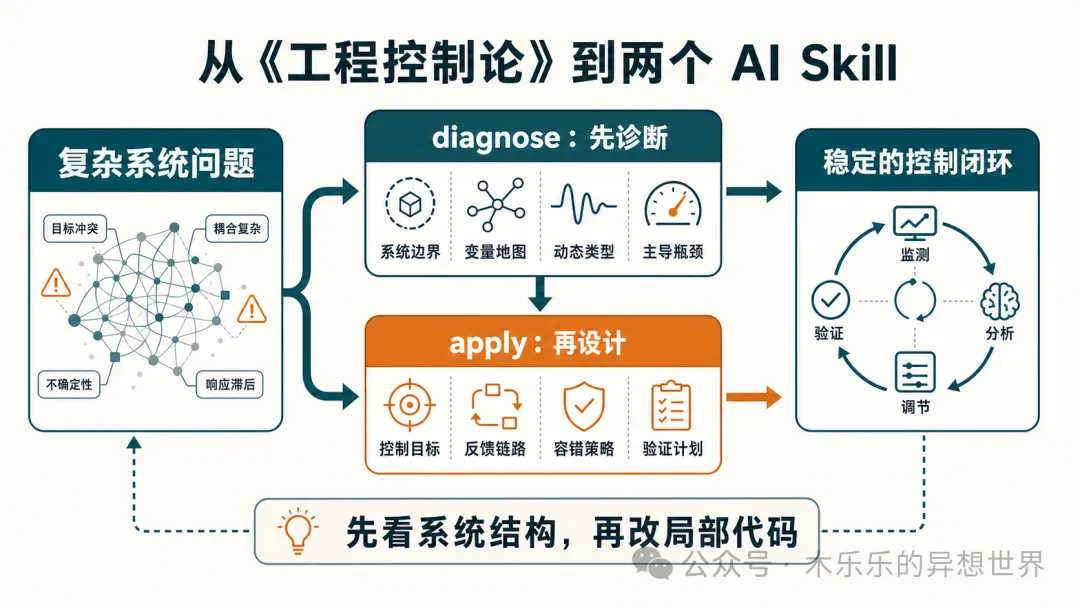
我把《工程控制論》做成了兩個 AI Skill:一個負責診斷,一個負責改造
整理版優先睇
將《工程控制論》變做兩個AI Skill,用系統控制思維診斷同改造複雜系統
呢篇文章係作者分享佢點樣將錢學森、宋健嘅《工程控制論》提煉成兩個AI Skill:一個負責診斷系統唔穩定嘅原因,另一個負責設計控制閉環。作者唔係寫讀書筆記,而係將書入面嘅系統思維變成可以直接用嚟分析真實系統嘅工具。佢嘅背景係成日做AI自動化同複雜流程,發現好多問題根本唔係單點bug,而係成個系統嘅測量、反饋同控制策略出咗問題。
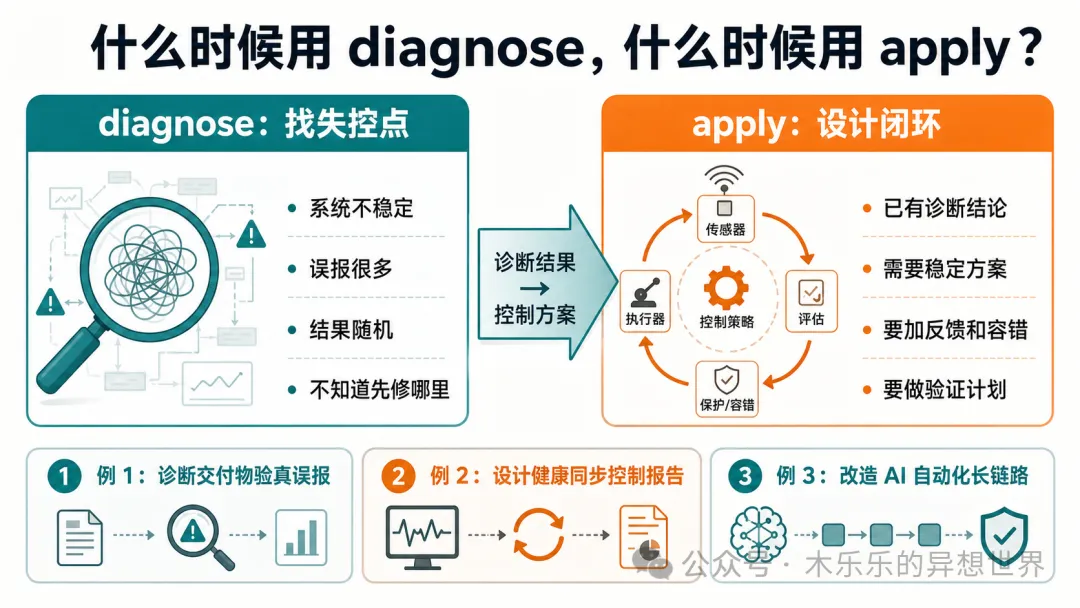
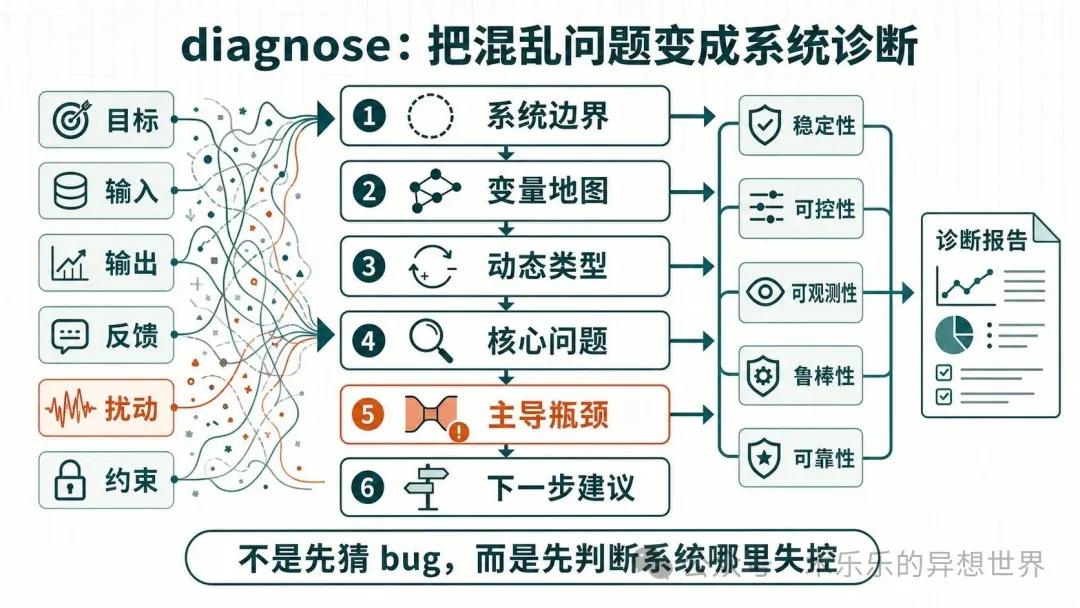
兩個Skill嘅分工好清楚:engineering-cybernetics-diagnose負責將混亂問題整理成系統診斷,按步驟分析系統邊界、變量、動態類型、控制問題同主導瓶頸;engineering-cybernetics-apply負責將診斷結果轉成控制方案,包括控制目標、系統模型、實施步驟同驗證計劃。作者用一個真實案例(交付物驗真節點不穩定)示範咗點樣用診斷Skill揾出真正原因——原來係LLM分類不穩同探活誤報將測量噪聲放大咗。
整體結論係:面對AI系統、自動化流程呢類複雜系統,應該先用系統控制思維診斷,再設計改造方案,而唔係一味死改局部code。將書本方法論變成可重用嘅Skill,先至係真正將知識變成生產力。
