我用 Codex 把《西遊記》做成繪本 PDF,才發現生圖只是最小的一步
整理版優先睇
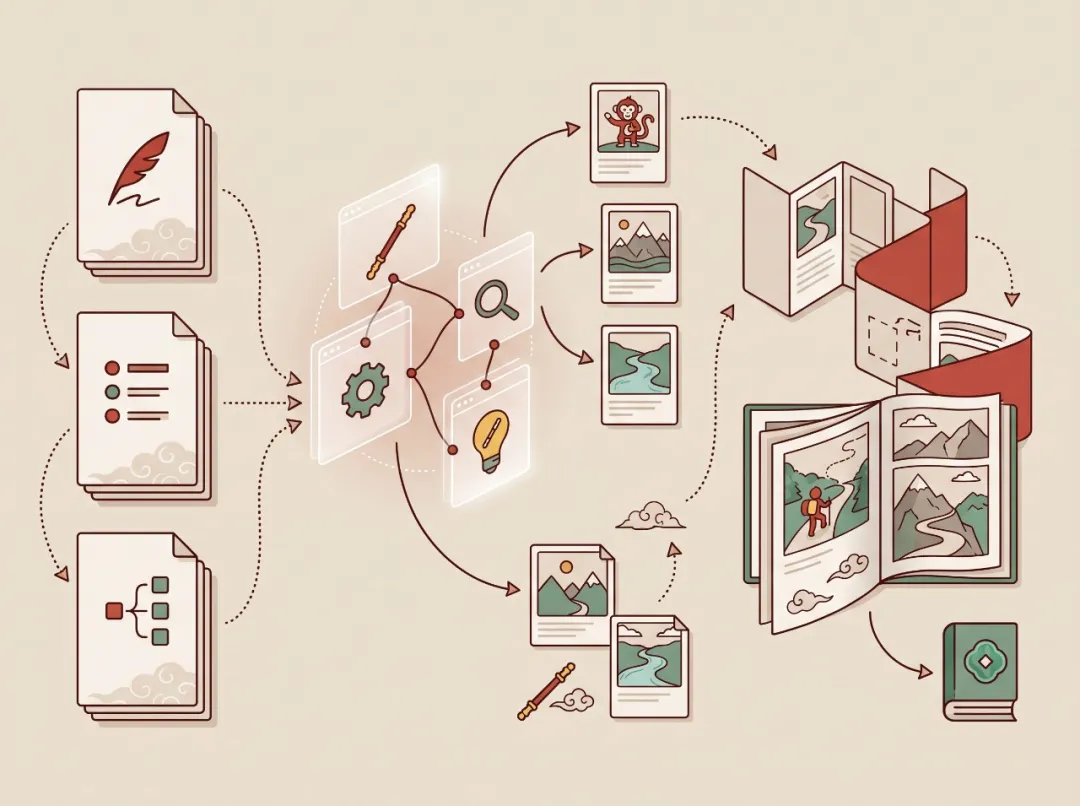
用 Markdown 拆分內容同流程,建立可複用嘅內容生產流水線,生圖只係最細嘅一步
呢篇文章嘅作者係一個技術人,佢想用 AI 生圖工具 Codex 將《西遊記·三打白骨精》整成一本 12 頁嘅繪本 PDF。佢發現直接生圖好易出問題,例如風格不一致、排版錯亂,所以佢決定將成件事拆成四層:用 Markdown 寫內容、解析分鏡、統一生成提示詞、最後拼成 PDF。整體結論係:真正有價值嘅唔係生圖本身,而係嗰條可持續複用嘅生產鏈。
具體做法係將內容同生成解耦,風格同場景分離。佢用 Markdown 儲存分鏡、旁白同風格定義,用 Python 解析並生成提示詞同圖片,再用 reportlab 排版 PDF。過程中先跑通佔位圖再換真圖,減少風險。佢仲整埋英文版,發現字體問題後改用 Helvetica 解決。
呢套流程嘅核心原則係:內容放 Markdown,生成邏輯放 Python。以後換題材(兒童繪本、產品手冊等)只需改內容文件,唔使重寫流程。先驗證管線再追求質量、風格定義只寫一次、輸出要可交付——呢啲都係值得參考嘅工程思維。
- 核心結論:生圖只係最細嘅一步,真正關鍵係建立內容與生成解耦嘅流水線。
- 方法:用 Markdown 儲存內容(分鏡、旁白、風格),用 Python 解析並生成提示詞、圖片同 PDF。
- 差異:將一次性項目變成可重複使用嘅系統,風格定義只寫一次,scene 只描述變化。
- 啟發:先驗證 pipeline 再追求質量,用佔位圖跑通流程係降低風險嘅關鍵。
- 可行動點:可以換故事題材(兒童繪本、產品手冊等),只需修改 Markdown 文件,流程不變。
內容結構
- [00_style.md](./san_da_bai_gu_jing/00_style.md)- [01_scenes.md](./san_da_bai_gu_jing/01_scenes.md)- [02_prompts.md](./san_da_bai_gu_jing/02_prompts.md)- [03_generate.md](./san_da_bai_gu_jing/03_generate.md)背景:生圖只係最細嘅一步
作者想做一本《西遊記·三打白骨精》繪本,睇落好似「生成一堆圖,再拼成一個 PDF」,但佢發現真正有用嘅地方唔係生成本身,而係流程拆分。佢將成件事拆成四層:用 Markdown 寫內容、從 Markdown 解析分鏡、統一生成圖像提示詞、最後拼成 PDF。
最終得到嘅唔係一次性腳本,而係一條可以反覆複用嘅內容生產流水線。佢強調:「內容和流程分離」係關鍵,而唔係「AI 能畫圖」。
內容和流程分離
點解要用 Markdown 做輸入
- 1 內容可讀,分鏡、旁白、風格都可以直接喺文本見到,唔使入數據庫。
- 2 流程可控,改 scene 文本就得,唔使鬱主程式。
- 3 適合自動化,只要約定好結構,例如「#### Scene 1」下面跟描述同旁白,程式就可以穩定抽取數據。
