我用 AI 翻譯的三個階段:提示詞時代 → 推理模型時代 → Agent 時代
整理版優先睇
AI 翻譯進化:從提示詞到 Agent 工作流,Jim Liu 嘅翻譯 Skill 迭代心得
呢篇文章係作者 Jim Liu 分享佢用 AI 做翻譯近兩年嘅經驗總結。佢發現翻譯表面簡單,但要做到通用好用,要處理輸入多樣、內容長短、質量分級、術語一致性等複雜問題。佢將經歷分成三個階段:提示詞時代要靠手動設計推理鏈(兩步/三步翻譯);推理模型時代用「重寫」代替「翻譯」大幅提升質量;Agent 時代就整合工作流、文件系統同並行執行,形成一套翻譯 Skill。
整體結論係:翻譯提示詞好簡單,但一個好嘅翻譯工具要解決嘅問題遠超提示詞本身。Agent 翻譯透過工作流、外部記憶同子 Agent 並行,做到更快更一致。關鍵在於所有產物持久化、關注點分離、漸進式體驗同並行優先。
作者最後將呢套系統整理成開源 Skill,放喺 GitHub,用 Claude Code 或小龍蝦(Cursor)都得。佢強調人類嘅角色係質量判官同方向指揮——發現問題、提供好壞標準,具體優化交俾 Agent 自己做。
- 翻譯提示詞好簡單,但通用翻譯工具要解決輸入格式、分塊策略、術語一致性、質量分級等問題,唔係一條提示詞搞得掂。
- 推理模型出現後,用「重寫」代替「翻譯」係關鍵轉變,模型有更大自由度處理隱喻同句式重組。
- Agent 翻譯透過工作流、文件系統做外部記憶,同埋並行子 Agent,速度提升幾倍,一致性靠共享提示詞文件保證。
- 所有中間產物(分析、提示詞、初稿、審校)都保存為文件,可追溯、可局部重翻、可無縫升級翻譯模式。
- 人類嘅價值在於判斷質量好壞、發現問題、指明方向;具體點樣改進 Skill,應該俾 Agent 自己分析優化。
Baoyu Translate Skill
可複用嘅 AI 翻譯 Skill,支援快速、普通、精細三種模式,並行翻譯同文件管理,安裝後可用於 Claude Code 或小龍蝦。
翻譯比你想像中複雜
翻譯呢個場景比表面睇複雜好多。提示詞本身好簡單,「將呢段話翻譯成中文」個個都識寫。但要做成一個通用嘅 Skill,你要考慮:輸入千奇百怪,有人貼一句話,有人掉一篇萬字長文,仲有人俾個 Markdown 檔案;每個人常用嘅語言對唔一樣;有時求其快睇個大意,有時要求翻譯質量必須高。
