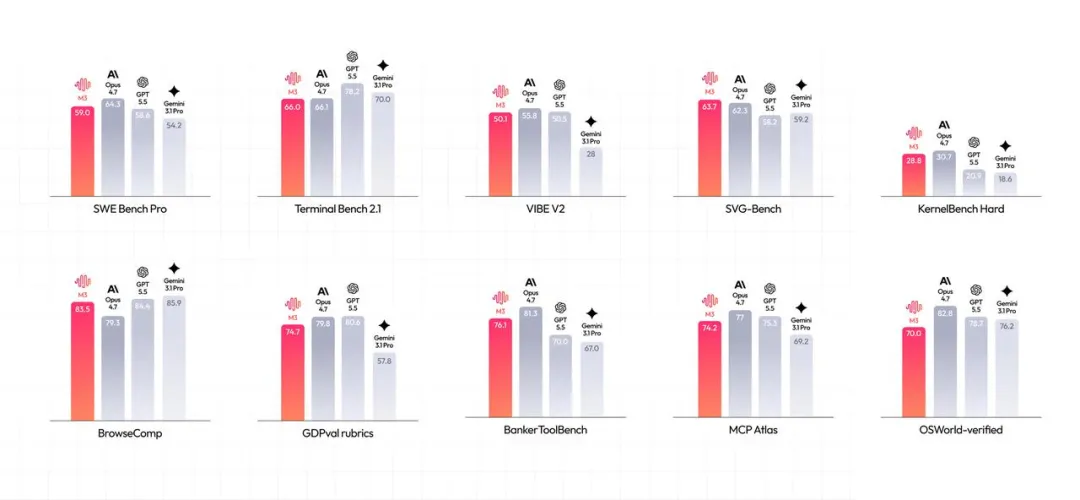
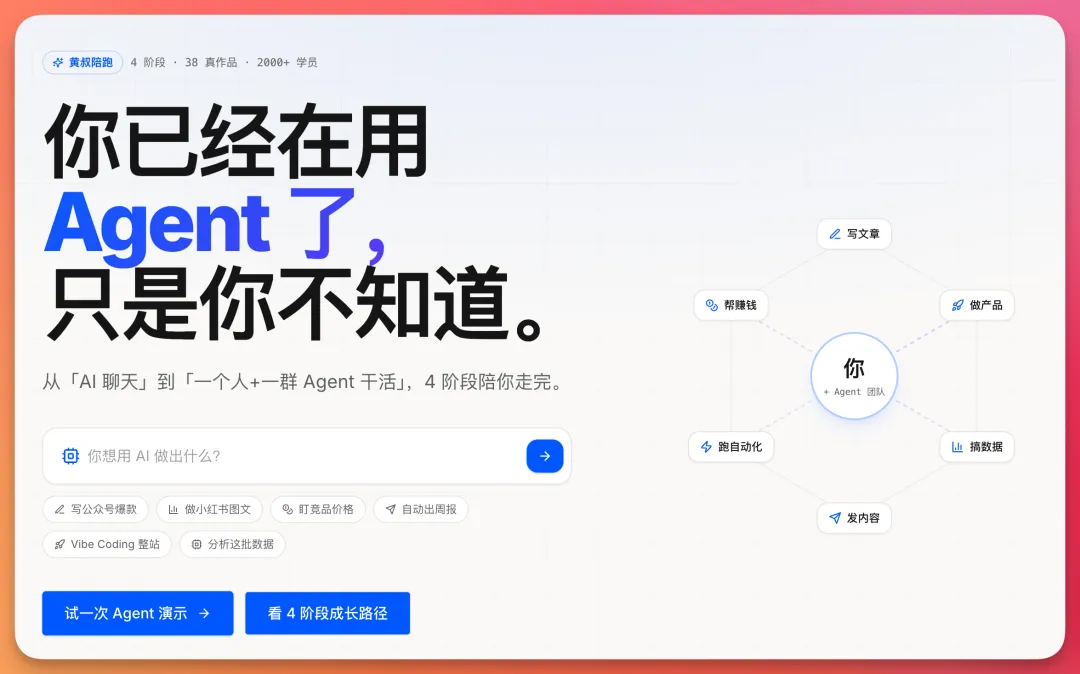
我用 M3 跑了三個真實長程任務,發現它強在後半程
整理版優先睇
M3 最強唔係單點Demo,而係長程任務後半程仲撐得住
作者黃叔係AI領域實踐者,最近用MiniMax M3跑咗三個真實長程任務,目的唔係睇佢單點Demo有幾靚,而係測試佢喺真實項目語境下嘅穩定性。文章指出,M3真正拉開差距嘅位,係任務越拖長、上下文越亂,佢越能將前面嘅資訊同後面嘅動作接起來,唔會中途失憶。
三個任務分別係:將官網從AI編程營銷頁改做成Agent原生官網、用本地知識庫搭建寫作專家團、將飛書知識庫變成可玩嘅網頁探案室。每個任務都涉及讀舊資料、拆任務、改代碼、跑驗證、食反饋,而M3喺呢啲長程工作流入面,後半程表現明顯穩定。
總體結論係:M3強嘅唔係Demo上限,而係長程任務下限。1M上下文嘅真正價值係讓模型喺持續做嘢時唔失憶,保持完整工作現場。但作者亦提醒,長程穩定唔等於全程自治,方向、事實、審美同業務取捨依然要人守門。
