倉庫開 Issue 或者 Pull Request。
現在GPT-image-2 嘅生圖功能能力好犀利,但係改圖依然係AI嘅痛點。
所以好似Lovart呢類設計Agent,就出咗可以直接編輯AI生成圖片嘅功能
但係,我發現,ChatGPT都可以直接做到呢件事喇。
基本上講一句說話就可以將Image2嘅圖轉成多個圖層、可以編輯嘅PSD檔案。
但係喺網頁端嘅體驗仍然冇辦法變成生產力。
之前分享過Codex配合Image2嘅工作流程,於是,經過我一輪操作
成功開發咗一個喺Codex入面生成Image之後再轉成PSD嘅skill
呢啲先係生產力啊!!開源地址喺文末。
跟住分享一下過程。

01
ChatGPT 網頁端:連接Photoshop,將合併圖拆成圖層
ChatGPT,首先喺設定嗰度打開連接點,將Photoshop應用程式連接入嚟。
然後,開新聊天框生圖。
啱啱好我哋下個月6月8號喺廈門有一場 AI 跨境電商線下大會,需要一張海報。啱好用 GPT-image-2 生成咗一張。

呢個時候海報係一張合併圖。要改文字或者換底色,直接改唔到。
轉嚇思路:首先叫 GPT 將海報拆成若干張獨立圖像,底色白色,每張對應 PSD 裏面嘅一個圖層,再拼成 PSD 檔案。
第一步:拆圖層
直接用呢段提示詞:
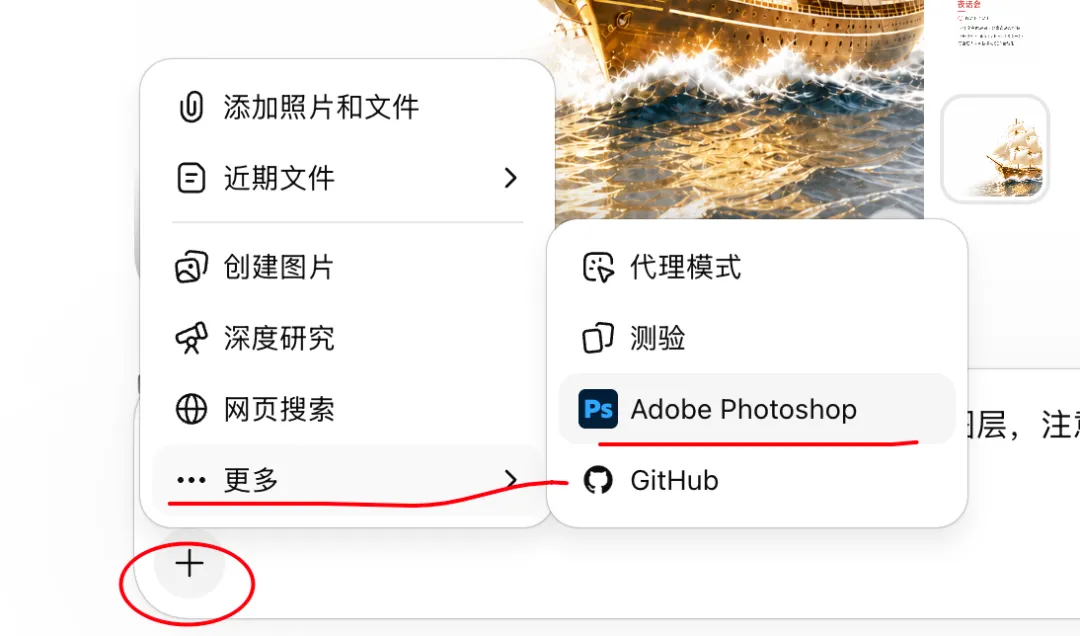
第二步:揀選 Photoshop 應用程式,生成 PSD
喺應用程式選擇嗰度撳開 Photoshop。
然後叫 ChatGPT 將拆好嘅圖拼成 PSD:
執行完就可以拎到一個 PSD 檔案。