- 《工程控制論》Skill嘅核心係幫你唔好急住問「邊度有bug」,而係先問「呢個系統控制緊咩?反饋鏈路喺邊?擾動嚟自邊度?」
- 兩個Skill分別係診斷(engineering-cybernetics-diagnose)同改造(engineering-cybernetics-apply),前者負責揾系統問題,後者負責設計控制方案,符合先觀測後控制嘅原則。
- 診斷Skill會分析系統邊界、變量、動態類型、控制問題同主導瓶頸,最後畀出修復優先級,幫你聚焦真正嘅放大器。
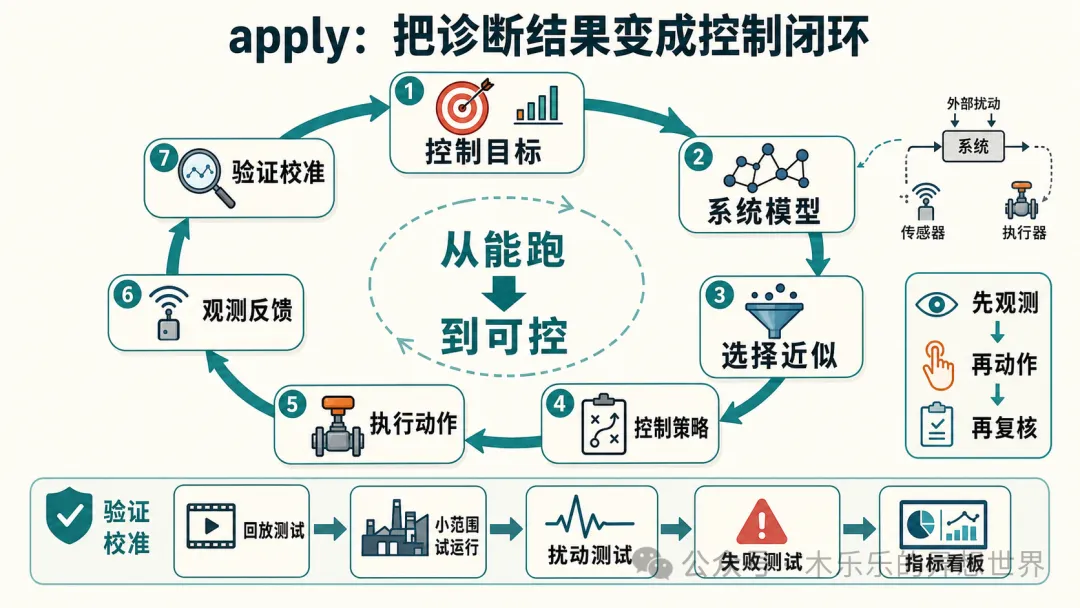
- 改造Skill將診斷結果轉成控制方案,包括控制目標、系統模型、實施步驟同驗證計劃,令系統從「能跑」變成「可控」。
- 真實案例顯示:交付物驗真節點不穩定嘅主因係測量系統不穩,而非單一bug,修復重點應該係穩定LLM分類同探活狀態,而唔係改規則閾值。
點解要將《工程控制論》做成Skill?
《工程控制論》唔係一本可以簡單總結成十條金句嘅書,佢講嘅係一套系統方法:點樣將工程實踐中嘅複雜過程抽象成可以觀察、建模同控制嘅系統。作者發現,呢套思維同而家做AI自動化好相似——好多系統嘅問題本質係長鏈路系統唔穩定,而唔係單點函數寫錯。
作者嘅核心動機係:面對複雜問題時,先問「系統控制緊咩?」而唔係「邊度有bug」。
讀完書之後,作者決定將佢變成兩個可以隨時調用嘅AI Skill,令呢套方法可以直接用嚟分析真實系統,而唔係留喺書本度。
點解拆成診斷同改造兩個Skill?
