我用 HyperFrames + F5,把三篇文章批量做成了帶克隆旁白的視頻
整理版優先睇
用 HyperFrames 同 F5-TTS 批量將技術文章變成有克隆旁白嘅橫屏視頻,重點係流程同挖坑經驗
作者係一個內容創作者,成日要將技術文章轉成視頻分享。佢面對嘅問題係:文章同視頻嘅節奏唔同,唔可以直接掉 Markdown 入去。所以佢用咗 HyperFrames 做畫面合成,F5-TTS 做聲音克隆,將三篇已經寫好嘅技術文章(分別講全模態工作流、Codex 功能避坑同 Hermes iMessage 配置)各自做成 1920×1080 橫屏解說視頻,每條都有旁白,而且聲音貼近佢提供嘅錄音。整體結論係:只要做足預備功夫——拆文章、寫口播、定風格、校對旁白稿、對齊參考音頻——就可以批量產出有質素嘅視頻,唔使每次從零開始。
呢個流程嘅第一步係拆文章。作者將每篇原文拆成 7 個小段,每段只講一個重點,令觀眾容易跟到。每個目錄獨立分開,避免改檔案時混亂。之後係視覺風格:三篇文章氣質唔同,所以分別用咗深色技術風、淺色風險標記風同聊天氣泡風,配合截圖、數字同命令,令畫面有層次。
最大嘅挑戰係克隆旁白。作者用 F5-TTS,但一開始生成嘅聲音係雜音。佢冇即刻換工具,而係拆開鏈路檢查:發現參考音頻太長,而且 ref_text 同實際音頻唔對齊,搞到模型崩潰。修法係將參考音頻裁到合適長度,並寫返對應嘅文本。之後統一響度處理,確保三條旁白音量一致。合成視頻時,仲要留意字體同英文術語粘連嘅問題。最後做三類驗收:視頻參數、畫面抽幀、音頻 ASR,確保成片冇問題。作者認為最值得複用嘅係呢個「拆鏈路」嘅思路,尤其係聲音相關嘅問題。
- 將文章拆成每段只講一件事嘅口播稿,係最關鍵嘅起步。
- 三篇文章用三種不同視覺風格,避免統一模板帶嚟嘅沉悶。
- F5-TTS 克隆旁白嘅最大坑:參考音頻同文本必須完全對齊,否則會出雜音。
- 合成視頻時要處理字體、術語粘連等細節,否則影響專業感。
- 最終驗收要檢查視頻參數、畫面抽幀同音頻 ASR,確保鏈路正常。
內容片段
hermes-multimodal-video/audio/narration-f5.wavcodex-features-video/audio/narration-f5.wavhermes-imessage-video/audio/narration-f5.wav第一步:文章拆段,準備口播稿
文章同視頻嘅節奏好唔同,觀眾一秒跟唔上就會飄走。所以第一步唔係直接將 Markdown 掉入工具,而係將每篇文章拆成 7 個小段,每段只講一件事。
每段只講一件事
- Hermes 全模態:重點係「免費 API 點樣接入 Agent 工作流」
- Codex 功能避坑:重點係「邊啲功能真有用,邊啲唔好亂開」
- Hermes 接 iMessage:重點係「由前置條件到手機實測嘅完整流程」
第二步:每篇獨立設計視覺風格
三篇文章氣質唔同,作者冇用統一模板。Hermes 全模態用深色技術風,綠色藍色做高亮;Codex 功能避坑用淺色底、紅黑強調;Hermes 接 iMessage 保留聊天氣泡同終端截圖,令觀眾一眼知道主題。