Markdown 天然適合被解析
呢個做法比硬編碼喺腳本入面穩得多。作者仲列出咗核心文件:00_style.md(全局畫風)、01_scenes.md(12個分鏡)、02_prompts.md(提示詞模板)、03_generate.md(生成任務說明),全部係流水線嘅輸入。
- 1 解析分鏡:程式掃描 Markdown,揾出 scene 塊,抽出場景編號、描述同旁白。
- 2 生成提示詞:將全局畫風、角色設定同當前 scene 內容合併成完整 prompt,保證整本書視覺一致性。
- 3 生圖:可以用 Codex 內置或 OpenAI API,唔同路徑但原理相同。
- 4 生成 PDF:用 reportlab 將插圖、旁白、頁碼、標題組合成 PDF,呢步先係真正可交付嘅成果。
實踐經驗:先跑通管線再換圖
作者嘅做法好有工程思維。佢先寫解析器,將 Markdown 嘅 scene 變成數據結構,然後所有步驟都圍繞統一嘅數據模型展開。佢仲做咗 dry-run,用佔位圖跑通整條鏈路,確認 scene 解析、prompt 渲染、PDF 生成都冇問題,先至換真圖。
先跑通,再優化
最後佢仲遇到一個典型問題:英文版文字摺疊擠壓,原因係字體選錯。佢改用 Helvetica 就解決咗。呢個經驗說明咗「你以為係修文案,實際上係修字體同渲染鏈」。
- 內容和生成解耦:故事放 Markdown,生成邏輯放 Python。
- 風格和場景分離:風格定義只寫一次,scene 只描述變化。
- 先驗證 pipeline 管線,再追求質量:先跑通,再優化。
- 輸出要能交付:可打印、可分享、可二次編輯、可復現。
呢套流程點樣複用
作者強調,真正有價值嘅唔係某一張圖,而係嗰條可持續複用嘅生產鏈。你而家已經可以直接用命令生成中文或英文 PDF,只需要改 Markdown 文件就可以換故事、換語言、換風格。
可持續複用的生產鏈
未來仲可以擴展:增加更多章節、輸出更多語言版本、換成唔同題材、加封面目錄、加自動排版校驗。呢個係一個最小可行系統,基礎打得靚,就可以不斷向上發展。
管線越清晰,返工越少
 我用 Codex 將《西遊記 · 三打白骨精》整咗一本 12 頁嘅繪本 PDF。
我用 Codex 將《西遊記 · 三打白骨精》整咗一本 12 頁嘅繪本 PDF。
呢件事望落好似「生成一堆圖,再砌成一個 PDF」,但真正有用嘅地方,唔係生成本身,而係流程嘅拆分。
我將成件事拆成四層:
1. 用 Markdown 寫內容 2. 從 Markdown 度解析分鏡 3. 統一生成圖像提示詞,再調用生圖 4. 將圖片同旁白組合成 PDF
最後得到嘅唔係一次性腳本,而係一條可以反覆重用嘅內容生產流水線。
今次整出嚟嘅係咩嘢
最終產物係一本繪本式 PDF:
• 12 頁 • 每頁一張插圖 • 每頁一條旁白 • 中文版同英文版都可以匯出
 個項目入面已經有呢幾份核心文件:
個項目入面已經有呢幾份核心文件:
- [00_style.md](./san_da_bai_gu_jing/00_style.md)
- [01_scenes.md](./san_da_bai_gu_jing/01_scenes.md)