作者冇整一個大而全嘅Skill,而係拆成兩個,因為真實工作有兩種唔同場景:一種係系統已經出事,你想知點解;另一種係你大概知問題,想設計更穩嘅方案。
- engineering-cybernetics-diagnose:負責將混亂問題整理成系統診斷,幫你揾出主導瓶頸。
- engineering-cybernetics-apply:負責將診斷結果轉成控制方案,輸出一個穩定嘅控制閉環。
診斷Skill:點樣拆解系統問題?
呢個Skill適合用喺自動化流程失敗、AI節點時好時壞、業務系統誤報多呢類場景。佢會按六個步驟分析,幫你搞清楚問題到底係代碼問題、測量問題、反饋問題定控制策略問題。
- 1 定義系統邊界:講清楚受控對象、控制器、環境同反饋鏈路。
- 2 畫變量地圖:揾出狀態變量、輸出、可控輸入、擾動同約束。
- 3 判斷動態類型:睇系統係連續定離散、線性定非線性、確定定隨機。
- 4 檢查核心控制問題:包括穩定性、可控性、可觀測性、反饋質量等。
- 5 揾主導瓶頸:唔係咩都修,而係揾最先要搞掂嗰個系統瓶頸。
- 6 畀下一步建議:教你應該補數據、改探活、加緩存定做降級。
呢個Skill唔係幫你「估bug」,而係幫你判斷問題嘅根源類型。
改造Skill同真實案例:從診斷到控制閉環
改造Skill將診斷結果轉成具體方案,包括控制目標、系統模型、實施步驟同驗證計劃。作者用健康記錄同步系統做例子:原來只係腳本識得跑,加上控制報告之後,每次運行都會輸出整體狀態、同步數量、失敗情況同下一步建議,系統從「腳本跑了」變成「我知道佢跑成點」。
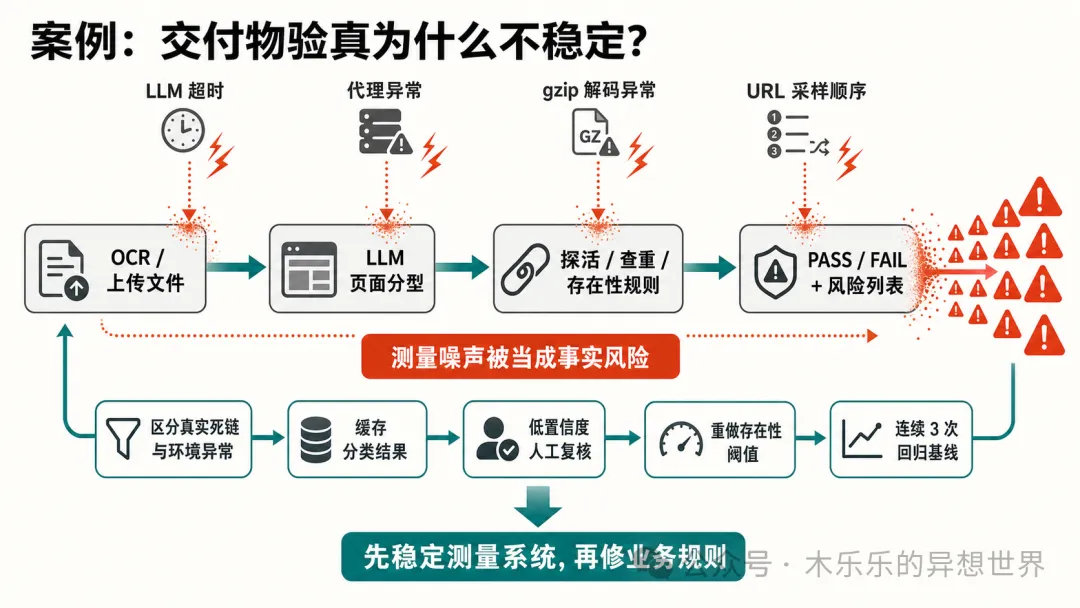
另一個真實案例係交付物驗真節點(check_delivery_node)不穩定。用診斷Skill一查,發現唔係普通bug,而係成條測量鏈路將前面嘅不確定性放大了。
- LLM頁面分類同服務歸屬不穩定:同一類文件有時成功有時失敗,返回結果唔一致。
- 探活將環境錯誤當成業務死鏈:代理失敗、gzip解碼失敗都歸類為MALFORMED,然後誤報成風險。
- 存在性檢查放大服務映射錯誤:服務映射一唔穩定,後續就彈出十幾條缺交付物風險。
對AI編程同讀書方法嘅啟示
AI編程好容易跌入一個坑:將所有問題都當成局部code問題。但好多AI系統嘅問題本質係輸入唔穩定、外部服務唔穩定、反饋太慢、錯誤分類太粗呢類系統級問題。
工程控制論嘅好處係幫我哋先退一步,將code鏈路睇成一個系統,日誌係反饋,異常係擾動,規則係控制器。
作者最後話,將《工程控制論》做成兩個Skill後,呢本書變成一個可以反覆調用嘅思考工具,先至係將書本變成生產力嘅最好方式。
只要係系統,就會有反饋、擾動、噪聲、延遲同失控,也就需要控制。呢兩個Skill就係幫你咁樣做。
⠀
最近我做咗一件好得意嘅事:將錢學森、宋健嘅《工程控制論》提煉成兩個可以隨時叫嚟用嘅 AI Skill。
⠀
唔係讀書筆記,亦都唔係書摘。
⠀
而係將本書嘅思考方式,變成兩個可以直接用嚟分析真實系統嘅工具:
⠀
- `engineering-cybernetics-diagnose`
- `engineering-cybernetics-apply`
⠀
前者負責診斷系統點解唔穩定,後者負責設計一個更穩定嘅控制閉環。
⠀
⠀
呢兩個 Skill 嘅核心價值係:當我哋面對一個複雜問題時,唔再急住問「邊度有 bug」,而係先問:
⠀
呢個系統到底喺度控制啲乜?