太長嘅內容模型處理唔到或者效果變差,需要分塊,分塊咗又唔保證前後一致。呢啲問題唔係一次想清楚嘅,係一輪輪迭代踩出嚟嘅。
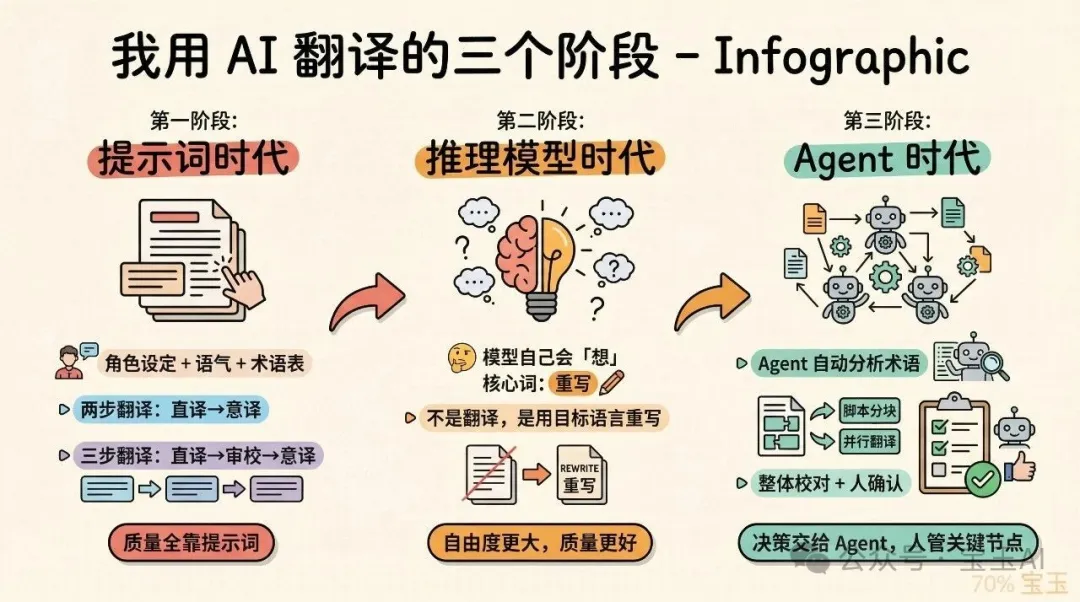
從提示詞到 Agent 嘅三個階段
第一個階段係推理模型出嚟之前。嗰陣翻譯質量全靠提示詞,角色設定、語氣要求、術語表,能塞嘅都塞曬。作者最早公開提出「兩步翻譯」同「三步翻譯」:先直譯再意譯,效果好好但費 Token。
第二階段係推理模型出嚟之後,翻譯提示詞嘅核心變成一個詞:「重寫」——唔係叫模型「翻譯」,而係叫佢用目標語言「重寫」段內容。呢個思路轉變帶嚟嘅質量提升好明顯。
第三階段係 Agent,翻譯工作流可以做得更精細。Agent 會先分析文章、生成提示詞、按結構分塊、起多個子 Agent 並行翻譯,最後合併校對。所有中間結果保存成檔案,方便局部重翻同調試。
Agent 翻譯 vs 傳統提示詞翻譯
- 1 提示詞翻譯:一條提示詞塞曬所有嘢,上下文係全部工作空間;Agent 翻譯:檔案系統係主記憶,上下文只係工作枱。
- 2 提示詞翻譯:一個模型從頭翻到尾,長文章要唔係截斷就係硬塞;Agent 翻譯:按結構安全分塊,多個子 Agent 並行。
- 3 提示詞翻譯:用完即棄,無中間產物;Agent 翻譯:所有中間結果保存成檔案,可追溯、可調試、可局部重翻。
翻譯 Skill 嘅迭代關鍵設計
Skill 嘅創建過程唔複雜:用 skill-creator 講清楚需求,生成初始版本,再用真實文章測試,發現問題就反饋俾 Claude Code 改進。呢個過程中,人類嘅角色係質量判官同方向指揮。
你唔需要去寫 Skill 嘅具體規則,你需要做嘅係發現問題、提供好壞嘅標準,然後等 Agent 自己分析同優化。
- 串行翻譯太慢?直接話畀 Agent「改成並行」,佢自己處理一致性問題。
- 隱喻翻譯生硬?畀兩版翻譯叫佢自己總結規律,佢總結嘅規則比人寫的更系統。
- 所有中間產物持久化:分析報告、翻譯提示詞、初稿、審校意見全部保存成檔案,方便迭代。
讓 Agent 自己發現問題,總結原則