- M3 真正拉開差距嘅係長程任務後半程穩定性,而唔係單點 Demo 上限
- 三個真實任務(官網改造、寫作專家團、知識庫探案室)展示咗 M3 喺舊項目語境下理解、拆解、行到尾嘅連續能力
- 弱模型前幾步好靚,但後半程容易忘約束、重複犯錯;M3 能保持上下文唔散,一路將任務帶到尾
- 1M 上下文嘅核心意義係讓模型喺長程任務中唔失憶,而唔係塞更多資料
- 測試 Agent 模型唔好只試小 Demo,要俾一條完整任務鏈;同時記住長程穩定唔等於全程自治,重要決策仲係要靠人
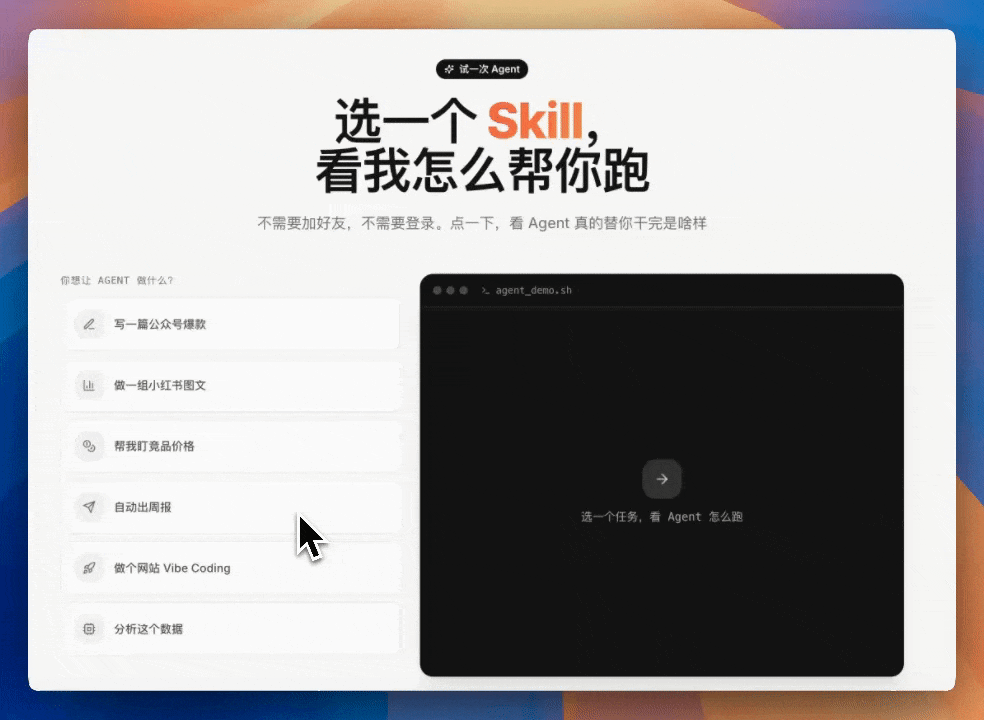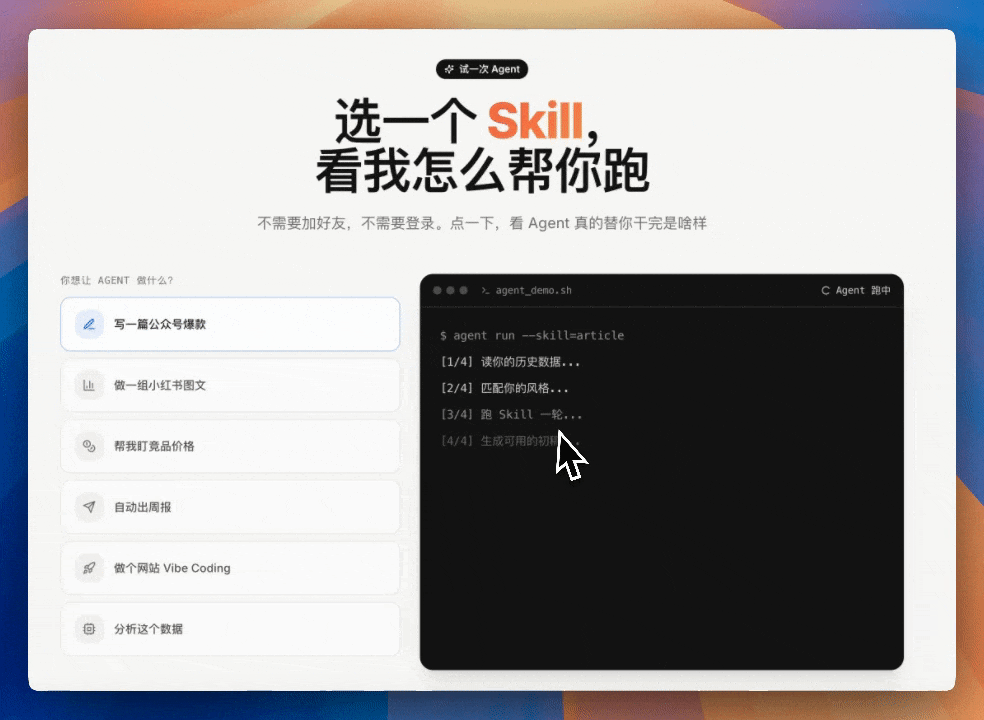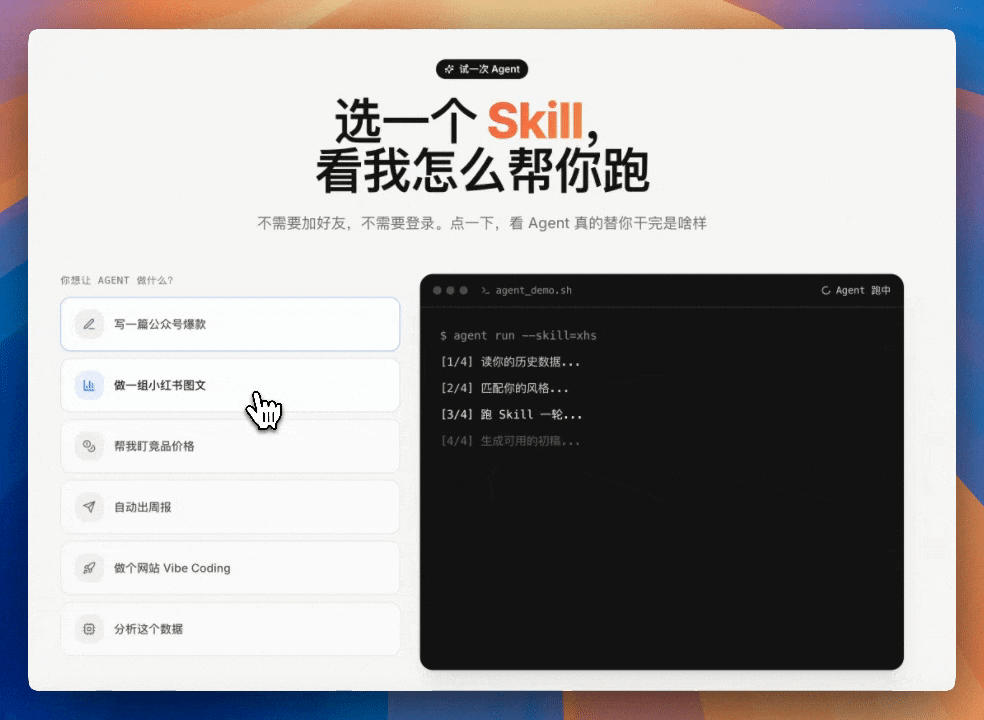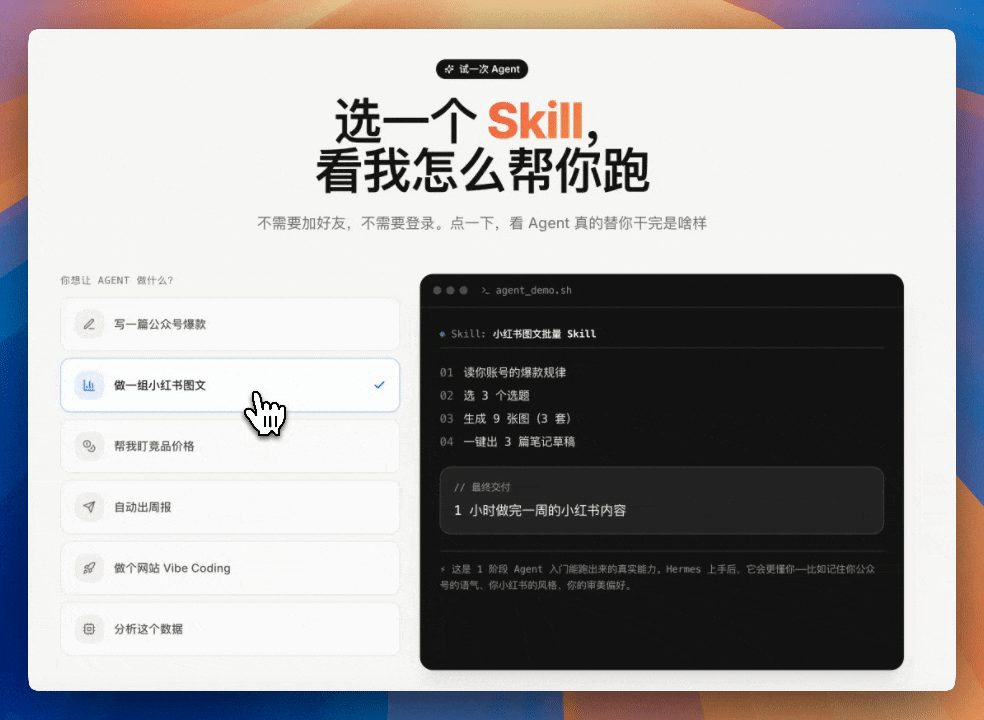
點解要測長程任務?