技術視頻唔好只堆大標題
- 標題負責話畀觀眾「呢段講咩」
- 截圖負責證明「呢一步真係做到咗」
- 數字同命令負責令人記住關鍵點
第三步:克隆旁白 - F5-TTS 嘅實戰與陷阱
旁白用 F5-TTS,但一開始生成嘅係雜音。作者冇即刻換工具,而係拆開鏈路逐層揾問題。
- 1 參考音頻要裁到合適長度,唔好太長
- 2 ref_text 必須同裁剪後音頻完全一致
- 3 技術詞要寫成自然口播,例如「Node 大過等於十八點十七」
參考音頻同參考文本要對齊
技術詞要寫成自然口播
修完後用 F5 生成三段旁白,再統一做響度處理:loudnorm=I=-17:TP=-2:LRA=11,48kHz stereo。
第四步:合成視頻嘅魔鬼細節
視頻能導出唔代表冇問題。作者遇到字體變成方塊,因為章節標籤用咗純等寬字體,中文 fallback 接唔好。另外英文術語粘連,例如「HermesAgentFullAccess」,係換行邏輯太粗暴食咗空格。
中文標籤要改用系統中文字體
英文術語粘連要按單詞、空格、中文字分別處理
- 技術截圖嘅英文命令保留等寬字體
- 視頻界面上嘅中文標籤用系統字體
- 換行邏輯改為按英文單詞、空格、中文字符分別處理
第五步:最後一定要驗收
作者做咗三類檢查:視頻參數、畫面抽幀、音頻抽檢。
- 視頻參數:1920×1080 橫屏、有音軌、AAC 48kHz
- 畫面抽幀:中文冇方塊、英文術語冇粘連、截圖冇擋正文、大標題冇超出畫面
- 音頻抽檢:WAV 有冇聲、響度正常、ASR 能辨識核心內容
ASR 能穩定抓到主幹內容
今次我做咗件好適合內容創作者嘅事:
將三篇已經寫好嘅技術文章,分別整成 1920×1080 橫屏影片,而且每條都有旁白,把聲仲盡量貼近我提供嘅嗰段錄音。
三篇文章分別係:
最後整出嚟唔係三條套模板嘅影片,而係每篇獨立定風格、獨立寫口播、獨立開資料夾、獨立匯出。
先睇結果。
瑕疵一定有㗎,始終係一次過,好多細節之後可以再優化,例如語速、發音等。
主要睇過程
你可以將呢篇文 send 畀 codex ,佢會知道點樣一步一步做

第一步:唔好急住整影片,先將文章拆成「講得出」嘅內容
文章同影片唔一樣。
文章可以慢慢睇,可以來回翻;影片唔得,觀眾一秒跟唔上,之後就好易飛走。
所以我第一步唔係直接將 Markdown 掉畀工具,而係先將每篇文章拆成 7 個細段。每個細段淨係講一件事:
Hermes 全模態呢篇,重點係「免費 API 點樣接入 Agent 工作流」
Codex 功能避坑呢篇,重點係「邊啲功能真係有用,邊啲唔好亂開」
Hermes 接 iMessage 呢篇,重點係「由前置條件到手機實測嘅完整流程」
每條影片都配咗一份 narration_script.md,即係最終嘅旁白稿。咁樣之後無論係生成音頻定係對齊畫面節奏,都有個穩定嘅文本底稿。
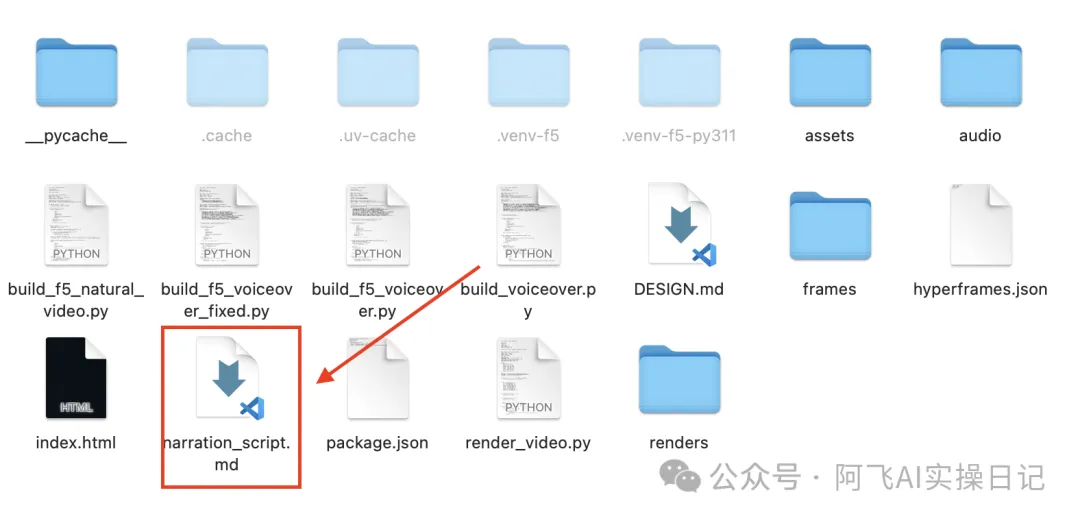
我嘅目錄係咁樣分:
hermes-multimodal-video/