⠀
反饋鏈路喺邊?
⠀
擾動嚟自邊度?
⠀
測量係咪可靠?
⠀
後面嘅規則有冇將前面嘅噪聲放大?
⠀
呢就係工程控制論特別適合 AI 編程、自動化系統、業務流程同複雜項目管理嘅地方。
⠀
⠀
【重點】一、點解要將《工程控制論》做成 Skill?
⠀
《工程控制論》唔係一本適合簡單總結成「十條金句」嘅書。
⠀
佢講嘅係一套系統方法:點樣將工程實踐入面嘅複雜過程,抽象成可以觀察、可以建模、可以控制、可以驗證嘅系統。
⠀
如果用產品經理明嘅話講,佢關心嘅唔係「單一個掣有冇問題」,而係:
⠀
- 輸入係乜?
- 輸出係乜?
- 中間狀態點樣變化?
- 邊啲變數可以控制?
- 邊啲變數只能觀測?
- 邊啲擾動會令系統失控?
- 點樣設計反饋,令系統自動返到目標狀態?
⠀
呢個同我哋而家做 AI 自動化好相似。
⠀
譬如一個 AI 審單系統、一個健康記錄自動同步系統、一個內容推薦自動化、一個交付物驗真節點,本質上都唔係單點功能,而係長鏈路系統。
⠀
只要鏈路入麪包括 LLM、OCR、外部接口、網絡、規則引擎、緩存、人工輸入,佢就一定會有唔確定性。
⠀
工程控制論嘅價值,就係幫我哋唔好俾表面問題牽住走。
⠀
佢會逼你先睇系統結構,再睇局部 bug。
⠀
⠀
【重點】二、點解拆成兩個 Skill?
⠀
我冇將《工程控制論》做成一個大而全嘅 Skill,而係拆成兩個。
⠀
原因好簡單:真實工作入面有兩種唔同場景。
⠀
一種係:系統已經出咗問題,我想知點解。
⠀
另一種係:我已經大概知道問題,我想設計一個更穩陣嘅方案。
⠀
所以我拆成:
⠀
engineering-cybernetics-diagnose⠀
和:
⠀
engineering-cybernetics-apply⠀
一個負責「診斷」,一個負責「改造」。
⠀
呢個其實都符合工程控制論嘅思路:先觀測同建模,再設計控制方案。
⠀
⠀
【重點】三、第一個 Skill:engineering-cybernetics-diagnose
⠀
`engineering-cybernetics-diagnose` 嘅作用係:將一個混亂嘅問題,整理成系統診斷。
⠀
佢適合用喺呢啲場景:
⠀
- 一個自動化流程成日失敗,但原因唔穩定
- 一個 AI 節點有時成功、有時失敗
- 一個業務系統誤報好多
- 一個長鏈路任務前面嘅小波動,會喺後面變成大問題
- 你唔知應該先改 code、改規則,定係補監控
⠀
⠀
佢會按呢幾個步驟嚟分析:
⠀
undefined. 定義系統邊界
先講清楚受控對象係乜,控制器係乜,環境係乜,反饋鏈路係乜。
⠀
undefined. 畫變量地圖
揾出狀態變量、輸出、可控輸入、擾動同約束。
⠀
undefined. 判斷動態類型
睇嚇佢係連續定離散,線性定非線性,確定定隨機,有冇時滯。
⠀
undefined. 檢查核心控制問題
包括穩定性、可控性、可觀測性、反饋質量、魯棒性、可靠性。
⠀
undefined. 揾主導瓶頸
唔係乜都修,而係揾最先要修嗰個系統瓶頸。
⠀
undefined. 俾下一步建議
話俾你知應該補數據、改探活、加緩存、做降級,定係重新設計閾值。
⠀
簡單講,呢個 Skill 唔係幫你「估 bug」。
⠀
佢係幫你判斷:呢個問題到底係 code 問題、測量問題、反饋問題,定係控制策略問題。
⠀
⠀
【重點】四、第二個 Skill:engineering-cybernetics-apply
⠀
`engineering-cybernetics-apply` 嘅作用係:將診斷結果轉成控制方案。
⠀
如果話 diagnose 係醫生睇病,咁 apply 就係開治療方案。
⠀
佢適合用喺呢啲場景:
⠀
- 你想將一個 script 變成穩定自動化
- 你想俾 AI 工作流加監控、重試、降級
- 你想設計一個反饋閉環
- 你想令系統由「識行」變成「可控」
- 你想做一個指標看板,持續校準系統表現
⠀
⠀
佢會輸出一個工程控制方案,包括:
⠀
- 控制目標
- 系統模型
- 建議用嘅近似模型
- 控制策略
- 實施步驟
- 驗證計劃
- 風險同待確認事項
⠀
譬如我之前用佢嚟優化健康記錄同步系統。
⠀
原本嘅系統係:
⠀
MakeTime 記錄
→ Notion 同步
→ 本地解析
→ 寫入飛書
→ 本地去重⠀
望落好似已經識行。
⠀
但由工程控制論角度睇,佢仲欠一樣嘢:反饋。
⠀
所以優化之後,我俾 `health_tracker.py sync-maketime` 加咗 `control_report`,每次執行都會輸出:
⠀
- 呢次整體狀態係乜
- 有幾條計劃寫入
- 有幾條已經同步
- 有幾條更新
- 有幾條失敗
- 飲食攝入係幾多
- 運動消耗係幾多
- 當日熱量缺口係幾多
- 下一步建議係乜
⠀
咁樣系統就由「script 行咗」變成「我知佢行成點」。
⠀
呢個就係控制閉環。
⠀
⠀
【重點】五、一個真實案例:交付物驗真節點點解唔穩定?