- [02_prompts.md](./san_da_bai_gu_jing/02_prompts.md)
- [03_generate.md](./san_da_bai_gu_jing/03_generate.md)佢哋唔係「文檔裝飾」,而係成條流水線嘅輸入。
點解用 Markdown
呢套方案嘅關鍵,唔係「AI 識畫圖」,而係「內容同流程分離」。
我用 Markdown 做輸入,有三個直接好處。
第一,內容可讀。
分鏡、旁白、風格、角色設定都可以直接喺文字度睇到,唔使入數據庫、唔使改代碼。
第二,流程可控。
你改嘅係 scene 文字,唔係 Python 邏輯。換故事、換語言、換風格,都唔使鬱主程式。
第三,適合自動化。
Markdown 本身就好適合俾人解析。只要約定好結構,例如:
• #### Scene 1• 描述:...• 旁白:...
程式就可以穩定噉抽取出數據。
呢樣嘢比將所有嘢硬編碼落腳本度穩定得多。
核心原理
呢條流水線本質上係一個內容編排器。
1. 解析分鏡
程式先掃描項目入面嘅所有 Markdown 文件,揾到 01_scenes.md 入面嘅分鏡塊。
每個分鏡包含:
• 場景編號 • 場景描述 • 旁白
例如:
• Scene 1:師徒四人行緊山路 • 旁白:佢哋一直向西行,去揾真經
呢一步嘅作用係將「人寫嘅故事」變成「機器可以處理嘅數據」。
2. 生成提示詞
跟住,程式將三部分內容合併成完整嘅 prompt:
• 全局畫風 • 角色設定 • 當前 scene 嘅內容
噉做嘅目的,係保證成本書嘅視覺一致性。
如果每頁都臨時手寫 prompt,風格會飄,角色會變,畫面會散。
如果將全局風格固定落嚟,淨係替換場景內容,模型更容易保持:
• 人物一致 • 構圖一致 • 顏色一致 • 敍事語氣一致
3. 生圖
呢度有兩條路:
• 用 Codex 內置嘅 image_gen生圖• 用 OpenAI Image API 行腳本化批量生成
今次我實際採用咗前者,原因好簡單:
• 唔需要 OPENAI_API_KEY• 直接喺現有工作流裏面生成可用圖片 • 適合嗱嗱聲做咗本故事書先,然後再返去代碼層整理流程
由原理上睇,兩種方式都係做緊同一件事:將 prompt 變成圖像資產。
4. 生成 PDF
最後一步係排版。
我用 reportlab 將每頁嘅:
• 插圖 • 旁白 • 頁碼 • 標題
結合成 PDF。
呢一步好重要。好多人將「生成圖片」當成終點,但真正可以交付嘅成果往往唔係圖片,而係一本可以直接閲讀、打印、分享嘅文檔。
我係點樣實踐嘅
今次唔係由零亂寫,而係跟住項目現有結構去做。
第一步:先讀現有 Markdown
項目裏面已經有四份關鍵文件:
• 00_style.md:全局畫風同角色約束• 01_scenes.md:12 個分鏡• 02_prompts.md:提示詞模板• 03_generate.md:生成任務說明
即係話素材本身已經結構化咗,程式只需要將佢哋串埋一齊。
第二步:先做解析器,再做生成器
我先寫咗一個 Python 腳本,將 Markdown 裏面嘅 scene 解析成數據結構。