codex-features-video/
hermes-imessage-video/
每個目錄入面都有:
DESIGN.md
narration_script.md
index.html
assets/
audio/
renders/
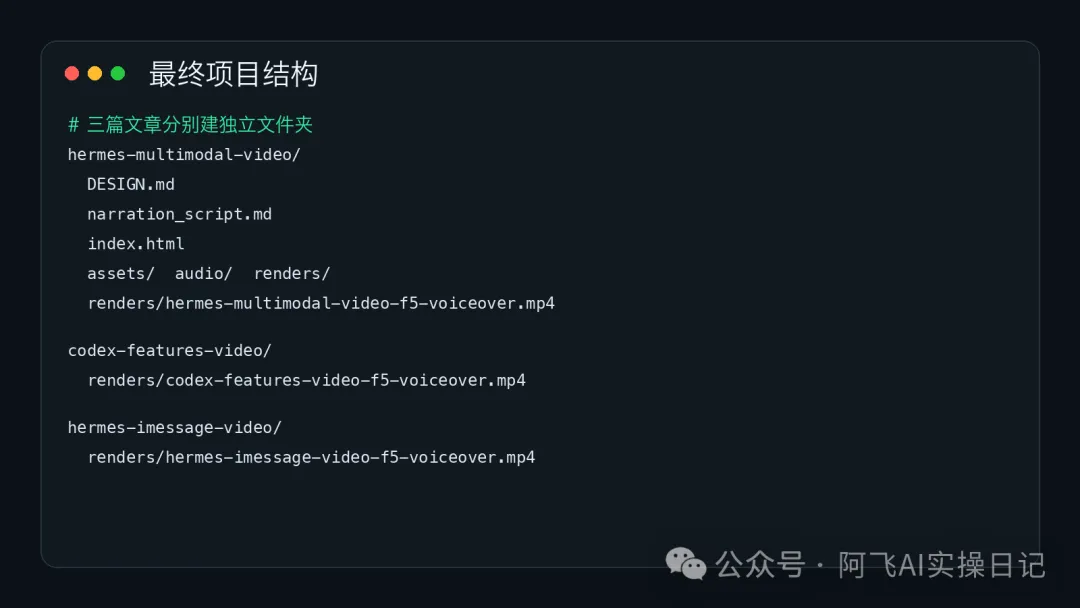
呢個結構好重要。千祈唔好將三條影片撈埋同一個目錄,唔係之後你改音頻、改截圖、重新渲染時,好易搞到自己亂曬籠。
第二步:每篇文章獨立揀風格
今次我冇用一個統一模板套三條影片。
原因好簡單:三篇文章嘅氣質唔同。
Hermes 全模態嗰篇,講嘅係模型、API、Agent、全模態工作流,所以我用咗偏深色嘅技術感界面,綠色同藍色做高亮,截圖放右邊,左邊放判斷同步驟。

Codex 功能避坑嗰篇,內容其實似「功能優先級清單」。如果都整成 cyber 風,就會顯得太重。所以我用咗淺色底、紅黑強調,更加似一張操作枱上面嘅風險標記。
Hermes 接 iMessage 呢篇,核心係消息網關同手機實測,所以畫面入面保留咗聊天氣泡、終端截圖、狀態檢查呢啲元素,等觀眾一眼睇得出呢個係設定通訊鏈路。
呢度有個小經驗:技術影片唔好淨係堆大標題。
標題負責話畀觀眾聽「呢段講咩」,截圖負責證明「呢步真係做到咗」,數字同命令負責令人記住關鍵點。三層資訊都有,影片先至唔似空洞嘅 PPT。
第三步:用 F5-TTS 做克隆旁白
旁白呢 part,我一開始都比較謹慎。
Edge TTS 好穩定,但佢主要係通用語音合成,唔係拎一段錄音就可以高質量克隆嘅路線。真正要「參考呢段錄音把聲」,更加適合用 F5-TTS 呢種有參考音頻同參考文本嘅方案。
可以自己錄段口播稿做參考音頻,但呢度有個坑,好關鍵。
F5-TTS 唔係隨便掉一段音頻入去就搞掂。佢需要:
參考音頻唔好太長
參考文本要同參考音頻內容對齊
技術詞彙喺旁白稿入面要寫成更接近真實讀法嘅形式
例如模型名、API、Full Access、Auto review、iMessage、Node.js 呢啲詞,如果文本寫得太是但,TTS 就有可能讀得好怪。
所以旁白稿入面我盡量寫成自然口播:
模型選 agnes two point zero flash
Node 大於等於十八點十七
Custom Direct API
Full Access
Auto review
iMessage
唔係每個詞都硬譯中文,亦唔係將英文逐個字母讀出嚟。
最大嘅坑:旁白一開始全部係雜音
呢個問題好典型。
一開始生成出嚟嘅旁白,聽落唔似口播,而係一嚿雜音。呢個時候唔好急住怪影片合成,亦唔好即刻換工具。
我先將問題拆開嚟睇:
如果 MP4 入面音頻有問題,可能係合成階段出錯
如果 WAV 本身就係雜音,咁就係 TTS 生成階段出錯
如果響度正常但聽唔清,可能係參考音頻同參考文本唔匹配
最後定位到,問題出喺 F5-TTS 嘅參考音頻同參考文本。
F5 會對參考音頻做截斷,如果你畀佢嘅參考文本仲係完整長錄音嘅文本,咁佢實際聽到嘅音頻同你話畀佢聽嘅文字就對唔上。對唔上之後,把聲就好易崩。