測試中發現一個典型問題:原文「The Swiss had been watching the Japanese in the rear view mirror」,模型直譯做「從後視鏡裏看」,但作者期望嘅係「把日本人看作身後的追趕者」。作者冇自己去改提示詞,而係整理咗高質量翻譯版本,叫 Agent 比較分析。
Agent 分析出核心模式:隱喻要解讀意圖而唔係直譯字面意象;保留用詞情感色彩;用中文嘅強調結構而唔係照搬英文語序。跟住 Agent 自己喺分析階段、翻譯原則同審校階段做咗優化。
- 所有產物持久化:源檔案、分析、提示詞、初稿、審校、終稿都保存為檔案。
- 關注點分離:分析歸分析,翻譯歸翻譯,審校歸審校,子 Agent 只負責初稿。
- 漸進式體驗:默認普通模式,完成後提示可以升級到精細模式。
- 並行優先:透過共享提示詞文件讓多個子 Agent 獨立工作。
我做 AI 翻譯這件事,前前後後折騰了快兩年。從最早手寫提示詞,到現在用 Agent 自動分塊、並行翻譯、審校潤色,中間踩了不少坑,也攢了不少經驗。最近把這些經驗整理成了一個可複用的翻譯 Skill,這篇文章聊聊這個 Skill 是怎麼一步步迭代出來的。
翻譯這個場景比看上去複雜。提示詞本身很簡單,“把這段話翻譯成中文”誰都會寫。但要做成一個通用的 Skill,你得考慮:輸入千奇百怪,有人貼一句話,有人丟一篇萬字長文,還有人給個 Markdown 文件;每個人常用的語言對不一樣;有時候只想快速看個大意,有時候要求翻譯質量必須高。
太長的內容模型處理不了或者效果變差,需要分塊,分塊了又不好保證前後一致。這些問題不是一次想清楚的,是一輪輪迭代踩出來的。
第一個階段是推理模型出來之前。
那時候翻譯質量全靠提示詞,角色設定、語氣要求、術語表,能塞的都塞進去。我應該是最早公開提出用“兩步翻譯”和“三步翻譯”來提升翻譯質量的。
兩步翻譯就是先直譯再意譯,原理類似推理鏈,讓模型先老老實實把原文意思對上,再用更自然的方式重新表達。效果確實好,但費 Token。三步翻譯多了一箇中間的審校環節,先直譯,再審校找問題,最後意譯,效果更好,但上下文佔用很大。
第二個階段是推理模型出來之後。