最近大家都喺度測 MiniMax M3,有人試登錄頁復刻、試視頻理解、試網頁遊戲。但作者覺得,M3 真正要睇嘅係長任務後半程嘅穩定性。真實嘅麻煩唔係「幫我寫一個頁面」,而係你要面對舊代碼、舊文檔、自己嘅知識庫、改咗一半嘅需求,仲要模型唔係表演,而係真係接住一個複雜項目。
所以作者直接用 M3 跑咗三個真實任務:將 zaoxiaban.top 從 AI 編程課程營銷頁改成 Agent Native 官網;用自己嘅知識庫搭建「寫作專家團」;將飛書知識庫變成可玩嘅「探案室」。
M3 嘅更新點對應 Agent 需求
M3 有三個關鍵能力:1M 上下文、原生多模態、Coding 同 Agentic 能力。表面上係三個模型能力點,但放喺 Agent 時代,佢哋對應嘅係 Agent 大腦最緊要嘅三件事:能記住現場、能睇明現場、能推動現場。
- 1M 上下文:唔係為咗塞更多字,而係等模型喺任務後半程仲保留完整工作現場。
- 原生多模態:真實任務嘅輸入唔淨止文字,仲有截圖、圖片、代碼、工具反饋;多模態讓模型直接理解任務環境。
- Coding 同 Agentic:決定模型能唔能夠將理解轉成行動——拆任務、寫代碼、調工具、讀錯誤、繼續修。
MiniMax Code 只係入口,M3 先係背後嘅大腦。作者想睇嘅係呢三個能力夾埋,能唔能夠撐住一個真實長程任務。
第一個真活:2小時改做成 Agent Native 官網
任務係將 zaoxiaban.top 從 AI 編程課程官網改做成 Agent 主題官網。作者唔係叫佢「做個靚頁面」,而係要佢先診斷舊官網,重構資訊架構,再直接改代碼。
第一步係讀懂舊官網:頁面幾多個 section、視覺層級、互動入口、核心敍事有冇打出來
M3 用多模態理解咗現有頁面結構後,拉起 4 個 Agent 並行做調研同改造,最終落地方案包括以下改變:
- 頁面結構:由 11 個 section 變 8 個 section
- 課程敍事:由 4 個 Part 變成 4 階段 Agent 成長路徑
- 互動元素:由 1 個課程大綱展開變成 AI 輸入框、階段切換、試 Agent 演示
- 視覺風格:由亮色科技藍變成暗色、節點網絡、等寬字體
- 核心敍事:由「很多武器缺席」變成「搬上 Agent First 主線」
最後直接改咗 14 個文件(約 2000 行 TypeScript/TSX),3 個 JSON 數據重寫,5 個新組件,6 個靜態頁預渲染。dev server 2.3 秒啟動,首次渲染 3.3 秒。
第二個真活:用 M3 搭自己嘅寫作專家團
作者係得到AI學習圈特聘導師,買咗得到嘅「寫作專家團」之後,即刻諗到:自己個知識庫有成堆歷史文章、風格指南、核心概念、選題卡、思考記錄同 Skill,點解唔搭一個更似自己嘅寫作系統?
M3 先盤點本地素材:核心概念詞典、文風指南、MBTI、蓋洛普、價值觀、思考模式、爆款文稿庫、已發佈選題。然後畀出專家團方案,生成 Agent Team,仲自己構建咗反饋學習環。
作者用呢個系統跑咗 3 個 Cycle,風格一致性由 87.5% 升到 100%。最特別係風格畫像唔係套模板,而係反向編譯風格模式:Cycle 1 學到嘅口語化情緒表達,Cycle 2 自然複用;Cycle 1 缺嘅轉折句式,Cycle 3 補返。
第三個真活:將飛書知識庫做成可玩嘅探案室
第三個任務最得意:作者畀 M3 一份幾十萬字嘅飛書知識庫(社團資料、學習路徑、工具清單、直播回放、活動索引),但唔係叫佢總結,而係要改造成一個可以玩嘅網頁探案室。
M3 將文檔拆成 5 個房間:入門大廳、工具陳列室、雙線選擇器、直播回放室、終極核心。每個房間都有線索、問題、答案校驗、錯誤提示同通關覆盤。
呢個 Case 睇嘅係信息重構能力:唔係將資料壓扁做摘要,而係先抽結構、再設計關卡、再落成數據結構,最後寫成一個可運行嘅 Next.js 網頁。項目仲有 localStorage 進度保存、遞進提示、通關覆盤同演示模式。
點解 1M 上下文唔係炫技
好多人見到長上下文第一個反應係「塞一本書入去」。但作者最關心嘅係Agent 喺長任務裏面唔失憶。真實開發會經歷:讀需求 → 讀舊代碼 → 讀文檔 → 生成方案 → 寫代碼 → 跑 build → 睇報錯 → 回頭修 → 再跑 → 根據反饋改。
如果上下文撐唔住,就會出現頭先講過嘅約束後面唔記得、同樣 bug 重複修、風格變味。呢個唔係智商問題,係記憶問題。
最近呢幾日,大家都喺度試 MiniMax M3。
有人試登入頁重製,有人試影片理解,有人試網頁遊戲,亦有人試截圖寫程式碼。全部都唔錯,但我始終覺得爭啲嘢。
因為 M3 真正要睇嘅,唔係單點 Demo 上限,而係長任務後半段嘅穩定性。
真正麻煩嘅唔係「幫我寫一個頁面」咁簡單。真正麻煩嘅係:你有舊程式碼、舊文件、自己嘅知識庫、改到一半嘅需求,仲希望個模型唔係淨係表演俾你睇,而係真係接手一個複雜項目。
所以今次我冇淨係試細 Demo。我直接拎 M3 嚟跑三個真實任務:
跑完之後,我最大嘅感覺唔係「M3 會寫程式碼」,而係任務拖得越長、上下文越亂,佢就越能夠將前面嘅訊息同後面嘅動作串連埋一齊。
01 先講 M3 嘅更新
今次 M3 嘅更新,我覺得唔可以淨係睇參數,當然參數本身都好關鍵:
1M 上下文、原生多模態、Coding 同 Agentic 能力,表面睇係三個模型能力點。但放喺 Agent 時代,佢哋對應嘅其實係一個 Agent 大腦最關鍵嘅三件事。
第一,能夠記住現場。
長程任務唔係單輪問答。佢會經歷讀需求、讀資料、讀程式碼、寫方案、改檔案、跑構建、睇報錯、再修正。1M 上下文嘅意義,唔係「可以塞更多字」,而係等個模型喺任務後半段仲保留完整嘅工作現場。
第二,能夠睇得明現場。
真實任務裏面嘅輸入唔止文字。舊官網截圖、頁面結構、文件圖片、程式碼檔案、工具反饋,都有可能同時出現。原生多模態嘅價值,係等個模型唔止聽你描述,而係可以直接理解任務環境。
第三,能夠推動現場。
Coding 同 Agentic 能力決定咗個模型可唔可以將理解轉化成行動:拆任務、寫程式碼、調用工具、讀錯誤、繼續修改。好多模型俾到建議,但真實嘅工作流程需要佢將事情向前推進。
所以 MiniMax Code 只係入口,M3 先係背後嘅大腦:
我今次真正想睇嘅,唔係 MiniMax Code 嘅交互形態有幾順手,亦唔係 M3 會唔會調用工具,而係呢三個模型能力結合埋一齊之後,可唔可以撐住一個真實長程任務。
弱啲嘅模型,都可以開個好頭。但任務一長,就容易忘記約束、重複犯錯、改錯方向、整好一個地方又整壞另一個地方,最後變成「表面睇成日喺度忙,其實已經散咗」。
我想睇嘅得一件事:
M3 可唔可以將一個長任務,由開頭一路帶到結尾。
後面嘅三個 Case,都係圍繞呢件事展開。
02 第一個真活:2 小時,將營銷頁改成 Agent Native 官網
第一個任務,係改 zaoxiaban.top。
呢個網站原本係我嘅 AI 編程課程官網。但最近課程方向變咗,由「AI 編程社團」轉向「Agent 由小白到高手」。官網如果仲停留喺舊版本,就會好尷尬:口講 Agent,身體仲係傳統營銷頁。
我俾 M3 嘅任務,唔係「幫我做一個靚頁面」。而係等佢先診斷舊官網,再重構資訊架構,最後直接改程式碼。
呢個 Case 嘅關鍵,唔係純文字改程式碼。佢第一步係先「睇得明」舊官網:頁面有幾多 section,視覺層級係點,互動入口喺邊度,邊啲核心敍事冇被表達出嚟。
之後佢能夠判斷「PRD 寫 8 個 section,但實際頁面有 11 個」,本質上就係先用多模態理解咗現有頁面結構。
佢隨後拉起 4 個 Agent 並行做調研同改造。

最後落地嘅改造包括:
| 維度 | 改造前 | 改造後 |
| 頁面結構 | 11 個 section | 8 個 section |
| 課程敍事 | 4 個 Part | 4 階段 Agent 成長路徑 |
| 互動元素 | 1 個課程大綱展開 | AI 輸入框、階段切換、試 Agent 演示 |
| 視覺風格 | 亮色科技藍 SaaS 感 | 暗色、節點網絡、等寬字體 |
| 核心敍事 | 好多武器缺席 | 搬上 Agent First 主線 |
最後佢直接改咗程式碼:14 個檔案,大約 2000 行 TypeScript/TSX,3 個 JSON 數據重寫,5 個新組件,6 個靜態頁預渲染。dev server 2.3 秒啟動,首次渲染 3.3 秒,HTTP 200。
成個前端頁面嘅樣式都幾唔錯,而且佢特別聰明咁做咗一個 Agent 演示。
呢個 Case 嘅結論唔係「M3 會寫前端」。
更準確啲講,係:M3 能夠先睇得明一個真實產品嘅當前狀態,再將佢轉成工程改造方案。
睇得明頁面,係多模態;重構敍事,係產品判斷;最後改程式碼,係 Coding。三件事串連埋一齊,先係 Agentic Coding。
佢唔係淨係生成一個頁面,而係喺舊項目語境裏面連續完成「理解現狀 - 提出方案 - 修改程式碼 - 驗證結果」。真正有價值嘅係,呢條鏈冇喺後半段斷開。
03 第二個真活:用 M3 搭建自己嘅寫作專家團
第二個任務更貼近我嘅業務。
黃叔亦係得到 AI 學習圈嘅特聘導師,最近買咗得到嘅新產品:「得到大腦寫作專家團」,覺得幾好。
我即刻諗到一個問題:我嘅知識庫裏面本身就有大量歷史文章、風格指南、核心概念、選題卡、思考記錄同 Skill。咁點解唔可以搭建一個更加似我嘅寫作專家團呢?