⠀
我最近仲用 `engineering-cybernetics-diagnose` 診斷過一個真實問題:交付物驗真與探活節點唔穩定。
⠀
呢個節點叫:
⠀
check_delivery_node⠀
起初望落似係細 bug:
⠀
有時誤報死鏈。
⠀
有時交付物明明存在,但就報缺失。
⠀
有時同一批文件跑出嚟嘅風險數量唔一致。
⠀
但叫咗 `engineering-cybernetics-diagnose` 之後,結論好清楚:
⠀
呢個唔係一個細 bug,而係一個長鏈路系統將前面嘅唔確定性層層放大咗。
⠀
⠀
→ 1. 先睇系統邊界
⠀
受控對象係 `check_delivery_node` 交付物驗真節點。
⠀
控制器包括:
⠀
- 頁面分型
- 服務歸屬
- `action_tags` 路由
- 探活規則
- 查重規則
- 存在性規則
⠀
環境包括:
⠀
- OCR
- LLM
- 外網 HTTP
- 代理
- 緩存
- 上傳文件
⠀
反饋鏈路包括:
⠀
- `risk_list`
- `check_results`
- `delivery_link_probe_results`
- 運行日誌
⠀
呢種拆法好關鍵。
⠀
因為佢即刻令問題由「某個 function 係咪寫錯」,變成「成條測量鏈路係咪可靠」。
⠀
→ 2. 再睇變量地圖
⠀
呢個節點入面嘅狀態變量包括:
⠀
- 頁面類型
- 服務歸屬
- 連結狀態
- 重複圖片
- 服務證據頁數量
⠀
輸出係:
⠀
- 節點最終 PASS/FAIL
- 風險數量
⠀
可控輸入係:
⠀
- 探活規則
- LLM 映射策略
- 重試/降級策略
- 存在性閾值
⠀
擾動嚟自:
⠀
- LLM 超時
- LLM 隨機輸出
- 網絡代理異常
- 百度網盤 gzip 解碼異常
- URL 採樣順序
⠀
呢一步嘅價值係:你會發現好多所謂「業務風險」,其實只係測量過程入面嘅噪聲。
⠀
→ 3. 判斷動態類型
⠀
呢個系統係一個:
⠀
離散、非線性、隨機、有明顯時滯的系統⠀
翻譯成人話就係:
⠀
佢唔係一條固定公式。
⠀
每一步都可能要靠外部服務同唔穩定輸入。
⠀
前面少少變化,後面會放大成好多風險。
⠀
譬如 LLM 呢次分類超時,下次分類成功;呢次認到 5 個 `action_tags`,下次認到 7 個。後面嘅存在性檢查就會即刻跟住變。
⠀
所以呢個節點唔穩定,唔係因為佢「唔夠努力」,而係因為系統結構本身就自然會放大前面嘅唔確定性。
⠀
→ 4. 揾到三個主因
⠀
診斷之後,主因好清楚。
⠀
第一,LLM 頁面分類同服務歸屬唔穩定。
⠀
Code 喺 `delivery_analyzer.py` 入面叫 LLM。歷史日誌顯示,同一類文件會出現呢次超時、下次成功嘅情況。成功後返嘅頁面類型同 `action_tags` 數量都唔完全一致。
⠀
第二,探活將環境錯誤當成業務死鏈。
⠀
`delivery_utils.py` 入面將所有 `requests` 異常都歸成 `MALFORMED`。
⠀
然後 `check_link_probe.py` 又將 `MALFORMED` 當成疑似死鏈報風險。
⠀
呢樣就會將代理失敗、gzip 解碼失敗、臨時網絡問題,全部誤傷成業務風險。
⠀
第三,存在性檢查會放大服務映射錯誤。
⠀
`check_existence.py` 入面只要某個服務冇映射到證據頁,就報「未找到對應證據頁面」。
⠀
如果服務映射本身唔穩,後面就會一口氣放大成十幾條缺交付物風險。
⠀
→ 5. 主導瓶頸係乜?
⠀
最後診斷出嚟一句話係:
⠀
呢個節點嘅「測量系統」唔穩定,後面嘅規則又將測量噪聲當成事實風險。
⠀
呢句話好重要。
⠀
因為佢直接改變咗修復優先順序。
⠀
如果你當佢係普通 bug,可能會走去改某一條規則。
⠀
但如果你當佢係控制系統,就會知道:應該先穩定測量系統,再講業務判斷。
⠀
→ 6. 下一步點改?
⠀
診斷俾出嘅修復順序係:
⠀
第一,先改探活狀態。
⠀
要區分真實死鏈同環境/客戶端異常。代理失敗、gzip 解碼失敗、臨時網絡失敗,唔可以直接算業務死鏈。
⠀
第二,俾 LLM 分類同服務映射加穩定層。
⠀
譬如緩存中間結果、固定重試策略、低置信度送入人工複核,而唔係直接觸發高風險。
⠀
第三,重做存在性閾值。
⠀
唔好用「讚好數/上評數」呢類大數量直接要求證據頁數量,否則自然容易誤報。
⠀
第四,建立回歸基線。
⠀
用同一批交付物連續行 3 次,要求頁面分類、服務映射、風險數大致一致。
⠀
呢個就係一個典型嘅工程控制論式修復。
⠀
佢唔係「見到邊度紅就修邊度」,而係先揾到系統唔穩定嘅放大器。
⠀
⠀
【重點】六、呢兩個 Skill 應該點用?
⠀
日常用起嚟其實好簡單。
⠀
如果你遇到一個複雜系統唔穩定,可以咁問:
⠀
調用 engineering-cybernetics-diagnose,
幫我診斷這個系統為什麼不穩定:
[貼系統背景、日誌、代碼線索、異常表現]⠀
佢適合回答:
⠀
- 問題喺邊度被放大?
- 邊啲係擾動?
- 邊啲係反饋?
- 邊啲係可控變量?
- 主導瓶頸係乜?