有了推理能力,不需要我手動設計推理鏈了,模型自己會“想”。這時候翻譯提示詞的核心變成了一個詞:“重寫”。不是讓模型“翻譯”,而是讓它用目標語言“重寫”這段內容。“翻譯”這個詞會讓模型惦記着原文的每個字,“重寫”給了它更大的自由度去處理隱喻、重組句式。這個思路轉變帶來的質量提升很明顯。
第三個階段是 Agent。
到了 Agent 時代,翻譯工作流可以做得更精細。之前所有決策都是我做的:要不要分塊、分多大、用什麼術語表、翻譯質量夠不夠好。現在很多決策可以交給 Agent,但關鍵節點由人來確認。
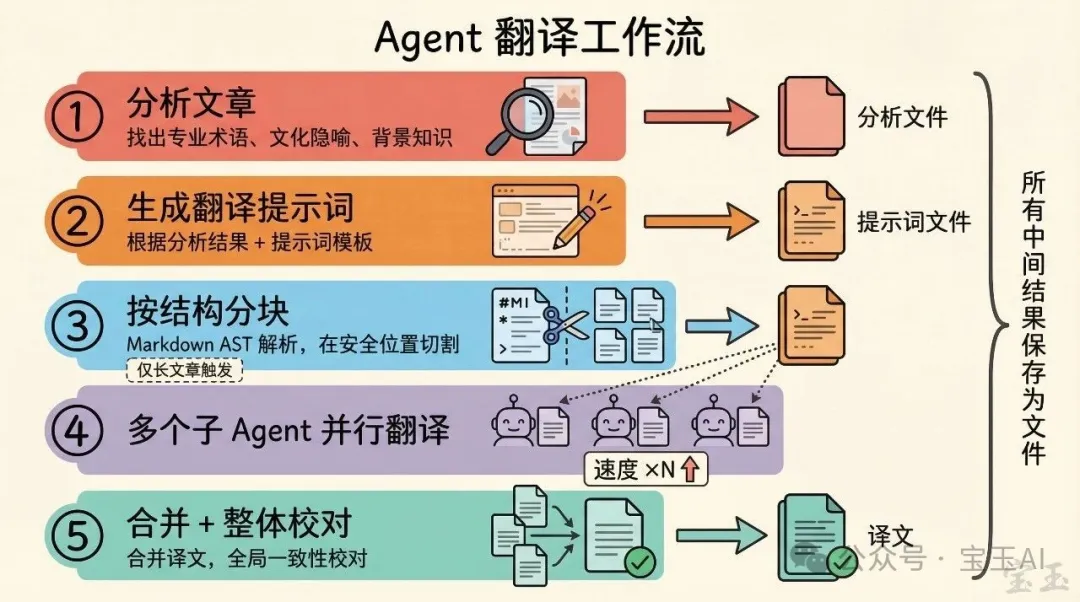
具體來說,我的 Agent 翻譯工作流是這樣的:
1. Agent 先分析要翻譯的文章,找出專業術語、文化隱喻、讀者可能不理解的背景知識,保存成分析文件 2. 根據分析結果和提示詞模板,生成翻譯提示詞,也保存成文件 3. 如果文章太長,用腳本按 Markdown 結構分塊 4. 多個子 Agent 並行翻譯,每個負責一塊 5. 翻譯完合併,再做整體校對
所有中間結果,分析報告、翻譯提示詞、每個分塊的原文和譯文、審校意見,全部保存成文件。翻譯是個迭代過程,某一塊翻得不好可以單獨重翻,不用從頭來。提示詞有問題可以直接改文件,不用重新跑分析。
到了這個階段,自然就想把整套流程做成 Skill 方便重用。
Agent 翻譯和提示詞翻譯有什麼不同
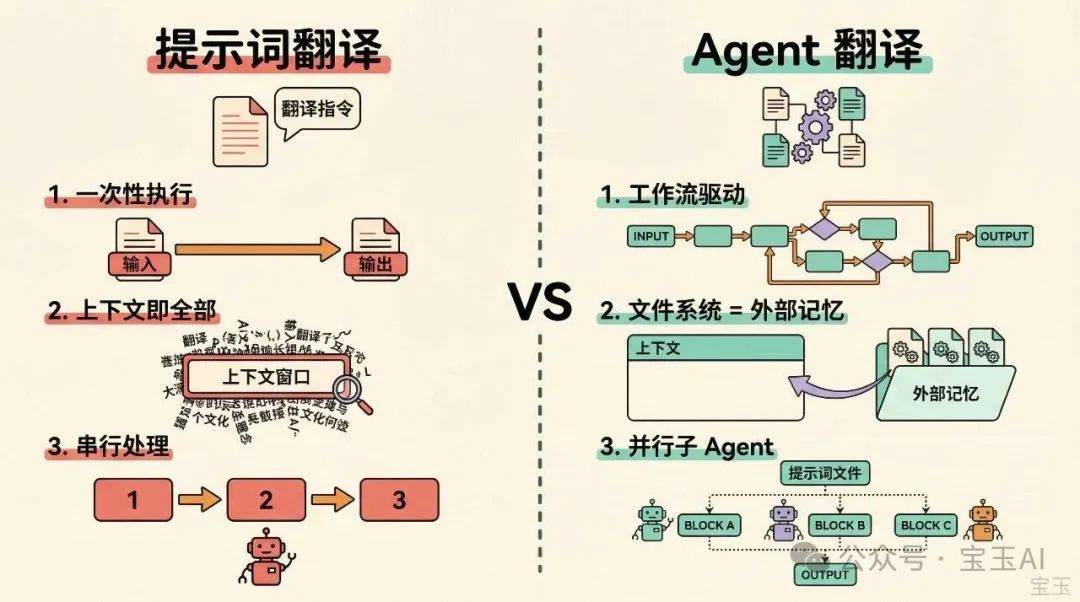
用提示詞翻譯,你把原文、指令、術語表塞進上下文,模型執行一次,輸出就是結果。上下文窗口是你的全部工作空間,所有東西都得擠在裏面。文章一長,要麼截斷要麼硬塞,質量和成本都不好控制。
Agent 翻譯不一樣,差別在三個地方。
第一,Agent 有工作流,不是一次性執行。 它會按 Skill 設計的流程走,但不是死板地按步驟走。碰到短文章跳過分塊,碰到長文章自己分析 Markdown 結構找安全的切分點,碰到純文本和 Markdown 用不同的分塊策略。目標語言、翻譯風格、質量要求,都可以根據用戶需求靈活調整。遇到問題它會自己寫腳本來處理,比如寫一段代碼做 AST 解析,避免把表格或代碼塊切斷。這些靠一條提示詞做不到。