修正方法都好直接:
先將參考音頻剪成可控長度,再將 ref_text 改成同呢段剪好嘅音頻完全一致嘅文本。
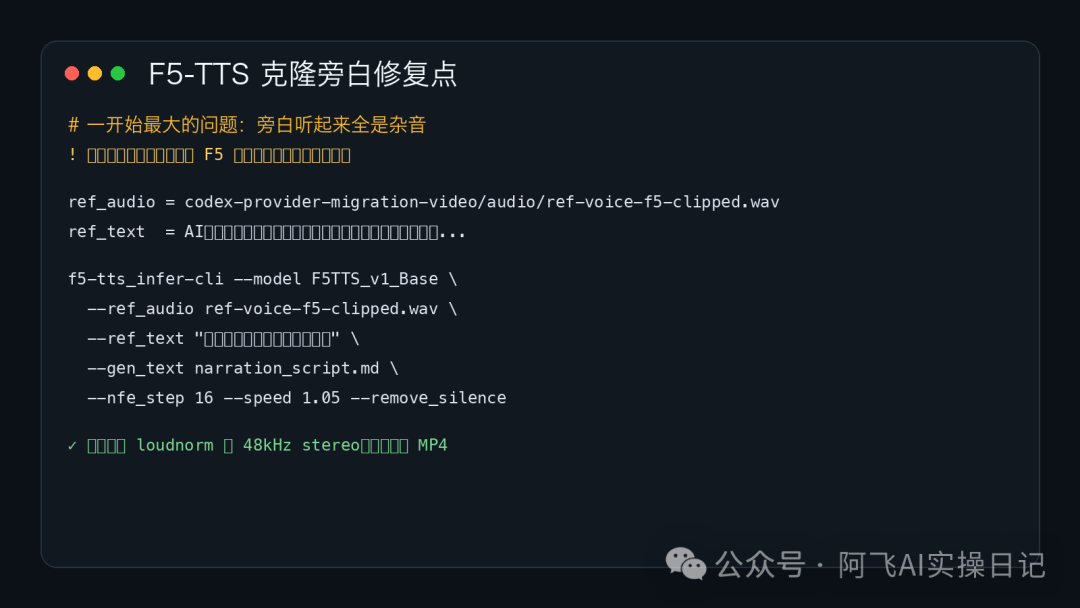
改完之後,再用 F5 生成三段完整旁白:
hermes-multimodal-video/audio/narration-f5.wav
codex-features-video/audio/narration-f5.wav
hermes-imessage-video/audio/narration-f5.wav
然後統一做響度處理:
loudnorm=I=-17:TP=-2:LRA=11
48000 Hz
stereo
咁樣最後放入影片時,音量唔會時大時細,亦唔會一個影片響、另一個影片矇。
第四步:合成影片,唔好淨係睇「可唔可以匯出」
影片可以匯出,唔代表成品冇問題。
今次我踩到嘅另一個小坑係字型。
有啲中文小標籤一開始變咗方塊字。原因係我將章節標籤用咗純等寬字型,英文冇問題,中文 fallback 冇接好,所以就顯示成方塊。
解決方式都好簡單:技術截圖入面嘅英文命令繼續保留等寬字型,但影片界面上嘅中文標籤改返系統中文字型。咁樣唔會冇咗技術感,亦唔會出亂碼。
仲有英文術語黐埋一齊嘅問題,例如:
HermesAgent
FullAccess
Node.js版本
呢類問題唔係 TTS 嘅問題,而係畫面文字換行邏輯太粗疏,將中英文之間嘅空格食咗。
我將文本換行邏輯改成按英文單詞、空格、中文字元分別處理,最後畫面上就變返做:
Hermes Agent
Full Access
Node.js 版本
呢啲細節睇落好細,但公眾號影片、B 站影片入面好明顯。觀眾未必講得出邊度怪,但會覺得畫面唔專業。
第五步:最後一定要驗收
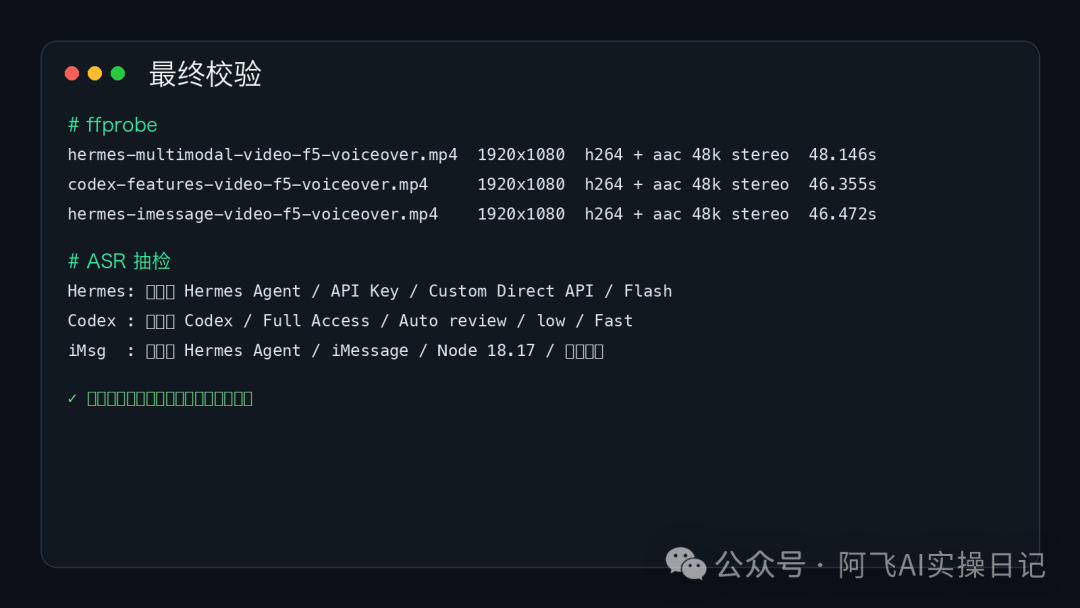
我最後做咗三類檢查。
第一類係影片參數:
係咪真係 1920×1080
係咪橫屏
有冇音軌
音頻係咪 AAC
取樣率係咪 48kHz
第二類係畫面抽格:
中文有冇方塊
英文術語有冇黐埋
截圖有冇遮住正文
大標題有冇超出畫面
第三類係音頻抽檢:
WAV 本身有冇聲
響度是否正常
ASR 可唔可以辨識到核心內容
呢步好重要。
因為「聽落似雜音」同「模型偶爾讀錯一個詞」係兩類完全唔同嘅問題。前者代表生成鏈路壞咗,一定要返工;後者係 TTS 質量問題,可以透過改寫旁白稿繼續優化。
今次最終 ASR 可以辨識到:
Hermes Agent
API Key
Custom Direct API
Codex
Full Access
Auto review
iMessage
Node 18.17
代表音頻唔係雜音,至少語音辨識可以穩定捉到主幹內容。
最後匯出嘅三個檔案
三條成品分別係:
hermes-multimodal-video/renders/hermes-multimodal-video-f5-voiceover.mp4