我俾 M3 嘅目標唔係寫一篇文章,而係搭一個系統。

佢先盤點我本地已有素材:核心概念詞典、文風指南、00-我 裏面嘅 MBTI、蓋洛普、價值觀、思考模式、爆款文稿庫、已發佈選題。然後畀出專家團方案,並生成 Agent Team。

佢仲自己構建咗反饋學習環。即係話,呢個唔係一次性寫稿,而係一個會讀素材、分角色、跑多輪反饋嘅寫作系統。

我用佢跑咗 3 個 cycle:
| Cycle | 選題 | 耗時 | 風格一致性 |
| 1 | 唔好將 AI 當電子奶嘴 | 25 分鐘 | 87.5% |
| 2 | AI 唔係答案機 | 22 分鐘 | 100% |
| 3 | M3 三個月真實體驗 | 24 分鐘 | 100% |
呢度最有趣嘅係風格畫像嘅變化:Cycle 1 學到嘅口語化情緒表達,Cycle 2 自然重用;Cycle 1 欠缺嘅轉折句式,Cycle 3 補返。唔係套用模板,而係逆向編譯風格模式。
但呢個 Case 裏面,最令我舒服嘅唔係風格學習,而係角色邊界冇亂。
幾時係風格官,幾時係主筆官,幾時係參謀官,佢冇明顯嘅角色混淆。
多 Agent 協作最怕嘅唔係某個角色唔夠聰明,而係角色邊界亂咗:調研官開始寫作,主筆官開始扮審稿,參謀官開始幫你兜底。一亂,成個系統就廢咗。

第一個 Case 證明咗 M3 能夠接手工程:讀取舊程式碼、改檔案、跑 build。
第二個 Case 更深入一層,證明咗 M3 能夠喺一長串上下文裏面保持角色邊界、記住前面發生過嘅事,並將多輪反饋帶到後面嘅輸出裏面。
呢個 Case 睇嘅係 M3 嘅長程約束保持能力。多角色、多輪反饋、風格畫像、審核標準同時存在嘅時候,佢仲能夠維持角色邊界同寫作方向,呢個比起一次過生成一篇文章更加能夠暴露模型嘅能力。
04 第三個真活:將飛書知識庫做成可玩嘅探案室
第三個任務,我俾 M3 嘅唔係程式碼庫,亦唔係文章選題,而係一份飛書知識庫。
裏面係社團資料、學習路徑、工具清單、直播回放、活動索引。正常模型見到呢啲嘢,多數會總結成目錄,最多再生成一份 FAQ。
今次我冇叫佢總結。
我叫佢將呢份知識庫改造成一個可以玩嘅網頁探案室。呢個知識庫有幾十個章節,加埋有幾十萬字。

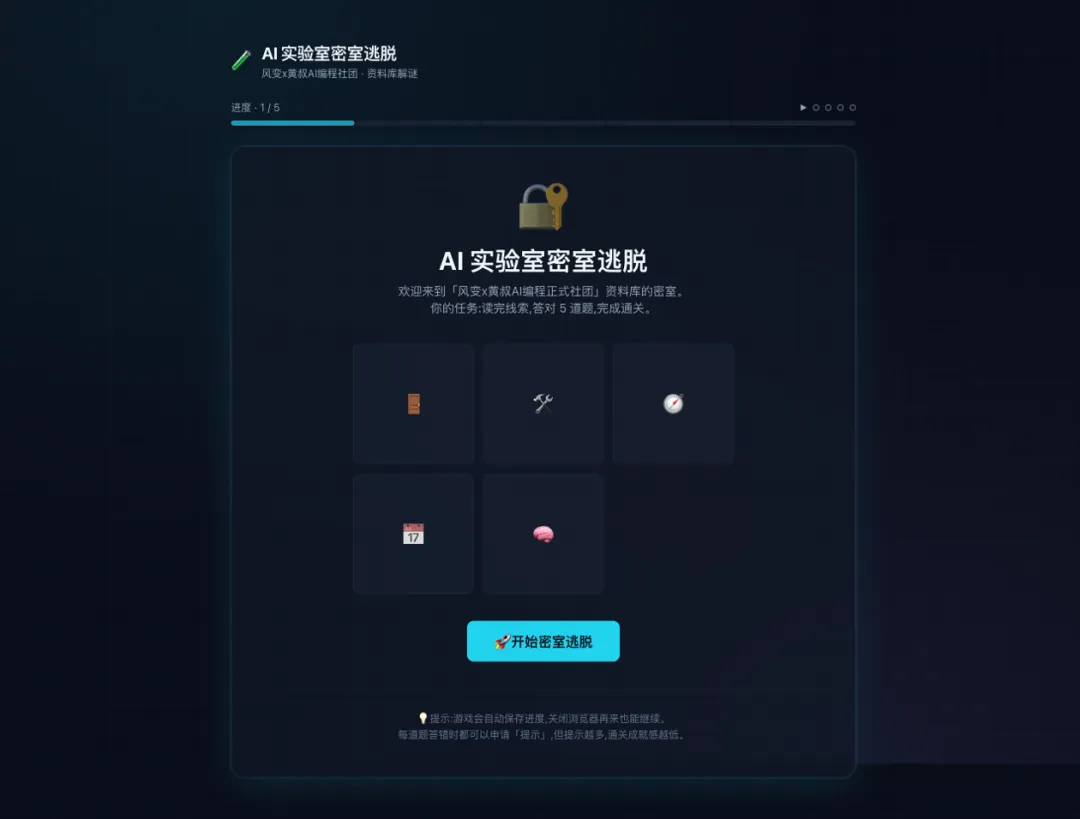
結果佢先將文檔拆成 5 個房間:入門大廳、工具陳列室、雙線選擇器、直播回放室、終極核心。每個房間都有線索、問題、答案校驗、錯誤提示同通關覆盤。
呢度最有趣嘅唔係佢寫咗幾多程式碼,而係佢真係理解咗資料庫嘅結構:邊啲內容適合做線索,邊啲資訊適合做謎題,最後玩家通關之後應該理解邊一句核心判斷。
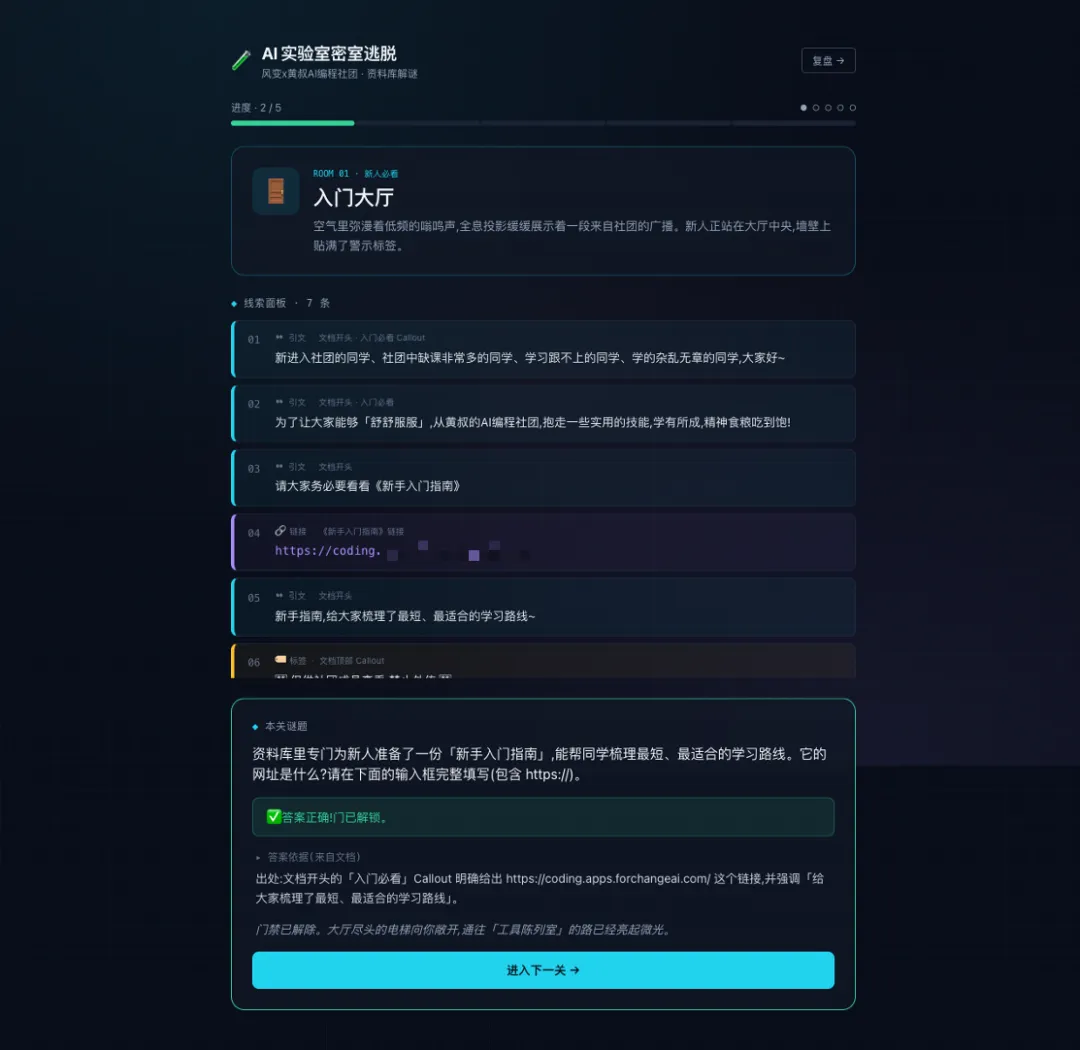
例如「入門大廳」考嘅係新人最應該先睇嘅入口;「雙線選擇器」考嘅係路徑 A 同路徑 B 嘅差異;「直播回放室」要求由一堆時間線裏面揾出 8 月 1 日直播嘅三個要點。玩家答啱之後,佢仲會展示答案依據係嚟自文檔邊度。
總結係將資料壓扁。呢個任務係將資料重新組織成一個互動產品。
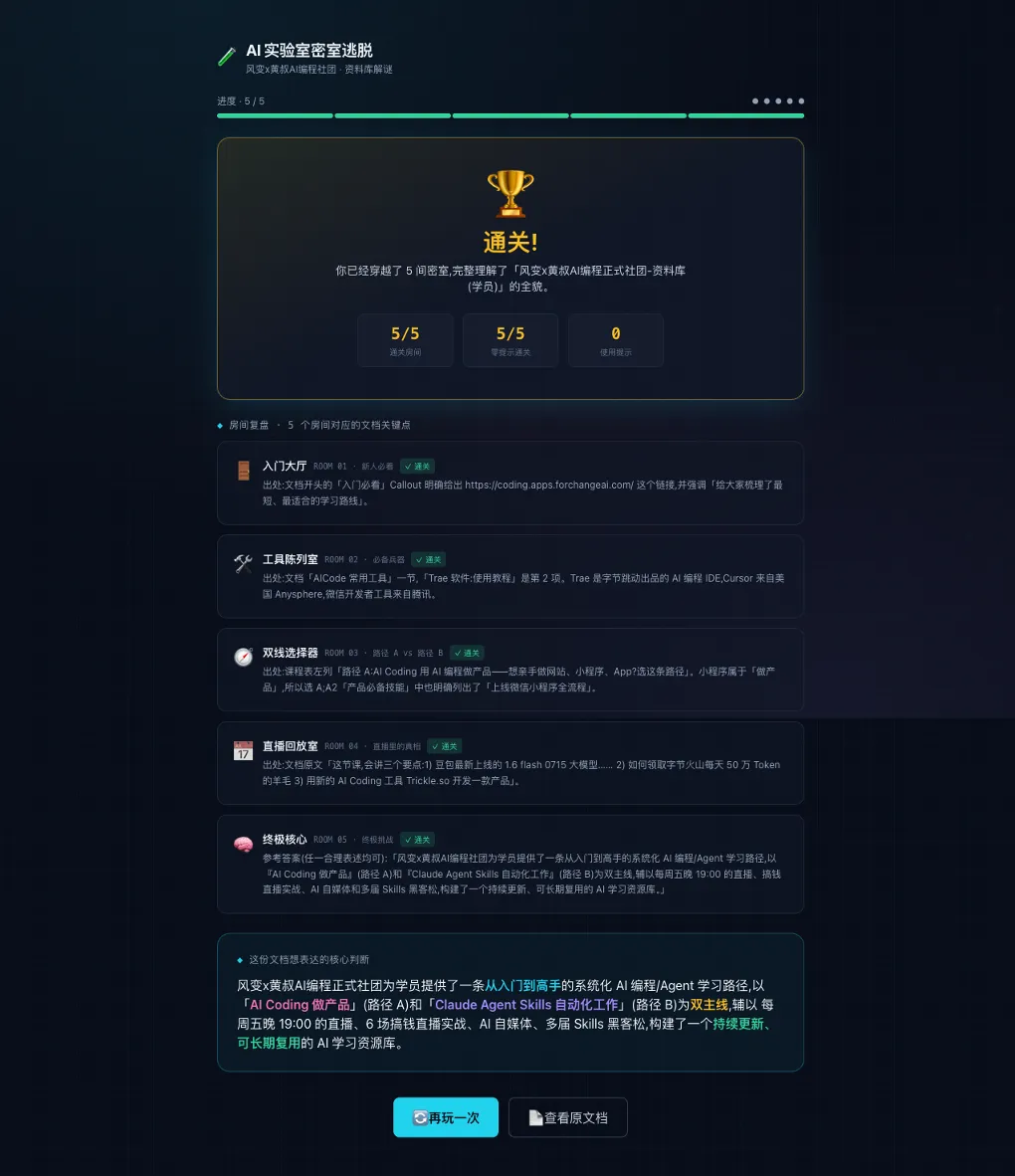
佢要先讀長文檔,再抽取結構,再設計關卡,再將內容落地成數據結構,最後寫成一個可以運行嘅 Next.js 網頁。項目裏面仲有 localStorage 進度保存、遞進提示、通關覆盤同演示模式。最後 build 通過。