第二,Agent 能用文件系統當外部記憶。 分析結果存成文件,翻譯提示詞存成文件,每一塊的譯文也存成文件。Agent 不需要把所有東西都裝在上下文裏,需要什麼讀什麼,上下文始終保持乾淨。傳統提示詞翻譯,上下文就是你的全部,用完即棄;Agent 翻譯,文件系統才是主記憶,上下文只是工作台。
第三,Agent 可以啓動子 Agent 並行工作。 傳統提示詞翻譯,一個模型從頭翻到尾。Agent 可以起十個子 Agent,每個只拿共享的提示詞文件加自己負責的那一塊,獨立翻譯。速度提升好幾倍,每個子 Agent 的上下文負載還更低,因為它只需要關注自己的那一塊。
這三個能力組合在一起,讓翻譯從”寫一條好提示詞”變成了”設計一套翻譯系統”。後面的內容就是這套系統怎麼一步步迭代出來的。
Skill 怎麼創建和迭代
創建 Skill 的過程本身不復雜。在 Claude Code 裏用 skill-creator,把想法說清楚,它就能生成一個初步版本。
我的第一條指令就把核心需求說清楚了:
幫我為當前項目創建一個新的翻譯的 skill:
1. 兩種模式:正常翻譯,和精細翻譯 2. 有一個 EXTEND.md 可以定製默認的 target 語言、語言到語言的術語表等 3. 如果是普通翻譯,直接翻譯即可 4. 如果是精細翻譯,做成一個工作流:先分析文章內容→初步翻譯→review→潤色等 5. 如果是內容太長,需要分塊翻譯,但是要先把術語、人名先找出來,確保全文一致
同時我直接附上了參考翻譯提示詞和術語表樣例,這樣 Claude 不需要猜測我的翻譯風格偏好。
整個 Skill 的創建和迭代過程是這樣的:
1. 在 Claude Code 裏用 skill-creator,直接把想法說出來,生成初始版本 2. 用生成的版本去翻譯真實文章,不是測試用例,是真的要用的內容 3. 讀翻譯結果,找出不滿意的地方 4. 把問題反饋給 Claude Code,讓它改進 Skill 5. 再翻譯,再檢查,循環往復
這個過程中,人的角色是質量判官和方向指揮。你要能判斷翻譯好不好,要能說清楚哪裏不好,但不需要自己去寫提示詞細節。比如我發現串行翻譯太慢,直接告訴 Agent“改成並行”,它自己去處理並行帶來的一致性問題。再比如隱喻翻譯生硬,我給它兩版翻譯讓它自己總結規律,它總結出來的規則比我寫的更系統。