- 應該先改邊度?
⠀
如果你已經知道問題,想設計改造方案,可以咁問:
⠀
調用 engineering-cybernetics-apply,
基於這個診斷結果,幫我設計一個控制閉環:
[貼診斷結論和現有流程]⠀
佢適合回答:
⠀
- 控制目標係乜?
- 需要邊啲觀測信號?
- 失敗時點樣降級?
- 幾時重試?
- 點樣避免誤報?
- 點樣做回歸驗證?
- 點樣令系統持續穩定?
⠀
⠀
我嘅建議係:先 diagnose,再 apply。
⠀
先診斷,再設計。
⠀
唔好一嚟就改系統。
⠀
⠀
【重點】七、佢對 AI 編程有咩意義?
⠀
AI 編程最易跌入一個坑:將所有問題都當成局部 code 問題。
⠀
但好多 AI 系統嘅問題,本質唔係某一行 code 錯咗,而係:
⠀
- 輸入唔穩定
- 中間判斷唔穩定
- 外部服務唔穩定
- 反饋太慢
- 錯誤分類太粗
- 閾值設計太硬
- 後續規則將噪聲放大咗
⠀
呢類問題,用普通 debug 思路好易越修越亂。
⠀
工程控制論嘅好處係,佢令我哋先退一步:
⠀
將 code 鏈路睇成一個系統。
⠀
將日誌睇成反饋。
⠀
將異常睇成擾動。
⠀
將規則睇成控制器。
⠀
將輸出結果睇成被控制變量。
⠀
咁樣一嚟,修復就唔再係「邊度痛醫邊度」,而係開始設計一個更穩定嘅系統。
⠀
⠀
【重點】八、我而家越來越信:Skill 係將書變成工具嘅最好方式
⠀
以前讀書,讀完就係讀完。
⠀
最多留低幾條筆記。
⠀
但今次將《工程控制論》做成兩個 Skill 之後,我覺得佢變成咗一個可以反覆叫嚟用嘅思考工具。
⠀
我唔需要每次都重新諗返控制論概念。
⠀
只要遇到系統唔穩定,我就可以叫:
⠀
engineering-cybernetics-diagnose⠀
遇到要設計控制閉環,我就可以叫:
⠀
engineering-cybernetics-apply⠀
呢個先係「將一本書變成生產力」嘅感覺。
⠀
唔係將書總結成知識點,而係將書入面嘅方法論,變成可以喺真實項目入面反覆叫嚟用嘅操作系統。
⠀
而工程控制論,剛好特別適合呢個時代。
⠀
因為我哋而家做緊嘅好多嘢,本質上都係系統:
⠀
AI 工作流係系統。
⠀
自動化任務係系統。
⠀
內容生產鏈路係系統。
⠀
健康記錄同步係系統。
⠀
交付物驗真都係系統。
⠀
只要是系統,就會有反饋、擾動、噪聲、延遲同失控。
⠀
咁就需要控制。
⠀
最近我做了一件很有意思的事:把錢學森、宋健的《工程控制論》提煉成了兩個可以隨時調用的 AI Skill。
⠀
不是讀書筆記,也不是書摘。
⠀
而是把書裏的思考方式,變成兩個可以直接拿來分析真實系統的工具:
⠀
- `engineering-cybernetics-diagnose`
- `engineering-cybernetics-apply`
⠀
前者負責診斷系統為什麼不穩定,後者負責設計一個更穩定的控制閉環。
⠀
⠀
這兩個 Skill 的核心價值是:當我們面對一個複雜問題時,不再急着問“哪裏有 bug”,而是先問:
⠀
這個系統到底在控制什麼?
⠀
反饋鏈路在哪裏?
⠀
擾動來自哪裏?
⠀
測量是否可靠?
⠀
後面的規則有沒有把前面的噪聲放大?
⠀
這就是工程控制論特別適合 AI 編程、自動化系統、業務流程和複雜項目管理的地方。
⠀
⠀
【重點】一、為什麼要把《工程控制論》做成 Skill?
⠀
《工程控制論》不是一本適合簡單總結成“十條金句”的書。
⠀
它講的是一套系統方法:如何把工程實踐中的複雜過程,抽象成可以觀察、可以建模、可以控制、可以驗證的系統。
⠀
如果用產品經理能理解的話說,它關心的不是“單個按鈕有沒有問題”,而是:
⠀
- 輸入是什麼?
- 輸出是什麼?
- 中間狀態怎麼變化?
- 哪些變量能控制?
- 哪些變量只能觀測?
- 哪些擾動會讓系統失控?
- 怎麼設計反饋,讓系統自動回到目標狀態?
⠀
這和我們現在做 AI 自動化非常像。
⠀
比如一個 AI 審單系統、一個健康記錄自動同步系統、一個內容推薦自動化、一個交付物驗真節點,本質上都不是單點功能,而是長鏈路系統。
⠀
只要鏈路裏包含 LLM、OCR、外部接口、網絡、規則引擎、緩存、人工輸入,它就一定會有不確定性。
⠀
工程控制論的價值,就是幫我們不要被表面問題牽着跑。
⠀
它會逼你先看系統結構,再看局部 bug。
⠀
⠀
【重點】二、為什麼拆成兩個 Skill?