呢個 Case 睇嘅係 M3 嘅資訊重構能力:佢唔係將飛書知識庫總結成摘要,而係先抽取章節結構同關鍵線索,再將資料重組為房間、謎題、狀態機同前端頁面。
官網改造,係佢接手工程。寫作專家團,係佢撐住長程。知識庫探案室,係佢將長上下文產品化。
呢三個結合埋一齊,先係我今次對 M3 嘅真實感受:佢唔係喺一個點上表演,而係喺一串任務裏面向前推進。
05 點解 1M 上下文唔係炫技
講到呢度,就可以返返去 M3 今次最重要嘅技術點:1M 上下文。
好多人見到長上下文,第一個反應係:咁我係咪可以塞一本書入去?當然可以。但呢個唔係我最關心嘅用法。
我最關心嘅係:Agent 喺長任務裏面可唔可以不失憶。
真實開發任務會經歷:讀需求、讀舊程式碼、讀文檔、生成方案、寫程式碼、跑 build、見到報錯、回頭修改、再跑、再根據用戶反饋改。
如果上下文撐唔住,就會出現一種好煩嘅狀態:前面啱啱講過嘅約束,後面唔記得;啱啱修好嘅 bug,又用同一種方法再修一次;啱啱定好嘅風格,寫到後面變咗味。
呢個唔係智商問題,而係記憶問題。
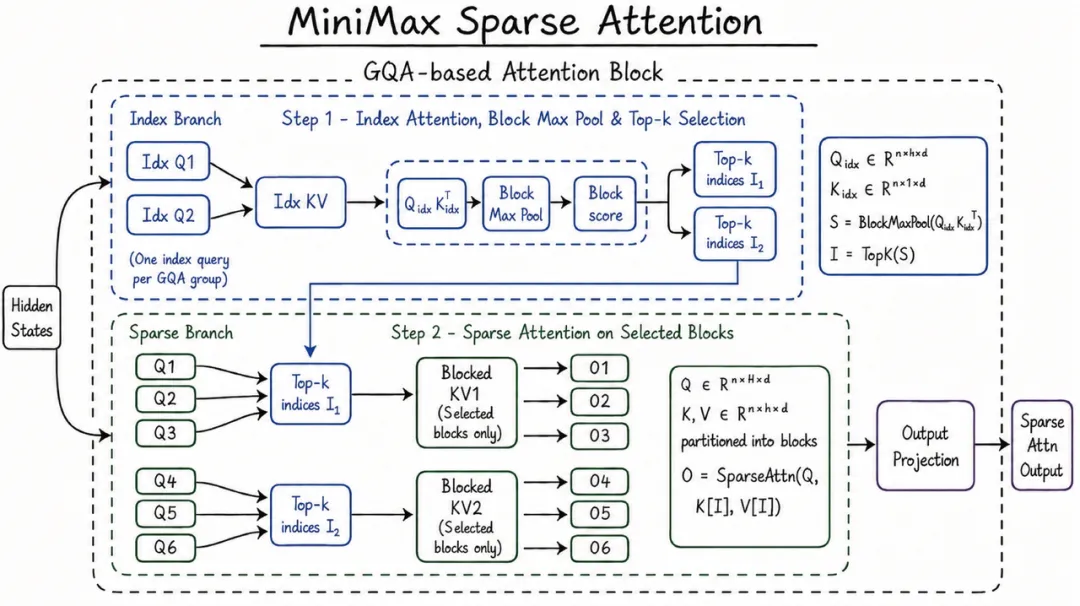
MiniMax 今次嘅 MSA 機制,簡單嚟講就係等個模型喺長上下文裏面將注意力用喺刀刃位。官方數據係,喺 100 萬上下文長度之下,每 token 計算量只有上一代嘅約 1/20,prefilling 階段加速約 9.7 倍,decoding 階段約 15.6 倍。
你唔需要記住呢啲技術細節。你只需要記住一句話:長上下文唔係為咗裝更多資料,而係為咗等個模型喺持續做嘢嘅時候冇咁容易失憶。
呢個亦係三個 Case 裏面最直接嘅體感。官網改造需要佢記住舊頁面、程式碼結構、知識庫概念同新方案;寫作專家團需要
佢記住我嘅風格畫像、個人經歷、核心概念同之前幾個 cycle 嘅反饋;知識庫探案室需要佢記住飛書資料庫嘅章節結構、線索來源、謎題答案同前端狀態機。
如果上下文唔穩定,呢啲任務都會變成:前半段仲似人做嘅,後半段開始似臨時工接手。
所以 1M 上下文真正支撐嘅,係等個模型喺長程任務後半段仲保留完整工作現場。
06 邊界:佢強喺邊,亦都應該知道邊啲唔好吹
講到呢度,好容易寫成一篇讚賞稿。但我唔想咁樣寫。
呢幾個案例亦都暴露咗 M3,或者話當前 Agent 工作流程嘅幾個邊界。
第一個邊界:長程穩定,唔等於全程自治。
M3 能夠將任務向前推進好多步,但當工具卡死、方向需要取捨、質量需要判斷嘅時候,人仍然要介入。
第二個邊界:模型更穩定,唔等於輸出天然可信。
尤其係寫作、數據、引用、知識庫重組呢類任務,模型越能夠將內容組織到好似真嘅一樣,人就越要檢查證據鏈。
第三個邊界:能夠做成產品,唔等於完全理解業務。
知識庫探案室可以運行,但邊啲線索嚟自原文,邊啲係模型重組,邊啲係為咗體驗做嘅簡化,都需要人類守住最後一道質量關。
呢三個邊界結合埋一齊,其實指向同一個判斷:M3 更適合長程任務,但佢唔係責任主體。
佢能夠將任務向前推進好多步,但最後嘅方向、事實、審美同業務取捨,仍然要有人守門。
07 Token 就係電:長程任務一定要敢用
最後補充一個好多人會忽略,但我覺得好關鍵嘅點。
如果你只係偶爾問模型幾句說話,價格差異唔明顯。但如果你開始用 Agent 跑真實任務,情況完全唔同。
官網改造會讀程式碼、讀文檔、寫方案、改檔案、跑構建、修錯誤;寫作專家團會讀歷史文章、讀知識庫、跑多角色審核;知識庫探案室則要將一份飛書資料庫讀完、拆結構、做關卡、寫前端、跑 build。呢啲全部都好食 token。