三種翻譯模式的由來
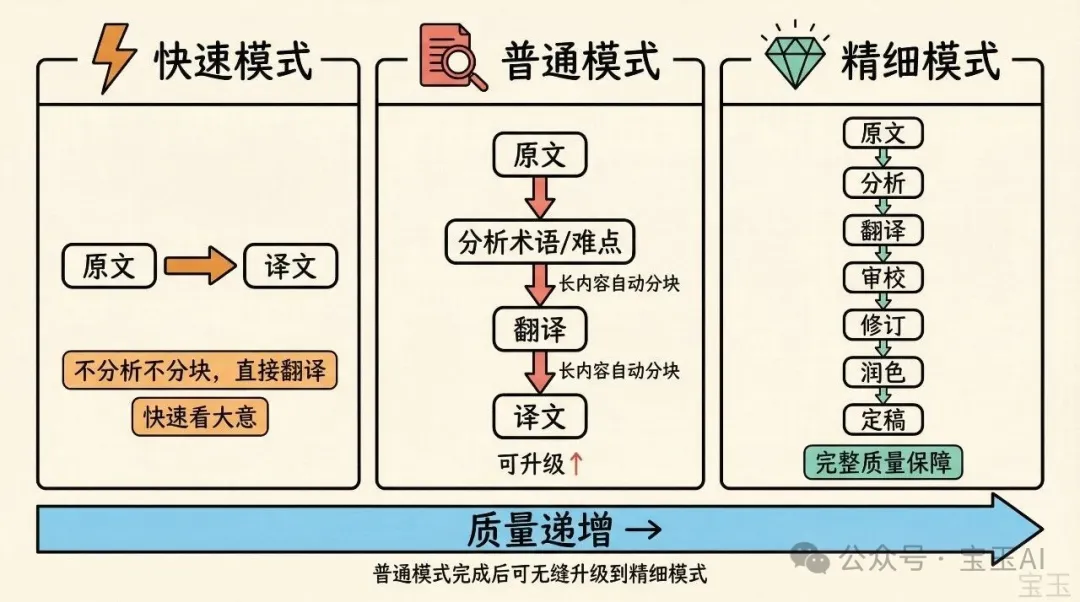
最初只設計了兩種模式:普通和精細。後來發現很多時候只是想快速看個大意,普通模式的分析步驟多餘了,於是加了快速模式,變成三種:
• 快速模式——不分析不分塊,直接翻譯,適合只想快速看個大意 • 普通模式——先分析文章內容,提取術語、識別難點,再翻譯。長內容會自動分塊,翻譯完合併。結束後會問你一句:要不要繼續潤色? • 精細模式——前面和普通模式一樣,但後面會繼續審校翻譯結果,根據審校意見修訂,最後潤色定稿
這裏有個用戶體驗的考慮:默認是普通模式。你不需要提前判斷自己需要什麼級別的翻譯質量。大多數時候普通模式就夠了,看完覺得需要更好,回覆”繼續潤色”就能無縫升級到精細模式。所有中間結果都保存成文件,升級模式時不用重跑前面的步驟。
從串行到並行,解決一致性問題
最初分塊翻譯是串行的。一個子 Agent 按順序翻譯所有塊,上一塊的結果放到下一塊的上下文裏,保證前後連貫。
但速度太慢,十個塊要一個接一個翻譯。更麻煩的是上下文可能會爆,如果截斷之前的內容又沒法用 Prompt Cache,成本反而更高。
改成並行呢?多個子 Agent 同時翻譯不同的塊,速度快了,但一致性沒法保證。同一個術語,第一個子 Agent 翻譯成“護城河”,第三個可能翻譯成“競爭壁壘”。
解決方案是把一致性的保障從“運行時上下文”轉移到“預先分析”。翻譯之前先做一次內容分析,把術語表、翻譯風格、命名約定都確定下來,寫成一份分析報告。然後根據分析報告和提示詞模板,生成一份完整的翻譯提示詞。
每個子 Agent 拿到的是同一份提示詞加上各自負責的分塊內容,術語怎麼翻、風格什麼調性,全部統一。十個塊、十個子 Agent 並行執行,速度提升好幾倍,一致性靠共享的提示詞文件保證。
分塊本身也有講究。最開始按空行分段,會把表格、代碼塊、列表切斷,後續處理很麻煩。後來改成用庫做 Markdown AST 解析,只在結構安全的地方切割,比如段落邊界、標題之後。
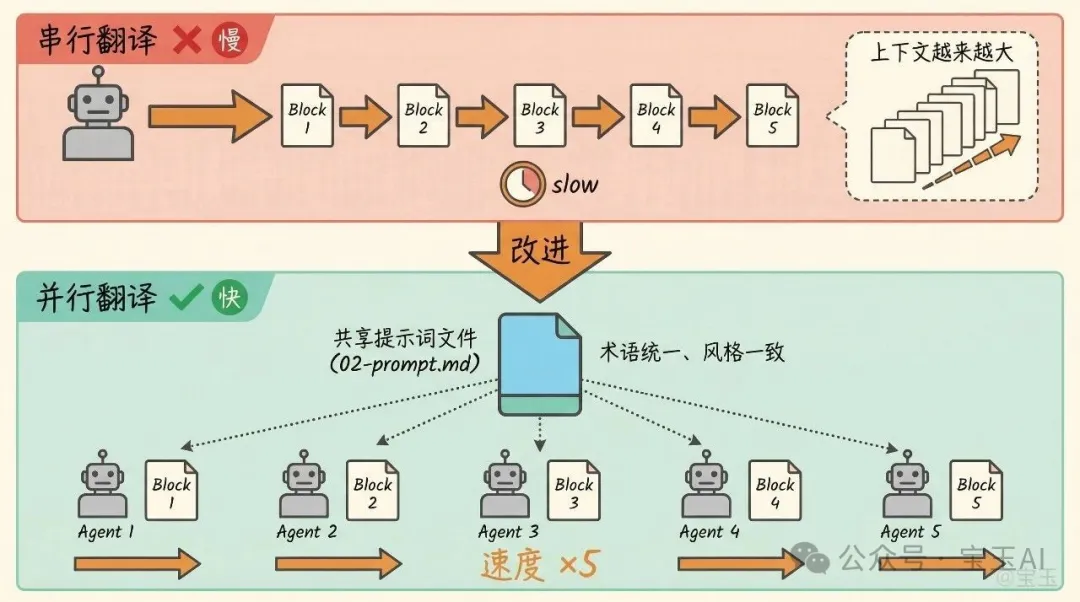
提示詞傳遞的四次重構
這部分是迭代次數最多的。