匯入 Photoshop,見到圖層喇。
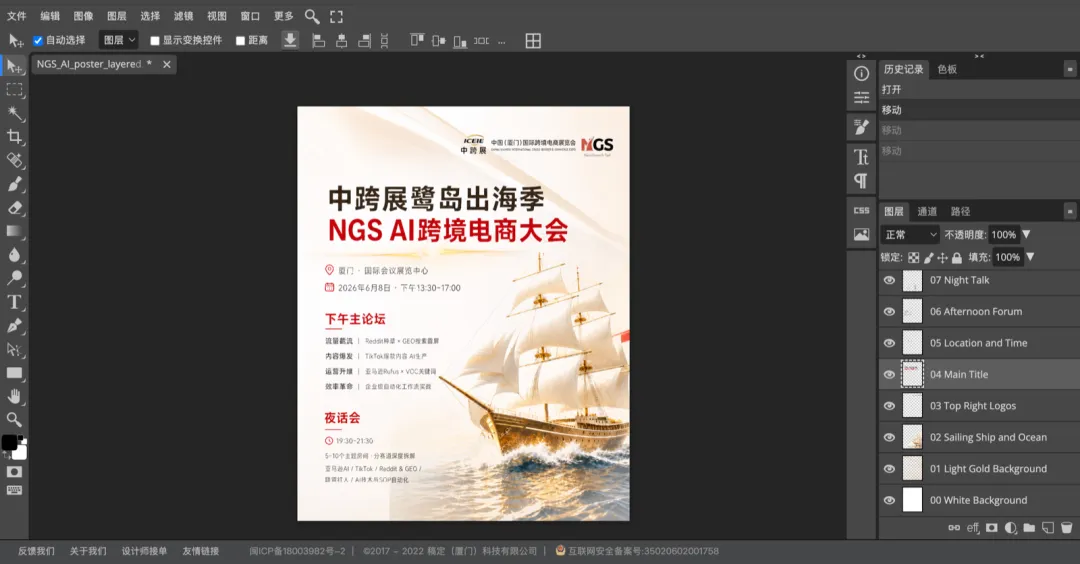

今次拆咗出嚟 7 層。
用得,但問題都好明顯:標題下面有殘影,文字同背景圖合埋咗喺同一層入面冇分開。圖比較複雜嘅話,7 層係網頁端嘅上限。
02
翻查咗一下對話記錄,發現背後係 Python 套件喺度執行
為咗搞清楚網頁端嘅極限喺邊,我偷睇咗一下ChatGPT嘅思考過程。
發現佢背後調用嘅係 Python 嘅 psd-tools 套件。
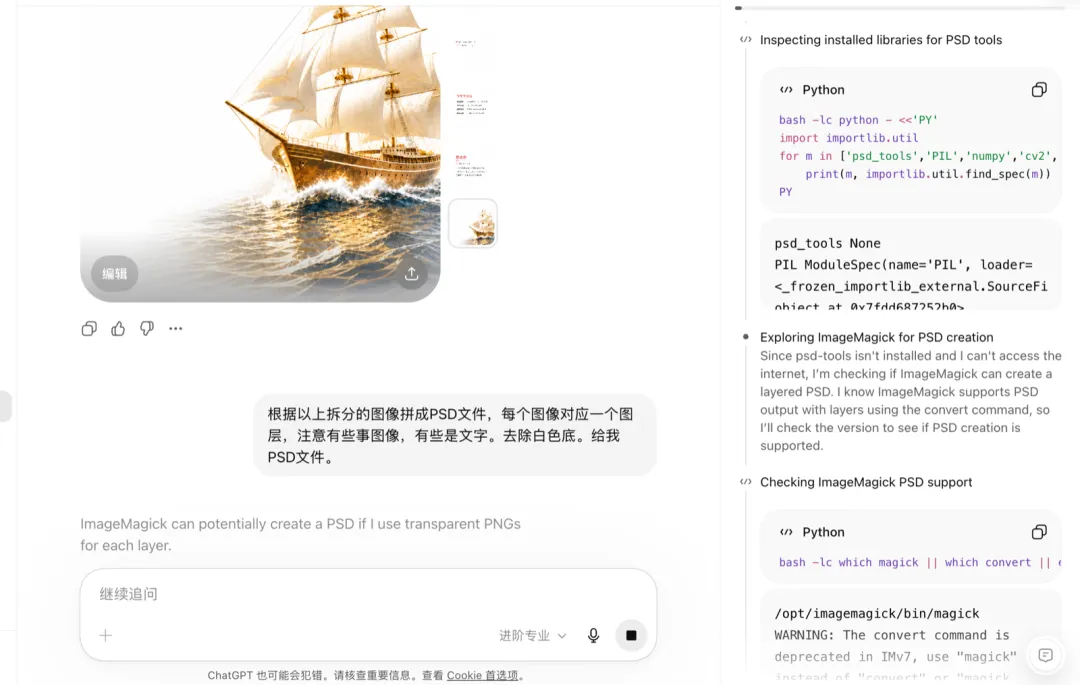
亦即係話,流程係:生圖 → 用 Python 處理圖像拆分 → 拼成 PSD。
講白咗就係,圖層拆得細唔細,取決於 Python 腳本點樣寫。而網頁端係一次性生成,生成完就完結,唔會返轉頭檢查「呢個圖層拆得啱唔啱」。