噉做嘅好處係,後面所有步驟都圍繞一個統一嘅數據模型嚟展開。
唔係「讀一段文字就畫一張圖」,而係:
1. 讀 scene 2. 生成 prompt 3. 產出 image 4. 寫 PDF page
每一步都可以單獨驗證。
第三步:先跑 dry-run
喺正式出圖之前,我先用佔位圖跑通咗成條鏈路。
呢個動作睇落簡單,但好關鍵。
佢可以確認:
• scene 係咪正確解析到 • prompt 係咪正確渲染到 • PDF 係咪生成到 • 頁數係咪對齊
嗱嗱聲打通咗條管線先,然後再將佔位圖替換成真圖,風險最低。
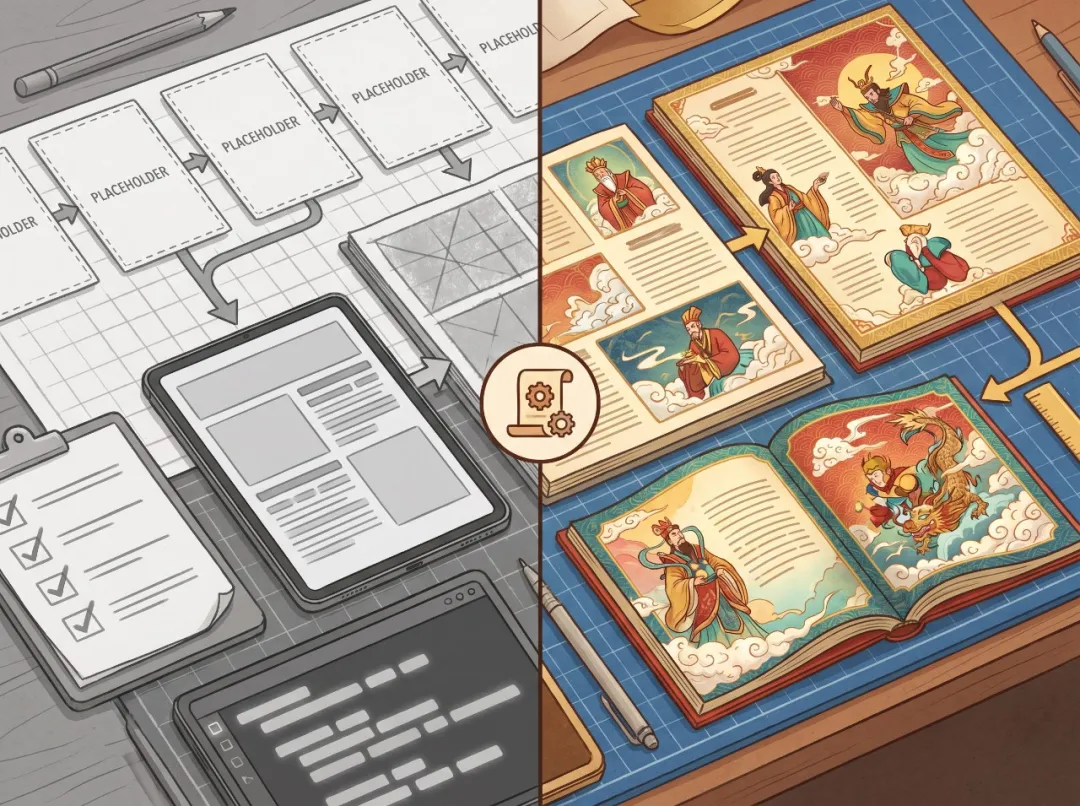
第四步:再用 Codex 生圖替換佔位圖
跟住我用 Codex 嘅內置生圖能力,逐張生成 12 張繪本圖。
每張圖都放返落項目目錄,再由 PDF 生成器讀取。
噉樣成個項目就冇依賴臨時文件,亦都冇將「生成資產」留喺工作區外面。
第五步:補英文版
中文版跑通之後,我又加咗英文旁白同英文標題輸出。
呢一步唔係簡單翻譯,而係將「同一套視覺資產」變成「雙語可交付版本」。
最後又遇到一個典型問題:
• 英文頁文字睇落摺疊、擠壓
原因唔係內容本身,而係 PDF 字體揀錯咗。
我將英文頁改做 Helvetica,問題就消失咗。
呢個就係工程上嘅真實過程:你以為係改文案,實際上係改字體同渲染鏈。
呢套流程嘅價值
呢類項目真正值得重用嘅,唔係「做咗一本書」,而係呢幾個原則。
1. 內容同生成解耦
故事內容放 Markdown,生成邏輯放 Python。
以後換成其他題材,例如:
• 兒童繪本 • 企業案例集 • 產品手冊 • 雙語故事集
都只需要換內容文件,唔使重寫流程。
2. 風格同場景分離
風格定義只寫一次,scene 只描述變化。
噉樣先可以保證成本書係「同一本」,而唔係「十二張各自獨立嘅圖」。
3. 先驗證 pipeline 管線,再追求品質
先跑通,再最佳化。
先確認可以匯出 PDF,再去調整 prompt。
先確認版式正常,再去執著藝術風格。
呢個方法比一開始就追求完美更有效。
4. 輸出要交到貨
淨係出到圖仲唔夠,最終交付物最好係:
• 可以打印 • 可以分享 • 可以二次編輯 • 可以重現
PDF 啱啱符合呢個目標。
點樣用呢套項目
而家呢套流程已經可以直接跑。
生成中文 PDF
直接用現成圖片生成 PDF:
python3 storybook_pipeline.py --use-existing-images輸出會喺:
• build/storybook/san_da_bai_gu_jing_storybook.pdf
生成英文 PDF
如果要英文版:
python3 storybook_pipeline.py --language en --use-existing-images輸出會喺:
• build/storybook/san_da_bai_gu_jing_storybook_en.pdf
重新生成圖片同 PDF
如果你想改圖,再重新行曬成條鏈路,可以切返去生圖模式。
而家項目入面保留咗兩條思路:
• Codex 內置生圖,適合直接喺現有工作流裏面生產圖片 • OpenAI API 路徑,適合批處理同腳本化接入