⠀
我沒有把《工程控制論》做成一個大而全的 Skill,而是拆成兩個。
⠀
原因很簡單:真實工作裏有兩種不同場景。
⠀
一種是:系統已經出問題了,我想知道為什麼。
⠀
另一種是:我已經知道大概問題了,我想設計一個更穩的方案。
⠀
所以我拆成:
⠀
engineering-cybernetics-diagnose⠀
和:
⠀
engineering-cybernetics-apply⠀
一個負責“診斷”,一個負責“改造”。
⠀
這其實也符合工程控制論的思路:先觀測和建模,再設計控制方案。
⠀
⠀
【重點】三、第一個 Skill:engineering-cybernetics-diagnose
⠀
`engineering-cybernetics-diagnose` 的作用是:把一個混亂的問題,整理成系統診斷。
⠀
它適合用在這些場景:
⠀
- 一個自動化流程經常失敗,但原因不穩定
- 一個 AI 節點有時成功、有時失敗
- 一個業務系統誤報很多
- 一個長鏈路任務前面的小波動,會在後面變成大問題
- 你不知道該先修代碼、改規則,還是補監控
⠀
⠀
它會按這幾個步驟來分析:
⠀
undefined. 定義系統邊界
先說清楚受控對象是什麼,控制器是什麼,環境是什麼,反饋鏈路是什麼。
⠀
undefined. 畫變量地圖
找出狀態變量、輸出、可控輸入、擾動和約束。
⠀
undefined. 判斷動態類型
看它是連續還是離散,線性還是非線性,確定還是隨機,有沒有時滯。
⠀
undefined. 檢查核心控制問題
包括穩定性、可控性、可觀測性、反饋質量、魯棒性、可靠性。
⠀
undefined. 找主導瓶頸
不是什麼都修,而是找最先該修的那個系統瓶頸。
⠀
undefined. 給下一步建議
告訴你該補數據、改探活、加緩存、做降級,還是重新設計閾值。
⠀
簡單說,這個 Skill 不是幫你“猜 bug”。
⠀
它是幫你判斷:這個問題到底是代碼問題、測量問題、反饋問題,還是控制策略問題。
⠀
⠀
【重點】四、第二個 Skill:engineering-cybernetics-apply
⠀
`engineering-cybernetics-apply` 的作用是:把診斷結果轉成控制方案。
⠀
如果說 diagnose 是醫生看病,那麼 apply 就是開治療方案。
⠀
它適合用在這些場景:
⠀
- 你想把一個腳本變成穩定自動化
- 你想給 AI 工作流加監控、重試、降級
- 你想設計一個反饋閉環
- 你想讓系統從“能跑”變成“可控”
- 你想做一個指標看板,持續校準系統表現
⠀
⠀
它會輸出一份工程控制方案,包括:
⠀
- 控制目標
- 系統模型
- 推薦近似模型
- 控制策略
- 實施步驟
- 驗證計劃
- 風險和待確認事項
⠀
比如我之前用它優化健康記錄同步系統。
⠀
原來的系統是:
⠀
MakeTime 記錄
→ Notion 同步
→ 本地解析
→ 寫入飛書
→ 本地去重⠀
看起來已經能跑。
⠀
但從工程控制論角度看,它還缺一個關鍵東西:反饋。
⠀
所以優化後,我給 `health_tracker.py sync-maketime` 增加了 `control_report`,每次運行都會輸出:
⠀
- 這次整體狀態是什麼
- 有幾條計劃寫入
- 有幾條已經同步
- 有幾條更新
- 有幾條失敗
- 飲食攝入是多少
- 運動消耗是多少
- 當日熱量缺口是多少
- 下一步建議是什麼
⠀
這樣系統就從“腳本跑了”變成了“我知道它跑得怎麼樣”。
⠀
這就是控制閉環。
⠀
⠀
【重點】五、一個真實案例:交付物驗真節點為什麼不穩定?
⠀
我最近還用 `engineering-cybernetics-diagnose` 診斷過一個真實問題:交付物驗真與探活節點不穩定。
⠀
這個節點叫:
⠀
check_delivery_node⠀
一開始看起來像是小 bug:
⠀
有時候誤報死鏈。
⠀
有時候交付物明明存在,卻報缺失。
⠀
有時候同一批文件跑出來的風險數量不一致。
⠀
但調用 `engineering-cybernetics-diagnose` 後,結論很清楚:
⠀
這不是一個小 bug,而是一個長鏈路系統把前面的不確定性層層放大了。
⠀
⠀
→ 1. 先看系統邊界
⠀
受控對象是 `check_delivery_node` 交付物驗真節點。
⠀
控制器包括:
⠀
- 頁面分型
- 服務歸屬
- `action_tags` 路由
- 探活規則
- 查重規則
- 存在性規則
⠀
環境包括:
⠀
- OCR
- LLM
- 外網 HTTP
- 代理
- 緩存
- 上傳文件
⠀
反饋鏈路包括:
⠀
- `risk_list`
- `check_results`
- `delivery_link_probe_results`
- 運行日誌
⠀
這個拆法很關鍵。
⠀
因為它馬上讓問題從“某個函數是不是寫錯了”,變成了“整條測量鏈路是否可靠”。
⠀
→ 2. 再看變量地圖
⠀
這個節點裏的狀態變量包括:
⠀
- 頁面類型
- 服務歸屬
- 連結狀態
- 重複圖片
- 服務證據頁數量
⠀
輸出是:
⠀
- 節點最終 PASS/FAIL
- 風險數量
⠀
可控輸入是:
⠀
- 探活規則
- LLM 映射策略
- 重試/降級策略
- 存在性閾值
⠀
擾動來自:
⠀
- LLM 超時
- LLM 隨機輸出
- 網絡代理異常
- 百度網盤 gzip 解碼異常
- URL 採樣順序
⠀
這一步的價值是:你會發現很多所謂“業務風險”,其實只是測量過程中的噪聲。
⠀
→ 3. 判斷動態類型
⠀
這個系統是一個:
⠀
離散、非線性、隨機、有明顯時滯的系統⠀
翻譯成人話就是:
⠀
它不是一個固定公式。
⠀
每一步都可能依賴外部服務和不穩定輸入。
⠀
前面一點點變化,後面會放大成很多風險。
⠀
比如 LLM 這次分類超時,下次分類成功;這次識別出 5 個 `action_tags`,下次識別出 7 個。後面的存在性檢查就會立刻跟着變化。
⠀
所以這個節點不穩定,不是因為它“不夠努力”,而是因為系統結構天然會放大前面的不確定性。
⠀
→ 4. 找到三個主因
⠀
診斷後,主因非常清楚。
⠀
第一,LLM 頁面分類和服務歸屬不穩定。
⠀
代碼在 `delivery_analyzer.py` 裏調用 LLM。歷史日誌顯示,同一類文件會出現這次超時、下次成功的情況。成功後返回的頁面類型和 `action_tags` 數量也不完全一致。
⠀
第二,探活把環境錯誤當成業務死鏈。
⠀
`delivery_utils.py` 裏把所有 `requests` 異常都歸成 `MALFORMED`。
⠀
然後 `check_link_probe.py` 又把 `MALFORMED` 當成疑似死鏈報風險。
⠀
這就會把代理失敗、gzip 解碼失敗、臨時網絡問題,全都誤傷成業務風險。
⠀
第三,存在性檢查會放大服務映射錯誤。
⠀
`check_existence.py` 裏只要某個服務沒有映射到證據頁,就報“未找到對應證據頁面”。
⠀
如果服務映射本身不穩,後面就會一口氣放大成十幾條缺交付物風險。
⠀
→ 5. 主導瓶頸是什麼?