我一直有個比喻:Token 就係電。冇電,所有 Agent 都只係擺設。
你一旦開始唔捨得用 token,就會不自覺減少嘗試次數。少跑一輪調研,少跑一次 verifier,少叫 Agent 讀多幾個檔案,少叫佢再改一版。最後表面睇慳咗 token,其實係慳咗 Agent 個腦。
所以今次 MiniMax 嘅 Token Plan,我關心嘅唔係「平」呢一個點,而係佢可唔可以等用戶敢用。套餐數字截圖入面都有,但具體權益、周限額同可用額度,仍然以每個人控制枱顯示為準。
呢度要講清楚一點:Token Plan 今次本身亦喺度升級,由過去偏向訂閲額度嘅理解,轉到更行業通用嘅 Token-Based 計量。呢個變化對長程 Agent 係合理嘅,因為 M3 更大、更智能、有原生多模態同 1M 上下文,本來就會食更多算力。
我自己呢輪測試,前後跑咗 2 至 3 個鐘,包括官網改造、專家團同知識庫探案室,喺 5 小時/周額度裏面並冇打穿額度。不過我嘅賬號有歷史權益,下面呢張圖只能夠說明呢輪任務嘅實際消耗感受,唔可以直接代表所有新購賬號。
官方今次亦都提供咗幾類過渡補貼:
建議有興趣嘅人可以快啲去購買 Token Plan,享用最新嘅福利。
08 結論
所以我最後嘅判斷係:M3 今次真正拉開嘅,唔係 Demo 上限,而係長程任務嘅下限。
以前好多模型都可以寫頁面、寫文章、寫一段程式碼。但任務一長,開始涉及舊項目、飛書知識庫、本地檔案、工具反饋、反覆修改,差距就出咗嚟。
弱啲嘅模型,頭幾步都可以跑得幾靚。但跑到後面,容易忘記約束、改錯方向、重複犯錯,最後變成「表面睇成日喺度忙,其實冇向前行」。
M3 今次令我睇到嘅,係佢更加能夠將一串事串連埋一齊:讀資料、拆任務、做方案、改程式碼、跑驗證、食反饋,再繼續向前推。
唔好淨係試 Demo。俾佢一條完整任務鏈。
能夠將呢條鏈跑得順,先係 Agent 模型。跑唔順,再靚嘅 Demo 都只係樣版。
最近這幾天,大家都在測 MiniMax M3。
有人測登錄頁復刻,有人測視頻理解,有人測網頁遊戲,也有人測截圖寫代碼。都挺好,但我總覺得還差一點。
因為 M3 真正要看的,不是單點 Demo 上限,而是長任務後半程的穩定性。
真正麻煩的不是“給我寫一個頁面”。真正麻煩的是:你有舊代碼、舊文檔、自己的知識庫、改了一半的需求,還希望模型不是給你表演,而是真的接住一個複雜項目。
所以這次我沒有隻測小 Demo。我直接拿 M3 跑了三個真實任務:
跑完之後,我最大的體感不是“M3 會寫代碼”,而是任務越拖長、上下文越亂,它越能把前面的信息和後面的動作接起來。
01 先說 M3 的更新
這次 M3 的更新,我覺得不能只看參數,當然參數本身也很關鍵:
1M 上下文、原生多模態、Coding 和 Agentic 能力,表面上是三個模型能力點。但放到 Agent 時代,它們其實對應的是一個 Agent 大腦最關鍵的三件事。
第一,能記住現場。
長程任務不是單輪問答。它會經歷讀需求、讀資料、讀代碼、寫方案、改文件、跑構建、看報錯、再修正。1M 上下文的意義,不是“能塞更多字”,而是讓模型在任務後半程還保留完整工作現場。
第二,能看懂現場。
真實任務裏的輸入不只是文字。舊官網截圖、頁面結構、文檔圖片、代碼文件、工具反饋,都可能同時出現。原生多模態的價值,是讓模型不只聽你描述,而是能直接理解任務環境。