第一版,讓子 Agent 自己去讀分析文件。子 Agent 還得自己找文件、理解分析結果,增加了不確定性。
第二版,主 Agent 讀取分析文件後,把所有上下文整合成一個完整的提示詞,直接傳給子 Agent。好了一些,但提示詞只存在於調用參數裏,沒法追溯、沒法手動檢查。
第三版,把組裝好的提示詞保存成文件。子 Agent 讀這個文件就行。提示詞本身成了一個可追溯的中間產物,你可以打開看看生成的提示詞對不對,甚至手動改。
第四版,實際測試時發現一個問題:提示詞文件裏包含了分塊列表,子 Agent 看到所有塊的信息會混淆,因為它只負責翻譯一個塊。於是把提示詞拆成兩部分,共享上下文(背景、術語表、翻譯原則)保存為文件,任務指令(翻譯哪個文件、保存到哪裏)作為調用參數單獨傳入。
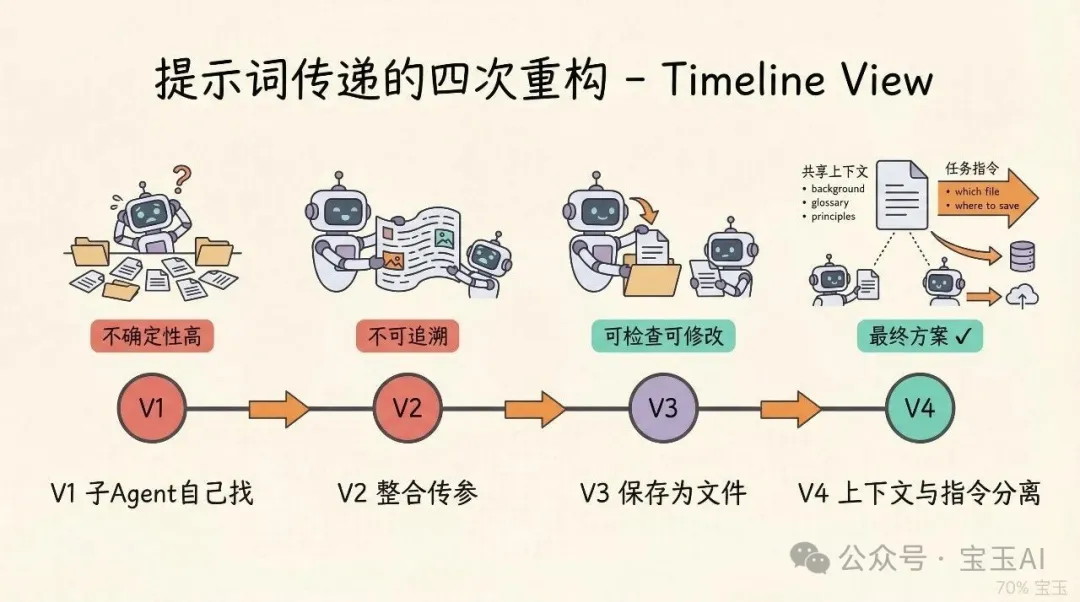
所有產物都保存成文件
無論輸入是文件、URL 還是粘貼的文本,第一步都是保存成文件。然後分析報告、翻譯提示詞、初稿、審校意見、修訂版、最終翻譯,全部保存在同一個目錄裏,用數字前綴標識步驟順序:
• 01-analysis.md—— 內容分析• 02-prompt.md—— 翻譯提示詞• 03-draft.md—— 初稿• 04-critique.md—— 審校意見• 05-revision.md—— 修訂版• translation.md—— 最終翻譯
某個塊翻譯質量不好?單獨重翻那一塊。想看看分析報告有沒有遺漏?直接打開 01-analysis.md。想手動調整翻譯提示詞?改 02-prompt.md 就行。普通模式翻譯完想升級到精細模式?前面的文件都在,直接從審校步驟開始。
並行翻譯也因此可行,提示詞已經是文件了,多個子 Agent 共享同一個文件,天然一致。
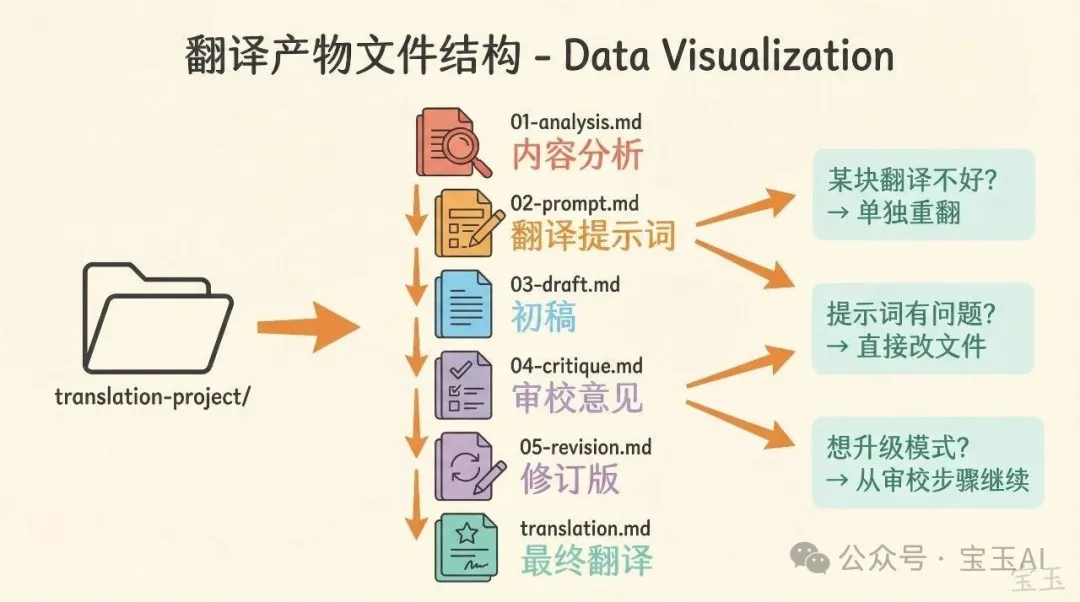
讓 Agent 自己發現問題
翻譯測試中發現一個典型問題。原文是:
“The Swiss had been watching the Japanese in the rear view mirror all through the 1960s, and they'd been improving at an alarming rate.”