codex-features-video/renders/codex-features-video-f5-voiceover.mp4
hermes-imessage-video/renders/hermes-imessage-video-f5-voiceover.mp4
參數都確認過:
1920×1080 橫屏
H.264 視頻
AAC 48kHz 雙聲道音頻
時長約 46 到 48 秒
呢套流程最值得重用嘅地方
如果你都想將文章批量變成影片,我覺得最值得抄嘅唔係某個命令,而係呢個順序:
文章拆段
寫成口播稿
每篇單獨定風格
挑文章裏的關鍵截圖
生成克隆旁白
合成視頻
抽幀檢查
ASR 檢查
最後再交付
尤其係克隆旁白呢一步,唔好淨係睇「模型行完未」。
一定要檢查參考音頻、參考文本、旁白文本、技術詞讀法、最終 WAV、最終 MP4。任何一環冇對齊,都可能出現聽落好玄學嘅問題。
今次最有價值嘅經驗就係:把聲崩咗唔好亂換工具,先將鏈路拆開。到底係參考音頻錯、參考文本錯、TTS 生成錯,定係影片封裝錯,逐層排查,問題好快就會浮現。
最後成品出咗之後,其實成套流程就好適合批量做喇。
文章負責深度,HyperFrames 負責畫面節奏,F5-TTS 負責聲音一致性。只要前面嘅口播稿同素材整理得好,一篇文章做成一條橫屏解說影片,就唔再係由零開始。
如果呢篇文章幫到你,順手㩒個讚、睇、轉發三連啦~
如果想第一時間收到推送,都可以畀我個星標⭐
💡推薦閲讀
關於 AI 編程工具,推薦一個🐂🍺嘅中轉工具,一個 key 同時用 Claude code/codex/gemini,性價比超高,服務穩定……
註冊地址:https://aigocode.com/invite/WYVFRE57
另外,提供 ChatGPT Plus 成品號,代充等,㩒文末【閲讀原文】睇詳情!
或加 WeChat:afly813 諮詢
目前我哋嘅 AI CODE 平台已支援 claude code 、codex、Gemini,想體驗最強最前沿嘅 AI 編程,衝就完事了!!🚀
夥伴們,以後寫 code,codex 同 claude 都可以爽歪歪啦!!!
令你嘅 Claude Code 效率飛起!你只差呢個萬能公式!!
呢個先係 AI 編程嘅最強組合,VSCode + Claude Code 令寫 Code 快到飛起!
【附提示詞模板】10 個 Claude code 高頻提示詞模板(可直接複製使用)!建議收藏!!
我哋嘅 ChatGPT 充值服務都已上線,㩒文末【閲讀原文】睇詳情!
鍾意嘅話❤,歡迎點讚、關注一波,之後會持續為大家分享 工作流、 AI 編程等實戰乾貨,一齊學 AI 啦!
這次我幹了一件挺適合內容創作者的事:
把三篇已經寫好的技術文章,分別做成 1920×1080 橫屏視頻,而且每條都有旁白,聲音還儘量貼近我提供的那段錄音。
三篇文章分別是:
最後做出來不是三條套模板的視頻,而是每篇單獨定風格、單獨寫口播、單獨建目錄、單獨導出。
先看結果。
瑕疵是肯定有的,畢竟是一次過的,還有很多細節後面可以再優化,比如語速,發音等
主要看過程
你可以將此文發給 codex ,它會知道如何一步一步的操作的