第三,能推動現場。
Coding 和 Agentic 能力決定了模型能不能把理解轉成行動:拆任務、寫代碼、調工具、讀錯誤、繼續修。很多模型能給建議,但真實工作流需要它把事情往前推。
所以 MiniMax Code 只是入口,M3 才是背後的大腦:
我這次真正想看的,不是 MiniMax Code 的交互形態有多順手,也不是 M3 會不會調用工具,而是這三個模型能力合在一起之後,能不能撐住一個真實長程任務。
弱一點的模型,也能把任務開個好頭。但任務一長,就容易忘約束、重複犯錯、改偏方向、修一個地方壞另一個地方,最後變成“看起來一直在忙,其實已經散了”。
我想看的只有一件事:
M3 能不能把一個長任務,從開頭一路帶到結尾。
後面的三個 Case,都是圍繞這件事展開。
02 第一個真活:2 小時,把營銷頁改成 Agent Native 官網
第一個任務,是改 zaoxiaban.top。
這個網站原來是我的 AI 編程課程官網。但最近課程方向變了,從“AI 編程社團”,轉向“Agent 從小白到高手”。官網如果還停在之前的版本里,就會很尷尬:嘴上說 Agent,身體還是傳統營銷頁。
我給 M3 的任務,不是“幫我做一個漂亮頁面”。而是讓它先診斷舊官網,再重構信息架構,最後直接改代碼。
這個 Case 的關鍵,不是純文本改代碼。它第一步是先“看懂”舊官網:頁面有多少 section,視覺層級是什麼,互動入口在哪裏,哪些核心敍事沒有被打出來。
後面它能判斷“PRD 寫 8 個 section,但實際頁面有 11 個”,本質上就是先用多模態理解了現有頁面結構。
它隨後拉起 4 個 Agent 並行做調研和改造。
最後落地的改造包括:
| 維度 | 改造前 | 改造後 |
| 頁面結構 | 11 個 section | 8 個 section |
| 課程敍事 | 4 個 Part | 4 階段 Agent 成長路徑 |
| 互動元素 | 1 個課程大綱展開 | AI 輸入框、階段切換、試 Agent 演示 |
| 視覺風格 | 亮色科技藍 SaaS 感 | 暗色、節點網絡、等寬字體 |
| 核心敍事 | 很多武器缺席 | 搬上 Agent First 主線 |
最後它直接改了代碼:14 個文件,大約 2000 行 TypeScript/TSX,3 個 JSON 數據重寫,5 個新組件,6 個靜態頁預渲染。dev server 2.3 秒啓動,首次渲染 3.3 秒,HTTP 200。
整個前端頁面的樣式還是挺不錯的,並且它特別聰明的做了一個Agent演示。
這個 Case 的結論不是“M3 會寫前端”。
更準確地說,是:M3 能先看懂一個真實產品的當前狀態,再把它轉成工程改造方案。
看懂頁面,是多模態;重構敍事,是產品判斷;最後改代碼,是 Coding。三件事連起來,才是 Agentic Coding。
它不是隻生成一個頁面,而是在舊項目語境裏連續完成“理解現狀 - 提出方案 - 修改代碼 - 驗證結果”。真正有價值的是,這條鏈沒有在後半程斷掉。
03 第二個真活:用 M3 搭自己的寫作專家團
第二個任務更貼近我的業務。
黃叔也是得到AI學習圈的特聘導師,最近購買了得到的新產品:“得到大腦寫作專家團”,感覺還不錯。
我馬上想到一個問題:我自己的知識庫裏,本來就有大量歷史文章、風格指南、核心概念、選題卡、思考記錄和 Skill。那為什麼不能搭一個更像我的寫作專家團?