然後我諗到咗 Codex。
Codex 有 reasoning loop——佢喺執行任務嘅過程中會檢查自己嘅中間結果,發現問題就會返去修正。呢個特性用喺圖像拆分上,理論上可以拆出更多圖層,品質亦更可控。
所以,我嘗試將呢套流程開發成 Skill。
03
用 Codex 開發 bggg-creator-image2psd Skill:12 層,冇殘影
打開 Codex,畀咗一段需求描述,加上網上揾到嘅兩個開源項目做參考。
一輪操作就開發好咗 bggg-creator-image2psd Skill,然後用同樣嘅廈門大會海報測試。
結果出咗嚟。
12 層。
匯入 Photoshop。
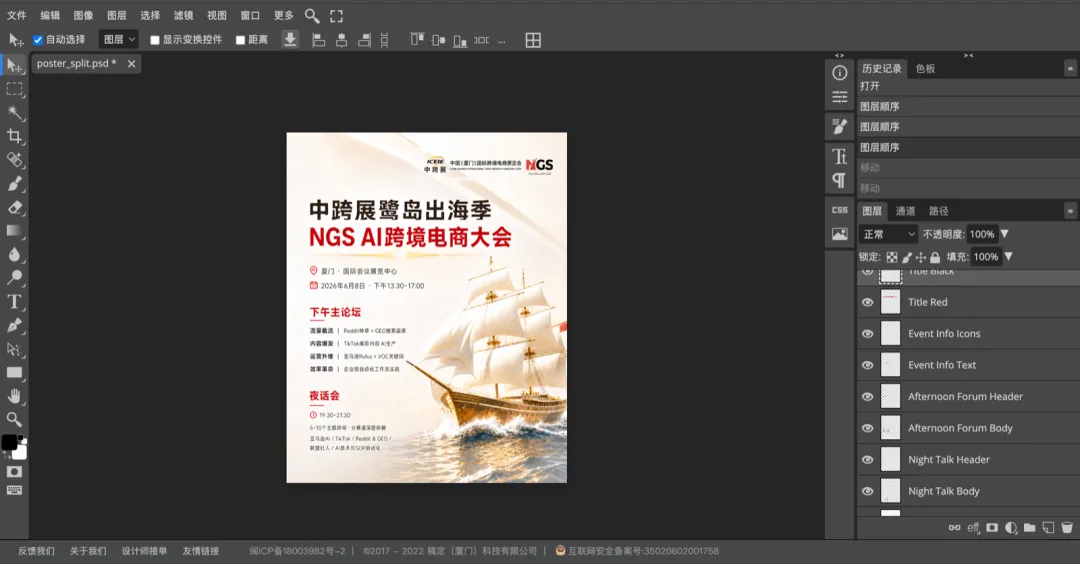