改故事內容
如果要換一個故事,只需要改呢啲 Markdown:
• 00_style.md• 01_scenes.md• 02_prompts.md
程式會自動重新解析並生成新嘅頁面。
一個值得留意嘅工程細節
好多人第一次做呢類項目,注意力會放喺「生圖係咪更加似原著風格」上面。
但真正容易出問題嘅,往往係後半段:
• 圖片尺寸唔統一 • 版面爆出嚟 • 字體唔兼容 • 英文顯示變形 • PDF 頁數同 scene 數唔一致
所以今次我特登將流程拆開,令到每一層都可以單獨檢查。
事實證明,管線越清晰,返工越少。
結語
今次做嘅唔係單張圖,而係一套可以重複生產繪本嘅最小系統。
佢嘅邏輯好簡單:
• Markdown 管內容 • prompt 管風格 • Codex 管生圖 • Python 管編排 • PDF 管交付
如果以後繼續擴展,呢套結構仲可以再長大:
• 增加更多章節 • 輸出更多語言版本 • 換成唔同題材 • 加封面同目錄 • 加自動排版同校驗
真正有價值嘅唔係某一張圖,而係呢條可以持續重用嘅生產鏈。
2026.05.08 22:16
滬·趙巷
📌 聲明:本文由 AI 輔助完成
我把《西遊記 · 三打白骨精》做成了一本 12 頁繪本 PDF。
這件事看起來像“生成一堆圖,再拼成一個 PDF”,但真正有用的地方,不在生成本身,而在流程拆分。
我把整件事拆成了四層:
1. 用 Markdown 寫內容 2. 從 Markdown 裏解析分鏡 3. 統一生成圖像提示詞,再調用生圖 4. 把圖片和旁白拼成 PDF
最後得到的不是一次性腳本,而是一條可以反覆複用的內容生產流水線。
這次做出來的是什麼
最終產物是一份繪本式 PDF:
• 12 頁 • 每頁一張插圖 • 每頁一條旁白 • 中文版和英文版都可以導出
項目裏已經有這幾份核心文件:
- [00_style.md](./san_da_bai_gu_jing/00_style.md)
- [01_scenes.md](./san_da_bai_gu_jing/01_scenes.md)
- [02_prompts.md](./san_da_bai_gu_jing/02_prompts.md)
- [03_generate.md](./san_da_bai_gu_jing/03_generate.md)它們不是“文檔裝飾”,而是整個流水線的輸入。
為什麼用 Markdown
這套方案的關鍵,不是“AI 能畫圖”,而是“內容和流程分離”。
我用 Markdown 做輸入,有三個直接好處。
第一,內容可讀。
分鏡、旁白、風格、角色設定都能直接在文本里看,不需要進數據庫、不需要改代碼。
第二,流程可控。
你改的是 scene 文本,不是 Python 邏輯。換故事、換語言、換風格,都不必動主程序。
第三,適合自動化。
Markdown 天然適合被解析。只要約定好結構,比如:
• #### Scene 1• 描述:...• 旁白:...
程序就能穩定抽取數據。
這比把所有東西硬編碼在腳本里要穩得多。
核心原理
這條流水線本質上是一個內容編排器。