模型翻譯成了:
“整個 1960 年代,瑞士人一直從後視鏡裏看着日本人以驚人的速度追趕上來。”
而我期望的翻譯是:
“整個六十年代,瑞士人一直把日本人看作身後的追趕者,而且對方進步的速度已經讓他們感到不安。”
“從後視鏡裏看”是英文隱喻的直譯,中文讀者讀起來彆扭。“alarming”被翻譯成“驚人的”,丟失了原文中瑞士人感到不安的主觀情緒。
我的做法不是自己去改提示詞。我手動整理了一份高質量翻譯版本,然後讓 Agent 自己去比較兩版翻譯,分析哪裏好、怎麼才能翻譯得更好。
Agent 分析出了幾個核心模式:隱喻要解讀意圖而不是直譯字面意象;傳達作者的意思而不是逐詞翻譯;保留用詞的情感色彩,“alarming”不只是“驚人的”,還有“不安”的意味;用中文的強調結構而不是照搬英文語序。
然後 Agent 在三個層面做了優化。分析階段新增了隱喻映射,要求對每個隱喻分析作者意圖、直譯風險、目標語言處理策略。翻譯原則里加了“翻譯意圖不翻譯字面”、“保留情感色彩”。審校階段專門檢查直譯隱喻和情感扁平化問題。
整個過程我做的就是:發現問題、提供對比樣例、指明方向。具體怎麼改 Skill,讓 Agent 自己來。
Agent 比你更懂怎麼寫好提示詞,但你要告訴它方向。 你不需要去寫 Skill 的具體規則,你需要做的是發現問題、提供好壞的標準,然後讓 Agent 自己分析和優化。你測試,你指揮,它執行。
個性化設置
每個人翻譯的需求不一樣。有人主要翻英文到中文,有人翻日文到英文。有人面向技術讀者,有人面向普通讀者。
Skill 裏設計了一個 EXTEND.md 文件,用戶可以設置自己的默認目標語言、翻譯風格、目標讀者、術語表。第一次使用時會引導你做一次設置,之後每次翻譯都會讀取你的配置。
目標讀者這個維度不只是一個配置項,它影響整個翻譯策略。給普通讀者要多加譯註,給技術讀者可以省略常見術語的解釋。學術讀者用正式語體,普通讀者用敍事風格。
譯註本身也有講究。不是簡單標個英文原詞,而是用通俗語言解釋含義。比如“遮禿效應”(comb-over effect,指一系列單獨看來微小的變化,最終將你從略有偏差帶入荒誕失常的境地),讓不瞭解這個概念的讀者也能順暢讀下去。
術語表的精簡
一開始術語表有 60 多條,後來精簡到 15 條。刪掉了 Machine Learning 翻譯成機器學習這類模型本身就知道的,只保留容易翻錯或有爭議的,比如 AI Wrapper 翻譯成 AI 套殼、Hallucination 翻譯成幻覺、Moat 翻譯成護城河。
術語表是給模型的補充知識,不是全部知識。 模型知道的就別重複了,重複太多反而稀釋了真正需要注意的條目。
類似的思路也用在了配置管理上。Skill 裏有分塊閾值、每塊最大詞數這些參數,最開始散落在各處,改一個要找好幾個地方。後來統一放到一個 Defaults 表裏,EXTEND.md 裏的設置可以覆蓋默認值,具體數字只出現一次。
回頭看,幾個反覆出現的原則
第一,所有產物持久化。 源文件、分析、提示詞、初稿、審校、終稿都保存為文件,可追溯、可調試、可恢復。
第二,關注點分離。 分析歸分析,翻譯歸翻譯,審校歸審校。子 Agent 只負責初稿翻譯,審校和潤色需要全局視角,交回主 Agent。
第三,漸進式體驗。 默認普通模式,完成後提示可以升級,用戶不需要提前預判。
第四,並行優先。 在保證質量的前提下儘量並行,通過共享提示詞文件讓多個子 Agent 獨立工作。
第五,提示詞即代碼。 翻譯提示詞保存成文件,可檢查、可修改、可複用。
從“把這段話翻譯成中文”到一個完整的翻譯 Skill,這中間的距離比我預想的大。翻譯提示詞確實簡單,但一個好用的翻譯工具要處理的問題遠不止翻譯本身:輸入格式、分塊策略、術語一致性、質量分級、中間產物管理、個性化配置。這些問題沒有一個能靠一條提示詞解決,但也沒有一個需要你自己從零寫代碼。你的價值在於判斷質量好壞、發現問題、指明方向。具體怎麼優化,讓 Agent 來。
項目地址:https://github.com/JimLiu/baoyu-skills
安裝方法:
npx skills add https://github.com/jimliu/baoyu-skills --skill baoyu-translate
小龍蝦🦞和 Claude code 都可以用。