第一步:別急着做視頻,先把文章拆成“可講”的內容
文章和視頻不一樣。
文章可以慢慢讀,可以來回翻;視頻不行,觀眾一秒鐘沒跟上,後面就容易飄走。
所以我第一步不是直接把 Markdown 丟給工具,而是先把每篇文章拆成 7 個小段。每個小段只講一件事:
Hermes 全模態這篇,重點是“免費 API 怎麼接進 Agent 工作流”
Codex 功能避坑這篇,重點是“哪些功能真有用,哪些別亂開”
Hermes 接 iMessage 這篇,重點是“從前置條件到手機實測的完整流程”
每條視頻都配了一份 narration_script.md,也就是最終旁白稿。這樣後面不管是生成音頻,還是對齊畫面節奏,都有一個穩定的文本底稿。
我的目錄是這樣分的:
hermes-multimodal-video/
codex-features-video/
hermes-imessage-video/
每個目錄裏面都有:
DESIGN.md
narration_script.md
index.html
assets/
audio/
renders/
這個結構很重要。不要把三條視頻混在一個目錄裏,不然後面你改音頻、改截圖、重渲染時,很容易自己把自己繞進去。
第二步:每篇文章單獨選風格
這次我沒有用一個統一模板套三條視頻。
原因很簡單:三篇文章的氣質不一樣。
Hermes 全模態那篇,講的是模型、API、Agent、全模態工作流,所以我用了偏深色的技術感界面,綠色和藍色做高亮,截圖放在右邊,左邊放判斷和步驟。
Codex 功能避坑那篇,內容其實更像“功能優先級清單”。如果也做成賽博風,就會顯得太重。所以我用了淺色底、紅黑強調,更像一張操作枱上的風險標記。
Hermes 接 iMessage 這篇,核心是消息網關和手機實測,所以畫面裏保留了聊天氣泡、終端截圖、狀態檢查這些元素,讓觀眾一眼知道這是在配置通信鏈路。
這裏有個小經驗:技術視頻不要只堆大標題。
標題負責告訴觀眾“這一段講什麼”,截圖負責證明“這一步真的做到了”,數字和命令負責讓人記住關鍵點。三層信息都在,視頻才不像空洞的 PPT。
第三步:用 F5-TTS 做克隆旁白
旁白這塊,我一開始也比較謹慎。
Edge TTS 很穩,但它主要是通用語音合成,不是拿一段錄音就能高質量克隆的路線。真正要“參考這段錄音的聲音”,還是更適合用 F5-TTS 這種帶參考音頻和參考文本的方案。
可以自己錄段口播稿作為參考音頻,但這裏有個坑,非常關鍵。
F5-TTS 不是隨便丟一段音頻進去就完事。它需要:
參考音頻不要太長
參考文本要和參考音頻內容對齊
技術詞要在旁白稿裏寫成更接近真實讀法的形式
比如模型名、API、Full Access、Auto review、iMessage、Node.js 這些詞,如果文本寫得太隨意,TTS 就可能讀得很怪。
所以旁白稿裏我儘量寫成自然口播:
模型選 agnes two point zero flash
Node 大於等於十八點十七
Custom Direct API
Full Access