1. 解析分鏡
程序先掃描項目裏的所有 Markdown 文件,找到 01_scenes.md 裏的分鏡塊。
每個分鏡包含:
• 場景編號 • 場景描述 • 旁白
例如:
• Scene 1:師徒四人走在山路上 • 旁白:他們一路向西,去尋找真經
這一步的作用是把“人寫的故事”變成“機器可處理的數據”。
2. 生成提示詞
接下來,程序把三部分內容合併成完整 prompt:
• 全局畫風 • 角色設定 • 當前 scene 的內容
這樣做的目的,是保證整本書的視覺一致性。
如果每一頁都臨時手寫 prompt,風格會漂,角色會變,畫面會散。
如果把全局風格固定下來,再只替換場景內容,模型更容易保持:
• 人物一致 • 構圖一致 • 顏色一致 • 敍事語氣一致
3. 生圖
這裏有兩條路:
• 用 Codex 內置的 image_gen生圖• 用 OpenAI Image API 走腳本化批量生成
這次我實際採用的是前者,原因很簡單:
• 不需要 OPENAI_API_KEY• 直接在當前工作流裏生成可用圖片 • 適合先把故事書做完,再回到代碼層整理流程
從原理上看,兩種方式都在做同一件事:把 prompt 變成圖像資產。
4. 生成 PDF
最後一步是排版。
我用 reportlab 把每一頁的:
• 插圖 • 旁白 • 頁碼 • 標題
組合成 PDF。
這一步很重要。很多人把“生成圖片”當成終點,但真正可交付的成果往往不是圖片,而是一本能直接閲讀、打印、分享的文檔。
我是怎麼實踐的
這次不是從零瞎寫,而是沿着項目現有結構往下做。
第一步:先讀現有 Markdown
項目裏已經有四份關鍵文件:
• 00_style.md:全局畫風和角色約束• 01_scenes.md:12 個分鏡• 02_prompts.md:提示詞模板• 03_generate.md:生成任務說明
這意味着素材本身已經結構化了,程序只需要把它們串起來。
第二步:先做解析器,再做生成器
我先寫了一個 Python 腳本,把 Markdown 裏的 scene 解析成數據結構。
這樣做的好處是,後面的所有步驟都圍繞一個統一的數據模型展開。
不是“讀一段文本就畫一張圖”,而是:
1. 讀 scene 2. 生成 prompt 3. 產出 image 4. 寫 PDF page
每一步都可單獨驗證。
第三步:先跑 dry-run
在正式出圖前,我先用佔位圖跑通了整條鏈路。
這個動作看起來樸素,但很關鍵。
它能確認:
• scene 是否能正確解析 • prompt 是否能正確渲染 • PDF 是否能生成 • 頁數是否對齊
先把管線打通,再把佔位圖替換成真圖,風險最低。
第四步:再用 Codex 生圖替換佔位圖
接着我用 Codex 的內置生圖能力,逐張生成 12 張繪本圖。
每一張圖都落到項目目錄裏,再由 PDF 生成器讀取。
這樣整個項目就沒有依賴臨時文件,也沒有把“生成資產”留在工作區外。
第五步:補英文版
中文版跑通之後,我又加了英文旁白和英文標題輸出。
這一步不是簡單翻譯,而是把“同一套視覺資產”變成“雙語可交付版本”。
最後又遇到了一個典型問題:
• 英文頁文字看起來摺疊、擠壓