⠀
最後診斷出來的一句話是:
⠀
這個節點的“測量系統”不穩,後面的規則又把測量噪聲當成事實風險。
⠀
這句話很重要。
⠀
因為它直接改變了修復優先級。
⠀
如果你把它當普通 bug,可能會去改某一條規則。
⠀
但如果你把它當控制系統,就會知道:應該先穩定測量系統,再談業務判斷。
⠀
→ 6. 下一步怎麼改?
⠀
診斷給出的修復順序是:
⠀
第一,先改探活狀態。
⠀
要區分真實死鏈和環境/客戶端異常。代理失敗、gzip 解碼失敗、臨時網絡失敗,不能直接算業務死鏈。
⠀
第二,給 LLM 分類和服務映射加穩定層。
⠀
比如緩存中間結果、固定重試策略、低置信度進入人工複核,而不是直接觸發高風險。
⠀
第三,重做存在性閾值。
⠀
不要用“點贊數/上評數”這類大數量直接要求證據頁數量,否則天然容易誤報。
⠀
第四,建立迴歸基線。
⠀
用同一批交付物連續跑 3 次,要求頁面分類、服務映射、風險數基本一致。
⠀
這就是一個典型的工程控制論式修復。
⠀
它不是“看到哪裏紅就修哪裏”,而是先找到系統不穩定的放大器。
⠀
⠀
【重點】六、這兩個 Skill 該怎麼用?
⠀
日常使用其實很簡單。
⠀
如果你遇到一個複雜系統不穩定,可以這樣問:
⠀
調用 engineering-cybernetics-diagnose,
幫我診斷這個系統為什麼不穩定:
[貼系統背景、日誌、代碼線索、異常表現]⠀
它適合回答:
⠀
- 問題在哪裏被放大?
- 哪些是擾動?
- 哪些是反饋?
- 哪些是可控變量?
- 主導瓶頸是什麼?
- 應該先改哪裏?
⠀
如果你已經知道問題,想設計改造方案,可以這樣問:
⠀
調用 engineering-cybernetics-apply,
基於這個診斷結果,幫我設計一個控制閉環:
[貼診斷結論和現有流程]⠀
它適合回答:
⠀
- 控制目標是什麼?
- 需要哪些觀測信號?
- 失敗時怎麼降級?
- 什麼時候重試?
- 怎麼避免誤報?
- 怎麼做迴歸驗證?
- 怎麼讓系統持續穩定?
⠀
⠀
我的建議是:先 diagnose,再 apply。
⠀
先診斷,再設計。
⠀
不要一上來就改系統。
⠀
⠀
【重點】七、它對 AI 編程有什麼意義?
⠀
AI 編程最容易掉進一個坑:把所有問題都當成局部代碼問題。
⠀
但很多 AI 系統的問題,本質不是某一行代碼錯了,而是:
⠀
- 輸入不穩定
- 中間判斷不穩定
- 外部服務不穩定
- 反饋太慢
- 錯誤分類太粗
- 閾值設計太硬
- 後續規則把噪聲放大了
⠀
這類問題,用普通 debug 思路很容易越修越亂。
⠀
工程控制論的好處是,它讓我們先退一步:
⠀
把代碼鏈路看成一個系統。
⠀
把日誌看成反饋。
⠀
把異常看成擾動。
⠀
把規則看成控制器。
⠀
把輸出結果看成被控制變量。
⠀
這樣一來,修復就不再是“哪裏疼治哪裏”,而是開始設計一個更穩定的系統。
⠀
⠀
【重點】八、我現在越來越相信:Skill 是把書變成工具的最好方式
⠀
以前讀書,讀完就是讀完了。
⠀
最多留下幾條筆記。
⠀
但這次把《工程控制論》做成兩個 Skill 後,我感覺它變成了一個可以反覆調用的思考工具。
⠀
我不需要每次都重新回憶控制論概念。
⠀
只要遇到系統不穩定,我就可以調用:
⠀
engineering-cybernetics-diagnose⠀
遇到要設計控制閉環,我就可以調用:
⠀
engineering-cybernetics-apply⠀
這才是“把一本書變成生產力”的感覺。
⠀
不是把書總結成知識點,而是把書裏的方法論,變成可以在真實項目裏反覆調用的操作系統。
⠀
而工程控制論,剛好特別適合這個時代。
⠀
因為我們正在做的很多東西,本質上都是系統:
⠀
AI 工作流是系統。
⠀
自動化任務是系統。
⠀
內容生產鏈路是系統。
⠀
健康記錄同步是系統。
⠀
交付物驗真也是系統。
⠀
只要是系統,就會有反饋、擾動、噪聲、延遲和失控。
⠀
也就需要控制。