Auto review
iMessage
不是每個詞都硬翻中文,也不是把英文一個字母一個字母念出來。
最大的坑:旁白一開始全是雜音
這個問題挺典型。
一開始生成出來的旁白,聽起來不是口播,而是一團雜音。這個時候不能急着怪視頻合成,也不能馬上換工具。
我先把問題拆開看:
如果 MP4 裏音頻有問題,可能是合成階段出錯
如果 WAV 本身就是雜音,那就是 TTS 生成階段出錯
如果響度正常但聽不清,可能是參考音頻和參考文本不匹配
最後定位下來,問題出在 F5-TTS 的參考音頻和參考文本。
F5 會對參考音頻做截斷,如果你給它的參考文本還是完整長錄音的文本,那它實際聽到的音頻和你告訴它的文字就對不上。對不上以後,聲音就容易崩。
修法也很直接:
先把參考音頻裁成可控長度,再把 ref_text 改成和這段裁剪音頻完全一致的文本。
修完後,再用 F5 生成三段完整旁白:
hermes-multimodal-video/audio/narration-f5.wav
codex-features-video/audio/narration-f5.wav
hermes-imessage-video/audio/narration-f5.wav
然後統一做響度處理:
loudnorm=I=-17:TP=-2:LRA=11
48000 Hz
stereo
這樣最後放進視頻時,音量不會忽大忽小,也不會一個視頻響、另一個視頻悶。
第四步:合成視頻,不要只看“能不能導出”
視頻能導出,不代表成片沒問題。
這次我踩到的另一個小坑是字體。
有些中文小標籤一開始變成了方塊字。原因是我把章節標籤用了純等寬字體,英文沒問題,中文 fallback 沒接好,就顯示成方塊。
解決方式也簡單:技術截圖裏的英文命令繼續保留等寬字體,但視頻界面上的中文標籤改回系統中文字體。這樣既不丟技術感,也不會出亂碼。
還有英文術語粘連的問題,比如:
HermesAgent
FullAccess
Node.js版本
這類問題不是 TTS 的問題,是畫面文字換行邏輯太粗暴,把中英文之間的空格吃掉了。
我把文本換行邏輯改成按英文單詞、空格、中文字符分別處理,最後畫面上就恢復成:
Hermes Agent
Full Access
Node.js 版本
這種細節看起來小,但公眾號視頻、B 站視頻裏非常明顯。觀眾不一定說得出來哪裏怪,但會覺得畫面不專業。
第五步:最後一定要驗收
我最後做了三類檢查。
第一類是視頻參數:
是否真的是 1920×1080
是否是橫屏
是否有音軌
音頻是不是 AAC
採樣率是不是 48kHz
第二類是畫面抽幀:
中文有沒有方塊
英文術語有沒有粘連
截圖有沒有擋住正文
大標題有沒有超出畫面
第三類是音頻抽檢:
WAV 本身有沒有聲音
響度是否正常
ASR 能不能識別出核心內容
這一步很重要。
因為“聽起來像雜音”和“模型偶爾讀錯一個詞”是兩類完全不同的問題。前者說明生成鏈路壞了,必須返工;後者是 TTS 質量問題,可以通過改寫旁白稿繼續優化。
這次最終 ASR 能識別出:
Hermes Agent
API Key