我給 M3 的目標不是寫一篇文章,而是搭一個系統。
它先盤點我本地已有素材:核心概念詞典、文風指南、00-我 裏的 MBTI、蓋洛普、價值觀、思考模式、爆款文稿庫、已發佈選題。然後給出專家團方案,並生成 Agent Team。
它還自己構建了反饋學習環。也就是說,這不是一次性寫稿,而是一個會讀素材、分角色、跑多輪反饋的寫作系統。
我用它跑了 3 個 cycle:
| Cycle | 選題 | 耗時 | 風格一致性 |
| 1 | 別把 AI 當電子奶嘴 | 25 分鐘 | 87.5% |
| 2 | AI 不是答案機 | 22 分鐘 | 100% |
| 3 | M3 三個月真實體驗 | 24 分鐘 | 100% |
這裏最有意思的是風格畫像的變化:Cycle 1 學到的口語化情緒表達,Cycle 2 自然複用;Cycle 1 缺的轉折句式,Cycle 3 補回來。不是套模板,是在反向編譯風格模式。
但這個 Case 裏,最讓我舒服的不是風格學習,而是角色邊界沒亂。
什麼時候是風格官,什麼時候是主筆官,什麼時候是參謀官,它沒有明顯串台。
多 Agent 協作最怕的不是某個角色不夠聰明,而是角色邊界亂掉:調研官開始寫作,主筆官開始假裝審稿,參謀官開始替你圓場。一亂,整個系統就廢了。
第一個 Case 證明的是 M3 能接工程:讀舊代碼、改文件、跑 build。
第二個 Case 更深一層,證明的是 M3 能在一長串上下文裏保持角色邊界、記住前面發生了什麼,並把多輪反饋帶到後面的輸出裏。
這個 Case 看的是 M3 的長程約束保持能力。多角色、多輪反饋、風格畫像、審核標準同時存在時,它還能維持角色邊界和寫作方向,這比單次生成一篇文章更能暴露模型能力。
04 第三個真活:把飛書知識庫做成可玩的探案室
第三個任務,我給 M3 的不是代碼庫,也不是文章選題,而是一份飛書知識庫。
裏面是社團資料、學習路徑、工具清單、直播回放、活動索引。正常模型看到這種東西,大概率會給你總結成目錄,最多再生成一份 FAQ。
這次我沒有讓它總結。
我讓它把這份知識庫改造成一個可以玩的網頁探案室。這個知識庫有幾十個章節,加起來幾十萬字。
結果它先把文檔拆成 5 個房間:入門大廳、工具陳列室、雙線選擇器、直播回放室、終極核心。每個房間都有線索、問題、答案校驗、錯誤提示和通關覆盤。
這裏最有意思的不是它寫了多少代碼,而是它真的理解了資料庫的結構:哪些內容適合做線索,哪些信息適合做謎題,最後玩家通關後應該理解哪一句核心判斷。
比如“入門大廳”考的是新人最該先看的入口;“雙線選擇器”考的是路徑 A 和路徑 B 的差異;“直播回放室”要求從一堆時間線裏找出 8 月 1 日直播的三個要點。玩家答對以後,它還會展示答案依據來自文檔哪裏。
總結是把資料壓扁。這個任務是把資料重新組織成一個交互產品。
它要先讀長文檔,再抽結構,再設計關卡,再把內容落成數據結構,最後寫成一個可運行的 Next.js 網頁。項目裏還有 localStorage 進度保存、遞進提示、通關覆盤和演示模式。最後 build 通過。
這個 Case 看的是 M3 的信息重構能力:它不是把飛書知識庫總結成摘要,而是先抽取章節結構和關鍵線索,再把資料重組為房間、謎題、狀態機和前端頁面。
官網改造,是它接工程。寫作專家團,是它撐長程。知識庫探案室,是它把長上下文產品化。
這三個合在一起,才是我這次對 M3 的真實感受:它不是在一個點上表演,而是在一串任務裏往前推進。
05 為什麼 1M 上下文不是炫技
講到這裏,就能回到 M3 這次最重要的技術點:1M 上下文。
很多人看到長上下文,第一反應是:那我是不是可以塞一本書進去?當然可以。但這不是我最關心的用法。
我真正關心的是:Agent 在長任務裏能不能不失憶。
真實開發任務會經歷:讀需求、讀舊代碼、讀文檔、生成方案、寫代碼、跑 build、看到報錯、回頭修、再跑、再根據用戶反饋改。
如果上下文撐不住,就會出現一種很煩人的狀態:前面剛說過的約束,後面忘了;剛修過的 bug,又用同樣方法再修一遍;剛定好的風格,寫到後面變味了。
這不是智商問題,是記憶問題。
MiniMax 這次的 MSA 機制,簡單說就是讓模型在長上下文裏把注意力用在刀刃上。官方數據是,在 100 萬上下文長度下,每 token 計算量只有上一代的約 1/20,prefilling 階段加速約 9.7 倍,decoding 階段約 15.6 倍。
你不需要記住這些技術細節。你只要記住一句話:長上下文不是為了裝更多資料,而是為了讓模型在持續幹活時不那麼容易失憶。
這也是三個 Case 裏最直觀的體感。官網改造需要它記住舊頁面、代碼結構、知識庫概念和新方案;寫作專家團需要
它記住我的風格畫像、個人經歷、核心概念和前幾個 cycle 的反饋;知識庫探案室需要它記住飛書資料庫的章節結構、線索來源、謎題答案和前端狀態機。
如果上下文不穩,這些任務都會變成:前半段還像人乾的,後半段開始像臨時工接班。
所以 1M 上下文真正支撐的,是讓模型在長程任務後半段還保留完整工作現場。
06 邊界:它強在哪,也該知道哪不該吹
說到這裏,容易寫成一篇誇誇稿。但我不想這麼寫。
這幾個案例也暴露了 M3,或者說當前 Agent 工作流的幾個邊界。
第一個邊界:長程穩定,不等於全程自治。
M3 能把任務往前推很多步,但當工具卡死、方向需要取捨、質量需要判斷時,人仍然要介入。
第二個邊界:模型更穩,不等於輸出天然可信。
尤其是寫作、數據、引用、知識庫重組這類任務,模型越能把內容組織得像真的,人越要檢查證據鏈。
第三個邊界:能做成產品,不等於完全理解業務。
知識庫探案室能跑起來,但哪些線索來自原文,哪些是模型重組,哪些是為了體驗做的簡化,都需要人守最後一道質量門。
這三個邊界合在一起,其實指向同一個判斷:M3 更適合長程任務,但它不是責任主體。
它能把任務往前推很多步,但最後的方向、事實、審美和業務取捨,還是要有人守門。
07 Token 就是電:長程任務必須敢用
最後補一個很多人會忽略,但我覺得很關鍵的點。
如果你只是偶爾問模型幾句話,價格差異不明顯。但如果你開始用 Agent 跑真實任務,情況完全不一樣。
官網改造會讀代碼、讀文檔、寫方案、改文件、跑構建、修錯誤;寫作專家團會讀歷史文章、讀知識庫、跑多角色審核;知識庫探案室則要把一份飛書資料庫讀完、拆結構、做關卡、寫前端、跑 build。這些都很吃 token。
我之前一直有個類比:Token 就是電。沒有電,所有 Agent 都只是擺設。
你一旦開始心疼 token,就會下意識減少嘗試次數。少跑一輪調研,少跑一次 verifier,少讓 Agent 多讀幾個文件,少讓它再改一版。最後看起來省了 token,其實是在省 Agent 的腦子。
所以這次 MiniMax 的 Token Plan,我關心的不是“便宜”這一個點,而是它能不能讓用戶敢用。套餐數字截圖裏都有,但具體權益、周限額和可用額度,還是以每個人控制枱顯示為準。
這裏要說清楚一點:Token Plan 這次本身也在升級,從過去更偏訂閲額度的理解,切到更行業通用的 Token-Based 計量。這個變化對長程 Agent 是合理的,因為 M3 更大、更智能、有原生多模態和 1M 上下文,本來就會吃更多算力。
我自己這輪測試,前後跑了 2-3 個小時,包括官網改造、專家團和知識庫探案室,在 5 小時/周額度裏並沒有把額度打穿。不過我的賬號有歷史權益,下面這張圖只能說明這輪任務的實際消耗感受,不能直接代表所有新購賬號。
官方這次也給了幾類過渡補貼:
建議大家感興趣的可以趕緊去購買一下Token Plan,享受最新的福利。
08 結論
所以我最後的判斷是:M3 這次真正拉開的,不是 Demo 上限,而是長程任務的下限。
以前很多模型也能寫頁面、寫文章、寫一段代碼。但任務一變長,開始涉及舊項目、飛書知識庫、本地文件、工具反饋、反覆修改,差距就出來了。
弱一點的模型,前幾步也能跑得挺漂亮。但跑到後面,容易忘約束、改錯方向、重複犯錯,最後變成“看起來一直在忙,其實沒往前走”。
M3 這次讓我看到的,是它更能把一串事接起來:讀資料、拆任務、做方案、改代碼、跑驗證、吃反饋,再繼續往前推。
別隻測 Demo。給它一條完整任務鏈。
能把這條鏈跑順,才是 Agent 模型。跑不順,再漂亮的 Demo 都只是樣片。