原因不是內容本身,而是 PDF 字體選錯了。
我把英文頁改成 Helvetica,問題就消失了。
這就是工程上的真實過程:你以為是在修文案,實際上是在修字體和渲染鏈。
這套流程的價值
這類項目真正值得複用的,不是“做了一本書”,而是這幾個原則。
1. 內容和生成解耦
故事內容放 Markdown,生成邏輯放 Python。
以後換成別的題材,比如:
• 兒童繪本 • 企業案例集 • 產品手冊 • 雙語故事集
都只需要換內容文件,不需要重寫流程。
2. 風格和場景分離
風格定義只寫一次,scene 只描述變化。
這樣才能保證整本書是“同一本”,而不是“十二張各自獨立的圖”。
3. 先驗證 pipeline 管線,再追求質量
先跑通,再優化。
先確認能導出 PDF,再去調 prompt。
先確認版式正常,再去糾結藝術風格。
這比一開始就追求完美更有效。
4. 輸出要能交付
只會出圖還不夠,最終交付物最好是:
• 可打印 • 可分享 • 可二次編輯 • 可復現
PDF 正好符合這個目標。
怎麼用這套項目
現在這套流程已經能直接跑。
生成中文 PDF
直接用現成圖片生成 PDF:
python3 storybook_pipeline.py --use-existing-images輸出會在:
• build/storybook/san_da_bai_gu_jing_storybook.pdf
生成英文 PDF
如果要英文版:
python3 storybook_pipeline.py --language en --use-existing-images輸出會在:
• build/storybook/san_da_bai_gu_jing_storybook_en.pdf
重新生成圖片和 PDF
如果你想改圖,再重新走整條鏈路,可以切回生圖模式。
當前項目裏保留了兩條思路:
• Codex 內置生圖,適合直接在當前工作流裏生產圖片 • OpenAI API 路徑,適合批處理和腳本化接入
改故事內容
如果要換一個故事,只需要改這些 Markdown:
• 00_style.md• 01_scenes.md• 02_prompts.md
程序會自動重新解析並生成新的頁面。
一個值得注意的工程細節
很多人第一次做這類項目,注意力會放在“生圖是不是更像原著風格”上。
但真正容易出問題的,往往是後半段:
• 圖片尺寸不統一 • 版面溢出 • 字體不兼容 • 英文顯示變形 • PDF 頁數和 scene 數不一致
所以這次我特意把流程拆開,讓每一層都能單獨檢查。
事實證明,管線越清晰,返工越少。
結語
這次做的不是單張圖,而是一套可重複生產繪本的最小系統。
它的邏輯很簡單:
• Markdown 管內容 • prompt 管風格 • Codex 管生圖 • Python 管編排 • PDF 管交付
如果以後繼續擴展,這套結構還能往下長:
• 增加更多章節 • 輸出更多語言版本 • 換成不同題材 • 加封面和目錄 • 加自動排版和校驗
真正有價值的不是某一張圖,而是這條可持續複用的生產鏈。
2026.05.08 22:16
滬·趙巷
📌 聲明:本文由 AI 輔助完成