Custom Direct API
Codex
Full Access
Auto review
iMessage
Node 18.17
說明音頻不是雜音,至少語音識別能穩定抓到主幹內容。
最後導出的三個文件
三條成片分別是:
hermes-multimodal-video/renders/hermes-multimodal-video-f5-voiceover.mp4
codex-features-video/renders/codex-features-video-f5-voiceover.mp4
hermes-imessage-video/renders/hermes-imessage-video-f5-voiceover.mp4
參數也都確認過:
1920×1080 橫屏
H.264 視頻
AAC 48kHz 雙聲道音頻
時長約 46 到 48 秒
這套流程最值得複用的地方
如果你也想把文章批量變成視頻,我覺得最值得抄的不是某個命令,而是這個順序:
文章拆段
寫成口播稿
每篇單獨定風格
挑文章裏的關鍵截圖
生成克隆旁白
合成視頻
抽幀檢查
ASR 檢查
最後再交付
尤其是克隆旁白這一步,不要只看“模型跑完了沒有”。
一定要檢查參考音頻、參考文本、旁白文本、技術詞讀法、最終 WAV、最終 MP4。任何一環沒對齊,都可能出現聽起來很玄學的問題。
這次最有價值的經驗就是:聲音崩了不要亂換工具,先把鏈路拆開。到底是參考音頻錯、參考文本錯、TTS 生成錯,還是視頻封裝錯,一層一層排,問題很快就會露出來。
最後成品出來之後,其實整套流程就很適合批量化了。
文章負責深度,HyperFrames 負責畫面節奏,F5-TTS 負責聲音一致性。只要前面的口播稿和素材整理得好,一篇文章做成一條橫屏解說視頻,就不再是從零開始。
如果文章對你有幫助,隨手點個贊、在看、轉發三連吧~
如果想第一時間收到推送,也可以給我個星標⭐
💡推薦閲讀
關於AI編程工具,推薦一個🐂🍺的中轉工具,一個key同時使用Claude code/codex/gemini ,性價比超高,服務穩定……
註冊地址:https://aigocode.com/invite/WYVFRE57
另外,提供ChatGPT Plus 成品號,代充等,點擊文末【閲讀原文】查看詳情!
或+v:afly813 諮詢
目前我們的 AI CODE 平台已支持 claude code 、codex、Gemini,想體驗最強最前沿的 AI 編程,衝就完事了!!🚀
夥伴們,以後寫代碼,codex和claude都可以爽yy啦!!!
讓你的 Claude Code 效率飛起!你只差這個萬能公式!!
這才是 AI 編程的最強組合,VSCode + Claude Code 讓寫代碼快到飛起!
【附提示詞模板】10個 Claude code 高頻提示詞模板(可直接複製使用)!建議收藏!!
我們的ChatGPT充值服務也已上線,點擊文末【閲讀原文】查看詳情!
喜歡的話❤,歡迎點贊、關注一波,後續會持續為大夥分享 工作流、 AI編程等實戰乾貨,讓我們一起學 AI!