標題下面嗰塊殘影消失咗。文字單獨成層,背景、圖形元素各自分開。
Codex 喺執行任務嘅過程中,發現拆出嘅圖層有邊緣污點,會自動返去調整 Python 腳本嘅參數,重新處理,直到結果乾淨為止。呢個係 reasoning loop 喺實際工作中嘅效果。

同一套 Skill,攞跨境電商嘅素材圖都測試咗一次,同樣拆到。

04
Skill開源地址
https://github.com/binggandata/bggg-skills/tree/main/bggg-creator-image2psd
包括之前開源嘅饕餮.skill,以及後續嘅 Skill,都會同步到呢個倉庫:
https://github.com/binggandata/bggg-skills
求stars支持
現在GPT-image-2 的生圖能力非常牛逼,但改圖依然是AI的痛。
所以像Lovart這樣的設計Agent,就出了能直接對AI生成圖片編輯的功能
但,我發現,ChatGPT也可以直接完成這件事了。
基本上一句話就能從Image2的圖轉成多個圖層、可以編輯的PSD文件。
但在網頁端的體驗還是無法落地成生產力。
之前分享過Codex配合Image2的工作流,於是,經過我一頓操作
成功開發了一個可以在Codex裏生成Image後再轉成PSD的skill
這才是生產力啊!!開源地址在文末。
接下來分享一下過程。
01
ChatGPT 網頁端:連上 Photoshop,把合併圖拆成圖層
ChatGPT,先在設置裏打開連接點,把 Photoshop應用連結進來。
然後,新開聊天框生圖。
剛好我們下個月6月8日在廈門有場 AI 跨境電商線下大會,需要一張海報。正好讓 GPT-image-2 生成了一張。
這時候海報是一張合併圖。要改文字或者換底色,直接改不了。
換個思路:先讓 GPT 把海報拆成若干張獨立圖像,底色白色,每張對應 PSD 裏的一個圖層,再拼成 PSD 文件。
第一步:拆圖層
直接用這段提示詞:
第二步:選中 Photoshop 應用,生成 PSD
在應用選擇裏點開 Photoshop。
然後讓 ChatGPT 把拆好的圖拼成 PSD:
跑完能拿到一個 PSD 文件。
導入 Photoshop,看到圖層了。
這次拆出來 7 層。
能用,但問題也很明顯:標題下面有殘影,文字和背景圖合在了同一層裏沒有分開。圖比較複雜的話,7 層是網頁端的上限。
02
翻了一下對話記錄,發現背後是 Python 包在跑
為了搞清楚網頁端的極限在哪,我偷瞄了一下 ChatGPT的思考過程。
發現它背後調用的是 Python 的 psd-tools 包。
也就是說,流程是:生圖 → 用 Python 處理圖像拆分 → 拼成 PSD。
說白了就是,圖層拆得細不細,取決於 Python 腳本怎麼寫。而網頁端是一次性生成,生完就結束,不會回頭檢查「這個圖層拆得對不對」。
然後我想到了 Codex。
Codex 有 reasoning loop——它在跑任務的過程中會檢查自己的中間結果,發現問題了會回去修。這個特性用在圖像拆分上,理論上能拆出更多圖層,質量也更可控。
所以,我嘗試把這套流程開發成 Skill。
03
用 Codex 開發 bggg-creator-image2psd Skill:12 層,無殘影
打開 Codex,給了一段需求描述,加上網上找到的兩個開源項目作參考。
一頓操作就開發好了 bggg-creator-image2psd Skill,然後用同樣的廈門大會海報測試。
結果出來了。
12 層。
導入 Photoshop。
標題下面那塊殘影消失了。文字單獨成層,背景、圖形元素各自分開。
Codex 在跑任務的過程中,發現拆出的圖層有邊緣污點,會自動回去調整 Python 腳本的參數,重新處理,直到結果乾淨為止。這是 reasoning loop 在實際工作中的效果。
同一套 Skill,拿跨境電商的素材圖也測了一遍,同樣能拆。
04
Skill開源地址
https://github.com/binggandata/bggg-skills/tree/main/bggg-creator-image2psd
包括之前開源的饕餮.skill,以及後續的 Skill,都會同步到這個倉庫:
https://github.com/binggandata/bggg-skills
求stars支持